 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Brightness-Restricted Adversarial Attack Patch
Jul 01, 2023
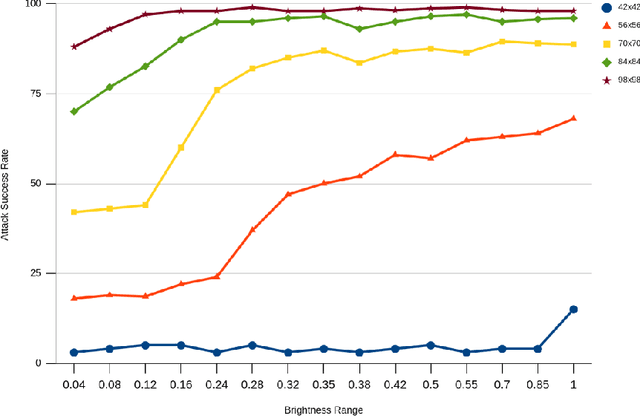

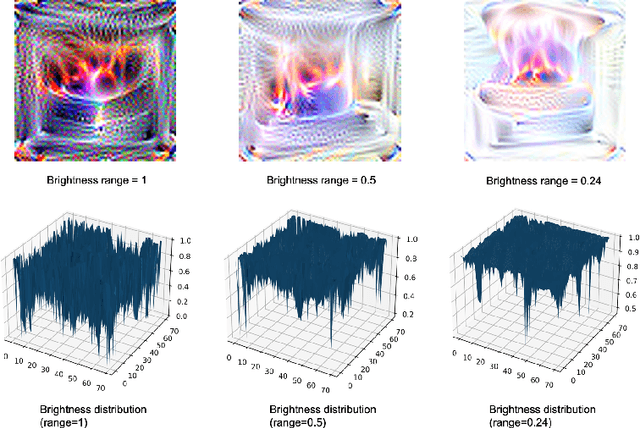
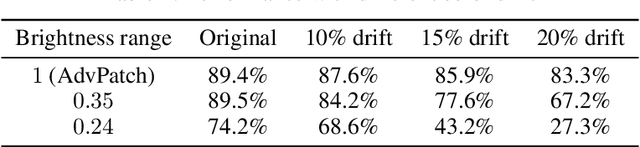
Adversarial attack patches have gained increasing attention due to their practical applicability in physical-world scenarios. However, the bright colors used in attack patches represent a significant drawback, as they can be easily identified by human observers. Moreover, even though these attacks have been highly successful in deceiving target networks, which specific features of the attack patch contribute to its success are still unknown. Our paper introduces a brightness-restricted patch (BrPatch) that uses optical characteristics to effectively reduce conspicuousness while preserving image independence. We also conducted an analysis of the impact of various image features (such as color, texture, noise, and size) on the effectiveness of an attack patch in physical-world deployment. Our experiments show that attack patches exhibit strong redundancy to brightness and are resistant to color transfer and noise. Based on our findings, we propose some additional methods to further reduce the conspicuousness of BrPatch. Our findings also explain the robustness of attack patches observed in physical-world scenarios.
NoisyTwins: Class-Consistent and Diverse Image Generation through StyleGANs
Apr 12, 2023


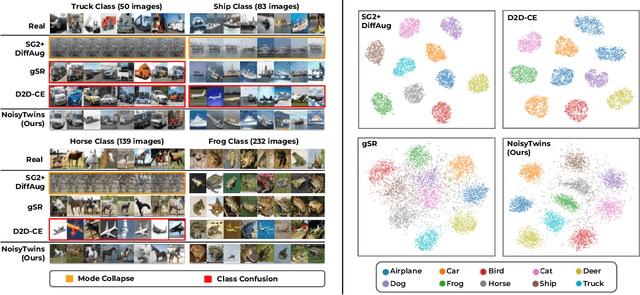
StyleGANs are at the forefront of controllable image generation as they produce a latent space that is semantically disentangled, making it suitable for image editing and manipulation. However, the performance of StyleGANs severely degrades when trained via class-conditioning on large-scale long-tailed datasets. We find that one reason for degradation is the collapse of latents for each class in the $\mathcal{W}$ latent space. With NoisyTwins, we first introduce an effective and inexpensive augmentation strategy for class embeddings, which then decorrelates the latents based on self-supervision in the $\mathcal{W}$ space. This decorrelation mitigates collapse, ensuring that our method preserves intra-class diversity with class-consistency in image generation. We show the effectiveness of our approach on large-scale real-world long-tailed datasets of ImageNet-LT and iNaturalist 2019, where our method outperforms other methods by $\sim 19\%$ on FID, establishing a new state-of-the-art.
CLR: Channel-wise Lightweight Reprogramming for Continual Learning
Jul 21, 2023Continual learning aims to emulate the human ability to continually accumulate knowledge over sequential tasks. The main challenge is to maintain performance on previously learned tasks after learning new tasks, i.e., to avoid catastrophic forgetting. We propose a Channel-wise Lightweight Reprogramming (CLR) approach that helps convolutional neural networks (CNNs) overcome catastrophic forgetting during continual learning. We show that a CNN model trained on an old task (or self-supervised proxy task) could be ``reprogrammed" to solve a new task by using our proposed lightweight (very cheap) reprogramming parameter. With the help of CLR, we have a better stability-plasticity trade-off to solve continual learning problems: To maintain stability and retain previous task ability, we use a common task-agnostic immutable part as the shared ``anchor" parameter set. We then add task-specific lightweight reprogramming parameters to reinterpret the outputs of the immutable parts, to enable plasticity and integrate new knowledge. To learn sequential tasks, we only train the lightweight reprogramming parameters to learn each new task. Reprogramming parameters are task-specific and exclusive to each task, which makes our method immune to catastrophic forgetting. To minimize the parameter requirement of reprogramming to learn new tasks, we make reprogramming lightweight by only adjusting essential kernels and learning channel-wise linear mappings from anchor parameters to task-specific domain knowledge. We show that, for general CNNs, the CLR parameter increase is less than 0.6\% for any new task. Our method outperforms 13 state-of-the-art continual learning baselines on a new challenging sequence of 53 image classification datasets. Code and data are available at https://github.com/gyhandy/Channel-wise-Lightweight-Reprogramming
Pix2Video: Video Editing using Image Diffusion
Mar 22, 2023

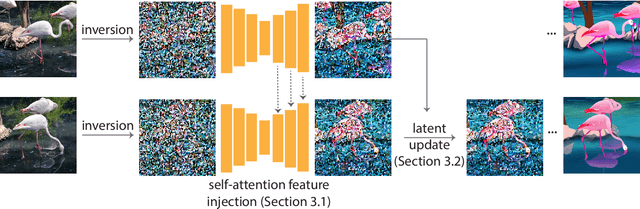
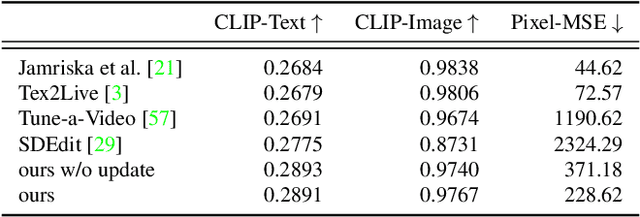
Image diffusion models, trained on massive image collections, have emerged as the most versatile image generator model in terms of quality and diversity. They support inverting real images and conditional (e.g., text) generation, making them attractive for high-quality image editing applications. We investigate how to use such pre-trained image models for text-guided video editing. The critical challenge is to achieve the target edits while still preserving the content of the source video. Our method works in two simple steps: first, we use a pre-trained structure-guided (e.g., depth) image diffusion model to perform text-guided edits on an anchor frame; then, in the key step, we progressively propagate the changes to the future frames via self-attention feature injection to adapt the core denoising step of the diffusion model. We then consolidate the changes by adjusting the latent code for the frame before continuing the process. Our approach is training-free and generalizes to a wide range of edits. We demonstrate the effectiveness of the approach by extensive experimentation and compare it against four different prior and parallel efforts (on ArXiv). We demonstrate that realistic text-guided video edits are possible, without any compute-intensive preprocessing or video-specific finetuning.
Does Saliency-Based Training bring Robustness for Deep Neural Networks in Image Classification?
Jun 28, 2023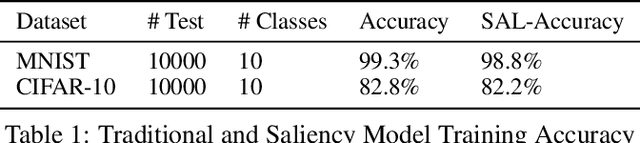
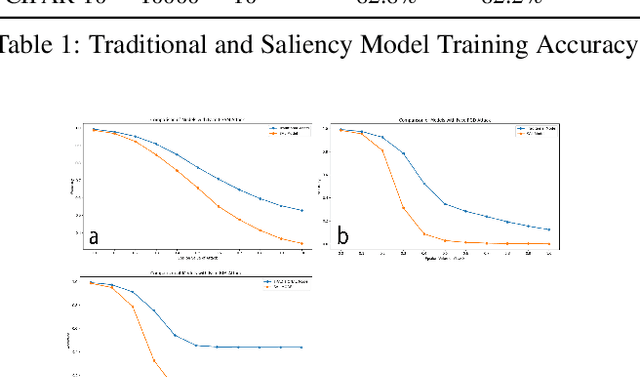
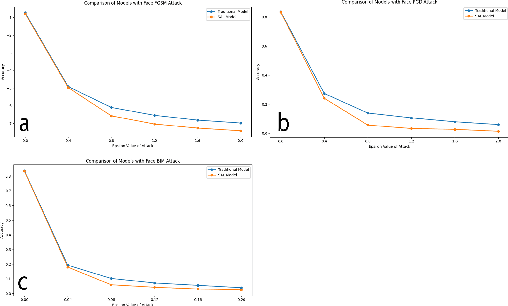
Deep Neural Networks are powerful tools to understand complex patterns and making decisions. However, their black-box nature impedes a complete understanding of their inner workings. While online saliency-guided training methods try to highlight the prominent features in the model's output to alleviate this problem, it is still ambiguous if the visually explainable features align with robustness of the model against adversarial examples. In this paper, we investigate the saliency trained model's vulnerability to adversarial examples methods. Models are trained using an online saliency-guided training method and evaluated against popular algorithms of adversarial examples. We quantify the robustness and conclude that despite the well-explained visualizations in the model's output, the salient models suffer from the lower performance against adversarial examples attacks.
Predicting mechanical properties of Carbon Nanotube (CNT) images Using Multi-Layer Synthetic Finite Element Model Simulations
Jul 16, 2023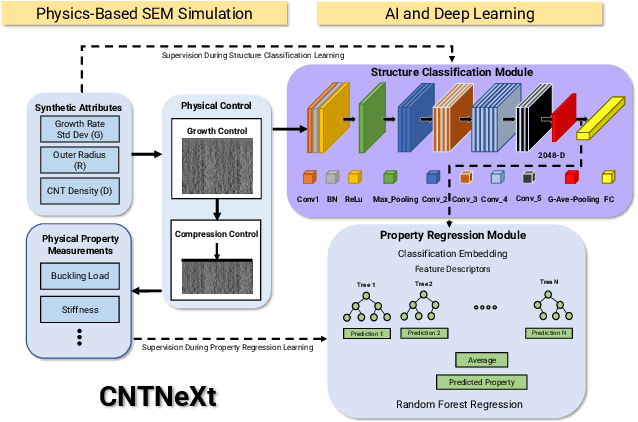
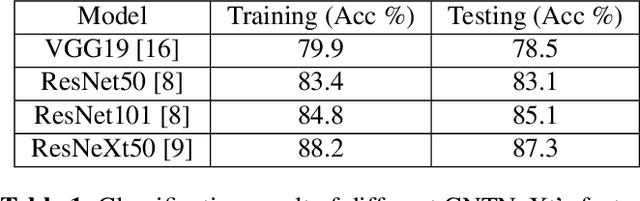

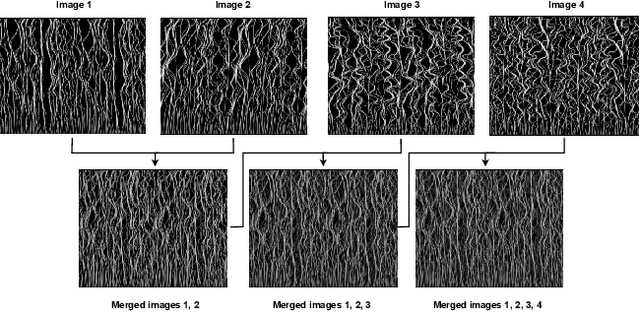
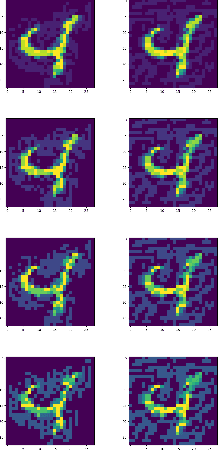
We present a pipeline for predicting mechanical properties of vertically-oriented carbon nanotube (CNT) forest images using a deep learning model for artificial intelligence (AI)-based materials discovery. Our approach incorporates an innovative data augmentation technique that involves the use of multi-layer synthetic (MLS) or quasi-2.5D images which are generated by blending 2D synthetic images. The MLS images more closely resemble 3D synthetic and real scanning electron microscopy (SEM) images of CNTs but without the computational cost of performing expensive 3D simulations or experiments. Mechanical properties such as stiffness and buckling load for the MLS images are estimated using a physics-based model. The proposed deep learning architecture, CNTNeXt, builds upon our previous CNTNet neural network, using a ResNeXt feature representation followed by random forest regression estimator. Our machine learning approach for predicting CNT physical properties by utilizing a blended set of synthetic images is expected to outperform single synthetic image-based learning when it comes to predicting mechanical properties of real scanning electron microscopy images. This has the potential to accelerate understanding and control of CNT forest self-assembly for diverse applications.
Fast Marching Energy CNN
Jun 28, 2023Leveraging geodesic distances and the geometrical information they convey is key for many data-oriented applications in imaging. Geodesic distance computation has been used for long for image segmentation using Image based metrics. We introduce a new method by generating isotropic Riemannian metrics adapted to a problem using CNN and give as illustrations an example of application. We then apply this idea to the segmentation of brain tumours as unit balls for the geodesic distance computed with the metric potential output by a CNN, thus imposing geometrical and topological constraints on the output mask. We show that geodesic distance modules work well in machine learning frameworks and can be used to achieve state-of-the-art performances while ensuring geometrical and/or topological properties.
InterFormer: Real-time Interactive Image Segmentation
Apr 06, 2023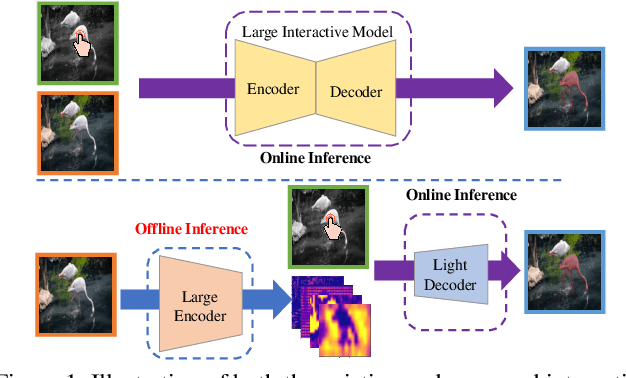

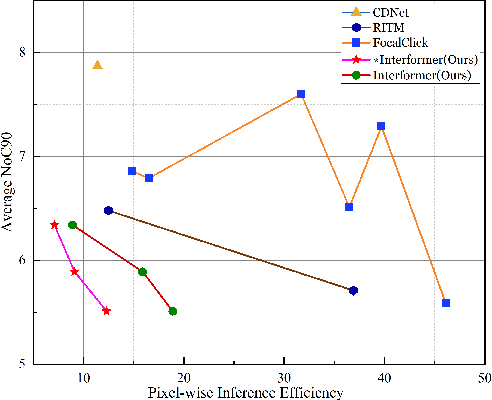
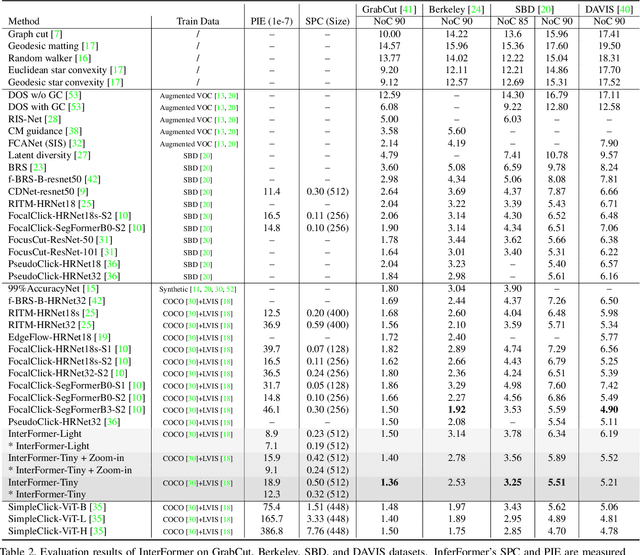
Interactive image segmentation enables annotators to efficiently perform pixel-level annotation for segmentation tasks. However, the existing interactive segmentation pipeline suffers from inefficient computations of interactive models because of the following two issues. First, annotators' later click is based on models' feedback of annotators' former click. This serial interaction is unable to utilize model's parallelism capabilities. Second, the model has to repeatedly process the image, the annotator's current click, and the model's feedback of the annotator's former clicks at each step of interaction, resulting in redundant computations. For efficient computation, we propose a method named InterFormer that follows a new pipeline to address these issues. InterFormer extracts and preprocesses the computationally time-consuming part i.e. image processing from the existing process. Specifically, InterFormer employs a large vision transformer (ViT) on high-performance devices to preprocess images in parallel, and then uses a lightweight module called interactive multi-head self attention (I-MSA) for interactive segmentation. Furthermore, the I-MSA module's deployment on low-power devices extends the practical application of interactive segmentation. The I-MSA module utilizes the preprocessed features to efficiently response to the annotator inputs in real-time. The experiments on several datasets demonstrate the effectiveness of InterFormer, which outperforms previous interactive segmentation models in terms of computational efficiency and segmentation quality, achieve real-time high-quality interactive segmentation on CPU-only devices.
Optimizing PatchCore for Few/many-shot Anomaly Detection
Jul 20, 2023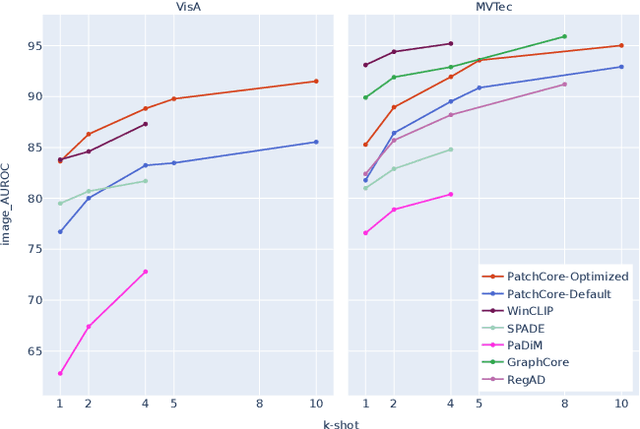
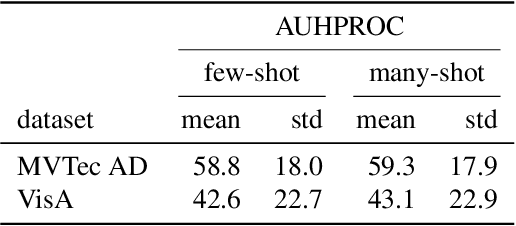
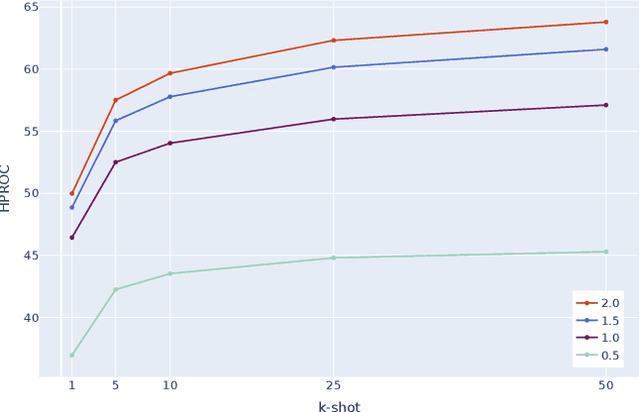
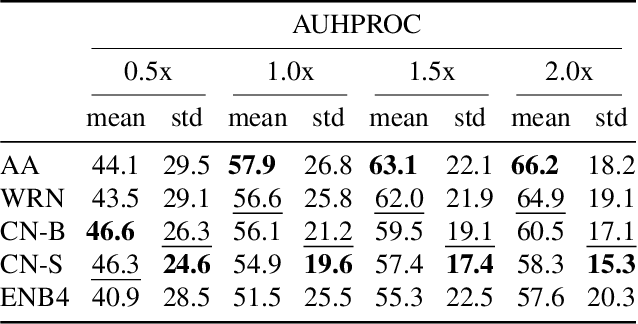
Few-shot anomaly detection (AD) is an emerging sub-field of general AD, and tries to distinguish between normal and anomalous data using only few selected samples. While newly proposed few-shot AD methods do compare against pre-existing algorithms developed for the full-shot domain as baselines, they do not dedicatedly optimize them for the few-shot setting. It thus remains unclear if the performance of such pre-existing algorithms can be further improved. We address said question in this work. Specifically, we present a study on the AD/anomaly segmentation (AS) performance of PatchCore, the current state-of-the-art full-shot AD/AS algorithm, in both the few-shot and the many-shot settings. We hypothesize that further performance improvements can be realized by (I) optimizing its various hyperparameters, and by (II) transferring techniques known to improve few-shot supervised learning to the AD domain. Exhaustive experiments on the public VisA and MVTec AD datasets reveal that (I) significant performance improvements can be realized by optimizing hyperparameters such as the underlying feature extractor, and that (II) image-level augmentations can, but are not guaranteed, to improve performance. Based on these findings, we achieve a new state of the art in few-shot AD on VisA, further demonstrating the merit of adapting pre-existing AD/AS methods to the few-shot setting. Last, we identify the investigation of feature extractors with a strong inductive bias as a potential future research direction for (few-shot) AD/AS.
Topology-Aware Uncertainty for Image Segmentation
Jun 09, 2023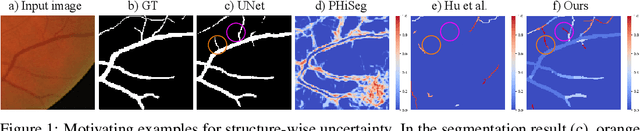
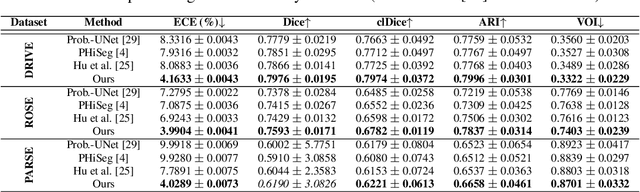

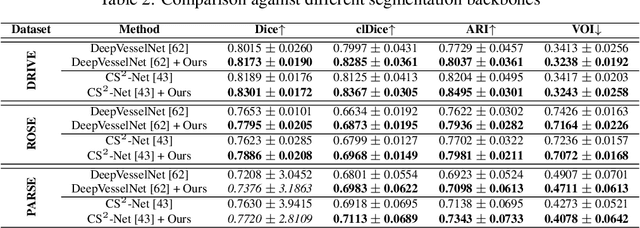
Segmentation of curvilinear structures such as vasculature and road networks is challenging due to relatively weak signals and complex geometry/topology. To facilitate and accelerate large scale annotation, one has to adopt semi-automatic approaches such as proofreading by experts. In this work, we focus on uncertainty estimation for such tasks, so that highly uncertain, and thus error-prone structures can be identified for human annotators to verify. Unlike most existing works, which provide pixel-wise uncertainty maps, we stipulate it is crucial to estimate uncertainty in the units of topological structures, e.g., small pieces of connections and branches. To achieve this, we leverage tools from topological data analysis, specifically discrete Morse theory (DMT), to first capture the structures, and then reason about their uncertainties. To model the uncertainty, we (1) propose a joint prediction model that estimates the uncertainty of a structure while taking the neighboring structures into consideration (inter-structural uncertainty); (2) propose a novel Probabilistic DMT to model the inherent uncertainty within each structure (intra-structural uncertainty) by sampling its representations via a perturb-and-walk scheme. On various 2D and 3D datasets, our method produces better structure-wise uncertainty maps compared to existing works.