 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Role of Locality and Weight Sharing in Image-Based Tasks: A Sample Complexity Separation between CNNs, LCNs, and FCNs
Mar 23, 2024
Vision tasks are characterized by the properties of locality and translation invariance. The superior performance of convolutional neural networks (CNNs) on these tasks is widely attributed to the inductive bias of locality and weight sharing baked into their architecture. Existing attempts to quantify the statistical benefits of these biases in CNNs over locally connected convolutional neural networks (LCNs) and fully connected neural networks (FCNs) fall into one of the following categories: either they disregard the optimizer and only provide uniform convergence upper bounds with no separating lower bounds, or they consider simplistic tasks that do not truly mirror the locality and translation invariance as found in real-world vision tasks. To address these deficiencies, we introduce the Dynamic Signal Distribution (DSD) classification task that models an image as consisting of $k$ patches, each of dimension $d$, and the label is determined by a $d$-sparse signal vector that can freely appear in any one of the $k$ patches. On this task, for any orthogonally equivariant algorithm like gradient descent, we prove that CNNs require $\tilde{O}(k+d)$ samples, whereas LCNs require $\Omega(kd)$ samples, establishing the statistical advantages of weight sharing in translation invariant tasks. Furthermore, LCNs need $\tilde{O}(k(k+d))$ samples, compared to $\Omega(k^2d)$ samples for FCNs, showcasing the benefits of locality in local tasks. Additionally, we develop information theoretic tools for analyzing randomized algorithms, which may be of interest for statistical research.
Enhancing Fingerprint Image Synthesis with GANs, Diffusion Models, and Style Transfer Techniques
Mar 20, 2024

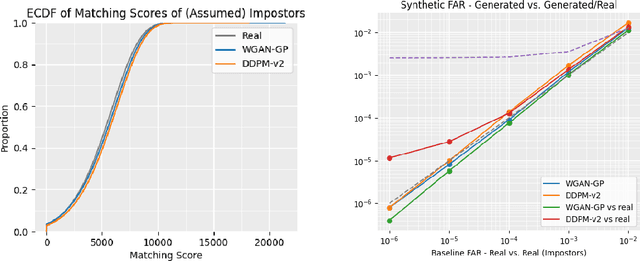
We present novel approaches involving generative adversarial networks and diffusion models in order to synthesize high quality, live and spoof fingerprint images while preserving features such as uniqueness and diversity. We generate live fingerprints from noise with a variety of methods, and we use image translation techniques to translate live fingerprint images to spoof. To generate different types of spoof images based on limited training data we incorporate style transfer techniques through a cycle autoencoder equipped with a Wasserstein metric along with Gradient Penalty (CycleWGAN-GP) in order to avoid mode collapse and instability. We find that when the spoof training data includes distinct spoof characteristics, it leads to improved live-to-spoof translation. We assess the diversity and realism of the generated live fingerprint images mainly through the Fr\'echet Inception Distance (FID) and the False Acceptance Rate (FAR). Our best diffusion model achieved a FID of 15.78. The comparable WGAN-GP model achieved slightly higher FID while performing better in the uniqueness assessment due to a slightly lower FAR when matched against the training data, indicating better creativity. Moreover, we give example images showing that a DDPM model clearly can generate realistic fingerprint images.
A Comprehensive Study of Multimodal Large Language Models for Image Quality Assessment
Mar 16, 2024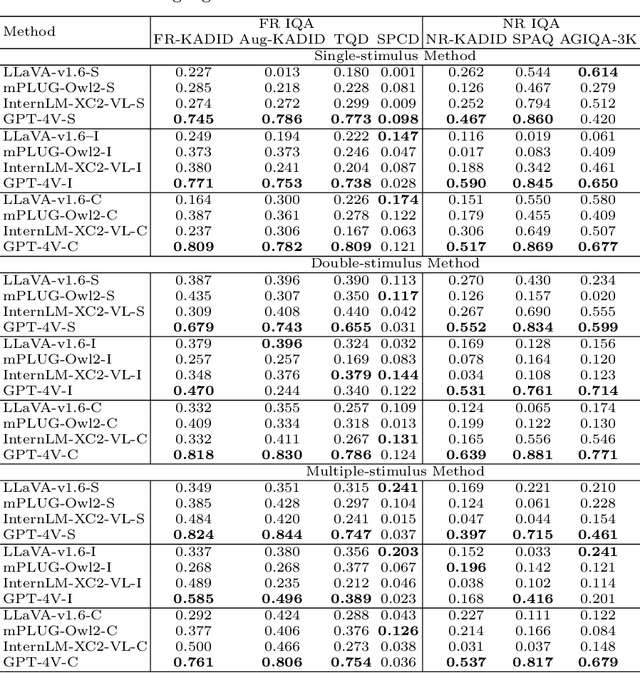
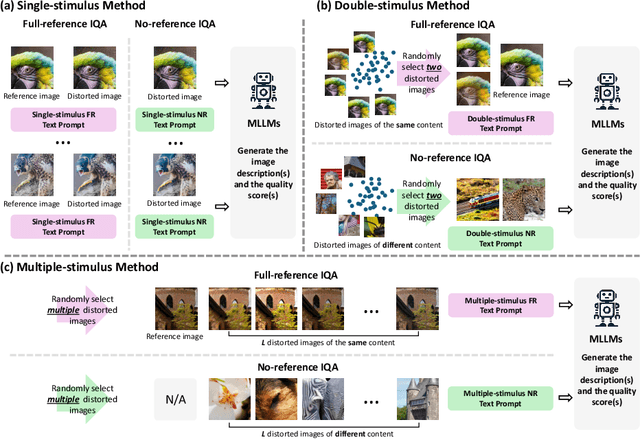
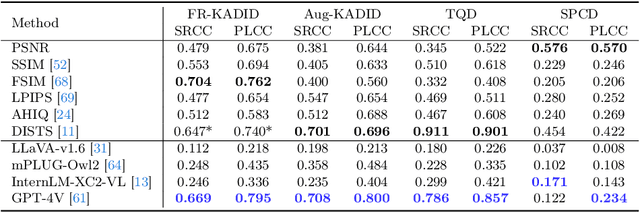

While Multimodal Large Language Models (MLLMs) have experienced significant advancement on visual understanding and reasoning, their potentials to serve as powerful, flexible, interpretable, and text-driven models for Image Quality Assessment (IQA) remains largely unexplored. In this paper, we conduct a comprehensive and systematic study of prompting MLLMs for IQA. Specifically, we first investigate nine prompting systems for MLLMs as the combinations of three standardized testing procedures in psychophysics (i.e., the single-stimulus, double-stimulus, and multiple-stimulus methods) and three popular prompting strategies in natural language processing (i.e., the standard, in-context, and chain-of-thought prompting). We then present a difficult sample selection procedure, taking into account sample diversity and uncertainty, to further challenge MLLMs equipped with the respective optimal prompting systems. We assess three open-source and one close-source MLLMs on several visual attributes of image quality (e.g., structural and textural distortions, color differences, and geometric transformations) in both full-reference and no-reference scenarios. Experimental results show that only the close-source GPT-4V provides a reasonable account for human perception of image quality, but is weak at discriminating fine-grained quality variations (e.g., color differences) and at comparing visual quality of multiple images, tasks humans can perform effortlessly.
Computation and Communication Efficient Lightweighting Vertical Federated Learning
Mar 30, 2024The exploration of computational and communication efficiency within Federated Learning (FL) has emerged as a prominent and crucial field of study. While most existing efforts to enhance these efficiencies have focused on Horizontal FL, the distinct processes and model structures of Vertical FL preclude the direct application of Horizontal FL-based techniques. In response, we introduce the concept of Lightweight Vertical Federated Learning (LVFL), targeting both computational and communication efficiencies. This approach involves separate lightweighting strategies for the feature model, to improve computational efficiency, and for feature embedding, to enhance communication efficiency. Moreover, we establish a convergence bound for our LVFL algorithm, which accounts for both communication and computational lightweighting ratios. Our evaluation of the algorithm on a image classification dataset reveals that LVFL significantly alleviates computational and communication demands while preserving robust learning performance. This work effectively addresses the gaps in communication and computational efficiency within Vertical FL.
Learning truly monotone operators with applications to nonlinear inverse problems
Mar 30, 2024This article introduces a novel approach to learning monotone neural networks through a newly defined penalization loss. The proposed method is particularly effective in solving classes of variational problems, specifically monotone inclusion problems, commonly encountered in image processing tasks. The Forward-Backward-Forward (FBF) algorithm is employed to address these problems, offering a solution even when the Lipschitz constant of the neural network is unknown. Notably, the FBF algorithm provides convergence guarantees under the condition that the learned operator is monotone. Building on plug-and-play methodologies, our objective is to apply these newly learned operators to solving non-linear inverse problems. To achieve this, we initially formulate the problem as a variational inclusion problem. Subsequently, we train a monotone neural network to approximate an operator that may not inherently be monotone. Leveraging the FBF algorithm, we then show simulation examples where the non-linear inverse problem is successfully solved.
Learned Scanpaths Aid Blind Panoramic Video Quality Assessment
Mar 30, 2024Panoramic videos have the advantage of providing an immersive and interactive viewing experience. Nevertheless, their spherical nature gives rise to various and uncertain user viewing behaviors, which poses significant challenges for panoramic video quality assessment (PVQA). In this work, we propose an end-to-end optimized, blind PVQA method with explicit modeling of user viewing patterns through visual scanpaths. Our method consists of two modules: a scanpath generator and a quality assessor. The scanpath generator is initially trained to predict future scanpaths by minimizing their expected code length and then jointly optimized with the quality assessor for quality prediction. Our blind PVQA method enables direct quality assessment of panoramic images by treating them as videos composed of identical frames. Experiments on three public panoramic image and video quality datasets, encompassing both synthetic and authentic distortions, validate the superiority of our blind PVQA model over existing methods.
CP HDR: A feature point detection and description library for LDR and HDR images
Mar 29, 2024


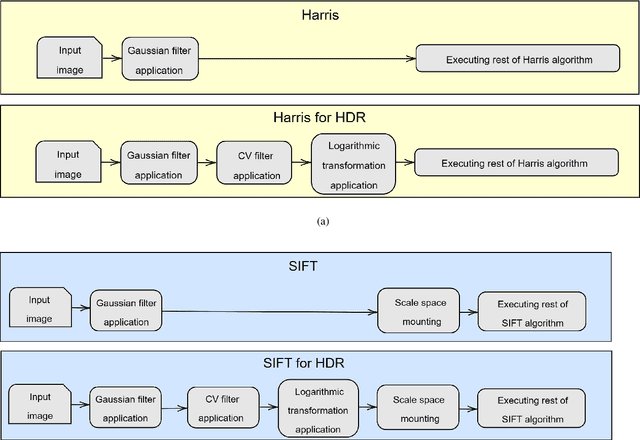
In computer vision, characteristics refer to image regions with unique properties, such as corners, edges, textures, or areas with high contrast. These regions can be represented through feature points (FPs). FP detection and description are fundamental steps to many computer vision tasks. Most FP detection and description methods use low dynamic range (LDR) images, sufficient for most applications involving digital images. However, LDR images may have saturated pixels in scenes with extreme light conditions, which degrade FP detection. On the other hand, high dynamic range (HDR) images usually present a greater dynamic range but FP detection algorithms do not take advantage of all the information in such images. In this study, we present a systematic review of image detection and description algorithms that use HDR images as input. We developed a library called CP_HDR that implements the Harris corner detector, SIFT detector and descriptor, and two modifications of those algorithms specialized in HDR images, called SIFT for HDR (SfHDR) and Harris for HDR (HfHDR). Previous studies investigated the use of HDR images in FP detection, but we did not find studies investigating the use of HDR images in FP description. Using uniformity, repeatability rate, mean average precision, and matching rate metrics, we compared the performance of the CP_HDR algorithms using LDR and HDR images. We observed an increase in the uniformity of the distribution of FPs among the high-light, mid-light, and low-light areas of the images. The results show that using HDR images as input to detection algorithms improves performance and that SfHDR and HfHDR enhance FP description.
Artifact Reduction in 3D and 4D Cone-beam Computed Tomography Images with Deep Learning -- A Review
Mar 27, 2024Deep learning based approaches have been used to improve image quality in cone-beam computed tomography (CBCT), a medical imaging technique often used in applications such as image-guided radiation therapy, implant dentistry or orthopaedics. In particular, while deep learning methods have been applied to reduce various types of CBCT image artifacts arising from motion, metal objects, or low-dose acquisition, a comprehensive review summarizing the successes and shortcomings of these approaches, with a primary focus on the type of artifacts rather than the architecture of neural networks, is lacking in the literature. In this review, the data generation and simulation pipelines, and artifact reduction techniques are specifically investigated for each type of artifact. We provide an overview of deep learning techniques that have successfully been shown to reduce artifacts in 3D, as well as in time-resolved (4D) CBCT through the use of projection- and/or volume-domain optimizations, or by introducing neural networks directly within the CBCT reconstruction algorithms. Research gaps are identified to suggest avenues for future exploration. One of the key findings of this work is an observed trend towards the use of generative models including GANs and score-based or diffusion models, accompanied with the need for more diverse and open training datasets and simulations.
* 16 pages, 4 figures, 1 Table, published in IEEE Access Journal
Deep Learning Segmentation and Classification of Red Blood Cells Using a Large Multi-Scanner Dataset
Mar 27, 2024Digital pathology has recently been revolutionized by advancements in artificial intelligence, deep learning, and high-performance computing. With its advanced tools, digital pathology can help improve and speed up the diagnostic process, reduce human errors, and streamline the reporting step. In this paper, we report a new large red blood cell (RBC) image dataset and propose a two-stage deep learning framework for RBC image segmentation and classification. The dataset is a highly diverse dataset of more than 100K RBCs containing eight different classes. The dataset, which is considerably larger than any publicly available hematopathology dataset, was labeled independently by two hematopathologists who also manually created masks for RBC cell segmentation. Subsequently, in the proposed framework, first, a U-Net model was trained to achieve automatic RBC image segmentation. Second, an EfficientNetB0 model was trained to classify RBC images into one of the eight classes using a transfer learning approach with a 5X2 cross-validation scheme. An IoU of 98.03% and an average classification accuracy of 96.5% were attained on the test set. Moreover, we have performed experimental comparisons against several prominent CNN models. These comparisons show the superiority of the proposed model with a good balance between performance and computational cost.
Improving Image Classification Accuracy through Complementary Intra-Class and Inter-Class Mixup
Mar 21, 2024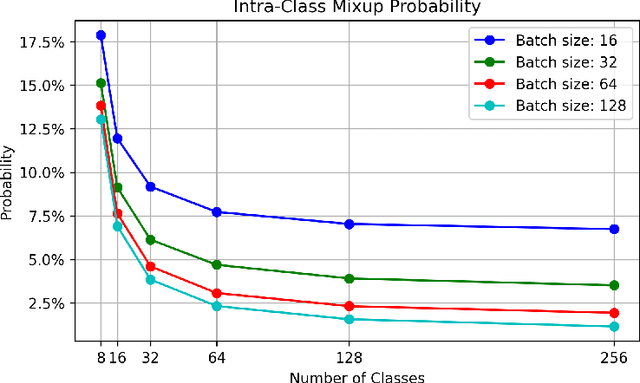

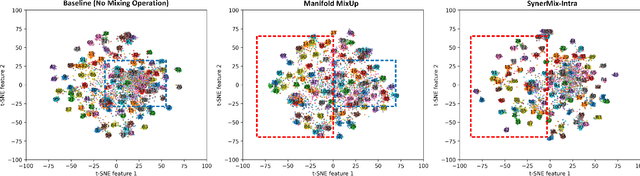
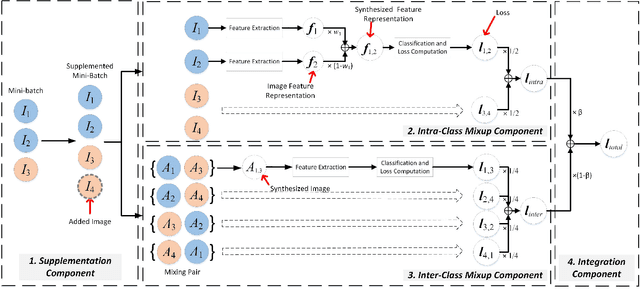
MixUp and its variants, such as Manifold MixUp, have two key limitations in image classification tasks. First, they often neglect mixing within the same class (intra-class mixup), leading to an underutilization of the relationships among samples within the same class. Second, although these methods effectively enhance inter-class separability by mixing between different classes (inter-class mixup), they fall short in improving intra-class cohesion through their mixing operations, limiting their classification performance. To tackle these issues, we propose a novel mixup method and a comprehensive integrated solution.Our mixup approach specifically targets intra-class mixup, an aspect commonly overlooked, to strengthen intra-class cohesion-a feature not provided by current mixup techniques.For each mini-batch, our method utilizes feature representations of unaugmented original images from each class within the mini-batch to generate a single synthesized feature representation through random linear interpolation. All synthesized representations for this mini-batch are then fed into the classification and loss layers to calculate an average classification loss that can markedly enhance intra-class cohesion. Moreover, our integrated solution seamlessly combines our intra-class mixup method with an existing mixup approach such as MixUp or Manifold MixUp. This comprehensive solution incorporates inter- and intra-class mixup in a balanced manner while concurrently improving intra-class cohesion and inter-class separability. Experimental results on six public datasets demonstrate that our integrated solution achieves a 0.1% to 3.43% higher accuracy than the best of either MixUp or our intra-class mixup method, averaging a 1.16% gain. It also outperforms the better performer of either Manifold MixUp or our intra-class mixup method by 0.12% to 5.16%, with an average gain of 1.11%.