 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised Image Denoising with Score Function
Apr 17, 2023
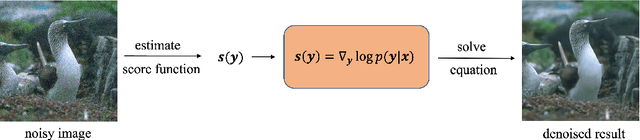

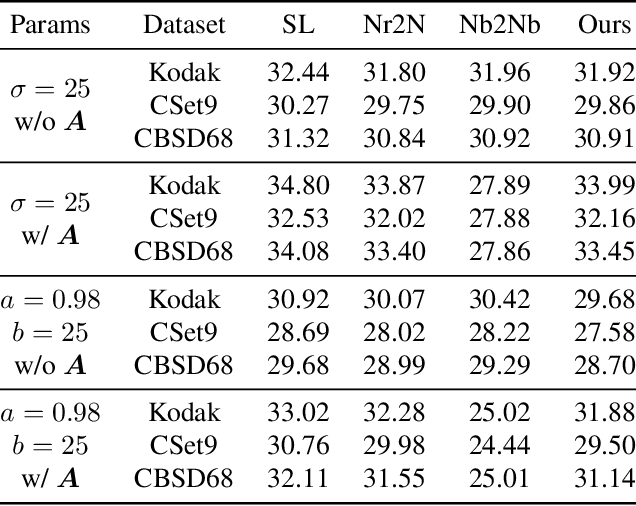
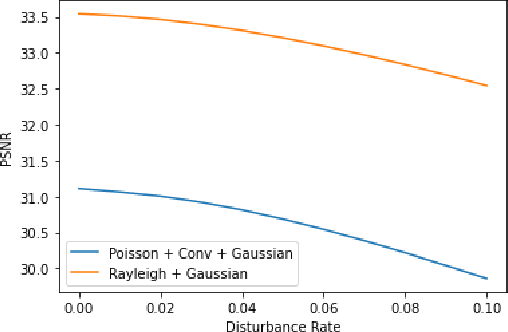
Though achieving excellent performance in some cases, current unsupervised learning methods for single image denoising usually have constraints in applications. In this paper, we propose a new approach which is more general and applicable to complicated noise models. Utilizing the property of score function, the gradient of logarithmic probability, we define a solving system for denoising. Once the score function of noisy images has been estimated, the denoised result can be obtained through the solving system. Our approach can be applied to multiple noise models, such as the mixture of multiplicative and additive noise combined with structured correlation. Experimental results show that our method is comparable when the noise model is simple, and has good performance in complicated cases where other methods are not applicable or perform poorly.
Expressive Text-to-Image Generation with Rich Text
Apr 13, 2023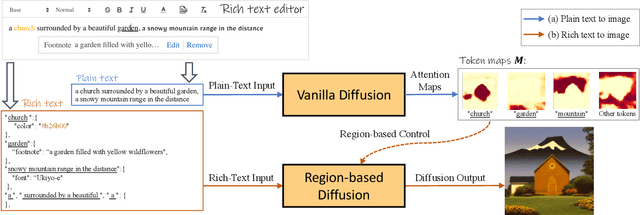


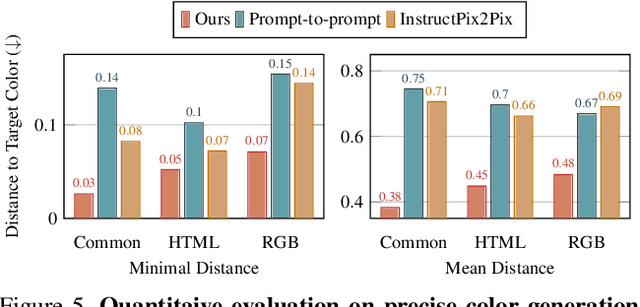
Plain text has become a prevalent interface for text-to-image synthesis. However, its limited customization options hinder users from accurately describing desired outputs. For example, plain text makes it hard to specify continuous quantities, such as the precise RGB color value or importance of each word. Furthermore, creating detailed text prompts for complex scenes is tedious for humans to write and challenging for text encoders to interpret. To address these challenges, we propose using a rich-text editor supporting formats such as font style, size, color, and footnote. We extract each word's attributes from rich text to enable local style control, explicit token reweighting, precise color rendering, and detailed region synthesis. We achieve these capabilities through a region-based diffusion process. We first obtain each word's region based on cross-attention maps of a vanilla diffusion process using plain text. For each region, we enforce its text attributes by creating region-specific detailed prompts and applying region-specific guidance. We present various examples of image generation from rich text and demonstrate that our method outperforms strong baselines with quantitative evaluations.
AutoDecoding Latent 3D Diffusion Models
Jul 07, 2023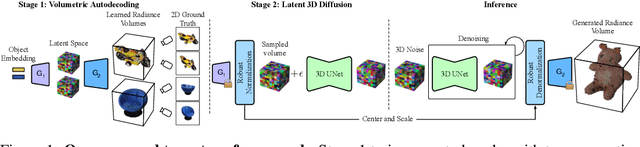
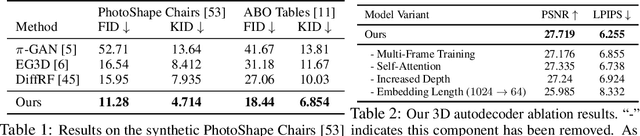

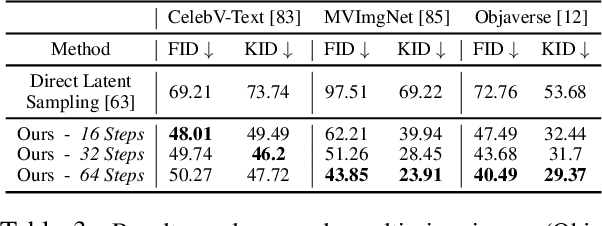
We present a novel approach to the generation of static and articulated 3D assets that has a 3D autodecoder at its core. The 3D autodecoder framework embeds properties learned from the target dataset in the latent space, which can then be decoded into a volumetric representation for rendering view-consistent appearance and geometry. We then identify the appropriate intermediate volumetric latent space, and introduce robust normalization and de-normalization operations to learn a 3D diffusion from 2D images or monocular videos of rigid or articulated objects. Our approach is flexible enough to use either existing camera supervision or no camera information at all -- instead efficiently learning it during training. Our evaluations demonstrate that our generation results outperform state-of-the-art alternatives on various benchmark datasets and metrics, including multi-view image datasets of synthetic objects, real in-the-wild videos of moving people, and a large-scale, real video dataset of static objects.
Improving the Efficiency of Human-in-the-Loop Systems: Adding Artificial to Human Experts
Jul 07, 2023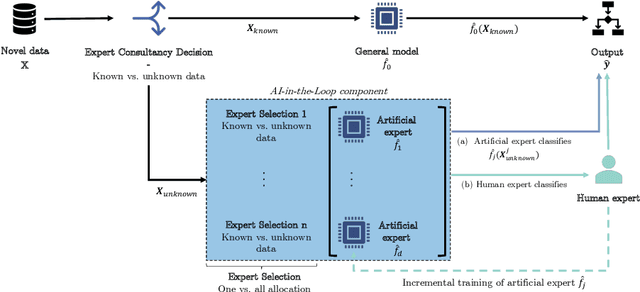
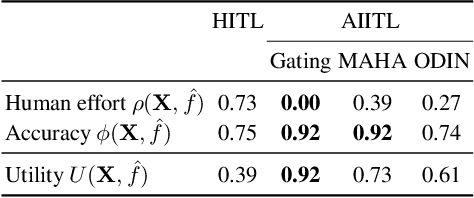
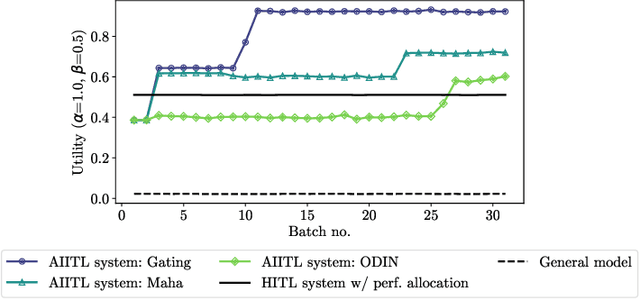
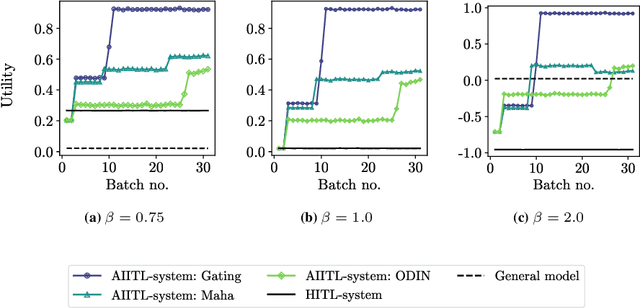
Information systems increasingly leverage artificial intelligence (AI) and machine learning (ML) to generate value from vast amounts of data. However, ML models are imperfect and can generate incorrect classifications. Hence, human-in-the-loop (HITL) extensions to ML models add a human review for instances that are difficult to classify. This study argues that continuously relying on human experts to handle difficult model classifications leads to a strong increase in human effort, which strains limited resources. To address this issue, we propose a hybrid system that creates artificial experts that learn to classify data instances from unknown classes previously reviewed by human experts. Our hybrid system assesses which artificial expert is suitable for classifying an instance from an unknown class and automatically assigns it. Over time, this reduces human effort and increases the efficiency of the system. Our experiments demonstrate that our approach outperforms traditional HITL systems for several benchmarks on image classification.
Yes, we CANN: Constrained Approximate Nearest Neighbors for local feature-based visual localization
Jun 15, 2023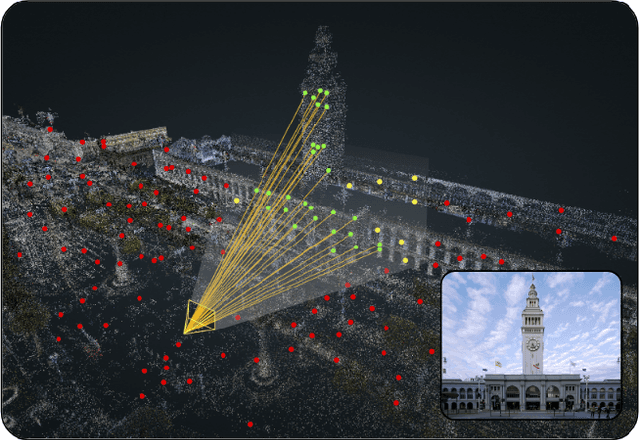
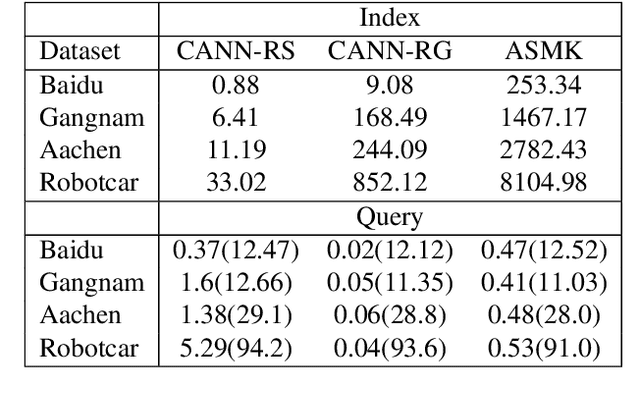
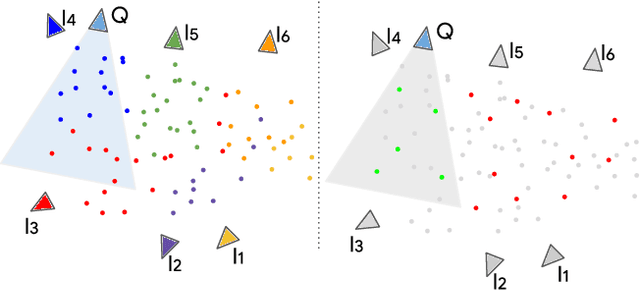
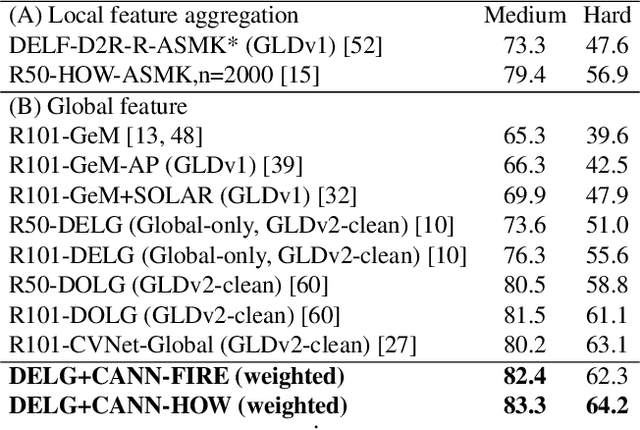
Large-scale visual localization systems continue to rely on 3D point clouds built from image collections using structure-from-motion. While the 3D points in these models are represented using local image features, directly matching a query image's local features against the point cloud is challenging due to the scale of the nearest-neighbor search problem. Many recent approaches to visual localization have thus proposed a hybrid method, where first a global (per image) embedding is used to retrieve a small subset of database images, and local features of the query are matched only against those. It seems to have become common belief that global embeddings are critical for said image-retrieval in visual localization, despite the significant downside of having to compute two feature types for each query image. In this paper, we take a step back from this assumption and propose Constrained Approximate Nearest Neighbors (CANN), a joint solution of k-nearest-neighbors across both the geometry and appearance space using only local features. We first derive the theoretical foundation for k-nearest-neighbor retrieval across multiple metrics and then showcase how CANN improves visual localization. Our experiments on public localization benchmarks demonstrate that our method significantly outperforms both state-of-the-art global feature-based retrieval and approaches using local feature aggregation schemes. Moreover, it is an order of magnitude faster in both index and query time than feature aggregation schemes for these datasets. Code will be released.
How to Efficiently Adapt Large Segmentation Model(SAM) to Medical Images
Jun 23, 2023
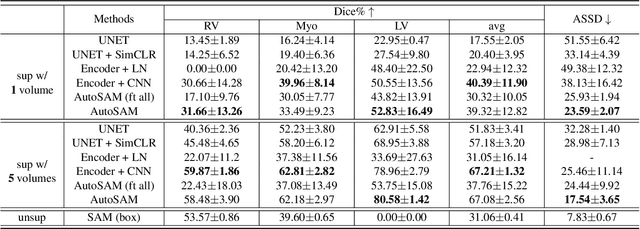
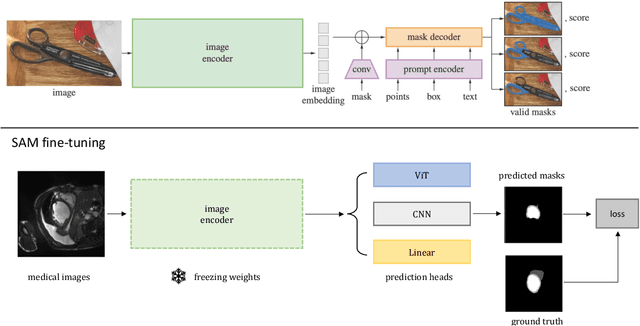

The emerging scale segmentation model, Segment Anything (SAM), exhibits impressive capabilities in zero-shot segmentation for natural images. However, when applied to medical images, SAM suffers from noticeable performance drop. To make SAM a real ``foundation model" for the computer vision community, it is critical to find an efficient way to customize SAM for medical image dataset. In this work, we propose to freeze SAM encoder and finetune a lightweight task-specific prediction head, as most of weights in SAM are contributed by the encoder. In addition, SAM is a promptable model, while prompt is not necessarily available in all application cases, and precise prompts for multiple class segmentation are also time-consuming. Therefore, we explore three types of prompt-free prediction heads in this work, include ViT, CNN, and linear layers. For ViT head, we remove the prompt tokens in the mask decoder of SAM, which is named AutoSAM. AutoSAM can also generate masks for different classes with one single inference after modification. To evaluate the label-efficiency of our finetuning method, we compare the results of these three prediction heads on a public medical image segmentation dataset with limited labeled data. Experiments demonstrate that finetuning SAM significantly improves its performance on medical image dataset, even with just one labeled volume. Moreover, AutoSAM and CNN prediction head also has better segmentation accuracy than training from scratch and self-supervised learning approaches when there is a shortage of annotations.
SAM.MD: Zero-shot medical image segmentation capabilities of the Segment Anything Model
Apr 10, 2023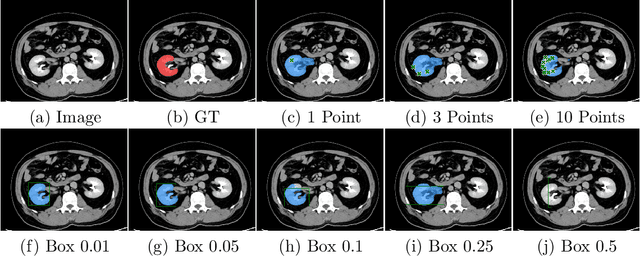
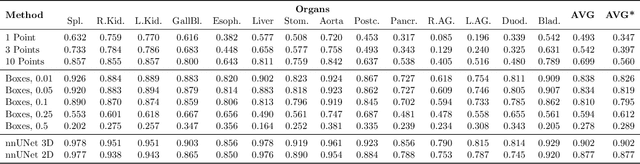
Foundation models have taken over natural language processing and image generation domains due to the flexibility of prompting. With the recent introduction of the Segment Anything Model (SAM), this prompt-driven paradigm has entered image segmentation with a hitherto unexplored abundance of capabilities. The purpose of this paper is to conduct an initial evaluation of the out-of-the-box zero-shot capabilities of SAM for medical image segmentation, by evaluating its performance on an abdominal CT organ segmentation task, via point or bounding box based prompting. We show that SAM generalizes well to CT data, making it a potential catalyst for the advancement of semi-automatic segmentation tools for clinicians. We believe that this foundation model, while not reaching state-of-the-art segmentation performance in our investigations, can serve as a highly potent starting point for further adaptations of such models to the intricacies of the medical domain. Keywords: medical image segmentation, SAM, foundation models, zero-shot learning
Uncurated Image-Text Datasets: Shedding Light on Demographic Bias
Apr 06, 2023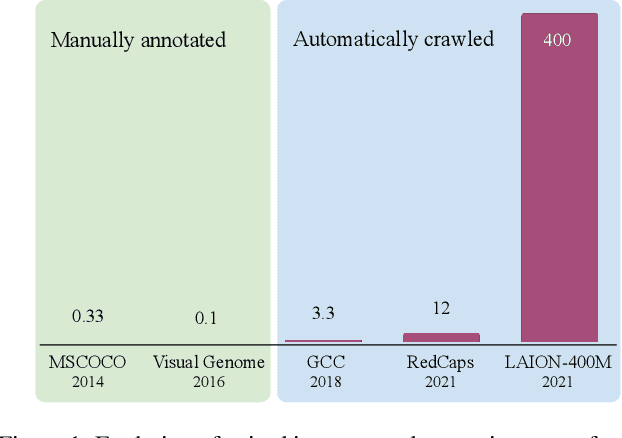
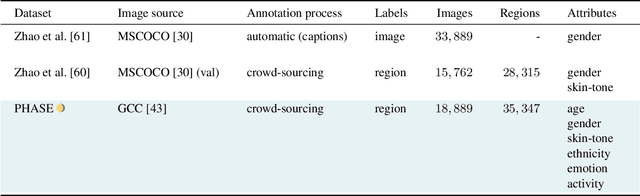
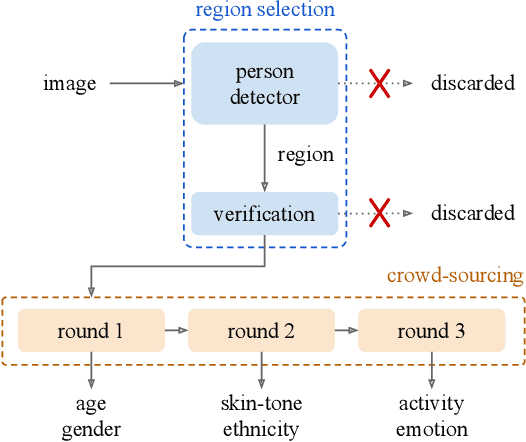
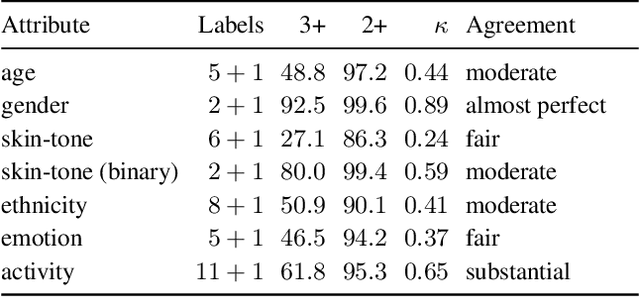
The increasing tendency to collect large and uncurated datasets to train vision-and-language models has raised concerns about fair representations. It is known that even small but manually annotated datasets, such as MSCOCO, are affected by societal bias. This problem, far from being solved, may be getting worse with data crawled from the Internet without much control. In addition, the lack of tools to analyze societal bias in big collections of images makes addressing the problem extremely challenging. Our first contribution is to annotate part of the Google Conceptual Captions dataset, widely used for training vision-and-language models, with four demographic and two contextual attributes. Our second contribution is to conduct a comprehensive analysis of the annotations, focusing on how different demographic groups are represented. Our last contribution lies in evaluating three prevailing vision-and-language tasks: image captioning, text-image CLIP embeddings, and text-to-image generation, showing that societal bias is a persistent problem in all of them.
ICSVR: Investigating Compositional and Semantic Understanding in Video Retrieval Models
Jun 28, 2023
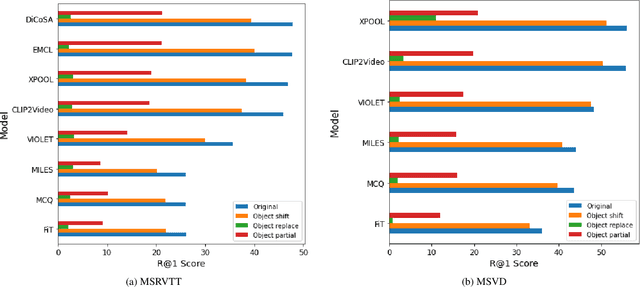
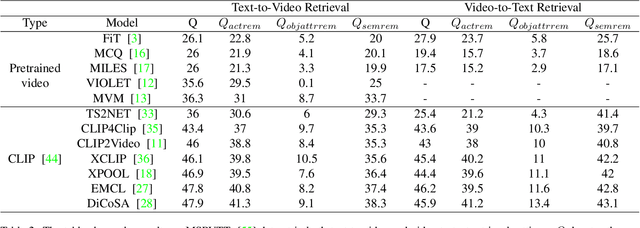
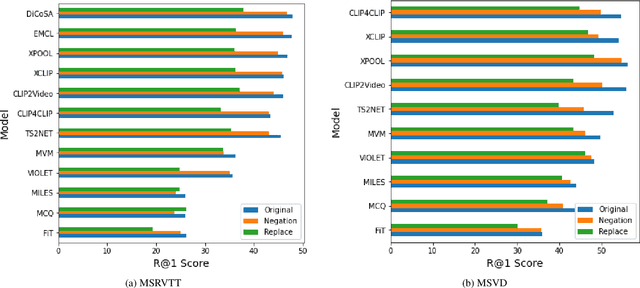
Video retrieval (VR) involves retrieving the ground truth video from the video database given a text caption or vice-versa. The two important components of compositionality: objects \& attributes and actions are joined using correct semantics to form a proper text query. These components (objects \& attributes, actions and semantics) each play an important role to help distinguish among videos and retrieve the correct ground truth video. However, it is unclear what is the effect of these components on the video retrieval performance. We therefore, conduct a systematic study to evaluate the compositional and semantic understanding of video retrieval models on standard benchmarks such as MSRVTT, MSVD and DIDEMO. The study is performed on two categories of video retrieval models: (i) which are pre-trained on video-text pairs and fine-tuned on downstream video retrieval datasets (Eg. Frozen-in-Time, Violet, MCQ etc.) (ii) which adapt pre-trained image-text representations like CLIP for video retrieval (Eg. CLIP4Clip, XCLIP, CLIP2Video etc.). Our experiments reveal that actions and semantics play a minor role compared to objects \& attributes in video understanding. Moreover, video retrieval models that use pre-trained image-text representations (CLIP) have better semantic and compositional understanding as compared to models pre-trained on video-text data.
Effective Transfer of Pretrained Large Visual Model for Fabric Defect Segmentation via Specifc Knowledge Injection
Jun 28, 2023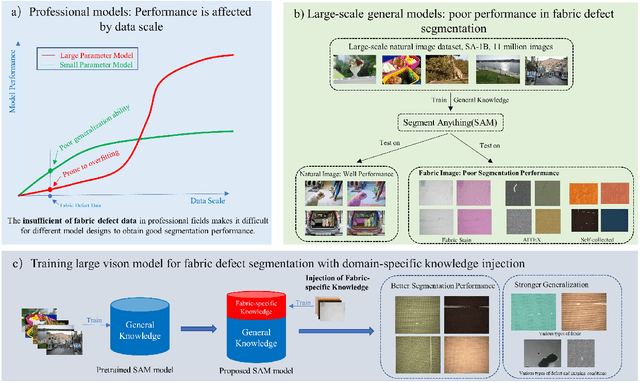
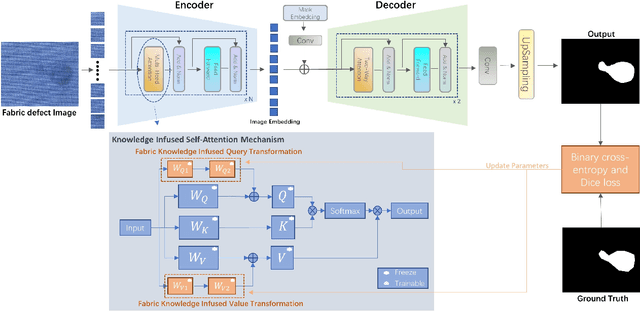


Fabric defect segmentation is integral to textile quality control. Despite this, the scarcity of high-quality annotated data and the diversity of fabric defects present significant challenges to the application of deep learning in this field. These factors limit the generalization and segmentation performance of existing models, impeding their ability to handle the complexity of diverse fabric types and defects. To overcome these obstacles, this study introduces an innovative method to infuse specialized knowledge of fabric defects into the Segment Anything Model (SAM), a large-scale visual model. By introducing and training a unique set of fabric defect-related parameters, this approach seamlessly integrates domain-specific knowledge into SAM without the need for extensive modifications to the pre-existing model parameters. The revamped SAM model leverages generalized image understanding learned from large-scale natural image datasets while incorporating fabric defect-specific knowledge, ensuring its proficiency in fabric defect segmentation tasks. The experimental results reveal a significant improvement in the model's segmentation performance, attributable to this novel amalgamation of generic and fabric-specific knowledge. When benchmarking against popular existing segmentation models across three datasets, our proposed model demonstrates a substantial leap in performance. Its impressive results in cross-dataset comparisons and few-shot learning experiments further demonstrate its potential for practical applications in textile quality control.