 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SUD$^2$: Supervision by Denoising Diffusion Models for Image Reconstruction
Apr 03, 2023
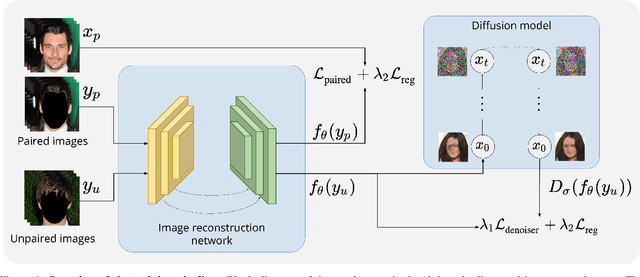


Many imaging inverse problems$\unicode{x2014}$such as image-dependent in-painting and dehazing$\unicode{x2014}$are challenging because their forward models are unknown or depend on unknown latent parameters. While one can solve such problems by training a neural network with vast quantities of paired training data, such paired training data is often unavailable. In this paper, we propose a generalized framework for training image reconstruction networks when paired training data is scarce. In particular, we demonstrate the ability of image denoising algorithms and, by extension, denoising diffusion models to supervise network training in the absence of paired training data.
Lightweight Improved Residual Network for Efficient Inverse Tone Mapping
Jul 08, 2023
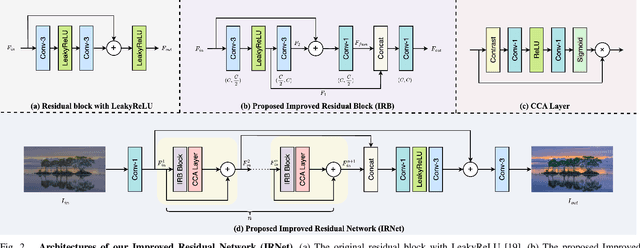
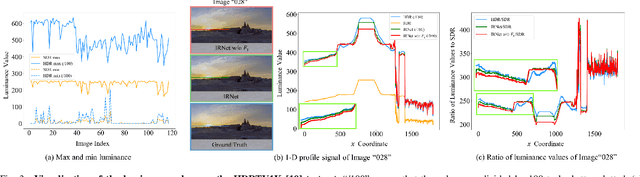

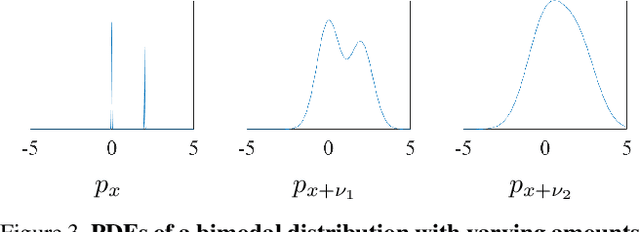
The display devices like HDR10 televisions are increasingly prevalent in our daily life for visualizing high dynamic range (HDR) images. But the majority of media images on the internet remain in 8-bit standard dynamic range (SDR) format. Therefore, converting SDR images to HDR ones by inverse tone mapping (ITM) is crucial to unlock the full potential of abundant media images. However, existing ITM methods are usually developed with complex network architectures requiring huge computational costs. In this paper, we propose a lightweight Improved Residual Network (IRNet) by enhancing the power of popular residual block for efficient ITM. Specifically, we propose a new Improved Residual Block (IRB) to extract and fuse multi-layer features for fine-grained HDR image reconstruction. Experiments on three benchmark datasets demonstrate that our IRNet achieves state-of-the-art performance on both the ITM and joint SR-ITM tasks. The code, models and data will be publicly available at https://github.com/ThisisVikki/ITM-baseline.
CLIDiM: Contrastive Learning for Image Denoising in Microscopy
Mar 27, 2023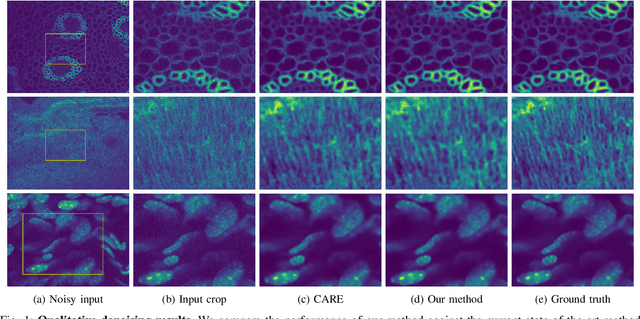



Microscopy images often suffer from high levels of noise, which can hinder further analysis and interpretation. Content-aware image restoration (CARE) methods have been proposed to address this issue, but they often require large amounts of training data and suffer from over-fitting. To overcome these challenges, we propose a novel framework for few-shot microscopy image denoising. Our approach combines a generative adversarial network (GAN) trained via contrastive learning (CL) with two structure preserving loss terms (Structural Similarity Index and Total Variation loss) to further improve the quality of the denoised images using little data. We demonstrate the effectiveness of our method on three well-known microscopy imaging datasets, and show that we can drastically reduce the amount of training data while retaining the quality of the denoising, thus alleviating the burden of acquiring paired data and enabling few-shot learning. The proposed framework can be easily extended to other image restoration tasks and has the potential to significantly advance the field of microscopy image analysis.
Sigmoid Loss for Language Image Pre-Training
Mar 30, 2023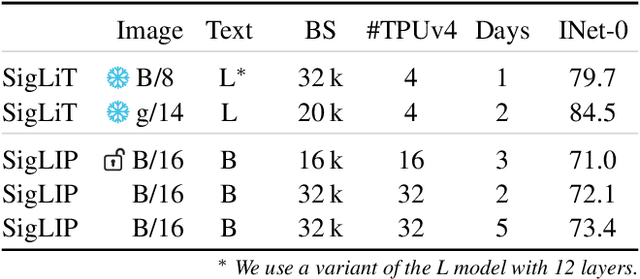
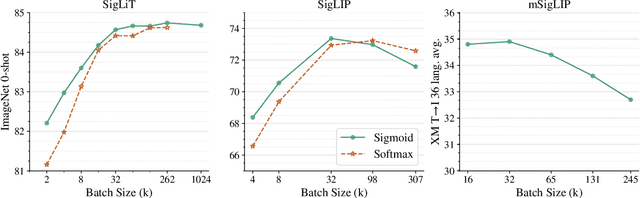
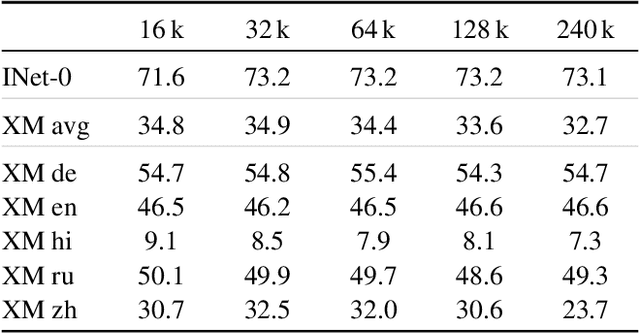
We propose a simple pairwise sigmoid loss for image-text pre-training. Unlike standard contrastive learning with softmax normalization, the sigmoid loss operates solely on image-text pairs and does not require a global view of the pairwise similarities for normalization. The sigmoid loss simultaneously allows further scaling up the batch size, while also performing better at smaller batch sizes. With only four TPUv4 chips, we can train a Base CLIP model at 4k batch size and a Large LiT model at 20k batch size, the latter achieves 84.5% ImageNet zero-shot accuracy in two days. This disentanglement of the batch size from the loss further allows us to study the impact of examples vs pairs and negative to positive ratio. Finally, we push the batch size to the extreme, up to one million, and find that the benefits of growing batch size quickly diminish, with a more reasonable batch size of 32k being sufficient. We hope our research motivates further explorations in improving the quality and efficiency of language-image pre-training.
Learning Content-enhanced Mask Transformer for Domain Generalized Urban-Scene Segmentation
Jul 01, 2023
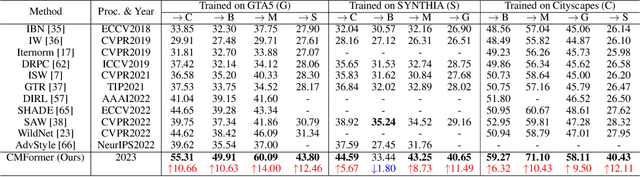
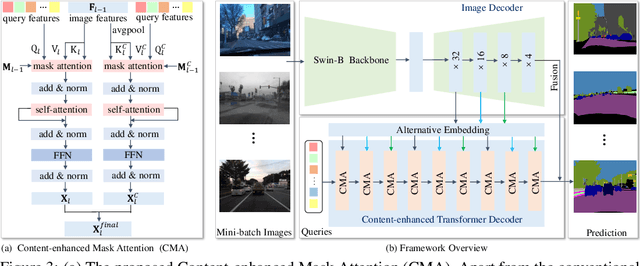

Domain-generalized urban-scene semantic segmentation (USSS) aims to learn generalized semantic predictions across diverse urban-scene styles. Unlike domain gap challenges, USSS is unique in that the semantic categories are often similar in different urban scenes, while the styles can vary significantly due to changes in urban landscapes, weather conditions, lighting, and other factors. Existing approaches typically rely on convolutional neural networks (CNNs) to learn the content of urban scenes. In this paper, we propose a Content-enhanced Mask TransFormer (CMFormer) for domain-generalized USSS. The main idea is to enhance the focus of the fundamental component, the mask attention mechanism, in Transformer segmentation models on content information. To achieve this, we introduce a novel content-enhanced mask attention mechanism. It learns mask queries from both the image feature and its down-sampled counterpart, as lower-resolution image features usually contain more robust content information and are less sensitive to style variations. These features are fused into a Transformer decoder and integrated into a multi-resolution content-enhanced mask attention learning scheme. Extensive experiments conducted on various domain-generalized urban-scene segmentation datasets demonstrate that the proposed CMFormer significantly outperforms existing CNN-based methods for domain-generalized semantic segmentation, achieving improvements of up to 14.00\% in terms of mIoU (mean intersection over union). The source code for CMFormer will be made available at this \href{https://github.com/BiQiWHU/domain-generalized-urban-scene-segmentation}{repository}.
High-Dimensional MR Reconstruction Integrating Subspace and Adaptive Generative Models
Jun 16, 2023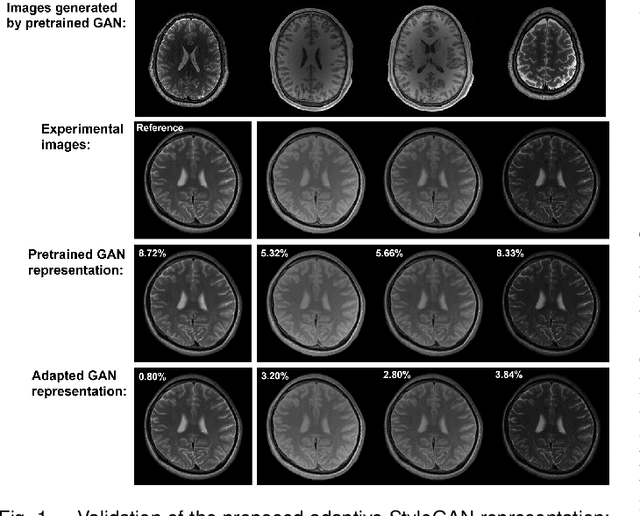
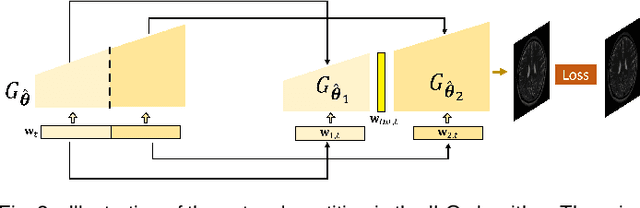
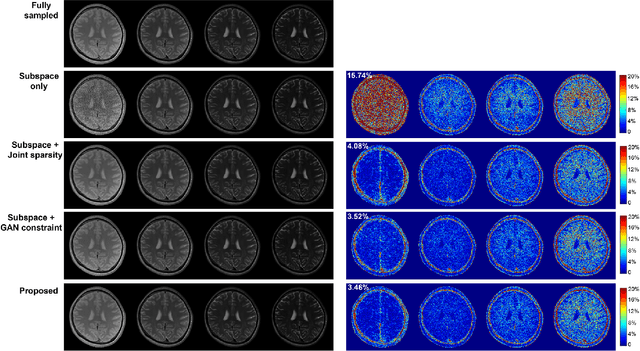
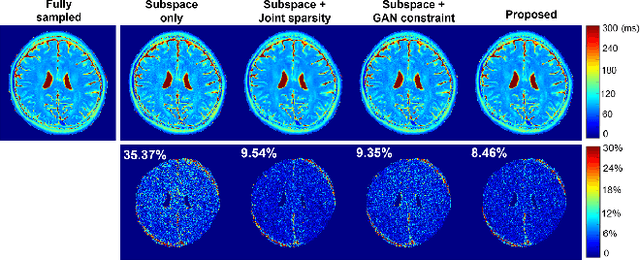
We present a novel method that integrates subspace modeling with an adaptive generative image prior for high-dimensional MR image reconstruction. The subspace model imposes an explicit low-dimensional representation of the high-dimensional images, while the generative image prior serves as a spatial constraint on the "contrast-weighted" images or the spatial coefficients of the subspace model. A formulation was introduced to synergize these two components with complimentary regularization such as joint sparsity. A special pretraining plus subject-specific network adaptation strategy was proposed to construct an accurate generative-model-based representation for images with varying contrasts, validated by experimental data. An iterative algorithm was introduced to jointly update the subspace coefficients and the multiresolution latent space of the generative image model that leveraged a recently developed intermediate layer optimization technique for network inversion. We evaluated the utility of the proposed method in two high-dimensional imaging applications: accelerated MR parameter mapping and high-resolution MRSI. Improved performance over state-of-the-art subspace-based methods was demonstrated in both cases. Our work demonstrated the potential of integrating data-driven and adaptive generative models with low-dimensional representation for high-dimensional imaging problems.
Scaling Open-Vocabulary Object Detection
Jun 16, 2023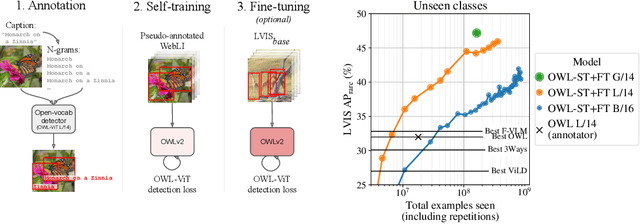
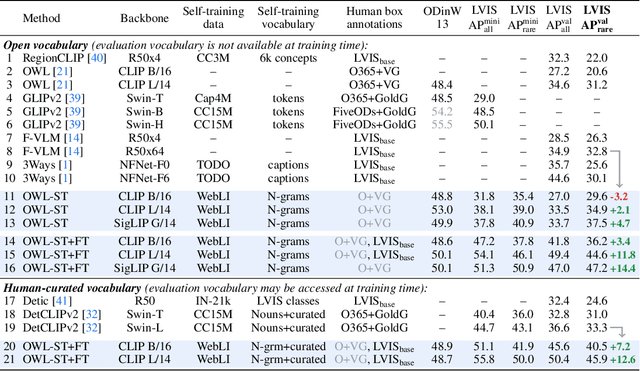
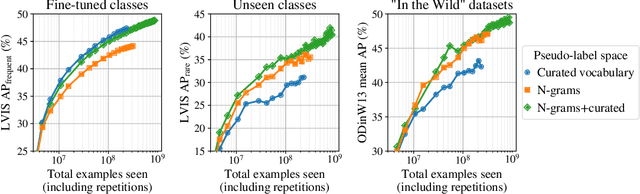
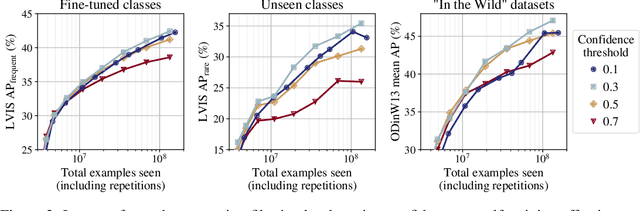
Open-vocabulary object detection has benefited greatly from pretrained vision-language models, but is still limited by the amount of available detection training data. While detection training data can be expanded by using Web image-text pairs as weak supervision, this has not been done at scales comparable to image-level pretraining. Here, we scale up detection data with self-training, which uses an existing detector to generate pseudo-box annotations on image-text pairs. Major challenges in scaling self-training are the choice of label space, pseudo-annotation filtering, and training efficiency. We present the OWLv2 model and OWL-ST self-training recipe, which address these challenges. OWLv2 surpasses the performance of previous state-of-the-art open-vocabulary detectors already at comparable training scales (~10M examples). However, with OWL-ST, we can scale to over 1B examples, yielding further large improvement: With an L/14 architecture, OWL-ST improves AP on LVIS rare classes, for which the model has seen no human box annotations, from 31.2% to 44.6% (43% relative improvement). OWL-ST unlocks Web-scale training for open-world localization, similar to what has been seen for image classification and language modelling.
PrefGen: Preference Guided Image Generation with Relative Attributes
Apr 01, 2023

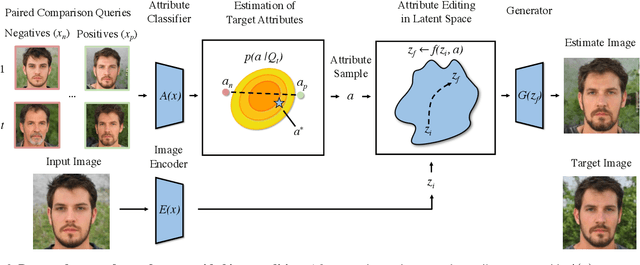
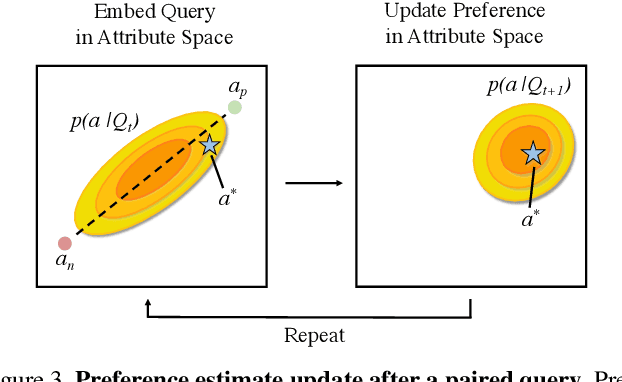
Deep generative models have the capacity to render high fidelity images of content like human faces. Recently, there has been substantial progress in conditionally generating images with specific quantitative attributes, like the emotion conveyed by one's face. These methods typically require a user to explicitly quantify the desired intensity of a visual attribute. A limitation of this method is that many attributes, like how "angry" a human face looks, are difficult for a user to precisely quantify. However, a user would be able to reliably say which of two faces seems "angrier". Following this premise, we develop the $\textit{PrefGen}$ system, which allows users to control the relative attributes of generated images by presenting them with simple paired comparison queries of the form "do you prefer image $a$ or image $b$?" Using information from a sequence of query responses, we can estimate user preferences over a set of image attributes and perform preference-guided image editing and generation. Furthermore, to make preference localization feasible and efficient, we apply an active query selection strategy. We demonstrate the success of this approach using a StyleGAN2 generator on the task of human face editing. Additionally, we demonstrate how our approach can be combined with CLIP, allowing a user to edit the relative intensity of attributes specified by text prompts. Code at https://github.com/helblazer811/PrefGen.
Unlocking Masked Autoencoders as Loss Function for Image and Video Restoration
Mar 29, 2023
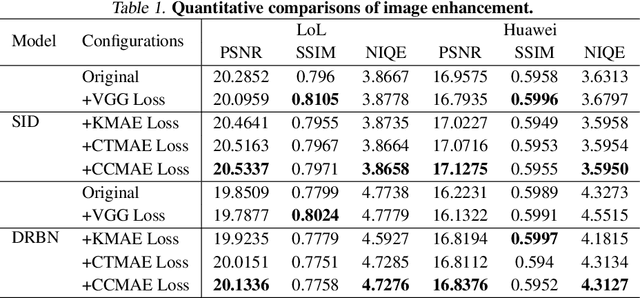
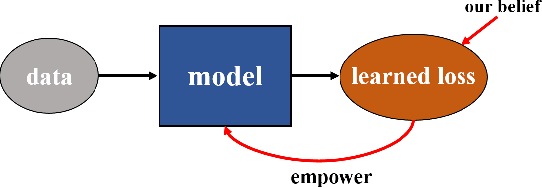
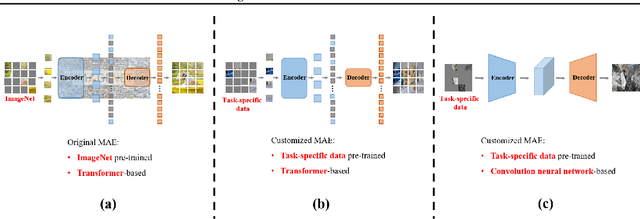
Image and video restoration has achieved a remarkable leap with the advent of deep learning. The success of deep learning paradigm lies in three key components: data, model, and loss. Currently, many efforts have been devoted to the first two while seldom study focuses on loss function. With the question ``are the de facto optimization functions e.g., $L_1$, $L_2$, and perceptual losses optimal?'', we explore the potential of loss and raise our belief ``learned loss function empowers the learning capability of neural networks for image and video restoration''. Concretely, we stand on the shoulders of the masked Autoencoders (MAE) and formulate it as a `learned loss function', owing to the fact the pre-trained MAE innately inherits the prior of image reasoning. We investigate the efficacy of our belief from three perspectives: 1) from task-customized MAE to native MAE, 2) from image task to video task, and 3) from transformer structure to convolution neural network structure. Extensive experiments across multiple image and video tasks, including image denoising, image super-resolution, image enhancement, guided image super-resolution, video denoising, and video enhancement, demonstrate the consistent performance improvements introduced by the learned loss function. Besides, the learned loss function is preferable as it can be directly plugged into existing networks during training without involving computations in the inference stage. Code will be publicly available.
Defect Detection Approaches Based on Simulated Reference Image
Mar 21, 2023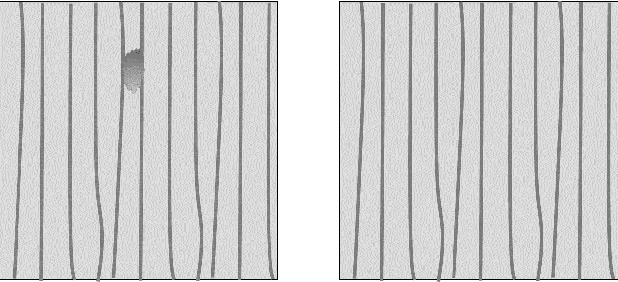

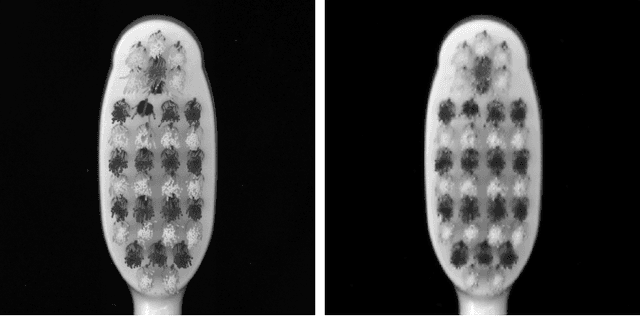

This work is addressing the problem of defect anomaly detection based on a clean reference image. Specifically, we focus on SEM semiconductor defects in addition to several natural image anomalies. There are well-known methods to create a simulation of an artificial reference image by its defect specimen. In this work, we introduce several applications for this capability, that the simulated reference is beneficial for improving their results. Among these defect detection methods are classic computer vision applied on difference-image, supervised deep-learning (DL) based on human labels, and unsupervised DL which is trained on feature-level patterns of normal reference images. We show in this study how to incorporate correctly the simulated reference image for these defect and anomaly detection applications. As our experiment demonstrates, simulated reference achieves higher performance than the real reference of an image of a defect and anomaly. This advantage of simulated reference occurs mainly due to the less noise and geometric variations together with better alignment and registration to the original defect background.