 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Modeling 3D cardiac contraction and relaxation with point cloud deformation networks
Jul 20, 2023
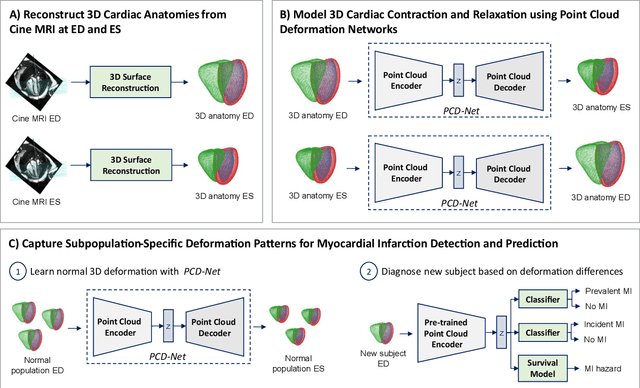
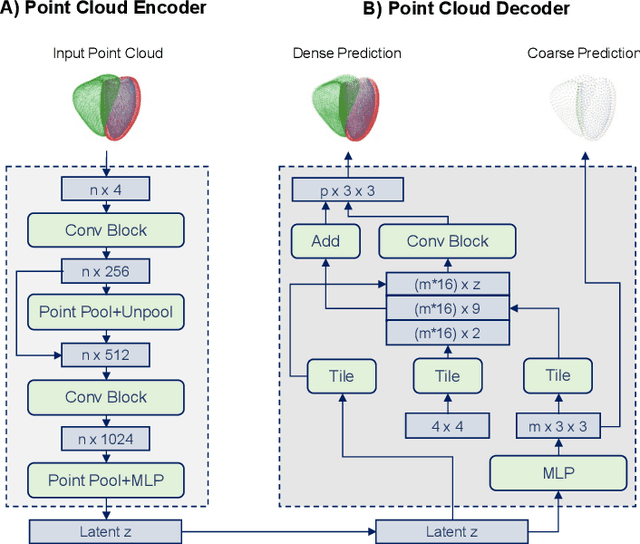
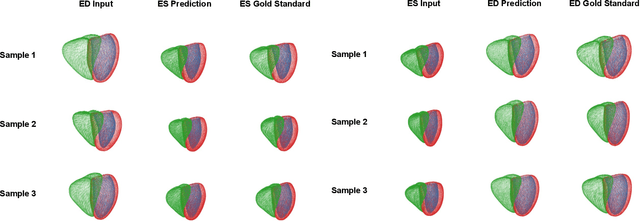
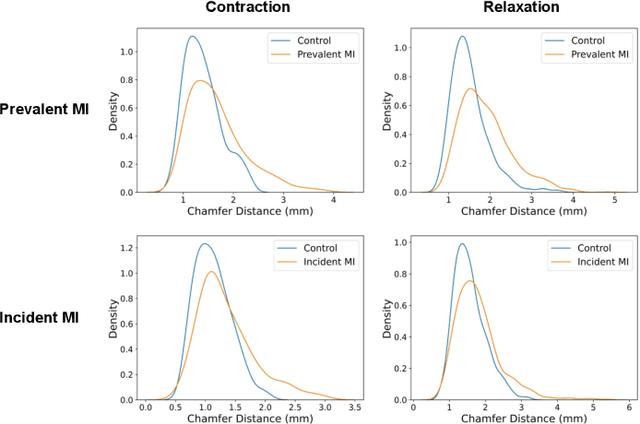
Global single-valued biomarkers of cardiac function typically used in clinical practice, such as ejection fraction, provide limited insight on the true 3D cardiac deformation process and hence, limit the understanding of both healthy and pathological cardiac mechanics. In this work, we propose the Point Cloud Deformation Network (PCD-Net) as a novel geometric deep learning approach to model 3D cardiac contraction and relaxation between the extreme ends of the cardiac cycle. It employs the recent advances in point cloud-based deep learning into an encoder-decoder structure, in order to enable efficient multi-scale feature learning directly on multi-class 3D point cloud representations of the cardiac anatomy. We evaluate our approach on a large dataset of over 10,000 cases from the UK Biobank study and find average Chamfer distances between the predicted and ground truth anatomies below the pixel resolution of the underlying image acquisition. Furthermore, we observe similar clinical metrics between predicted and ground truth populations and show that the PCD-Net can successfully capture subpopulation-specific differences between normal subjects and myocardial infarction (MI) patients. We then demonstrate that the learned 3D deformation patterns outperform multiple clinical benchmarks by 13% and 7% in terms of area under the receiver operating characteristic curve for the tasks of prevalent MI detection and incident MI prediction and by 7% in terms of Harrell's concordance index for MI survival analysis.
Disentangled Pre-training for Image Matting
Apr 03, 2023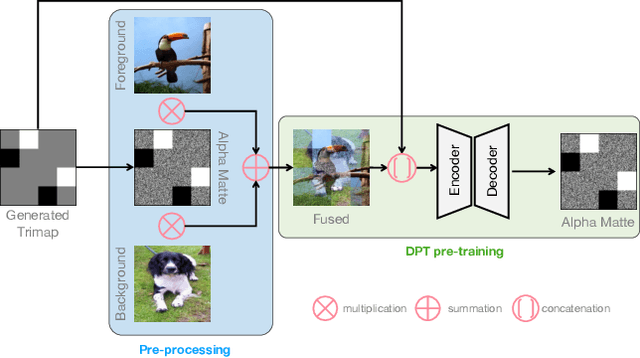
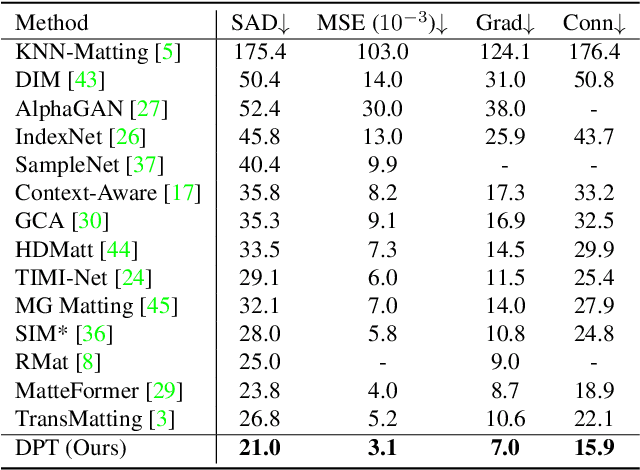

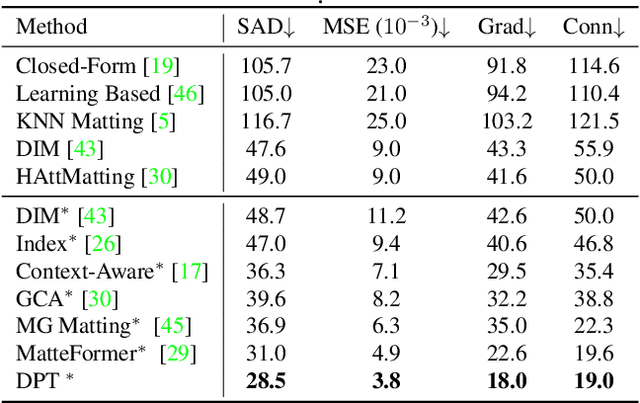
Image matting requires high-quality pixel-level human annotations to support the training of a deep model in recent literature. Whereas such annotation is costly and hard to scale, significantly holding back the development of the research. In this work, we make the first attempt towards addressing this problem, by proposing a self-supervised pre-training approach that can leverage infinite numbers of data to boost the matting performance. The pre-training task is designed in a similar manner as image matting, where random trimap and alpha matte are generated to achieve an image disentanglement objective. The pre-trained model is then used as an initialisation of the downstream matting task for fine-tuning. Extensive experimental evaluations show that the proposed approach outperforms both the state-of-the-art matting methods and other alternative self-supervised initialisation approaches by a large margin. We also show the robustness of the proposed approach over different backbone architectures. The code and models will be publicly available.
Marginal Thresholding in Noisy Image Segmentation
May 04, 2023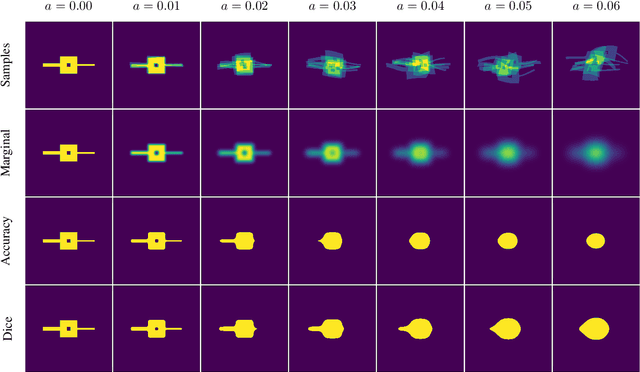
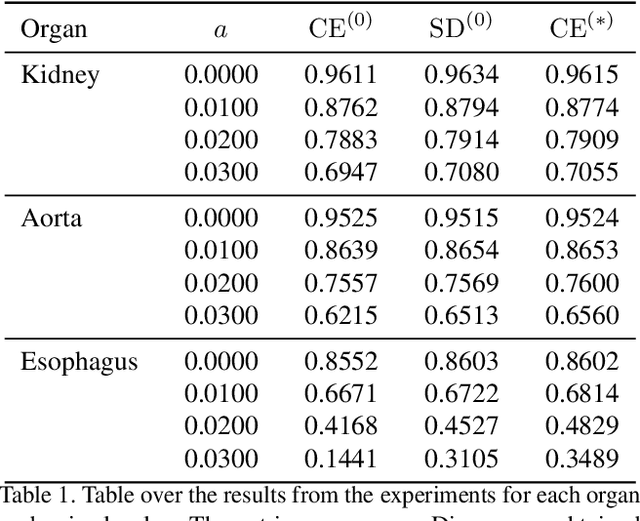
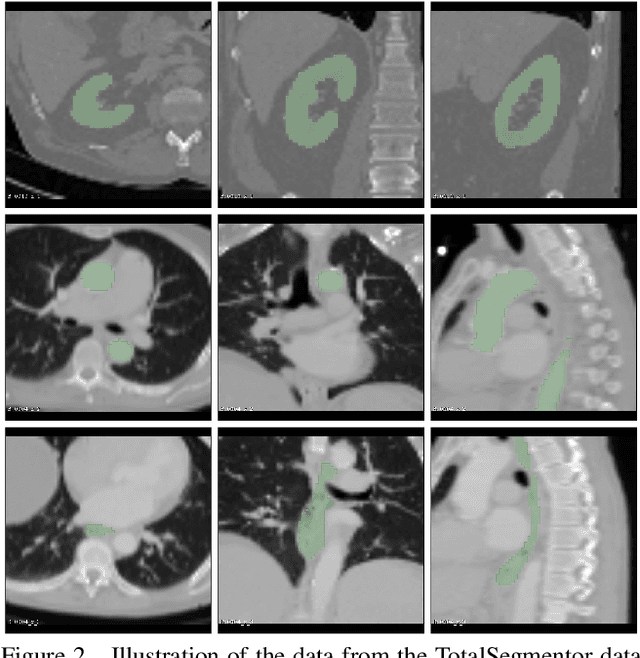
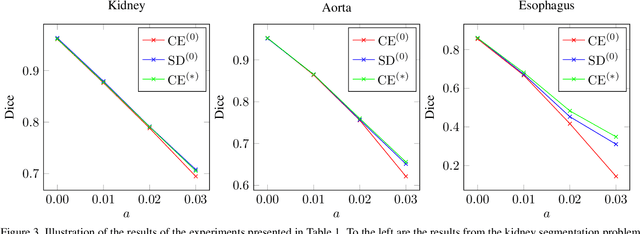
This work presents a study on label noise in medical image segmentation by considering a noise model based on Gaussian field deformations. Such noise is of interest because it yields realistic looking segmentations and because it is unbiased in the sense that the expected deformation is the identity mapping. Efficient methods for sampling and closed form solutions for the marginal probabilities are provided. Moreover, theoretically optimal solutions to the loss functions cross-entropy and soft-Dice are studied and it is shown how they diverge as the level of noise increases. Based on recent work on loss function characterization, it is shown that optimal solutions to soft-Dice can be recovered by thresholding solutions to cross-entropy with a particular a priori unknown threshold that efficiently can be computed. This raises the question whether the decrease in performance seen when using cross-entropy as compared to soft-Dice is caused by using the wrong threshold. The hypothesis is validated in 5-fold studies on three organ segmentation problems from the TotalSegmentor data set, using 4 different strengths of noise. The results show that changing the threshold leads the performance of cross-entropy to go from systematically worse than soft-Dice to similar or better results than soft-Dice.
Collaborative Score Distillation for Consistent Visual Synthesis
Jul 04, 2023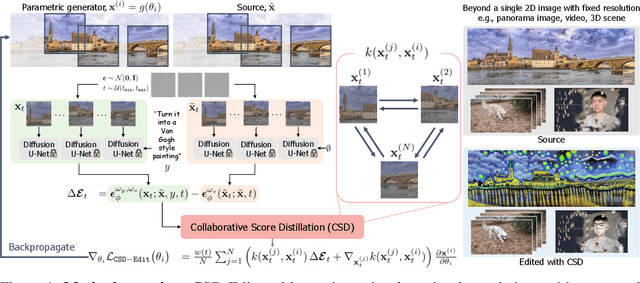



Generative priors of large-scale text-to-image diffusion models enable a wide range of new generation and editing applications on diverse visual modalities. However, when adapting these priors to complex visual modalities, often represented as multiple images (e.g., video), achieving consistency across a set of images is challenging. In this paper, we address this challenge with a novel method, Collaborative Score Distillation (CSD). CSD is based on the Stein Variational Gradient Descent (SVGD). Specifically, we propose to consider multiple samples as "particles" in the SVGD update and combine their score functions to distill generative priors over a set of images synchronously. Thus, CSD facilitates seamless integration of information across 2D images, leading to a consistent visual synthesis across multiple samples. We show the effectiveness of CSD in a variety of tasks, encompassing the visual editing of panorama images, videos, and 3D scenes. Our results underline the competency of CSD as a versatile method for enhancing inter-sample consistency, thereby broadening the applicability of text-to-image diffusion models.
Applying a Color Palette with Local Control using Diffusion Models
Jul 13, 2023



We demonstrate two novel editing procedures in the context of fantasy card art. Palette transfer applies a specified reference palette to a given card. For fantasy art, the desired change in palette can be very large, leading to huge changes in the "look" of the art. We demonstrate that a pipeline of vector quantization; matching; and "vector dequantization" (using a diffusion model) produces successful extreme palette transfers. Segment control allows an artist to move one or more image segments, and to optionally specify the desired color of the result. The combination of these two types of edit yields valuable workflows, including: move a segment, then recolor; recolor, then force some segments to take a prescribed color. We demonstrate our methods on the challenging Yu-Gi-Oh card art dataset.
Bidirectional Temporal Diffusion Model for Temporally Consistent Human Animation
Jul 02, 2023
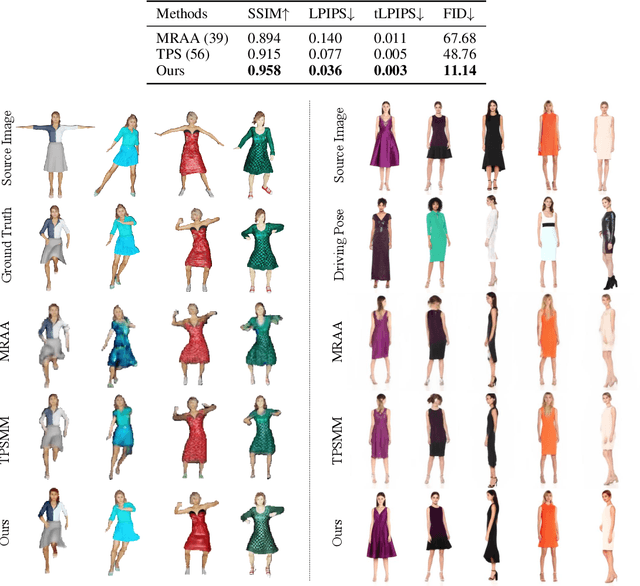
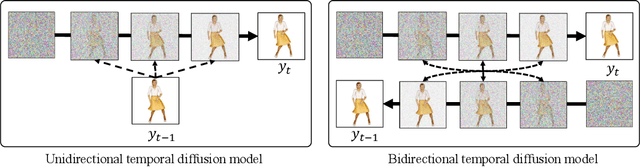
We introduce a method to generate temporally coherent human animation from a single image, a video, or a random noise. This problem has been formulated as modeling of an auto-regressive generation, i.e., to regress past frames to decode future frames. However, such unidirectional generation is highly prone to motion drifting over time, generating unrealistic human animation with significant artifacts such as appearance distortion. We claim that bidirectional temporal modeling enforces temporal coherence on a generative network by largely suppressing the motion ambiguity of human appearance. To prove our claim, we design a novel human animation framework using a denoising diffusion model: a neural network learns to generate the image of a person by denoising temporal Gaussian noises whose intermediate results are cross-conditioned bidirectionally between consecutive frames. In the experiments, our method demonstrates strong performance compared to existing unidirectional approaches with realistic temporal coherence
SAVE: Spectral-Shift-Aware Adaptation of Image Diffusion Models for Text-guided Video Editing
May 30, 2023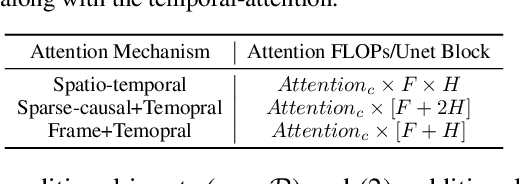
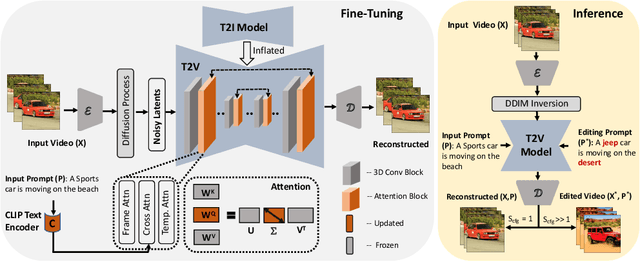
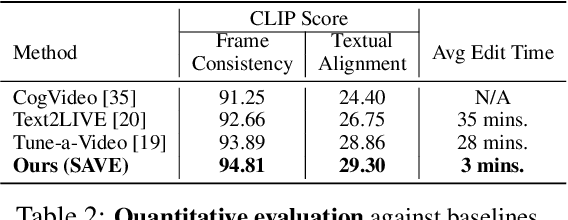
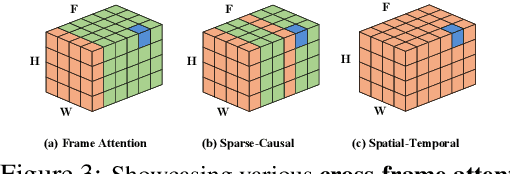
Text-to-Image (T2I) diffusion models have achieved remarkable success in synthesizing high-quality images conditioned on text prompts. Recent methods have tried to replicate the success by either training text-to-video (T2V) models on a very large number of text-video pairs or adapting T2I models on text-video pairs independently. Although the latter is computationally less expensive, it still takes a significant amount of time for per-video adaption. To address this issue, we propose SAVE, a novel spectral-shift-aware adaptation framework, in which we fine-tune the spectral shift of the parameter space instead of the parameters themselves. Specifically, we take the spectral decomposition of the pre-trained T2I weights and only control the change in the corresponding singular values, i.e. spectral shift, while freezing the corresponding singular vectors. To avoid drastic drift from the original T2I weights, we introduce a spectral shift regularizer that confines the spectral shift to be more restricted for large singular values and more relaxed for small singular values. Since we are only dealing with spectral shifts, the proposed method reduces the adaptation time significantly (approx. 10 times) and has fewer resource constrains for training. Such attributes posit SAVE to be more suitable for real-world applications, e.g. editing undesirable content during video streaming. We validate the effectiveness of SAVE with an extensive experimental evaluation under different settings, e.g. style transfer, object replacement, privacy preservation, etc.
Low-Light Image Enhancement via Structure Modeling and Guidance
May 10, 2023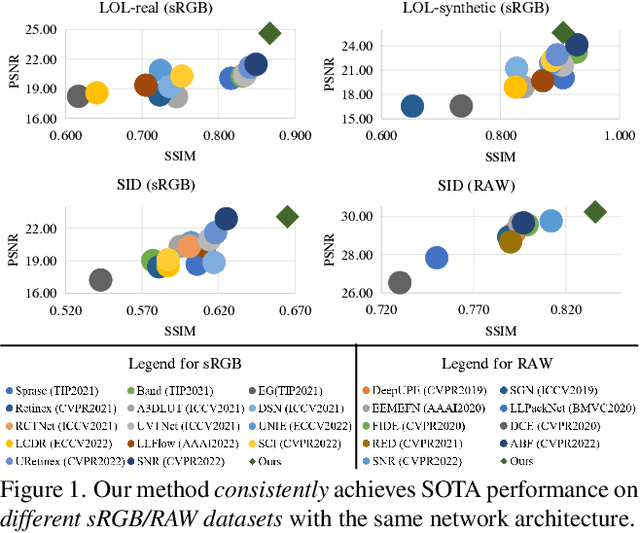
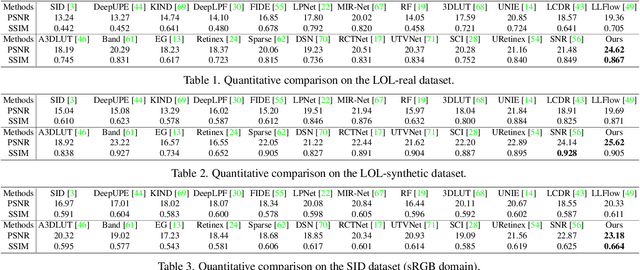

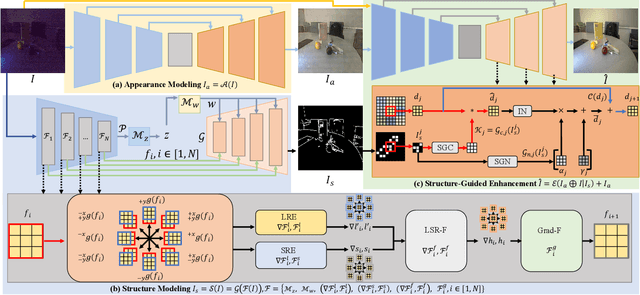
This paper proposes a new framework for low-light image enhancement by simultaneously conducting the appearance as well as structure modeling. It employs the structural feature to guide the appearance enhancement, leading to sharp and realistic results. The structure modeling in our framework is implemented as the edge detection in low-light images. It is achieved with a modified generative model via designing a structure-aware feature extractor and generator. The detected edge maps can accurately emphasize the essential structural information, and the edge prediction is robust towards the noises in dark areas. Moreover, to improve the appearance modeling, which is implemented with a simple U-Net, a novel structure-guided enhancement module is proposed with structure-guided feature synthesis layers. The appearance modeling, edge detector, and enhancement module can be trained end-to-end. The experiments are conducted on representative datasets (sRGB and RAW domains), showing that our model consistently achieves SOTA performance on all datasets with the same architecture.
CLIPA-v2: Scaling CLIP Training with 81.1% Zero-shot ImageNet Accuracy within a \$10,000 Budget; An Extra \$4,000 Unlocks 81.8% Accuracy
Jun 27, 2023

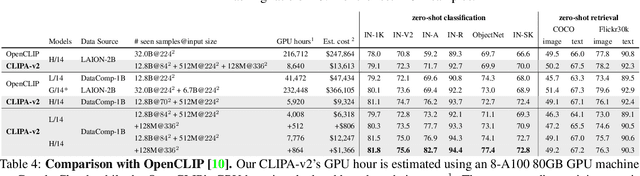
The recent work CLIPA presents an inverse scaling law for CLIP training -- whereby the larger the image/text encoders used, the shorter the sequence length of image/text tokens that can be applied in training. This finding enables us to train high-performance CLIP models with significantly reduced computations. Building upon this work, we hereby present CLIPA-v2 with two key contributions. Technically, we find this inverse scaling law is also applicable in the finetuning stage, enabling further reduction in computational needs. Empirically, we explore CLIPA at scale, extending the experiments up to the H/14 model with ~13B image-text pairs seen during training. Our results are exciting -- by only allocating a budget of \$10,000, our CLIP model achieves an impressive zero-shot ImageNet accuracy of 81.1%, surpassing the prior best CLIP model (from OpenCLIP, 80.1%) by 1.0% and meanwhile reducing the computational cost by ~39X. Moreover, with an additional investment of $4,000, we can further elevate the zero-shot ImageNet accuracy to 81.8%. Our code and models are available at https://github.com/UCSC-VLAA/CLIPA.
Unsupervised Spectral Demosaicing with Lightweight Spectral Attention Networks
Jul 05, 2023
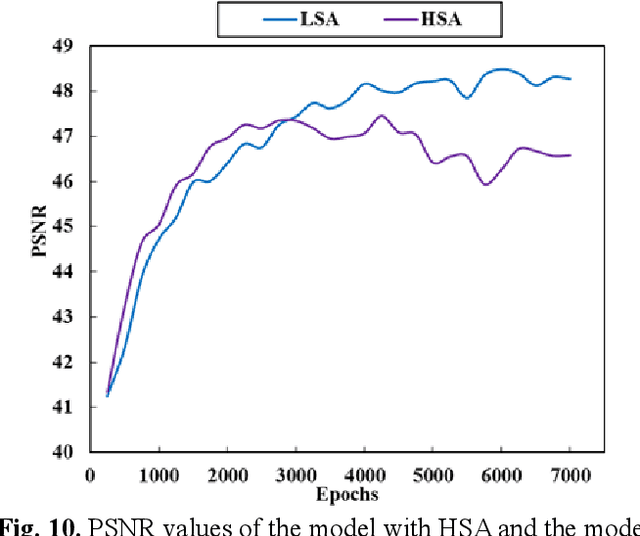
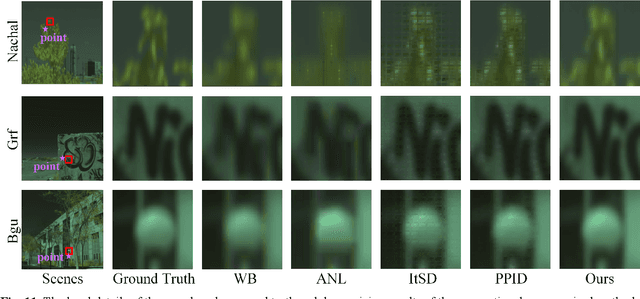
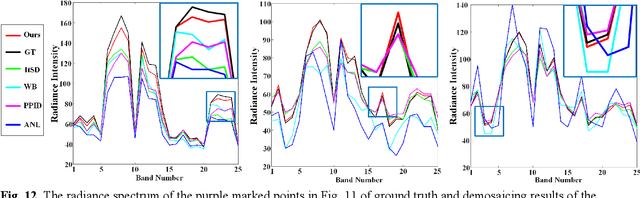
This paper presents a deep learning-based spectral demosaicing technique trained in an unsupervised manner. Many existing deep learning-based techniques relying on supervised learning with synthetic images, often underperform on real-world images especially when the number of spectral bands increases. According to the characteristics of the spectral mosaic image, this paper proposes a mosaic loss function, the corresponding model structure, a transformation strategy, and an early stopping strategy, which form a complete unsupervised spectral demosaicing framework. A challenge in real-world spectral demosaicing is inconsistency between the model parameters and the computational resources of the imager. We reduce the complexity and parameters of the spectral attention module by dividing the spectral attention tensor into spectral attention matrices in the spatial dimension and spectral attention vector in the channel dimension, which is more suitable for unsupervised framework. This paper also presents Mosaic25, a real 25-band hyperspectral mosaic image dataset of various objects, illuminations, and materials for benchmarking. Extensive experiments on synthetic and real-world datasets demonstrate that the proposed method outperforms conventional unsupervised methods in terms of spatial distortion suppression, spectral fidelity, robustness, and computational cost.