 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Zero-Shot Composed Image Retrieval with Textual Inversion
Mar 27, 2023
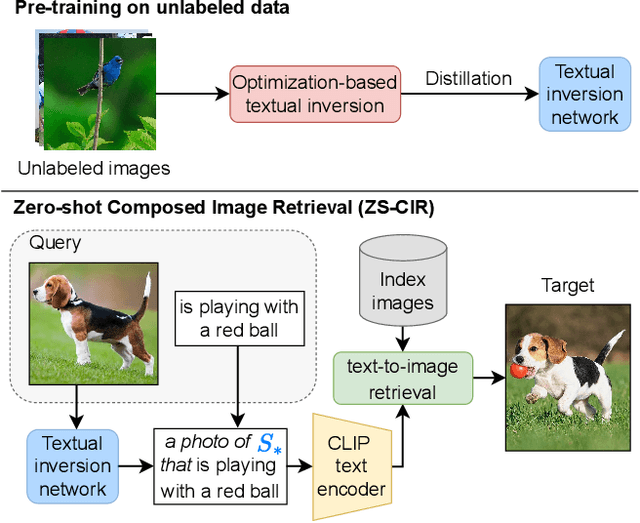
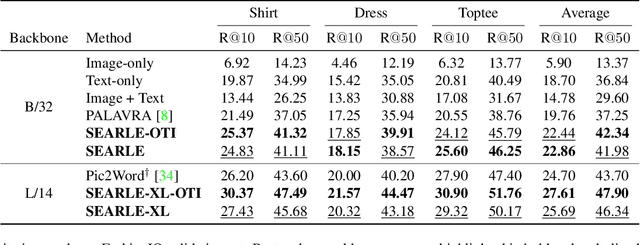
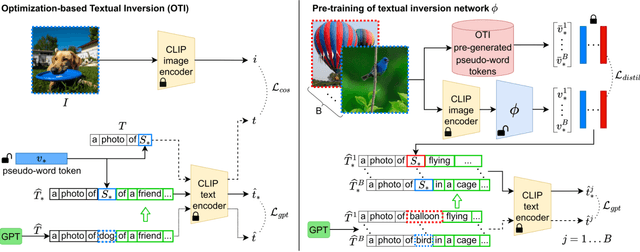
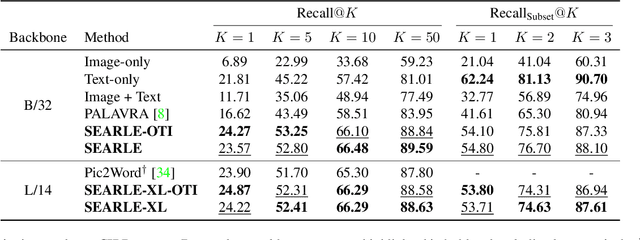
Composed Image Retrieval (CIR) aims to retrieve a target image based on a query composed of a reference image and a relative caption that describes the difference between the two images. The high effort and cost required for labeling datasets for CIR hamper the widespread usage of existing methods, as they rely on supervised learning. In this work, we propose a new task, Zero-Shot CIR (ZS-CIR), that aims to address CIR without requiring a labeled training dataset. Our approach, named zero-Shot composEd imAge Retrieval with textuaL invErsion (SEARLE), maps the visual features of the reference image into a pseudo-word token in CLIP token embedding space and integrates it with the relative caption. To support research on ZS-CIR, we introduce an open-domain benchmarking dataset named Composed Image Retrieval on Common Objects in context (CIRCO), which is the first dataset for CIR containing multiple ground truths for each query. The experiments show that SEARLE exhibits better performance than the baselines on the two main datasets for CIR tasks, FashionIQ and CIRR, and on the proposed CIRCO. The dataset, the code and the model are publicly available at https://github.com/miccunifi/SEARLE .
Zero-shot Generative Model Adaptation via Image-specific Prompt Learning
Apr 06, 2023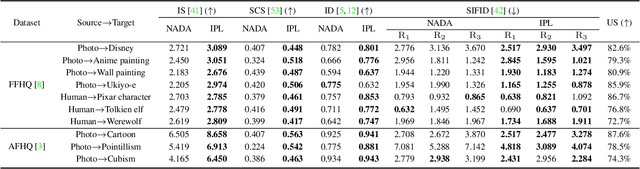
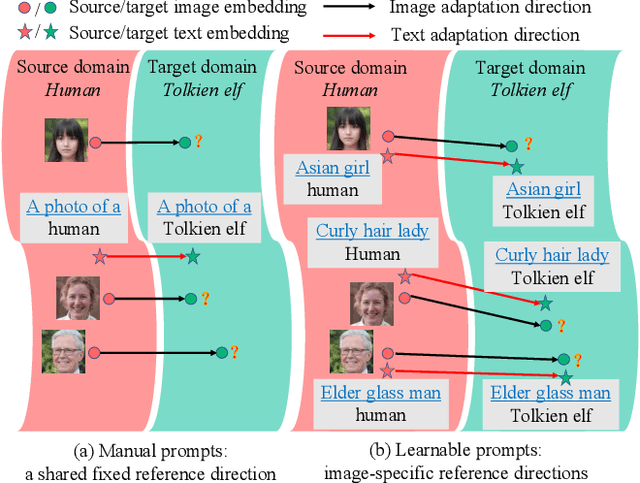
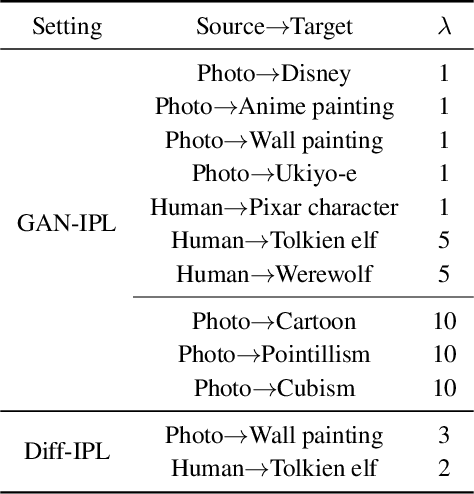
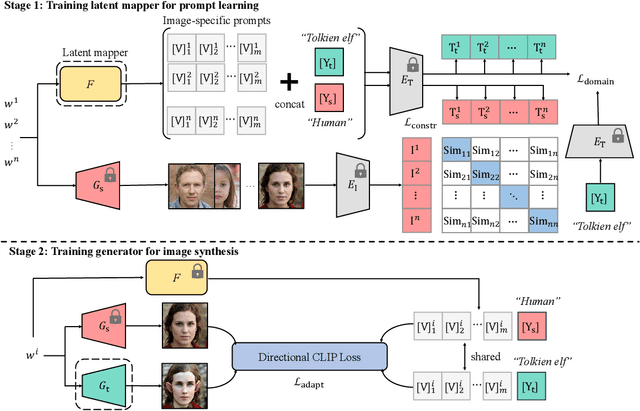
Recently, CLIP-guided image synthesis has shown appealing performance on adapting a pre-trained source-domain generator to an unseen target domain. It does not require any target-domain samples but only the textual domain labels. The training is highly efficient, e.g., a few minutes. However, existing methods still have some limitations in the quality of generated images and may suffer from the mode collapse issue. A key reason is that a fixed adaptation direction is applied for all cross-domain image pairs, which leads to identical supervision signals. To address this issue, we propose an Image-specific Prompt Learning (IPL) method, which learns specific prompt vectors for each source-domain image. This produces a more precise adaptation direction for every cross-domain image pair, endowing the target-domain generator with greatly enhanced flexibility. Qualitative and quantitative evaluations on various domains demonstrate that IPL effectively improves the quality and diversity of synthesized images and alleviates the mode collapse. Moreover, IPL is independent of the structure of the generative model, such as generative adversarial networks or diffusion models. Code is available at https://github.com/Picsart-AI-Research/IPL-Zero-Shot-Generative-Model-Adaptation.
Diffusion in Diffusion: Cyclic One-Way Diffusion for Text-Vision-Conditioned Generation
Jun 14, 2023


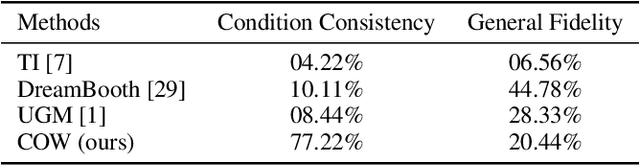
Text-to-Image (T2I) generation with diffusion models allows users to control the semantic content in the synthesized images given text conditions. As a further step toward a more customized image creation application, we introduce a new multi-modality generation setting that synthesizes images based on not only the semantic-level textual input but also on the pixel-level visual conditions. Existing literature first converts the given visual information to semantic-level representation by connecting it to languages, and then incorporates it into the original denoising process. Seemingly intuitive, such methodological design loses the pixel values during the semantic transition, thus failing to fulfill the task scenario where the preservation of low-level vision is desired (e.g., ID of a given face image). To this end, we propose Cyclic One-Way Diffusion (COW), a training-free framework for creating customized images with respect to semantic text and pixel-visual conditioning. Notably, we observe that sub-regions of an image impose mutual interference, just like physical diffusion, to achieve ultimate harmony along the denoising trajectory. Thus we propose to repetitively utilize the given visual condition in a cyclic way, by planting the visual condition as a high-concentration ``seed'' at the initialization step of the denoising process, and ``diffuse'' it into a harmonious picture by controlling a one-way information flow from the visual condition. We repeat the destroy-and-construct process multiple times to gradually but steadily impose the internal diffusion process within the image. Experiments on the challenging one-shot face and text-conditioned image synthesis task demonstrate our superiority in terms of speed, image quality, and conditional fidelity compared to learning-based text-vision conditional methods.
Evaluating Adversarial Robustness on Document Image Classification
Apr 24, 2023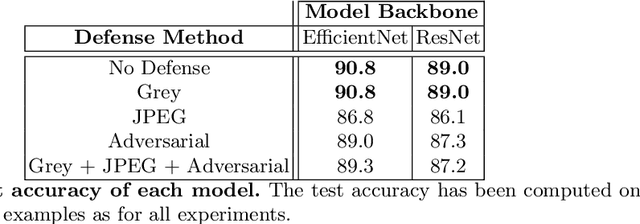

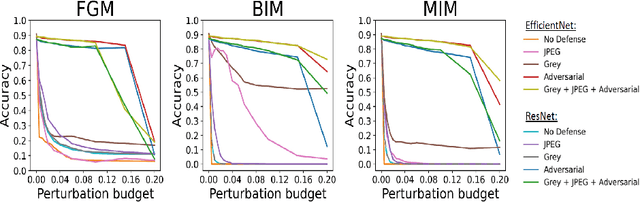
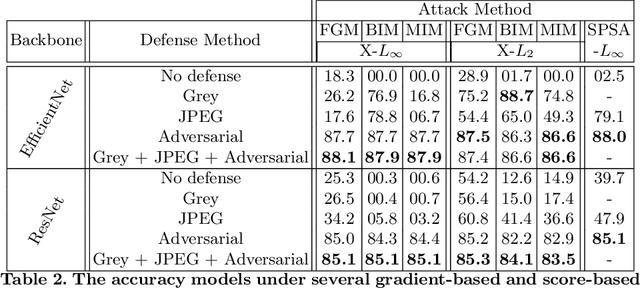
Adversarial attacks and defenses have gained increasing interest on computer vision systems in recent years, but as of today, most investigations are limited to images. However, many artificial intelligence models actually handle documentary data, which is very different from real world images. Hence, in this work, we try to apply the adversarial attack philosophy on documentary and natural data and to protect models against such attacks. We focus our work on untargeted gradient-based, transfer-based and score-based attacks and evaluate the impact of adversarial training, JPEG input compression and grey-scale input transformation on the robustness of ResNet50 and EfficientNetB0 model architectures. To the best of our knowledge, no such work has been conducted by the community in order to study the impact of these attacks on the document image classification task.
Sulcal Pattern Matching with the Wasserstein Distance
Jul 01, 2023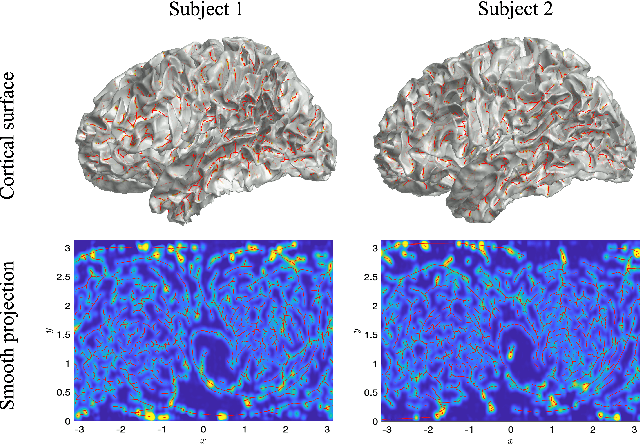
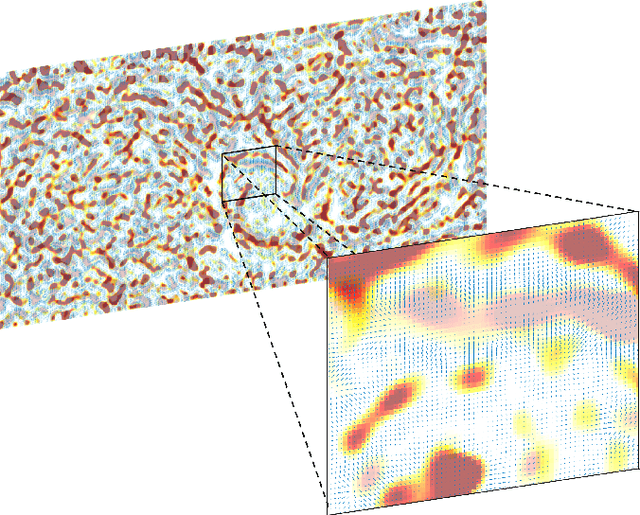
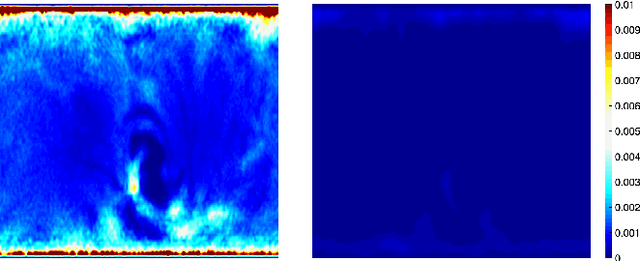
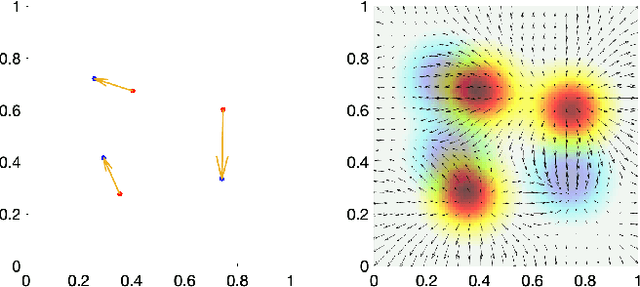
We present the unified computational framework for modeling the sulcal patterns of human brain obtained from the magnetic resonance images. The Wasserstein distance is used to align the sulcal patterns nonlinearly. These patterns are topologically different across subjects making the pattern matching a challenge. We work out the mathematical details and develop the gradient descent algorithms for estimating the deformation field. We further quantify the image registration performance. This method is applied in identifying the differences between male and female sulcal patterns.
Continuous and Noninvasive Measurement of Arterial Pulse Pressure and Pressure Waveform using an Image-free Ultrasound System
May 29, 2023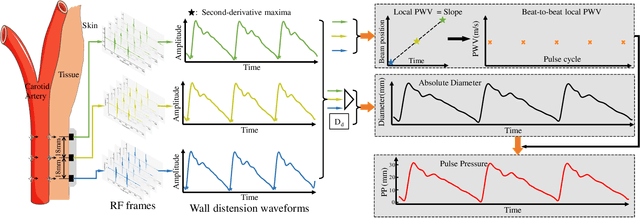
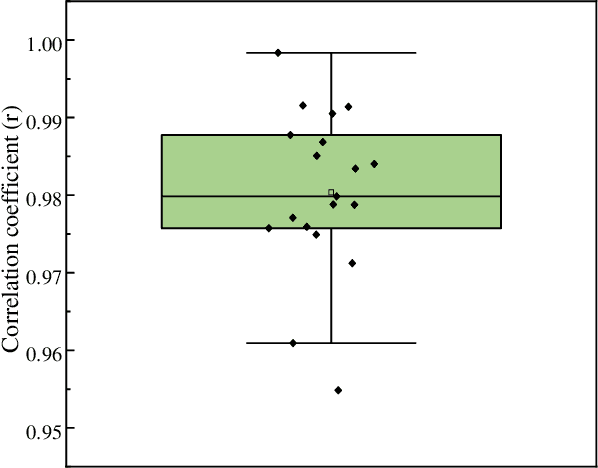
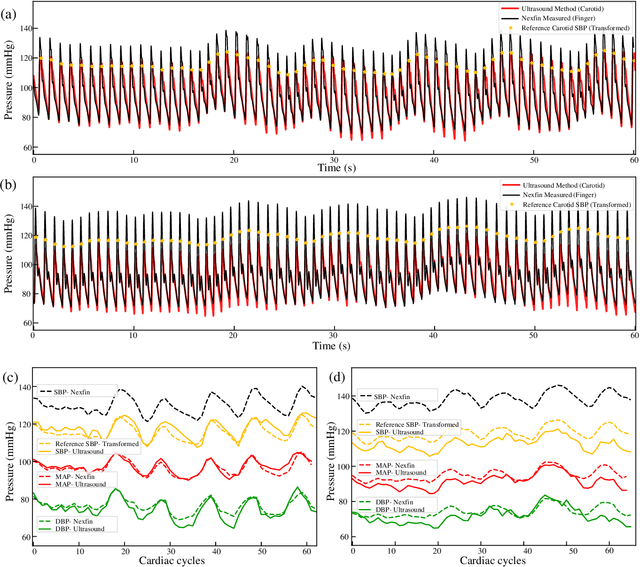
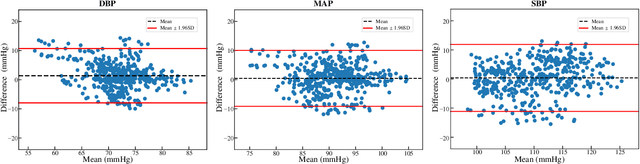
The local beat-to-beat local pulse pressure (PP) and blood pressure waveform of arteries, especially central arteries, are important indicators of the course of cardiovascular diseases (CVDs). Nevertheless, noninvasive measurement of them remains a challenge in the clinic. This work presents a three-element image-free ultrasound system with a low-computational method for real-time measurement of local pulse wave velocity (PWV) and diameter waveforms, enabling real-time and noninvasive continuous PP and blood pressure waveforms measurement without calibration. The developed system has been well-validated in vitro and in vivo. In in vitro cardiovascular phantom experiments, the results demonstrated high accuracy in the measurement of PP (error < 3 mmHg) and blood pressure waveform (root-mean-square-errors (RMSE) < 2 mmHg, correlation coefficient (r) > textgreater 0.99). In subsequent human carotid experiments, the system was compared with an arterial tonometer, which showed excellent PP accuracy (mean absolute error (MAE) = 3.7 +- 3.4 mmHg) and pressure waveform similarity (RMSE = 3.7 +- 1.6 mmHg, r = 0.98 +- 0.01). Furthermore, comparative experiments with the volume clamp device demonstrated the system's ability to accurately trace blood pressure changes (induced by deep breathing) over a period of one minute, with the MAE of DBP, MAP, and SBP within 5 +- 8 mmHg. The present results demonstrate the accuracy and reliability of the developed system for continuous and noninvasive measurement of arterial PP and blood pressure waveform measurements, with potential applications in the diagnosis and prevention of CVDs.
Detection of Adversarial Physical Attacks in Time-Series Image Data
Apr 27, 2023

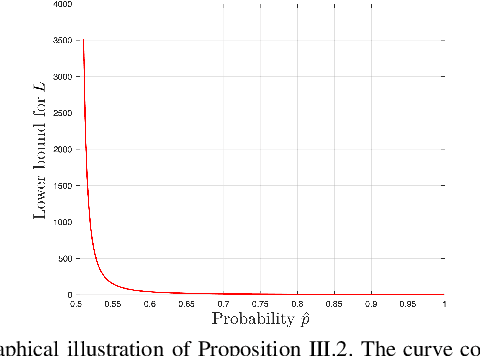
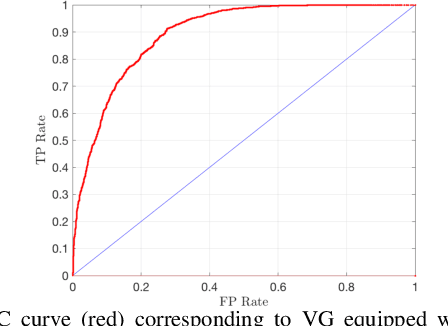
Deep neural networks (DNN) have become a common sensing modality in autonomous systems as they allow for semantically perceiving the ambient environment given input images. Nevertheless, DNN models have proven to be vulnerable to adversarial digital and physical attacks. To mitigate this issue, several detection frameworks have been proposed to detect whether a single input image has been manipulated by adversarial digital noise or not. In our prior work, we proposed a real-time detector, called VisionGuard (VG), for adversarial physical attacks against single input images to DNN models. Building upon that work, we propose VisionGuard* (VG), which couples VG with majority-vote methods, to detect adversarial physical attacks in time-series image data, e.g., videos. This is motivated by autonomous systems applications where images are collected over time using onboard sensors for decision-making purposes. We emphasize that majority-vote mechanisms are quite common in autonomous system applications (among many other applications), as e.g., in autonomous driving stacks for object detection. In this paper, we investigate, both theoretically and experimentally, how this widely used mechanism can be leveraged to enhance the performance of adversarial detectors. We have evaluated VG* on videos of both clean and physically attacked traffic signs generated by a state-of-the-art robust physical attack. We provide extensive comparative experiments against detectors that have been designed originally for out-of-distribution data and digitally attacked images.
Super-resolution imaging through a multimode fiber: the physical upsampling of speckle-driven
Jul 11, 2023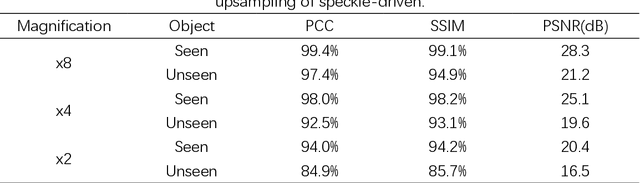
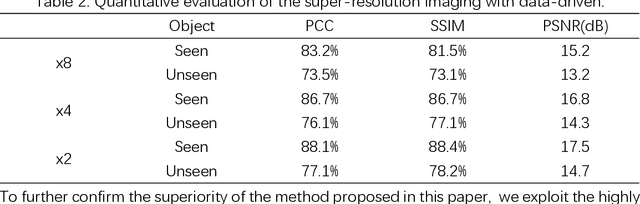
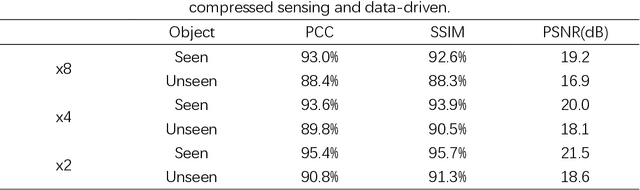
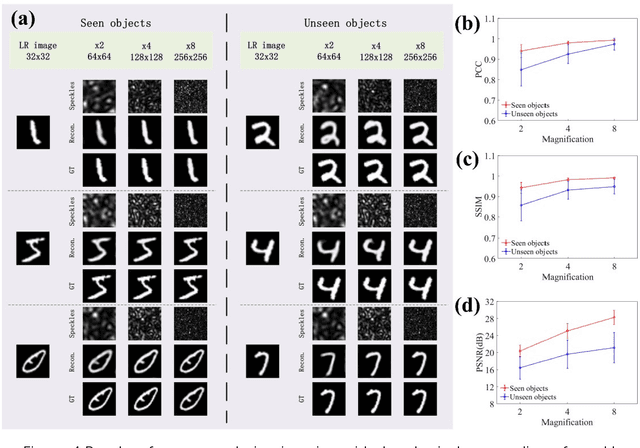
Following recent advancements in multimode fiber (MMF), miniaturization of imaging endoscopes has proven crucial for minimally invasive surgery in vivo. Recent progress enabled by super-resolution imaging methods with a data-driven deep learning (DL) framework has balanced the relationship between the core size and resolution. However, most of the DL approaches lack attention to the physical properties of the speckle, which is crucial for reconciling the relationship between the magnification of super-resolution imaging and the quality of reconstruction quality. In the paper, we find that the interferometric process of speckle formation is an essential basis for creating DL models with super-resolution imaging. It physically realizes the upsampling of low-resolution (LR) images and enhances the perceptual capabilities of the models. The finding experimentally validates the role played by the physical upsampling of speckle-driven, effectively complementing the lack of information in data-driven. Experimentally, we break the restriction of the poor reconstruction quality at great magnification by inputting the same size of the speckle with the size of the high-resolution (HR) image to the model. The guidance of our research for endoscopic imaging may accelerate the further development of minimally invasive surgery.
Pick your Poison: Undetectability versus Robustness in Data Poisoning Attacks against Deep Image Classification
May 07, 2023
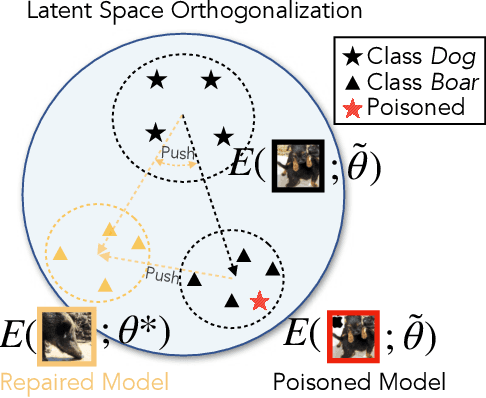
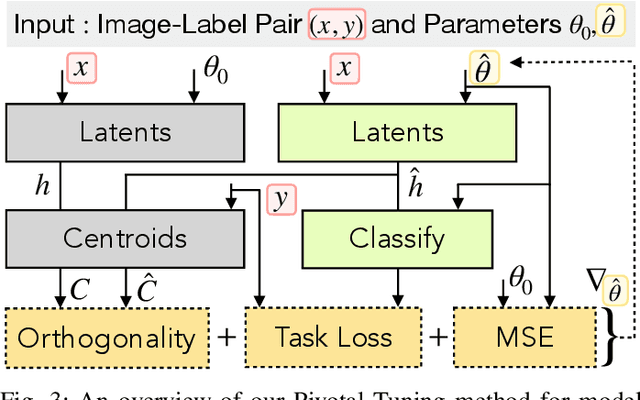

Deep image classification models trained on large amounts of web-scraped data are vulnerable to data poisoning, a mechanism for backdooring models. Even a few poisoned samples seen during training can entirely undermine the model's integrity during inference. While it is known that poisoning more samples enhances an attack's effectiveness and robustness, it is unknown whether poisoning too many samples weakens an attack by making it more detectable. We observe a fundamental detectability/robustness trade-off in data poisoning attacks: Poisoning too few samples renders an attack ineffective and not robust, but poisoning too many samples makes it detectable. This raises the bar for data poisoning attackers who have to balance this trade-off to remain robust and undetectable. Our work proposes two defenses designed to (i) detect and (ii) repair poisoned models as a post-processing step after training using a limited amount of trusted image-label pairs. We show that our defenses mitigate all surveyed attacks and outperform existing defenses using less trusted data to repair a model. Our defense scales to joint vision-language models, such as CLIP, and interestingly, we find that attacks on larger models are more easily detectable but also more robust than those on smaller models. Lastly, we propose two adaptive attacks demonstrating that while our work raises the bar for data poisoning attacks, it cannot mitigate all forms of backdooring.
Efficient Annotation of Medieval Charters
Jun 24, 2023
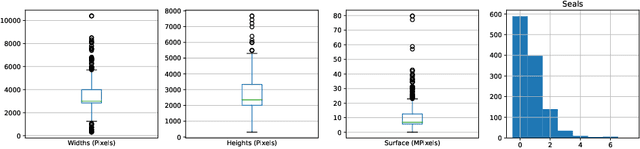
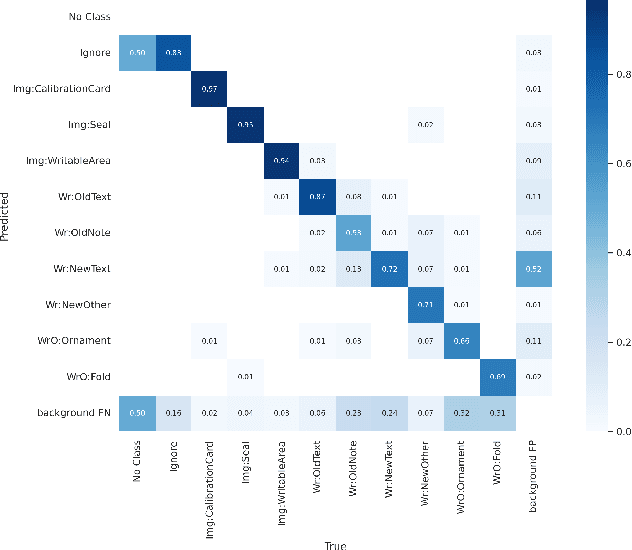
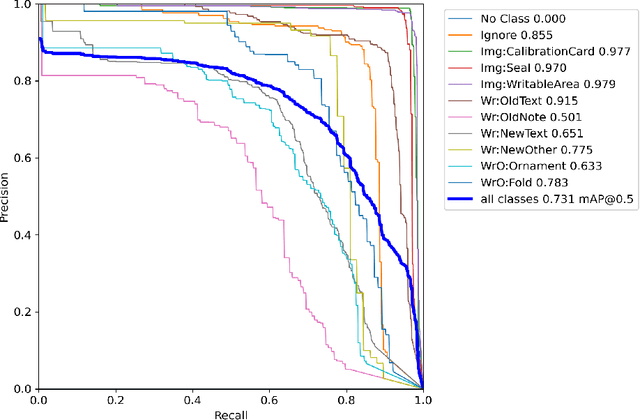
Diplomatics, the analysis of medieval charters, is a major field of research in which paleography is applied. Annotating data, if performed by laymen, needs validation and correction by experts. In this paper, we propose an effective and efficient annotation approach for charter segmentation, essentially reducing it to object detection. This approach allows for a much more efficient use of the paleographer's time and produces results that can compete and even outperform pixel-level segmentation in some use cases. Further experiments shed light on how to design a class ontology in order to make the best use of annotators' time and effort. Exploiting the presence of calibration cards in the image, we further annotate the data with the physical length in pixels and train regression neural networks to predict it from image patches.