 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Improved EATFormer: A Vision Transformer for Medical Image Classification
Mar 19, 2024
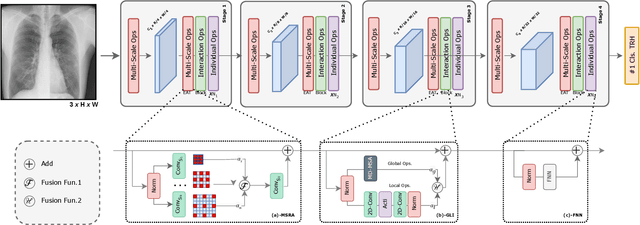
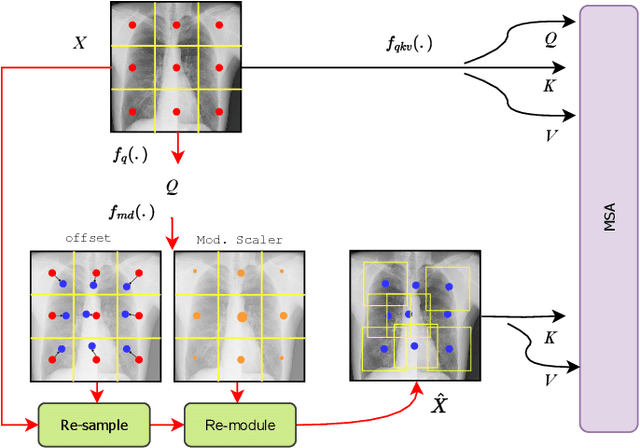
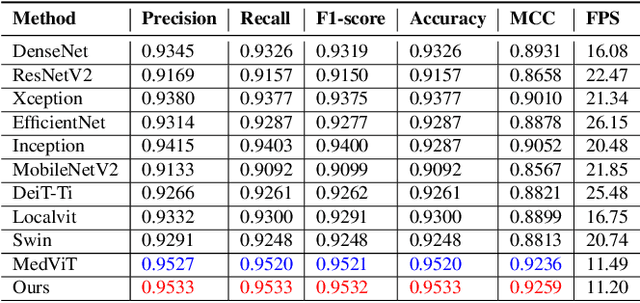
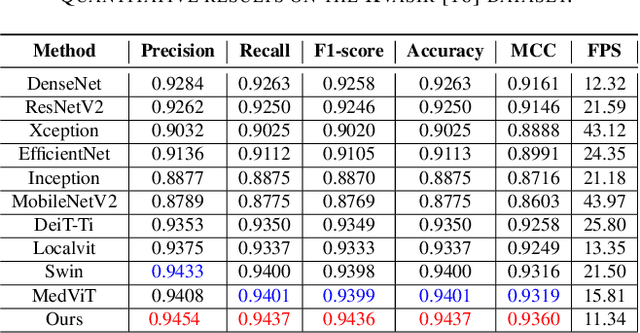
The accurate analysis of medical images is vital for diagnosing and predicting medical conditions. Traditional approaches relying on radiologists and clinicians suffer from inconsistencies and missed diagnoses. Computer-aided diagnosis systems can assist in achieving early, accurate, and efficient diagnoses. This paper presents an improved Evolutionary Algorithm-based Transformer architecture for medical image classification using Vision Transformers. The proposed EATFormer architecture combines the strengths of Convolutional Neural Networks and Vision Transformers, leveraging their ability to identify patterns in data and adapt to specific characteristics. The architecture incorporates novel components, including the Enhanced EA-based Transformer block with Feed-Forward Network, Global and Local Interaction , and Multi-Scale Region Aggregation modules. It also introduces the Modulated Deformable MSA module for dynamic modeling of irregular locations. The paper discusses the Vision Transformer (ViT) model's key features, such as patch-based processing, positional context incorporation, and Multi-Head Attention mechanism. It introduces the Multi-Scale Region Aggregation module, which aggregates information from different receptive fields to provide an inductive bias. The Global and Local Interaction module enhances the MSA-based global module by introducing a local path for extracting discriminative local information. Experimental results on the Chest X-ray and Kvasir datasets demonstrate that the proposed EATFormer significantly improves prediction speed and accuracy compared to baseline models.
Lost in Translation? Translation Errors and Challenges for Fair Assessment of Text-to-Image Models on Multilingual Concepts
Mar 17, 2024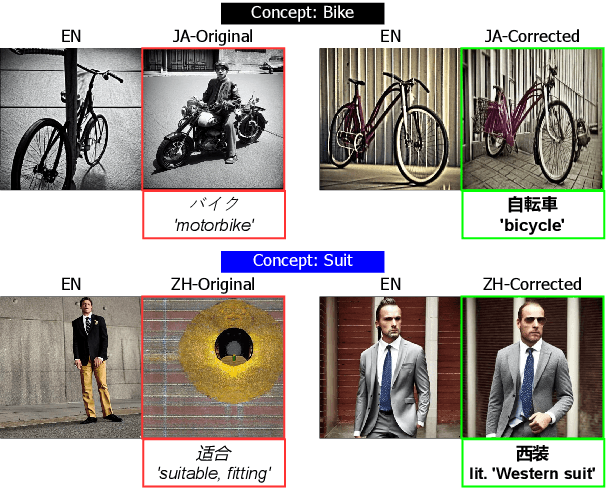

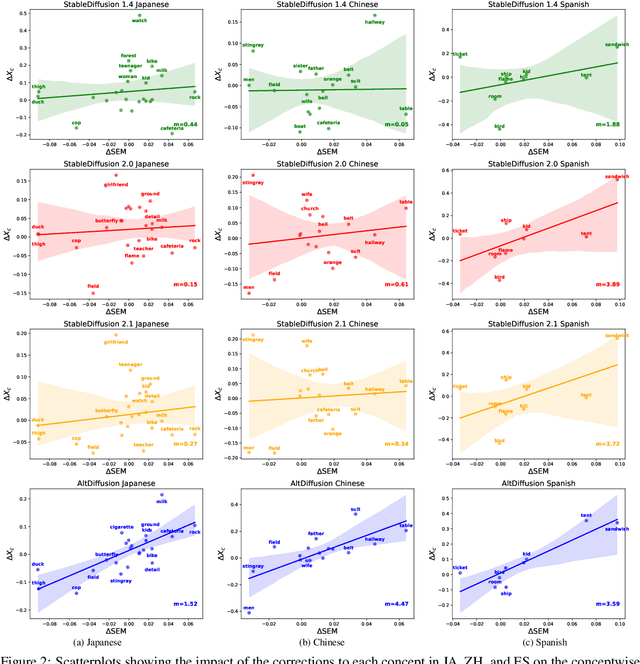

Benchmarks of the multilingual capabilities of text-to-image (T2I) models compare generated images prompted in a test language to an expected image distribution over a concept set. One such benchmark, "Conceptual Coverage Across Languages" (CoCo-CroLa), assesses the tangible noun inventory of T2I models by prompting them to generate pictures from a concept list translated to seven languages and comparing the output image populations. Unfortunately, we find that this benchmark contains translation errors of varying severity in Spanish, Japanese, and Chinese. We provide corrections for these errors and analyze how impactful they are on the utility and validity of CoCo-CroLa as a benchmark. We reassess multiple baseline T2I models with the revisions, compare the outputs elicited under the new translations to those conditioned on the old, and show that a correction's impactfulness on the image-domain benchmark results can be predicted in the text domain with similarity scores. Our findings will guide the future development of T2I multilinguality metrics by providing analytical tools for practical translation decisions.
Exploiting Semantic Reconstruction to Mitigate Hallucinations in Vision-Language Models
Mar 26, 2024Hallucinations in vision-language models pose a significant challenge to their reliability, particularly in the generation of long captions. Current methods fall short of accurately identifying and mitigating these hallucinations. To address this issue, we introduce ESREAL, a novel unsupervised learning framework designed to suppress the generation of hallucinations through accurate localization and penalization of hallucinated tokens. Initially, ESREAL creates a reconstructed image based on the generated caption and aligns its corresponding regions with those of the original image. This semantic reconstruction aids in identifying both the presence and type of token-level hallucinations within the generated caption. Subsequently, ESREAL computes token-level hallucination scores by assessing the semantic similarity of aligned regions based on the type of hallucination. Finally, ESREAL employs a proximal policy optimization algorithm, where it selectively penalizes hallucinated tokens according to their token-level hallucination scores. Our framework notably reduces hallucinations in LLaVA, InstructBLIP, and mPLUG-Owl2 by 32.81%, 27.08%, and 7.46% on the CHAIR metric. This improvement is achieved solely through signals derived from the image itself, without the need for any image-text pairs.
Super-Resolution of SOHO/MDI Magnetograms of Solar Active Regions Using SDO/HMI Data and an Attention-Aided Convolutional Neural Network
Mar 27, 2024Image super-resolution has been an important subject in image processing and recognition. Here, we present an attention-aided convolutional neural network (CNN) for solar image super-resolution. Our method, named SolarCNN, aims to enhance the quality of line-of-sight (LOS) magnetograms of solar active regions (ARs) collected by the Michelson Doppler Imager (MDI) on board the Solar and Heliospheric Observatory (SOHO). The ground-truth labels used for training SolarCNN are the LOS magnetograms collected by the Helioseismic and Magnetic Imager (HMI) on board the Solar Dynamics Observatory (SDO). Solar ARs consist of strong magnetic fields in which magnetic energy can suddenly be released to produce extreme space weather events, such as solar flares, coronal mass ejections, and solar energetic particles. SOHO/MDI covers Solar Cycle 23, which is stronger with more eruptive events than Cycle 24. Enhanced SOHO/MDI magnetograms allow for better understanding and forecasting of violent events of space weather. Experimental results show that SolarCNN improves the quality of SOHO/MDI magnetograms in terms of the structural similarity index measure (SSIM), Pearson's correlation coefficient (PCC), and the peak signal-to-noise ratio (PSNR).
Towards Realistic Scene Generation with LiDAR Diffusion Models
Mar 31, 2024Diffusion models (DMs) excel in photo-realistic image synthesis, but their adaptation to LiDAR scene generation poses a substantial hurdle. This is primarily because DMs operating in the point space struggle to preserve the curve-like patterns and 3D geometry of LiDAR scenes, which consumes much of their representation power. In this paper, we propose LiDAR Diffusion Models (LiDMs) to generate LiDAR-realistic scenes from a latent space tailored to capture the realism of LiDAR scenes by incorporating geometric priors into the learning pipeline. Our method targets three major desiderata: pattern realism, geometry realism, and object realism. Specifically, we introduce curve-wise compression to simulate real-world LiDAR patterns, point-wise coordinate supervision to learn scene geometry, and patch-wise encoding for a full 3D object context. With these three core designs, our method achieves competitive performance on unconditional LiDAR generation in 64-beam scenario and state of the art on conditional LiDAR generation, while maintaining high efficiency compared to point-based DMs (up to 107$\times$ faster). Furthermore, by compressing LiDAR scenes into a latent space, we enable the controllability of DMs with various conditions such as semantic maps, camera views, and text prompts. Our code and pretrained weights are available at https://github.com/hancyran/LiDAR-Diffusion.
Attack Deterministic Conditional Image Generative Models for Diverse and Controllable Generation
Mar 13, 2024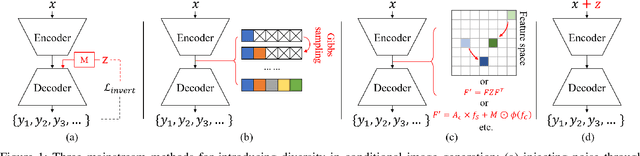
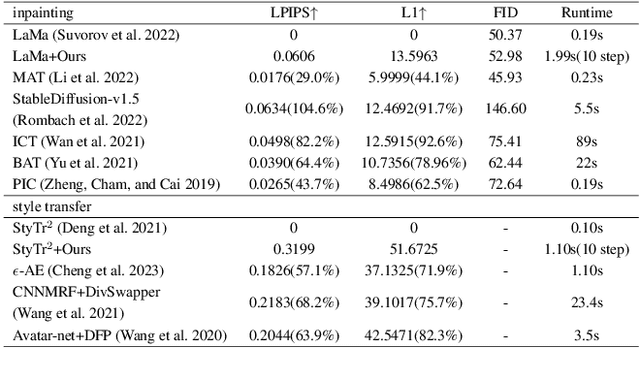


Existing generative adversarial network (GAN) based conditional image generative models typically produce fixed output for the same conditional input, which is unreasonable for highly subjective tasks, such as large-mask image inpainting or style transfer. On the other hand, GAN-based diverse image generative methods require retraining/fine-tuning the network or designing complex noise injection functions, which is computationally expensive, task-specific, or struggle to generate high-quality results. Given that many deterministic conditional image generative models have been able to produce high-quality yet fixed results, we raise an intriguing question: is it possible for pre-trained deterministic conditional image generative models to generate diverse results without changing network structures or parameters? To answer this question, we re-examine the conditional image generation tasks from the perspective of adversarial attack and propose a simple and efficient plug-in projected gradient descent (PGD) like method for diverse and controllable image generation. The key idea is attacking the pre-trained deterministic generative models by adding a micro perturbation to the input condition. In this way, diverse results can be generated without any adjustment of network structures or fine-tuning of the pre-trained models. In addition, we can also control the diverse results to be generated by specifying the attack direction according to a reference text or image. Our work opens the door to applying adversarial attack to low-level vision tasks, and experiments on various conditional image generation tasks demonstrate the effectiveness and superiority of the proposed method.
ViTAR: Vision Transformer with Any Resolution
Mar 28, 2024This paper tackles a significant challenge faced by Vision Transformers (ViTs): their constrained scalability across different image resolutions. Typically, ViTs experience a performance decline when processing resolutions different from those seen during training. Our work introduces two key innovations to address this issue. Firstly, we propose a novel module for dynamic resolution adjustment, designed with a single Transformer block, specifically to achieve highly efficient incremental token integration. Secondly, we introduce fuzzy positional encoding in the Vision Transformer to provide consistent positional awareness across multiple resolutions, thereby preventing overfitting to any single training resolution. Our resulting model, ViTAR (Vision Transformer with Any Resolution), demonstrates impressive adaptability, achieving 83.3\% top-1 accuracy at a 1120x1120 resolution and 80.4\% accuracy at a 4032x4032 resolution, all while reducing computational costs. ViTAR also shows strong performance in downstream tasks such as instance and semantic segmentation and can easily combined with self-supervised learning techniques like Masked AutoEncoder. Our work provides a cost-effective solution for enhancing the resolution scalability of ViTs, paving the way for more versatile and efficient high-resolution image processing.
Plug-and-Play Grounding of Reasoning in Multimodal Large Language Models
Mar 28, 2024The surge of Multimodal Large Language Models (MLLMs), given their prominent emergent capabilities in instruction following and reasoning, has greatly advanced the field of visual reasoning. However, constrained by their non-lossless image tokenization, most MLLMs fall short of comprehensively capturing details of text and objects, especially in high-resolution images. To address this, we propose P2G, a novel framework for plug-and-play grounding of reasoning in MLLMs. Specifically, P2G exploits the tool-usage potential of MLLMs to employ expert agents to achieve on-the-fly grounding to critical visual and textual objects of image, thus achieving deliberate reasoning via multimodal prompting. We further create P2GB, a benchmark aimed at assessing MLLMs' ability to understand inter-object relationships and text in challenging high-resolution images. Comprehensive experiments on visual reasoning tasks demonstrate the superiority of P2G. Noteworthy, P2G achieved comparable performance with GPT-4V on P2GB, with a 7B backbone. Our work highlights the potential of plug-and-play grounding of reasoning and opens up a promising alternative beyond model scaling.
Shortcut Learning in Medical Image Segmentation
Mar 11, 2024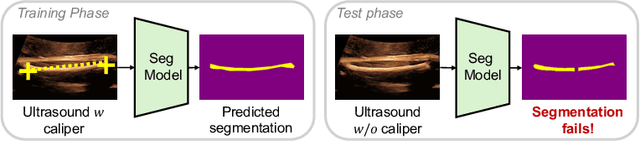

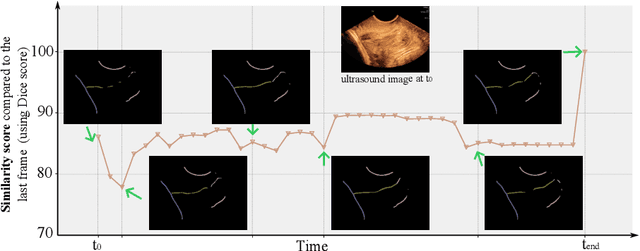

Shortcut learning is a phenomenon where machine learning models prioritize learning simple, potentially misleading cues from data that do not generalize well beyond the training set. While existing research primarily investigates this in the realm of image classification, this study extends the exploration of shortcut learning into medical image segmentation. We demonstrate that clinical annotations such as calipers, and the combination of zero-padded convolutions and center-cropped training sets in the dataset can inadvertently serve as shortcuts, impacting segmentation accuracy. We identify and evaluate the shortcut learning on two different but common medical image segmentation tasks. In addition, we suggest strategies to mitigate the influence of shortcut learning and improve the generalizability of the segmentation models. By uncovering the presence and implications of shortcuts in medical image segmentation, we provide insights and methodologies for evaluating and overcoming this pervasive challenge and call for attention in the community for shortcuts in segmentation.
Active Generation for Image Classification
Mar 11, 2024
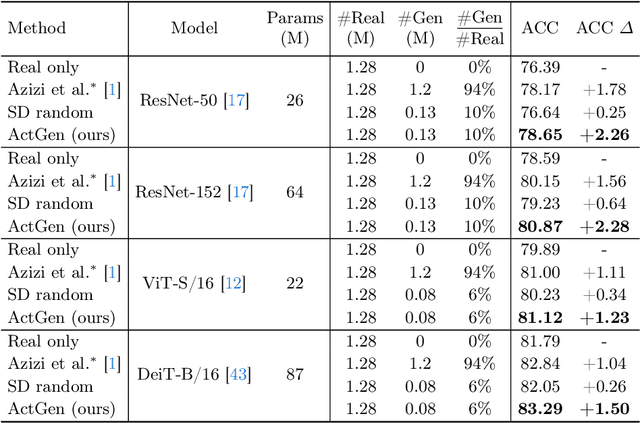

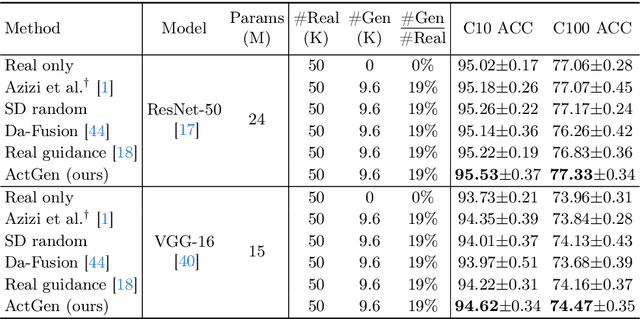
Recently, the growing capabilities of deep generative models have underscored their potential in enhancing image classification accuracy. However, existing methods often demand the generation of a disproportionately large number of images compared to the original dataset, while having only marginal improvements in accuracy. This computationally expensive and time-consuming process hampers the practicality of such approaches. In this paper, we propose to address the efficiency of image generation by focusing on the specific needs and characteristics of the model. With a central tenet of active learning, our method, named ActGen, takes a training-aware approach to image generation. It aims to create images akin to the challenging or misclassified samples encountered by the current model and incorporates these generated images into the training set to augment model performance. ActGen introduces an attentive image guidance technique, using real images as guides during the denoising process of a diffusion model. The model's attention on class prompt is leveraged to ensure the preservation of similar foreground object while diversifying the background. Furthermore, we introduce a gradient-based generation guidance method, which employs two losses to generate more challenging samples and prevent the generated images from being too similar to previously generated ones. Experimental results on the CIFAR and ImageNet datasets demonstrate that our method achieves better performance with a significantly reduced number of generated images.