 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
AWFSD: Accelerated Wirtinger Flow with Score-based Diffusion Image Prior for Poisson-Gaussian Holographic Phase Retrieval
May 12, 2023
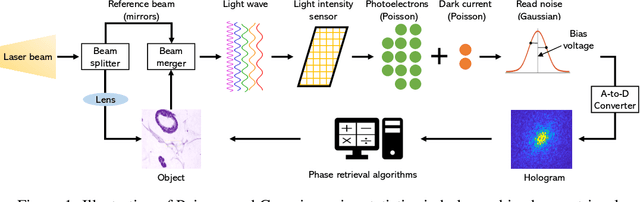

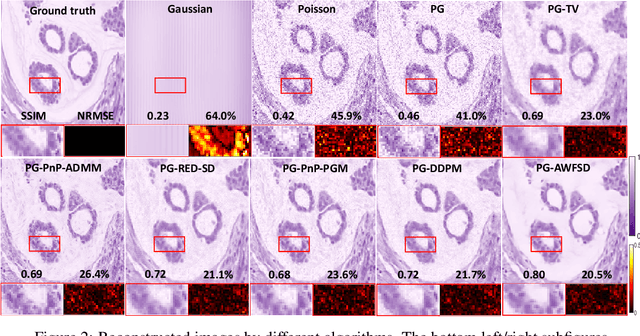
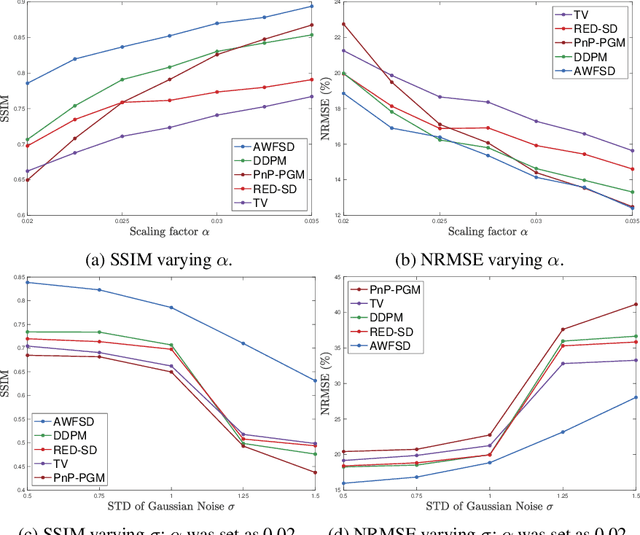
Phase retrieval (PR) is an essential problem in a number of coherent imaging systems. This work aims at resolving the holographic phase retrieval problem in real world scenarios where the measurements are corrupted by a mixture of Poisson and Gaussian (PG) noise that stems from optical imaging systems. To solve this problem, we develop a novel algorithm based on Accelerated Wirtinger Flow that uses Score-based Diffusion models as the generative prior (AWFSD). In particular, we frame the PR problem as an optimization task that involves both a data fidelity term and a regularization term. We derive the gradient of the PG log-likelihood function along with its corresponding Lipschitz constant, ensuring a more accurate data consistency term for practical measurements. We introduce a generative prior as part of our regularization approach by using a score-based diffusion model to capture (the gradient of) the image prior distribution. We provide theoretical analysis that establishes a critical-point convergence guarantee for the proposed AWFSD algorithm. Our simulation experiments demonstrate that: 1) The proposed algorithm based on the PG likelihood model enhances reconstruction compared to that solely based on either Gaussian or Poisson likelihood. 2) The proposed AWFSD algorithm produces reconstructions with higher image quality both qualitatively and quantitatively, and is more robust to variations in noise levels when compared with state-of-the-art methods for phase retrieval.
PKU-GoodsAD: A Supermarket Goods Dataset for Unsupervised Anomaly Detection and Segmentation
Jul 11, 2023

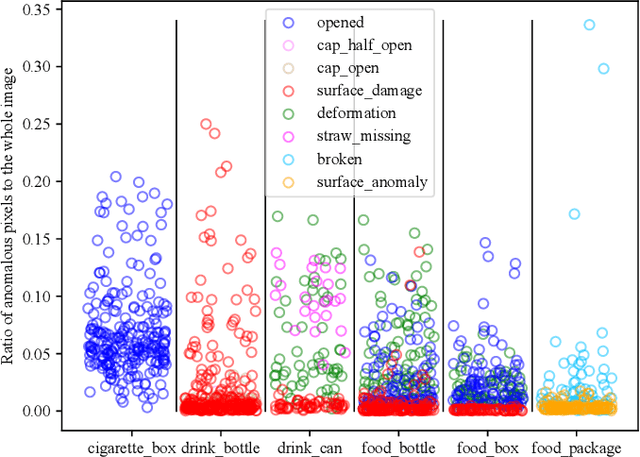
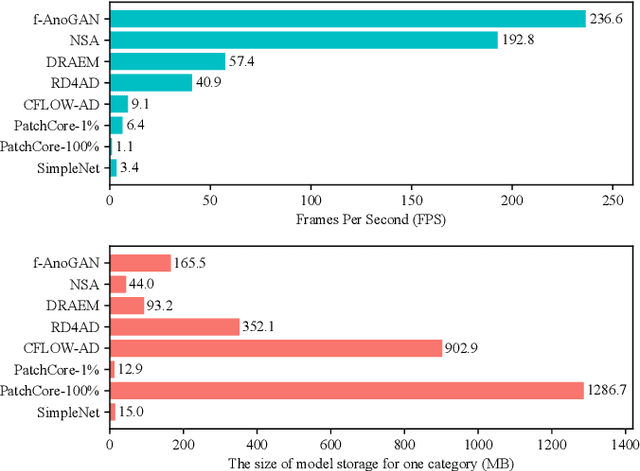
Visual anomaly detection is essential and commonly used for many tasks in the field of computer vision. Recent anomaly detection datasets mainly focus on industrial automated inspection, medical image analysis and video surveillance. In order to broaden the application and research of anomaly detection in unmanned supermarkets and smart manufacturing, we introduce the supermarket goods anomaly detection (GoodsAD) dataset. It contains 6124 high-resolution images of 484 different appearance goods divided into 6 categories. Each category contains several common different types of anomalies such as deformation, surface damage and opened. Anomalies contain both texture changes and structural changes. It follows the unsupervised setting and only normal (defect-free) images are used for training. Pixel-precise ground truth regions are provided for all anomalies. Moreover, we also conduct a thorough evaluation of current state-of-the-art unsupervised anomaly detection methods. This initial benchmark indicates that some methods which perform well on the industrial anomaly detection dataset (e.g., MVTec AD), show poor performance on our dataset. This is a comprehensive, multi-object dataset for supermarket goods anomaly detection that focuses on real-world applications.
MemeFier: Dual-stage Modality Fusion for Image Meme Classification
Apr 07, 2023
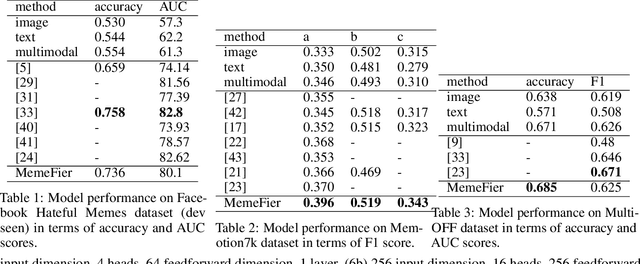
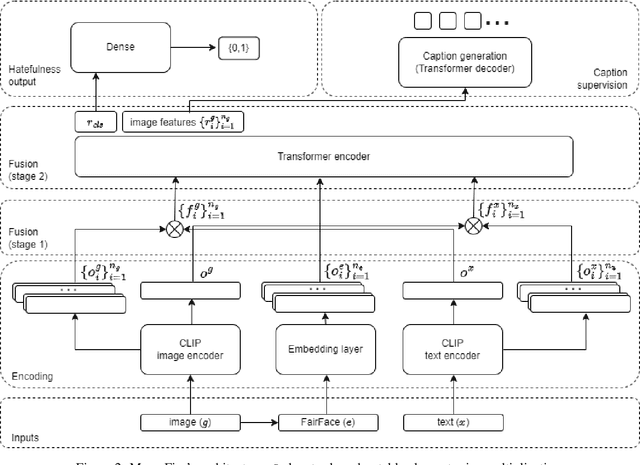

Hate speech is a societal problem that has significantly grown through the Internet. New forms of digital content such as image memes have given rise to spread of hate using multimodal means, being far more difficult to analyse and detect compared to the unimodal case. Accurate automatic processing, analysis and understanding of this kind of content will facilitate the endeavor of hindering hate speech proliferation through the digital world. To this end, we propose MemeFier, a deep learning-based architecture for fine-grained classification of Internet image memes, utilizing a dual-stage modality fusion module. The first fusion stage produces feature vectors containing modality alignment information that captures non-trivial connections between the text and image of a meme. The second fusion stage leverages the power of a Transformer encoder to learn inter-modality correlations at the token level and yield an informative representation. Additionally, we consider external knowledge as an additional input, and background image caption supervision as a regularizing component. Extensive experiments on three widely adopted benchmarks, i.e., Facebook Hateful Memes, Memotion7k and MultiOFF, indicate that our approach competes and in some cases surpasses state-of-the-art. Our code is available on https://github.com/ckoutlis/memefier.
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Jul 17, 2023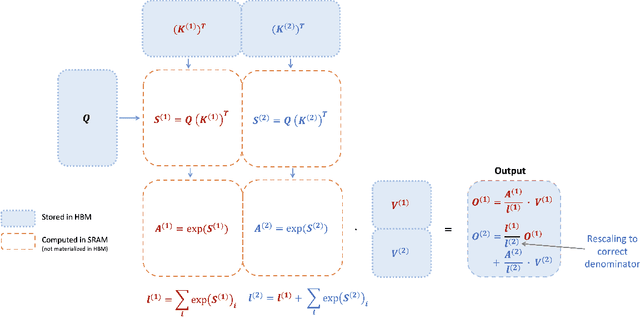
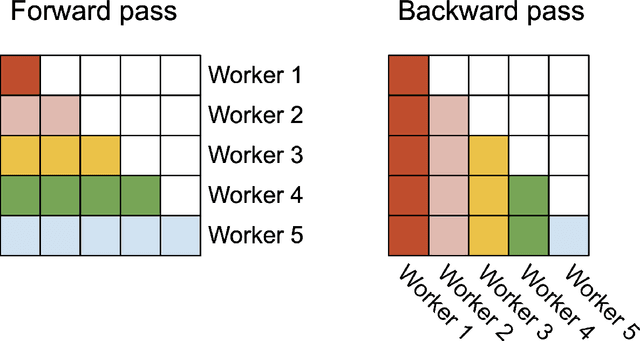
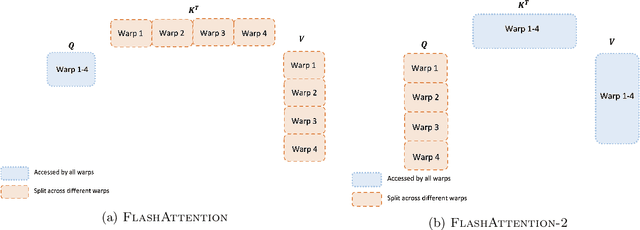

Scaling Transformers to longer sequence lengths has been a major problem in the last several years, promising to improve performance in language modeling and high-resolution image understanding, as well as to unlock new applications in code, audio, and video generation. The attention layer is the main bottleneck in scaling to longer sequences, as its runtime and memory increase quadratically in the sequence length. FlashAttention exploits the asymmetric GPU memory hierarchy to bring significant memory saving (linear instead of quadratic) and runtime speedup (2-4$\times$ compared to optimized baselines), with no approximation. However, FlashAttention is still not nearly as fast as optimized matrix-multiply (GEMM) operations, reaching only 25-40\% of the theoretical maximum FLOPs/s. We observe that the inefficiency is due to suboptimal work partitioning between different thread blocks and warps on the GPU, causing either low-occupancy or unnecessary shared memory reads/writes. We propose FlashAttention-2, with better work partitioning to address these issues. In particular, we (1) tweak the algorithm to reduce the number of non-matmul FLOPs (2) parallelize the attention computation, even for a single head, across different thread blocks to increase occupancy, and (3) within each thread block, distribute the work between warps to reduce communication through shared memory. These yield around 2$\times$ speedup compared to FlashAttention, reaching 50-73\% of the theoretical maximum FLOPs/s on A100 and getting close to the efficiency of GEMM operations. We empirically validate that when used end-to-end to train GPT-style models, FlashAttention-2 reaches training speed of up to 225 TFLOPs/s per A100 GPU (72\% model FLOPs utilization).
New Adversarial Image Detection Based on Sentiment Analysis
May 03, 2023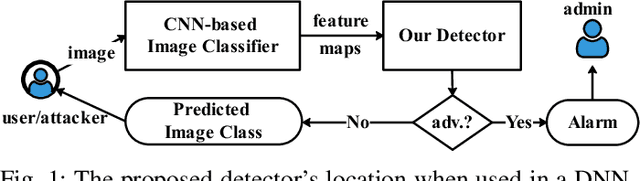
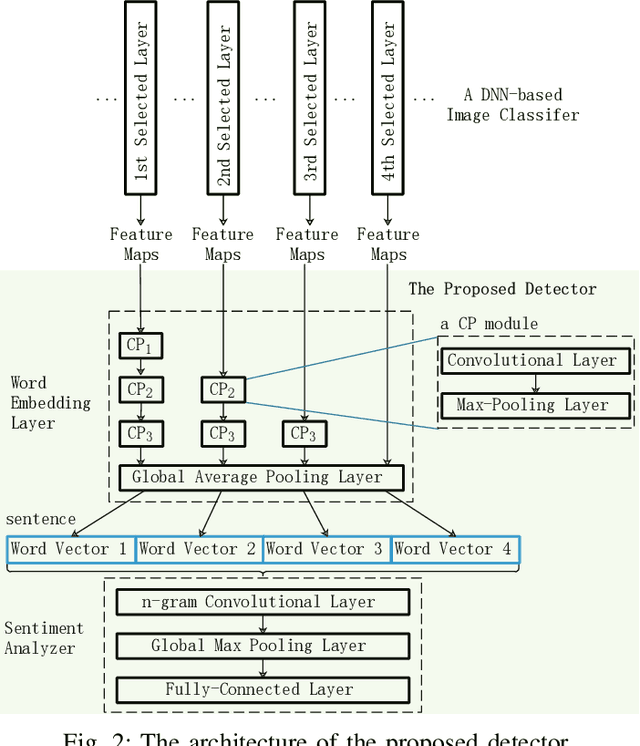
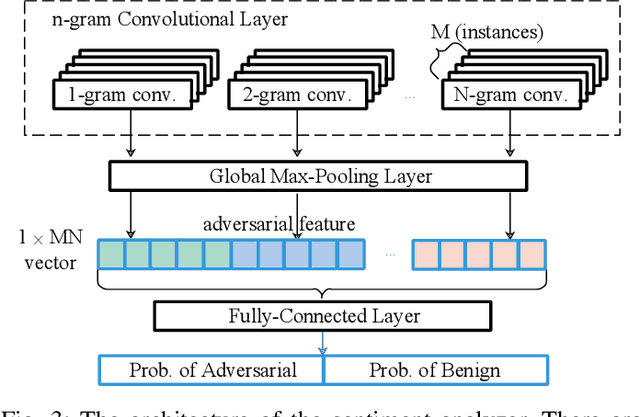

Deep Neural Networks (DNNs) are vulnerable to adversarial examples, while adversarial attack models, e.g., DeepFool, are on the rise and outrunning adversarial example detection techniques. This paper presents a new adversarial example detector that outperforms state-of-the-art detectors in identifying the latest adversarial attacks on image datasets. Specifically, we propose to use sentiment analysis for adversarial example detection, qualified by the progressively manifesting impact of an adversarial perturbation on the hidden-layer feature maps of a DNN under attack. Accordingly, we design a modularized embedding layer with the minimum learnable parameters to embed the hidden-layer feature maps into word vectors and assemble sentences ready for sentiment analysis. Extensive experiments demonstrate that the new detector consistently surpasses the state-of-the-art detection algorithms in detecting the latest attacks launched against ResNet and Inception neutral networks on the CIFAR-10, CIFAR-100 and SVHN datasets. The detector only has about 2 million parameters, and takes shorter than 4.6 milliseconds to detect an adversarial example generated by the latest attack models using a Tesla K80 GPU card.
Causal Image Synthesis of Brain MR in 3D
Mar 25, 2023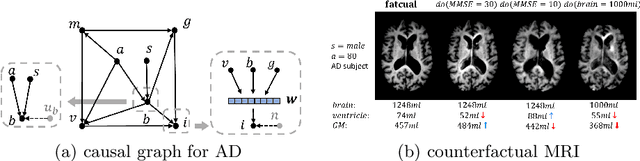

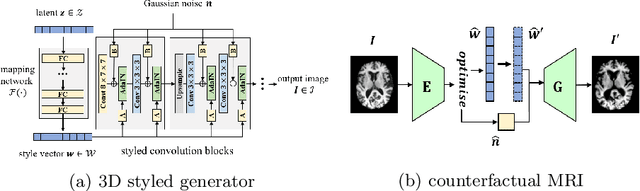

Clinical decision making requires counterfactual reasoning based on a factual medical image and thus necessitates causal image synthesis. To this end, we present a novel method for modeling the causality between demographic variables, clinical indices and brain MR images for Alzheimer's Diseases. Specifically, we leverage a structural causal model to depict the causality and a styled generator to synthesize the image. Furthermore, as a crucial step to reduce modeling complexity and make learning tractable, we propose the use of low dimensional latent feature representation of a high-dimensional 3D image, together with exogenous noise, to build causal relationship between the image and non image variables. We experiment the proposed method based on 1586 subjects and 3683 3D images and synthesize counterfactual brain MR images intervened on certain attributes, such as age, brain volume and cognitive test score. Quantitative metrics and qualitative evaluation of counterfactual images demonstrates the superiority of our generated images.
INR-MDSQC: Implicit Neural Representation Multiple Description Scalar Quantization for robust image Coding
Jun 24, 2023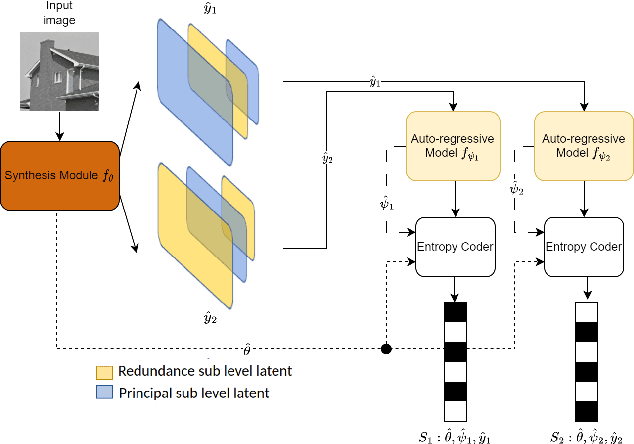
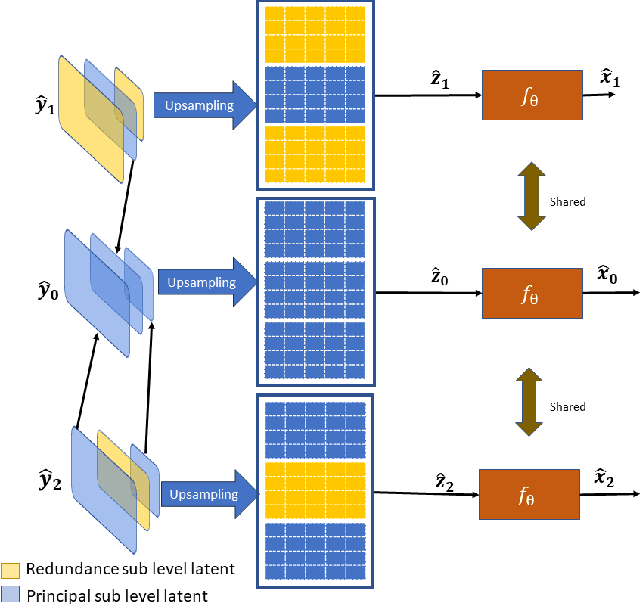
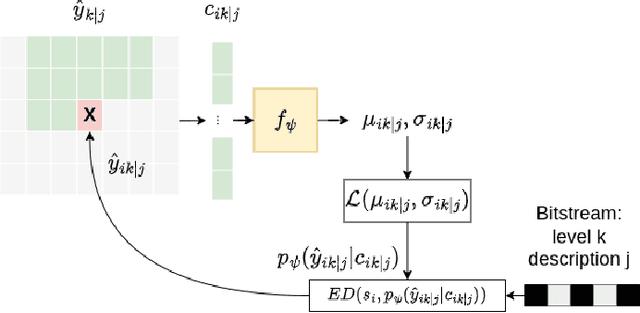
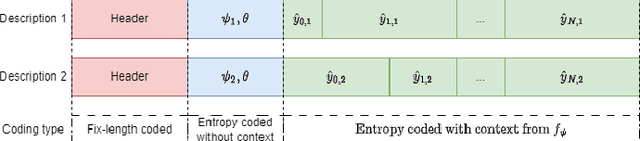
Multiple Description Coding (MDC) is an error-resilient source coding method designed for transmission over noisy channels. We present a novel MDC scheme employing a neural network based on implicit neural representation. This involves overfitting the neural representation for images. Each description is transmitted along with model parameters and its respective latent spaces. Our method has advantages over traditional MDC that utilizes auto-encoders, such as eliminating the need for model training and offering high flexibility in redundancy adjustment. Experiments demonstrate that our solution is competitive with autoencoder-based MDC and classic MDC based on HEVC, delivering superior visual quality.
Grain and Grain Boundary Segmentation using Machine Learning with Real and Generated Datasets
Jul 12, 2023

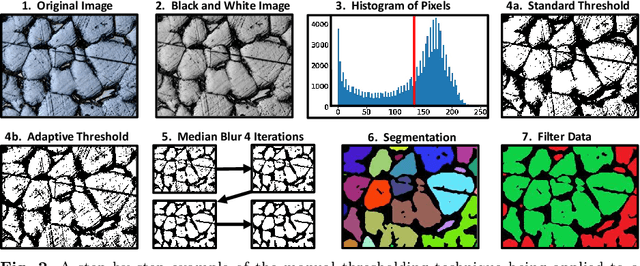
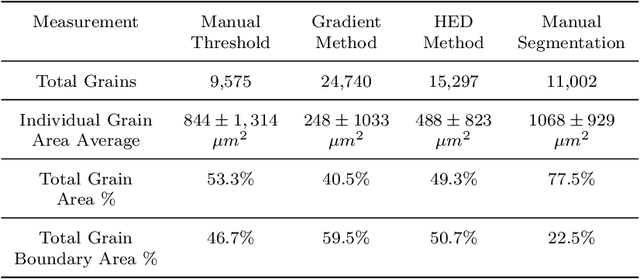
We report significantly improved accuracy of grain boundary segmentation using Convolutional Neural Networks (CNN) trained on a combination of real and generated data. Manual segmentation is accurate but time-consuming, and existing computational methods are faster but often inaccurate. To combat this dilemma, machine learning models can be used to achieve the accuracy of manual segmentation and have the efficiency of a computational method. An extensive dataset of from 316L stainless steel samples is additively manufactured, prepared, polished, etched, and then microstructure grain images were systematically collected. Grain segmentation via existing computational methods and manual (by-hand) were conducted, to create "real" training data. A Voronoi tessellation pattern combined with random synthetic noise and simulated defects, is developed to create a novel artificial grain image fabrication method. This provided training data supplementation for data-intensive machine learning methods. The accuracy of the grain measurements from microstructure images segmented via computational methods and machine learning methods proposed in this work are calculated and compared to provide much benchmarks in grain segmentation. Over 400 images of the microstructure of stainless steel samples were manually segmented for machine learning training applications. This data and the artificial data is available on Kaggle.
Test-Time Training on Video Streams
Jul 12, 2023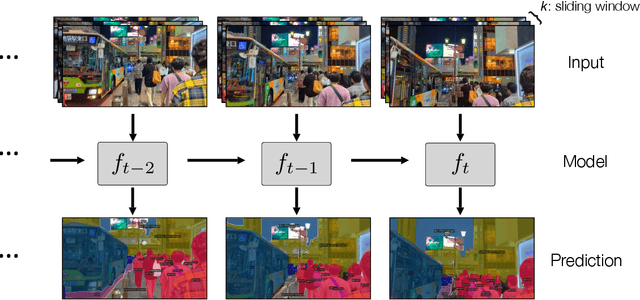
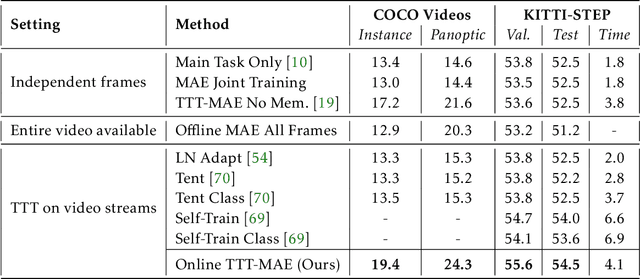
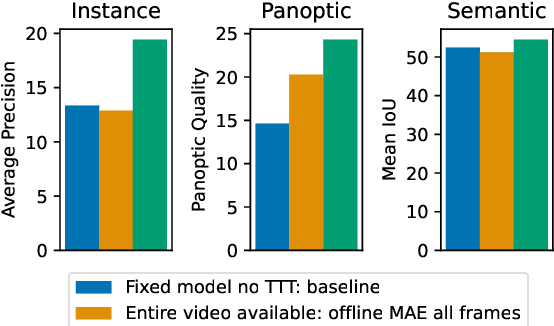
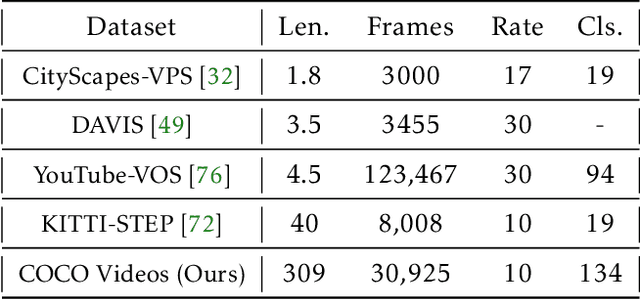
Prior work has established test-time training (TTT) as a general framework to further improve a trained model at test time. Before making a prediction on each test instance, the model is trained on the same instance using a self-supervised task, such as image reconstruction with masked autoencoders. We extend TTT to the streaming setting, where multiple test instances - video frames in our case - arrive in temporal order. Our extension is online TTT: The current model is initialized from the previous model, then trained on the current frame and a small window of frames immediately before. Online TTT significantly outperforms the fixed-model baseline for four tasks, on three real-world datasets. The relative improvement is 45% and 66% for instance and panoptic segmentation. Surprisingly, online TTT also outperforms its offline variant that accesses more information, training on all frames from the entire test video regardless of temporal order. This differs from previous findings using synthetic videos. We conceptualize locality as the advantage of online over offline TTT. We analyze the role of locality with ablations and a theory based on bias-variance trade-off.
Discovering a reaction-diffusion model for Alzheimer's disease by combining PINNs with symbolic regression
Jul 16, 2023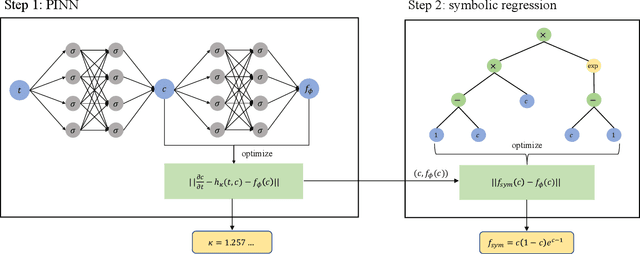

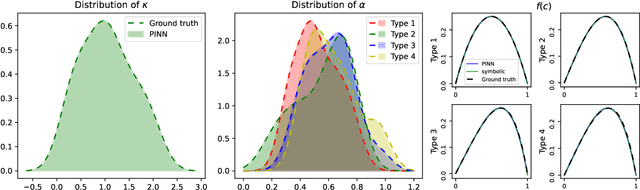
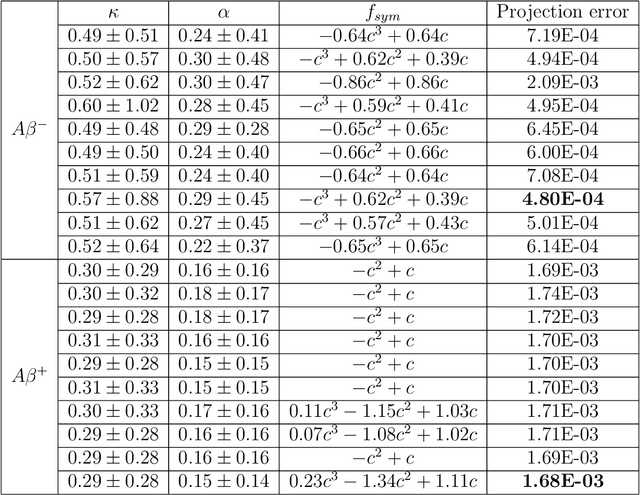
Misfolded tau proteins play a critical role in the progression and pathology of Alzheimer's disease. Recent studies suggest that the spatio-temporal pattern of misfolded tau follows a reaction-diffusion type equation. However, the precise mathematical model and parameters that characterize the progression of misfolded protein across the brain remain incompletely understood. Here, we use deep learning and artificial intelligence to discover a mathematical model for the progression of Alzheimer's disease using longitudinal tau positron emission tomography from the Alzheimer's Disease Neuroimaging Initiative database. Specifically, we integrate physics informed neural networks (PINNs) and symbolic regression to discover a reaction-diffusion type partial differential equation for tau protein misfolding and spreading. First, we demonstrate the potential of our model and parameter discovery on synthetic data. Then, we apply our method to discover the best model and parameters to explain tau imaging data from 46 individuals who are likely to develop Alzheimer's disease and 30 healthy controls. Our symbolic regression discovers different misfolding models $f(c)$ for two groups, with a faster misfolding for the Alzheimer's group, $f(c) = 0.23c^3 - 1.34c^2 + 1.11c$, than for the healthy control group, $f(c) = -c^3 +0.62c^2 + 0.39c$. Our results suggest that PINNs, supplemented by symbolic regression, can discover a reaction-diffusion type model to explain misfolded tau protein concentrations in Alzheimer's disease. We expect our study to be the starting point for a more holistic analysis to provide image-based technologies for early diagnosis, and ideally early treatment of neurodegeneration in Alzheimer's disease and possibly other misfolding-protein based neurodegenerative disorders.