 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Local Conditional Neural Fields for Versatile and Generalizable Large-Scale Reconstructions in Computational Imaging
Jul 22, 2023
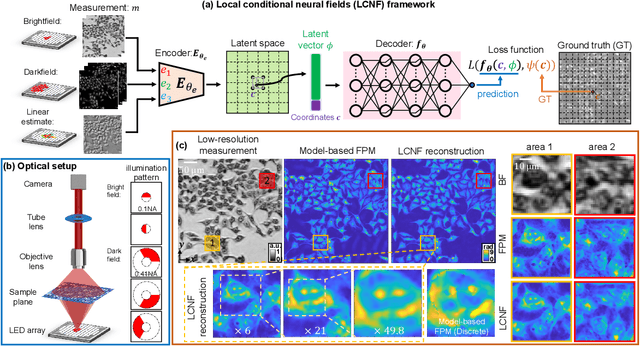
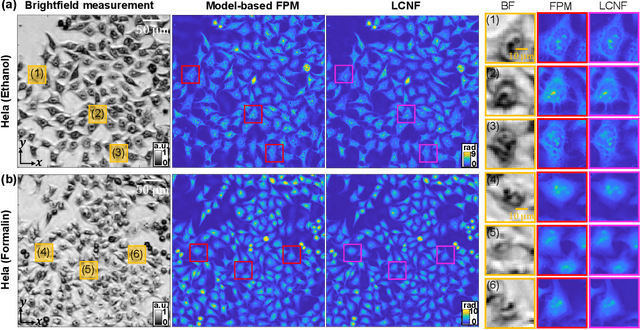
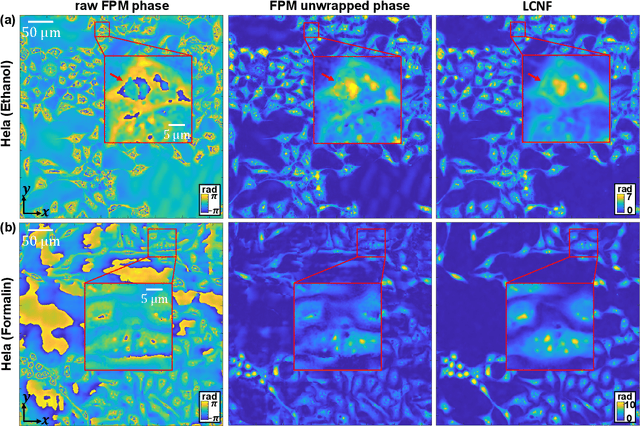
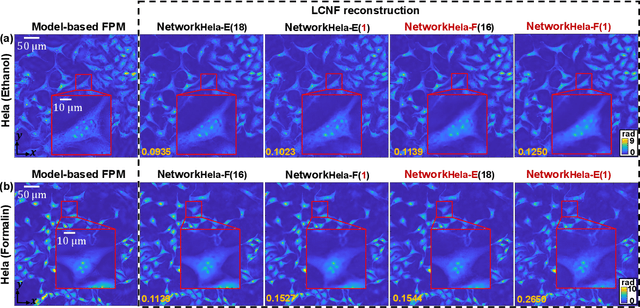
Deep learning has transformed computational imaging, but traditional pixel-based representations limit their ability to capture continuous, multiscale details of objects. Here we introduce a novel Local Conditional Neural Fields (LCNF) framework, leveraging a continuous implicit neural representation to address this limitation. LCNF enables flexible object representation and facilitates the reconstruction of multiscale information. We demonstrate the capabilities of LCNF in solving the highly ill-posed inverse problem in Fourier ptychographic microscopy (FPM) with multiplexed measurements, achieving robust, scalable, and generalizable large-scale phase retrieval. Unlike traditional neural fields frameworks, LCNF incorporates a local conditional representation that promotes model generalization, learning multiscale information, and efficient processing of large-scale imaging data. By combining an encoder and a decoder conditioned on a learned latent vector, LCNF achieves versatile continuous-domain super-resolution image reconstruction. We demonstrate accurate reconstruction of wide field-of-view, high-resolution phase images using only a few multiplexed measurements. LCNF robustly captures the continuous object priors and eliminates various phase artifacts, even when it is trained on imperfect datasets. The framework exhibits strong generalization, reconstructing diverse objects even with limited training data. Furthermore, LCNF can be trained on a physics simulator using natural images and successfully applied to experimental measurements on biological samples. Our results highlight the potential of LCNF for solving large-scale inverse problems in computational imaging, with broad applicability in various deep-learning-based techniques.
Spherical Feature Pyramid Networks For Semantic Segmentation
Jul 05, 2023
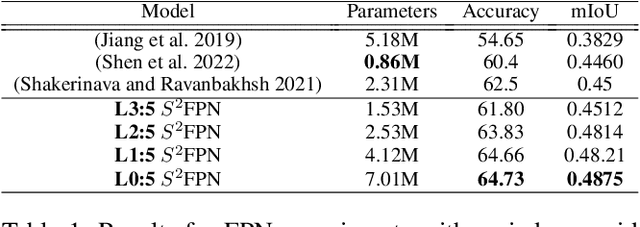
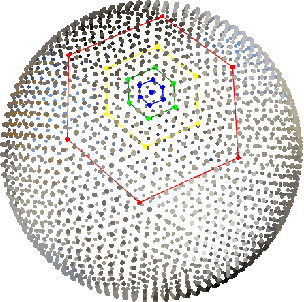

Semantic segmentation for spherical data is a challenging problem in machine learning since conventional planar approaches require projecting the spherical image to the Euclidean plane. Representing the signal on a fundamentally different topology introduces edges and distortions which impact network performance. Recently, graph-based approaches have bypassed these challenges to attain significant improvements by representing the signal on a spherical mesh. Current approaches to spherical segmentation exclusively use variants of the UNet architecture, meaning more successful planar architectures remain unexplored. Inspired by the success of feature pyramid networks (FPNs) in planar image segmentation, we leverage the pyramidal hierarchy of graph-based spherical CNNs to design spherical FPNs. Our spherical FPN models show consistent improvements over spherical UNets, whilst using fewer parameters. On the Stanford 2D-3D-S dataset, our models achieve state-of-the-art performance with an mIOU of 48.75, an improvement of 3.75 IoU points over the previous best spherical CNN.
Vision Transformer for Efficient Chest X-ray and Gastrointestinal Image Classification
Apr 23, 2023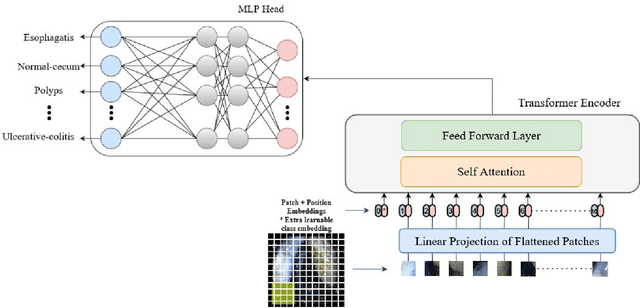
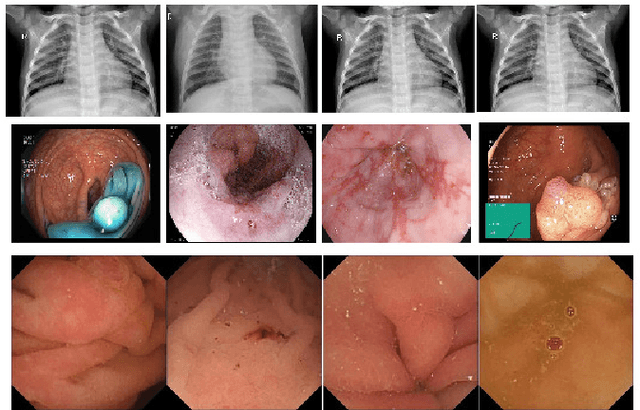
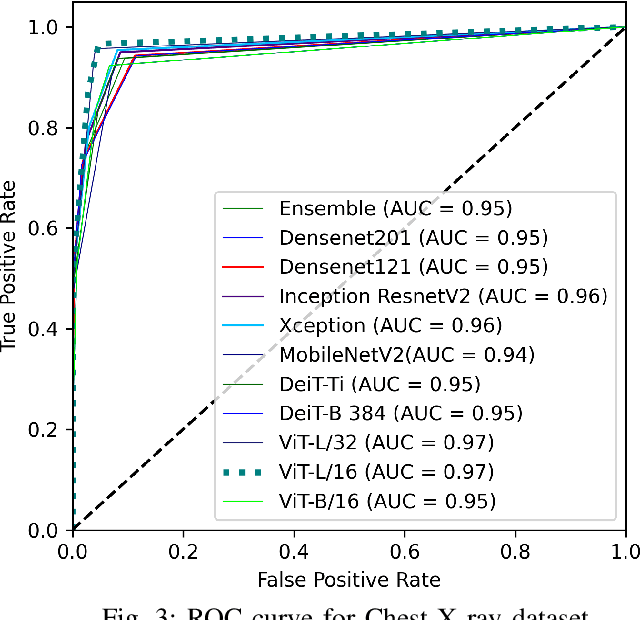
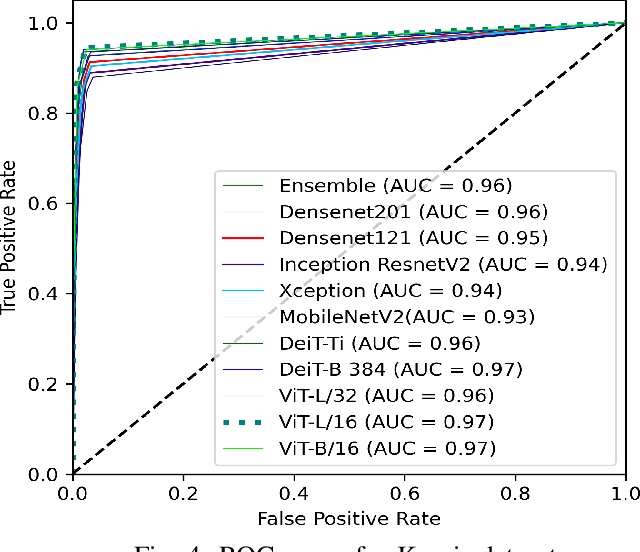
Medical image analysis is a hot research topic because of its usefulness in different clinical applications, such as early disease diagnosis and treatment. Convolutional neural networks (CNNs) have become the de-facto standard in medical image analysis tasks because of their ability to learn complex features from the available datasets, which makes them surpass humans in many image-understanding tasks. In addition to CNNs, transformer architectures also have gained popularity for medical image analysis tasks. However, despite progress in the field, there are still potential areas for improvement. This study uses different CNNs and transformer-based methods with a wide range of data augmentation techniques. We evaluated their performance on three medical image datasets from different modalities. We evaluated and compared the performance of the vision transformer model with other state-of-the-art (SOTA) pre-trained CNN networks. For Chest X-ray, our vision transformer model achieved the highest F1 score of 0.9532, recall of 0.9533, Matthews correlation coefficient (MCC) of 0.9259, and ROC-AUC score of 0.97. Similarly, for the Kvasir dataset, we achieved an F1 score of 0.9436, recall of 0.9437, MCC of 0.9360, and ROC-AUC score of 0.97. For the Kvasir-Capsule (a large-scale VCE dataset), our ViT model achieved a weighted F1-score of 0.7156, recall of 0.7182, MCC of 0.3705, and ROC-AUC score of 0.57. We found that our transformer-based models were better or more effective than various CNN models for classifying different anatomical structures, findings, and abnormalities. Our model showed improvement over the CNN-based approaches and suggests that it could be used as a new benchmarking algorithm for algorithm development.
Attention Hybrid Variational Net for Accelerated MRI Reconstruction
Jun 21, 2023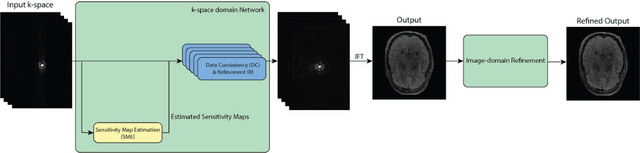
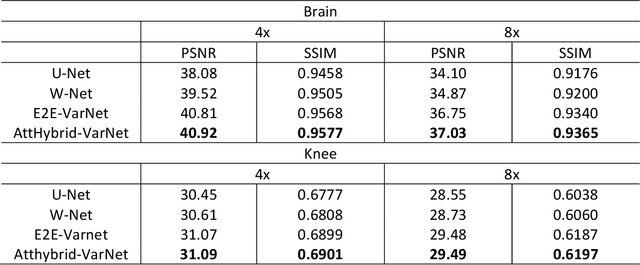
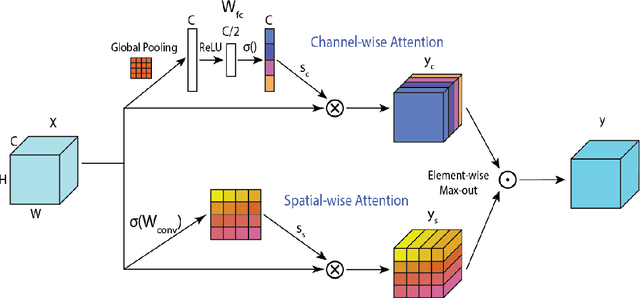
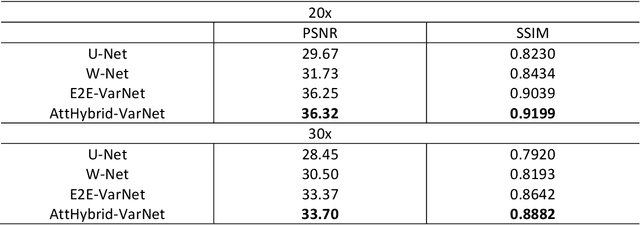
The application of compressed sensing (CS)-enabled data reconstruction for accelerating magnetic resonance imaging (MRI) remains a challenging problem. This is due to the fact that the information lost in k-space from the acceleration mask makes it difficult to reconstruct an image similar to the quality of a fully sampled image. Multiple deep learning-based structures have been proposed for MRI reconstruction using CS, both in the k-space and image domains as well as using unrolled optimization methods. However, the drawback of these structures is that they are not fully utilizing the information from both domains (k-space and image). Herein, we propose a deep learning-based attention hybrid variational network that performs learning in both the k-space and image domain. We evaluate our method on a well-known open-source MRI dataset and a clinical MRI dataset of patients diagnosed with strokes from our institution to demonstrate the performance of our network. In addition to quantitative evaluation, we undertook a blinded comparison of image quality across networks performed by a subspecialty trained radiologist. Overall, we demonstrate that our network achieves a superior performance among others under multiple reconstruction tasks.
Improving NeRF with Height Data for Utilization of GIS Data
Jul 15, 2023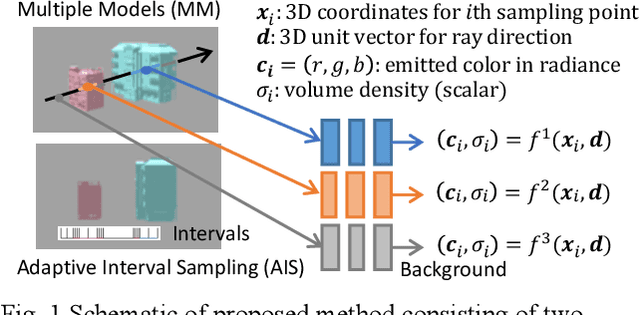
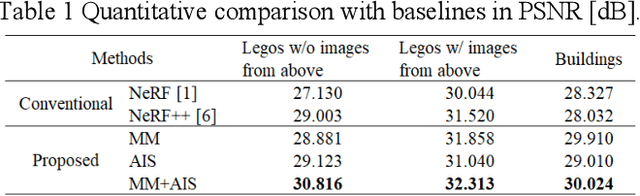
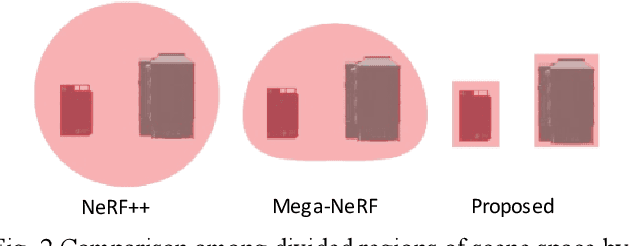
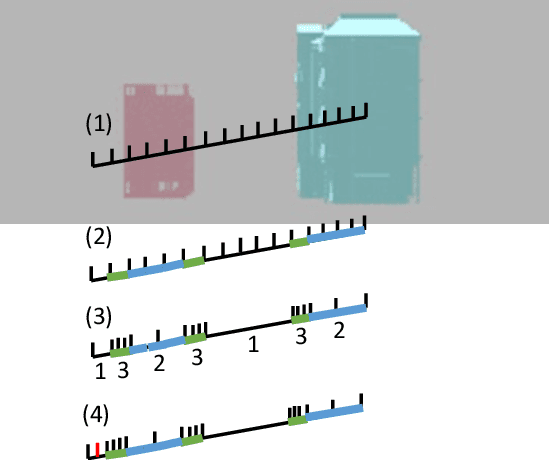
Neural Radiance Fields (NeRF) has been applied to various tasks related to representations of 3D scenes. Most studies based on NeRF have focused on a small object, while a few studies have tried to reconstruct large-scale scenes although these methods tend to require large computational cost. For the application of NeRF to large-scale scenes, a method based on NeRF is proposed in this paper to effectively use height data which can be obtained from GIS (Geographic Information System). For this purpose, the scene space was divided into multiple objects and a background using the height data to represent them with separate neural networks. In addition, an adaptive sampling method is also proposed by using the height data. As a result, the accuracy of image rendering was improved with faster training speed.
Keyword-Based Diverse Image Retrieval by Semantics-aware Contrastive Learning and Transformer
May 06, 2023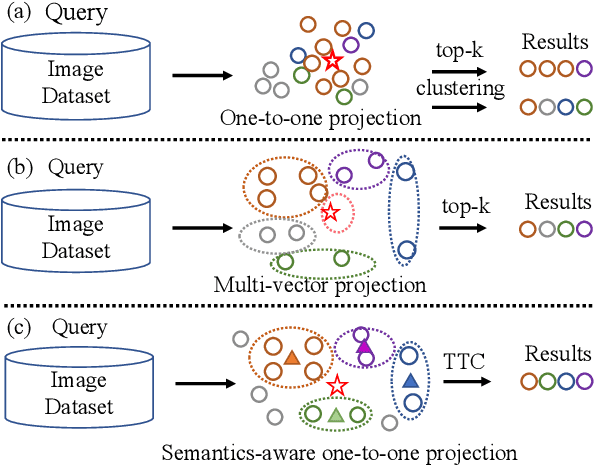


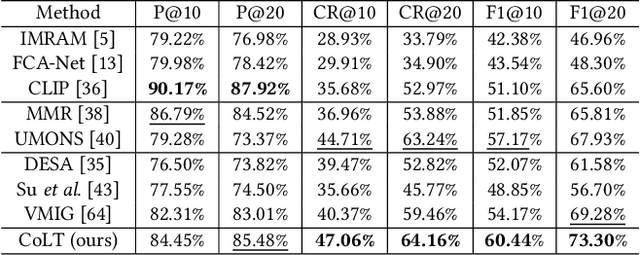
In addition to relevance, diversity is an important yet less studied performance metric of cross-modal image retrieval systems, which is critical to user experience. Existing solutions for diversity-aware image retrieval either explicitly post-process the raw retrieval results from standard retrieval systems or try to learn multi-vector representations of images to represent their diverse semantics. However, neither of them is good enough to balance relevance and diversity. On the one hand, standard retrieval systems are usually biased to common semantics and seldom exploit diversity-aware regularization in training, which makes it difficult to promote diversity by post-processing. On the other hand, multi-vector representation methods are not guaranteed to learn robust multiple projections. As a result, irrelevant images and images of rare or unique semantics may be projected inappropriately, which degrades the relevance and diversity of the results generated by some typical algorithms like top-k. To cope with these problems, this paper presents a new method called CoLT that tries to generate much more representative and robust representations for accurately classifying images. Specifically, CoLT first extracts semantics-aware image features by enhancing the preliminary representations of an existing one-to-one cross-modal system with semantics-aware contrastive learning. Then, a transformer-based token classifier is developed to subsume all the features into their corresponding categories. Finally, a post-processing algorithm is designed to retrieve images from each category to form the final retrieval result. Extensive experiments on two real-world datasets Div400 and Div150Cred show that CoLT can effectively boost diversity, and outperforms the existing methods as a whole (with a higher F1 score).
Exploiting Diffusion Prior for Real-World Image Super-Resolution
May 11, 2023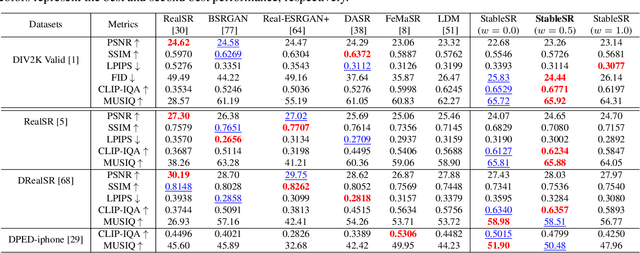
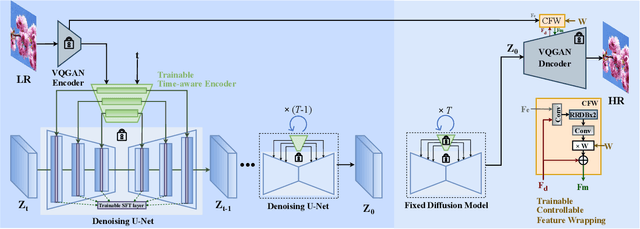
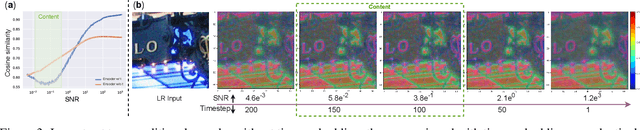

We present a novel approach to leverage prior knowledge encapsulated in pre-trained text-to-image diffusion models for blind super-resolution (SR). Specifically, by employing our time-aware encoder, we can achieve promising restoration results without altering the pre-trained synthesis model, thereby preserving the generative prior and minimizing training cost. To remedy the loss of fidelity caused by the inherent stochasticity of diffusion models, we introduce a controllable feature wrapping module that allows users to balance quality and fidelity by simply adjusting a scalar value during the inference process. Moreover, we develop a progressive aggregation sampling strategy to overcome the fixed-size constraints of pre-trained diffusion models, enabling adaptation to resolutions of any size. A comprehensive evaluation of our method using both synthetic and real-world benchmarks demonstrates its superiority over current state-of-the-art approaches.
Cutting-Edge Techniques for Depth Map Super-Resolution
Jun 27, 2023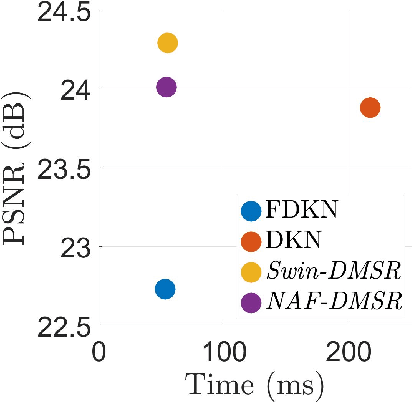

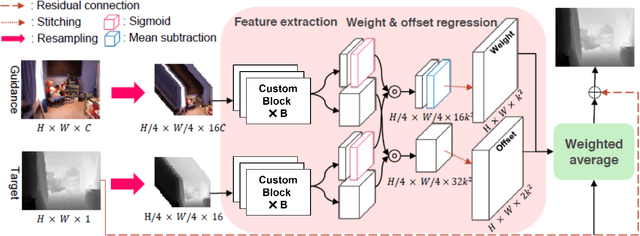
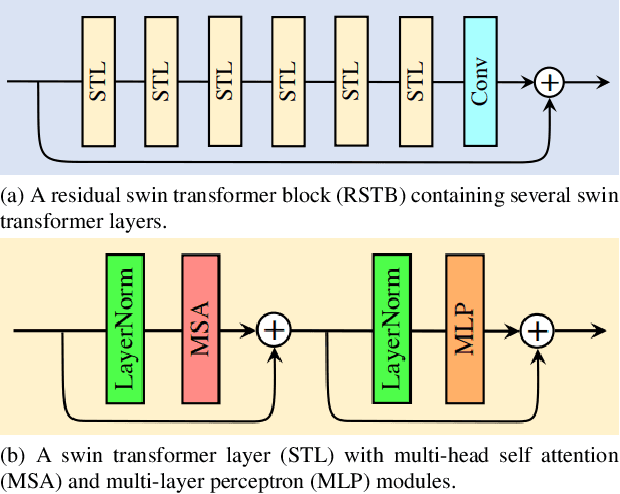
To overcome hardware limitations in commercially available depth sensors which result in low-resolution depth maps, depth map super-resolution (DMSR) is a practical and valuable computer vision task. DMSR requires upscaling a low-resolution (LR) depth map into a high-resolution (HR) space. Joint image filtering for DMSR has been applied using spatially-invariant and spatially-variant convolutional neural network (CNN) approaches. In this project, we propose a novel joint image filtering DMSR algorithm using a Swin transformer architecture. Furthermore, we introduce a Nonlinear Activation Free (NAF) network based on a conventional CNN model used in cutting-edge image restoration applications and compare the performance of the techniques. The proposed algorithms are validated through numerical studies and visual examples demonstrating improvements to state-of-the-art performance while maintaining competitive computation time for noisy depth map super-resolution.
Deficiency-Aware Masked Transformer for Video Inpainting
Jul 17, 2023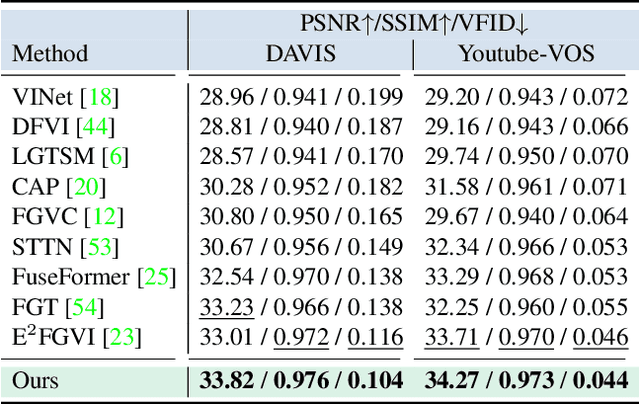
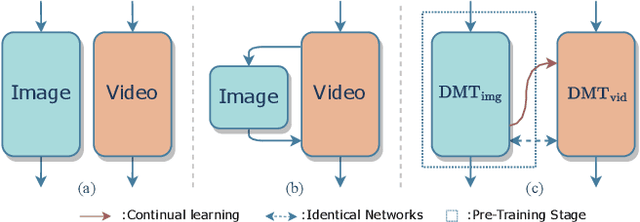
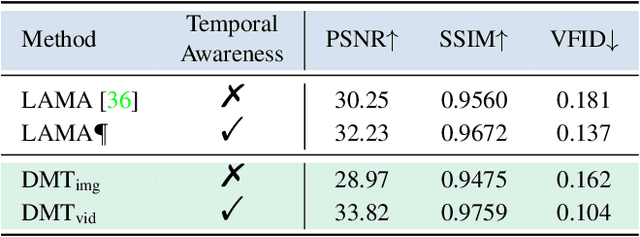
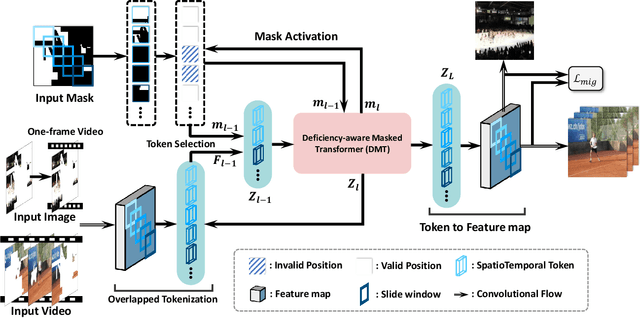
Recent video inpainting methods have made remarkable progress by utilizing explicit guidance, such as optical flow, to propagate cross-frame pixels. However, there are cases where cross-frame recurrence of the masked video is not available, resulting in a deficiency. In such situation, instead of borrowing pixels from other frames, the focus of the model shifts towards addressing the inverse problem. In this paper, we introduce a dual-modality-compatible inpainting framework called Deficiency-aware Masked Transformer (DMT), which offers three key advantages. Firstly, we pretrain a image inpainting model DMT_img serve as a prior for distilling the video model DMT_vid, thereby benefiting the hallucination of deficiency cases. Secondly, the self-attention module selectively incorporates spatiotemporal tokens to accelerate inference and remove noise signals. Thirdly, a simple yet effective Receptive Field Contextualizer is integrated into DMT, further improving performance. Extensive experiments conducted on YouTube-VOS and DAVIS datasets demonstrate that DMT_vid significantly outperforms previous solutions. The code and video demonstrations can be found at github.com/yeates/DMT.
Fast model inference and training on-board of Satellites
Jul 17, 2023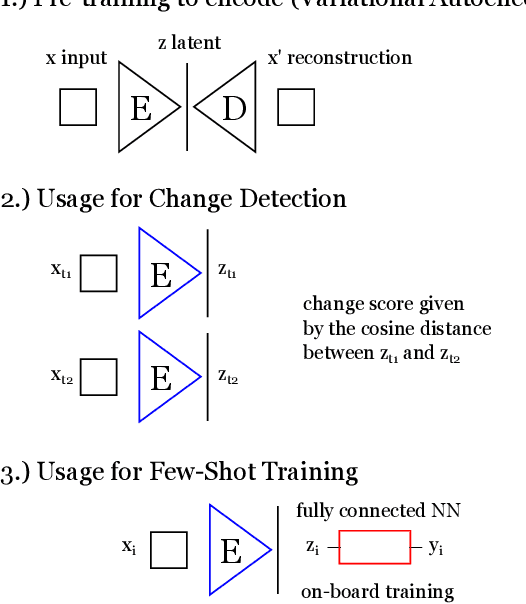
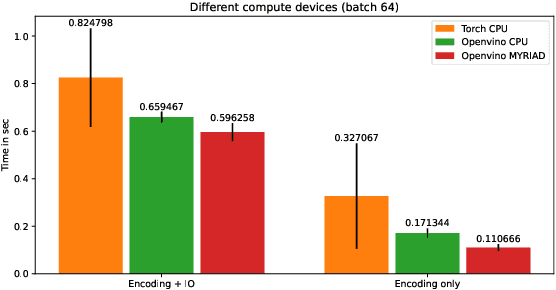
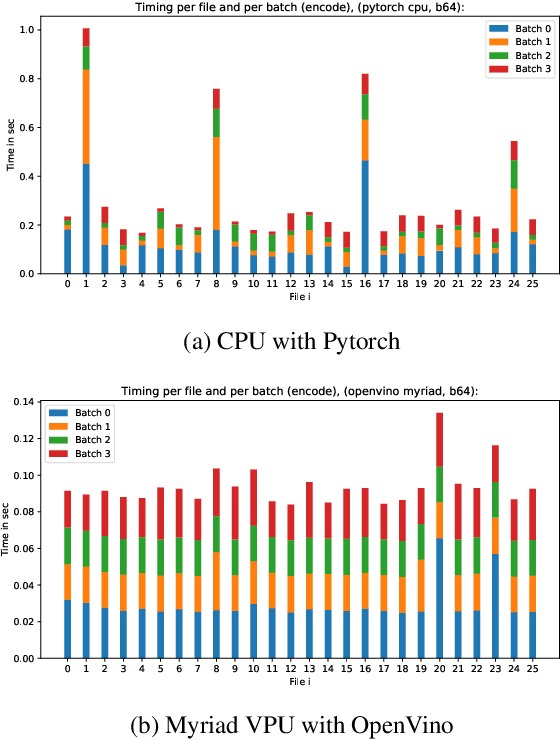
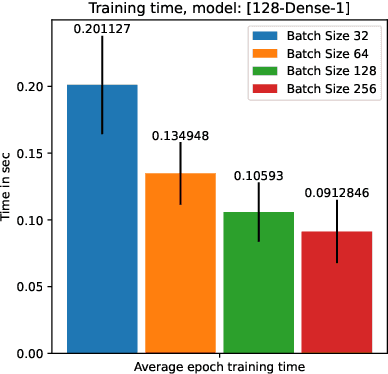
Artificial intelligence onboard satellites has the potential to reduce data transmission requirements, enable real-time decision-making and collaboration within constellations. This study deploys a lightweight foundational model called RaVAEn on D-Orbit's ION SCV004 satellite. RaVAEn is a variational auto-encoder (VAE) that generates compressed latent vectors from small image tiles, enabling several downstream tasks. In this work we demonstrate the reliable use of RaVAEn onboard a satellite, achieving an encoding time of 0.110s for tiles of a 4.8x4.8 km$^2$ area. In addition, we showcase fast few-shot training onboard a satellite using the latent representation of data. We compare the deployment of the model on the on-board CPU and on the available Myriad vision processing unit (VPU) accelerator. To our knowledge, this work shows for the first time the deployment of a multi-task model on-board a CubeSat and the on-board training of a machine learning model.