 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Two Birds, One Stone: A Unified Framework for Joint Learning of Image and Video Style Transfers
Apr 22, 2023
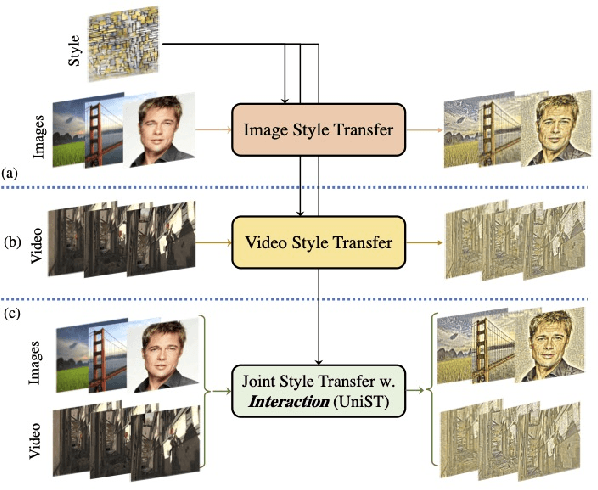

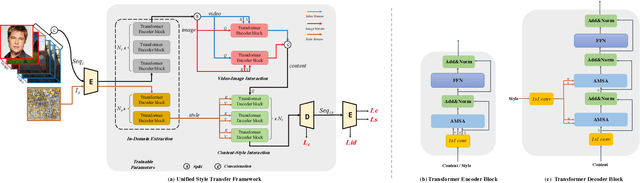
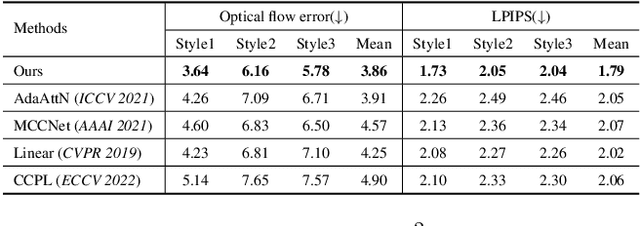
Current arbitrary style transfer models are limited to either image or video domains. In order to achieve satisfying image and video style transfers, two different models are inevitably required with separate training processes on image and video domains, respectively. In this paper, we show that this can be precluded by introducing UniST, a Unified Style Transfer framework for both images and videos. At the core of UniST is a domain interaction transformer (DIT), which first explores context information within the specific domain and then interacts contextualized domain information for joint learning. In particular, DIT enables exploration of temporal information from videos for the image style transfer task and meanwhile allows rich appearance texture from images for video style transfer, thus leading to mutual benefits. Considering heavy computation of traditional multi-head self-attention, we present a simple yet effective axial multi-head self-attention (AMSA) for DIT, which improves computational efficiency while maintains style transfer performance. To verify the effectiveness of UniST, we conduct extensive experiments on both image and video style transfer tasks and show that UniST performs favorably against state-of-the-art approaches on both tasks. Our code and results will be released.
Causal Image Synthesis of Brain MR in 3D
Mar 25, 2023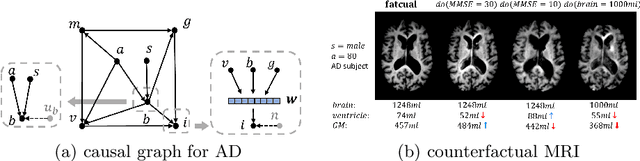

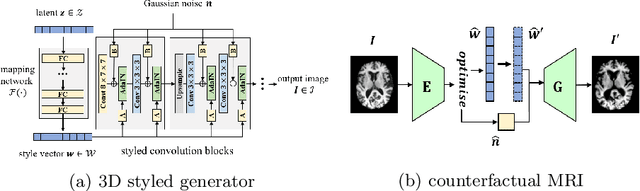

Clinical decision making requires counterfactual reasoning based on a factual medical image and thus necessitates causal image synthesis. To this end, we present a novel method for modeling the causality between demographic variables, clinical indices and brain MR images for Alzheimer's Diseases. Specifically, we leverage a structural causal model to depict the causality and a styled generator to synthesize the image. Furthermore, as a crucial step to reduce modeling complexity and make learning tractable, we propose the use of low dimensional latent feature representation of a high-dimensional 3D image, together with exogenous noise, to build causal relationship between the image and non image variables. We experiment the proposed method based on 1586 subjects and 3683 3D images and synthesize counterfactual brain MR images intervened on certain attributes, such as age, brain volume and cognitive test score. Quantitative metrics and qualitative evaluation of counterfactual images demonstrates the superiority of our generated images.
Learnable Pillar-based Re-ranking for Image-Text Retrieval
Apr 25, 2023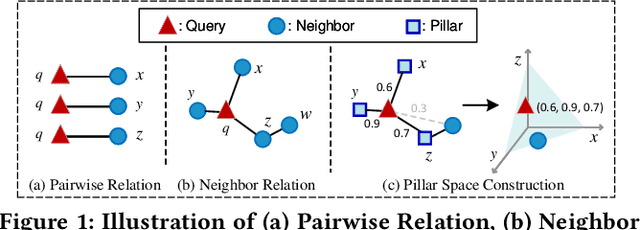
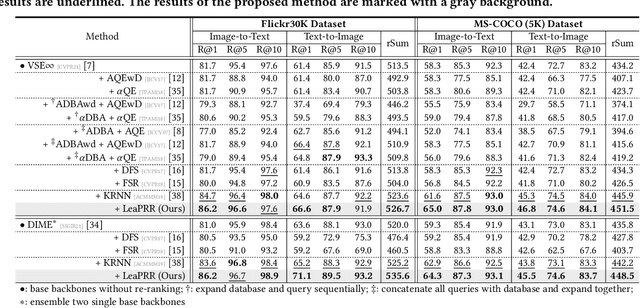
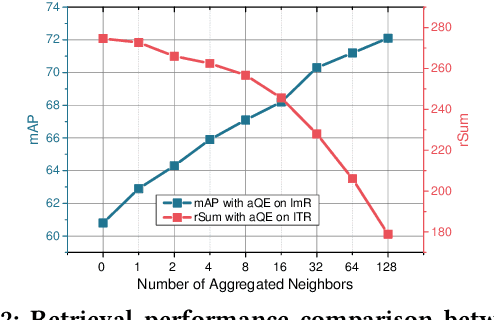
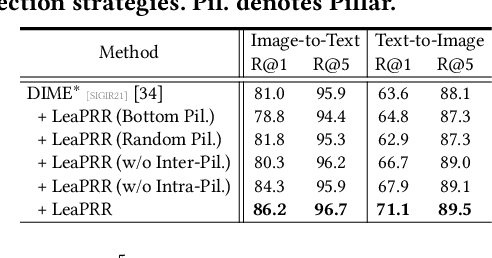
Image-text retrieval aims to bridge the modality gap and retrieve cross-modal content based on semantic similarities. Prior work usually focuses on the pairwise relations (i.e., whether a data sample matches another) but ignores the higher-order neighbor relations (i.e., a matching structure among multiple data samples). Re-ranking, a popular post-processing practice, has revealed the superiority of capturing neighbor relations in single-modality retrieval tasks. However, it is ineffective to directly extend existing re-ranking algorithms to image-text retrieval. In this paper, we analyze the reason from four perspectives, i.e., generalization, flexibility, sparsity, and asymmetry, and propose a novel learnable pillar-based re-ranking paradigm. Concretely, we first select top-ranked intra- and inter-modal neighbors as pillars, and then reconstruct data samples with the neighbor relations between them and the pillars. In this way, each sample can be mapped into a multimodal pillar space only using similarities, ensuring generalization. After that, we design a neighbor-aware graph reasoning module to flexibly exploit the relations and excavate the sparse positive items within a neighborhood. We also present a structure alignment constraint to promote cross-modal collaboration and align the asymmetric modalities. On top of various base backbones, we carry out extensive experiments on two benchmark datasets, i.e., Flickr30K and MS-COCO, demonstrating the effectiveness, superiority, generalization, and transferability of our proposed re-ranking paradigm.
* Accepted by SIGIR'2023
SwinFSR: Stereo Image Super-Resolution using SwinIR and Frequency Domain Knowledge
Apr 25, 2023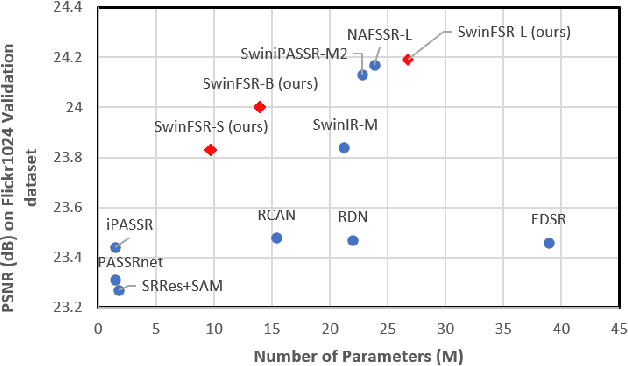
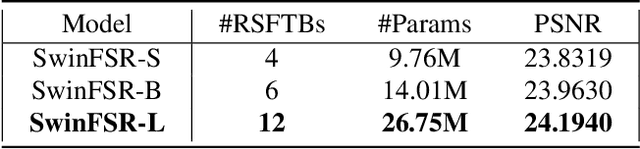
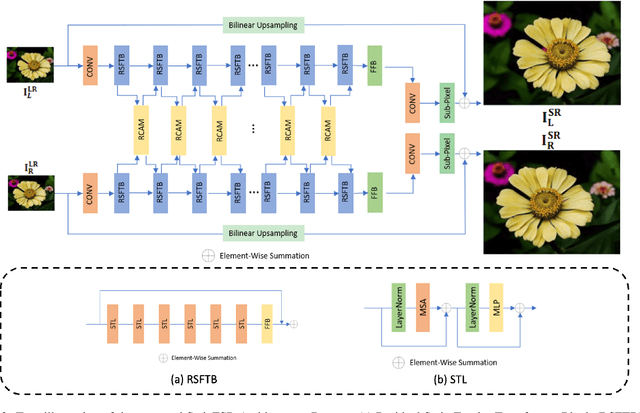
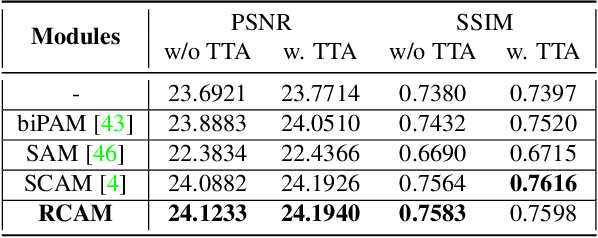
Stereo Image Super-Resolution (stereoSR) has attracted significant attention in recent years due to the extensive deployment of dual cameras in mobile phones, autonomous vehicles and robots. In this work, we propose a new StereoSR method, named SwinFSR, based on an extension of SwinIR, originally designed for single image restoration, and the frequency domain knowledge obtained by the Fast Fourier Convolution (FFC). Specifically, to effectively gather global information, we modify the Residual Swin Transformer blocks (RSTBs) in SwinIR by explicitly incorporating the frequency domain knowledge using the FFC and employing the resulting residual Swin Fourier Transformer blocks (RSFTBs) for feature extraction. Besides, for the efficient and accurate fusion of stereo views, we propose a new cross-attention module referred to as RCAM, which achieves highly competitive performance while requiring less computational cost than the state-of-the-art cross-attention modules. Extensive experimental results and ablation studies demonstrate the effectiveness and efficiency of our proposed SwinFSR.
Memorization Through the Lens of Curvature of Loss Function Around Samples
Jul 11, 2023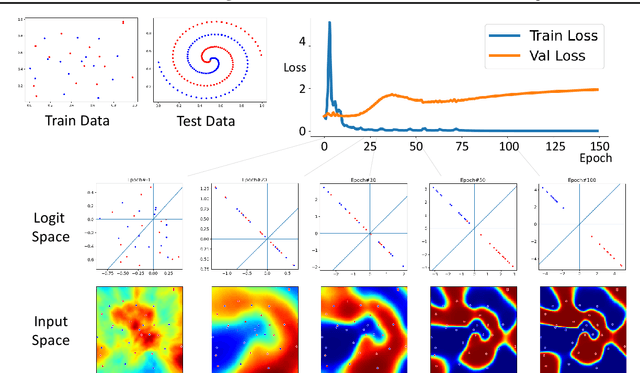
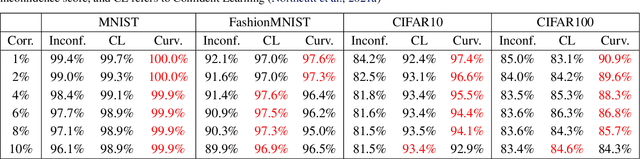


Neural networks are overparametrized and easily overfit the datasets they train on. In the extreme case, it is shown that they can memorize a training set with fully randomized labels. We propose using the curvature of loss function around the training sample as a measure of its memorization, averaged over all training epochs. We use this to study the generalization versus memorization properties of different samples in popular image datasets. We visualize samples with the highest curvature of loss around them, and show that these visually correspond to long-tailed, mislabeled or conflicting samples. This analysis helps us find a, to the best of our knowledge, novel failure model on the CIFAR100 dataset, that of duplicated images with different labels. We also synthetically mislabel a proportion of the dataset by randomly corrupting the labels of a few samples, and show that sorting by curvature yields high AUROC values for identifying the mislabeled samples.
MemeFier: Dual-stage Modality Fusion for Image Meme Classification
Apr 07, 2023
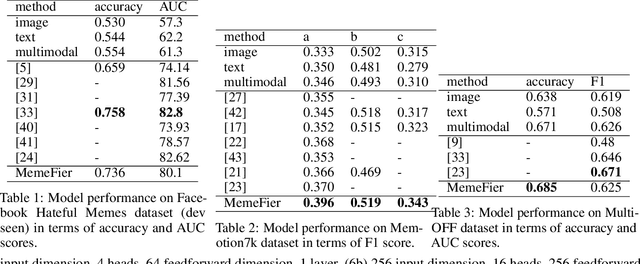
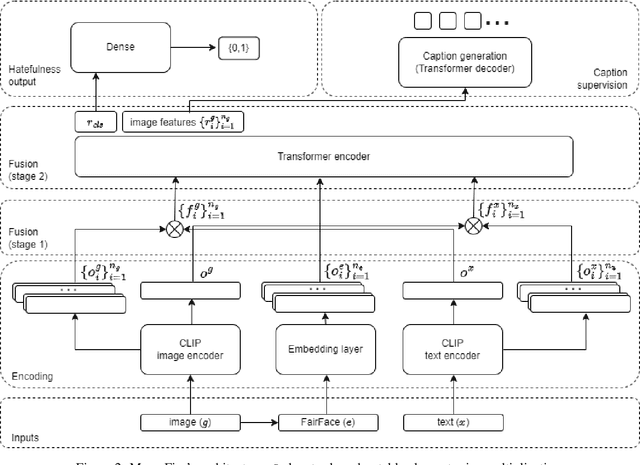

Hate speech is a societal problem that has significantly grown through the Internet. New forms of digital content such as image memes have given rise to spread of hate using multimodal means, being far more difficult to analyse and detect compared to the unimodal case. Accurate automatic processing, analysis and understanding of this kind of content will facilitate the endeavor of hindering hate speech proliferation through the digital world. To this end, we propose MemeFier, a deep learning-based architecture for fine-grained classification of Internet image memes, utilizing a dual-stage modality fusion module. The first fusion stage produces feature vectors containing modality alignment information that captures non-trivial connections between the text and image of a meme. The second fusion stage leverages the power of a Transformer encoder to learn inter-modality correlations at the token level and yield an informative representation. Additionally, we consider external knowledge as an additional input, and background image caption supervision as a regularizing component. Extensive experiments on three widely adopted benchmarks, i.e., Facebook Hateful Memes, Memotion7k and MultiOFF, indicate that our approach competes and in some cases surpasses state-of-the-art. Our code is available on https://github.com/ckoutlis/memefier.
Decoupled Diffusion Models with Explicit Transition Probability
Jun 23, 2023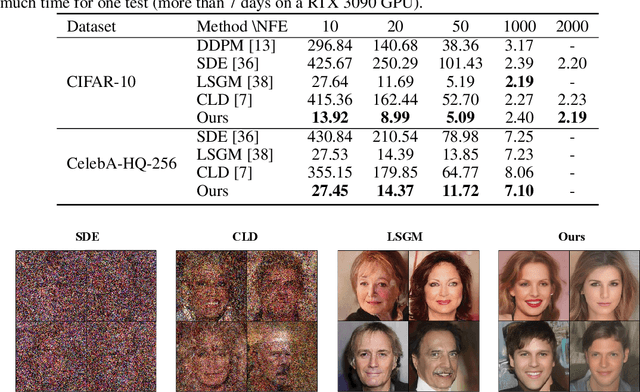
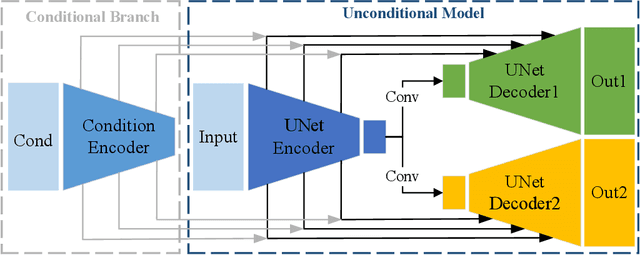
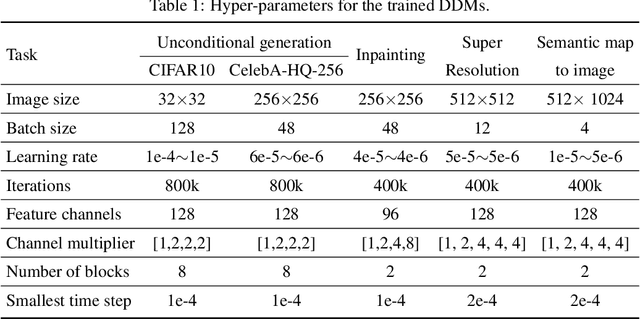

Recent diffusion probabilistic models (DPMs) have shown remarkable abilities of generated content, however, they often suffer from complex forward processes, resulting in inefficient solutions for the reversed process and prolonged sampling times. In this paper, we aim to address the aforementioned challenges by focusing on the diffusion process itself that we propose to decouple the intricate diffusion process into two comparatively simpler process to improve the generative efficacy and speed. In particular, we present a novel diffusion paradigm named DDM (\textbf{D}ecoupled \textbf{D}iffusion \textbf{M}odels) based on the It\^{o} diffusion process, in which the image distribution is approximated by an explicit transition probability while the noise path is controlled by the standard Wiener process. We find that decoupling the diffusion process reduces the learning difficulty and the explicit transition probability improves the generative speed significantly. We prove a new training objective for DPM, which enables the model to learn to predict the noise and image components separately. Moreover, given the novel forward diffusion equation, we derive the reverse denoising formula of DDM that naturally supports fewer steps of generation without ordinary differential equation (ODE) based accelerators. Our experiments demonstrate that DDM outperforms previous DPMs by a large margin in fewer function evaluations setting and gets comparable performances in long function evaluations setting. We also show that our framework can be applied to image-conditioned generation and high-resolution image synthesis, and that it can generate high-quality images with only 10 function evaluations.
Zero-Shot Composed Image Retrieval with Textual Inversion
Mar 27, 2023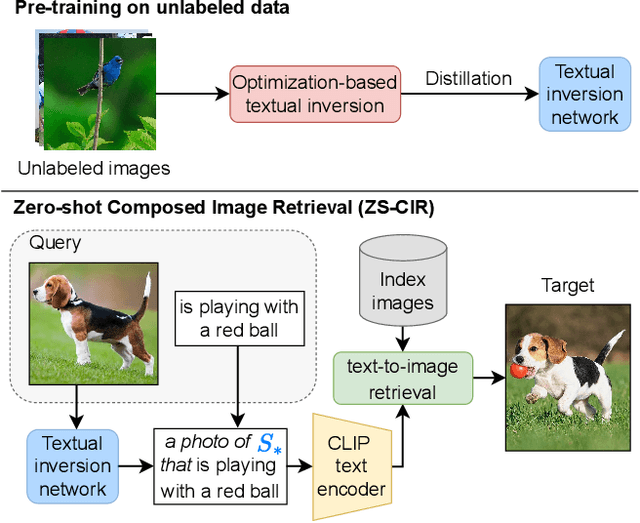
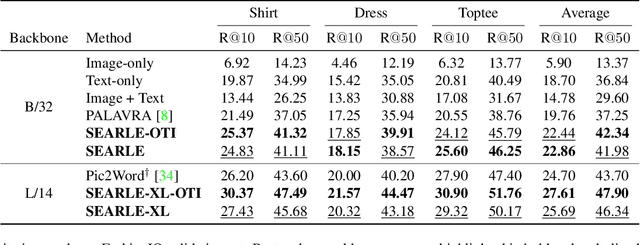
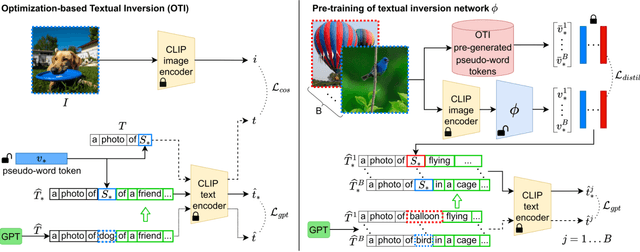
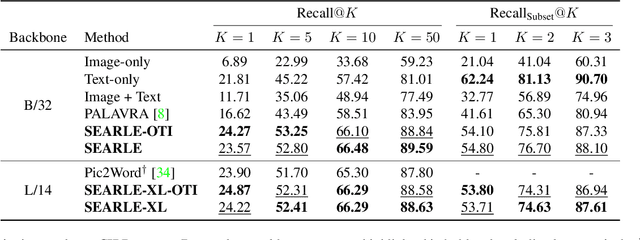
Composed Image Retrieval (CIR) aims to retrieve a target image based on a query composed of a reference image and a relative caption that describes the difference between the two images. The high effort and cost required for labeling datasets for CIR hamper the widespread usage of existing methods, as they rely on supervised learning. In this work, we propose a new task, Zero-Shot CIR (ZS-CIR), that aims to address CIR without requiring a labeled training dataset. Our approach, named zero-Shot composEd imAge Retrieval with textuaL invErsion (SEARLE), maps the visual features of the reference image into a pseudo-word token in CLIP token embedding space and integrates it with the relative caption. To support research on ZS-CIR, we introduce an open-domain benchmarking dataset named Composed Image Retrieval on Common Objects in context (CIRCO), which is the first dataset for CIR containing multiple ground truths for each query. The experiments show that SEARLE exhibits better performance than the baselines on the two main datasets for CIR tasks, FashionIQ and CIRR, and on the proposed CIRCO. The dataset, the code and the model are publicly available at https://github.com/miccunifi/SEARLE .
Unsupervised Intrinsic Image Decomposition with LiDAR Intensity
Mar 28, 2023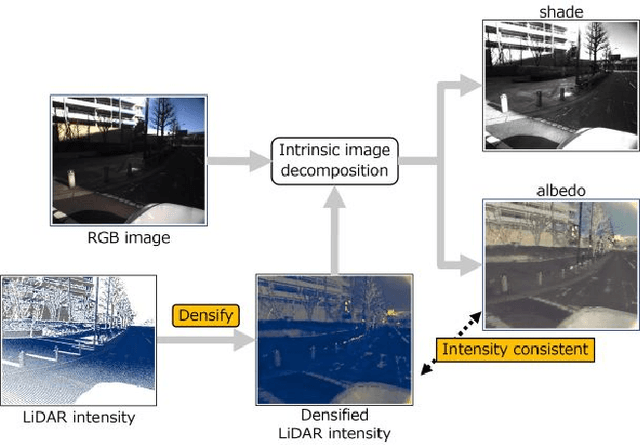

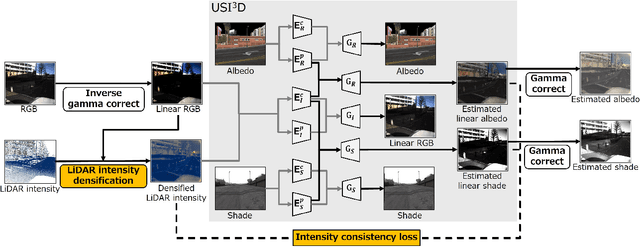
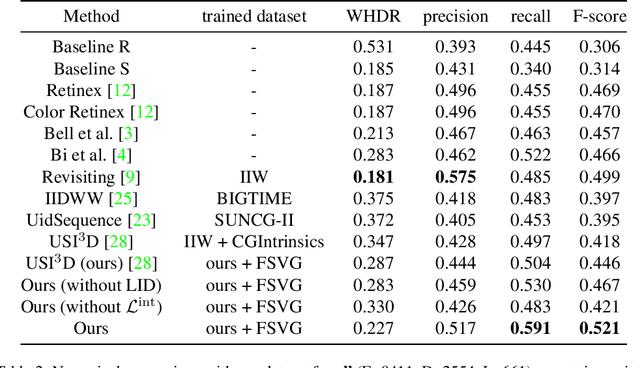
Intrinsic image decomposition (IID) is the task that decomposes a natural image into albedo and shade. While IID is typically solved through supervised learning methods, it is not ideal due to the difficulty in observing ground truth albedo and shade in general scenes. Conversely, unsupervised learning methods are currently underperforming supervised learning methods since there are no criteria for solving the ill-posed problems. Recently, light detection and ranging (LiDAR) is widely used due to its ability to make highly precise distance measurements. Thus, we have focused on the utilization of LiDAR, especially LiDAR intensity, to address this issue. In this paper, we propose unsupervised intrinsic image decomposition with LiDAR intensity (IID-LI). Since the conventional unsupervised learning methods consist of image-to-image transformations, simply inputting LiDAR intensity is not an effective approach. Therefore, we design an intensity consistency loss that computes the error between LiDAR intensity and gray-scaled albedo to provide a criterion for the ill-posed problem. In addition, LiDAR intensity is difficult to handle due to its sparsity and occlusion, hence, a LiDAR intensity densification module is proposed. We verified the estimating quality using our own dataset, which include RGB images, LiDAR intensity and human judged annotations. As a result, we achieved an estimation accuracy that outperforms conventional unsupervised learning methods. Dataset link : (https://github.com/ntthilab-cv/NTT-intrinsic-dataset).
T-MARS: Improving Visual Representations by Circumventing Text Feature Learning
Jul 06, 2023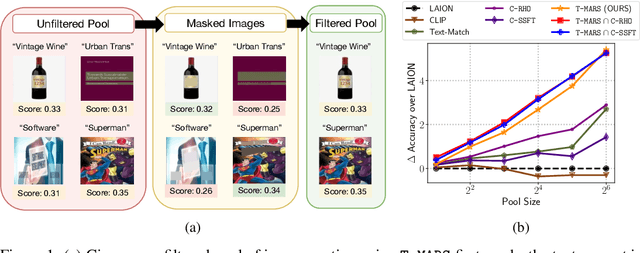
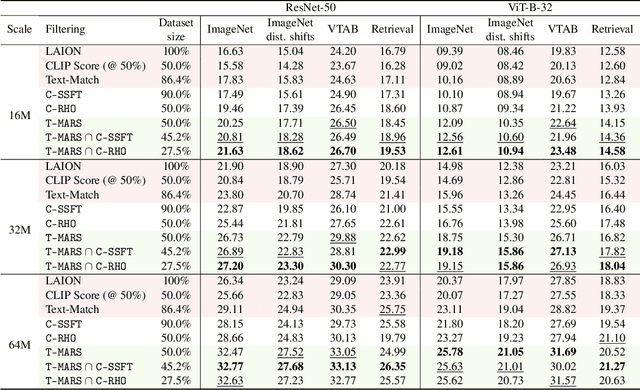

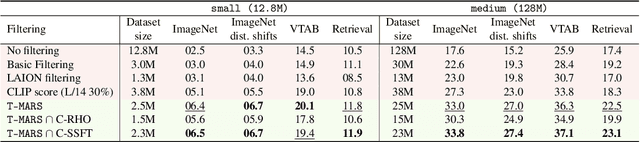
Large web-sourced multimodal datasets have powered a slew of new methods for learning general-purpose visual representations, advancing the state of the art in computer vision and revolutionizing zero- and few-shot recognition. One crucial decision facing practitioners is how, if at all, to curate these ever-larger datasets. For example, the creators of the LAION-5B dataset chose to retain only image-caption pairs whose CLIP similarity score exceeded a designated threshold. In this paper, we propose a new state-of-the-art data filtering approach motivated by our observation that nearly 40% of LAION's images contain text that overlaps significantly with the caption. Intuitively, such data could be wasteful as it incentivizes models to perform optical character recognition rather than learning visual features. However, naively removing all such data could also be wasteful, as it throws away images that contain visual features (in addition to overlapping text). Our simple and scalable approach, T-MARS (Text Masking and Re-Scoring), filters out only those pairs where the text dominates the remaining visual features -- by first masking out the text and then filtering out those with a low CLIP similarity score of the masked image. Experimentally, T-MARS outperforms the top-ranked method on the "medium scale" of DataComp (a data filtering benchmark) by a margin of 6.5% on ImageNet and 4.7% on VTAB. Additionally, our systematic evaluation on various data pool sizes from 2M to 64M shows that the accuracy gains enjoyed by T-MARS linearly increase as data and compute are scaled exponentially. Code is available at https://github.com/locuslab/T-MARS.