 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
FocusMAE: Gallbladder Cancer Detection from Ultrasound Videos with Focused Masked Autoencoders
Mar 29, 2024
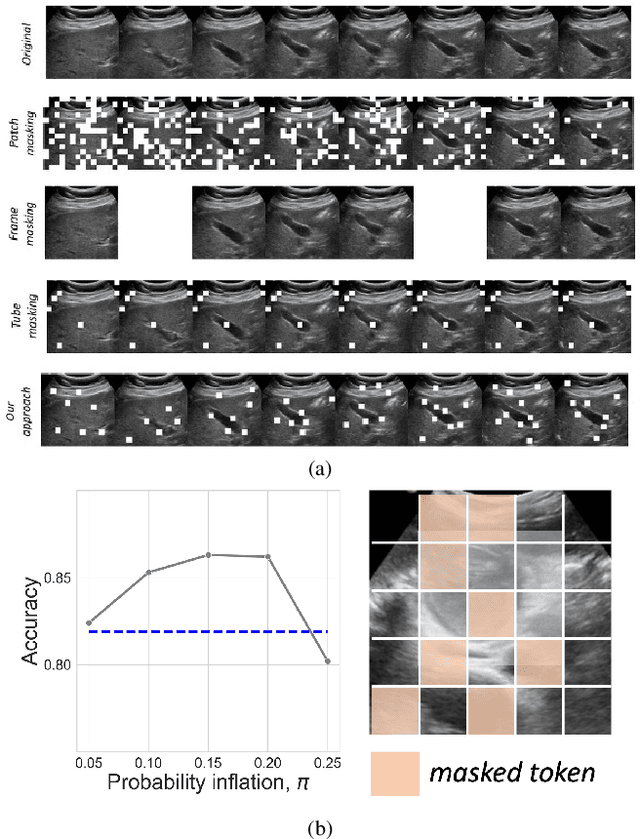
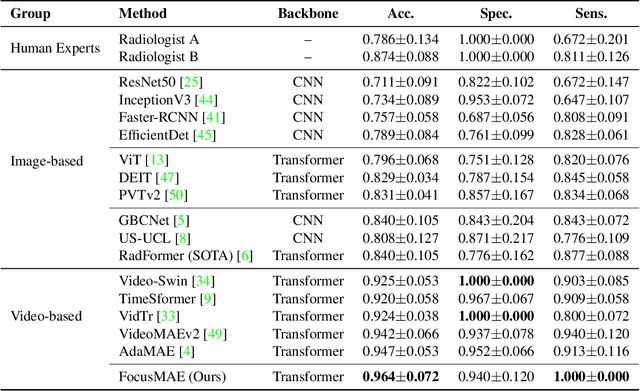
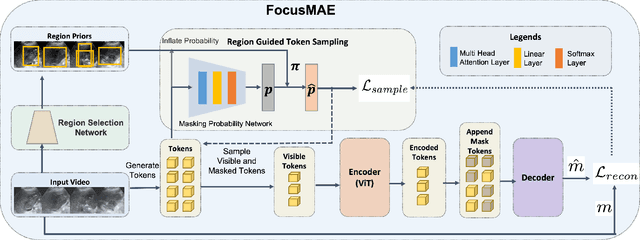
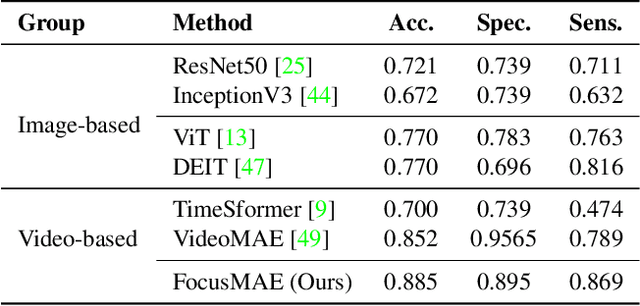
In recent years, automated Gallbladder Cancer (GBC) detection has gained the attention of researchers. Current state-of-the-art (SOTA) methodologies relying on ultrasound sonography (US) images exhibit limited generalization, emphasizing the need for transformative approaches. We observe that individual US frames may lack sufficient information to capture disease manifestation. This study advocates for a paradigm shift towards video-based GBC detection, leveraging the inherent advantages of spatiotemporal representations. Employing the Masked Autoencoder (MAE) for representation learning, we address shortcomings in conventional image-based methods. We propose a novel design called FocusMAE to systematically bias the selection of masking tokens from high-information regions, fostering a more refined representation of malignancy. Additionally, we contribute the most extensive US video dataset for GBC detection. We also note that, this is the first study on US video-based GBC detection. We validate the proposed methods on the curated dataset, and report a new state-of-the-art (SOTA) accuracy of 96.4% for the GBC detection problem, against an accuracy of 84% by current Image-based SOTA - GBCNet, and RadFormer, and 94.7% by Video-based SOTA - AdaMAE. We further demonstrate the generality of the proposed FocusMAE on a public CT-based Covid detection dataset, reporting an improvement in accuracy by 3.3% over current baselines. The source code and pretrained models are available at: https://gbc-iitd.github.io/focusmae
Minimum-Norm Interpolation Under Covariate Shift
Mar 31, 2024Transfer learning is a critical part of real-world machine learning deployments and has been extensively studied in experimental works with overparameterized neural networks. However, even in the simplest setting of linear regression a notable gap still exists in the theoretical understanding of transfer learning. In-distribution research on high-dimensional linear regression has led to the identification of a phenomenon known as \textit{benign overfitting}, in which linear interpolators overfit to noisy training labels and yet still generalize well. This behavior occurs under specific conditions on the source covariance matrix and input data dimension. Therefore, it is natural to wonder how such high-dimensional linear models behave under transfer learning. We prove the first non-asymptotic excess risk bounds for benignly-overfit linear interpolators in the transfer learning setting. From our analysis, we propose a taxonomy of \textit{beneficial} and \textit{malignant} covariate shifts based on the degree of overparameterization. We follow our analysis with empirical studies that show these beneficial and malignant covariate shifts for linear interpolators on real image data, and for fully-connected neural networks in settings where the input data dimension is larger than the training sample size.
TexVocab: Texture Vocabulary-conditioned Human Avatars
Mar 31, 2024To adequately utilize the available image evidence in multi-view video-based avatar modeling, we propose TexVocab, a novel avatar representation that constructs a texture vocabulary and associates body poses with texture maps for animation. Given multi-view RGB videos, our method initially back-projects all the available images in the training videos to the posed SMPL surface, producing texture maps in the SMPL UV domain. Then we construct pairs of human poses and texture maps to establish a texture vocabulary for encoding dynamic human appearances under various poses. Unlike the commonly used joint-wise manner, we further design a body-part-wise encoding strategy to learn the structural effects of the kinematic chain. Given a driving pose, we query the pose feature hierarchically by decomposing the pose vector into several body parts and interpolating the texture features for synthesizing fine-grained human dynamics. Overall, our method is able to create animatable human avatars with detailed and dynamic appearances from RGB videos, and the experiments show that our method outperforms state-of-the-art approaches. The project page can be found at https://texvocab.github.io/.
DailyMAE: Towards Pretraining Masked Autoencoders in One Day
Mar 31, 2024Recently, masked image modeling (MIM), an important self-supervised learning (SSL) method, has drawn attention for its effectiveness in learning data representation from unlabeled data. Numerous studies underscore the advantages of MIM, highlighting how models pretrained on extensive datasets can enhance the performance of downstream tasks. However, the high computational demands of pretraining pose significant challenges, particularly within academic environments, thereby impeding the SSL research progress. In this study, we propose efficient training recipes for MIM based SSL that focuses on mitigating data loading bottlenecks and employing progressive training techniques and other tricks to closely maintain pretraining performance. Our library enables the training of a MAE-Base/16 model on the ImageNet 1K dataset for 800 epochs within just 18 hours, using a single machine equipped with 8 A100 GPUs. By achieving speed gains of up to 5.8 times, this work not only demonstrates the feasibility of conducting high-efficiency SSL training but also paves the way for broader accessibility and promotes advancement in SSL research particularly for prototyping and initial testing of SSL ideas. The code is available in https://github.com/erow/FastSSL.
Segmentation Re-thinking Uncertainty Estimation Metrics for Semantic Segmentation
Mar 28, 2024In the domain of computer vision, semantic segmentation emerges as a fundamental application within machine learning, wherein individual pixels of an image are classified into distinct semantic categories. This task transcends traditional accuracy metrics by incorporating uncertainty quantification, a critical measure for assessing the reliability of each segmentation prediction. Such quantification is instrumental in facilitating informed decision-making, particularly in applications where precision is paramount. Within this nuanced framework, the metric known as PAvPU (Patch Accuracy versus Patch Uncertainty) has been developed as a specialized tool for evaluating entropy-based uncertainty in image segmentation tasks. However, our investigation identifies three core deficiencies within the PAvPU framework and proposes robust solutions aimed at refining the metric. By addressing these issues, we aim to enhance the reliability and applicability of uncertainty quantification, especially in scenarios that demand high levels of safety and accuracy, thus contributing to the advancement of semantic segmentation methodologies in critical applications.
Generative Quanta Color Imaging
Mar 28, 2024The astonishing development of single-photon cameras has created an unprecedented opportunity for scientific and industrial imaging. However, the high data throughput generated by these 1-bit sensors creates a significant bottleneck for low-power applications. In this paper, we explore the possibility of generating a color image from a single binary frame of a single-photon camera. We evidently find this problem being particularly difficult to standard colorization approaches due to the substantial degree of exposure variation. The core innovation of our paper is an exposure synthesis model framed under a neural ordinary differential equation (Neural ODE) that allows us to generate a continuum of exposures from a single observation. This innovation ensures consistent exposure in binary images that colorizers take on, resulting in notably enhanced colorization. We demonstrate applications of the method in single-image and burst colorization and show superior generative performance over baselines. Project website can be found at https://vishal-s-p.github.io/projects/2023/generative_quanta_color.html.
Make Me Happier: Evoking Emotions Through Image Diffusion Models
Mar 13, 2024
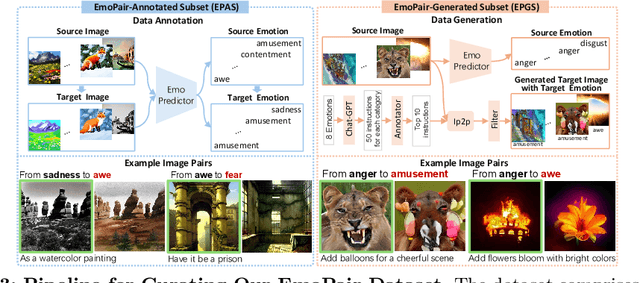
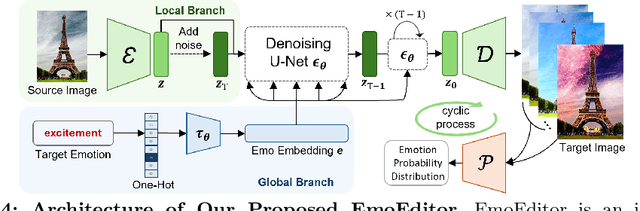
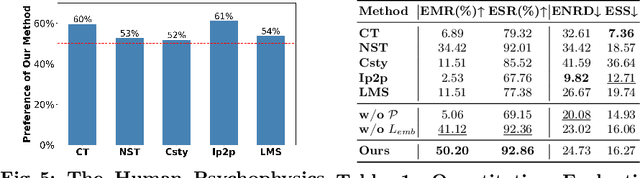
Despite the rapid progress in image generation, emotional image editing remains under-explored. The semantics, context, and structure of an image can evoke emotional responses, making emotional image editing techniques valuable for various real-world applications, including treatment of psychological disorders, commercialization of products, and artistic design. For the first time, we present a novel challenge of emotion-evoked image generation, aiming to synthesize images that evoke target emotions while retaining the semantics and structures of the original scenes. To address this challenge, we propose a diffusion model capable of effectively understanding and editing source images to convey desired emotions and sentiments. Moreover, due to the lack of emotion editing datasets, we provide a unique dataset consisting of 340,000 pairs of images and their emotion annotations. Furthermore, we conduct human psychophysics experiments and introduce four new evaluation metrics to systematically benchmark all the methods. Experimental results demonstrate that our method surpasses all competitive baselines. Our diffusion model is capable of identifying emotional cues from original images, editing images that elicit desired emotions, and meanwhile, preserving the semantic structure of the original images. All code, model, and data will be made public.
How to Handle Sketch-Abstraction in Sketch-Based Image Retrieval?
Mar 20, 2024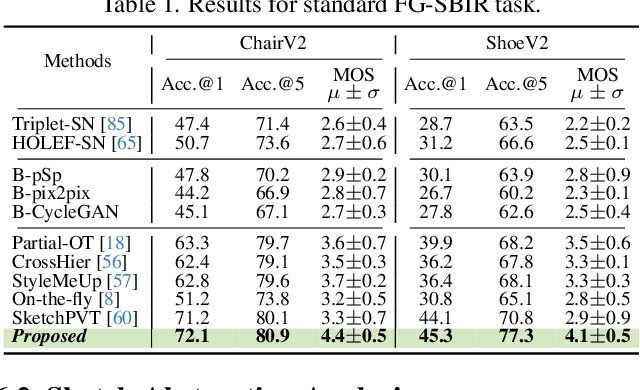
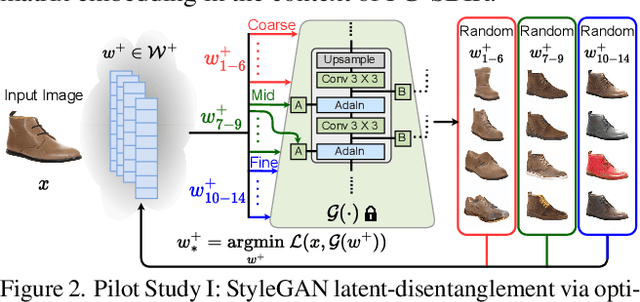
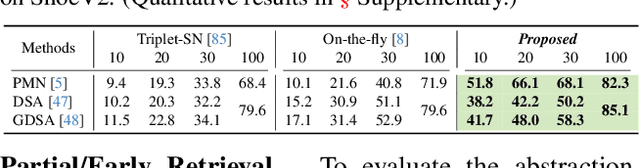
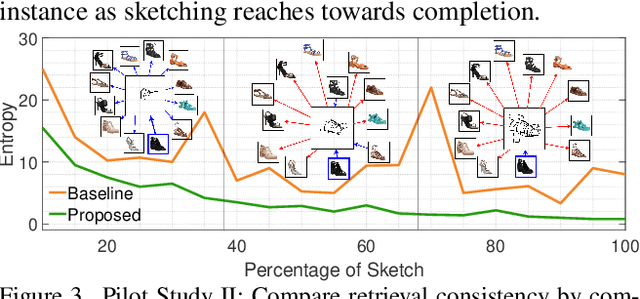
In this paper, we propose a novel abstraction-aware sketch-based image retrieval framework capable of handling sketch abstraction at varied levels. Prior works had mainly focused on tackling sub-factors such as drawing style and order, we instead attempt to model abstraction as a whole, and propose feature-level and retrieval granularity-level designs so that the system builds into its DNA the necessary means to interpret abstraction. On learning abstraction-aware features, we for the first-time harness the rich semantic embedding of pre-trained StyleGAN model, together with a novel abstraction-level mapper that deciphers the level of abstraction and dynamically selects appropriate dimensions in the feature matrix correspondingly, to construct a feature matrix embedding that can be freely traversed to accommodate different levels of abstraction. For granularity-level abstraction understanding, we dictate that the retrieval model should not treat all abstraction-levels equally and introduce a differentiable surrogate Acc.@q loss to inject that understanding into the system. Different to the gold-standard triplet loss, our Acc.@q loss uniquely allows a sketch to narrow/broaden its focus in terms of how stringent the evaluation should be - the more abstract a sketch, the less stringent (higher q). Extensive experiments depict our method to outperform existing state-of-the-arts in standard SBIR tasks along with challenging scenarios like early retrieval, forensic sketch-photo matching, and style-invariant retrieval.
Heterogeneous Network Based Contrastive Learning Method for PolSAR Land Cover Classification
Mar 29, 2024
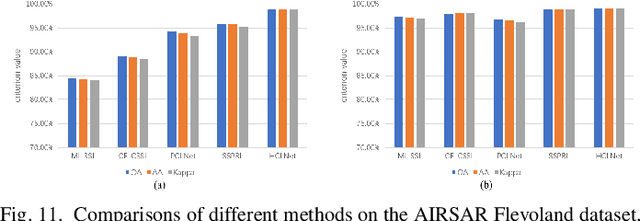

Polarimetric synthetic aperture radar (PolSAR) image interpretation is widely used in various fields. Recently, deep learning has made significant progress in PolSAR image classification. Supervised learning (SL) requires a large amount of labeled PolSAR data with high quality to achieve better performance, however, manually labeled data is insufficient. This causes the SL to fail into overfitting and degrades its generalization performance. Furthermore, the scattering confusion problem is also a significant challenge that attracts more attention. To solve these problems, this article proposes a Heterogeneous Network based Contrastive Learning method(HCLNet). It aims to learn high-level representation from unlabeled PolSAR data for few-shot classification according to multi-features and superpixels. Beyond the conventional CL, HCLNet introduces the heterogeneous architecture for the first time to utilize heterogeneous PolSAR features better. And it develops two easy-to-use plugins to narrow the domain gap between optics and PolSAR, including feature filter and superpixel-based instance discrimination, which the former is used to enhance the complementarity of multi-features, and the latter is used to increase the diversity of negative samples. Experiments demonstrate the superiority of HCLNet on three widely used PolSAR benchmark datasets compared with state-of-the-art methods. Ablation studies also verify the importance of each component. Besides, this work has implications for how to efficiently utilize the multi-features of PolSAR data to learn better high-level representation in CL and how to construct networks suitable for PolSAR data better.
Multiple Teachers-Meticulous Student: A Domain Adaptive Meta-Knowledge Distillation Model for Medical Image Classification
Mar 17, 2024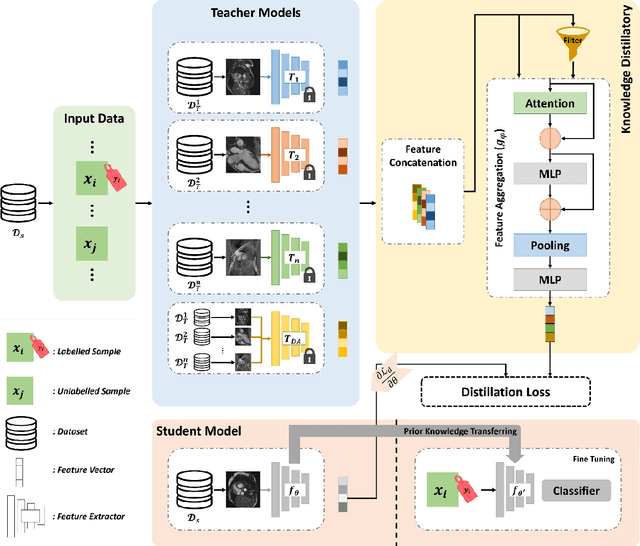
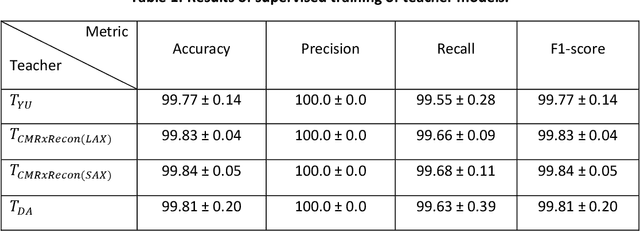
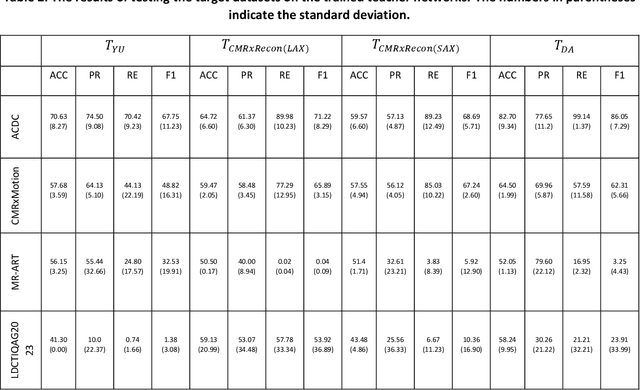
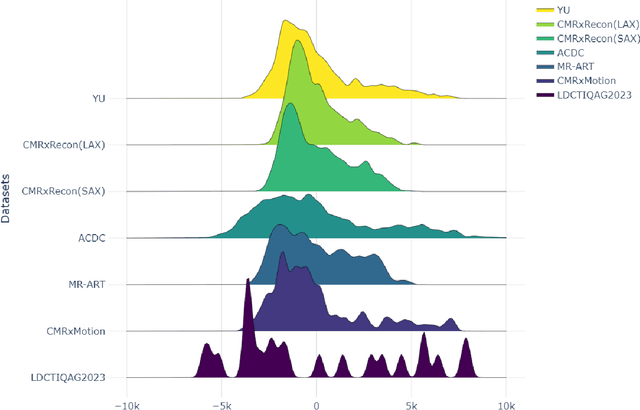
Background: Image classification can be considered one of the key pillars of medical image analysis. Deep learning (DL) faces challenges that prevent its practical applications despite the remarkable improvement in medical image classification. The data distribution differences can lead to a drop in the efficiency of DL, known as the domain shift problem. Besides, requiring bulk annotated data for model training, the large size of models, and the privacy-preserving of patients are other challenges of using DL in medical image classification. This study presents a strategy that can address the mentioned issues simultaneously. Method: The proposed domain adaptive model based on knowledge distillation can classify images by receiving limited annotated data of different distributions. The designed multiple teachers-meticulous student model trains a student network that tries to solve the challenges by receiving the parameters of several teacher networks. The proposed model was evaluated using six available datasets of different distributions by defining the respiratory motion artefact detection task. Results: The results of extensive experiments using several datasets show the superiority of the proposed model in addressing the domain shift problem and lack of access to bulk annotated data. Besides, the privacy preservation of patients by receiving only the teacher network parameters instead of the original data and consolidating the knowledge of several DL models into a model with almost similar performance are other advantages of the proposed model. Conclusions: The proposed model can pave the way for practical clinical applications of deep classification methods by achieving the mentioned objectives simultaneously.