 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
See Through the Fog: Curriculum Learning with Progressive Occlusion in Medical Imaging
Jun 30, 2023
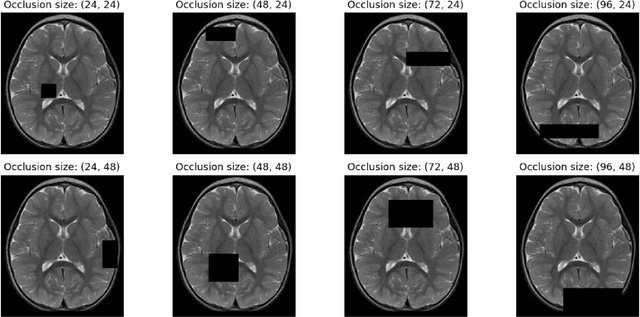
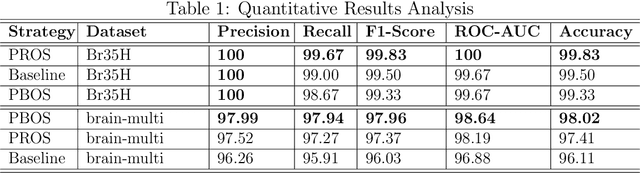
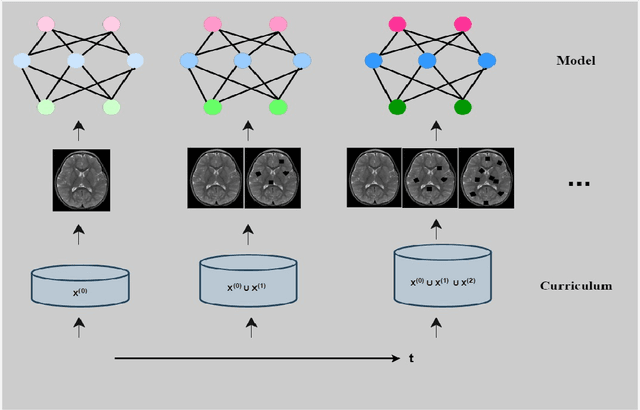
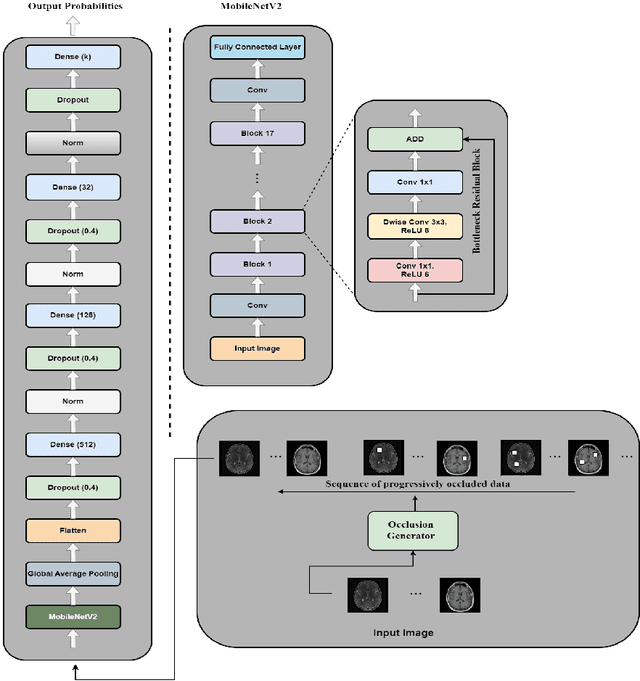
In recent years, deep learning models have revolutionized medical image interpretation, offering substantial improvements in diagnostic accuracy. However, these models often struggle with challenging images where critical features are partially or fully occluded, which is a common scenario in clinical practice. In this paper, we propose a novel curriculum learning-based approach to train deep learning models to handle occluded medical images effectively. Our method progressively introduces occlusion, starting from clear, unobstructed images and gradually moving to images with increasing occlusion levels. This ordered learning process, akin to human learning, allows the model to first grasp simple, discernable patterns and subsequently build upon this knowledge to understand more complicated, occluded scenarios. Furthermore, we present three novel occlusion synthesis methods, namely Wasserstein Curriculum Learning (WCL), Information Adaptive Learning (IAL), and Geodesic Curriculum Learning (GCL). Our extensive experiments on diverse medical image datasets demonstrate substantial improvements in model robustness and diagnostic accuracy over conventional training methodologies.
RS5M: A Large Scale Vision-Language Dataset for Remote Sensing Vision-Language Foundation Model
Jun 20, 2023
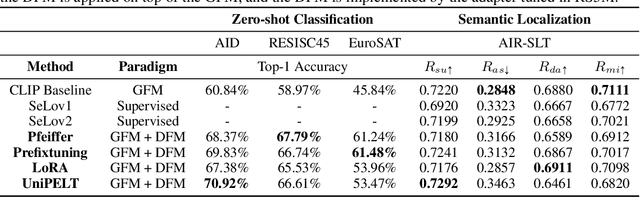
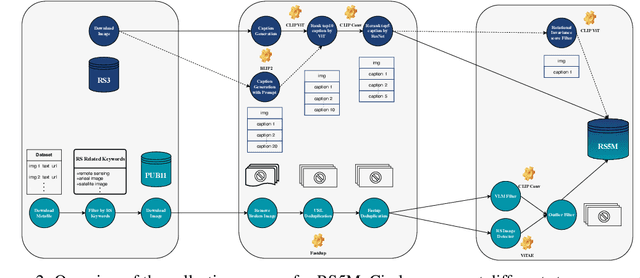
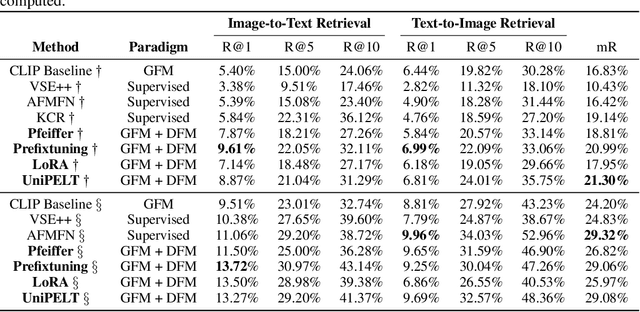
Pre-trained Vision-Language Foundation Models utilizing extensive image-text paired data have demonstrated unprecedented image-text association capabilities, achieving remarkable results across various downstream tasks. A critical challenge is how to make use of existing large-scale pre-trained VLMs, which are trained on common objects, to perform the domain-specific transfer for accomplishing domain-related downstream tasks. In this paper, we propose a new framework that includes the Domain Foundation Model (DFM), bridging the gap between the General Foundation Model (GFM) and domain-specific downstream tasks. Moreover, we present an image-text paired dataset in the field of remote sensing (RS), RS5M, which has 5 million RS images with English descriptions. The dataset is obtained from filtering publicly available image-text paired datasets and captioning label-only RS datasets with pre-trained VLM. These constitute the first large-scale RS image-text paired dataset. Additionally, we tried several Parameter-Efficient Fine-Tuning methods on RS5M to implement the DFM. Experimental results show that our proposed dataset are highly effective for various tasks, improving upon the baseline by $8 \% \sim 16 \%$ in zero-shot classification tasks, and obtaining good results in both Vision-Language Retrieval and Semantic Localization tasks. Finally, we show successful results of training the RS Stable Diffusion model using the RS5M, uncovering more use cases of the dataset.
Quantum Annealing for Single Image Super-Resolution
Apr 18, 2023
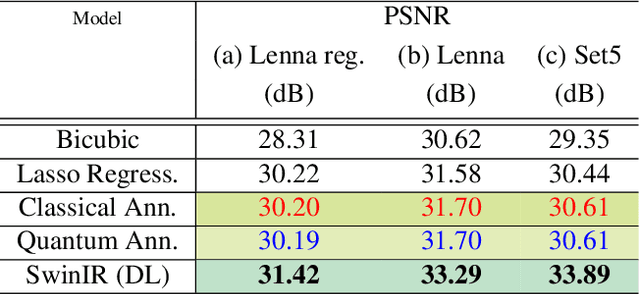
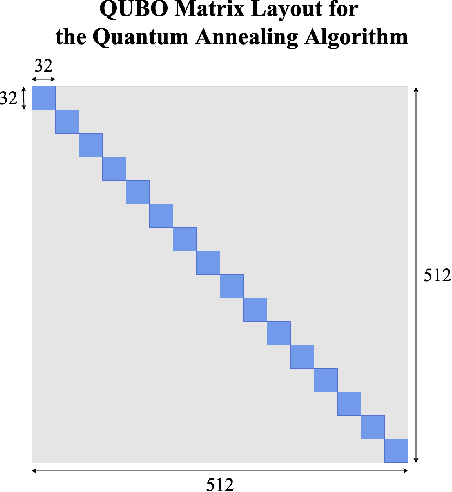

This paper proposes a quantum computing-based algorithm to solve the single image super-resolution (SISR) problem. One of the well-known classical approaches for SISR relies on the well-established patch-wise sparse modeling of the problem. Yet, this field's current state of affairs is that deep neural networks (DNNs) have demonstrated far superior results than traditional approaches. Nevertheless, quantum computing is expected to become increasingly prominent for machine learning problems soon. As a result, in this work, we take the privilege to perform an early exploration of applying a quantum computing algorithm to this important image enhancement problem, i.e., SISR. Among the two paradigms of quantum computing, namely universal gate quantum computing and adiabatic quantum computing (AQC), the latter has been successfully applied to practical computer vision problems, in which quantum parallelism has been exploited to solve combinatorial optimization efficiently. This work demonstrates formulating quantum SISR as a sparse coding optimization problem, which is solved using quantum annealers accessed via the D-Wave Leap platform. The proposed AQC-based algorithm is demonstrated to achieve improved speed-up over a classical analog while maintaining comparable SISR accuracy.
BerDiff: Conditional Bernoulli Diffusion Model for Medical Image Segmentation
Apr 10, 2023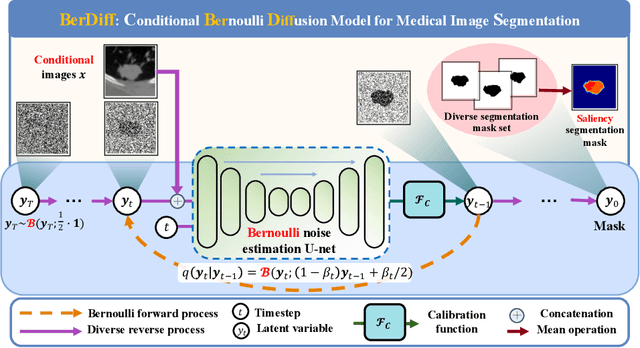
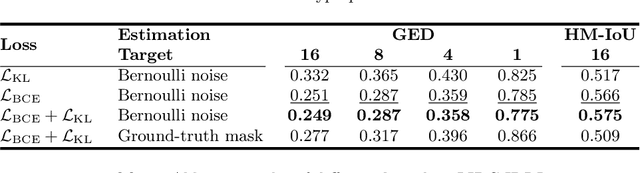
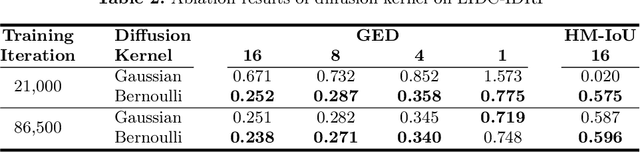
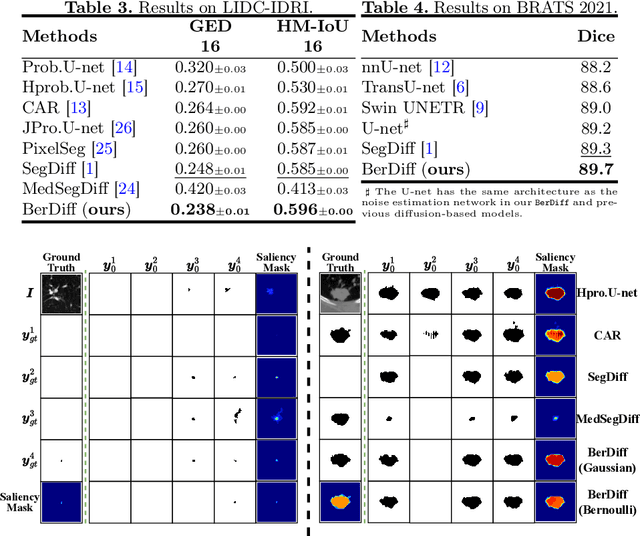
Medical image segmentation is a challenging task with inherent ambiguity and high uncertainty, attributed to factors such as unclear tumor boundaries and multiple plausible annotations. The accuracy and diversity of segmentation masks are both crucial for providing valuable references to radiologists in clinical practice. While existing diffusion models have shown strong capacities in various visual generation tasks, it is still challenging to deal with discrete masks in segmentation. To achieve accurate and diverse medical image segmentation masks, we propose a novel conditional Bernoulli Diffusion model for medical image segmentation (BerDiff). Instead of using the Gaussian noise, we first propose to use the Bernoulli noise as the diffusion kernel to enhance the capacity of the diffusion model for binary segmentation tasks, resulting in more accurate segmentation masks. Second, by leveraging the stochastic nature of the diffusion model, our BerDiff randomly samples the initial Bernoulli noise and intermediate latent variables multiple times to produce a range of diverse segmentation masks, which can highlight salient regions of interest that can serve as valuable references for radiologists. In addition, our BerDiff can efficiently sample sub-sequences from the overall trajectory of the reverse diffusion, thereby speeding up the segmentation process. Extensive experimental results on two medical image segmentation datasets with different modalities demonstrate that our BerDiff outperforms other recently published state-of-the-art methods. Our results suggest diffusion models could serve as a strong backbone for medical image segmentation.
Realistic Data Enrichment for Robust Image Segmentation in Histopathology
Apr 19, 2023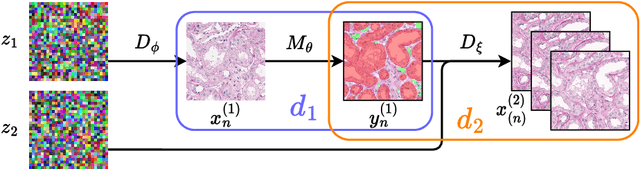
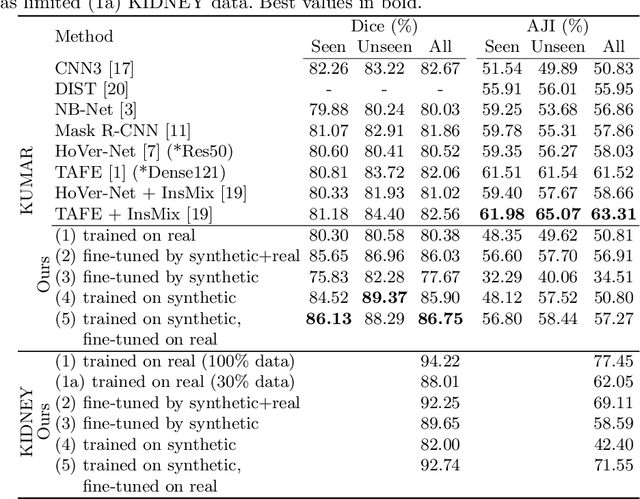

Poor performance of quantitative analysis in histopathological Whole Slide Images (WSI) has been a significant obstacle in clinical practice. Annotating large-scale WSIs manually is a demanding and time-consuming task, unlikely to yield the expected results when used for fully supervised learning systems. Rarely observed disease patterns and large differences in object scales are difficult to model through conventional patient intake. Prior methods either fall back to direct disease classification, which only requires learning a few factors per image, or report on average image segmentation performance, which is highly biased towards majority observations. Geometric image augmentation is commonly used to improve robustness for average case predictions and to enrich limited datasets. So far no method provided sampling of a realistic posterior distribution to improve stability, e.g. for the segmentation of imbalanced objects within images. Therefore, we propose a new approach, based on diffusion models, which can enrich an imbalanced dataset with plausible examples from underrepresented groups by conditioning on segmentation maps. Our method can simply expand limited clinical datasets making them suitable to train machine learning pipelines, and provides an interpretable and human-controllable way of generating histopathology images that are indistinguishable from real ones to human experts. We validate our findings on two datasets, one from the public domain and one from a Kidney Transplant study.
Diagnostic Benchmark and Iterative Inpainting for Layout-Guided Image Generation
Apr 14, 2023
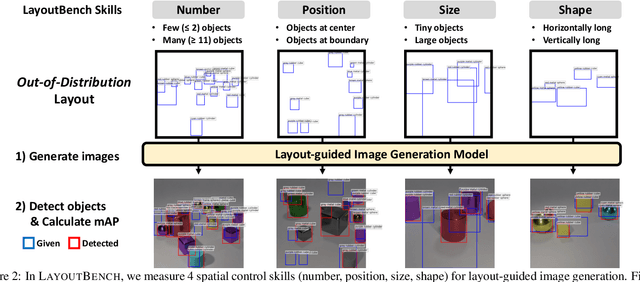
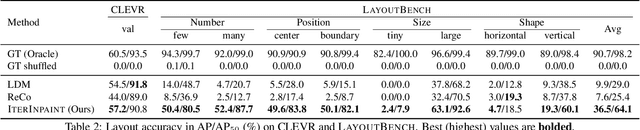
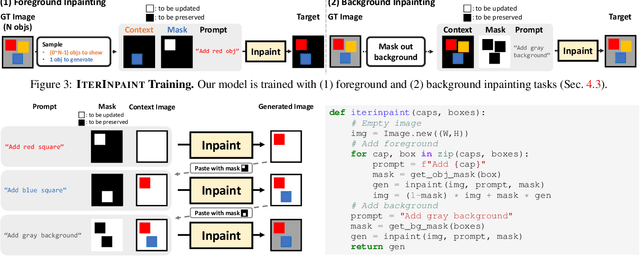
Spatial control is a core capability in controllable image generation. Advancements in layout-guided image generation have shown promising results on in-distribution (ID) datasets with similar spatial configurations. However, it is unclear how these models perform when facing out-of-distribution (OOD) samples with arbitrary, unseen layouts. In this paper, we propose LayoutBench, a diagnostic benchmark for layout-guided image generation that examines four categories of spatial control skills: number, position, size, and shape. We benchmark two recent representative layout-guided image generation methods and observe that the good ID layout control may not generalize well to arbitrary layouts in the wild (e.g., objects at the boundary). Next, we propose IterInpaint, a new baseline that generates foreground and background regions in a step-by-step manner via inpainting, demonstrating stronger generalizability than existing models on OOD layouts in LayoutBench. We perform quantitative and qualitative evaluation and fine-grained analysis on the four LayoutBench skills to pinpoint the weaknesses of existing models. Lastly, we show comprehensive ablation studies on IterInpaint, including training task ratio, crop&paste vs. repaint, and generation order. Project website: https://layoutbench.github.io
New Variants of Frank-Wolfe Algorithm for Video Co-localization Problem
Jul 10, 2023

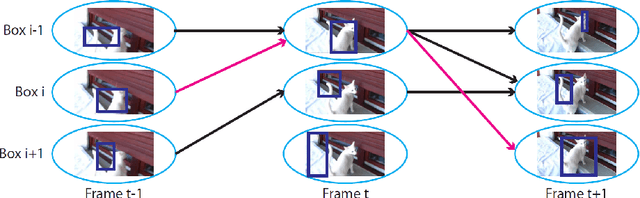
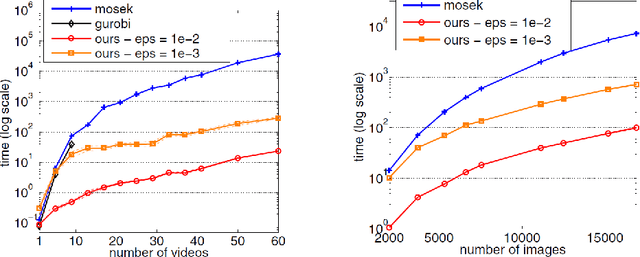
The co-localization problem is a model that simultaneously localizes objects of the same class within a series of images or videos. In \cite{joulin2014efficient}, authors present new variants of the Frank-Wolfe algorithm (aka conditional gradient) that increase the efficiency in solving the image and video co-localization problems. The authors show the efficiency of their methods with the rate of decrease in a value called the Wolfe gap in each iteration of the algorithm. In this project, inspired by the conditional gradient sliding algorithm (CGS) \cite{CGS:Lan}, We propose algorithms for solving such problems and demonstrate the efficiency of the proposed algorithms through numerical experiments. The efficiency of these methods with respect to the Wolfe gap is compared with implementing them on the YouTube-Objects dataset for videos.
PP-GAN : Style Transfer from Korean Portraits to ID Photos Using Landmark Extractor with GAN
Jun 23, 2023
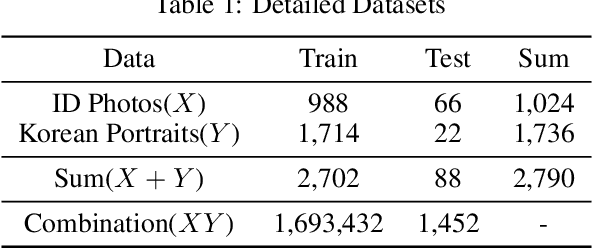

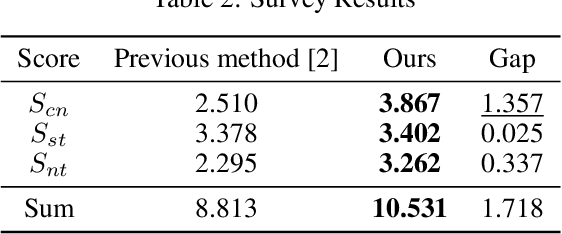
The objective of a style transfer is to maintain the content of an image while transferring the style of another image. However, conventional research on style transfer has a significant limitation in preserving facial landmarks, such as the eyes, nose, and mouth, which are crucial for maintaining the identity of the image. In Korean portraits, the majority of individuals wear "Gat", a type of headdress exclusively worn by men. Owing to its distinct characteristics from the hair in ID photos, transferring the "Gat" is challenging. To address this issue, this study proposes a deep learning network that can perform style transfer, including the "Gat", while preserving the identity of the face. Unlike existing style transfer approaches, the proposed method aims to preserve texture, costume, and the "Gat" on the style image. The Generative Adversarial Network forms the backbone of the proposed network. The color, texture, and intensity were extracted differently based on the characteristics of each block and layer of the pre-trained VGG-16, and only the necessary elements during training were preserved using a facial landmark mask. The head area was presented using the eyebrow area to transfer the "Gat". Furthermore, the identity of the face was retained, and style correlation was considered based on the Gram matrix. The proposed approach demonstrated superior transfer and preservation performance compared to previous studies.
Text-to-image Diffusion Models in Generative AI: A Survey
Apr 02, 2023


This survey reviews text-to-image diffusion models in the context that diffusion models have emerged to be popular for a wide range of generative tasks. As a self-contained work, this survey starts with a brief introduction of how a basic diffusion model works for image synthesis, followed by how condition or guidance improves learning. Based on that, we present a review of state-of-the-art methods on text-conditioned image synthesis, i.e., text-to-image. We further summarize applications beyond text-to-image generation: text-guided creative generation and text-guided image editing. Beyond the progress made so far, we discuss existing challenges and promising future directions.
Graph Convolutional Networks based on Manifold Learning for Semi-Supervised Image Classification
Apr 24, 2023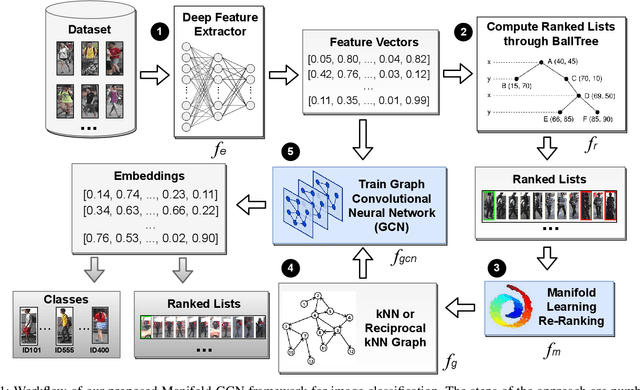
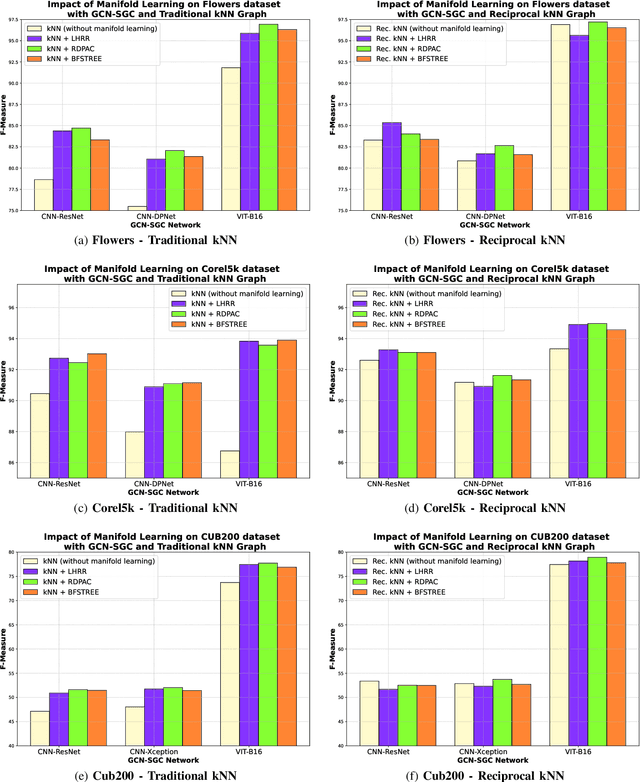
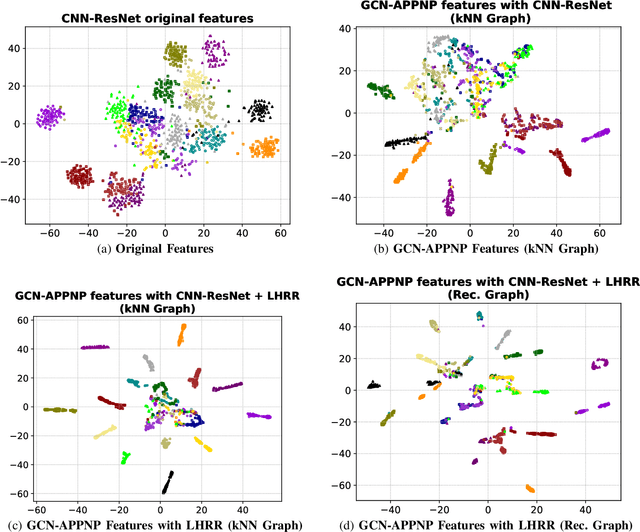
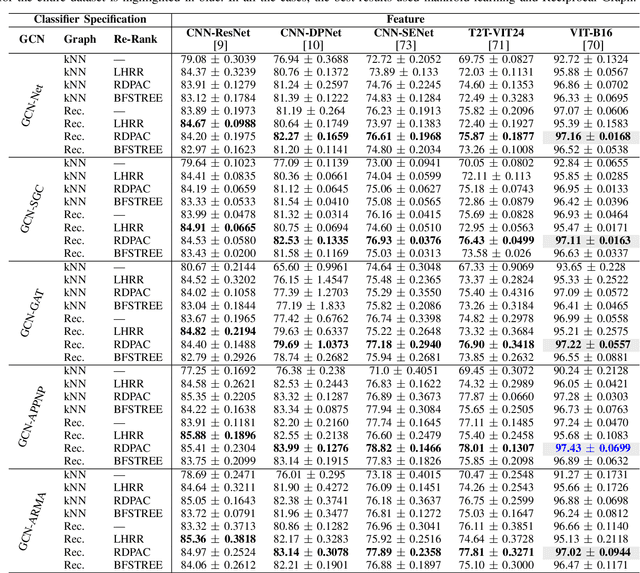
Due to a huge volume of information in many domains, the need for classification methods is imperious. In spite of many advances, most of the approaches require a large amount of labeled data, which is often not available, due to costs and difficulties of manual labeling processes. In this scenario, unsupervised and semi-supervised approaches have been gaining increasing attention. The GCNs (Graph Convolutional Neural Networks) represent a promising solution since they encode the neighborhood information and have achieved state-of-the-art results on scenarios with limited labeled data. However, since GCNs require graph-structured data, their use for semi-supervised image classification is still scarce in the literature. In this work, we propose a novel approach, the Manifold-GCN, based on GCNs for semi-supervised image classification. The main hypothesis of this paper is that the use of manifold learning to model the graph structure can further improve the GCN classification. To the best of our knowledge, this is the first framework that allows the combination of GCNs with different types of manifold learning approaches for image classification. All manifold learning algorithms employed are completely unsupervised, which is especially useful for scenarios where the availability of labeled data is a concern. A broad experimental evaluation was conducted considering 5 GCN models, 3 manifold learning approaches, 3 image datasets, and 5 deep features. The results reveal that our approach presents better accuracy than traditional and recent state-of-the-art methods with very efficient run times for both training and testing.