 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Topology-Aware Uncertainty for Image Segmentation
Jun 09, 2023
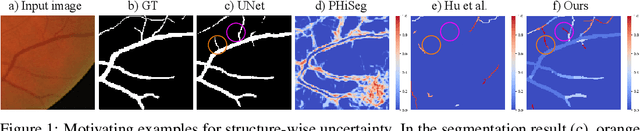
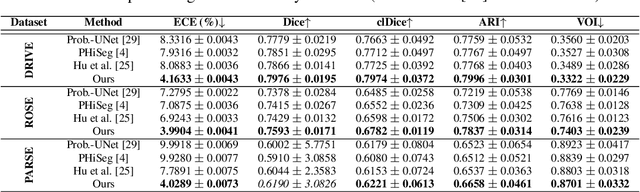

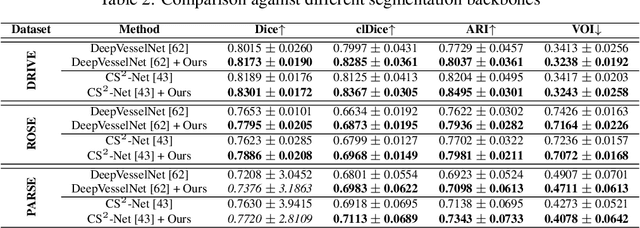
Segmentation of curvilinear structures such as vasculature and road networks is challenging due to relatively weak signals and complex geometry/topology. To facilitate and accelerate large scale annotation, one has to adopt semi-automatic approaches such as proofreading by experts. In this work, we focus on uncertainty estimation for such tasks, so that highly uncertain, and thus error-prone structures can be identified for human annotators to verify. Unlike most existing works, which provide pixel-wise uncertainty maps, we stipulate it is crucial to estimate uncertainty in the units of topological structures, e.g., small pieces of connections and branches. To achieve this, we leverage tools from topological data analysis, specifically discrete Morse theory (DMT), to first capture the structures, and then reason about their uncertainties. To model the uncertainty, we (1) propose a joint prediction model that estimates the uncertainty of a structure while taking the neighboring structures into consideration (inter-structural uncertainty); (2) propose a novel Probabilistic DMT to model the inherent uncertainty within each structure (intra-structural uncertainty) by sampling its representations via a perturb-and-walk scheme. On various 2D and 3D datasets, our method produces better structure-wise uncertainty maps compared to existing works.
Implementation of a perception system for autonomous vehicles using a detection-segmentation network in SoC FPGA
Jul 17, 2023
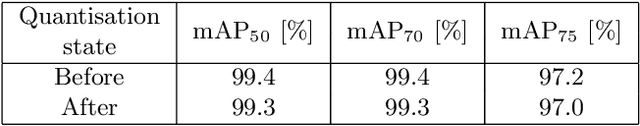
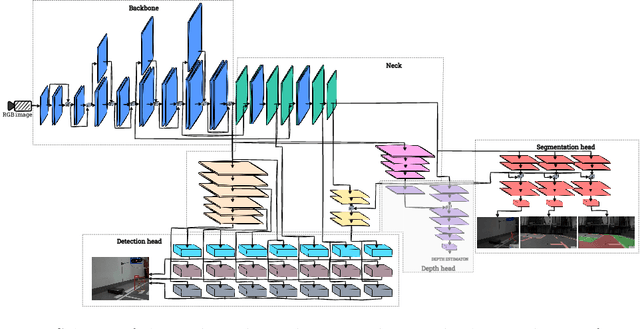
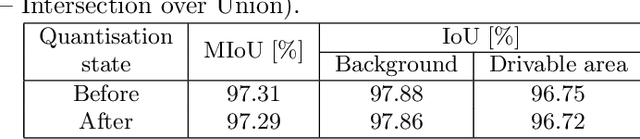
Perception and control systems for autonomous vehicles are an active area of scientific and industrial research. These solutions should be characterised by high efficiency in recognising obstacles and other environmental elements in different road conditions, real-time capability, and energy efficiency. Achieving such functionality requires an appropriate algorithm and a suitable computing platform. In this paper, we have used the MultiTaskV3 detection-segmentation network as the basis for a perception system that can perform both functionalities within a single architecture. It was appropriately trained, quantised, and implemented on the AMD Xilinx Kria KV260 Vision AI embedded platform. By using this device, it was possible to parallelise and accelerate the computations. Furthermore, the whole system consumes relatively little power compared to a CPU-based implementation (an average of 5 watts, compared to the minimum of 55 watts for weaker CPUs, and the small size (119mm x 140mm x 36mm) of the platform allows it to be used in devices where the amount of space available is limited. It also achieves an accuracy higher than 97% of the mAP (mean average precision) for object detection and above 90% of the mIoU (mean intersection over union) for image segmentation. The article also details the design of the Mecanum wheel vehicle, which was used to test the proposed solution in a mock-up city.
SEMI-DiffusionInst: A Diffusion Model Based Approach for Semiconductor Defect Classification and Segmentation
Jul 17, 2023

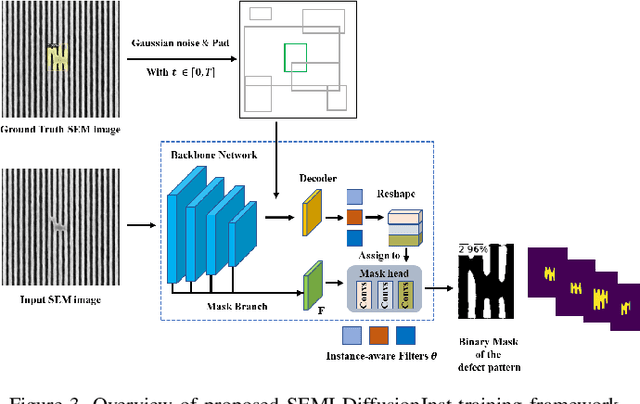
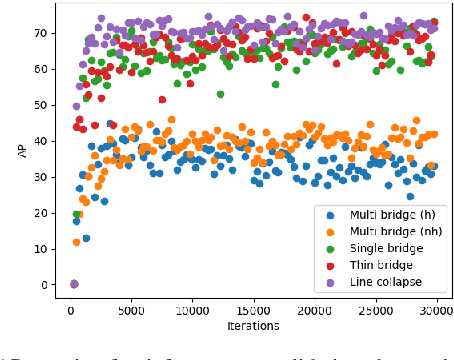
With continuous progression of Moore's Law, integrated circuit (IC) device complexity is also increasing. Scanning Electron Microscope (SEM) image based extensive defect inspection and accurate metrology extraction are two main challenges in advanced node (2 nm and beyond) technology. Deep learning (DL) algorithm based computer vision approaches gained popularity in semiconductor defect inspection over last few years. In this research work, a new semiconductor defect inspection framework "SEMI-DiffusionInst" is investigated and compared to previous frameworks. To the best of the authors' knowledge, this work is the first demonstration to accurately detect and precisely segment semiconductor defect patterns by using a diffusion model. Different feature extractor networks as backbones and data sampling strategies are investigated towards achieving a balanced trade-off between precision and computing efficiency. Our proposed approach outperforms previous work on overall mAP and performs comparatively better or as per for almost all defect classes (per class APs). The bounding box and segmentation mAPs achieved by the proposed SEMI-DiffusionInst model are improved by 3.83% and 2.10%,respectively. Among individual defect types, precision on line collapse and thin bridge defects are improved approximately 15% on detection task for both defect types. It has also been shown that by tuning inference hyperparameters, inference time can be improved significantly without compromising model precision. Finally, certain limitations and future work strategy to overcome them are discussed.
RCM-Fusion: Radar-Camera Multi-Level Fusion for 3D Object Detection
Jul 17, 2023
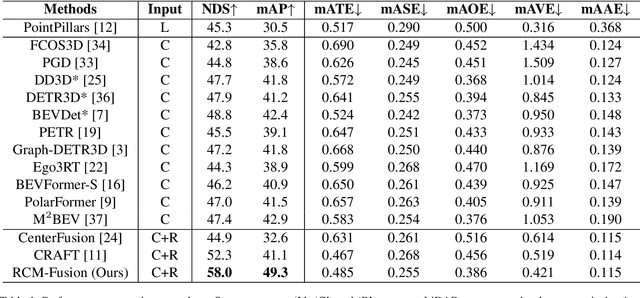
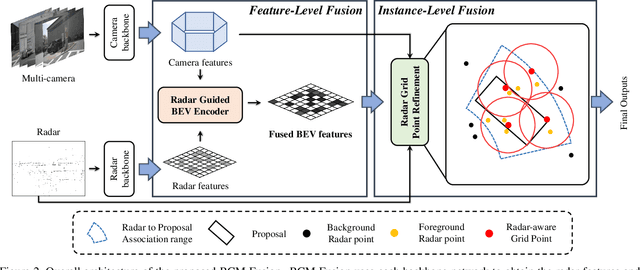
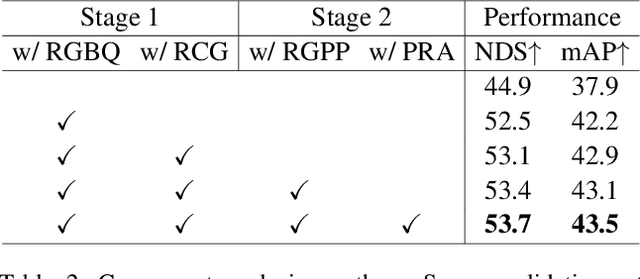
While LiDAR sensors have been succesfully applied to 3D object detection, the affordability of radar and camera sensors has led to a growing interest in fusiong radars and cameras for 3D object detection. However, previous radar-camera fusion models have not been able to fully utilize radar information in that initial 3D proposals were generated based on the camera features only and the instance-level fusion is subsequently conducted. In this paper, we propose radar-camera multi-level fusion (RCM-Fusion), which fuses radar and camera modalities at both the feature-level and instance-level to fully utilize radar information. At the feature-level, we propose a Radar Guided BEV Encoder which utilizes radar Bird's-Eye-View (BEV) features to transform image features into precise BEV representations and then adaptively combines the radar and camera BEV features. At the instance-level, we propose a Radar Grid Point Refinement module that reduces localization error by considering the characteristics of the radar point clouds. The experiments conducted on the public nuScenes dataset demonstrate that our proposed RCM-Fusion offers 11.8% performance gain in nuScenes detection score (NDS) over the camera-only baseline model and achieves state-of-the-art performaces among radar-camera fusion methods in the nuScenes 3D object detection benchmark. Code will be made publicly available.
Towards Coherent Image Inpainting Using Denoising Diffusion Implicit Models
Apr 06, 2023
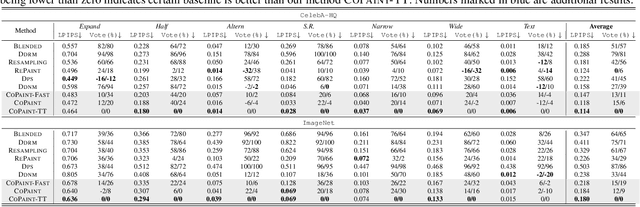
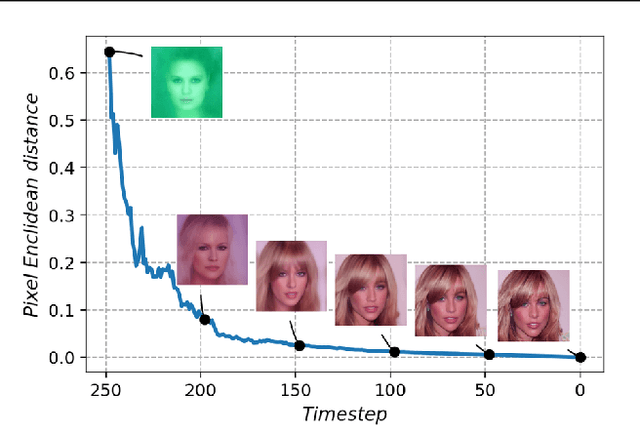
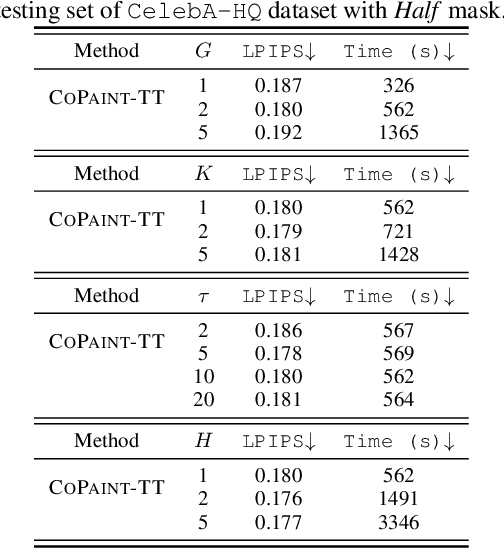
Image inpainting refers to the task of generating a complete, natural image based on a partially revealed reference image. Recently, many research interests have been focused on addressing this problem using fixed diffusion models. These approaches typically directly replace the revealed region of the intermediate or final generated images with that of the reference image or its variants. However, since the unrevealed regions are not directly modified to match the context, it results in incoherence between revealed and unrevealed regions. To address the incoherence problem, a small number of methods introduce a rigorous Bayesian framework, but they tend to introduce mismatches between the generated and the reference images due to the approximation errors in computing the posterior distributions. In this paper, we propose COPAINT, which can coherently inpaint the whole image without introducing mismatches. COPAINT also uses the Bayesian framework to jointly modify both revealed and unrevealed regions, but approximates the posterior distribution in a way that allows the errors to gradually drop to zero throughout the denoising steps, thus strongly penalizing any mismatches with the reference image. Our experiments verify that COPAINT can outperform the existing diffusion-based methods under both objective and subjective metrics. The codes are available at https://github.com/UCSB-NLP-Chang/CoPaint/.
VVC+M: Plug and Play Scalable Image Coding for Humans and Machines
May 17, 2023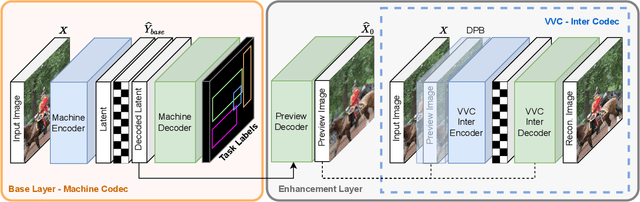
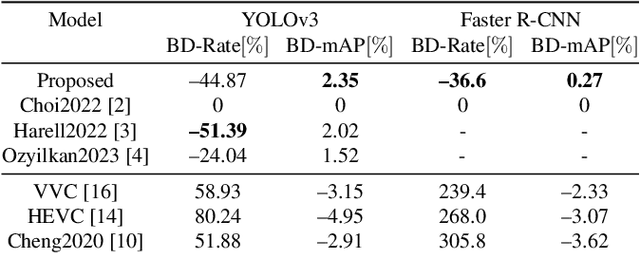
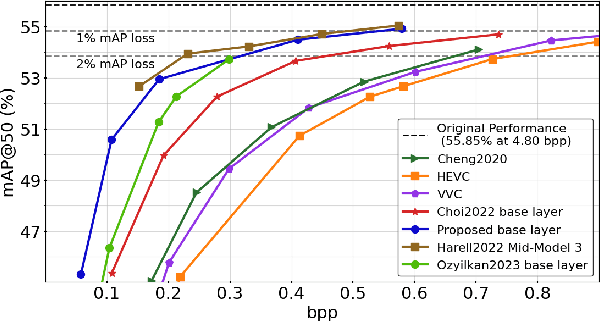
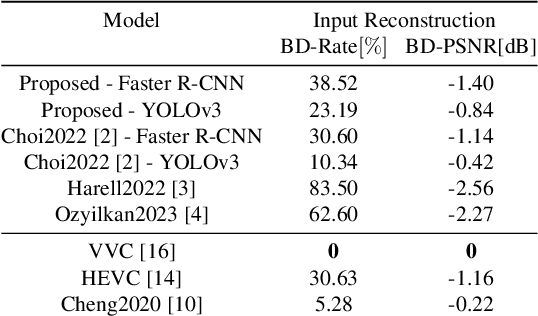
Compression for machines is an emerging field, where inputs are encoded while optimizing the performance of downstream automated analysis. In scalable coding for humans and machines, the compressed representation used for machines is further utilized to enable input reconstruction. Often performed by jointly optimizing the compression scheme for both machine task and human perception, this results in sub-optimal rate-distortion (RD) performance for the machine side. We focus on the case of images, proposing to utilize the pre-existing residual coding capabilities of video codecs such as VVC to create a scalable codec from any image compression for machines (ICM) scheme. Using our approach we improve an existing scalable codec to achieve superior RD performance on the machine task, while remaining competitive for human perception. Moreover, our approach can be trained post-hoc for any given ICM scheme, and without creating a coupling between the quality of the machine analysis and human vision.
Applications of Binary Similarity and Distance Measures
Jul 01, 2023In the recent past, binary similarity measures have been applied in solving biometric identification problems, including fingerprint, handwritten character detection, and in iris image recognition. The application of the relevant measurements has also resulted in more accurate data analysis. This paper surveys the applicability of binary similarity and distance measures in various fields.
Key-Locked Rank One Editing for Text-to-Image Personalization
May 02, 2023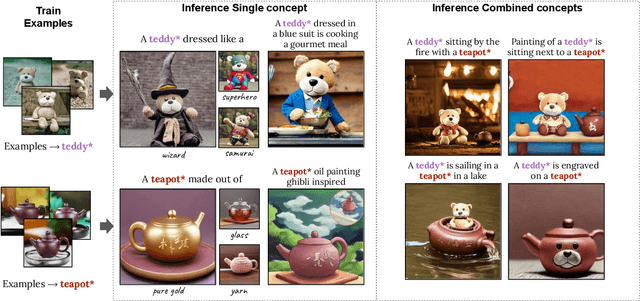



Text-to-image models (T2I) offer a new level of flexibility by allowing users to guide the creative process through natural language. However, personalizing these models to align with user-provided visual concepts remains a challenging problem. The task of T2I personalization poses multiple hard challenges, such as maintaining high visual fidelity while allowing creative control, combining multiple personalized concepts in a single image, and keeping a small model size. We present Perfusion, a T2I personalization method that addresses these challenges using dynamic rank-1 updates to the underlying T2I model. Perfusion avoids overfitting by introducing a new mechanism that "locks" new concepts' cross-attention Keys to their superordinate category. Additionally, we develop a gated rank-1 approach that enables us to control the influence of a learned concept during inference time and to combine multiple concepts. This allows runtime-efficient balancing of visual-fidelity and textual-alignment with a single 100KB trained model, which is five orders of magnitude smaller than the current state of the art. Moreover, it can span different operating points across the Pareto front without additional training. Finally, we show that Perfusion outperforms strong baselines in both qualitative and quantitative terms. Importantly, key-locking leads to novel results compared to traditional approaches, allowing to portray personalized object interactions in unprecedented ways, even in one-shot settings.
1st Solution Places for CVPR 2023 UG$^2$+ Challenge Track 2.2-Coded Target Restoration through Atmospheric Turbulence
Jun 15, 2023

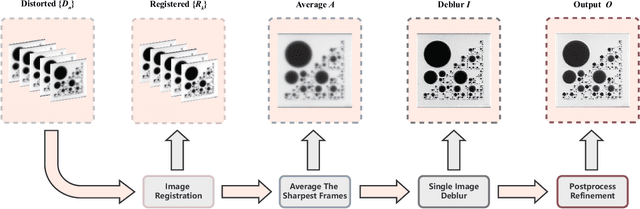

In this technical report, we briefly introduce the solution of our team VIELab-HUST for coded target restoration through atmospheric turbulence in CVPR 2023 UG$^2$+ Track 2.2. In this task, we propose an efficient multi-stage framework to restore a high quality image from distorted frames. Specifically, each distorted frame is initially aligned using image registration to suppress geometric distortion. We subsequently select the sharpest set of registered frames by employing a frame selection approach based on image sharpness, and average them to produce an image that is largely free of geometric distortion, albeit with blurriness. A learning-based deblurring method is then applied to remove the residual blur in the averaged image. Finally, post-processing techniques are utilized to further enhance the quality of the output image. Our framework is capable of handling different kinds of coded target dataset provided in the final testing phase, and ranked 1st on the final leaderboard. Our code will be available at https://github.com/xsqhust/Turbulence_Removal.
A Gated Cross-domain Collaborative Network for Underwater Object Detection
Jun 25, 2023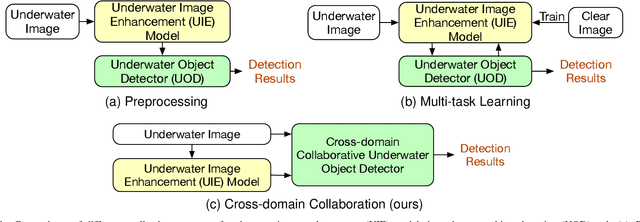
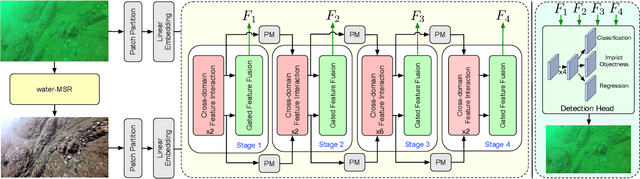
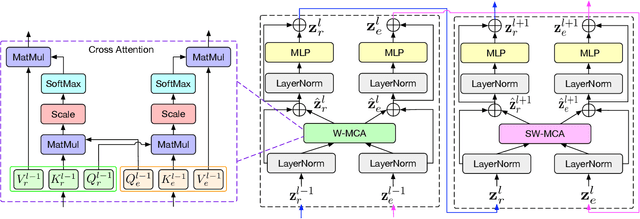

Underwater object detection (UOD) plays a significant role in aquaculture and marine environmental protection. Considering the challenges posed by low contrast and low-light conditions in underwater environments, several underwater image enhancement (UIE) methods have been proposed to improve the quality of underwater images. However, only using the enhanced images does not improve the performance of UOD, since it may unavoidably remove or alter critical patterns and details of underwater objects. In contrast, we believe that exploring the complementary information from the two domains is beneficial for UOD. The raw image preserves the natural characteristics of the scene and texture information of the objects, while the enhanced image improves the visibility of underwater objects. Based on this perspective, we propose a Gated Cross-domain Collaborative Network (GCC-Net) to address the challenges of poor visibility and low contrast in underwater environments, which comprises three dedicated components. Firstly, a real-time UIE method is employed to generate enhanced images, which can improve the visibility of objects in low-contrast areas. Secondly, a cross-domain feature interaction module is introduced to facilitate the interaction and mine complementary information between raw and enhanced image features. Thirdly, to prevent the contamination of unreliable generated results, a gated feature fusion module is proposed to adaptively control the fusion ratio of cross-domain information. Our method presents a new UOD paradigm from the perspective of cross-domain information interaction and fusion. Experimental results demonstrate that the proposed GCC-Net achieves state-of-the-art performance on four underwater datasets.