 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Marginal Thresholding in Noisy Image Segmentation
May 04, 2023
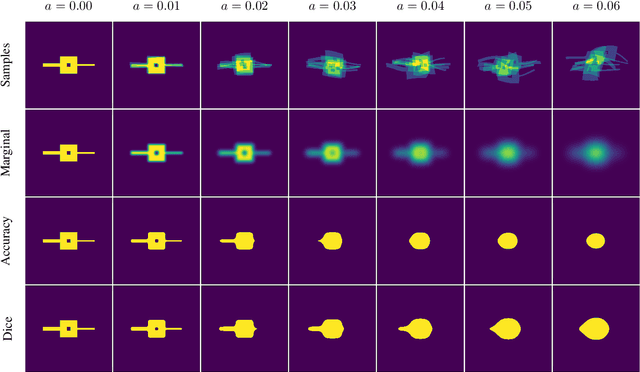
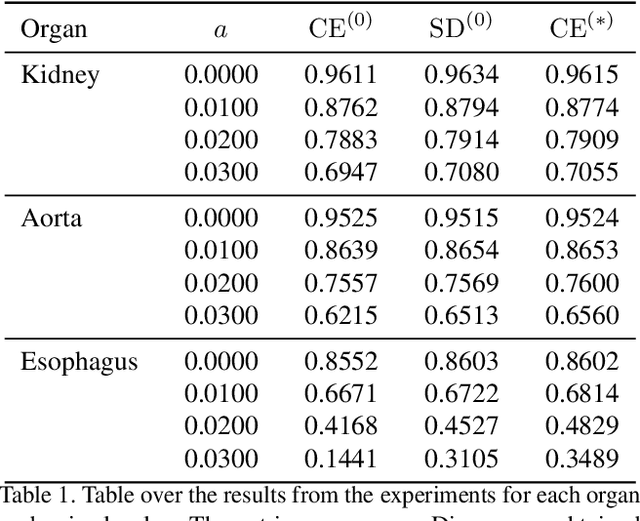
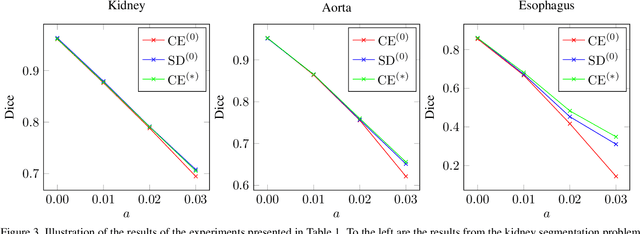
This work presents a study on label noise in medical image segmentation by considering a noise model based on Gaussian field deformations. Such noise is of interest because it yields realistic looking segmentations and because it is unbiased in the sense that the expected deformation is the identity mapping. Efficient methods for sampling and closed form solutions for the marginal probabilities are provided. Moreover, theoretically optimal solutions to the loss functions cross-entropy and soft-Dice are studied and it is shown how they diverge as the level of noise increases. Based on recent work on loss function characterization, it is shown that optimal solutions to soft-Dice can be recovered by thresholding solutions to cross-entropy with a particular a priori unknown threshold that efficiently can be computed. This raises the question whether the decrease in performance seen when using cross-entropy as compared to soft-Dice is caused by using the wrong threshold. The hypothesis is validated in 5-fold studies on three organ segmentation problems from the TotalSegmentor data set, using 4 different strengths of noise. The results show that changing the threshold leads the performance of cross-entropy to go from systematically worse than soft-Dice to similar or better results than soft-Dice.
Domain Generalization for Mammographic Image Analysis via Contrastive Learning
Apr 20, 2023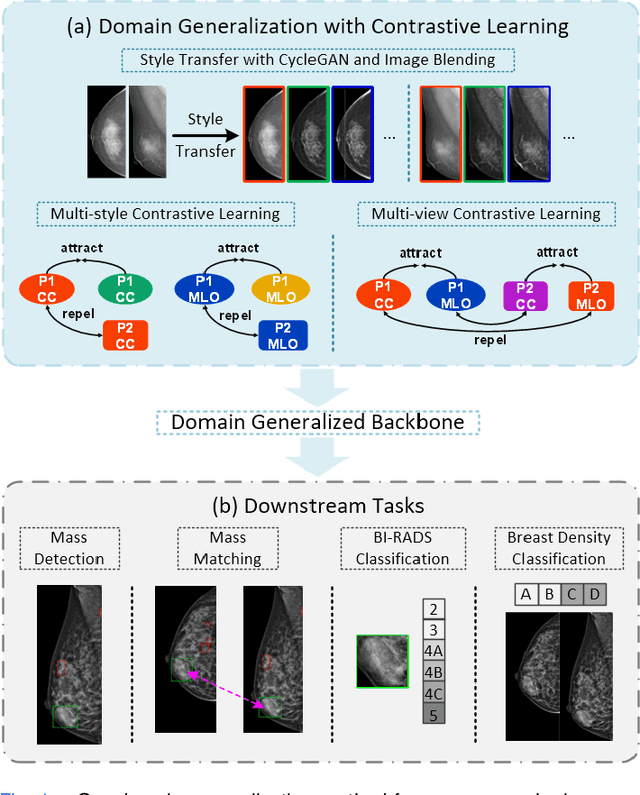
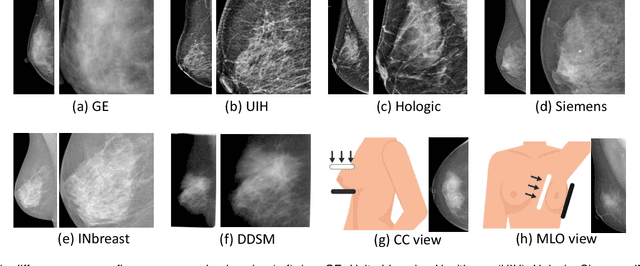

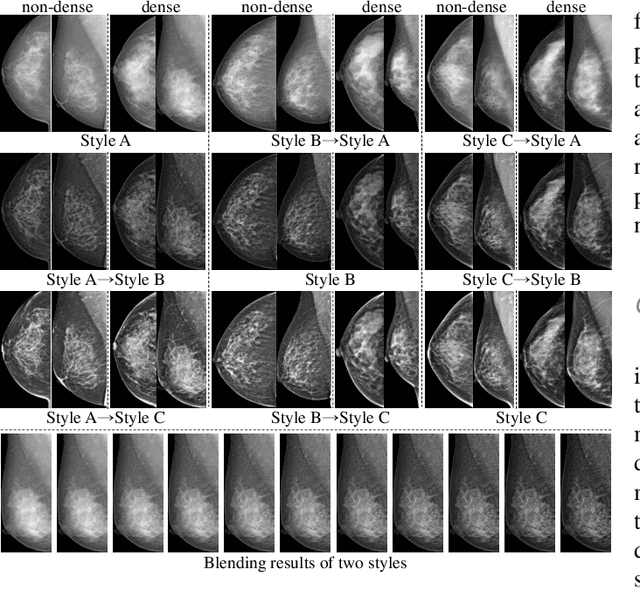
Mammographic image analysis is a fundamental problem in the computer-aided diagnosis scheme, which has recently made remarkable progress with the advance of deep learning. However, the construction of a deep learning model requires training data that are large and sufficiently diverse in terms of image style and quality. In particular, the diversity of image style may be majorly attributed to the vendor factor. However, mammogram collection from vendors as many as possible is very expensive and sometimes impractical for laboratory-scale studies. Accordingly, to further augment the generalization capability of deep learning models to various vendors with limited resources, a new contrastive learning scheme is developed. Specifically, the backbone network is firstly trained with a multi-style and multi-view unsupervised self-learning scheme for the embedding of invariant features to various vendor styles. Afterward, the backbone network is then recalibrated to the downstream tasks of mass detection, multi-view mass matching, BI-RADS classification and breast density classification with specific supervised learning. The proposed method is evaluated with mammograms from four vendors and two unseen public datasets. The experimental results suggest that our approach can effectively improve analysis performance on both seen and unseen domains, and outperforms many state-of-the-art (SOTA) generalization methods.
Long-Tailed Continual Learning For Visual Food Recognition
Jul 01, 2023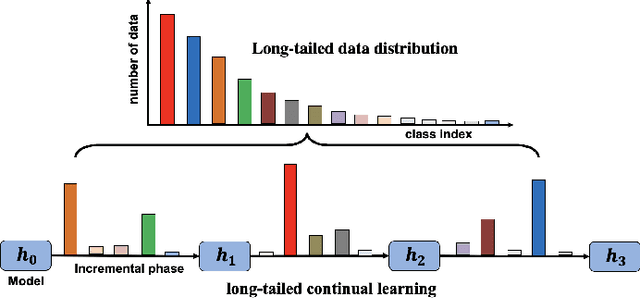
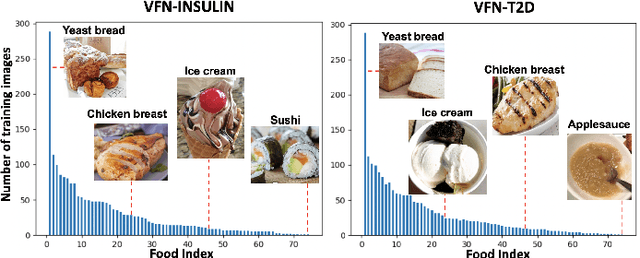
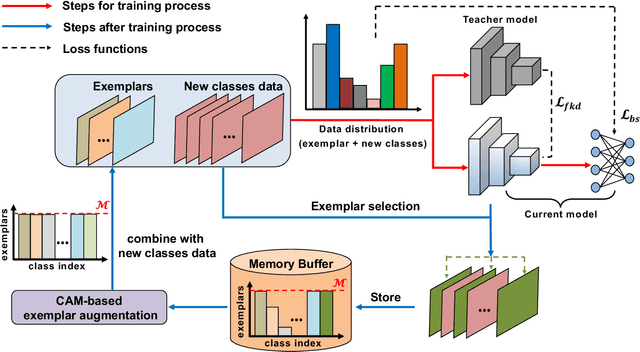
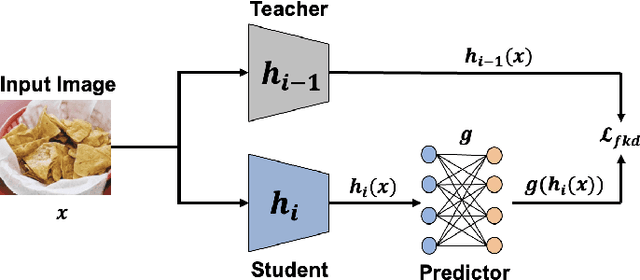
Deep learning based food recognition has achieved remarkable progress in predicting food types given an eating occasion image. However, there are two major obstacles that hinder deployment in real world scenario. First, as new foods appear sequentially overtime, a trained model needs to learn the new classes continuously without causing catastrophic forgetting for already learned knowledge of existing food types. Second, the distribution of food images in real life is usually long-tailed as a small number of popular food types are consumed more frequently than others, which can vary in different populations. This requires the food recognition method to learn from class-imbalanced data by improving the generalization ability on instance-rare food classes. In this work, we focus on long-tailed continual learning and aim to address both aforementioned challenges. As existing long-tailed food image datasets only consider healthy people population, we introduce two new benchmark food image datasets, VFN-INSULIN and VFN-T2D, which exhibits on the real world food consumption for insulin takers and individuals with type 2 diabetes without taking insulin, respectively. We propose a novel end-to-end framework for long-tailed continual learning, which effectively addresses the catastrophic forgetting by applying an additional predictor for knowledge distillation to avoid misalignment of representation during continual learning. We also introduce a novel data augmentation technique by integrating class-activation-map (CAM) and CutMix, which significantly improves the generalization ability for instance-rare food classes to address the class-imbalance issue. The proposed method show promising performance with large margin improvements compared with existing methods.
Spatio-Temporal Classification of Lung Ventilation Patterns using 3D EIT Images: A General Approach for Individualized Lung Function Evaluation
Jul 01, 2023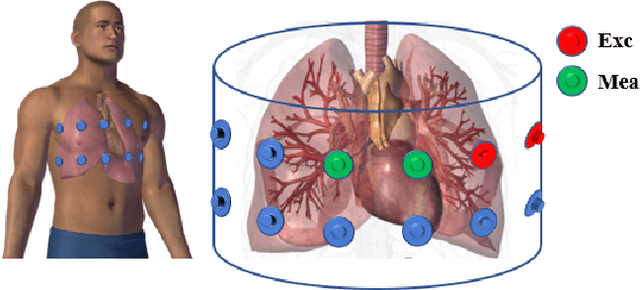
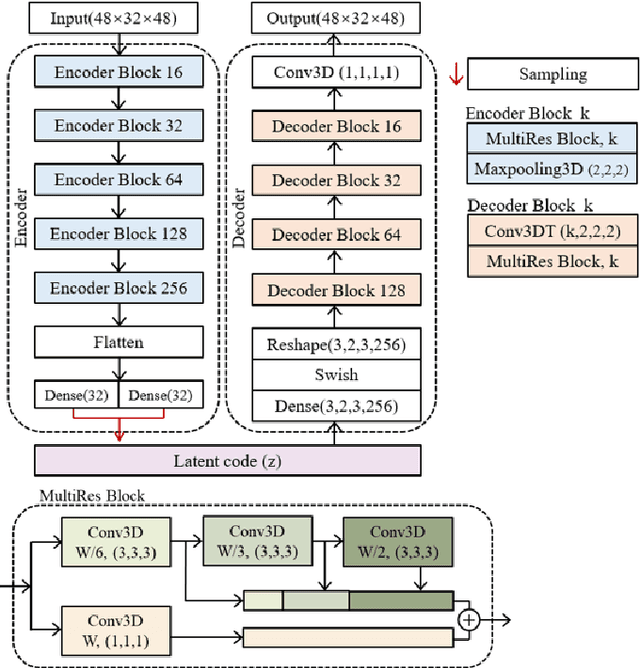
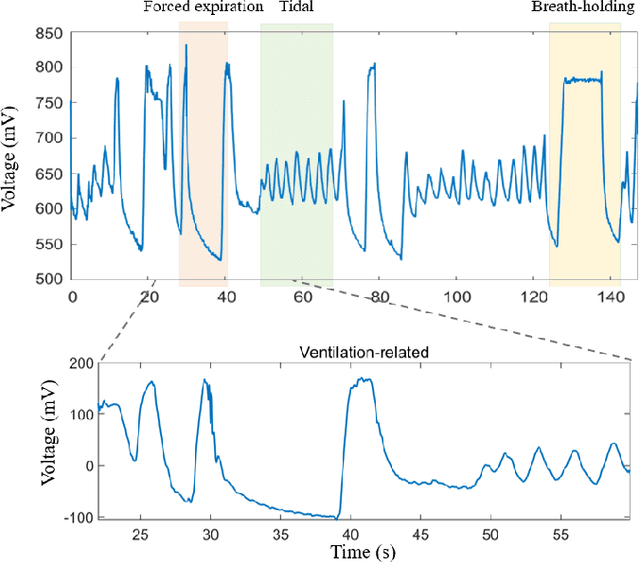
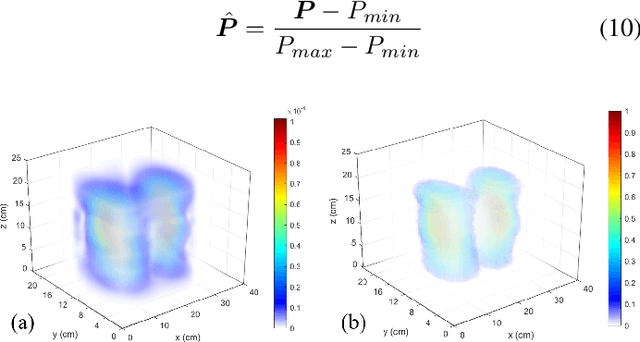
The Pulmonary Function Test (PFT) is an widely utilized and rigorous classification test for lung function evaluation, serving as a comprehensive tool for lung diagnosis. Meanwhile, Electrical Impedance Tomography (EIT) is a rapidly advancing clinical technique that visualizes conductivity distribution induced by ventilation. EIT provides additional spatial and temporal information on lung ventilation beyond traditional PFT. However, relying solely on conventional isolated interpretations of PFT results and EIT images overlooks the continuous dynamic aspects of lung ventilation. This study aims to classify lung ventilation patterns by extracting spatial and temporal features from the 3D EIT image series. The study uses a Variational Autoencoder network with a MultiRes block to compress the spatial distribution in a 3D image into a one-dimensional vector. These vectors are then concatenated to create a feature map for the exhibition of temporal features. A simple convolutional neural network is used for classification. Data collected from 137 subjects were finally used for training. The model is validated by ten-fold and leave-one-out cross-validation first. The accuracy and sensitivity of normal ventilation mode are 0.95 and 1.00, and the f1-score is 0.94. Furthermore, we check the reliability and feasibility of the proposed pipeline by testing it on newly recruited nine subjects. Our results show that the pipeline correctly predicts the ventilation mode of 8 out of 9 subjects. The study demonstrates the potential of using image series for lung ventilation mode classification, providing a feasible method for patient prescreening and presenting an alternative form of PFT.
Self-aware and Cross-sample Prototypical Learning for Semi-supervised Medical Image Segmentation
May 25, 2023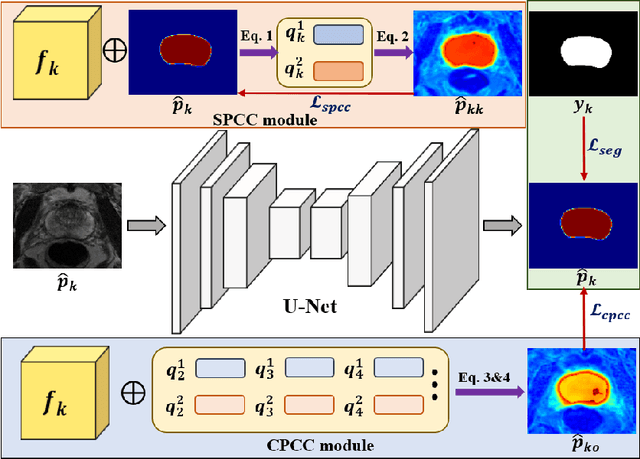
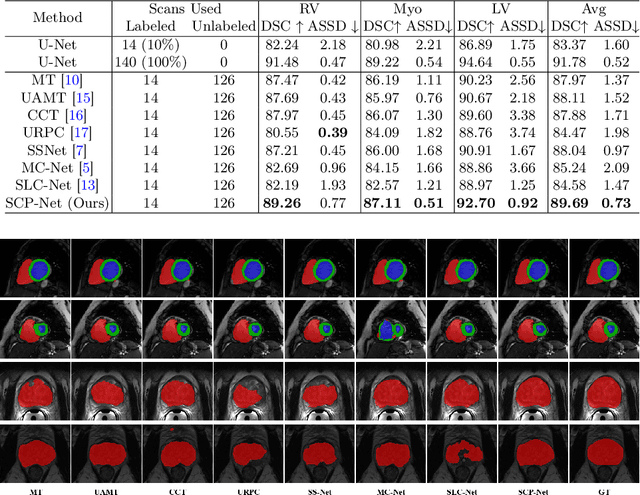
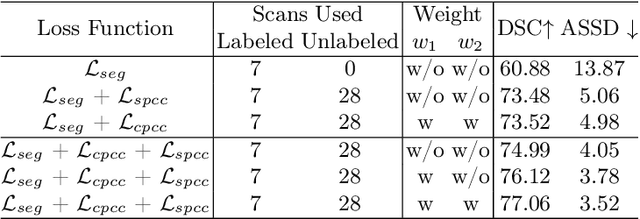
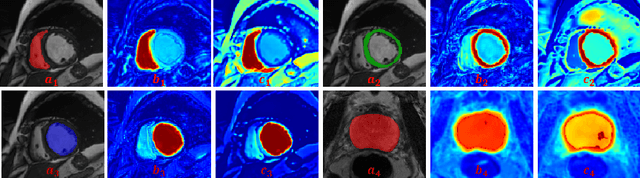
Consistency learning plays a crucial role in semi-supervised medical image segmentation as it enables the effective utilization of limited annotated data while leveraging the abundance of unannotated data. The effectiveness and efficiency of consistency learning are challenged by prediction diversity and training stability, which are often overlooked by existing studies. Meanwhile, the limited quantity of labeled data for training often proves inadequate for formulating intra-class compactness and inter-class discrepancy of pseudo labels. To address these issues, we propose a self-aware and cross-sample prototypical learning method (SCP-Net) to enhance the diversity of prediction in consistency learning by utilizing a broader range of semantic information derived from multiple inputs. Furthermore, we introduce a self-aware consistency learning method that exploits unlabeled data to improve the compactness of pseudo labels within each class. Moreover, a dual loss re-weighting method is integrated into the cross-sample prototypical consistency learning method to improve the reliability and stability of our model. Extensive experiments on ACDC dataset and PROMISE12 dataset validate that SCP-Net outperforms other state-of-the-art semi-supervised segmentation methods and achieves significant performance gains compared to the limited supervised training. Our code will come soon.
Prompting Diffusion Representations for Cross-Domain Semantic Segmentation
Jul 05, 2023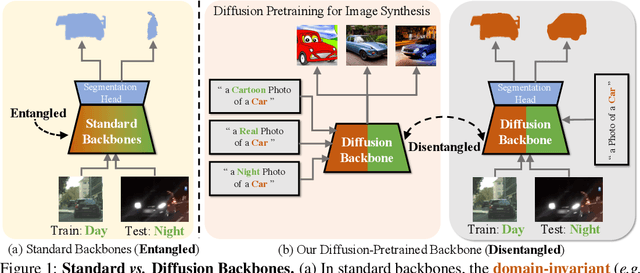

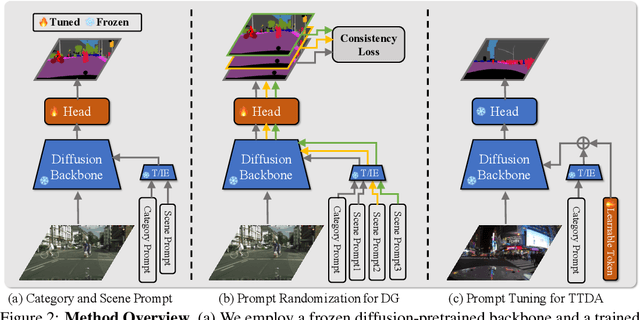
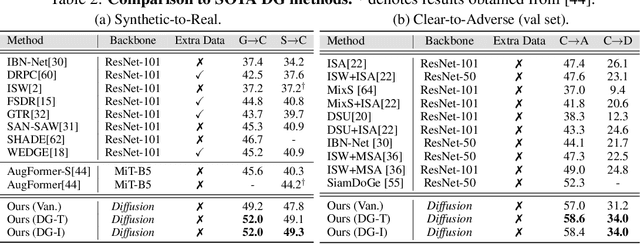
While originally designed for image generation, diffusion models have recently shown to provide excellent pretrained feature representations for semantic segmentation. Intrigued by this result, we set out to explore how well diffusion-pretrained representations generalize to new domains, a crucial ability for any representation. We find that diffusion-pretraining achieves extraordinary domain generalization results for semantic segmentation, outperforming both supervised and self-supervised backbone networks. Motivated by this, we investigate how to utilize the model's unique ability of taking an input prompt, in order to further enhance its cross-domain performance. We introduce a scene prompt and a prompt randomization strategy to help further disentangle the domain-invariant information when training the segmentation head. Moreover, we propose a simple but highly effective approach for test-time domain adaptation, based on learning a scene prompt on the target domain in an unsupervised manner. Extensive experiments conducted on four synthetic-to-real and clear-to-adverse weather benchmarks demonstrate the effectiveness of our approaches. Without resorting to any complex techniques, such as image translation, augmentation, or rare-class sampling, we set a new state-of-the-art on all benchmarks. Our implementation will be publicly available at \url{https://github.com/ETHRuiGong/PTDiffSeg}.
Robotic Sonographer: Autonomous Robotic Ultrasound using Domain Expertise in Bayesian Optimization
Jul 05, 2023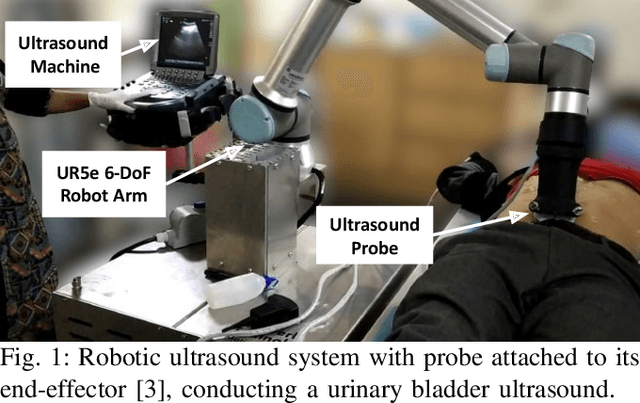
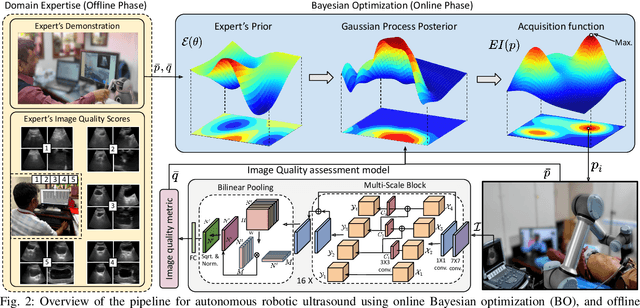
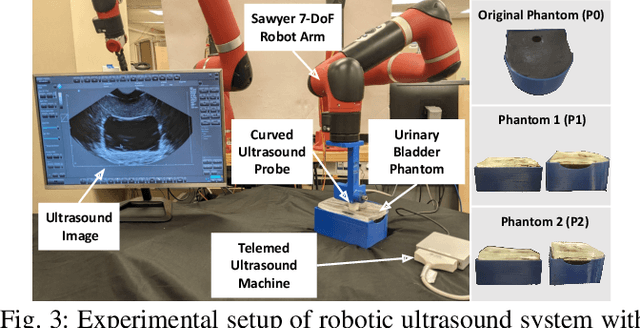
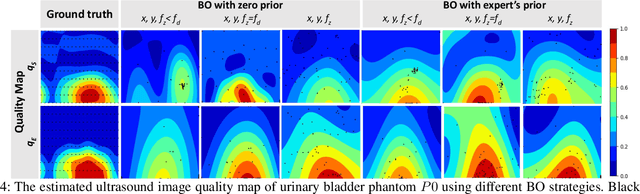
Ultrasound is a vital imaging modality utilized for a variety of diagnostic and interventional procedures. However, an expert sonographer is required to make accurate maneuvers of the probe over the human body while making sense of the ultrasound images for diagnostic purposes. This procedure requires a substantial amount of training and up to a few years of experience. In this paper, we propose an autonomous robotic ultrasound system that uses Bayesian Optimization (BO) in combination with the domain expertise to predict and effectively scan the regions where diagnostic quality ultrasound images can be acquired. The quality map, which is a distribution of image quality in a scanning region, is estimated using Gaussian process in BO. This relies on a prior quality map modeled using expert's demonstration of the high-quality probing maneuvers. The ultrasound image quality feedback is provided to BO, which is estimated using a deep convolution neural network model. This model was previously trained on database of images labelled for diagnostic quality by expert radiologists. Experiments on three different urinary bladder phantoms validated that the proposed autonomous ultrasound system can acquire ultrasound images for diagnostic purposes with a probing position and force accuracy of 98.7% and 97.8%, respectively.
Source Identification: A Self-Supervision Task for Dense Prediction
Jul 05, 2023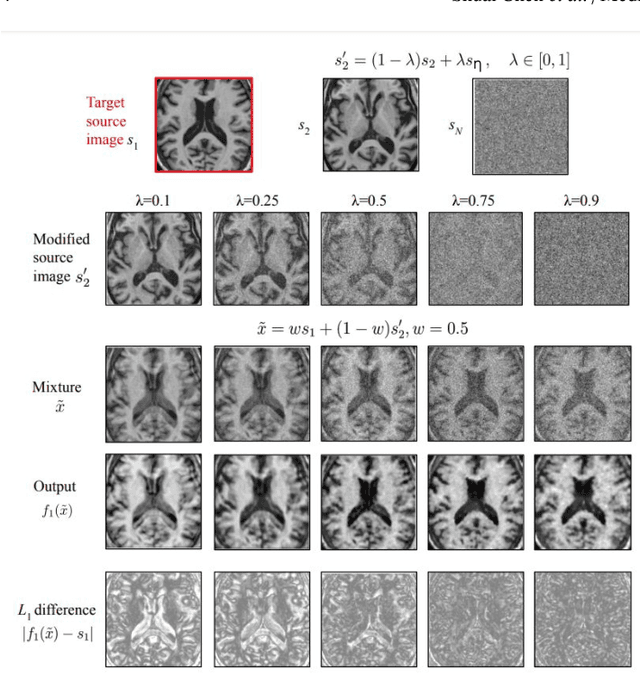
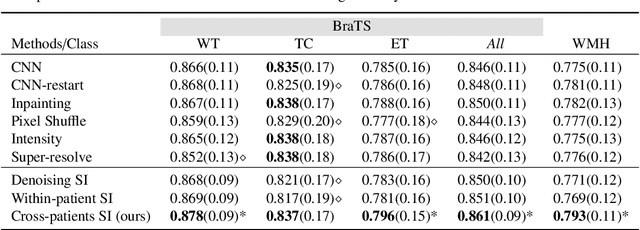
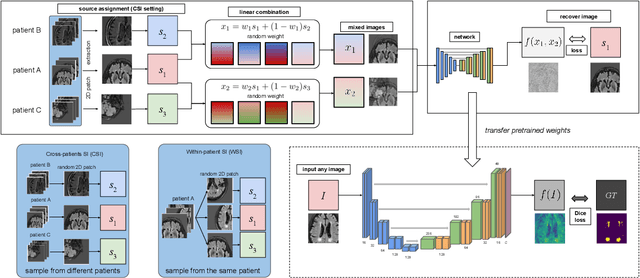
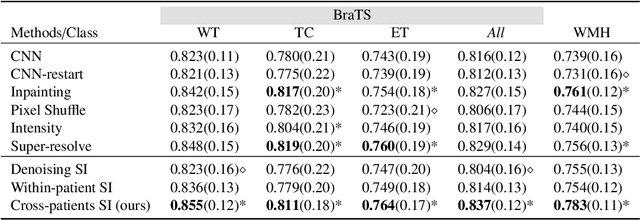
The paradigm of self-supervision focuses on representation learning from raw data without the need of labor-consuming annotations, which is the main bottleneck of current data-driven methods. Self-supervision tasks are often used to pre-train a neural network with a large amount of unlabeled data and extract generic features of the dataset. The learned model is likely to contain useful information which can be transferred to the downstream main task and improve performance compared to random parameter initialization. In this paper, we propose a new self-supervision task called source identification (SI), which is inspired by the classic blind source separation problem. Synthetic images are generated by fusing multiple source images and the network's task is to reconstruct the original images, given the fused images. A proper understanding of the image content is required to successfully solve the task. We validate our method on two medical image segmentation tasks: brain tumor segmentation and white matter hyperintensities segmentation. The results show that the proposed SI task outperforms traditional self-supervision tasks for dense predictions including inpainting, pixel shuffling, intensity shift, and super-resolution. Among variations of the SI task fusing images of different types, fusing images from different patients performs best.
Optimizing PatchCore for Few/many-shot Anomaly Detection
Jul 20, 2023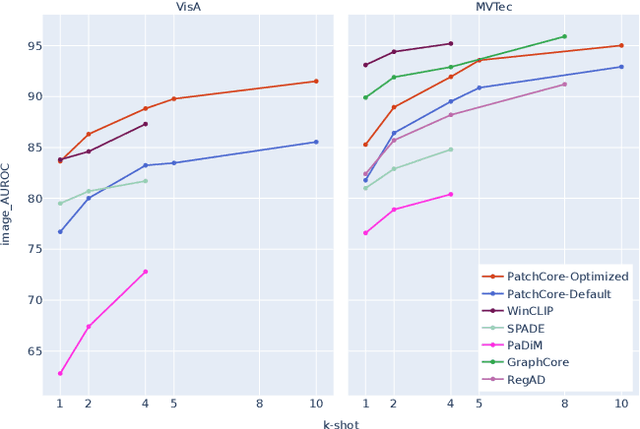
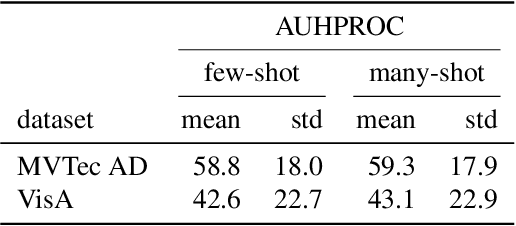
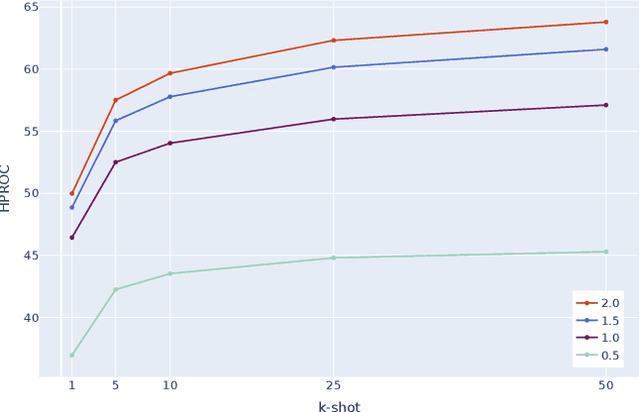
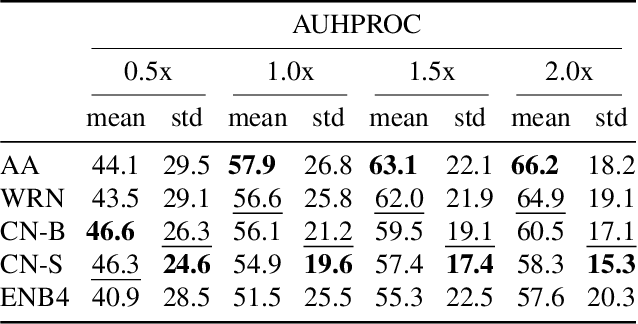
Few-shot anomaly detection (AD) is an emerging sub-field of general AD, and tries to distinguish between normal and anomalous data using only few selected samples. While newly proposed few-shot AD methods do compare against pre-existing algorithms developed for the full-shot domain as baselines, they do not dedicatedly optimize them for the few-shot setting. It thus remains unclear if the performance of such pre-existing algorithms can be further improved. We address said question in this work. Specifically, we present a study on the AD/anomaly segmentation (AS) performance of PatchCore, the current state-of-the-art full-shot AD/AS algorithm, in both the few-shot and the many-shot settings. We hypothesize that further performance improvements can be realized by (I) optimizing its various hyperparameters, and by (II) transferring techniques known to improve few-shot supervised learning to the AD domain. Exhaustive experiments on the public VisA and MVTec AD datasets reveal that (I) significant performance improvements can be realized by optimizing hyperparameters such as the underlying feature extractor, and that (II) image-level augmentations can, but are not guaranteed, to improve performance. Based on these findings, we achieve a new state of the art in few-shot AD on VisA, further demonstrating the merit of adapting pre-existing AD/AS methods to the few-shot setting. Last, we identify the investigation of feature extractors with a strong inductive bias as a potential future research direction for (few-shot) AD/AS.
Solving Diffusion ODEs with Optimal Boundary Conditions for Better Image Super-Resolution
May 24, 2023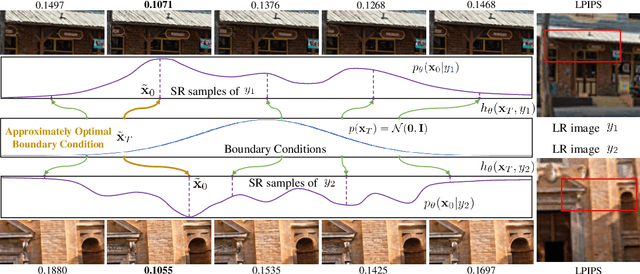
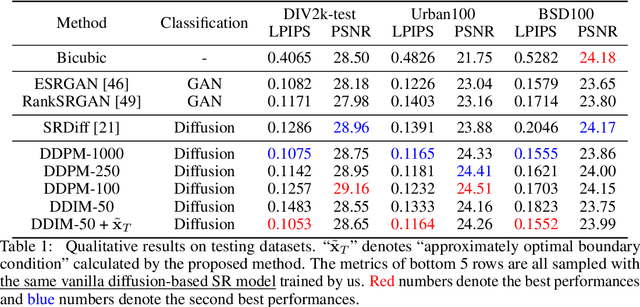
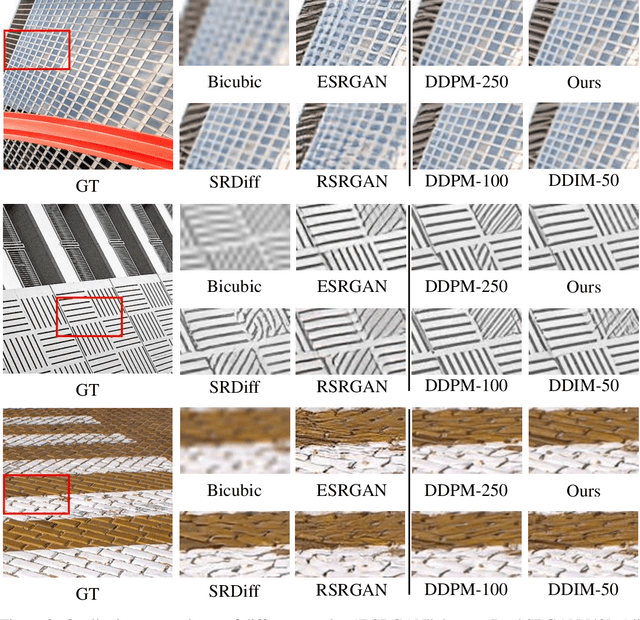
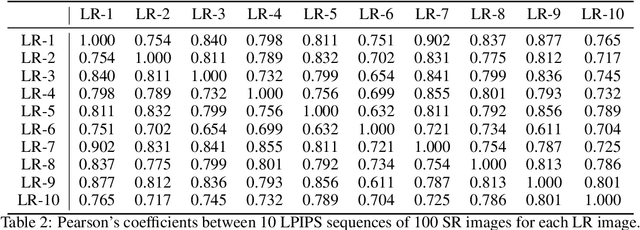
Diffusion models, as a kind of powerful generative model, have given impressive results on image super-resolution (SR) tasks. However, due to the randomness introduced in the reverse process of diffusion models, the performances of diffusion-based SR models are fluctuating at every time of sampling, especially for samplers with few resampled steps. This inherent randomness of diffusion models results in ineffectiveness and instability, making it challenging for users to guarantee the quality of SR results. However, our work takes this randomness as an opportunity: fully analyzing and leveraging it leads to the construction of an effective plug-and-play sampling method that owns the potential to benefit a series of diffusion-based SR methods. More in detail, we propose to steadily sample high-quality SR images from pretrained diffusion-based SR models by solving diffusion ordinary differential equations (diffusion ODEs) with optimal boundary conditions (BCs) and analyze the characteristics between the choices of BCs and their corresponding SR results. Our analysis shows the route to obtain an approximately optimal BC via an efficient exploration in the whole space. The quality of SR results sampled by the proposed method with fewer steps outperforms the quality of results sampled by current methods with randomness from the same pretrained diffusion-based SR model, which means that our sampling method ``boosts'' current diffusion-based SR models without any additional training.