 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An X3D Neural Network Analysis for Runner's Performance Assessment in a Wild Sporting Environment
Jul 22, 2023
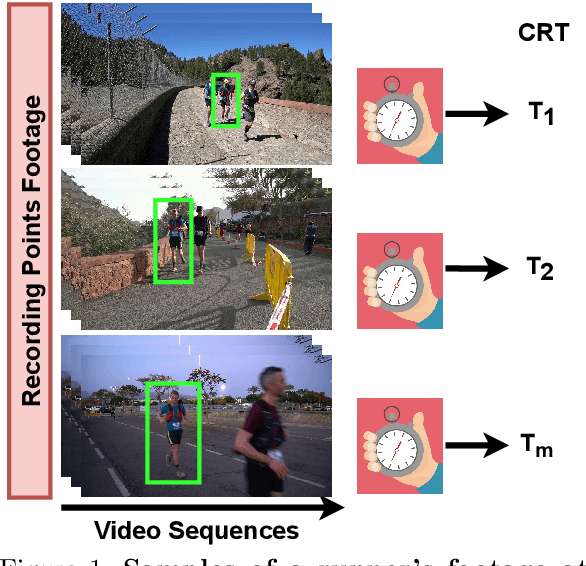
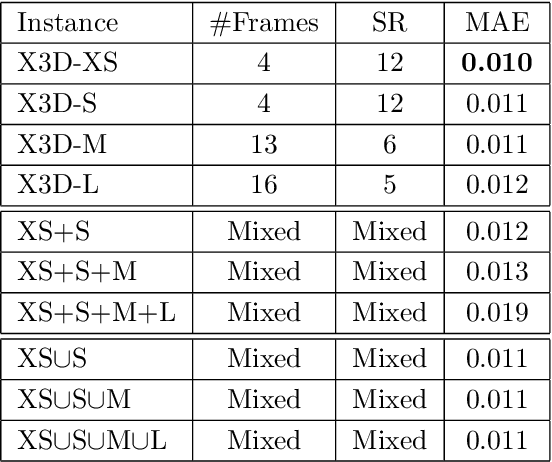
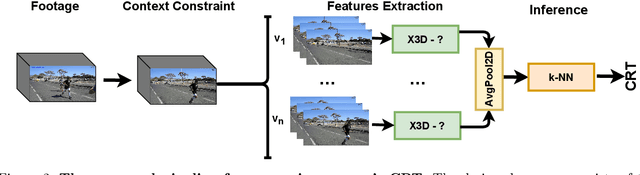
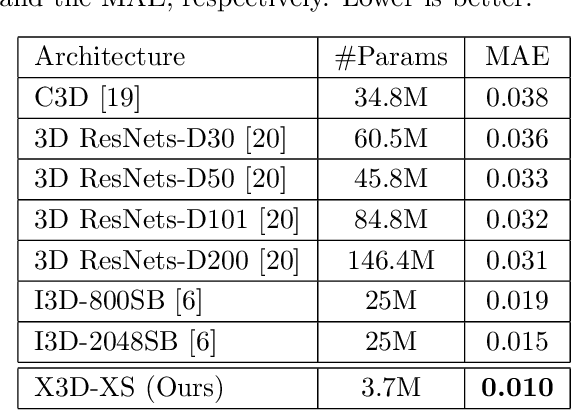
We present a transfer learning analysis on a sporting environment of the expanded 3D (X3D) neural networks. Inspired by action quality assessment methods in the literature, our method uses an action recognition network to estimate athletes' cumulative race time (CRT) during an ultra-distance competition. We evaluate the performance considering the X3D, a family of action recognition networks that expand a small 2D image classification architecture along multiple network axes, including space, time, width, and depth. We demonstrate that the resulting neural network can provide remarkable performance for short input footage, with a mean absolute error of 12 minutes and a half when estimating the CRT for runners who have been active from 8 to 20 hours. Our most significant discovery is that X3D achieves state-of-the-art performance while requiring almost seven times less memory to achieve better precision than previous work.
Multi-code deep image prior based plug-and-play ADMM for image denoising and CT reconstruction
Apr 12, 2023

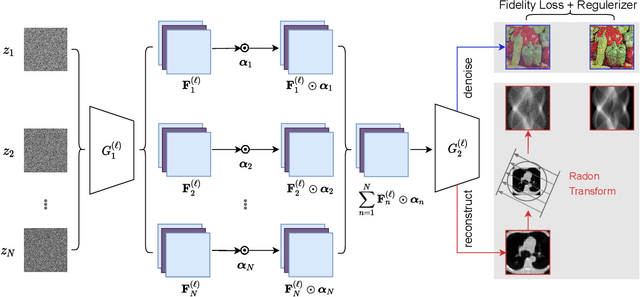

The use of the convolutional neural network based prior in imaging inverse problems has become increasingly popular. Current state-of-the-art methods, however, can easily result in severe overfitting, which makes a number of early stopping techniques necessary to eliminate the overfitting problem. To motivate our work, we review some existing approaches to image priors. We find that the deep image prior in combined with the handcrafted prior has an outstanding performance in terms of interpretability and representability. We propose a multi-code deep image prior, a multiple latent codes variant of the deep image prior, which can be utilized to eliminate overfitting and is also robust to the different numbers of the latent codes. Due to the non-differentiability of the handcrafted prior, we use the alternative direction method of multipliers (ADMM) algorithm. We compare the performance of the proposed method on an image denoising problem and a highly ill-posed CT reconstruction problem against the existing state-of-the-art methods, including PnP-DIP, DIP-VBTV and ADMM DIP-WTV methods. For the CelebA dataset denoising, we obtain 1.46 dB peak signal to noise ratio improvement against all compared methods. For the CT reconstruction, the corresponding average improvement of three test images is 4.3 dB over DIP, and 1.7 dB over ADMM DIP-WTV, and 1.2 dB over PnP-DIP along with a significant improvement in the structural similarity index.
Model Calibration in Dense Classification with Adaptive Label Perturbation
Jul 25, 2023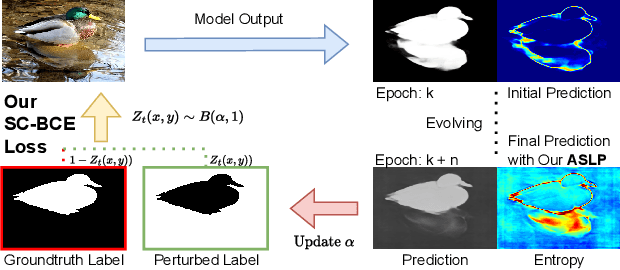
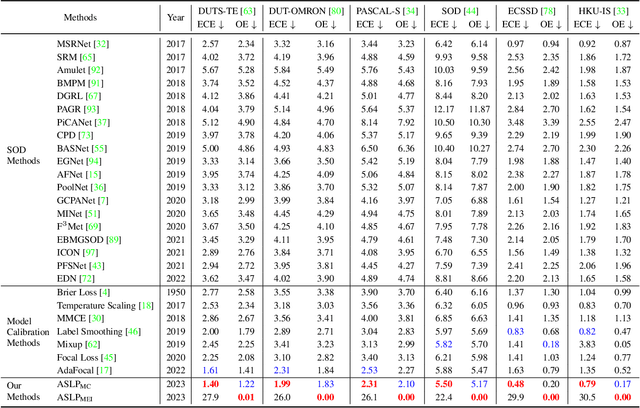
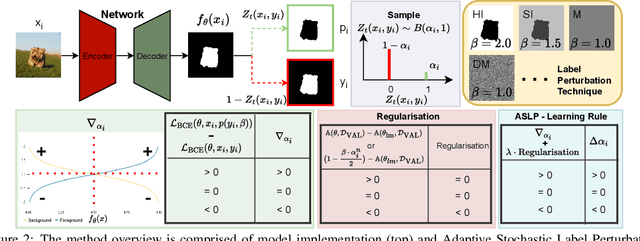
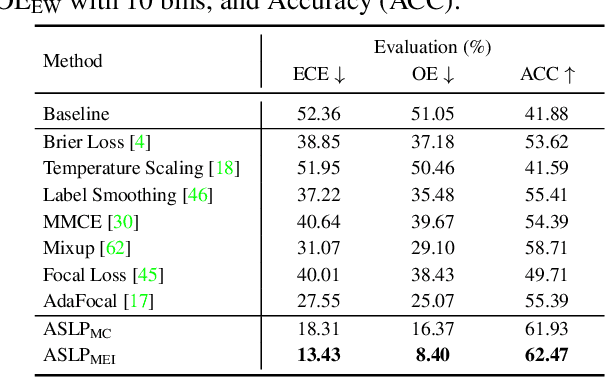
For safety-related applications, it is crucial to produce trustworthy deep neural networks whose prediction is associated with confidence that can represent the likelihood of correctness for subsequent decision-making. Existing dense binary classification models are prone to being over-confident. To improve model calibration, we propose Adaptive Stochastic Label Perturbation (ASLP) which learns a unique label perturbation level for each training image. ASLP employs our proposed Self-Calibrating Binary Cross Entropy (SC-BCE) loss, which unifies label perturbation processes including stochastic approaches (like DisturbLabel), and label smoothing, to correct calibration while maintaining classification rates. ASLP follows Maximum Entropy Inference of classic statistical mechanics to maximise prediction entropy with respect to missing information. It performs this while: (1) preserving classification accuracy on known data as a conservative solution, or (2) specifically improves model calibration degree by minimising the gap between the prediction accuracy and expected confidence of the target training label. Extensive results demonstrate that ASLP can significantly improve calibration degrees of dense binary classification models on both in-distribution and out-of-distribution data. The code is available on https://github.com/Carlisle-Liu/ASLP.
Occupancy Grid Mapping without Ray-Casting for High-resolution LiDAR Sensors
Jul 17, 2023Occupancy mapping is a fundamental component of robotic systems to reason about the unknown and known regions of the environment. This article presents an efficient occupancy mapping framework for high-resolution LiDAR sensors, termed D-Map. The framework introduces three main novelties to address the computational efficiency challenges of occupancy mapping. Firstly, we use a depth image to determine the occupancy state of regions instead of the traditional ray-casting method. Secondly, we introduce an efficient on-tree update strategy on a tree-based map structure. These two techniques avoid redundant visits to small cells, significantly reducing the number of cells to be updated. Thirdly, we remove known cells from the map at each update by leveraging the low false alarm rate of LiDAR sensors. This approach not only enhances our framework's update efficiency by reducing map size but also endows it with an interesting decremental property, which we have named D-Map. To support our design, we provide theoretical analyses of the accuracy of the depth image projection and time complexity of occupancy updates. Furthermore, we conduct extensive benchmark experiments on various LiDAR sensors in both public and private datasets. Our framework demonstrates superior efficiency in comparison with other state-of-the-art methods while maintaining comparable mapping accuracy and high memory efficiency. We demonstrate two real-world applications of D-Map for real-time occupancy mapping on a handle device and an aerial platform carrying a high-resolution LiDAR. In addition, we open-source the implementation of D-Map on GitHub to benefit society: github.com/hku-mars/D-Map.
D2S: Representing local descriptors and global scene coordinates for camera relocalization
Jul 28, 2023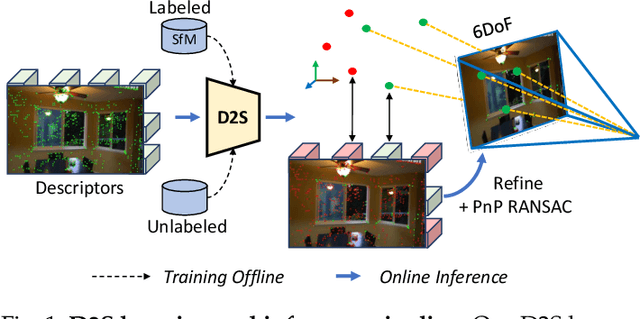
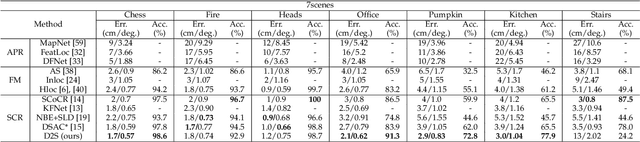
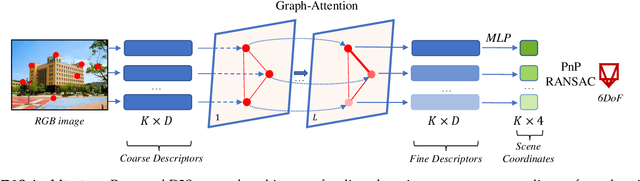

State-of-the-art visual localization methods mostly rely on complex procedures to match local descriptors and 3D point clouds. However, these procedures can incur significant cost in terms of inference, storage, and updates over time. In this study, we propose a direct learning-based approach that utilizes a simple network named D2S to represent local descriptors and their scene coordinates. Our method is characterized by its simplicity and cost-effectiveness. It solely leverages a single RGB image for localization during the testing phase and only requires a lightweight model to encode a complex sparse scene. The proposed D2S employs a combination of a simple loss function and graph attention to selectively focus on robust descriptors while disregarding areas such as clouds, trees, and several dynamic objects. This selective attention enables D2S to effectively perform a binary-semantic classification for sparse descriptors. Additionally, we propose a new outdoor dataset to evaluate the capabilities of visual localization methods in terms of scene generalization and self-updating from unlabeled observations. Our approach outperforms the state-of-the-art CNN-based methods in scene coordinate regression in indoor and outdoor environments. It demonstrates the ability to generalize beyond training data, including scenarios involving transitions from day to night and adapting to domain shifts, even in the absence of the labeled data sources. The source code, trained models, dataset, and demo videos are available at the following link: https://thpjp.github.io/d2s
SSL-CPCD: Self-supervised learning with composite pretext-class discrimination for improved generalisability in endoscopic image analysis
May 31, 2023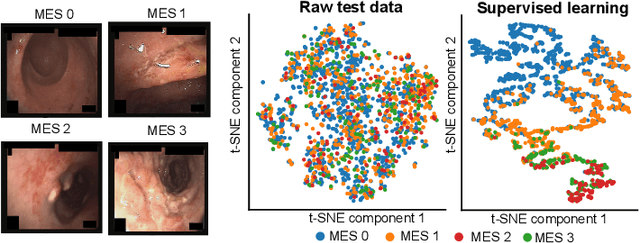
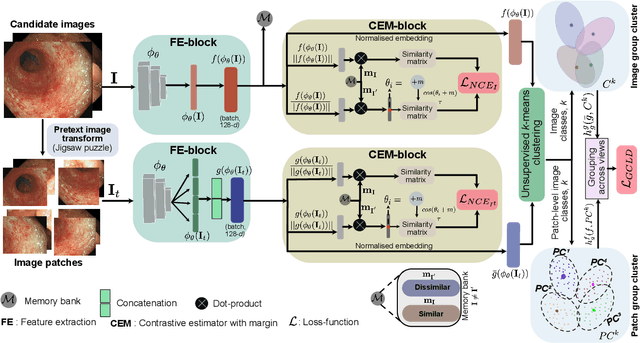
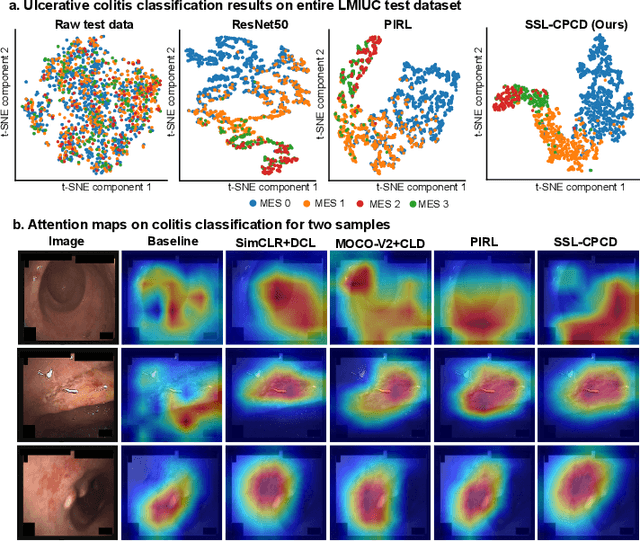
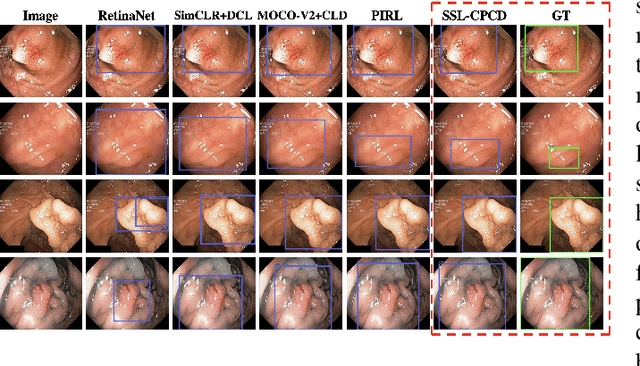
Data-driven methods have shown tremendous progress in medical image analysis. In this context, deep learning-based supervised methods are widely popular. However, they require a large amount of training data and face issues in generalisability to unseen datasets that hinder clinical translation. Endoscopic imaging data incorporates large inter- and intra-patient variability that makes these models more challenging to learn representative features for downstream tasks. Thus, despite the publicly available datasets and datasets that can be generated within hospitals, most supervised models still underperform. While self-supervised learning has addressed this problem to some extent in natural scene data, there is a considerable performance gap in the medical image domain. In this paper, we propose to explore patch-level instance-group discrimination and penalisation of inter-class variation using additive angular margin within the cosine similarity metrics. Our novel approach enables models to learn to cluster similar representative patches, thereby improving their ability to provide better separation between different classes. Our results demonstrate significant improvement on all metrics over the state-of-the-art (SOTA) methods on the test set from the same and diverse datasets. We evaluated our approach for classification, detection, and segmentation. SSL-CPCD achieves 79.77% on Top 1 accuracy for ulcerative colitis classification, 88.62% on mAP for polyp detection, and 82.32% on dice similarity coefficient for segmentation tasks are nearly over 4%, 2%, and 3%, respectively, compared to the baseline architectures. We also demonstrate that our method generalises better than all SOTA methods to unseen datasets, reporting nearly 7% improvement in our generalisability assessment.
Keystroke Dynamics for User Identification
Jul 07, 2023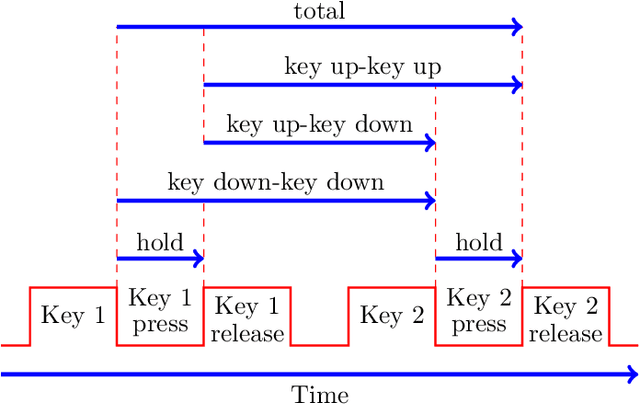

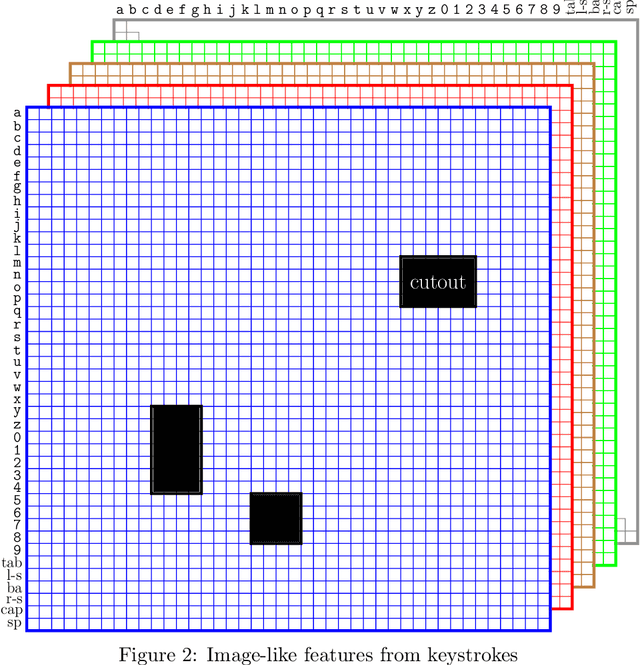

In previous research, keystroke dynamics has shown promise for user authentication, based on both fixed-text and free-text data. In this research, we consider the more challenging multiclass user identification problem, based on free-text data. We experiment with a complex image-like feature that has previously been used to achieve state-of-the-art authentication results over free-text data. Using this image-like feature and multiclass Convolutional Neural Networks, we are able to obtain a classification (i.e., identification) accuracy of 0.78 over a set of 148 users. However, we find that a Random Forest classifier trained on a slightly modified version of this same feature yields an accuracy of 0.93.
Improving Semi-Supervised Semantic Segmentation with Dual-Level Siamese Structure Network
Jul 26, 2023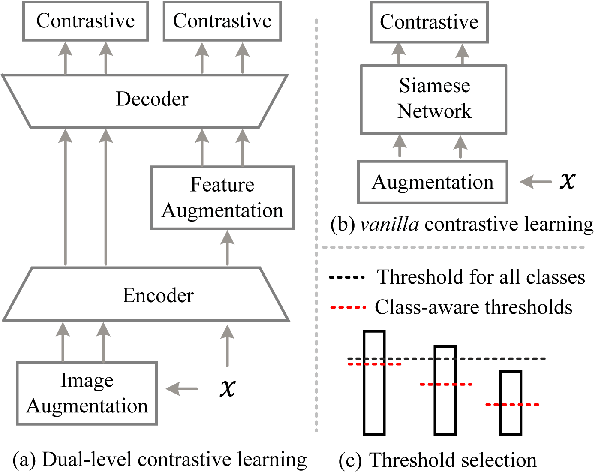
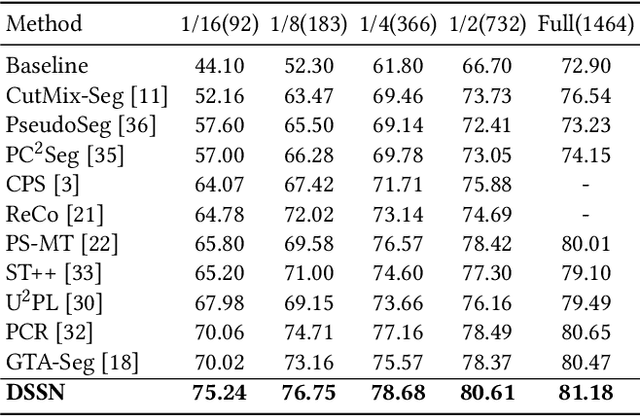
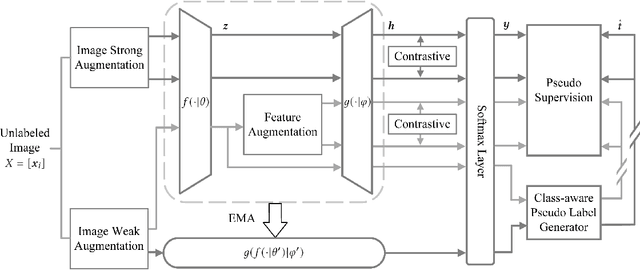
Semi-supervised semantic segmentation (SSS) is an important task that utilizes both labeled and unlabeled data to reduce expenses on labeling training examples. However, the effectiveness of SSS algorithms is limited by the difficulty of fully exploiting the potential of unlabeled data. To address this, we propose a dual-level Siamese structure network (DSSN) for pixel-wise contrastive learning. By aligning positive pairs with a pixel-wise contrastive loss using strong augmented views in both low-level image space and high-level feature space, the proposed DSSN is designed to maximize the utilization of available unlabeled data. Additionally, we introduce a novel class-aware pseudo-label selection strategy for weak-to-strong supervision, which addresses the limitations of most existing methods that do not perform selection or apply a predefined threshold for all classes. Specifically, our strategy selects the top high-confidence prediction of the weak view for each class to generate pseudo labels that supervise the strong augmented views. This strategy is capable of taking into account the class imbalance and improving the performance of long-tailed classes. Our proposed method achieves state-of-the-art results on two datasets, PASCAL VOC 2012 and Cityscapes, outperforming other SSS algorithms by a significant margin.
* ACM MM 2023 accpeted
Memory-Efficient Graph Convolutional Networks for Object Classification and Detection with Event Cameras
Jul 26, 2023
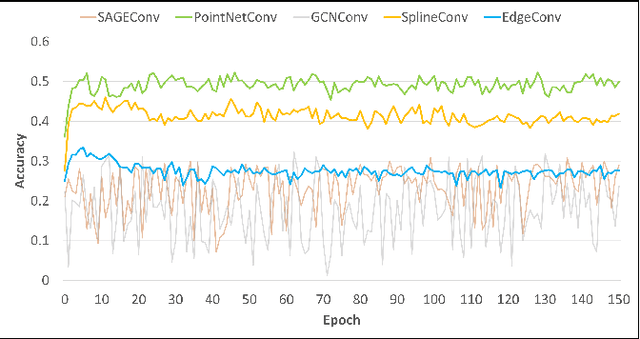

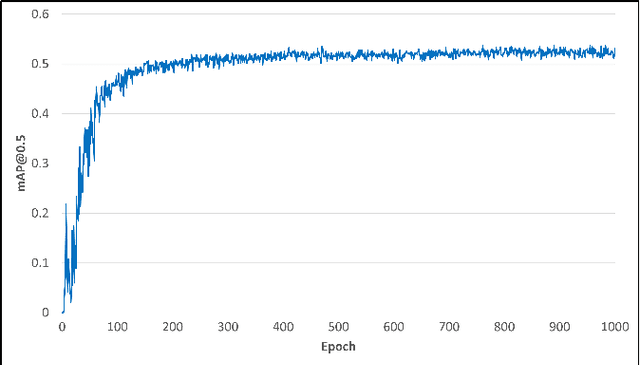
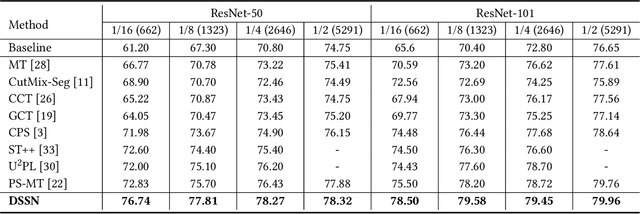
Recent advances in event camera research emphasize processing data in its original sparse form, which allows the use of its unique features such as high temporal resolution, high dynamic range, low latency, and resistance to image blur. One promising approach for analyzing event data is through graph convolutional networks (GCNs). However, current research in this domain primarily focuses on optimizing computational costs, neglecting the associated memory costs. In this paper, we consider both factors together in order to achieve satisfying results and relatively low model complexity. For this purpose, we performed a comparative analysis of different graph convolution operations, considering factors such as execution time, the number of trainable model parameters, data format requirements, and training outcomes. Our results show a 450-fold reduction in the number of parameters for the feature extraction module and a 4.5-fold reduction in the size of the data representation while maintaining a classification accuracy of 52.3%, which is 6.3% higher compared to the operation used in state-of-the-art approaches. To further evaluate performance, we implemented the object detection architecture and evaluated its performance on the N-Caltech101 dataset. The results showed an accuracy of 53.7 % mAP@0.5 and reached an execution rate of 82 graphs per second.
RCM-Fusion: Radar-Camera Multi-Level Fusion for 3D Object Detection
Jul 27, 2023
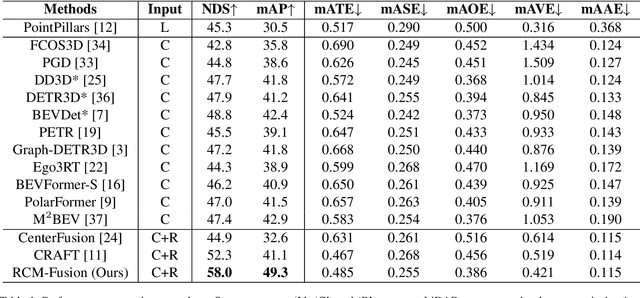
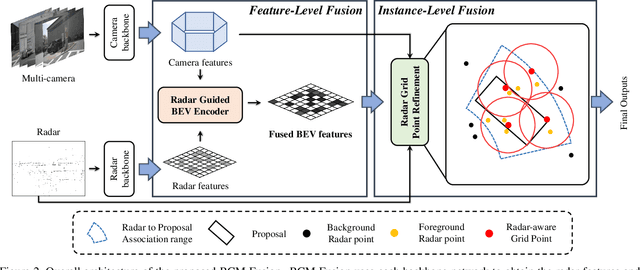
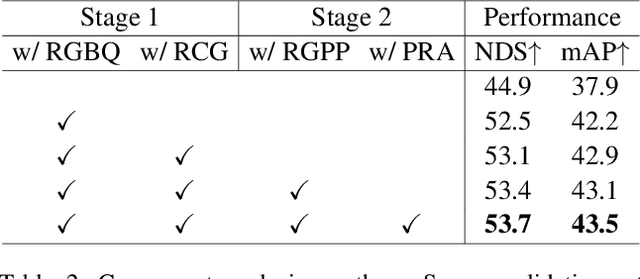
While LiDAR sensors have been succesfully applied to 3D object detection, the affordability of radar and camera sensors has led to a growing interest in fusiong radars and cameras for 3D object detection. However, previous radar-camera fusion models have not been able to fully utilize radar information in that initial 3D proposals were generated based on the camera features only and the instance-level fusion is subsequently conducted. In this paper, we propose radar-camera multi-level fusion (RCM-Fusion), which fuses radar and camera modalities at both the feature-level and instance-level to fully utilize radar information. At the feature-level, we propose a Radar Guided BEV Encoder which utilizes radar Bird's-Eye-View (BEV) features to transform image features into precise BEV representations and then adaptively combines the radar and camera BEV features. At the instance-level, we propose a Radar Grid Point Refinement module that reduces localization error by considering the characteristics of the radar point clouds. The experiments conducted on the public nuScenes dataset demonstrate that our proposed RCM-Fusion offers 11.8% performance gain in nuScenes detection score (NDS) over the camera-only baseline model and achieves state-of-the-art performaces among radar-camera fusion methods in the nuScenes 3D object detection benchmark. Code will be made publicly available.