 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Do DL models and training environments have an impact on energy consumption?
Jul 18, 2023
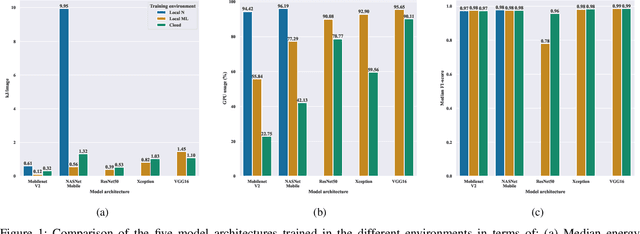
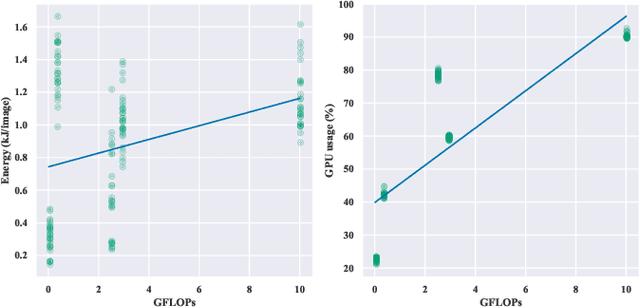
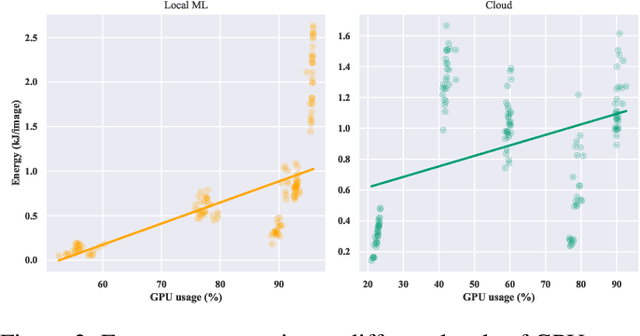
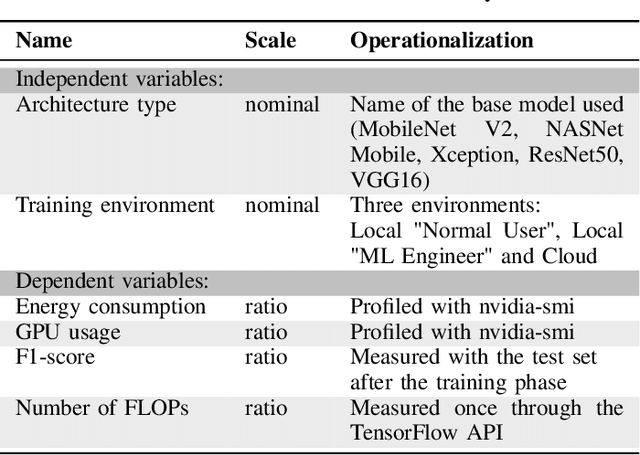
Current research in the computer vision field mainly focuses on improving Deep Learning (DL) correctness and inference time performance. However, there is still little work on the huge carbon footprint that has training DL models. This study aims to analyze the impact of the model architecture and training environment when training greener computer vision models. We divide this goal into two research questions. First, we analyze the effects of model architecture on achieving greener models while keeping correctness at optimal levels. Second, we study the influence of the training environment on producing greener models. To investigate these relationships, we collect multiple metrics related to energy efficiency and model correctness during the models' training. Then, we outline the trade-offs between the measured energy efficiency and the models' correctness regarding model architecture, and their relationship with the training environment. We conduct this research in the context of a computer vision system for image classification. In conclusion, we show that selecting the proper model architecture and training environment can reduce energy consumption dramatically (up to 98.83%) at the cost of negligible decreases in correctness. Also, we find evidence that GPUs should scale with the models' computational complexity for better energy efficiency.
Balancing Privacy and Progress in Artificial Intelligence: Anonymization in Histopathology for Biomedical Research and Education
Jul 18, 2023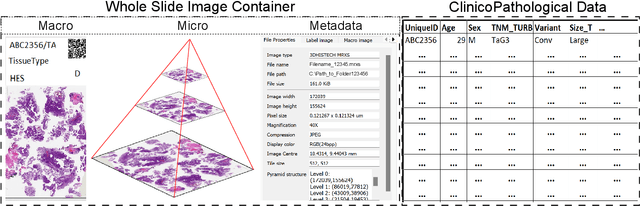
The advancement of biomedical research heavily relies on access to large amounts of medical data. In the case of histopathology, Whole Slide Images (WSI) and clinicopathological information are valuable for developing Artificial Intelligence (AI) algorithms for Digital Pathology (DP). Transferring medical data "as open as possible" enhances the usability of the data for secondary purposes but poses a risk to patient privacy. At the same time, existing regulations push towards keeping medical data "as closed as necessary" to avoid re-identification risks. Generally, these legal regulations require the removal of sensitive data but do not consider the possibility of data linkage attacks due to modern image-matching algorithms. In addition, the lack of standardization in DP makes it harder to establish a single solution for all formats of WSIs. These challenges raise problems for bio-informatics researchers in balancing privacy and progress while developing AI algorithms. This paper explores the legal regulations and terminologies for medical data-sharing. We review existing approaches and highlight challenges from the histopathological perspective. We also present a data-sharing guideline for histological data to foster multidisciplinary research and education.
Linearized Relative Positional Encoding
Jul 18, 2023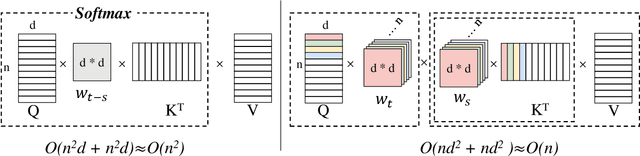
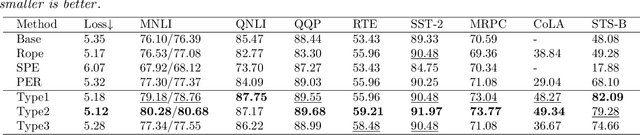

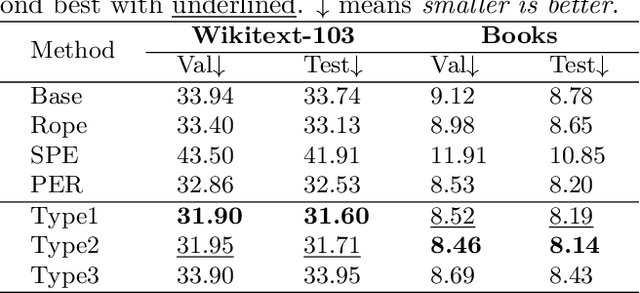
Relative positional encoding is widely used in vanilla and linear transformers to represent positional information. However, existing encoding methods of a vanilla transformer are not always directly applicable to a linear transformer, because the latter requires a decomposition of the query and key representations into separate kernel functions. Nevertheless, principles for designing encoding methods suitable for linear transformers remain understudied. In this work, we put together a variety of existing linear relative positional encoding approaches under a canonical form and further propose a family of linear relative positional encoding algorithms via unitary transformation. Our formulation leads to a principled framework that can be used to develop new relative positional encoding methods that preserve linear space-time complexity. Equipped with different models, the proposed linearized relative positional encoding (LRPE) family derives effective encoding for various applications. Experiments show that compared with existing methods, LRPE achieves state-of-the-art performance in language modeling, text classification, and image classification. Meanwhile, it emphasizes a general paradigm for designing broadly more relative positional encoding methods that are applicable to linear transformers. The code is available at https://github.com/OpenNLPLab/Lrpe.
Improving Prototypical Part Networks with Reward Reweighing, Reselection, and Retraining
Jul 08, 2023
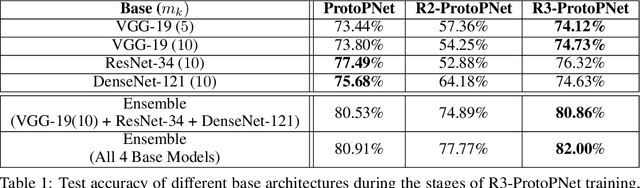
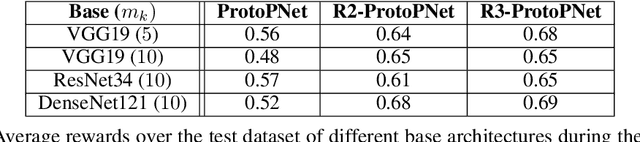
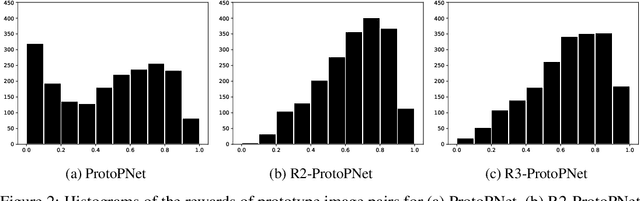
In recent years, work has gone into developing deep interpretable methods for image classification that clearly attributes a model's output to specific features of the data. One such of these methods is the prototypical part network (ProtoPNet), which attempts to classify images based on meaningful parts of the input. While this method results in interpretable classifications, this method often learns to classify from spurious or inconsistent parts of the image. Hoping to remedy this, we take inspiration from the recent developments in Reinforcement Learning with Human Feedback (RLHF) to fine-tune these prototypes. By collecting human annotations of prototypes quality via a 1-5 scale on the CUB-200-2011 dataset, we construct a reward model that learns to identify non-spurious prototypes. In place of a full RL update, we propose the reweighted, reselected, and retrained prototypical part network (R3-ProtoPNet), which adds an additional three steps to the ProtoPNet training loop. The first two steps are reward-based reweighting and reselection, which align prototypes with human feedback. The final step is retraining to realign the model's features with the updated prototypes. We find that R3-ProtoPNet improves the overall consistency and meaningfulness of the prototypes, but lower the test predictive accuracy when used independently. When multiple R3-ProtoPNets are incorporated into an ensemble, we find an increase in test predictive performance while maintaining interpretability.
How to Tidy Up a Table: Fusing Visual and Semantic Commonsense Reasoning for Robotic Tasks with Vague Objectives
Jul 21, 2023Vague objectives in many real-life scenarios pose long-standing challenges for robotics, as defining rules, rewards, or constraints for optimization is difficult. Tasks like tidying a messy table may appear simple for humans, but articulating the criteria for tidiness is complex due to the ambiguity and flexibility in commonsense reasoning. Recent advancement in Large Language Models (LLMs) offers us an opportunity to reason over these vague objectives: learned from extensive human data, LLMs capture meaningful common sense about human behavior. However, as LLMs are trained solely on language input, they may struggle with robotic tasks due to their limited capacity to account for perception and low-level controls. In this work, we propose a simple approach to solve the task of table tidying, an example of robotic tasks with vague objectives. Specifically, the task of tidying a table involves not just clustering objects by type and functionality for semantic tidiness but also considering spatial-visual relations of objects for a visually pleasing arrangement, termed as visual tidiness. We propose to learn a lightweight, image-based tidiness score function to ground the semantically tidy policy of LLMs to achieve visual tidiness. We innovatively train the tidiness score using synthetic data gathered using random walks from a few tidy configurations. Such trajectories naturally encode the order of tidiness, thereby eliminating the need for laborious and expensive human demonstrations. Our empirical results show that our pipeline can be applied to unseen objects and complex 3D arrangements.
Learning Restoration is Not Enough: Transfering Identical Mapping for Single-Image Shadow Removal
May 18, 2023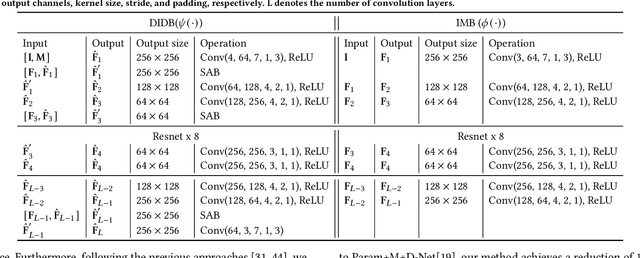

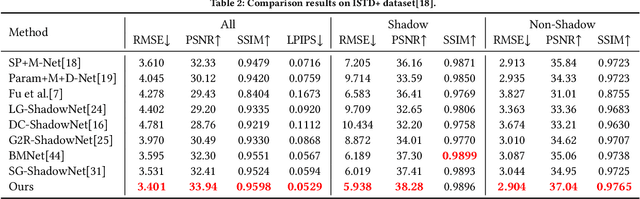
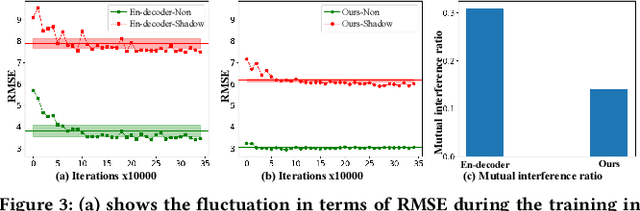
Shadow removal is to restore shadow regions to their shadow-free counterparts while leaving non-shadow regions unchanged. State-of-the-art shadow removal methods train deep neural networks on collected shadow & shadow-free image pairs, which are desired to complete two distinct tasks via shared weights, i.e., data restoration for shadow regions and identical mapping for non-shadow regions. We find that these two tasks exhibit poor compatibility, and using shared weights for these two tasks could lead to the model being optimized towards only one task instead of both during the training process. Note that such a key issue is not identified by existing deep learning-based shadow removal methods. To address this problem, we propose to handle these two tasks separately and leverage the identical mapping results to guide the shadow restoration in an iterative manner. Specifically, our method consists of three components: an identical mapping branch (IMB) for non-shadow regions processing, an iterative de-shadow branch (IDB) for shadow regions restoration based on identical results, and a smart aggregation block (SAB). The IMB aims to reconstruct an image that is identical to the input one, which can benefit the restoration of the non-shadow regions without explicitly distinguishing between shadow and non-shadow regions. Utilizing the multi-scale features extracted by the IMB, the IDB can effectively transfer information from non-shadow regions to shadow regions progressively, facilitating the process of shadow removal. The SAB is designed to adaptive integrate features from both IMB and IDB. Moreover, it generates a finely tuned soft shadow mask that guides the process of removing shadows. Extensive experiments demonstrate our method outperforms all the state-of-the-art shadow removal approaches on the widely used shadow removal datasets.
Runtime optimization of acquisition trajectories for X-ray computed tomography with a robotic sample holder
Jun 23, 2023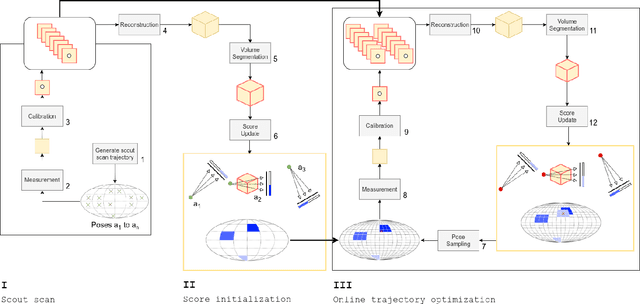
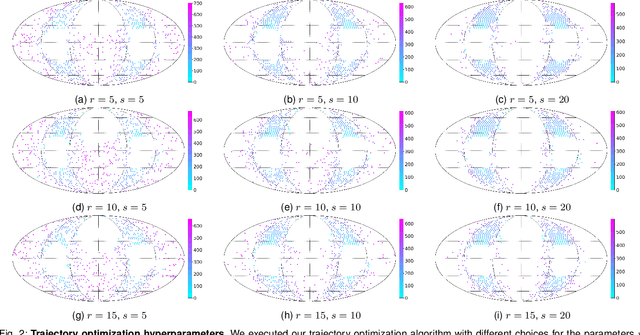
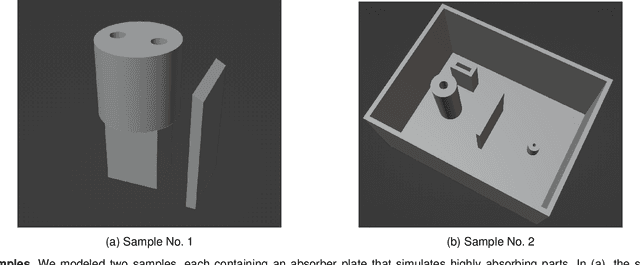
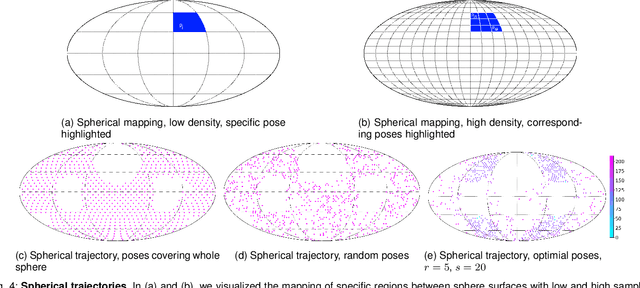
Tomographic imaging systems are expected to work with a wide range of samples that house complex structures and challenging material compositions, which can influence image quality in a bad way. Complex samples increase total measurement duration and may introduce beam-hardening artifacts that lead to poor reconstruction image quality. This work presents an online trajectory optimization method for an X-ray computed tomography system with a robotic sample holder. The proposed method reduces measurement time and increases reconstruction image quality by generating an optimized spherical trajectory for the given sample without prior knowledge. The trajectory is generated successively at runtime based on intermediate sample measurements. We present experimental results with the robotic sample holder where two sample measurements using an optimized spherical trajectory achieve improved reconstruction quality compared to a conventional spherical trajectory. Our results demonstrate the ability of our system to increase reconstruction image quality and avoid artifacts at runtime when no prior information about the sample is provided.
Solar Active Region Magnetogram Image Dataset for Studies of Space Weather
May 18, 2023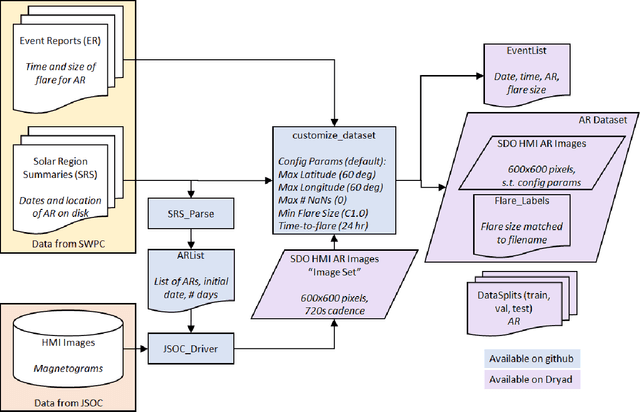
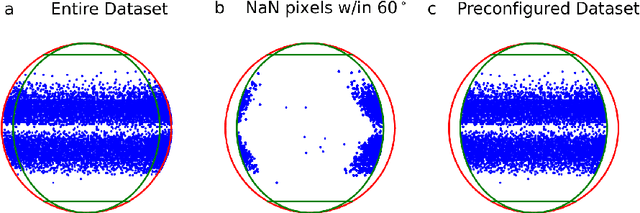

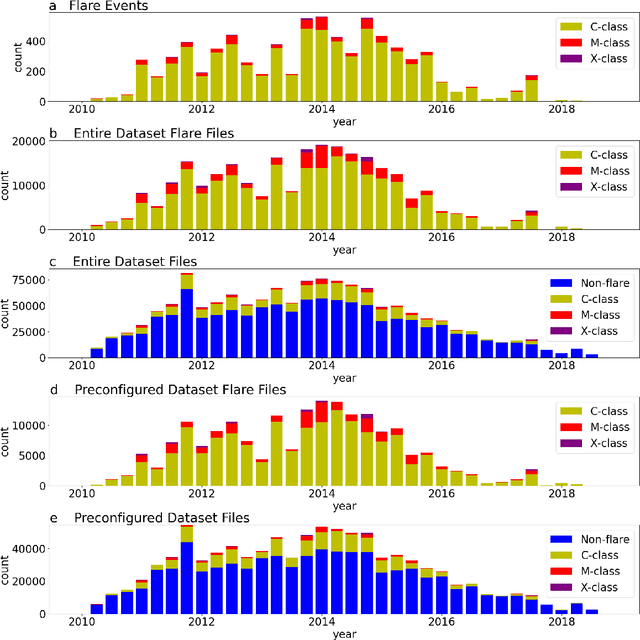
In this dataset we provide a comprehensive collection of magnetograms (images quantifying the strength of the magnetic field) from the National Aeronautics and Space Administration's (NASA's) Solar Dynamics Observatory (SDO). The dataset incorporates data from three sources and provides SDO Helioseismic and Magnetic Imager (HMI) magnetograms of solar active regions (regions of large magnetic flux, generally the source of eruptive events) as well as labels of corresponding flaring activity. This dataset will be useful for image analysis or solar physics research related to magnetic structure, its evolution over time, and its relation to solar flares. The dataset will be of interest to those researchers investigating automated solar flare prediction methods, including supervised and unsupervised machine learning (classical and deep), binary and multi-class classification, and regression. This dataset is a minimally processed, user configurable dataset of consistently sized images of solar active regions that can serve as a benchmark dataset for solar flare prediction research.
Properties of Discrete Sliced Wasserstein Losses
Jul 19, 2023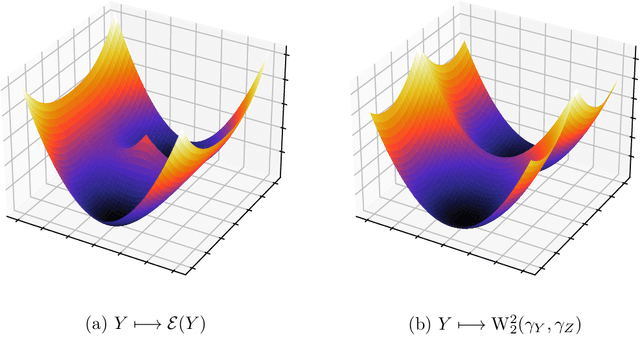
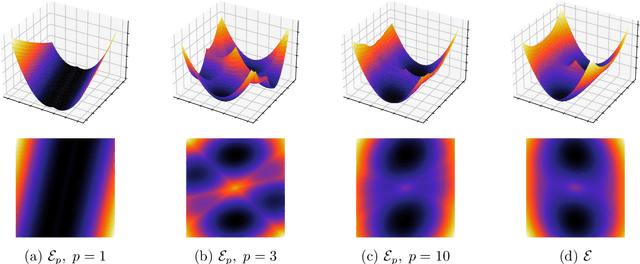
The Sliced Wasserstein (SW) distance has become a popular alternative to the Wasserstein distance for comparing probability measures. Widespread applications include image processing, domain adaptation and generative modelling, where it is common to optimise some parameters in order to minimise SW, which serves as a loss function between discrete probability measures (since measures admitting densities are numerically unattainable). All these optimisation problems bear the same sub-problem, which is minimising the Sliced Wasserstein energy. In this paper we study the properties of $\mathcal{E}: Y \longmapsto \mathrm{SW}_2^2(\gamma_Y, \gamma_Z)$, i.e. the SW distance between two uniform discrete measures with the same amount of points as a function of the support $Y \in \mathbb{R}^{n \times d}$ of one of the measures. We investigate the regularity and optimisation properties of this energy, as well as its Monte-Carlo approximation $\mathcal{E}_p$ (estimating the expectation in SW using only $p$ samples) and show convergence results on the critical points of $\mathcal{E}_p$ to those of $\mathcal{E}$, as well as an almost-sure uniform convergence. Finally, we show that in a certain sense, Stochastic Gradient Descent methods minimising $\mathcal{E}$ and $\mathcal{E}_p$ converge towards (Clarke) critical points of these energies.
A reinforcement learning approach for VQA validation: an application to diabetic macular edema grading
Jul 19, 2023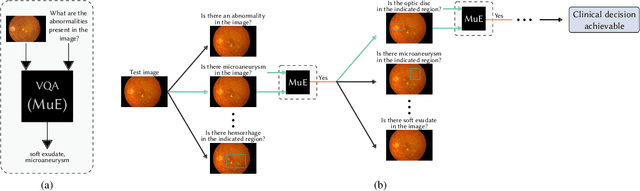

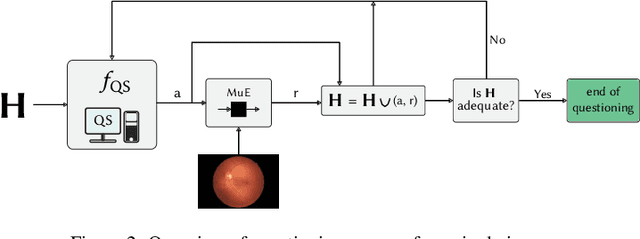
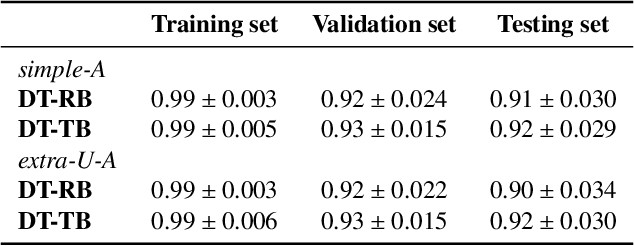
Recent advances in machine learning models have greatly increased the performance of automated methods in medical image analysis. However, the internal functioning of such models is largely hidden, which hinders their integration in clinical practice. Explainability and trust are viewed as important aspects of modern methods, for the latter's widespread use in clinical communities. As such, validation of machine learning models represents an important aspect and yet, most methods are only validated in a limited way. In this work, we focus on providing a richer and more appropriate validation approach for highly powerful Visual Question Answering (VQA) algorithms. To better understand the performance of these methods, which answer arbitrary questions related to images, this work focuses on an automatic visual Turing test (VTT). That is, we propose an automatic adaptive questioning method, that aims to expose the reasoning behavior of a VQA algorithm. Specifically, we introduce a reinforcement learning (RL) agent that observes the history of previously asked questions, and uses it to select the next question to pose. We demonstrate our approach in the context of evaluating algorithms that automatically answer questions related to diabetic macular edema (DME) grading. The experiments show that such an agent has similar behavior to a clinician, whereby asking questions that are relevant to key clinical concepts.
* 16 pages (+ 23 pages supplementary material)