 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Cluster Entropy: Active Domain Adaptation in Pathological Image Segmentation
Apr 26, 2023
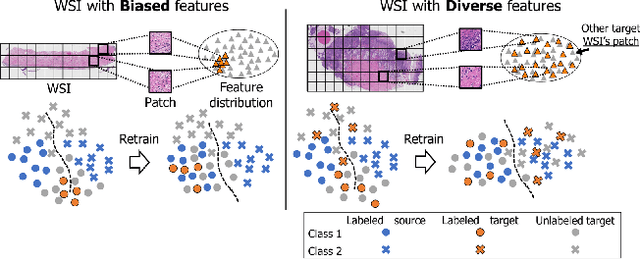
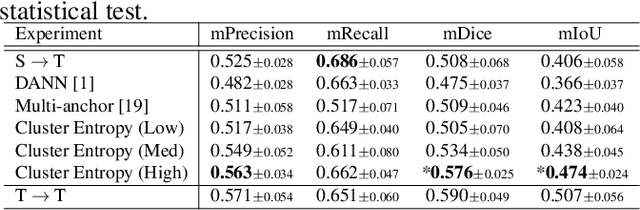

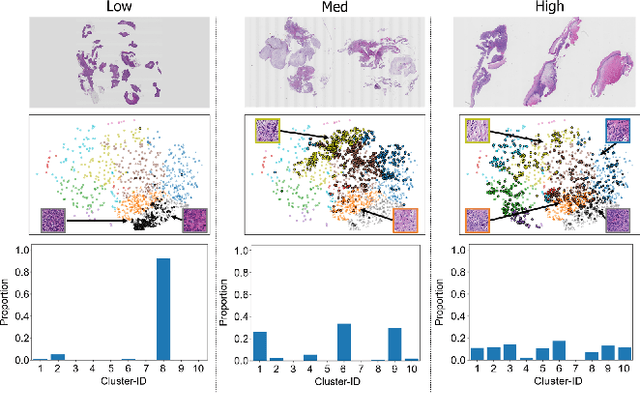
The domain shift in pathological segmentation is an important problem, where a network trained by a source domain (collected at a specific hospital) does not work well in the target domain (from different hospitals) due to the different image features. Due to the problems of class imbalance and different class prior of pathology, typical unsupervised domain adaptation methods do not work well by aligning the distribution of source domain and target domain. In this paper, we propose a cluster entropy for selecting an effective whole slide image (WSI) that is used for semi-supervised domain adaptation. This approach can measure how the image features of the WSI cover the entire distribution of the target domain by calculating the entropy of each cluster and can significantly improve the performance of domain adaptation. Our approach achieved competitive results against the prior arts on datasets collected from two hospitals.
Multi-modal Graph Neural Network for Early Diagnosis of Alzheimer's Disease from sMRI and PET Scans
Jul 31, 2023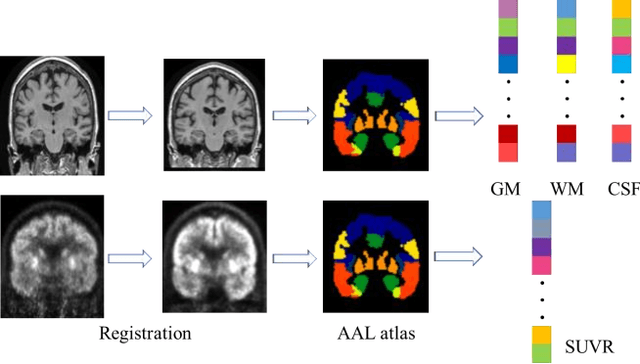
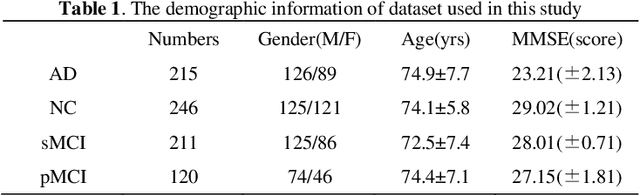
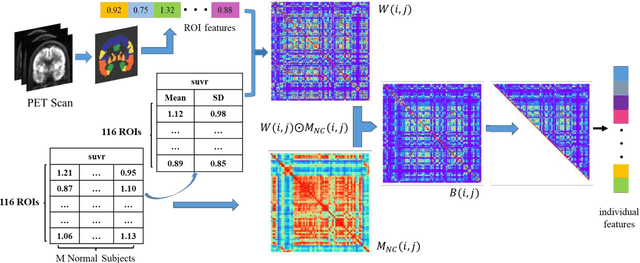
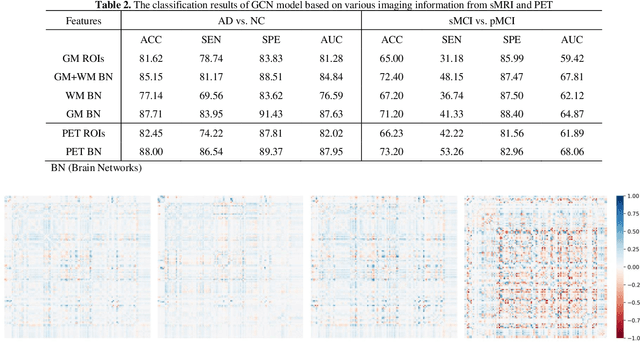
In recent years, deep learning models have been applied to neuroimaging data for early diagnosis of Alzheimer's disease (AD). Structural magnetic resonance imaging (sMRI) and positron emission tomography (PET) images provide structural and functional information about the brain, respectively. Combining these features leads to improved performance than using a single modality alone in building predictive models for AD diagnosis. However, current multi-modal approaches in deep learning, based on sMRI and PET, are mostly limited to convolutional neural networks, which do not facilitate integration of both image and phenotypic information of subjects. We propose to use graph neural networks (GNN) that are designed to deal with problems in non-Euclidean domains. In this study, we demonstrate how brain networks can be created from sMRI or PET images and be used in a population graph framework that can combine phenotypic information with imaging features of these brain networks. Then, we present a multi-modal GNN framework where each modality has its own branch of GNN and a technique is proposed to combine the multi-modal data at both the level of node vectors and adjacency matrices. Finally, we perform late fusion to combine the preliminary decisions made in each branch and produce a final prediction. As multi-modality data becomes available, multi-source and multi-modal is the trend of AD diagnosis. We conducted explorative experiments based on multi-modal imaging data combined with non-imaging phenotypic information for AD diagnosis and analyzed the impact of phenotypic information on diagnostic performance. Results from experiments demonstrated that our proposed multi-modal approach improves performance for AD diagnosis, and this study also provides technical reference and support the need for multivariate multi-modal diagnosis methods.
Catch Missing Details: Image Reconstruction with Frequency Augmented Variational Autoencoder
May 04, 2023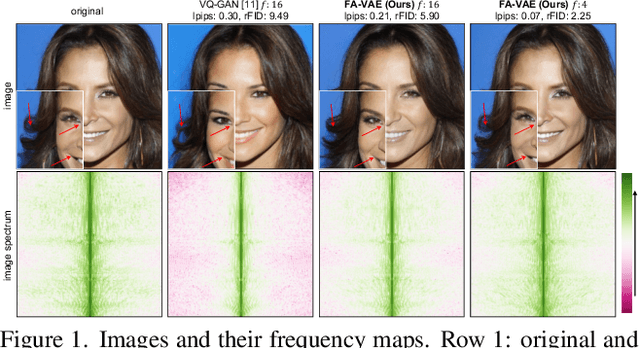
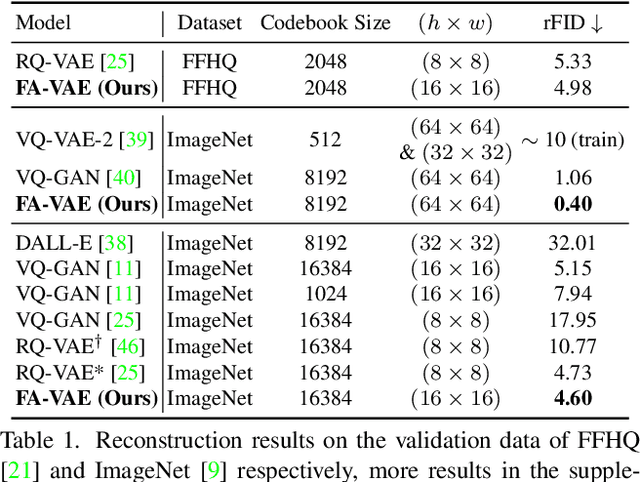
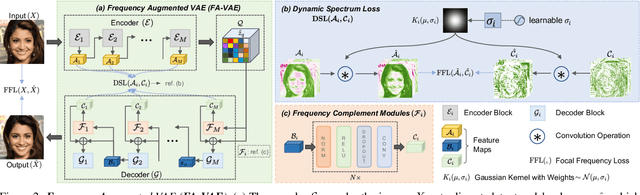
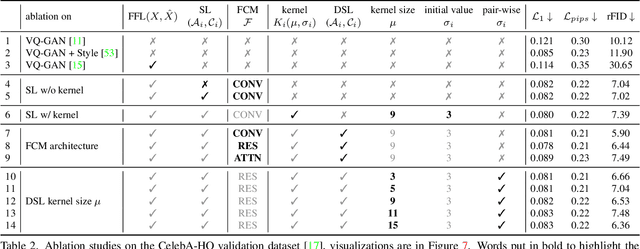
The popular VQ-VAE models reconstruct images through learning a discrete codebook but suffer from a significant issue in the rapid quality degradation of image reconstruction as the compression rate rises. One major reason is that a higher compression rate induces more loss of visual signals on the higher frequency spectrum which reflect the details on pixel space. In this paper, a Frequency Complement Module (FCM) architecture is proposed to capture the missing frequency information for enhancing reconstruction quality. The FCM can be easily incorporated into the VQ-VAE structure, and we refer to the new model as Frequency Augmented VAE (FA-VAE). In addition, a Dynamic Spectrum Loss (DSL) is introduced to guide the FCMs to balance between various frequencies dynamically for optimal reconstruction. FA-VAE is further extended to the text-to-image synthesis task, and a Cross-attention Autoregressive Transformer (CAT) is proposed to obtain more precise semantic attributes in texts. Extensive reconstruction experiments with different compression rates are conducted on several benchmark datasets, and the results demonstrate that the proposed FA-VAE is able to restore more faithfully the details compared to SOTA methods. CAT also shows improved generation quality with better image-text semantic alignment.
Streamlined Global and Local Features Combinator (SGLC) for High Resolution Image Dehazing
Apr 26, 2023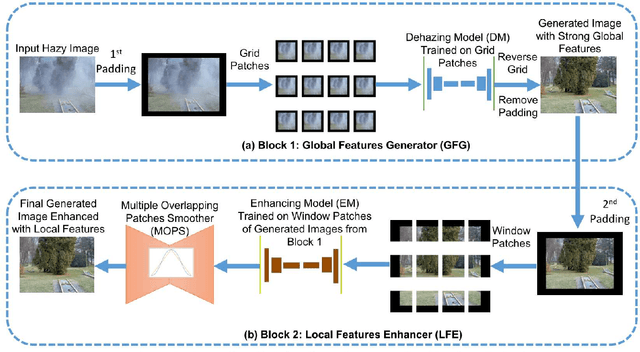
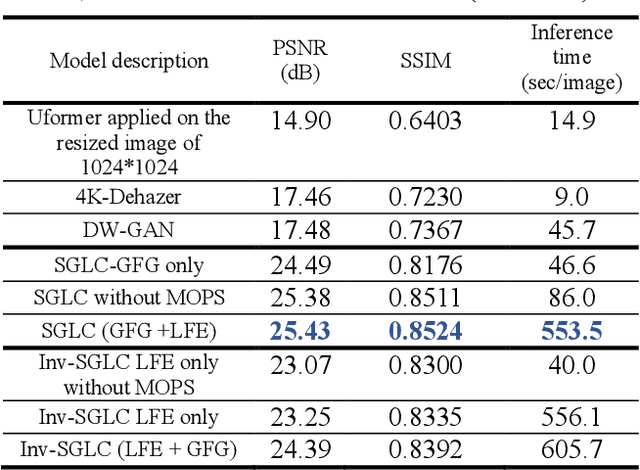

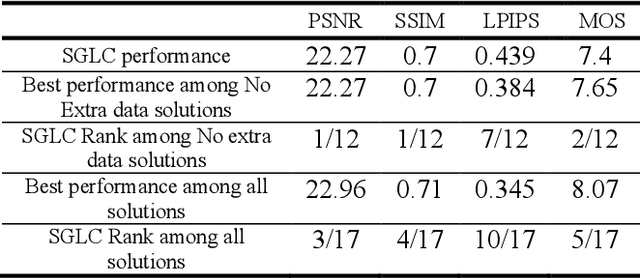
Image Dehazing aims to remove atmospheric fog or haze from an image. Although the Dehazing models have evolved a lot in recent years, few have precisely tackled the problem of High-Resolution hazy images. For this kind of image, the model needs to work on a downscaled version of the image or on cropped patches from it. In both cases, the accuracy will drop. This is primarily due to the inherent failure to combine global and local features when the image size increases. The Dehazing model requires global features to understand the general scene peculiarities and the local features to work better with fine and pixel details. In this study, we propose the Streamlined Global and Local Features Combinator (SGLC) to solve these issues and to optimize the application of any Dehazing model to High-Resolution images. The SGLC contains two successive blocks. The first is the Global Features Generator (GFG) which generates the first version of the Dehazed image containing strong global features. The second block is the Local Features Enhancer (LFE) which improves the local feature details inside the previously generated image. When tested on the Uformer architecture for Dehazing, SGLC increased the PSNR metric by a significant margin. Any other model can be incorporated inside the SGLC process to improve its efficiency on High-Resolution input data.
Training-Free Location-Aware Text-to-Image Synthesis
Apr 26, 2023
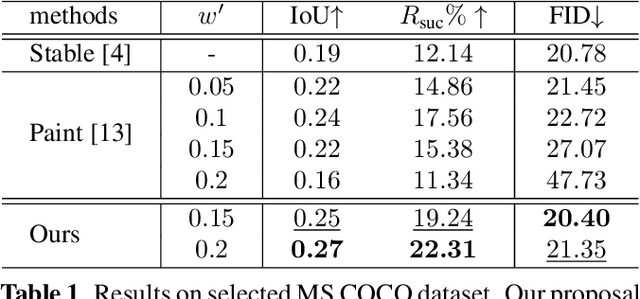

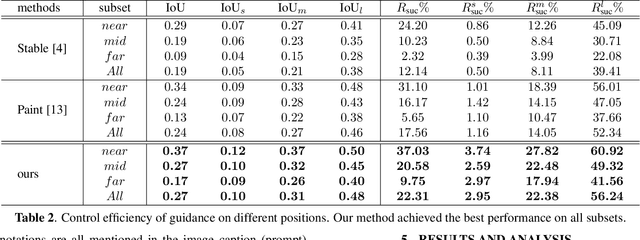
Current large-scale generative models have impressive efficiency in generating high-quality images based on text prompts. However, they lack the ability to precisely control the size and position of objects in the generated image. In this study, we analyze the generative mechanism of the stable diffusion model and propose a new interactive generation paradigm that allows users to specify the position of generated objects without additional training. Moreover, we propose an object detection-based evaluation metric to assess the control capability of location aware generation task. Our experimental results show that our method outperforms state-of-the-art methods on both control capacity and image quality.
SPColor: Semantic Prior Guided Exemplar-based Image Colorization
Apr 14, 2023
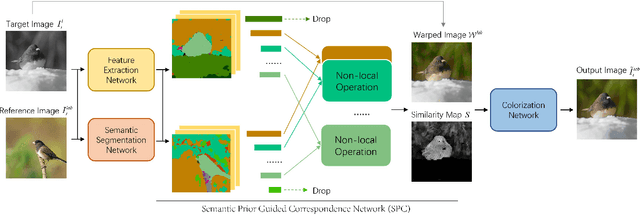


Exemplar-based image colorization aims to colorize a target grayscale image based on a color reference image, and the key is to establish accurate pixel-level semantic correspondence between these two images. Previous methods search for correspondence across the entire reference image, and this type of global matching is easy to get mismatch. We summarize the difficulties in two aspects: (1) When the reference image only contains a part of objects related to target image, improper correspondence will be established in unrelated regions. (2) It is prone to get mismatch in regions where the shape or texture of the object is easily confused. To overcome these issues, we propose SPColor, a semantic prior guided exemplar-based image colorization framework. Different from previous methods, SPColor first coarsely classifies pixels of the reference and target images to several pseudo-classes under the guidance of semantic prior, then the correspondences are only established locally between the pixels in the same class via the newly designed semantic prior guided correspondence network. In this way, improper correspondence between different semantic classes is explicitly excluded, and the mismatch is obviously alleviated. Besides, to better reserve the color from reference, a similarity masked perceptual loss is designed. Noting that the carefully designed SPColor utilizes the semantic prior provided by an unsupervised segmentation model, which is free for additional manual semantic annotations. Experiments demonstrate that our model outperforms recent state-of-the-art methods both quantitatively and qualitatively on public dataset.
Five A$^{+}$ Network: You Only Need 9K Parameters for Underwater Image Enhancement
May 15, 2023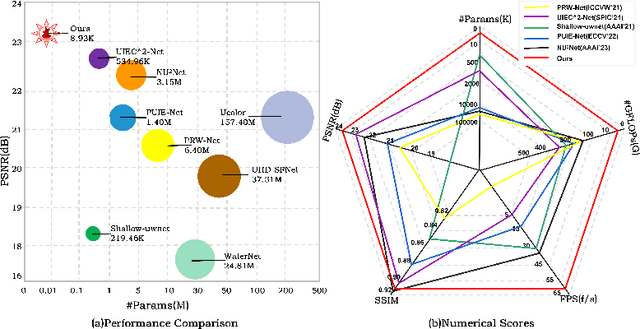
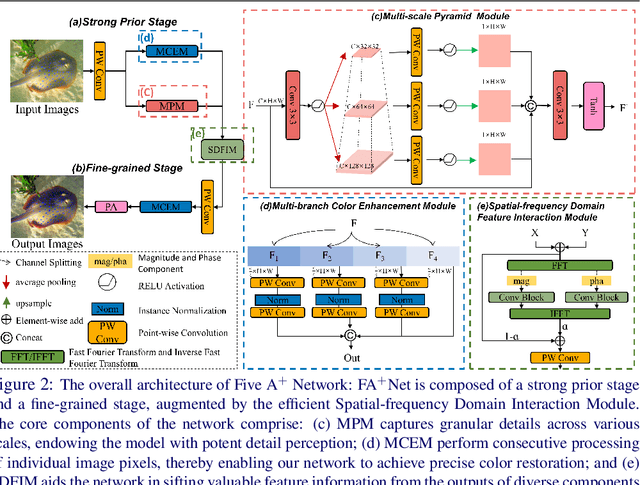

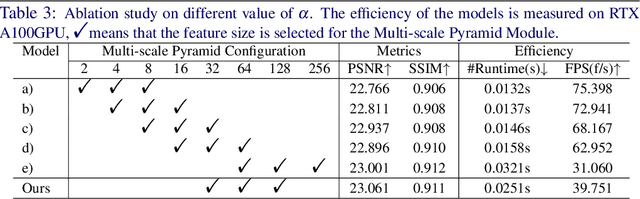
A lightweight underwater image enhancement network is of great significance for resource-constrained platforms, but balancing model size, computational efficiency, and enhancement performance has proven difficult for previous approaches. In this work, we propose the Five A$^{+}$ Network (FA$^{+}$Net), a highly efficient and lightweight real-time underwater image enhancement network with only $\sim$ 9k parameters and $\sim$ 0.01s processing time. The FA$^{+}$Net employs a two-stage enhancement structure. The strong prior stage aims to decompose challenging underwater degradations into sub-problems, while the fine-grained stage incorporates multi-branch color enhancement module and pixel attention module to amplify the network's perception of details. To the best of our knowledge, FA$^{+}$Net is the only network with the capability of real-time enhancement of 1080P images. Thorough extensive experiments and comprehensive visual comparison, we show that FA$^{+}$Net outperforms previous approaches by obtaining state-of-the-art performance on multiple datasets while significantly reducing both parameter count and computational complexity. The code is open source at https://github.com/Owen718/FiveAPlus-Network.
Diffusion Explainer: Visual Explanation for Text-to-image Stable Diffusion
May 08, 2023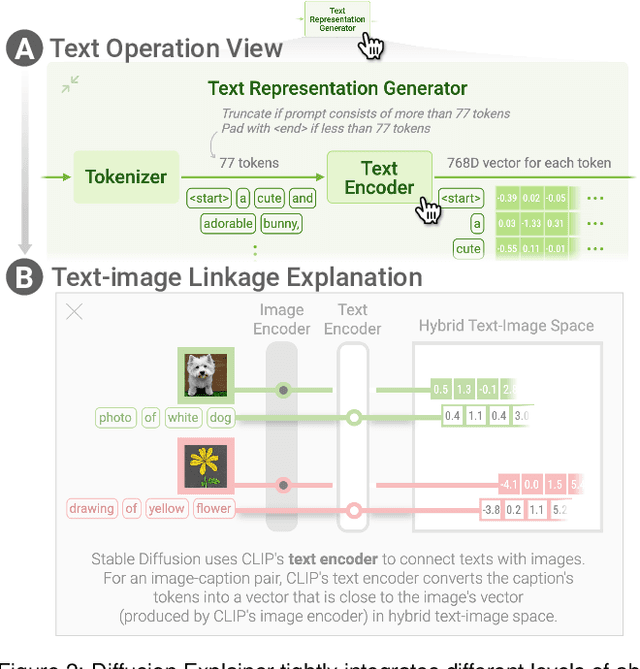
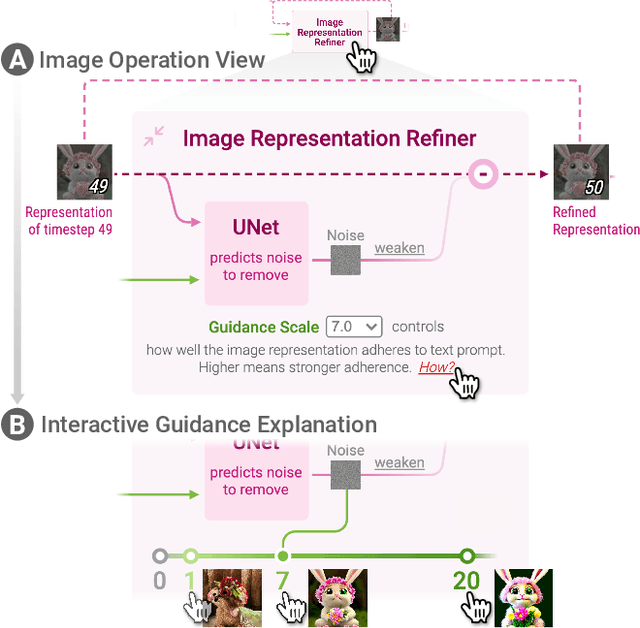
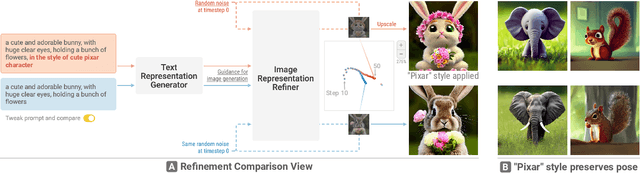
Diffusion-based generative models' impressive ability to create convincing images has captured global attention. However, their complex internal structures and operations often make them difficult for non-experts to understand. We present Diffusion Explainer, the first interactive visualization tool that explains how Stable Diffusion transforms text prompts into images. Diffusion Explainer tightly integrates a visual overview of Stable Diffusion's complex components with detailed explanations of their underlying operations, enabling users to fluidly transition between multiple levels of abstraction through animations and interactive elements. By comparing the evolutions of image representations guided by two related text prompts over refinement timesteps, users can discover the impact of prompts on image generation. Diffusion Explainer runs locally in users' web browsers without the need for installation or specialized hardware, broadening the public's education access to modern AI techniques. Our open-sourced tool is available at: https://poloclub.github.io/diffusion-explainer/. A video demo is available at https://youtu.be/Zg4gxdIWDds.
Semantic-Aware Graph Matching Mechanism for Multi-Label Image Recognition
Apr 21, 2023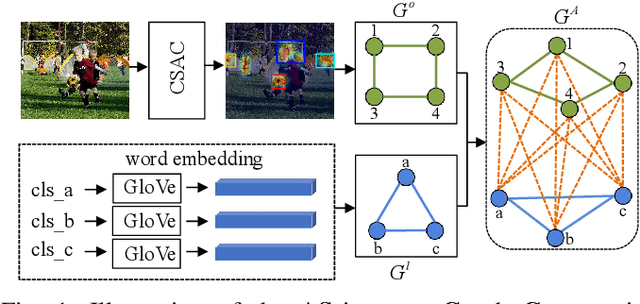
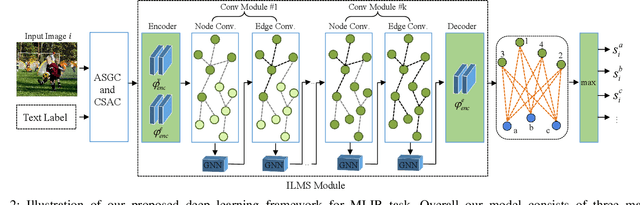
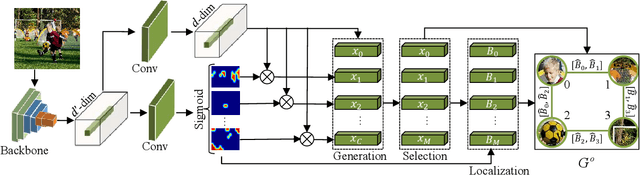

Multi-label image recognition aims to predict a set of labels that present in an image. The key to deal with such problem is to mine the associations between image contents and labels, and further obtain the correct assignments between images and their labels. In this paper, we treat each image as a bag of instances, and formulate the task of multi-label image recognition as an instance-label matching selection problem. To model such problem, we propose an innovative Semantic-aware Graph Matching framework for Multi-Label image recognition (ML-SGM), in which Graph Matching mechanism is introduced owing to its good performance of excavating the instance and label relationship. The framework explicitly establishes category correlations and instance-label correspondences by modeling the relation among content-aware (instance) and semantic-aware (label) category representations, to facilitate multi-label image understanding and reduce the dependency of large amounts of training samples for each category. Specifically, we first construct an instance spatial graph and a label semantic graph respectively and then incorporate them into a constructed assignment graph by connecting each instance to all labels. Subsequently, the graph network block is adopted to aggregate and update all nodes and edges state on the assignment graph to form structured representations for each instance and label. Our network finally derives a prediction score for each instance-label correspondence and optimizes such correspondence with a weighted cross-entropy loss. Empirical results conducted on generic multi-label image recognition demonstrate the superiority of our proposed method. Moreover, the proposed method also shows advantages in multi-label recognition with partial labels and multi-label few-shot learning, as well as outperforms current state-of-the-art methods with a clear margin.
Prompt-based Tuning of Transformer Models for Multi-Center Medical Image Segmentation
May 30, 2023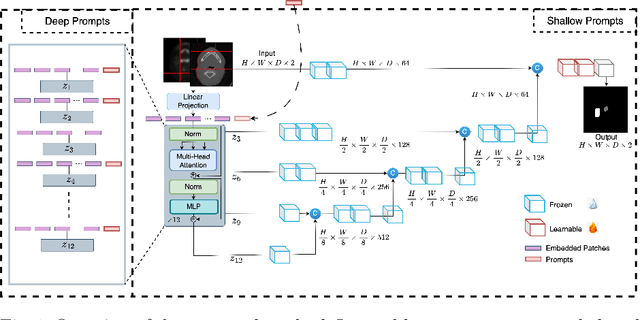

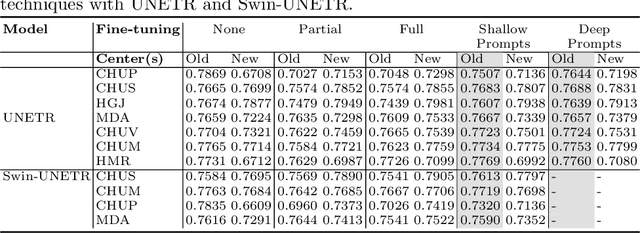
Medical image segmentation is a vital healthcare endeavor requiring precise and efficient models for appropriate diagnosis and treatment. Vision transformer-based segmentation models have shown great performance in accomplishing this task. However, to build a powerful backbone, the self-attention block of ViT requires large-scale pre-training data. The present method of modifying pre-trained models entails updating all or some of the backbone parameters. This paper proposes a novel fine-tuning strategy for adapting a pretrained transformer-based segmentation model on data from a new medical center. This method introduces a small number of learnable parameters, termed prompts, into the input space (less than 1\% of model parameters) while keeping the rest of the model parameters frozen. Extensive studies employing data from new unseen medical centers show that prompts-based fine-tuning of medical segmentation models provides excellent performance on the new center data with a negligible drop on the old centers. Additionally, our strategy delivers great accuracy with minimum re-training on new center data, significantly decreasing the computational and time costs of fine-tuning pre-trained models.