 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
LLCaps: Learning to Illuminate Low-Light Capsule Endoscopy with Curved Wavelet Attention and Reverse Diffusion
Jul 05, 2023
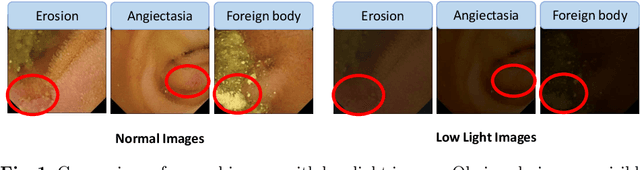
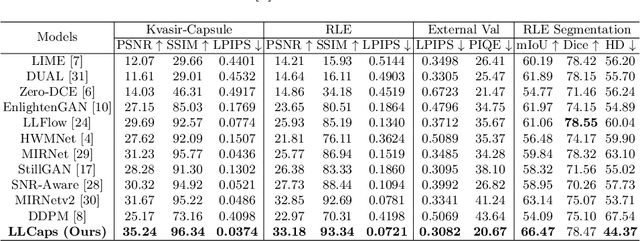
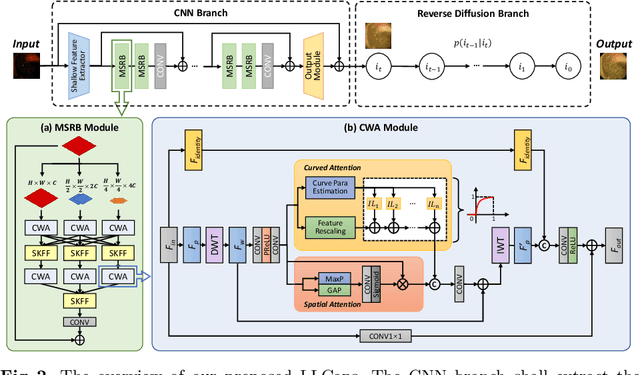
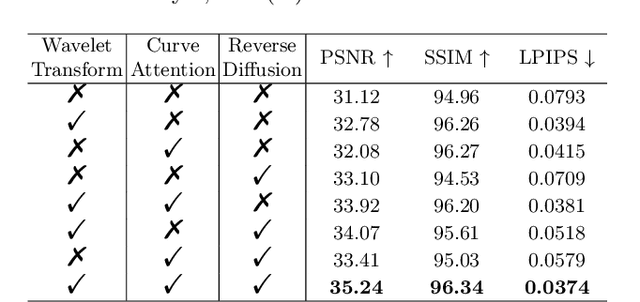
Wireless capsule endoscopy (WCE) is a painless and non-invasive diagnostic tool for gastrointestinal (GI) diseases. However, due to GI anatomical constraints and hardware manufacturing limitations, WCE vision signals may suffer from insufficient illumination, leading to a complicated screening and examination procedure. Deep learning-based low-light image enhancement (LLIE) in the medical field gradually attracts researchers. Given the exuberant development of the denoising diffusion probabilistic model (DDPM) in computer vision, we introduce a WCE LLIE framework based on the multi-scale convolutional neural network (CNN) and reverse diffusion process. The multi-scale design allows models to preserve high-resolution representation and context information from low-resolution, while the curved wavelet attention (CWA) block is proposed for high-frequency and local feature learning. Furthermore, we combine the reverse diffusion procedure to further optimize the shallow output and generate the most realistic image. The proposed method is compared with ten state-of-the-art (SOTA) LLIE methods and significantly outperforms quantitatively and qualitatively. The superior performance on GI disease segmentation further demonstrates the clinical potential of our proposed model. Our code is publicly accessible.
Image Blending with Osmosis
Mar 15, 2023



Image blending is an integral part of many multi-image applications such as panorama stitching or remote image acquisition processes. In such scenarios, multiple images are connected at predefined boundaries to form a larger image. A convincing transition between these boundaries may be challenging, since each image might have been acquired under different conditions or even by different devices. We propose the first blending approach based on osmosis filters. These drift-diffusion processes define an image evolution with a non-trivial steady state. For our blending purposes, we explore several ways to compose drift vector fields based on the derivatives of our input images. These vector fields guide the evolution such that the steady state yields a convincing blended result. Our method benefits from the well-founded theoretical results for osmosis, which include useful invariances under multiplicative changes of the colour values. Experiments on real-world data show that this yields better quality than traditional gradient domain blending, especially under challenging illumination conditions.
FVP: Fourier Visual Prompting for Source-Free Unsupervised Domain Adaptation of Medical Image Segmentation
Apr 26, 2023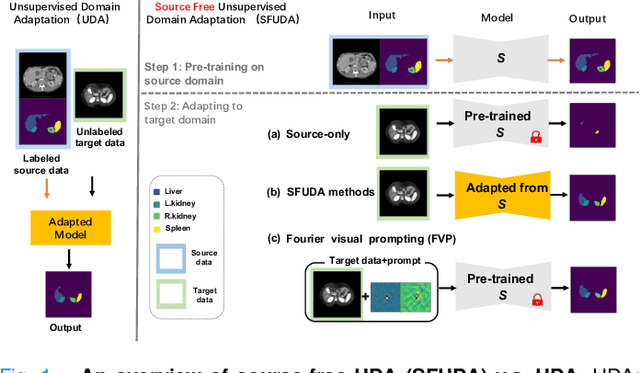


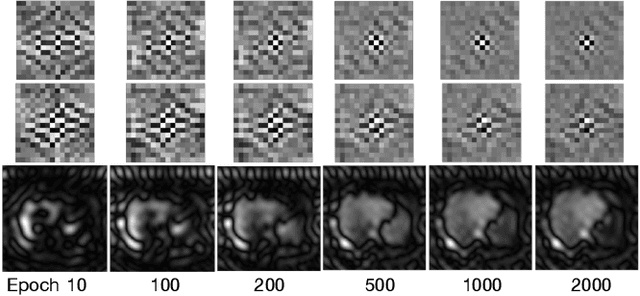
Medical image segmentation methods normally perform poorly when there is a domain shift between training and testing data. Unsupervised Domain Adaptation (UDA) addresses the domain shift problem by training the model using both labeled data from the source domain and unlabeled data from the target domain. Source-Free UDA (SFUDA) was recently proposed for UDA without requiring the source data during the adaptation, due to data privacy or data transmission issues, which normally adapts the pre-trained deep model in the testing stage. However, in real clinical scenarios of medical image segmentation, the trained model is normally frozen in the testing stage. In this paper, we propose Fourier Visual Prompting (FVP) for SFUDA of medical image segmentation. Inspired by prompting learning in natural language processing, FVP steers the frozen pre-trained model to perform well in the target domain by adding a visual prompt to the input target data. In FVP, the visual prompt is parameterized using only a small amount of low-frequency learnable parameters in the input frequency space, and is learned by minimizing the segmentation loss between the predicted segmentation of the prompted target image and reliable pseudo segmentation label of the target image under the frozen model. To our knowledge, FVP is the first work to apply visual prompts to SFUDA for medical image segmentation. The proposed FVP is validated using three public datasets, and experiments demonstrate that FVP yields better segmentation results, compared with various existing methods.
Identifying and Disentangling Spurious Features in Pretrained Image Representations
Jun 22, 2023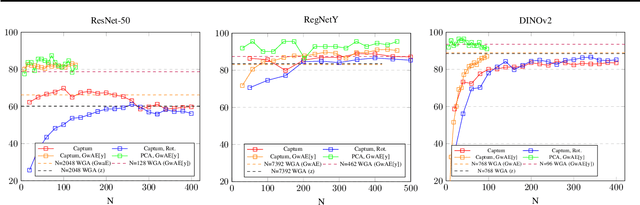
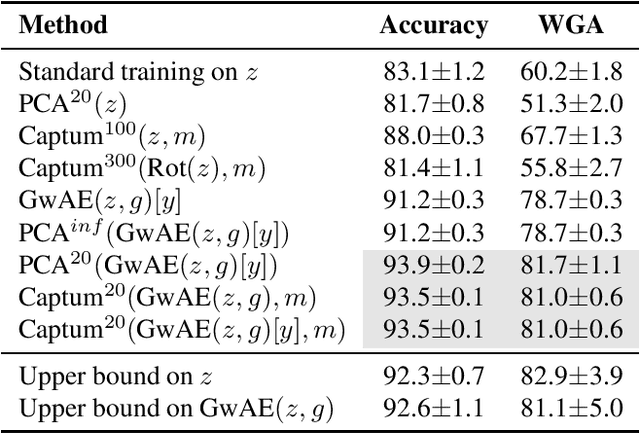
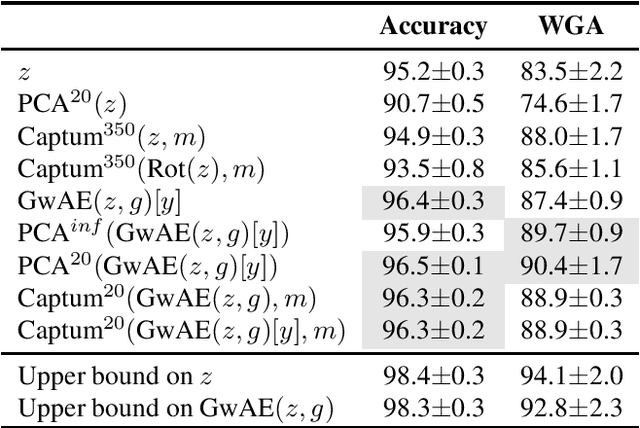
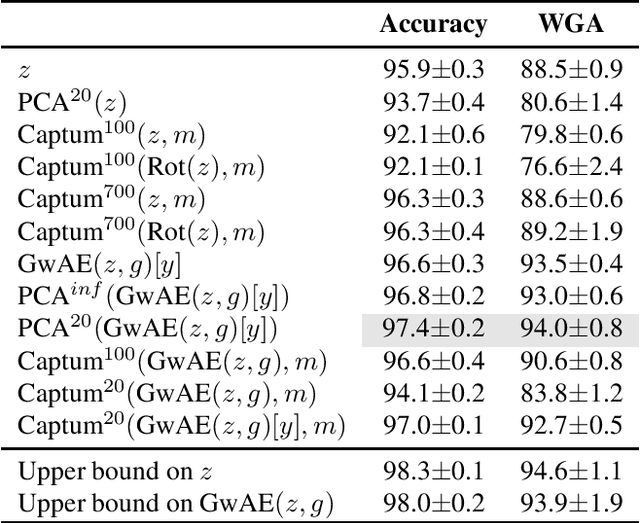
Neural networks employ spurious correlations in their predictions, resulting in decreased performance when these correlations do not hold. Recent works suggest fixing pretrained representations and training a classification head that does not use spurious features. We investigate how spurious features are represented in pretrained representations and explore strategies for removing information about spurious features. Considering the Waterbirds dataset and a few pretrained representations, we find that even with full knowledge of spurious features, their removal is not straightforward due to entangled representation. To address this, we propose a linear autoencoder training method to separate the representation into core, spurious, and other features. We propose two effective spurious feature removal approaches that are applied to the encoding and significantly improve classification performance measured by worst group accuracy.
Document Image Cleaning using Budget-Aware Black-Box Approximation
Jun 22, 2023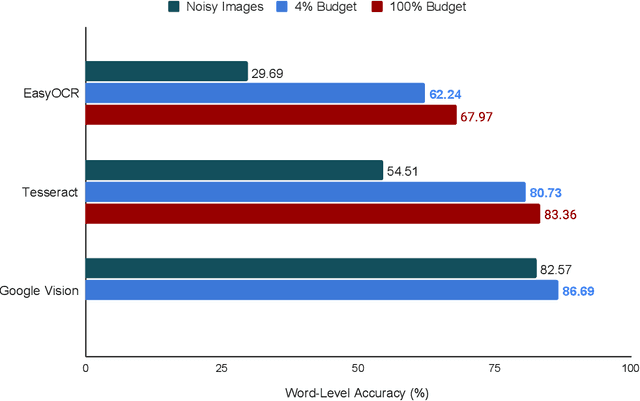
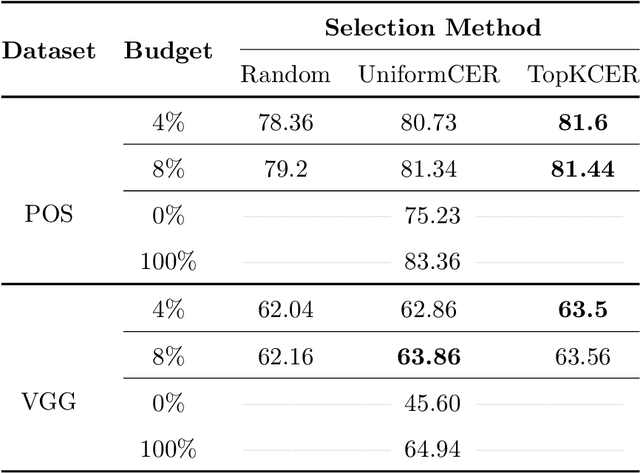
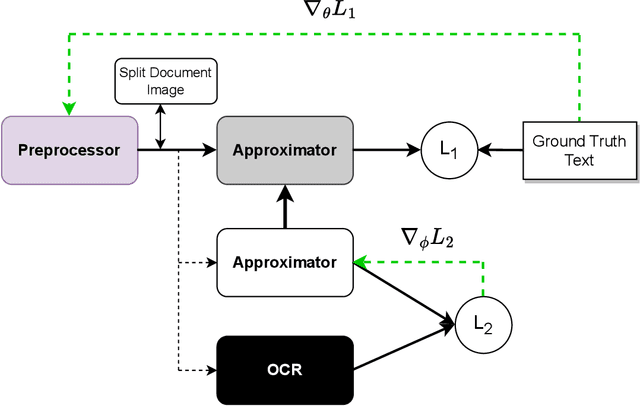
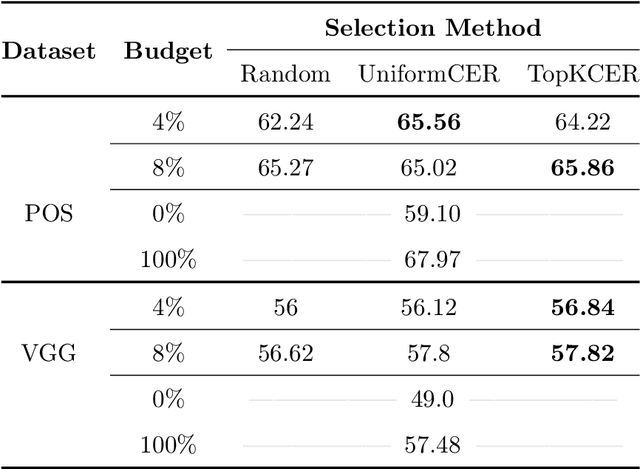
Recent work has shown that by approximating the behaviour of a non-differentiable black-box function using a neural network, the black-box can be integrated into a differentiable training pipeline for end-to-end training. This methodology is termed "differentiable bypass,'' and a successful application of this method involves training a document preprocessor to improve the performance of a black-box OCR engine. However, a good approximation of an OCR engine requires querying it for all samples throughout the training process, which can be computationally and financially expensive. Several zeroth-order optimization (ZO) algorithms have been proposed in black-box attack literature to find adversarial examples for a black-box model by computing its gradient in a query-efficient manner. However, the query complexity and convergence rate of such algorithms makes them infeasible for our problem. In this work, we propose two sample selection algorithms to train an OCR preprocessor with less than 10% of the original system's OCR engine queries, resulting in more than 60% reduction of the total training time without significant loss of accuracy. We also show an improvement of 4% in the word-level accuracy of a commercial OCR engine with only 2.5% of the total queries and a 32x reduction in monetary cost. Further, we propose a simple ranking technique to prune 30% of the document images from the training dataset without affecting the system's performance.
Exploiting Diffusion Prior for Real-World Image Super-Resolution
May 11, 2023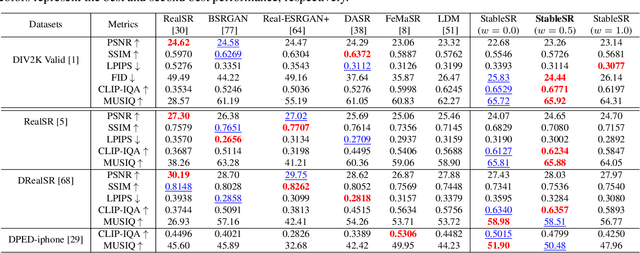
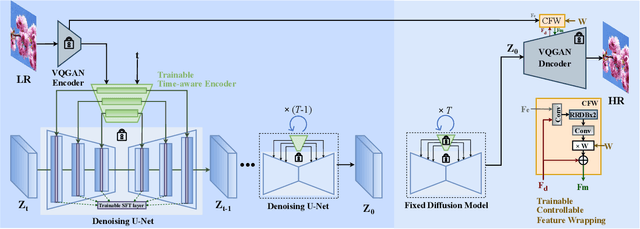
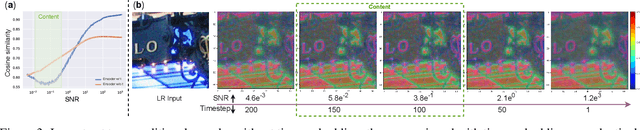

We present a novel approach to leverage prior knowledge encapsulated in pre-trained text-to-image diffusion models for blind super-resolution (SR). Specifically, by employing our time-aware encoder, we can achieve promising restoration results without altering the pre-trained synthesis model, thereby preserving the generative prior and minimizing training cost. To remedy the loss of fidelity caused by the inherent stochasticity of diffusion models, we introduce a controllable feature wrapping module that allows users to balance quality and fidelity by simply adjusting a scalar value during the inference process. Moreover, we develop a progressive aggregation sampling strategy to overcome the fixed-size constraints of pre-trained diffusion models, enabling adaptation to resolutions of any size. A comprehensive evaluation of our method using both synthetic and real-world benchmarks demonstrates its superiority over current state-of-the-art approaches.
Close-up View synthesis by Interpolating Optical Flow
Jul 12, 2023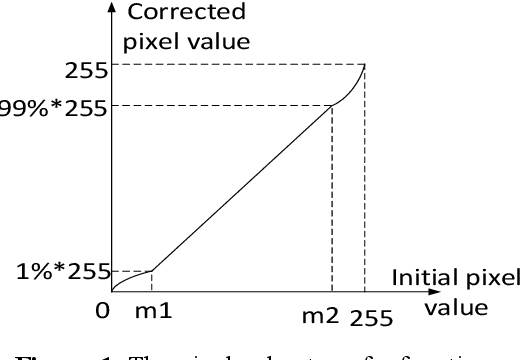
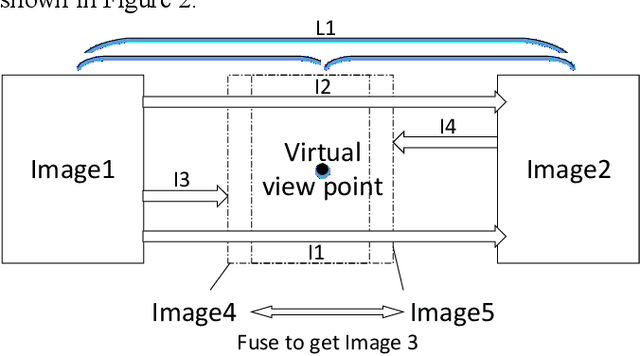


The virtual viewpoint is perceived as a new technique in virtual navigation, as yet not supported due to the lack of depth information and obscure camera parameters. In this paper, a method for achieving close-up virtual view is proposed and it only uses optical flow to build parallax effects to realize pseudo 3D projection without using depth sensor. We develop a bidirectional optical flow method to obtain any virtual viewpoint by proportional interpolation of optical flow. Moreover, with the ingenious application of the optical-flow-value, we achieve clear and visual-fidelity magnified results through lens stretching in any corner, which overcomes the visual distortion and image blur through viewpoint magnification and transition in Google Street View system.
Data Augmentation in Training CNNs: Injecting Noise to Images
Jul 12, 2023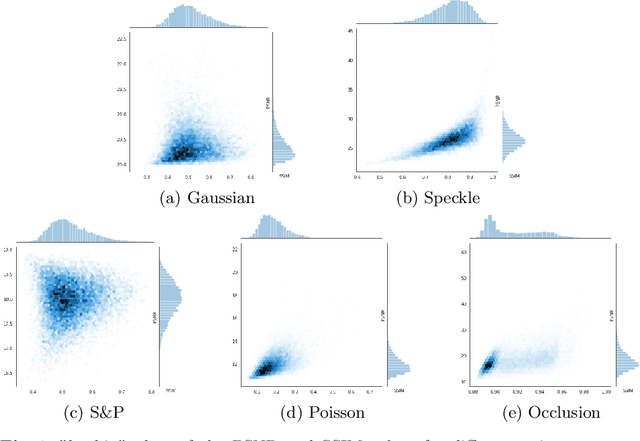

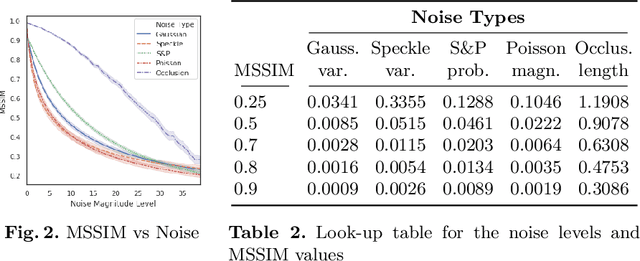

Noise injection is a fundamental tool for data augmentation, and yet there is no widely accepted procedure to incorporate it with learning frameworks. This study analyzes the effects of adding or applying different noise models of varying magnitudes to Convolutional Neural Network (CNN) architectures. Noise models that are distributed with different density functions are given common magnitude levels via Structural Similarity (SSIM) metric in order to create an appropriate ground for comparison. The basic results are conforming with the most of the common notions in machine learning, and also introduce some novel heuristics and recommendations on noise injection. The new approaches will provide better understanding on optimal learning procedures for image classification.
Riesz feature representation: scale equivariant scattering network for classification tasks
Jul 17, 2023
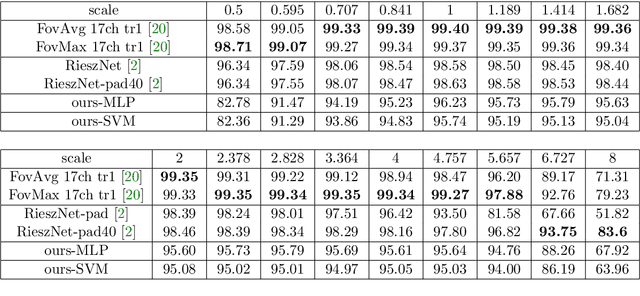

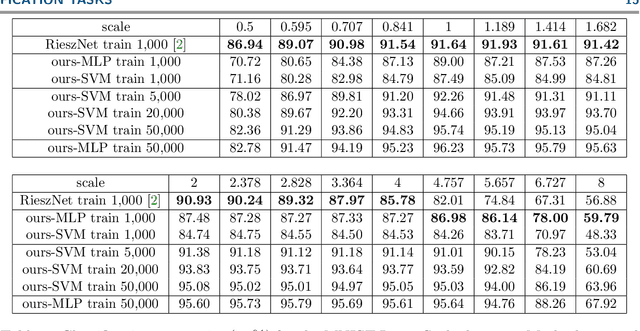
Scattering networks yield powerful and robust hierarchical image descriptors which do not require lengthy training and which work well with very few training data. However, they rely on sampling the scale dimension. Hence, they become sensitive to scale variations and are unable to generalize to unseen scales. In this work, we define an alternative feature representation based on the Riesz transform. We detail and analyze the mathematical foundations behind this representation. In particular, it inherits scale equivariance from the Riesz transform and completely avoids sampling of the scale dimension. Additionally, the number of features in the representation is reduced by a factor four compared to scattering networks. Nevertheless, our representation performs comparably well for texture classification with an interesting addition: scale equivariance. Our method yields superior performance when dealing with scales outside of those covered by the training dataset. The usefulness of the equivariance property is demonstrated on the digit classification task, where accuracy remains stable even for scales four times larger than the one chosen for training. As a second example, we consider classification of textures.
A Novel Multi-Task Model Imitating Dermatologists for Accurate Differential Diagnosis of Skin Diseases in Clinical Images
Jul 17, 2023
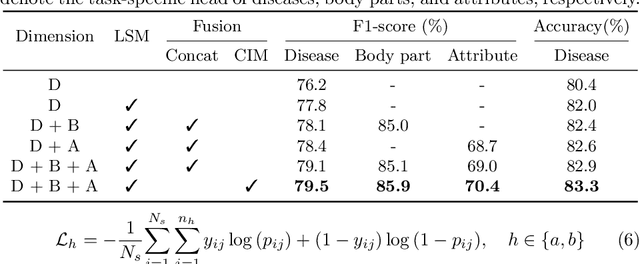
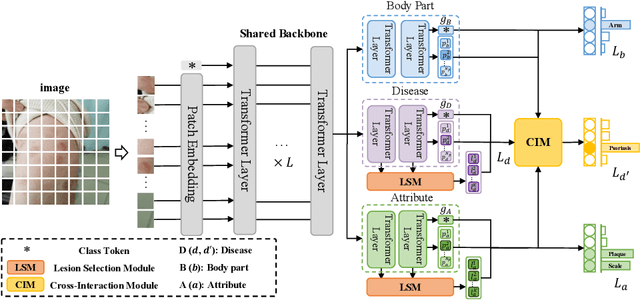
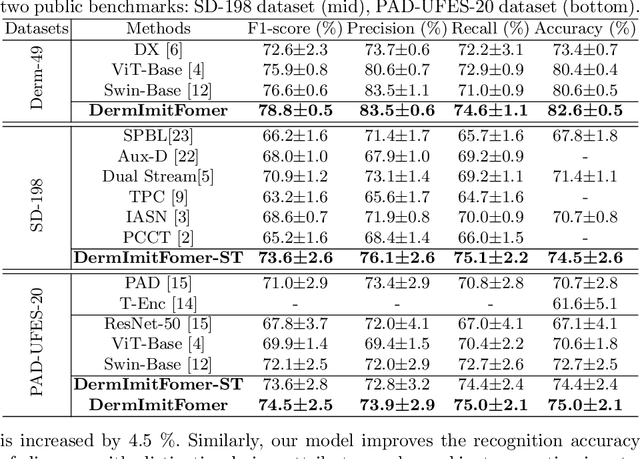
Skin diseases are among the most prevalent health issues, and accurate computer-aided diagnosis methods are of importance for both dermatologists and patients. However, most of the existing methods overlook the essential domain knowledge required for skin disease diagnosis. A novel multi-task model, namely DermImitFormer, is proposed to fill this gap by imitating dermatologists' diagnostic procedures and strategies. Through multi-task learning, the model simultaneously predicts body parts and lesion attributes in addition to the disease itself, enhancing diagnosis accuracy and improving diagnosis interpretability. The designed lesion selection module mimics dermatologists' zoom-in action, effectively highlighting the local lesion features from noisy backgrounds. Additionally, the presented cross-interaction module explicitly models the complicated diagnostic reasoning between body parts, lesion attributes, and diseases. To provide a more robust evaluation of the proposed method, a large-scale clinical image dataset of skin diseases with significantly more cases than existing datasets has been established. Extensive experiments on three different datasets consistently demonstrate the state-of-the-art recognition performance of the proposed approach.