 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MasaCtrl: Tuning-Free Mutual Self-Attention Control for Consistent Image Synthesis and Editing
Apr 17, 2023
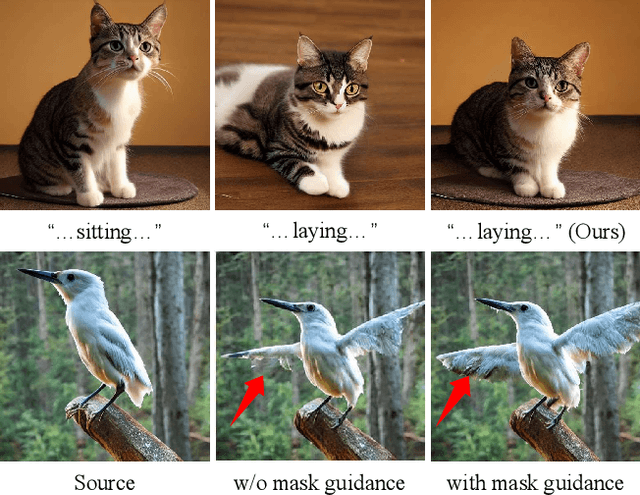
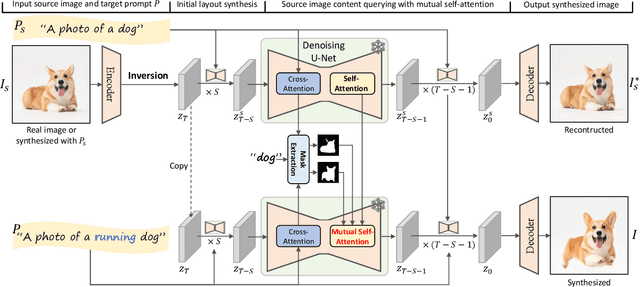
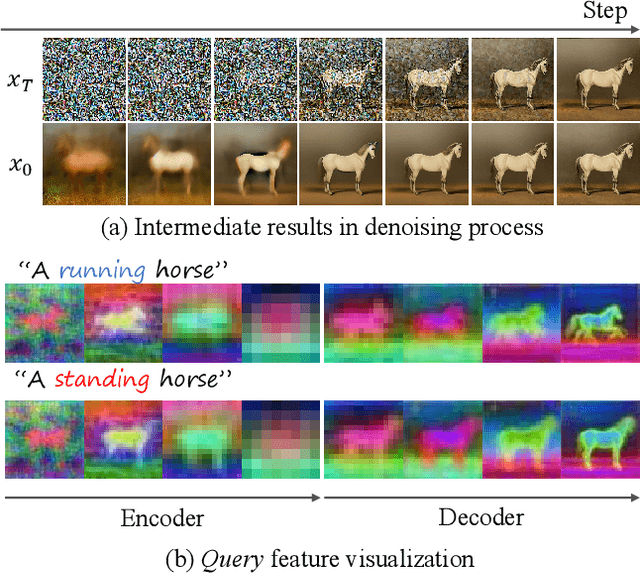
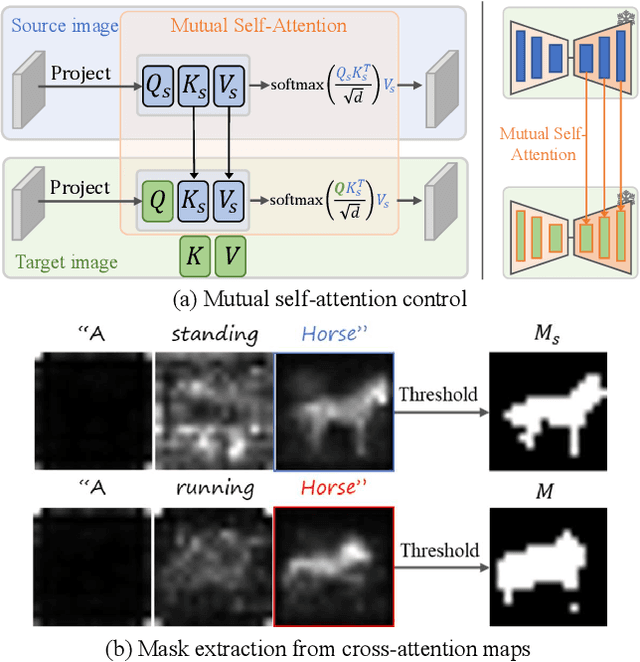
Despite the success in large-scale text-to-image generation and text-conditioned image editing, existing methods still struggle to produce consistent generation and editing results. For example, generation approaches usually fail to synthesize multiple images of the same objects/characters but with different views or poses. Meanwhile, existing editing methods either fail to achieve effective complex non-rigid editing while maintaining the overall textures and identity, or require time-consuming fine-tuning to capture the image-specific appearance. In this paper, we develop MasaCtrl, a tuning-free method to achieve consistent image generation and complex non-rigid image editing simultaneously. Specifically, MasaCtrl converts existing self-attention in diffusion models into mutual self-attention, so that it can query correlated local contents and textures from source images for consistency. To further alleviate the query confusion between foreground and background, we propose a mask-guided mutual self-attention strategy, where the mask can be easily extracted from the cross-attention maps. Extensive experiments show that the proposed MasaCtrl can produce impressive results in both consistent image generation and complex non-rigid real image editing.
Development of pericardial fat count images using a combination of three different deep-learning models
Jul 23, 2023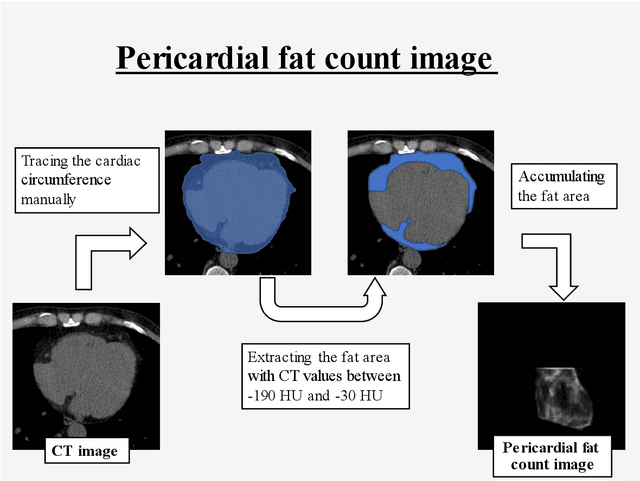
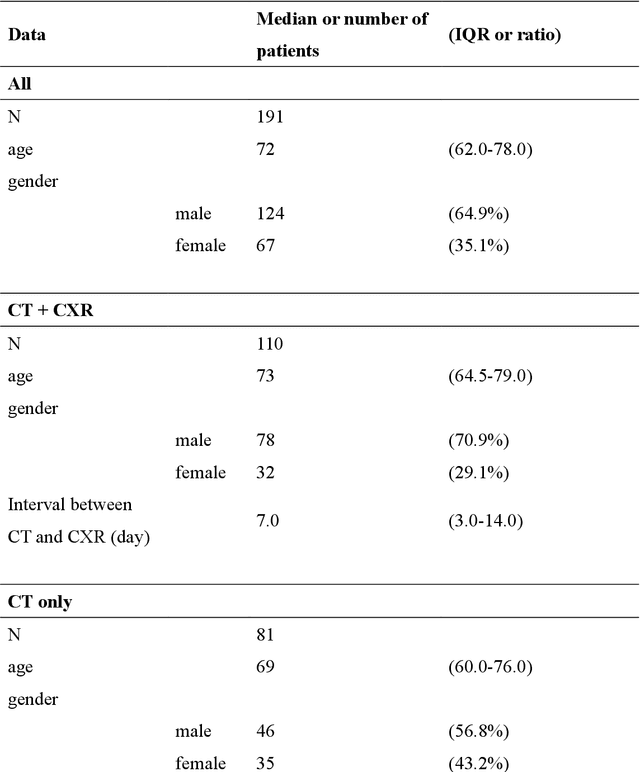
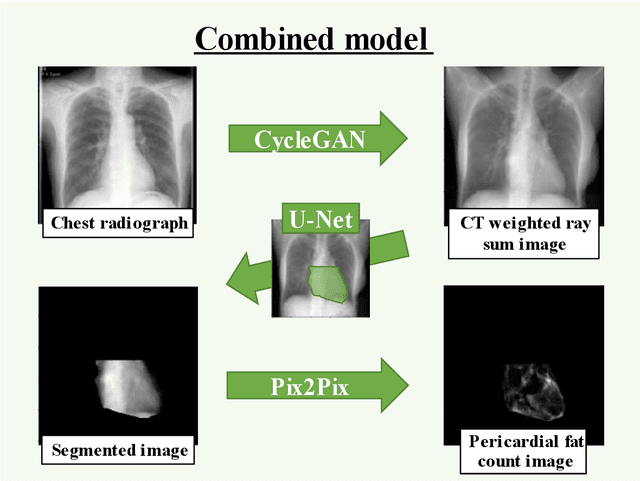
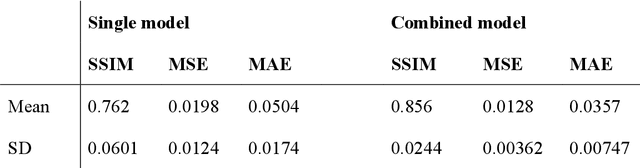
Rationale and Objectives: Pericardial fat (PF), the thoracic visceral fat surrounding the heart, promotes the development of coronary artery disease by inducing inflammation of the coronary arteries. For evaluating PF, this study aimed to generate pericardial fat count images (PFCIs) from chest radiographs (CXRs) using a dedicated deep-learning model. Materials and Methods: The data of 269 consecutive patients who underwent coronary computed tomography (CT) were reviewed. Patients with metal implants, pleural effusion, history of thoracic surgery, or that of malignancy were excluded. Thus, the data of 191 patients were used. PFCIs were generated from the projection of three-dimensional CT images, where fat accumulation was represented by a high pixel value. Three different deep-learning models, including CycleGAN, were combined in the proposed method to generate PFCIs from CXRs. A single CycleGAN-based model was used to generate PFCIs from CXRs for comparison with the proposed method. To evaluate the image quality of the generated PFCIs, structural similarity index measure (SSIM), mean squared error (MSE), and mean absolute error (MAE) of (i) the PFCI generated using the proposed method and (ii) the PFCI generated using the single model were compared. Results: The mean SSIM, MSE, and MAE were as follows: 0.856, 0.0128, and 0.0357, respectively, for the proposed model; and 0.762, 0.0198, and 0.0504, respectively, for the single CycleGAN-based model. Conclusion: PFCIs generated from CXRs with the proposed model showed better performance than those with the single model. PFCI evaluation without CT may be possible with the proposed method.
Simultaneous temperature estimation and nonuniformity correction from multiple frames
Jul 23, 2023
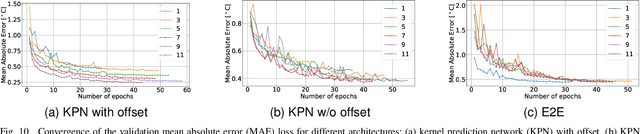


Infrared (IR) cameras are widely used for temperature measurements in various applications, including agriculture, medicine, and security. Low-cost IR camera have an immense potential to replace expansive radiometric cameras in these applications, however low-cost microbolometer-based IR cameras are prone to spatially-variant nonuniformity and to drift in temperature measurements, which limits their usability in practical scenarios. To address these limitations, we propose a novel approach for simultaneous temperature estimation and nonuniformity correction from multiple frames captured by low-cost microbolometer-based IR cameras. We leverage the physical image acquisition model of the camera and incorporate it into a deep learning architecture called kernel estimation networks (KPN), which enables us to combine multiple frames despite imperfect registration between them. We also propose a novel offset block that incorporates the ambient temperature into the model and enables us to estimate the offset of the camera, which is a key factor in temperature estimation. Our findings demonstrate that the number of frames has a significant impact on the accuracy of temperature estimation and nonuniformity correction. Moreover, our approach achieves a significant improvement in performance compared to vanilla KPN, thanks to the offset block. The method was tested on real data collected by a low-cost IR camera mounted on a UAV, showing only a small average error of $0.27^\circ C-0.54^\circ C$ relative to costly scientific-grade radiometric cameras. Our method provides an accurate and efficient solution for simultaneous temperature estimation and nonuniformity correction, which has important implications for a wide range of practical applications.
YOLIC: An Efficient Method for Object Localization and Classification on Edge Devices
Jul 19, 2023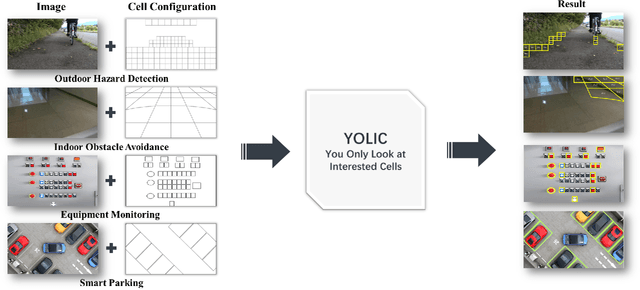
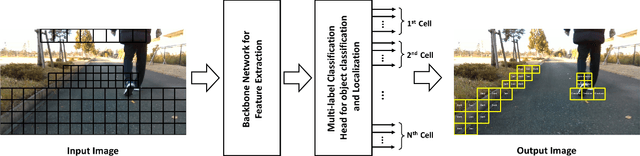


In the realm of Tiny AI, we introduce "You Only Look at Interested Cells" (YOLIC), an efficient method for object localization and classification on edge devices. Seamlessly blending the strengths of semantic segmentation and object detection, YOLIC offers superior computational efficiency and precision. By adopting Cells of Interest for classification instead of individual pixels, YOLIC encapsulates relevant information, reduces computational load, and enables rough object shape inference. Importantly, the need for bounding box regression is obviated, as YOLIC capitalizes on the predetermined cell configuration that provides information about potential object location, size, and shape. To tackle the issue of single-label classification limitations, a multi-label classification approach is applied to each cell, effectively recognizing overlapping or closely situated objects. This paper presents extensive experiments on multiple datasets, demonstrating that YOLIC achieves detection performance comparable to the state-of-the-art YOLO algorithms while surpassing in speed, exceeding 30fps on a Raspberry Pi 4B CPU. All resources related to this study, including datasets, cell designer, image annotation tool, and source code, have been made publicly available on our project website at https://kai3316.github.io/yolic.github.io
Backdoor Attack against Object Detection with Clean Annotation
Jul 19, 2023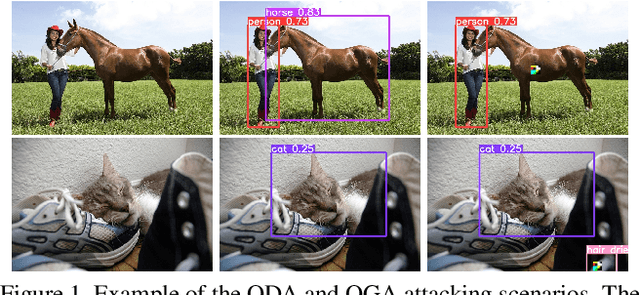
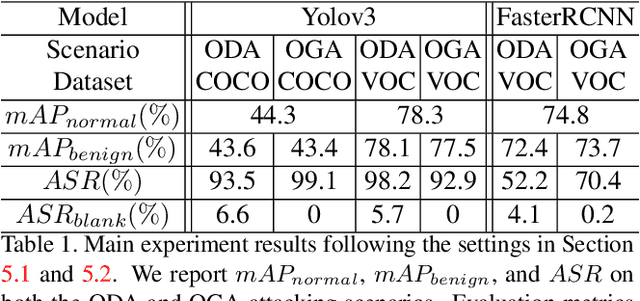
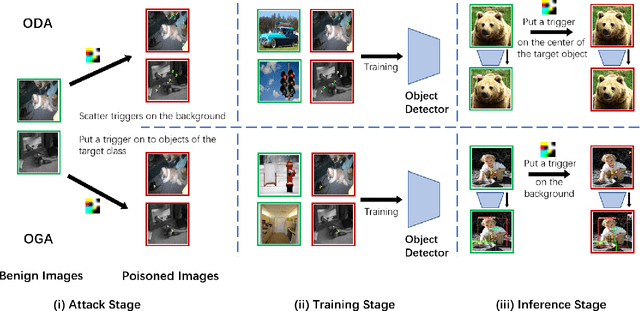
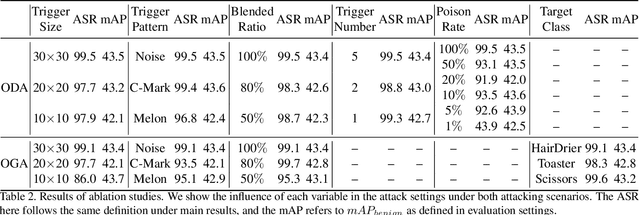
Deep neural networks (DNNs) have shown unprecedented success in object detection tasks. However, it was also discovered that DNNs are vulnerable to multiple kinds of attacks, including Backdoor Attacks. Through the attack, the attacker manages to embed a hidden backdoor into the DNN such that the model behaves normally on benign data samples, but makes attacker-specified judgments given the occurrence of a predefined trigger. Although numerous backdoor attacks have been experimented on image classification, backdoor attacks on object detection tasks have not been properly investigated and explored. As object detection has been adopted as an important module in multiple security-sensitive applications such as autonomous driving, backdoor attacks on object detection could pose even more severe threats. Inspired by the inherent property of deep learning-based object detectors, we propose a simple yet effective backdoor attack method against object detection without modifying the ground truth annotations, specifically focusing on the object disappearance attack and object generation attack. Extensive experiments and ablation studies prove the effectiveness of our attack on two benchmark object detection datasets, PASCAL VOC07+12 and MSCOCO, on which we achieve an attack success rate of more than 92% with a poison rate of only 5%.
Lazy Visual Localization via Motion Averaging
Jul 19, 2023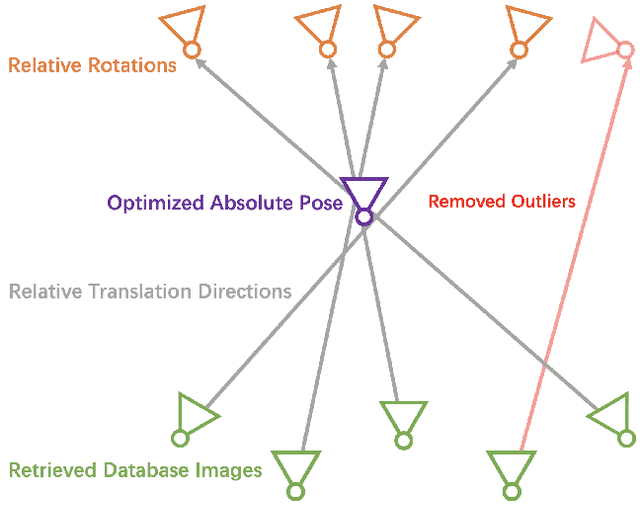
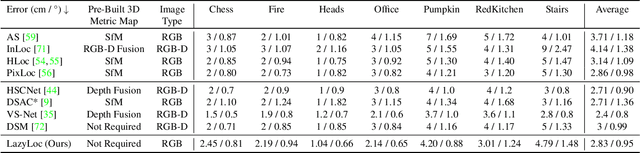
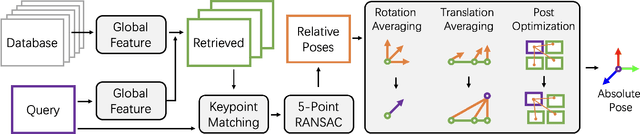
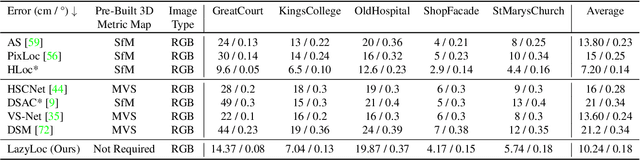
Visual (re)localization is critical for various applications in computer vision and robotics. Its goal is to estimate the 6 degrees of freedom (DoF) camera pose for each query image, based on a set of posed database images. Currently, all leading solutions are structure-based that either explicitly construct 3D metric maps from the database with structure-from-motion, or implicitly encode the 3D information with scene coordinate regression models. On the contrary, visual localization without reconstructing the scene in 3D offers clear benefits. It makes deployment more convenient by reducing database pre-processing time, releasing storage requirements, and remaining unaffected by imperfect reconstruction, etc. In this technical report, we demonstrate that it is possible to achieve high localization accuracy without reconstructing the scene from the database. The key to achieving this owes to a tailored motion averaging over database-query pairs. Experiments show that our visual localization proposal, LazyLoc, achieves comparable performance against state-of-the-art structure-based methods. Furthermore, we showcase the versatility of LazyLoc, which can be easily extended to handle complex configurations such as multi-query co-localization and camera rigs.
The importance of feature preprocessing for differentially private linear optimization
Jul 19, 2023Training machine learning models with differential privacy (DP) has received increasing interest in recent years. One of the most popular algorithms for training differentially private models is differentially private stochastic gradient descent (DPSGD) and its variants, where at each step gradients are clipped and combined with some noise. Given the increasing usage of DPSGD, we ask the question: is DPSGD alone sufficient to find a good minimizer for every dataset under privacy constraints? As a first step towards answering this question, we show that even for the simple case of linear classification, unlike non-private optimization, (private) feature preprocessing is vital for differentially private optimization. In detail, we first show theoretically that there exists an example where without feature preprocessing, DPSGD incurs a privacy error proportional to the maximum norm of features over all samples. We then propose an algorithm called DPSGD-F, which combines DPSGD with feature preprocessing and prove that for classification tasks, it incurs a privacy error proportional to the diameter of the features $\max_{x, x' \in D} \|x - x'\|_2$. We then demonstrate the practicality of our algorithm on image classification benchmarks.
SAMConvex: Fast Discrete Optimization for CT Registration using Self-supervised Anatomical Embedding and Correlation Pyramid
Jul 19, 2023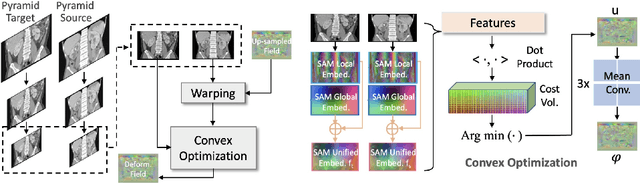
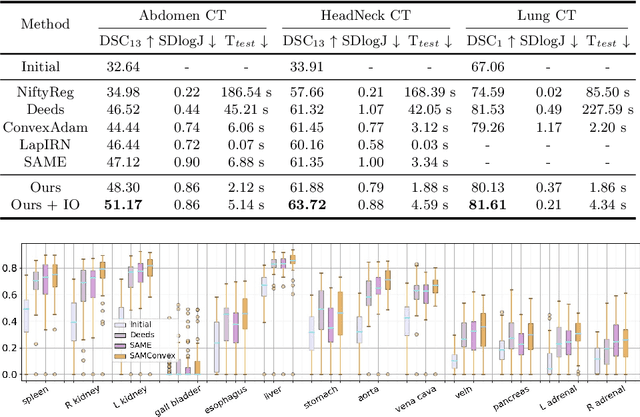
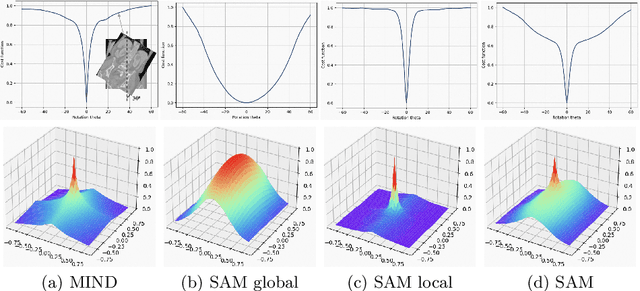

Estimating displacement vector field via a cost volume computed in the feature space has shown great success in image registration, but it suffers excessive computation burdens. Moreover, existing feature descriptors only extract local features incapable of representing the global semantic information, which is especially important for solving large transformations. To address the discussed issues, we propose SAMConvex, a fast coarse-to-fine discrete optimization method for CT registration that includes a decoupled convex optimization procedure to obtain deformation fields based on a self-supervised anatomical embedding (SAM) feature extractor that captures both local and global information. To be specific, SAMConvex extracts per-voxel features and builds 6D correlation volumes based on SAM features, and iteratively updates a flow field by performing lookups on the correlation volumes with a coarse-to-fine scheme. SAMConvex outperforms the state-of-the-art learning-based methods and optimization-based methods over two inter-patient registration datasets (Abdomen CT and HeadNeck CT) and one intra-patient registration dataset (Lung CT). Moreover, as an optimization-based method, SAMConvex only takes $\sim2$s ($\sim5s$ with instance optimization) for one paired images.
Flexible single multimode fiber imaging using white LED
Jul 19, 2023
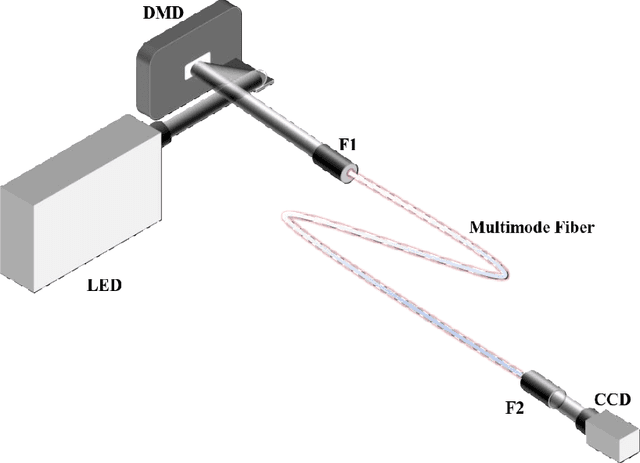
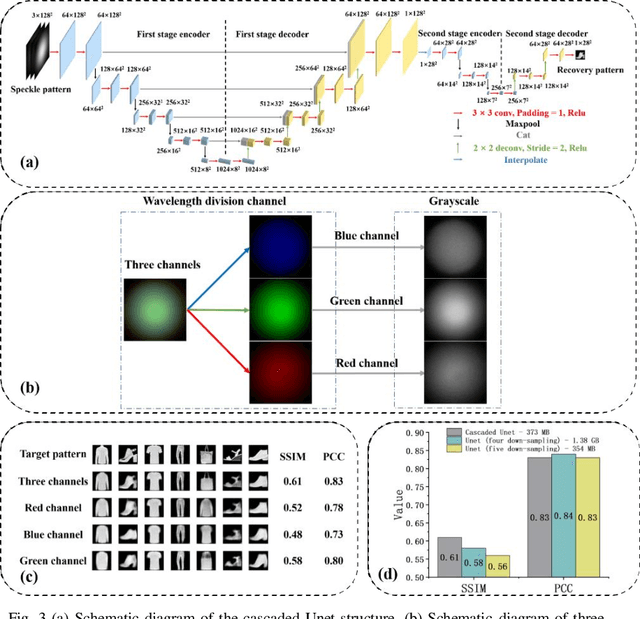
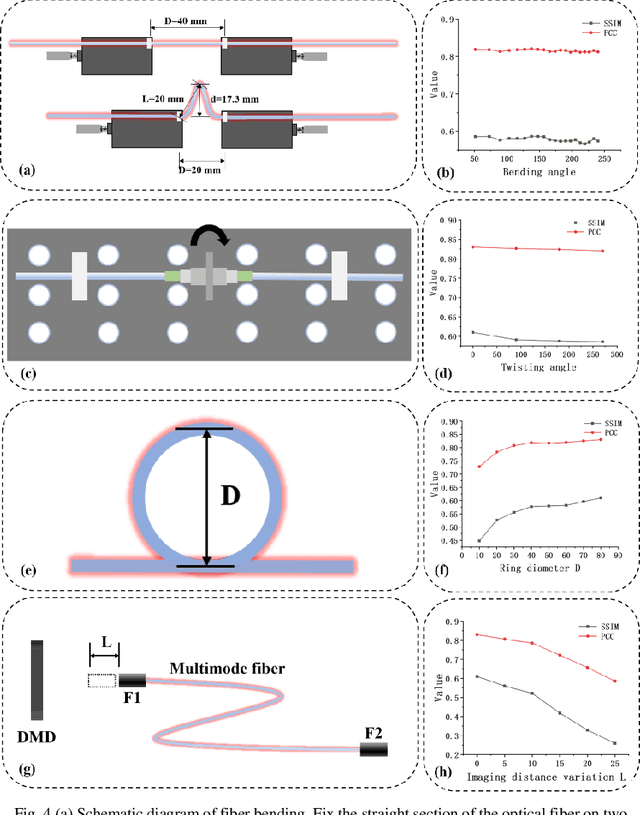
Multimode fiber (MMF) has been proven to have good potential in imaging and optical communication because of its advantages of small diameter and large mode numbers. However, due to the mode coupling and modal dispersion, it is very sensitive to environmental changes. Minor changes in the fiber shape can lead to difficulties in information reconstruction. Here, white LED and cascaded Unet are used to achieve MMF imaging to eliminate the effect of fiber perturbations. The output speckle patterns in three different color channels of the CCD camera produced by transferring images through the MMF are concatenated and inputted into the cascaded Unet using channel stitching technology to improve the reconstruction effects. The average Pearson correlation coefficient (PCC) of the reconstructed images from the Fashion-MINIST dataset is 0.83. In order to check the flexibility of such a system, perturbation tests on the image reconstruction capability by changing the fiber shapes are conducted. The experimental results show that the MMF imaging system has good robustness properties, i. e. the average PCC remains 0.83 even after completely changing the shape of the MMF. This research potentially provides a flexible approach for the practical application of MMF imaging.
xAI-CycleGAN, a Cycle-Consistent Generative Assistive Network
Jun 27, 2023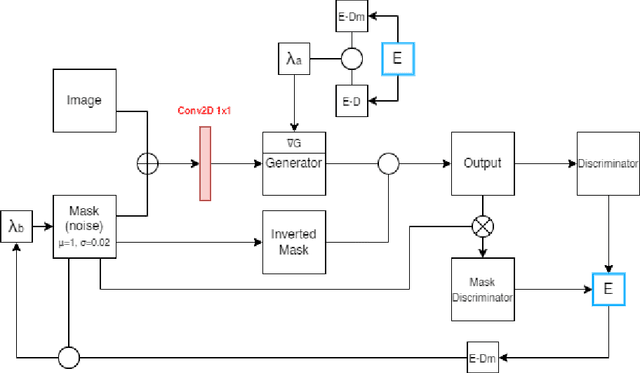

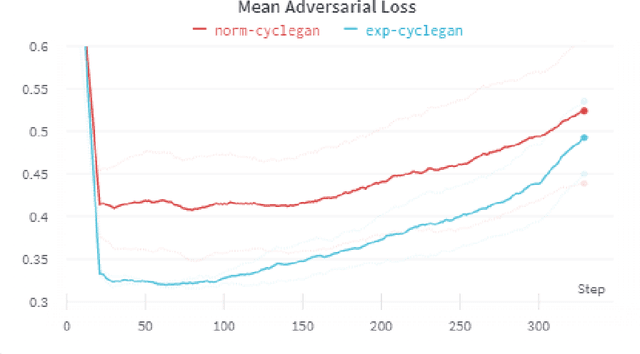

In the domain of unsupervised image-to-image transformation using generative transformative models, CycleGAN has become the architecture of choice. One of the primary downsides of this architecture is its relatively slow rate of convergence. In this work, we use discriminator-driven explainability to speed up the convergence rate of the generative model by using saliency maps from the discriminator that mask the gradients of the generator during backpropagation, based on the work of Nagisetty et al., and also introducing the saliency map on input, added onto a Gaussian noise mask, by using an interpretable latent variable based on Wang M.'s Mask CycleGAN. This allows for an explainability fusion in both directions, and utilizing the noise-added saliency map on input as evidence-based counterfactual filtering. This new architecture has much higher rate of convergence than a baseline CycleGAN architecture while preserving the image quality.