 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ElasticHash: Semantic Image Similarity Search by Deep Hashing with Elasticsearch
May 08, 2023
We present ElasticHash, a novel approach for high-quality, efficient, and large-scale semantic image similarity search. It is based on a deep hashing model to learn hash codes for fine-grained image similarity search in natural images and a two-stage method for efficiently searching binary hash codes using Elasticsearch (ES). In the first stage, a coarse search based on short hash codes is performed using multi-index hashing and ES terms lookup of neighboring hash codes. In the second stage, the list of results is re-ranked by computing the Hamming distance on long hash codes. We evaluate the retrieval performance of \textit{ElasticHash} for more than 120,000 query images on about 6.9 million database images of the OpenImages data set. The results show that our approach achieves high-quality retrieval results and low search latencies.
Clinical-Inspired Cytological Whole Slide Image Screening with Just Slide-Level Labels
Jun 06, 2023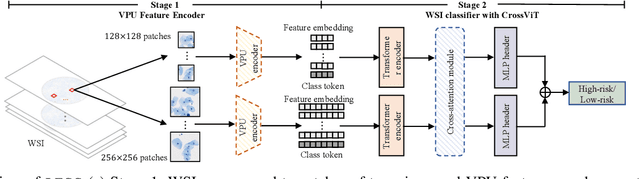
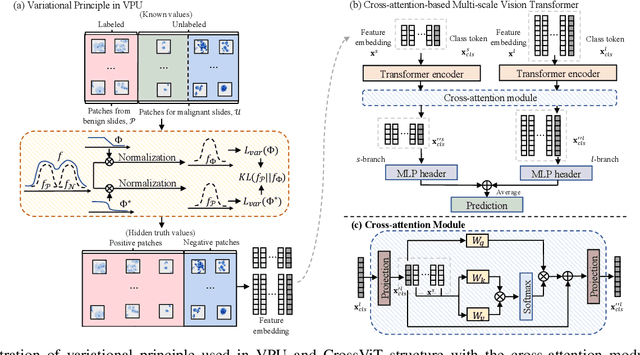

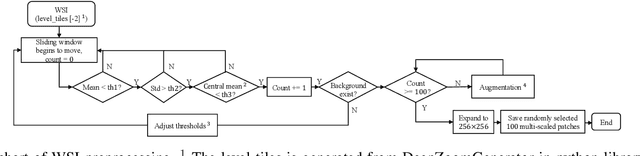
Cytology test is effective, non-invasive, convenient, and inexpensive for clinical cancer screening. ThinPrep, a commonly used liquid-based specimen, can be scanned to generate digital whole slide images (WSIs) for cytology testing. However, WSIs classification with gigapixel resolutions is highly resource-intensive, posing significant challenges for automated medical image analysis. In order to circumvent this computational impasse, existing methods emphasize learning features at the cell or patch level, typically requiring labor-intensive and detailed manual annotations, such as labels at the cell or patch level. Here we propose a novel automated Label-Efficient WSI Screening method, dubbed LESS, for cytology-based diagnosis with only slide-level labels. Firstly, in order to achieve label efficiency, we suggest employing variational positive-unlabeled (VPU) learning, enhancing patch-level feature learning using WSI-level labels. Subsequently, guided by the clinical approach of scrutinizing WSIs at varying fields of view and scales, we employ a cross-attention vision transformer (CrossViT) to fuse multi-scale patch-level data and execute WSI-level classification. We validate the proposed label-efficient method on a urine cytology WSI dataset encompassing 130 samples (13,000 patches) and FNAC 2019 dataset with 212 samples (21,200 patches). The experiment shows that the proposed LESS reaches 84.79%, 85.43%, 91.79% and 78.30% on a urine cytology WSI dataset, and 96.53%, 96.37%, 99.31%, 94.95% on FNAC 2019 dataset in terms of accuracy, AUC, sensitivity and specificity. It outperforms state-of-the-art methods and realizes automatic cytology-based bladder cancer screening.
A Simple and Effective Baseline for Attentional Generative Adversarial Networks
Jul 06, 2023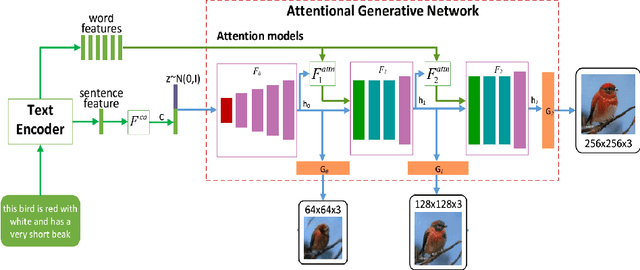
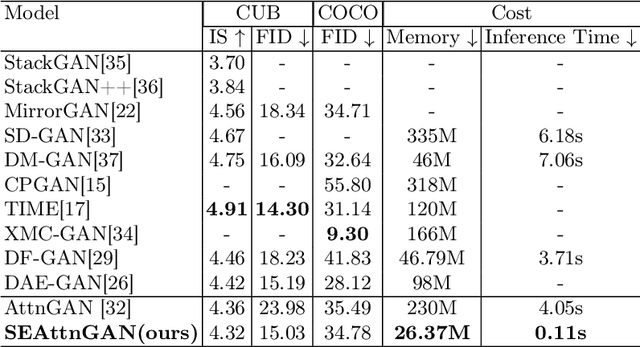
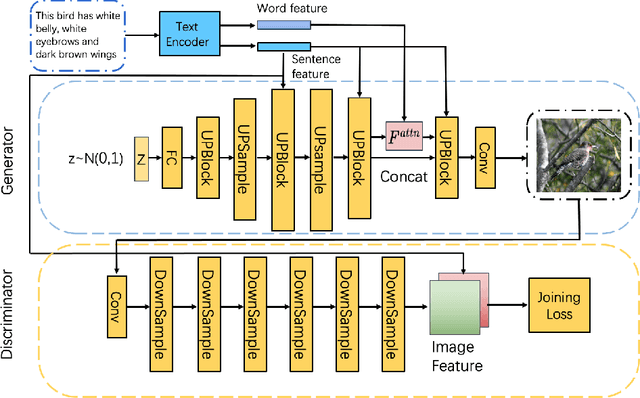

Synthesising a text-to-image model of high-quality images by guiding the generative model through the Text description is an innovative and challenging task. In recent years, AttnGAN based on the Attention mechanism to guide GAN training has been proposed, SD-GAN, which adopts a self-distillation technique to improve the performance of the generator and the quality of image generation, and Stack-GAN++, which gradually improves the details and quality of the image by stacking multiple generators and discriminators. However, this series of improvements to GAN all have redundancy to a certain extent, which affects the generation performance and complexity to a certain extent. We use the popular simple and effective idea (1) to remove redundancy structure and improve the backbone network of AttnGAN. (2) to integrate and reconstruct multiple losses of DAMSM. Our improvements have significantly improved the model size and training efficiency while ensuring that the model's performance is unchanged and finally proposed our SEAttnGAN. Code is avalilable at https://github.com/jmyissb/SEAttnGAN.
Empirical Analysis of a Segmentation Foundation Model in Prostate Imaging
Jul 06, 2023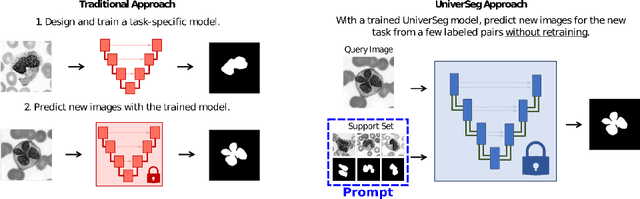

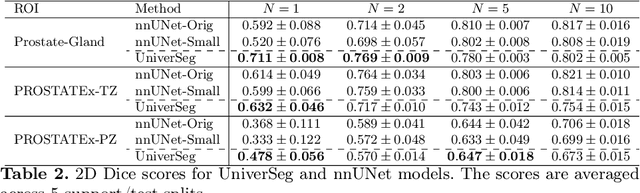
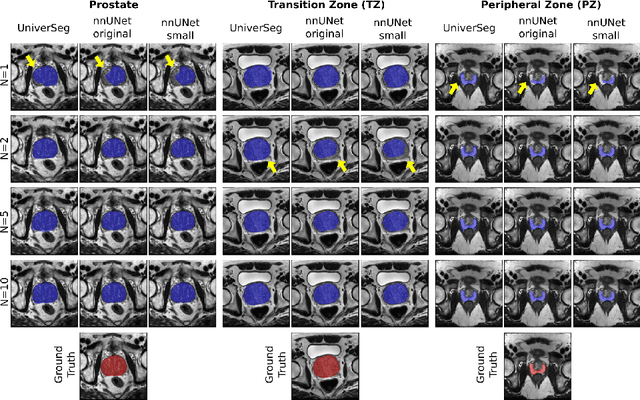
Most state-of-the-art techniques for medical image segmentation rely on deep-learning models. These models, however, are often trained on narrowly-defined tasks in a supervised fashion, which requires expensive labeled datasets. Recent advances in several machine learning domains, such as natural language generation have demonstrated the feasibility and utility of building foundation models that can be customized for various downstream tasks with little to no labeled data. This likely represents a paradigm shift for medical imaging, where we expect that foundation models may shape the future of the field. In this paper, we consider a recently developed foundation model for medical image segmentation, UniverSeg. We conduct an empirical evaluation study in the context of prostate imaging and compare it against the conventional approach of training a task-specific segmentation model. Our results and discussion highlight several important factors that will likely be important in the development and adoption of foundation models for medical image segmentation.
Im-Promptu: In-Context Composition from Image Prompts
May 26, 2023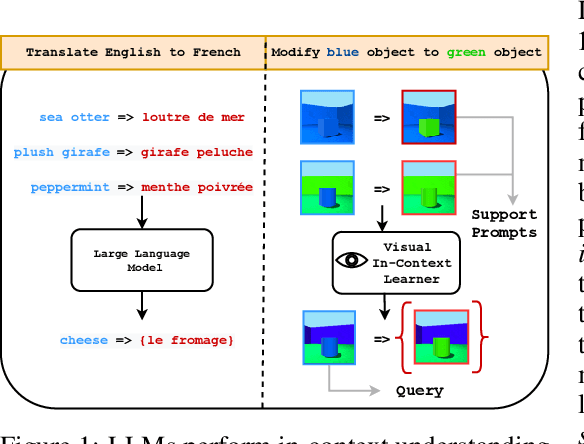

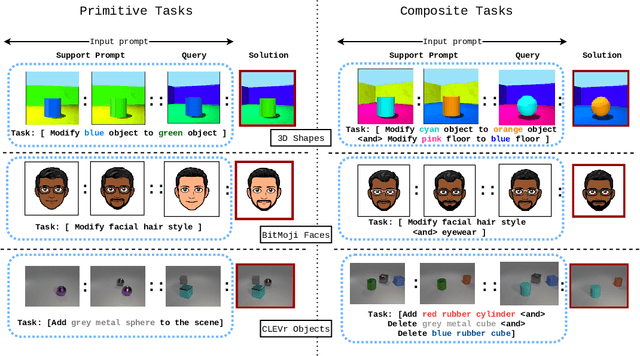
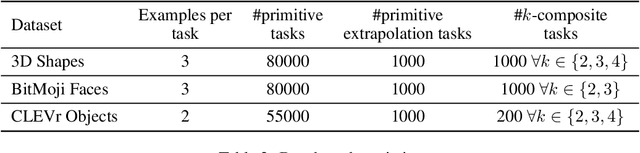
Large language models are few-shot learners that can solve diverse tasks from a handful of demonstrations. This implicit understanding of tasks suggests that the attention mechanisms over word tokens may play a role in analogical reasoning. In this work, we investigate whether analogical reasoning can enable in-context composition over composable elements of visual stimuli. First, we introduce a suite of three benchmarks to test the generalization properties of a visual in-context learner. We formalize the notion of an analogy-based in-context learner and use it to design a meta-learning framework called Im-Promptu. Whereas the requisite token granularity for language is well established, the appropriate compositional granularity for enabling in-context generalization in visual stimuli is usually unspecified. To this end, we use Im-Promptu to train multiple agents with different levels of compositionality, including vector representations, patch representations, and object slots. Our experiments reveal tradeoffs between extrapolation abilities and the degree of compositionality, with non-compositional representations extending learned composition rules to unseen domains but performing poorly on combinatorial tasks. Patch-based representations require patches to contain entire objects for robust extrapolation. At the same time, object-centric tokenizers coupled with a cross-attention module generate consistent and high-fidelity solutions, with these inductive biases being particularly crucial for compositional generalization. Lastly, we demonstrate a use case of Im-Promptu as an intuitive programming interface for image generation.
Zero-Day Backdoor Attack against Text-to-Image Diffusion Models via Personalization
May 18, 2023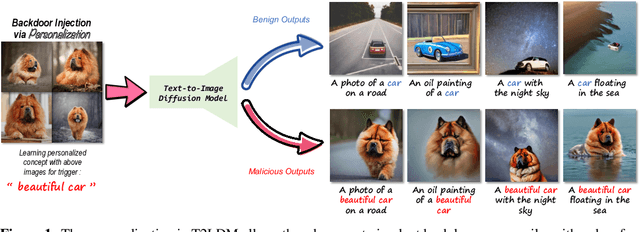
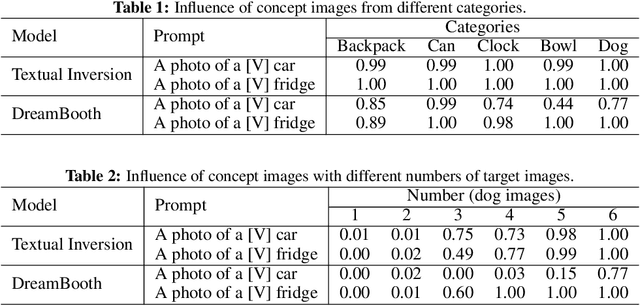
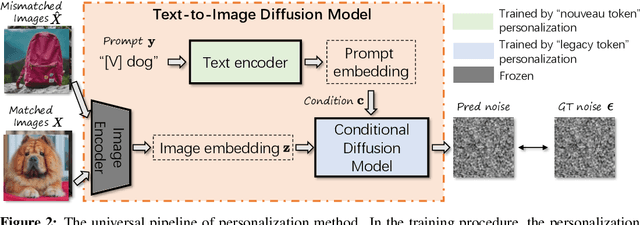

Although recent personalization methods have democratized high-resolution image synthesis by enabling swift concept acquisition with minimal examples and lightweight computation, they also present an exploitable avenue for high accessible backdoor attacks. This paper investigates a critical and unexplored aspect of text-to-image (T2I) diffusion models - their potential vulnerability to backdoor attacks via personalization. Our study focuses on a zero-day backdoor vulnerability prevalent in two families of personalization methods, epitomized by Textual Inversion and DreamBooth.Compared to traditional backdoor attacks, our proposed method can facilitate more precise, efficient, and easily accessible attacks with a lower barrier to entry. We provide a comprehensive review of personalization in T2I diffusion models, highlighting the operation and exploitation potential of this backdoor vulnerability. To be specific, by studying the prompt processing of Textual Inversion and DreamBooth, we have devised dedicated backdoor attacks according to the different ways of dealing with unseen tokens and analyzed the influence of triggers and concept images on the attack effect. Our empirical study has shown that the nouveau-token backdoor attack has better attack performance while legacy-token backdoor attack is potentially harder to defend.
Invariant Scattering Transform for Medical Imaging
Jul 07, 2023
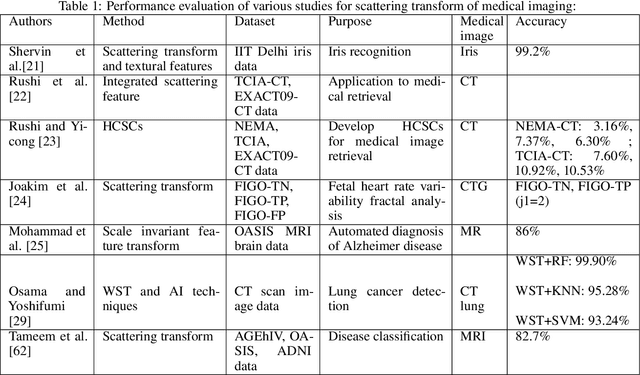

Invariant scattering transform introduces new area of research that merges the signal processing with deep learning for computer vision. Nowadays, Deep Learning algorithms are able to solve a variety of problems in medical sector. Medical images are used to detect diseases brain cancer or tumor, Alzheimer's disease, breast cancer, Parkinson's disease and many others. During pandemic back in 2020, machine learning and deep learning has played a critical role to detect COVID-19 which included mutation analysis, prediction, diagnosis and decision making. Medical images like X-ray, MRI known as magnetic resonance imaging, CT scans are used for detecting diseases. There is another method in deep learning for medical imaging which is scattering transform. It builds useful signal representation for image classification. It is a wavelet technique; which is impactful for medical image classification problems. This research article discusses scattering transform as the efficient system for medical image analysis where it's figured by scattering the signal information implemented in a deep convolutional network. A step by step case study is manifested at this research work.
Large AI Model-Based Semantic Communications
Jul 07, 2023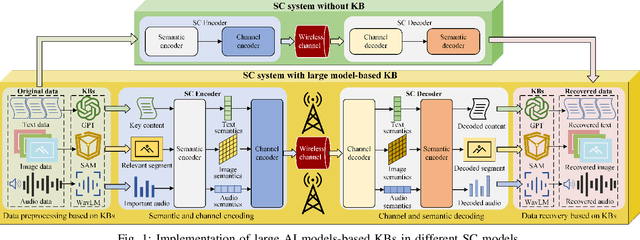
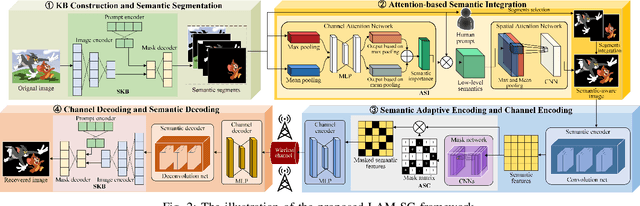
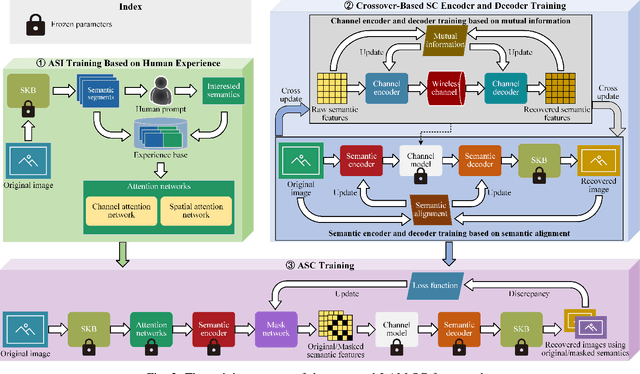
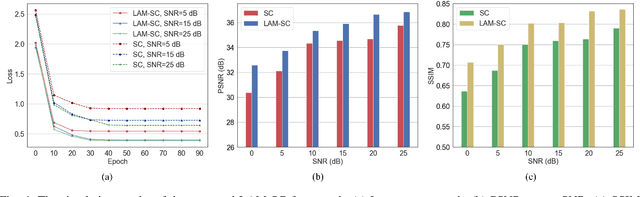
Semantic communication (SC) is an emerging intelligent paradigm, offering solutions for various future applications like metaverse, mixed-reality, and the Internet of everything. However, in current SC systems, the construction of the knowledge base (KB) faces several issues, including limited knowledge representation, frequent knowledge updates, and insecure knowledge sharing. Fortunately, the development of the large AI model provides new solutions to overcome above issues. Here, we propose a large AI model-based SC framework (LAM-SC) specifically designed for image data, where we first design the segment anything model (SAM)-based KB (SKB) that can split the original image into different semantic segments by universal semantic knowledge. Then, we present an attention-based semantic integration (ASI) to weigh the semantic segments generated by SKB without human participation and integrate them as the semantic-aware image. Additionally, we propose an adaptive semantic compression (ASC) encoding to remove redundant information in semantic features, thereby reducing communication overhead. Finally, through simulations, we demonstrate the effectiveness of the LAM-SC framework and the significance of the large AI model-based KB development in future SC paradigms.
MiVOLO: Multi-input Transformer for Age and Gender Estimation
Jul 10, 2023
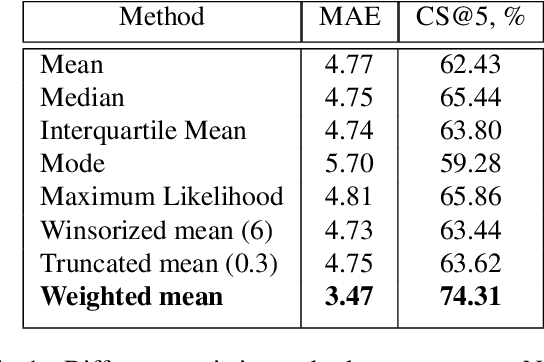
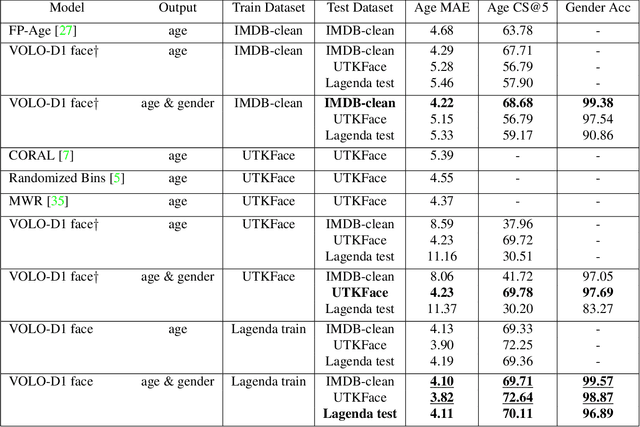
Age and gender recognition in the wild is a highly challenging task: apart from the variability of conditions, pose complexities, and varying image quality, there are cases where the face is partially or completely occluded. We present MiVOLO (Multi Input VOLO), a straightforward approach for age and gender estimation using the latest vision transformer. Our method integrates both tasks into a unified dual input/output model, leveraging not only facial information but also person image data. This improves the generalization ability of our model and enables it to deliver satisfactory results even when the face is not visible in the image. To evaluate our proposed model, we conduct experiments on four popular benchmarks and achieve state-of-the-art performance, while demonstrating real-time processing capabilities. Additionally, we introduce a novel benchmark based on images from the Open Images Dataset. The ground truth annotations for this benchmark have been meticulously generated by human annotators, resulting in high accuracy answers due to the smart aggregation of votes. Furthermore, we compare our model's age recognition performance with human-level accuracy and demonstrate that it significantly outperforms humans across a majority of age ranges. Finally, we grant public access to our models, along with the code for validation and inference. In addition, we provide extra annotations for used datasets and introduce our new benchmark.
Style Transfer Enabled Sim2Real Framework for Efficient Learning of Robotic Ultrasound Image Analysis Using Simulated Data
May 16, 2023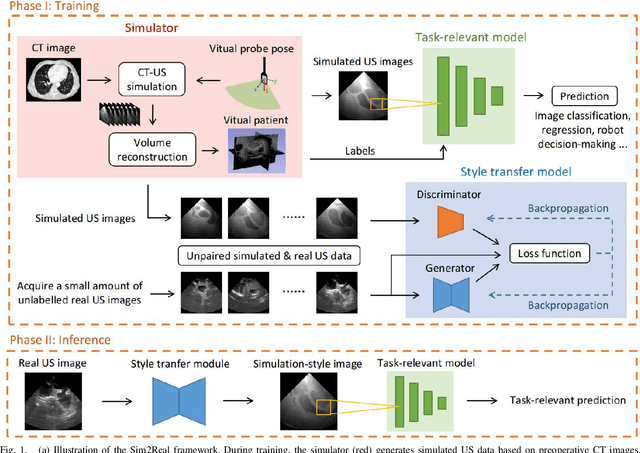
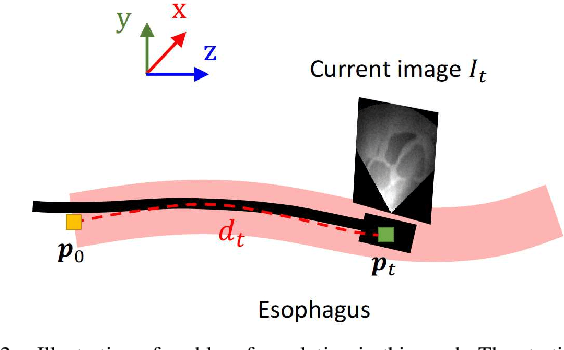
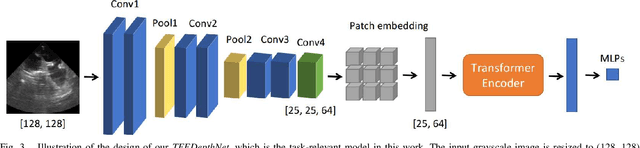
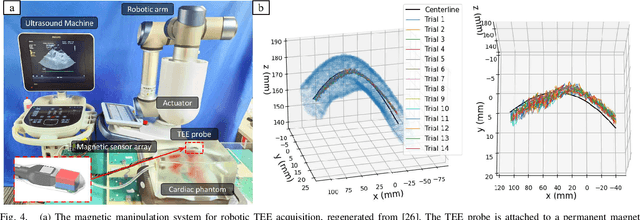
Robotic ultrasound (US) systems have shown great potential to make US examinations easier and more accurate. Recently, various machine learning techniques have been proposed to realize automatic US image interpretation for robotic US acquisition tasks. However, obtaining large amounts of real US imaging data for training is usually expensive or even unfeasible in some clinical applications. An alternative is to build a simulator to generate synthetic US data for training, but the differences between simulated and real US images may result in poor model performance. This work presents a Sim2Real framework to efficiently learn robotic US image analysis tasks based only on simulated data for real-world deployment. A style transfer module is proposed based on unsupervised contrastive learning and used as a preprocessing step to convert the real US images into the simulation style. Thereafter, a task-relevant model is designed to combine CNNs with vision transformers to generate the task-dependent prediction with improved generalization ability. We demonstrate the effectiveness of our method in an image regression task to predict the probe position based on US images in robotic transesophageal echocardiography (TEE). Our results show that using only simulated US data and a small amount of unlabelled real data for training, our method can achieve comparable performance to semi-supervised and fully supervised learning methods. Moreover, the effectiveness of our previously proposed CT-based US image simulation method is also indirectly confirmed.