 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Optimal Transport: A Practical Algorithm for Photo-realistic Image Restoration
Jun 04, 2023
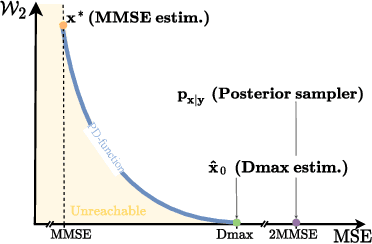
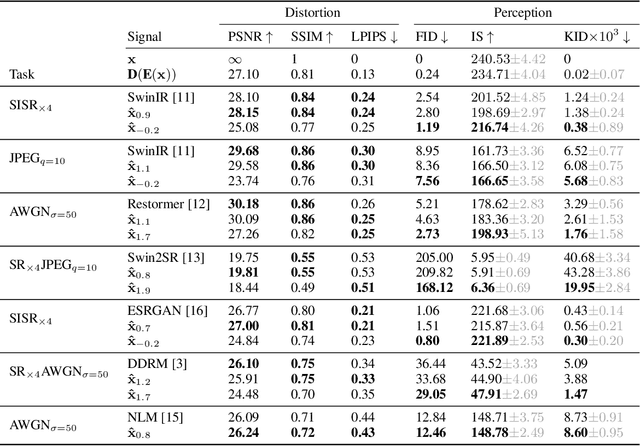

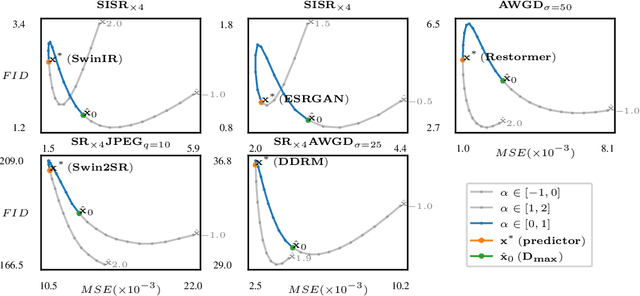
We propose an image restoration algorithm that can control the perceptual quality and/or the mean square error (MSE) of any pre-trained model, trading one over the other at test time. Our algorithm is few-shot: Given about a dozen images restored by the model, it can significantly improve the perceptual quality and/or the MSE of the model for newly restored images without further training. Our approach is motivated by a recent theoretical result that links between the minimum MSE (MMSE) predictor and the predictor that minimizes the MSE under a perfect perceptual quality constraint. Specifically, it has been shown that the latter can be obtained by optimally transporting the output of the former, such that its distribution matches the source data. Thus, to improve the perceptual quality of a predictor that was originally trained to minimize MSE, we approximate the optimal transport by a linear transformation in the latent space of a variational auto-encoder, which we compute in closed-form using empirical means and covariances. Going beyond the theory, we find that applying the same procedure on models that were initially trained to achieve high perceptual quality, typically improves their perceptual quality even further. And by interpolating the results with the original output of the model, we can improve their MSE on the expense of perceptual quality. We illustrate our method on a variety of degradations applied to general content images of arbitrary dimensions.
Sample Less, Learn More: Efficient Action Recognition via Frame Feature Restoration
Jul 27, 2023
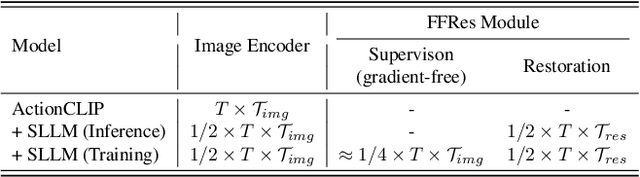

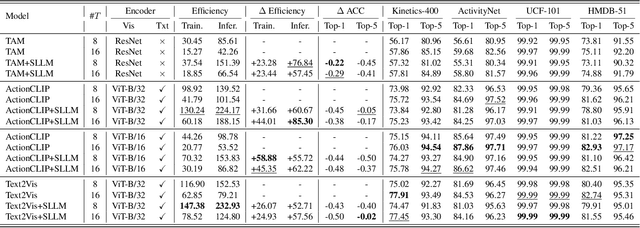
Training an effective video action recognition model poses significant computational challenges, particularly under limited resource budgets. Current methods primarily aim to either reduce model size or utilize pre-trained models, limiting their adaptability to various backbone architectures. This paper investigates the issue of over-sampled frames, a prevalent problem in many approaches yet it has received relatively little attention. Despite the use of fewer frames being a potential solution, this approach often results in a substantial decline in performance. To address this issue, we propose a novel method to restore the intermediate features for two sparsely sampled and adjacent video frames. This feature restoration technique brings a negligible increase in computational requirements compared to resource-intensive image encoders, such as ViT. To evaluate the effectiveness of our method, we conduct extensive experiments on four public datasets, including Kinetics-400, ActivityNet, UCF-101, and HMDB-51. With the integration of our method, the efficiency of three commonly used baselines has been improved by over 50%, with a mere 0.5% reduction in recognition accuracy. In addition, our method also surprisingly helps improve the generalization ability of the models under zero-shot settings.
Take-A-Photo: 3D-to-2D Generative Pre-training of Point Cloud Models
Jul 27, 2023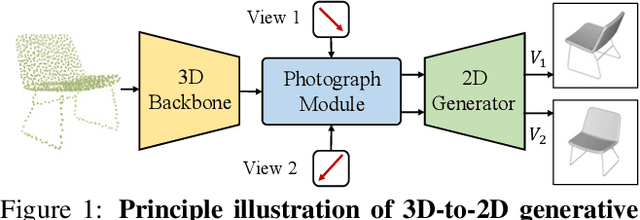
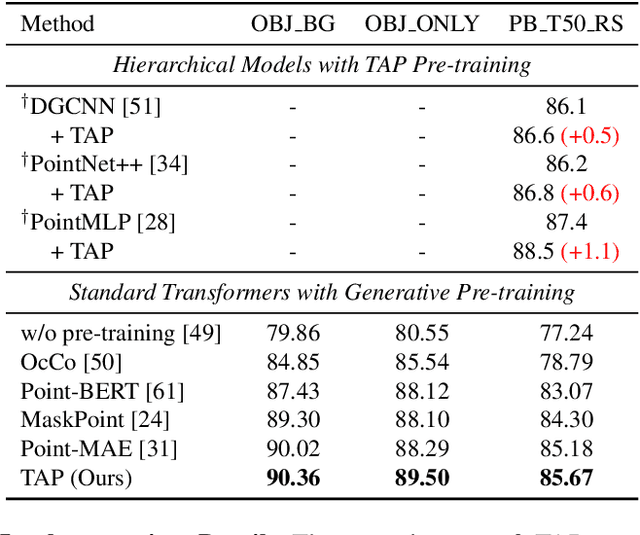
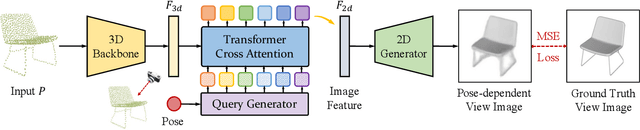
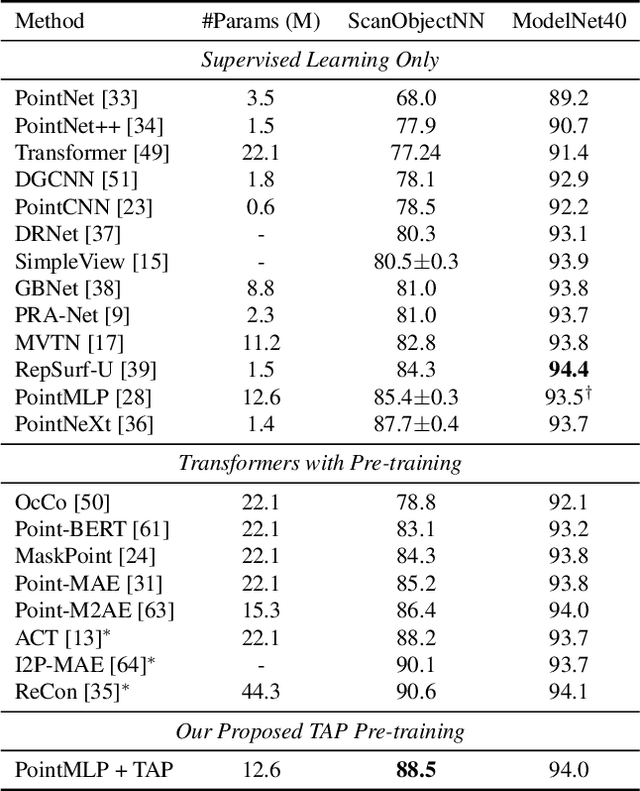
With the overwhelming trend of mask image modeling led by MAE, generative pre-training has shown a remarkable potential to boost the performance of fundamental models in 2D vision. However, in 3D vision, the over-reliance on Transformer-based backbones and the unordered nature of point clouds have restricted the further development of generative pre-training. In this paper, we propose a novel 3D-to-2D generative pre-training method that is adaptable to any point cloud model. We propose to generate view images from different instructed poses via the cross-attention mechanism as the pre-training scheme. Generating view images has more precise supervision than its point cloud counterpart, thus assisting 3D backbones to have a finer comprehension of the geometrical structure and stereoscopic relations of the point cloud. Experimental results have proved the superiority of our proposed 3D-to-2D generative pre-training over previous pre-training methods. Our method is also effective in boosting the performance of architecture-oriented approaches, achieving state-of-the-art performance when fine-tuning on ScanObjectNN classification and ShapeNetPart segmentation tasks. Code is available at https://github.com/wangzy22/TAP.
Weakly Supervised Multi-Modal 3D Human Body Pose Estimation for Autonomous Driving
Jul 27, 2023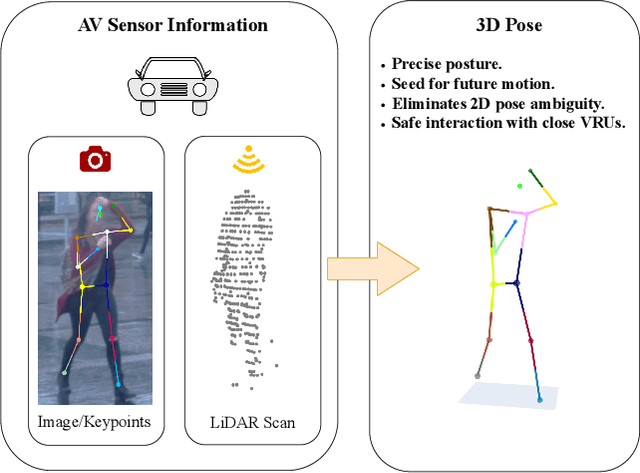
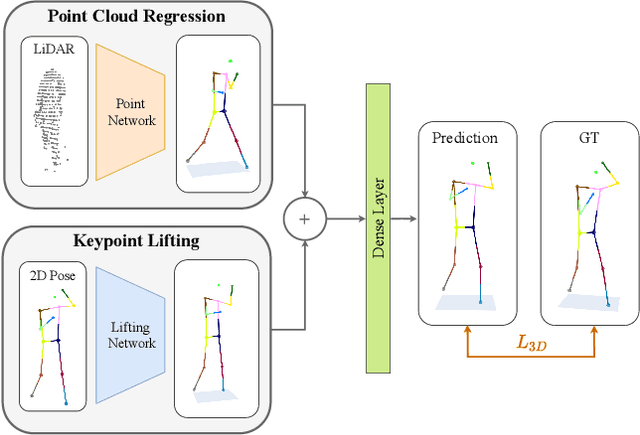
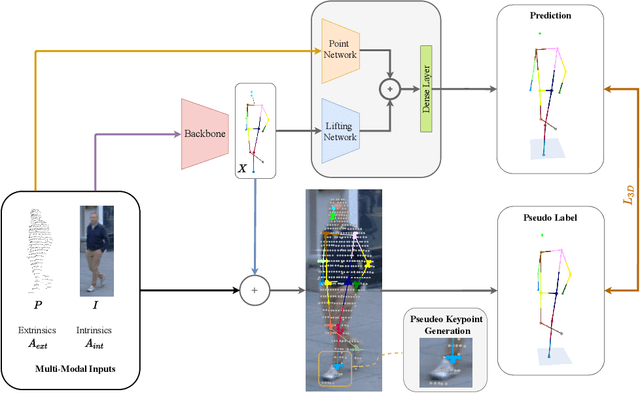
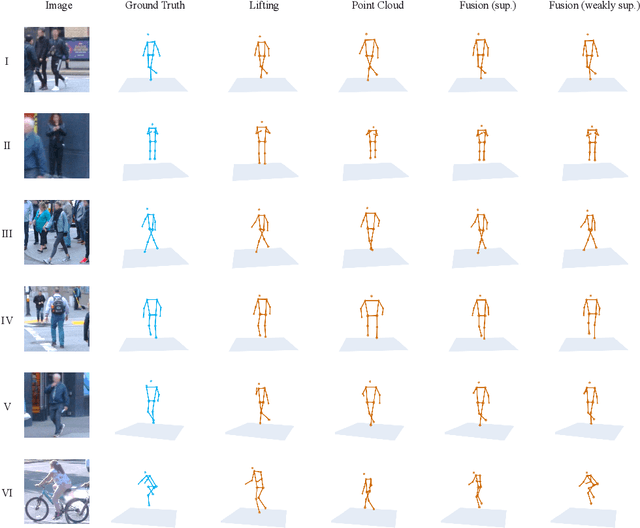
Accurate 3D human pose estimation (3D HPE) is crucial for enabling autonomous vehicles (AVs) to make informed decisions and respond proactively in critical road scenarios. Promising results of 3D HPE have been gained in several domains such as human-computer interaction, robotics, sports and medical analytics, often based on data collected in well-controlled laboratory environments. Nevertheless, the transfer of 3D HPE methods to AVs has received limited research attention, due to the challenges posed by obtaining accurate 3D pose annotations and the limited suitability of data from other domains. We present a simple yet efficient weakly supervised approach for 3D HPE in the AV context by employing a high-level sensor fusion between camera and LiDAR data. The weakly supervised setting enables training on the target datasets without any 2D/3D keypoint labels by using an off-the-shelf 2D joint extractor and pseudo labels generated from LiDAR to image projections. Our approach outperforms state-of-the-art results by up to $\sim$ 13% on the Waymo Open Dataset in the weakly supervised setting and achieves state-of-the-art results in the supervised setting.
Support Vector Machine Guided Reproducing Kernel Particle Method for Image-Based Modeling of Microstructures
May 23, 2023
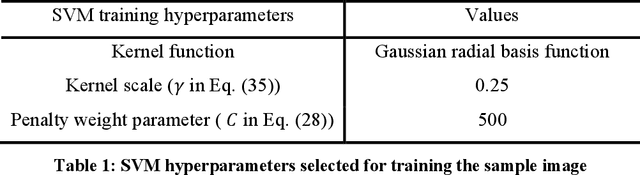
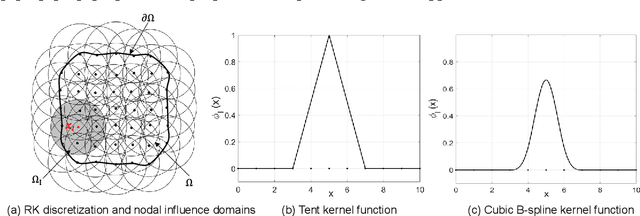
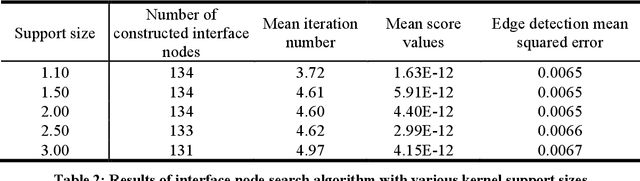
This work presents an approach for automating the discretization and approximation procedures in constructing digital representations of composites from Micro-CT images featuring intricate microstructures. The proposed method is guided by the Support Vector Machine (SVM) classification, offering an effective approach for discretizing microstructural images. An SVM soft margin training process is introduced as a classification of heterogeneous material points, and image segmentation is accomplished by identifying support vectors through a local regularized optimization problem. In addition, an Interface-Modified Reproducing Kernel Particle Method (IM-RKPM) is proposed for appropriate approximations of weak discontinuities across material interfaces. The proposed method modifies the smooth kernel functions with a regularized heavy-side function concerning the material interfaces to alleviate Gibb's oscillations. This IM-RKPM is formulated without introducing duplicated degrees of freedom associated with the interface nodes commonly needed in the conventional treatments of weak discontinuities in the meshfree methods. Moreover, IM-RKPM can be implemented with various domain integration techniques, such as Stabilized Conforming Nodal Integration (SCNI). The extension of the proposed method to 3-dimension is straightforward, and the effectiveness of the proposed method is validated through the image-based modeling of polymer-ceramic composite microstructures.
Task-Oriented Channel Attention for Fine-Grained Few-Shot Classification
Jul 28, 2023
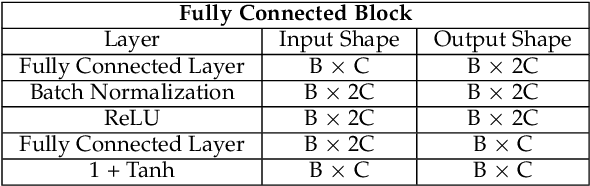
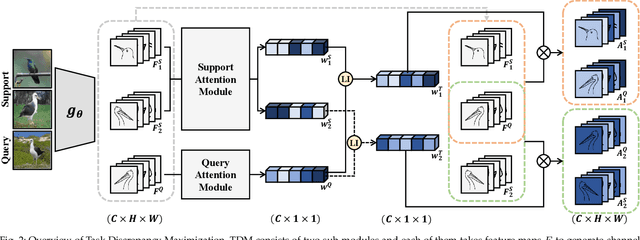
The difficulty of the fine-grained image classification mainly comes from a shared overall appearance across classes. Thus, recognizing discriminative details, such as eyes and beaks for birds, is a key in the task. However, this is particularly challenging when training data is limited. To address this, we propose Task Discrepancy Maximization (TDM), a task-oriented channel attention method tailored for fine-grained few-shot classification with two novel modules Support Attention Module (SAM) and Query Attention Module (QAM). SAM highlights channels encoding class-wise discriminative features, while QAM assigns higher weights to object-relevant channels of the query. Based on these submodules, TDM produces task-adaptive features by focusing on channels encoding class-discriminative details and possessed by the query at the same time, for accurate class-sensitive similarity measure between support and query instances. While TDM influences high-level feature maps by task-adaptive calibration of channel-wise importance, we further introduce Instance Attention Module (IAM) operating in intermediate layers of feature extractors to instance-wisely highlight object-relevant channels, by extending QAM. The merits of TDM and IAM and their complementary benefits are experimentally validated in fine-grained few-shot classification tasks. Moreover, IAM is also shown to be effective in coarse-grained and cross-domain few-shot classifications.
A Novel SLCA-UNet Architecture for Automatic MRI Brain Tumor Segmentation
Jul 16, 2023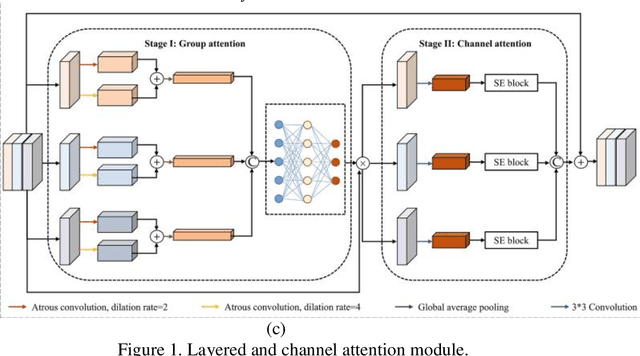
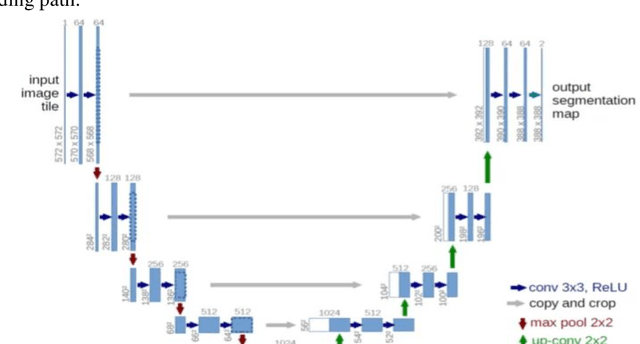
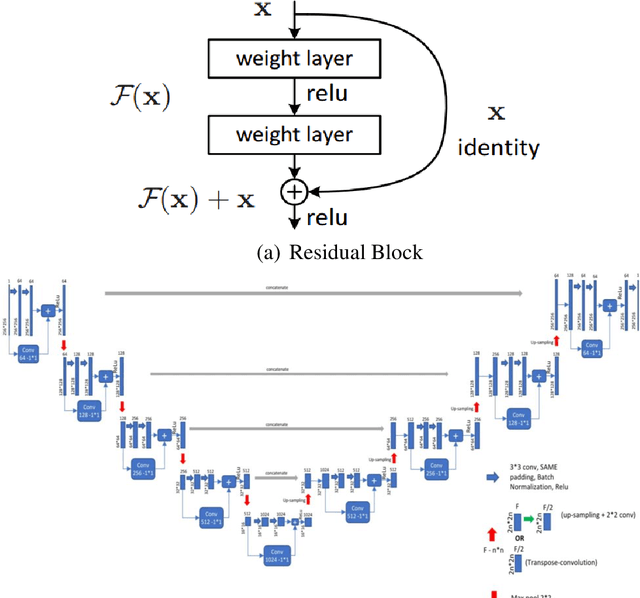
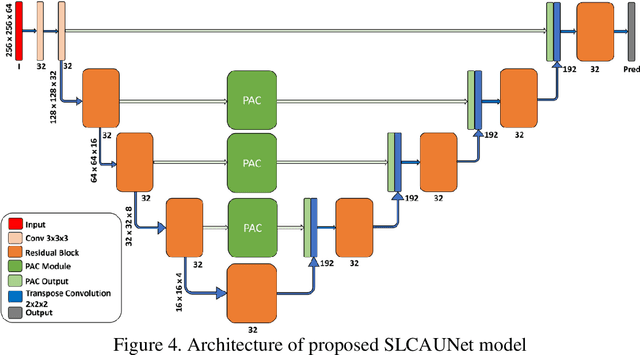
Brain tumor is deliberated as one of the severe health complications which lead to decrease in life expectancy of the individuals and is also considered as a prominent cause of mortality worldwide. Therefore, timely detection and prediction of brain tumors can be helpful to prevent death rates due to brain tumors. Biomedical image analysis is a widely known solution to diagnose brain tumor. Although MRI is the current standard method for imaging tumors, its clinical usefulness is constrained by the requirement of manual segmentation which is time-consuming. Deep learning-based approaches have emerged as a promising solution to develop automated biomedical image exploration tools and the UNet architecture is commonly used for segmentation. However, the traditional UNet has limitations in terms of complexity, training, accuracy, and contextual information processing. As a result, the modified UNet architecture, which incorporates residual dense blocks, layered attention, and channel attention modules, in addition to stacked convolution, can effectively capture both coarse and fine feature information. The proposed SLCA UNet approach achieves good performance on the freely accessible Brain Tumor Segmentation (BraTS) dataset, with an average performance of 0.845, 0.845, 0.999, and 8.1 in terms of Dice, Sensitivity, Specificity, and Hausdorff95 for BraTS 2020 dataset, respectively.
ExFaceGAN: Exploring Identity Directions in GAN's Learned Latent Space for Synthetic Identity Generation
Jul 18, 2023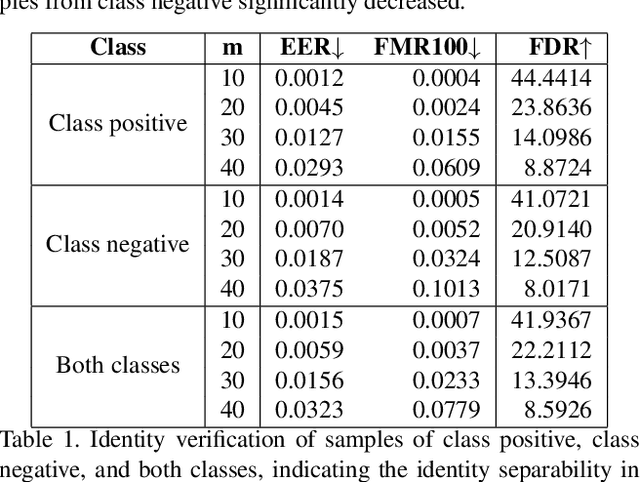
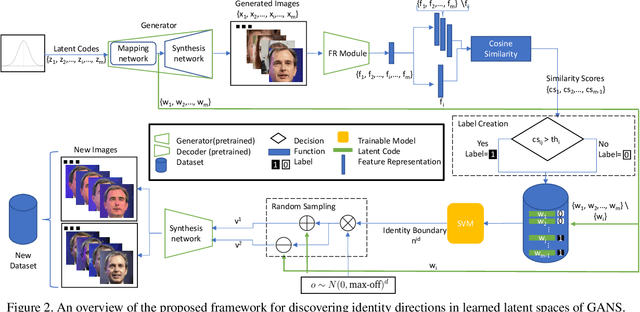
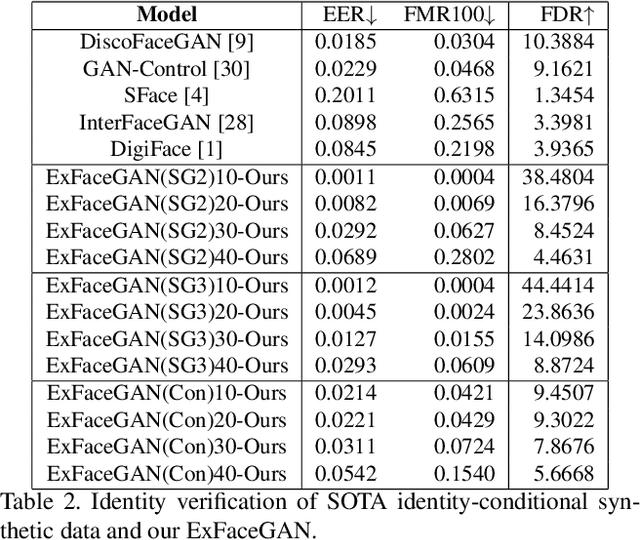
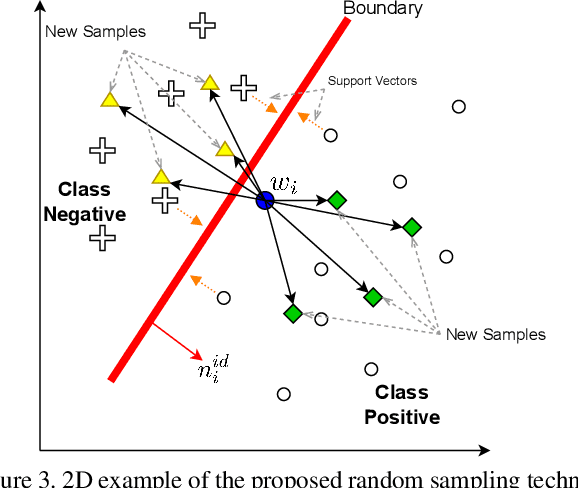
Deep generative models have recently presented impressive results in generating realistic face images of random synthetic identities. To generate multiple samples of a certain synthetic identity, previous works proposed to disentangle the latent space of GANs by incorporating additional supervision or regularization, enabling the manipulation of certain attributes. Others proposed to disentangle specific factors in unconditional pretrained GANs latent spaces to control their output, which also requires supervision by attribute classifiers. Moreover, these attributes are entangled in GAN's latent space, making it difficult to manipulate them without affecting the identity information. We propose in this work a framework, ExFaceGAN, to disentangle identity information in pretrained GANs latent spaces, enabling the generation of multiple samples of any synthetic identity. Given a reference latent code of any synthetic image and latent space of pretrained GAN, our ExFaceGAN learns an identity directional boundary that disentangles the latent space into two sub-spaces, with latent codes of samples that are either identity similar or dissimilar to a reference image. By sampling from each side of the boundary, our ExFaceGAN can generate multiple samples of synthetic identity without the need for designing a dedicated architecture or supervision from attribute classifiers. We demonstrate the generalizability and effectiveness of ExFaceGAN by integrating it into learned latent spaces of three SOTA GAN approaches. As an example of the practical benefit of our ExFaceGAN, we empirically prove that data generated by ExFaceGAN can be successfully used to train face recognition models (\url{https://github.com/fdbtrs/ExFaceGAN}).
A Simple and Effective Baseline for Attentional Generative Adversarial Networks
Jul 06, 2023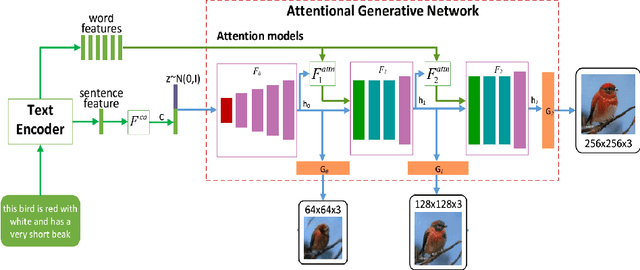
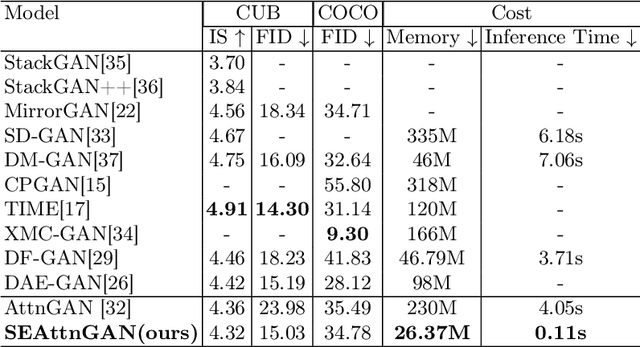
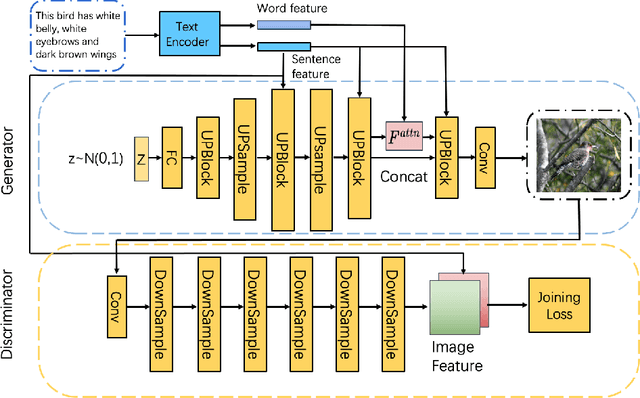

Synthesising a text-to-image model of high-quality images by guiding the generative model through the Text description is an innovative and challenging task. In recent years, AttnGAN based on the Attention mechanism to guide GAN training has been proposed, SD-GAN, which adopts a self-distillation technique to improve the performance of the generator and the quality of image generation, and Stack-GAN++, which gradually improves the details and quality of the image by stacking multiple generators and discriminators. However, this series of improvements to GAN all have redundancy to a certain extent, which affects the generation performance and complexity to a certain extent. We use the popular simple and effective idea (1) to remove redundancy structure and improve the backbone network of AttnGAN. (2) to integrate and reconstruct multiple losses of DAMSM. Our improvements have significantly improved the model size and training efficiency while ensuring that the model's performance is unchanged and finally proposed our SEAttnGAN. Code is avalilable at https://github.com/jmyissb/SEAttnGAN.
Empirical Analysis of a Segmentation Foundation Model in Prostate Imaging
Jul 06, 2023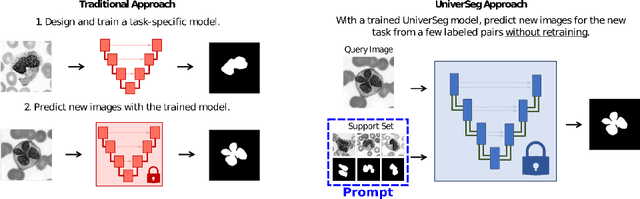

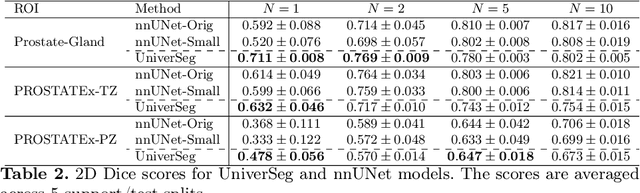
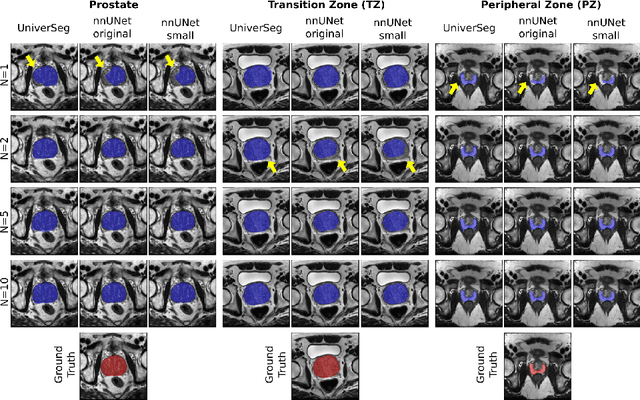
Most state-of-the-art techniques for medical image segmentation rely on deep-learning models. These models, however, are often trained on narrowly-defined tasks in a supervised fashion, which requires expensive labeled datasets. Recent advances in several machine learning domains, such as natural language generation have demonstrated the feasibility and utility of building foundation models that can be customized for various downstream tasks with little to no labeled data. This likely represents a paradigm shift for medical imaging, where we expect that foundation models may shape the future of the field. In this paper, we consider a recently developed foundation model for medical image segmentation, UniverSeg. We conduct an empirical evaluation study in the context of prostate imaging and compare it against the conventional approach of training a task-specific segmentation model. Our results and discussion highlight several important factors that will likely be important in the development and adoption of foundation models for medical image segmentation.