 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Streamlined Global and Local Features Combinator (SGLC) for High Resolution Image Dehazing
Apr 26, 2023
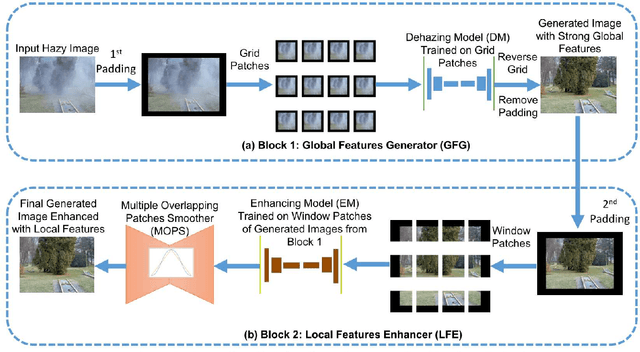
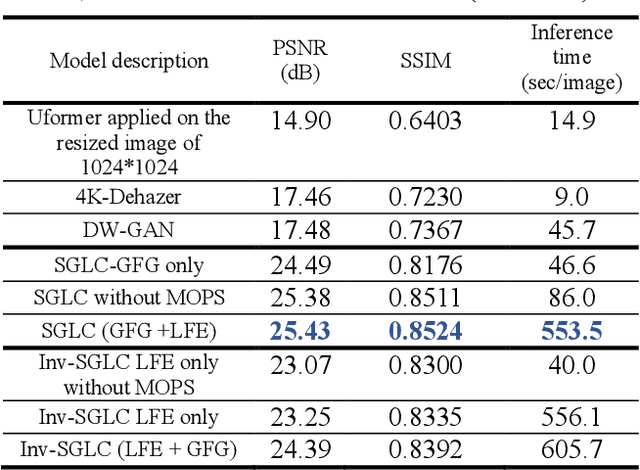

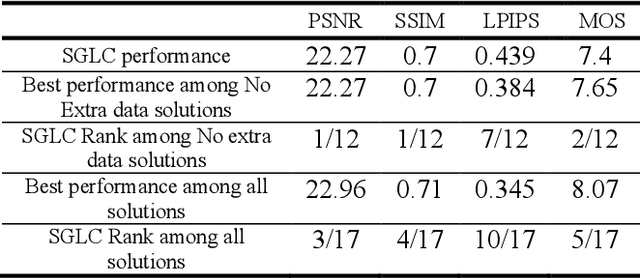
Image Dehazing aims to remove atmospheric fog or haze from an image. Although the Dehazing models have evolved a lot in recent years, few have precisely tackled the problem of High-Resolution hazy images. For this kind of image, the model needs to work on a downscaled version of the image or on cropped patches from it. In both cases, the accuracy will drop. This is primarily due to the inherent failure to combine global and local features when the image size increases. The Dehazing model requires global features to understand the general scene peculiarities and the local features to work better with fine and pixel details. In this study, we propose the Streamlined Global and Local Features Combinator (SGLC) to solve these issues and to optimize the application of any Dehazing model to High-Resolution images. The SGLC contains two successive blocks. The first is the Global Features Generator (GFG) which generates the first version of the Dehazed image containing strong global features. The second block is the Local Features Enhancer (LFE) which improves the local feature details inside the previously generated image. When tested on the Uformer architecture for Dehazing, SGLC increased the PSNR metric by a significant margin. Any other model can be incorporated inside the SGLC process to improve its efficiency on High-Resolution input data.
Training-Free Location-Aware Text-to-Image Synthesis
Apr 26, 2023
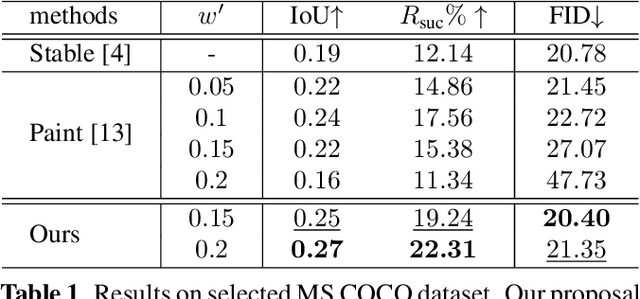

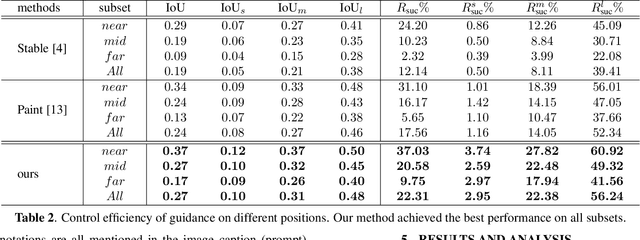
Current large-scale generative models have impressive efficiency in generating high-quality images based on text prompts. However, they lack the ability to precisely control the size and position of objects in the generated image. In this study, we analyze the generative mechanism of the stable diffusion model and propose a new interactive generation paradigm that allows users to specify the position of generated objects without additional training. Moreover, we propose an object detection-based evaluation metric to assess the control capability of location aware generation task. Our experimental results show that our method outperforms state-of-the-art methods on both control capacity and image quality.
Five A$^{+}$ Network: You Only Need 9K Parameters for Underwater Image Enhancement
May 15, 2023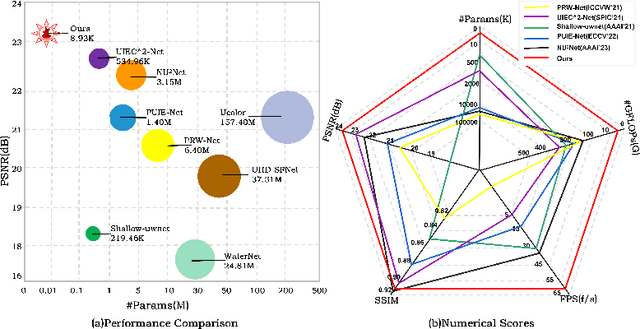
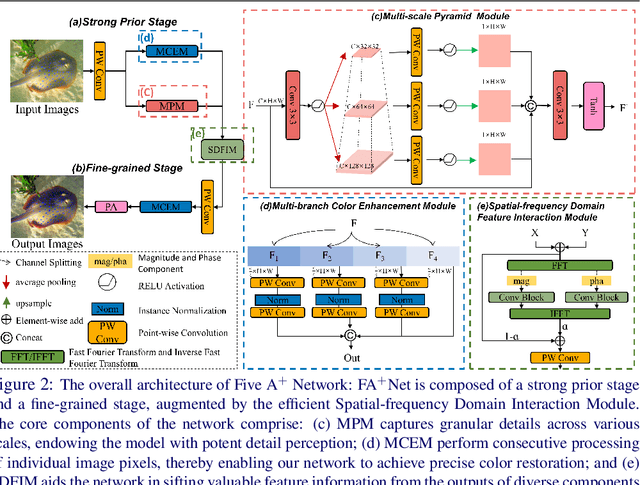

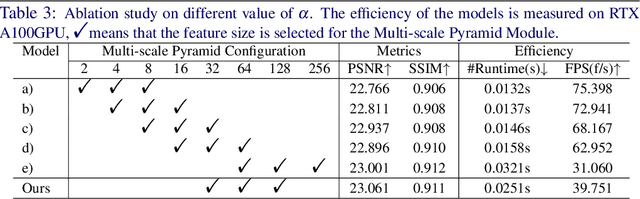
A lightweight underwater image enhancement network is of great significance for resource-constrained platforms, but balancing model size, computational efficiency, and enhancement performance has proven difficult for previous approaches. In this work, we propose the Five A$^{+}$ Network (FA$^{+}$Net), a highly efficient and lightweight real-time underwater image enhancement network with only $\sim$ 9k parameters and $\sim$ 0.01s processing time. The FA$^{+}$Net employs a two-stage enhancement structure. The strong prior stage aims to decompose challenging underwater degradations into sub-problems, while the fine-grained stage incorporates multi-branch color enhancement module and pixel attention module to amplify the network's perception of details. To the best of our knowledge, FA$^{+}$Net is the only network with the capability of real-time enhancement of 1080P images. Thorough extensive experiments and comprehensive visual comparison, we show that FA$^{+}$Net outperforms previous approaches by obtaining state-of-the-art performance on multiple datasets while significantly reducing both parameter count and computational complexity. The code is open source at https://github.com/Owen718/FiveAPlus-Network.
SPColor: Semantic Prior Guided Exemplar-based Image Colorization
Apr 14, 2023
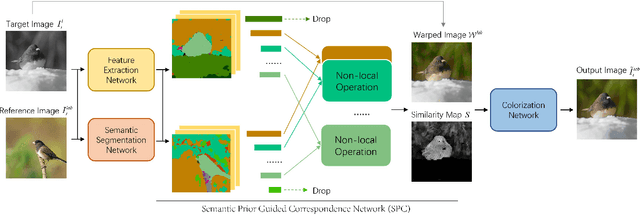


Exemplar-based image colorization aims to colorize a target grayscale image based on a color reference image, and the key is to establish accurate pixel-level semantic correspondence between these two images. Previous methods search for correspondence across the entire reference image, and this type of global matching is easy to get mismatch. We summarize the difficulties in two aspects: (1) When the reference image only contains a part of objects related to target image, improper correspondence will be established in unrelated regions. (2) It is prone to get mismatch in regions where the shape or texture of the object is easily confused. To overcome these issues, we propose SPColor, a semantic prior guided exemplar-based image colorization framework. Different from previous methods, SPColor first coarsely classifies pixels of the reference and target images to several pseudo-classes under the guidance of semantic prior, then the correspondences are only established locally between the pixels in the same class via the newly designed semantic prior guided correspondence network. In this way, improper correspondence between different semantic classes is explicitly excluded, and the mismatch is obviously alleviated. Besides, to better reserve the color from reference, a similarity masked perceptual loss is designed. Noting that the carefully designed SPColor utilizes the semantic prior provided by an unsupervised segmentation model, which is free for additional manual semantic annotations. Experiments demonstrate that our model outperforms recent state-of-the-art methods both quantitatively and qualitatively on public dataset.
Diffusion Explainer: Visual Explanation for Text-to-image Stable Diffusion
May 08, 2023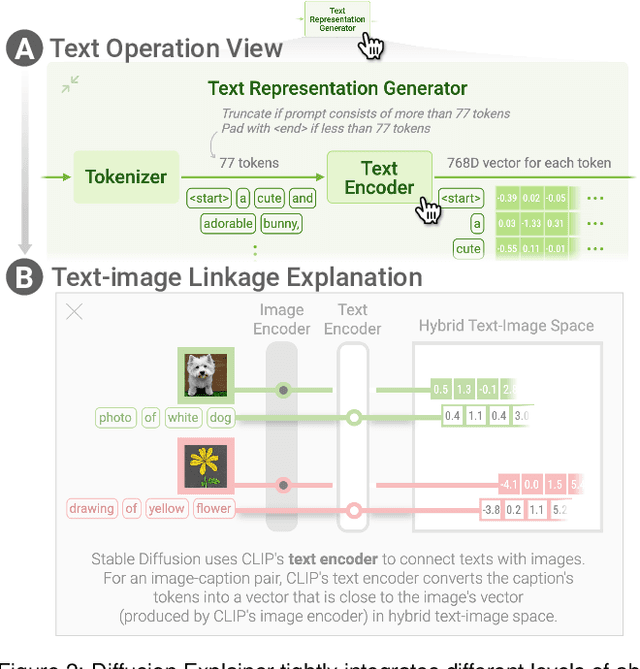
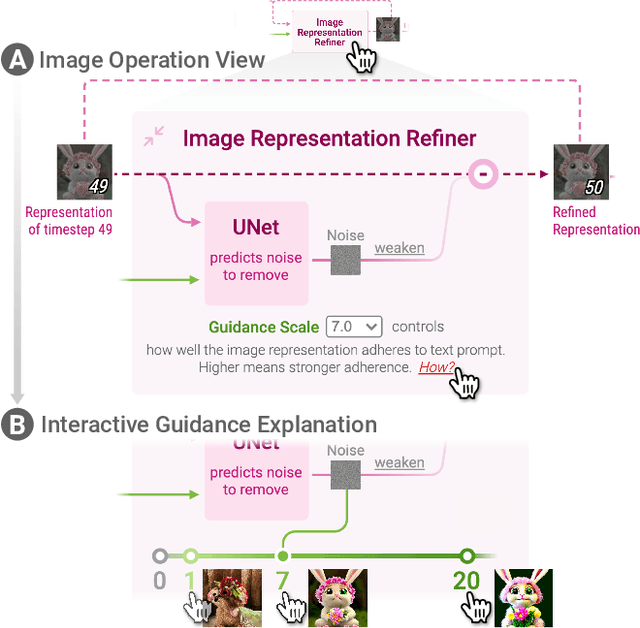
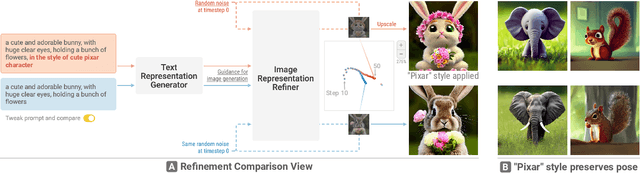
Diffusion-based generative models' impressive ability to create convincing images has captured global attention. However, their complex internal structures and operations often make them difficult for non-experts to understand. We present Diffusion Explainer, the first interactive visualization tool that explains how Stable Diffusion transforms text prompts into images. Diffusion Explainer tightly integrates a visual overview of Stable Diffusion's complex components with detailed explanations of their underlying operations, enabling users to fluidly transition between multiple levels of abstraction through animations and interactive elements. By comparing the evolutions of image representations guided by two related text prompts over refinement timesteps, users can discover the impact of prompts on image generation. Diffusion Explainer runs locally in users' web browsers without the need for installation or specialized hardware, broadening the public's education access to modern AI techniques. Our open-sourced tool is available at: https://poloclub.github.io/diffusion-explainer/. A video demo is available at https://youtu.be/Zg4gxdIWDds.
A3D: Adaptive, Accurate, and Autonomous Navigation for Edge-Assisted Drones
Jul 19, 2023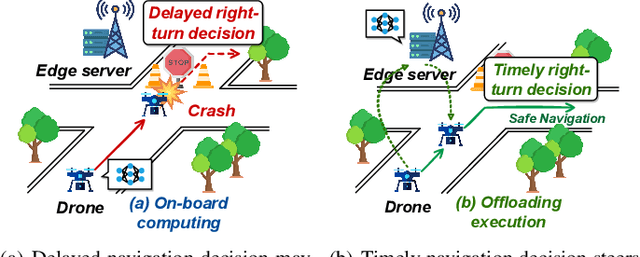
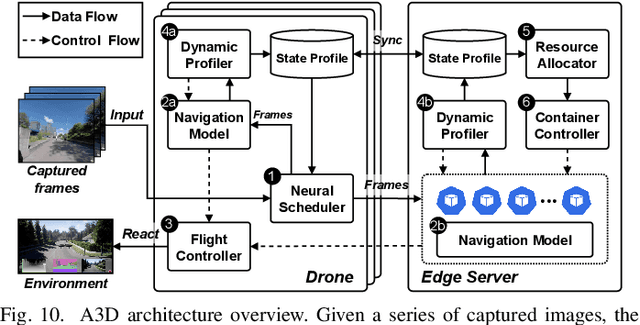
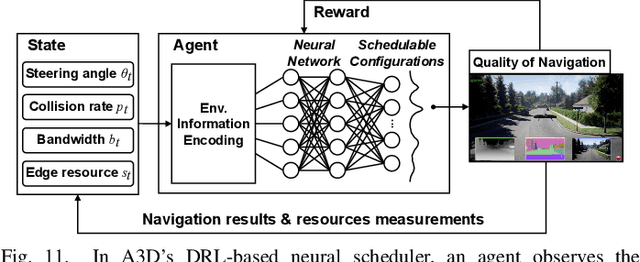
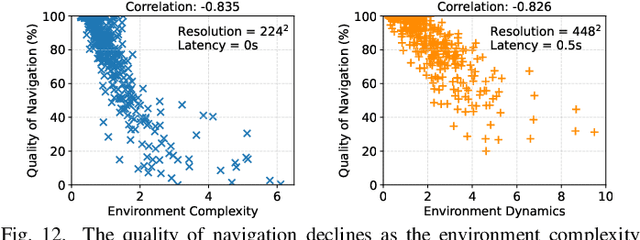
Accurate navigation is of paramount importance to ensure flight safety and efficiency for autonomous drones. Recent research starts to use Deep Neural Networks to enhance drone navigation given their remarkable predictive capability for visual perception. However, existing solutions either run DNN inference tasks on drones in situ, impeded by the limited onboard resource, or offload the computation to external servers which may incur large network latency. Few works consider jointly optimizing the offloading decisions along with image transmission configurations and adapting them on the fly. In this paper, we propose A3D, an edge server assisted drone navigation framework that can dynamically adjust task execution location, input resolution, and image compression ratio in order to achieve low inference latency, high prediction accuracy, and long flight distances. Specifically, we first augment state-of-the-art convolutional neural networks for drone navigation and define a novel metric called Quality of Navigation as our optimization objective which can effectively capture the above goals. We then design a deep reinforcement learning based neural scheduler at the drone side for which an information encoder is devised to reshape the state features and thus improve its learning ability. To further support simultaneous multi-drone serving, we extend the edge server design by developing a network-aware resource allocation algorithm, which allows provisioning containerized resources aligned with drones' demand. We finally implement a proof-of-concept prototype with realistic devices and validate its performance in a real-world campus scene, as well as a simulation environment for thorough evaluation upon AirSim. Extensive experimental results show that A3D can reduce end-to-end latency by 28.06% and extend the flight distance by up to 27.28% compared with non-adaptive solutions.
A New Dataset and Comparative Study for Aphid Cluster Detection
Jul 12, 2023

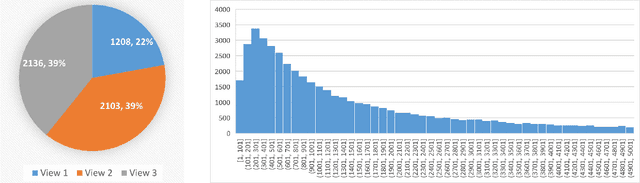
Aphids are one of the main threats to crops, rural families, and global food security. Chemical pest control is a necessary component of crop production for maximizing yields, however, it is unnecessary to apply the chemical approaches to the entire fields in consideration of the environmental pollution and the cost. Thus, accurately localizing the aphid and estimating the infestation level is crucial to the precise local application of pesticides. Aphid detection is very challenging as each individual aphid is really small and all aphids are crowded together as clusters. In this paper, we propose to estimate the infection level by detecting aphid clusters. We have taken millions of images in the sorghum fields, manually selected 5,447 images that contain aphids, and annotated each aphid cluster in the image. To use these images for machine learning models, we crop the images into patches and created a labeled dataset with over 151,000 image patches. Then, we implement and compare the performance of four state-of-the-art object detection models.
Prompt-based Tuning of Transformer Models for Multi-Center Medical Image Segmentation
May 30, 2023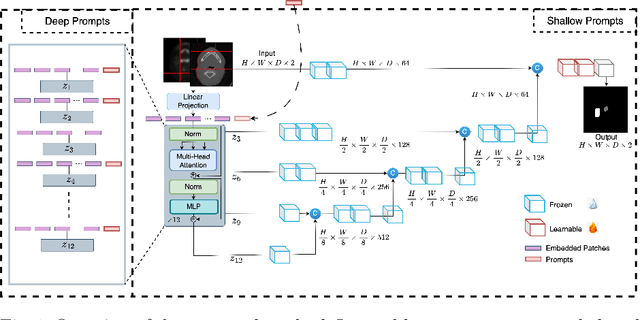

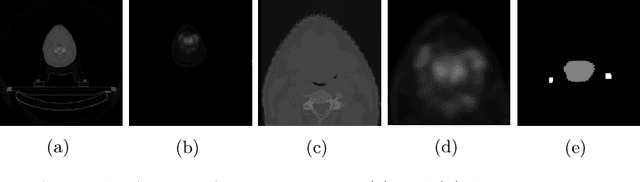
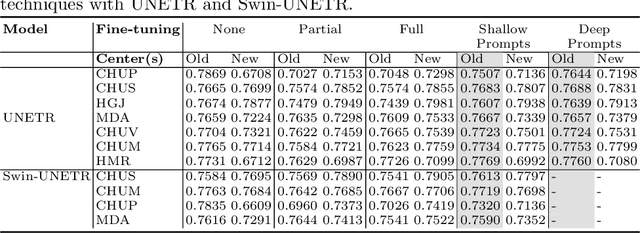
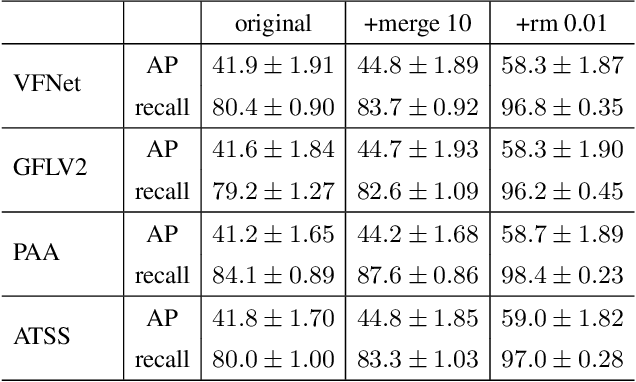
Medical image segmentation is a vital healthcare endeavor requiring precise and efficient models for appropriate diagnosis and treatment. Vision transformer-based segmentation models have shown great performance in accomplishing this task. However, to build a powerful backbone, the self-attention block of ViT requires large-scale pre-training data. The present method of modifying pre-trained models entails updating all or some of the backbone parameters. This paper proposes a novel fine-tuning strategy for adapting a pretrained transformer-based segmentation model on data from a new medical center. This method introduces a small number of learnable parameters, termed prompts, into the input space (less than 1\% of model parameters) while keeping the rest of the model parameters frozen. Extensive studies employing data from new unseen medical centers show that prompts-based fine-tuning of medical segmentation models provides excellent performance on the new center data with a negligible drop on the old centers. Additionally, our strategy delivers great accuracy with minimum re-training on new center data, significantly decreasing the computational and time costs of fine-tuning pre-trained models.
PRIOR: Prototype Representation Joint Learning from Medical Images and Reports
Jul 24, 2023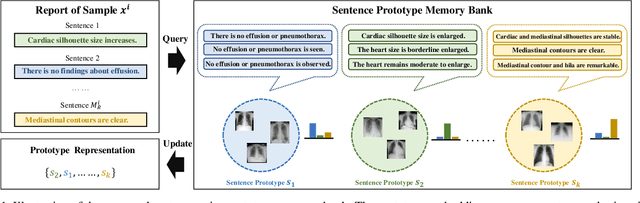
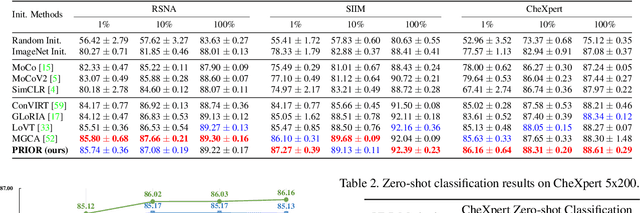
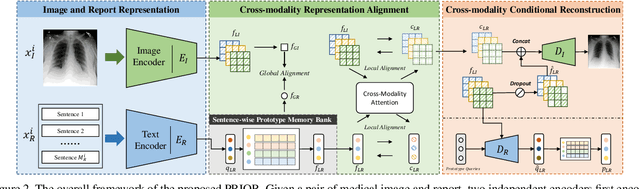
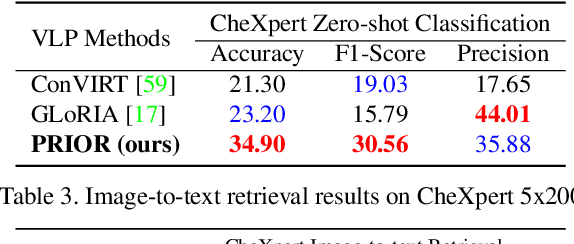
Contrastive learning based vision-language joint pre-training has emerged as a successful representation learning strategy. In this paper, we present a prototype representation learning framework incorporating both global and local alignment between medical images and reports. In contrast to standard global multi-modality alignment methods, we employ a local alignment module for fine-grained representation. Furthermore, a cross-modality conditional reconstruction module is designed to interchange information across modalities in the training phase by reconstructing masked images and reports. For reconstructing long reports, a sentence-wise prototype memory bank is constructed, enabling the network to focus on low-level localized visual and high-level clinical linguistic features. Additionally, a non-auto-regressive generation paradigm is proposed for reconstructing non-sequential reports. Experimental results on five downstream tasks, including supervised classification, zero-shot classification, image-to-text retrieval, semantic segmentation, and object detection, show the proposed method outperforms other state-of-the-art methods across multiple datasets and under different dataset size settings. The code is available at https://github.com/QtacierP/PRIOR.
Enhancing Human-like Multi-Modal Reasoning: A New Challenging Dataset and Comprehensive Framework
Jul 24, 2023



Multimodal reasoning is a critical component in the pursuit of artificial intelligence systems that exhibit human-like intelligence, especially when tackling complex tasks. While the chain-of-thought (CoT) technique has gained considerable attention, the existing ScienceQA dataset, which focuses on multimodal scientific questions and explanations from elementary and high school textbooks, lacks a comprehensive evaluation of diverse approaches. To address this gap, we present COCO Multi-Modal Reasoning Dataset(COCO-MMRD), a novel dataset that encompasses an extensive collection of open-ended questions, rationales, and answers derived from the large object dataset COCO. Unlike previous datasets that rely on multiple-choice questions, our dataset pioneers the use of open-ended questions in the context of multimodal CoT, introducing a more challenging problem that effectively assesses the reasoning capability of CoT models. Through comprehensive evaluations and detailed analyses, we provide valuable insights and propose innovative techniques, including multi-hop cross-modal attention and sentence-level contrastive learning, to enhance the image and text encoders. Extensive experiments demonstrate the efficacy of the proposed dataset and techniques, offering novel perspectives for advancing multimodal reasoning.