 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Registration-Free Hybrid Learning Empowers Simple Multimodal Imaging System for High-quality Fusion Detection
Jul 07, 2023
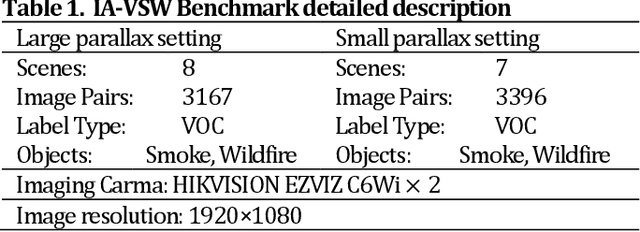
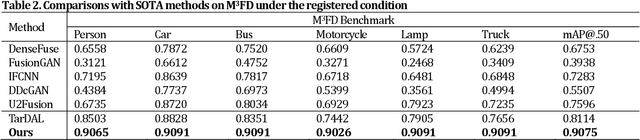

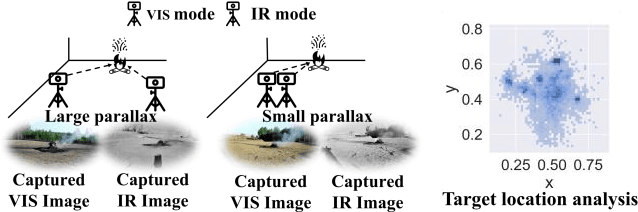
Multimodal fusion detection always places high demands on the imaging system and image pre-processing, while either a high-quality pre-registration system or image registration processing is costly. Unfortunately, the existing fusion methods are designed for registered source images, and the fusion of inhomogeneous features, which denotes a pair of features at the same spatial location that expresses different semantic information, cannot achieve satisfactory performance via these methods. As a result, we propose IA-VFDnet, a CNN-Transformer hybrid learning framework with a unified high-quality multimodal feature matching module (AKM) and a fusion module (WDAF), in which AKM and DWDAF work in synergy to perform high-quality infrared-aware visible fusion detection, which can be applied to smoke and wildfire detection. Furthermore, experiments on the M3FD dataset validate the superiority of the proposed method, with IA-VFDnet achieving the best detection performance than other state-of-the-art methods under conventional registered conditions. In addition, the first unregistered multimodal smoke and wildfire detection benchmark is openly available in this letter.
Multi-Task Cross-Modality Attention-Fusion for 2D Object Detection
Jul 17, 2023

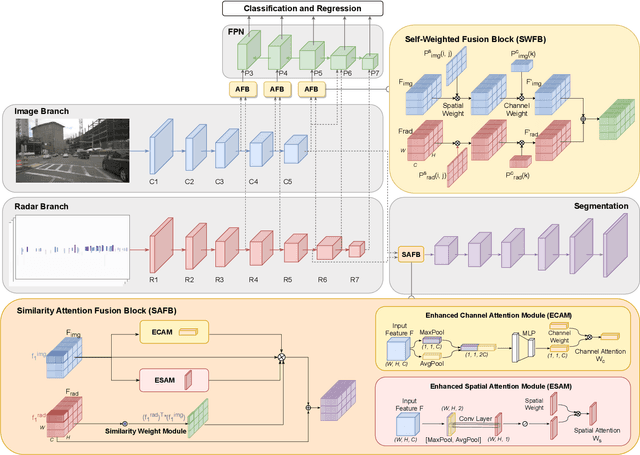
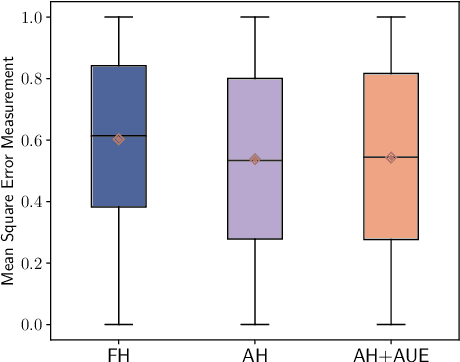
Accurate and robust object detection is critical for autonomous driving. Image-based detectors face difficulties caused by low visibility in adverse weather conditions. Thus, radar-camera fusion is of particular interest but presents challenges in optimally fusing heterogeneous data sources. To approach this issue, we propose two new radar preprocessing techniques to better align radar and camera data. In addition, we introduce a Multi-Task Cross-Modality Attention-Fusion Network (MCAF-Net) for object detection, which includes two new fusion blocks. These allow for exploiting information from the feature maps more comprehensively. The proposed algorithm jointly detects objects and segments free space, which guides the model to focus on the more relevant part of the scene, namely, the occupied space. Our approach outperforms current state-of-the-art radar-camera fusion-based object detectors in the nuScenes dataset and achieves more robust results in adverse weather conditions and nighttime scenarios.
Training Discrete Energy-Based Models with Energy Discrepancy
Jul 14, 2023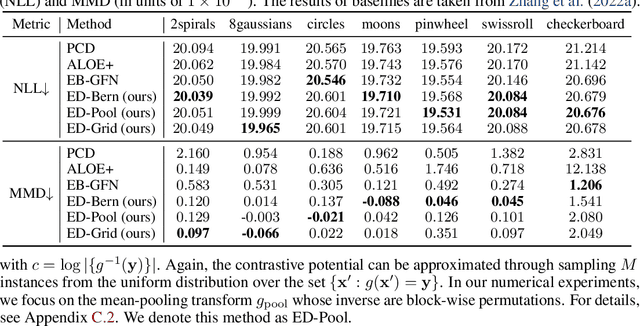

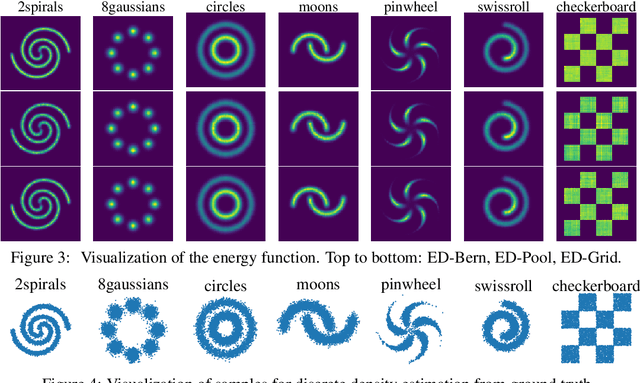
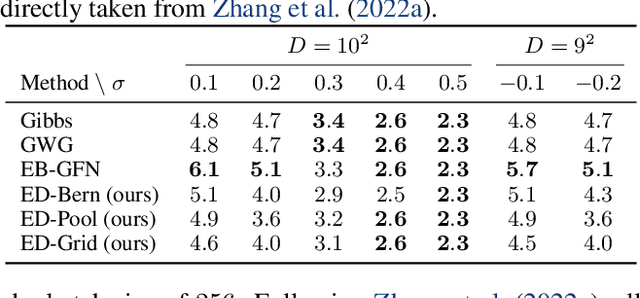
Training energy-based models (EBMs) on discrete spaces is challenging because sampling over such spaces can be difficult. We propose to train discrete EBMs with energy discrepancy (ED), a novel type of contrastive loss functional which only requires the evaluation of the energy function at data points and their perturbed counter parts, thus not relying on sampling strategies like Markov chain Monte Carlo (MCMC). Energy discrepancy offers theoretical guarantees for a broad class of perturbation processes of which we investigate three types: perturbations based on Bernoulli noise, based on deterministic transforms, and based on neighbourhood structures. We demonstrate their relative performance on lattice Ising models, binary synthetic data, and discrete image data sets.
Answer Mining from a Pool of Images: Towards Retrieval-Based Visual Question Answering
Jun 29, 2023
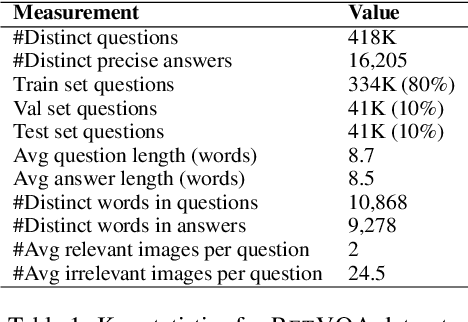
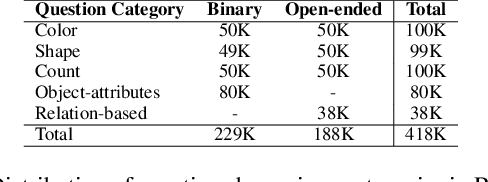
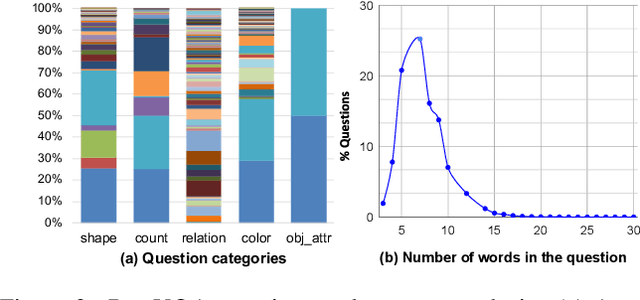
We study visual question answering in a setting where the answer has to be mined from a pool of relevant and irrelevant images given as a context. For such a setting, a model must first retrieve relevant images from the pool and answer the question from these retrieved images. We refer to this problem as retrieval-based visual question answering (or RETVQA in short). The RETVQA is distinctively different and more challenging than the traditionally-studied Visual Question Answering (VQA), where a given question has to be answered with a single relevant image in context. Towards solving the RETVQA task, we propose a unified Multi Image BART (MI-BART) that takes a question and retrieved images using our relevance encoder for free-form fluent answer generation. Further, we introduce the largest dataset in this space, namely RETVQA, which has the following salient features: multi-image and retrieval requirement for VQA, metadata-independent questions over a pool of heterogeneous images, expecting a mix of classification-oriented and open-ended generative answers. Our proposed framework achieves an accuracy of 76.5% and a fluency of 79.3% on the proposed dataset, namely RETVQA and also outperforms state-of-the-art methods by 4.9% and 11.8% on the image segment of the publicly available WebQA dataset on the accuracy and fluency metrics, respectively.
Divide & Bind Your Attention for Improved Generative Semantic Nursing
Jul 20, 2023

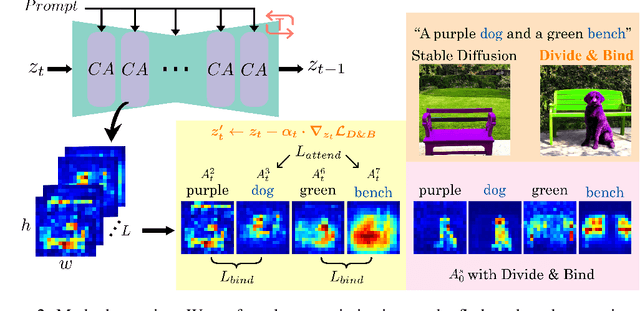
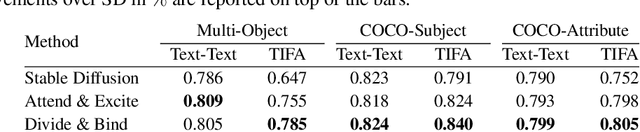
Emerging large-scale text-to-image generative models, e.g., Stable Diffusion (SD), have exhibited overwhelming results with high fidelity. Despite the magnificent progress, current state-of-the-art models still struggle to generate images fully adhering to the input prompt. Prior work, Attend & Excite, has introduced the concept of Generative Semantic Nursing (GSN), aiming to optimize cross-attention during inference time to better incorporate the semantics. It demonstrates promising results in generating simple prompts, e.g., ``a cat and a dog''. However, its efficacy declines when dealing with more complex prompts, and it does not explicitly address the problem of improper attribute binding. To address the challenges posed by complex prompts or scenarios involving multiple entities and to achieve improved attribute binding, we propose Divide & Bind. We introduce two novel loss objectives for GSN: a novel attendance loss and a binding loss. Our approach stands out in its ability to faithfully synthesize desired objects with improved attribute alignment from complex prompts and exhibits superior performance across multiple evaluation benchmarks. More videos and updates can be found on the project page \url{https://sites.google.com/view/divide-and-bind}.
FedSoup: Improving Generalization and Personalization in Federated Learning via Selective Model Interpolation
Jul 20, 2023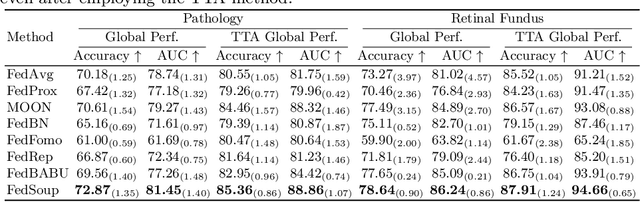
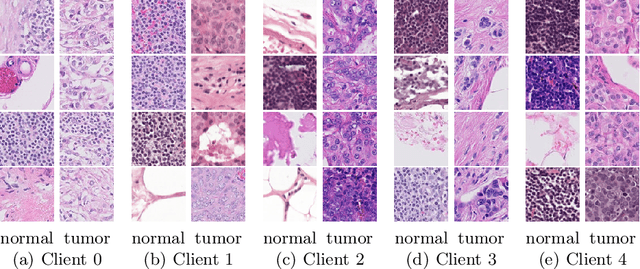
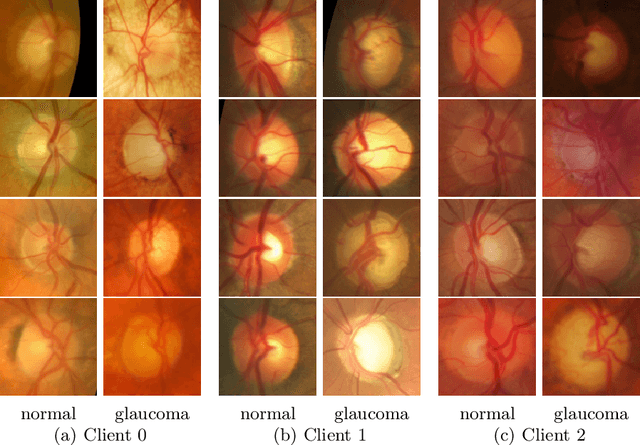
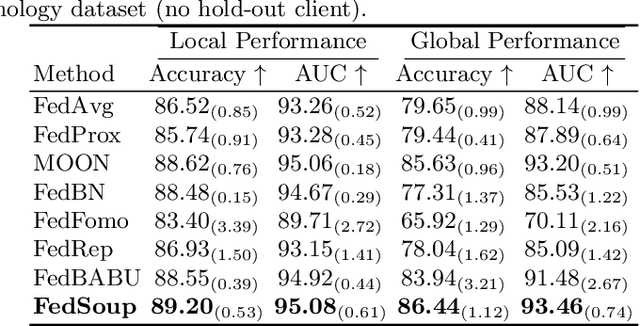
Cross-silo federated learning (FL) enables the development of machine learning models on datasets distributed across data centers such as hospitals and clinical research laboratories. However, recent research has found that current FL algorithms face a trade-off between local and global performance when confronted with distribution shifts. Specifically, personalized FL methods have a tendency to overfit to local data, leading to a sharp valley in the local model and inhibiting its ability to generalize to out-of-distribution data. In this paper, we propose a novel federated model soup method (i.e., selective interpolation of model parameters) to optimize the trade-off between local and global performance. Specifically, during the federated training phase, each client maintains its own global model pool by monitoring the performance of the interpolated model between the local and global models. This allows us to alleviate overfitting and seek flat minima, which can significantly improve the model's generalization performance. We evaluate our method on retinal and pathological image classification tasks, and our proposed method achieves significant improvements for out-of-distribution generalization. Our code is available at https://github.com/ubc-tea/FedSoup.
PE-YOLO: Pyramid Enhancement Network for Dark Object Detection
Jul 20, 2023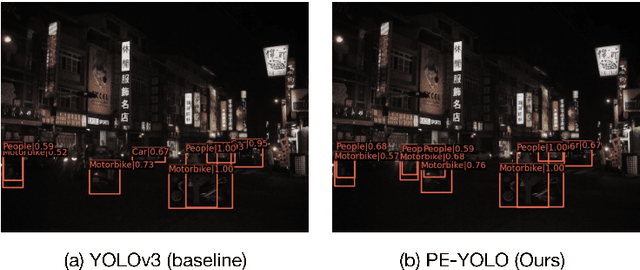
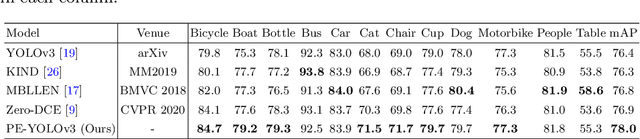
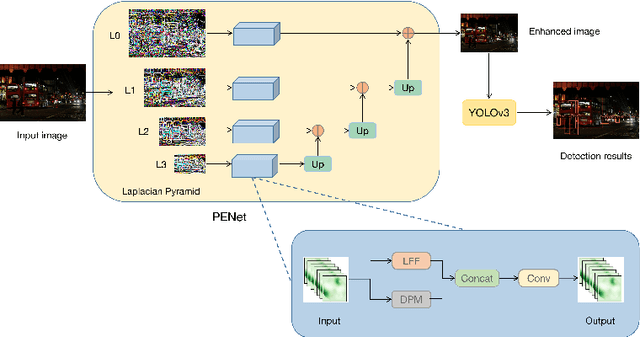

Current object detection models have achieved good results on many benchmark datasets, detecting objects in dark conditions remains a large challenge. To address this issue, we propose a pyramid enhanced network (PENet) and joint it with YOLOv3 to build a dark object detection framework named PE-YOLO. Firstly, PENet decomposes the image into four components of different resolutions using the Laplacian pyramid. Specifically we propose a detail processing module (DPM) to enhance the detail of images, which consists of context branch and edge branch. In addition, we propose a low-frequency enhancement filter (LEF) to capture low-frequency semantics and prevent high-frequency noise. PE-YOLO adopts an end-to-end joint training approach and only uses normal detection loss to simplify the training process. We conduct experiments on the low-light object detection dataset ExDark to demonstrate the effectiveness of ours. The results indicate that compared with other dark detectors and low-light enhancement models, PE-YOLO achieves the advanced results, achieving 78.0% in mAP and 53.6 in FPS, respectively, which can adapt to object detection under different low-light conditions. The code is available at https://github.com/XiangchenYin/PE-YOLO.
Local Conditional Neural Fields for Versatile and Generalizable Large-Scale Reconstructions in Computational Imaging
Jul 22, 2023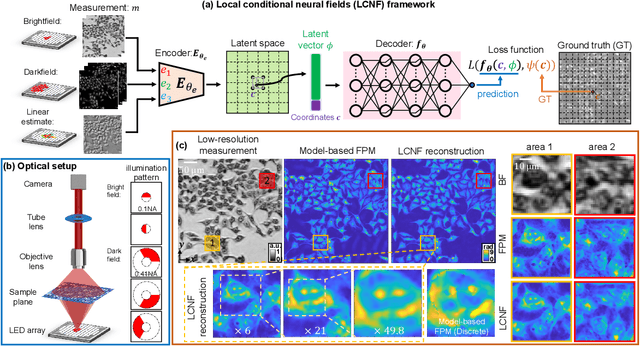
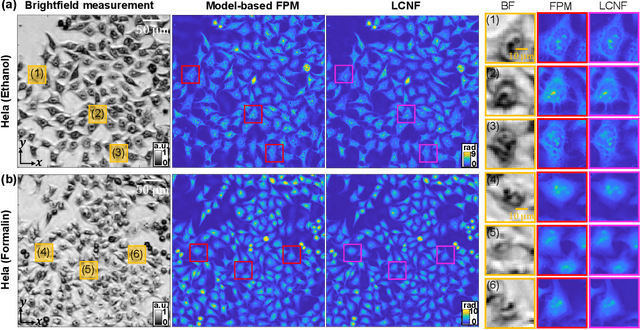
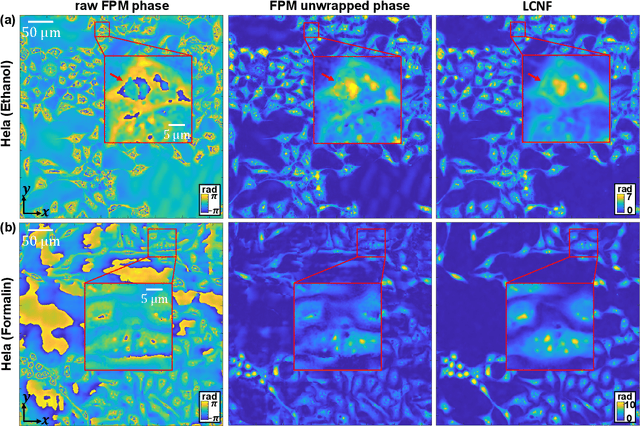
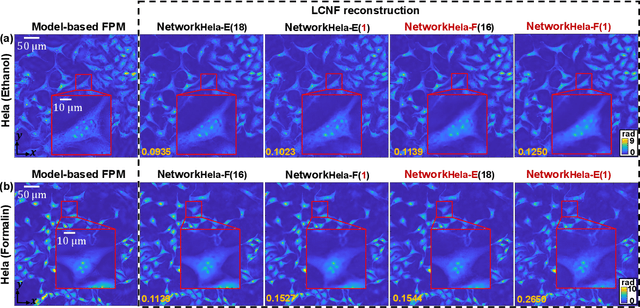
Deep learning has transformed computational imaging, but traditional pixel-based representations limit their ability to capture continuous, multiscale details of objects. Here we introduce a novel Local Conditional Neural Fields (LCNF) framework, leveraging a continuous implicit neural representation to address this limitation. LCNF enables flexible object representation and facilitates the reconstruction of multiscale information. We demonstrate the capabilities of LCNF in solving the highly ill-posed inverse problem in Fourier ptychographic microscopy (FPM) with multiplexed measurements, achieving robust, scalable, and generalizable large-scale phase retrieval. Unlike traditional neural fields frameworks, LCNF incorporates a local conditional representation that promotes model generalization, learning multiscale information, and efficient processing of large-scale imaging data. By combining an encoder and a decoder conditioned on a learned latent vector, LCNF achieves versatile continuous-domain super-resolution image reconstruction. We demonstrate accurate reconstruction of wide field-of-view, high-resolution phase images using only a few multiplexed measurements. LCNF robustly captures the continuous object priors and eliminates various phase artifacts, even when it is trained on imperfect datasets. The framework exhibits strong generalization, reconstructing diverse objects even with limited training data. Furthermore, LCNF can be trained on a physics simulator using natural images and successfully applied to experimental measurements on biological samples. Our results highlight the potential of LCNF for solving large-scale inverse problems in computational imaging, with broad applicability in various deep-learning-based techniques.
Is Task-Agnostic Explainable AI a Myth?
Jul 13, 2023

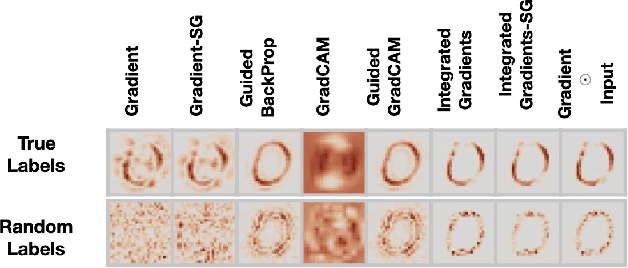
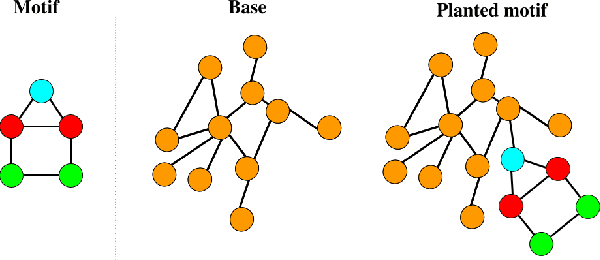
Our work serves as a framework for unifying the challenges of contemporary explainable AI (XAI). We demonstrate that while XAI methods provide supplementary and potentially useful output for machine learning models, researchers and decision-makers should be mindful of their conceptual and technical limitations, which frequently result in these methods themselves becoming black boxes. We examine three XAI research avenues spanning image, textual, and graph data, covering saliency, attention, and graph-type explainers. Despite the varying contexts and timeframes of the mentioned cases, the same persistent roadblocks emerge, highlighting the need for a conceptual breakthrough in the field to address the challenge of compatibility between XAI methods and application tasks.
TransPose: A Transformer-based 6D Object Pose Estimation Network with Depth Refinement
Jul 09, 2023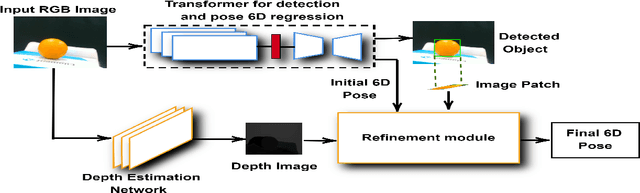
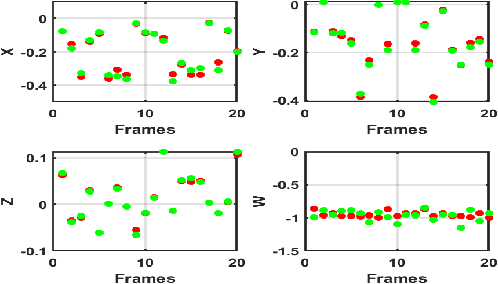
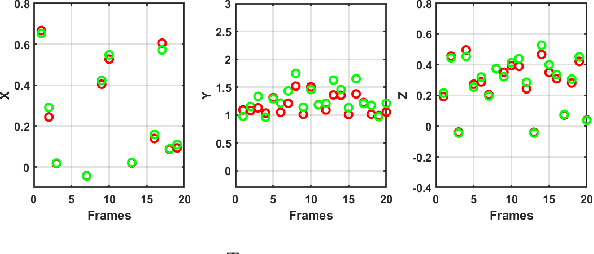
As demand for robotics manipulation application increases, accurate vision-based 6D pose estimation becomes essential for autonomous operations. Convolutional Neural Networks (CNNs) based approaches for pose estimation have been previously introduced. However, the quest for better performance still persists especially for accurate robotics manipulation. This quest extends to the Agri-robotics domain. In this paper, we propose TransPose, an improved Transformer-based 6D pose estimation with a depth refinement module. The architecture takes in only an RGB image as input with no additional supplementing modalities such as depth or thermal images. The architecture encompasses an innovative lighter depth estimation network that estimates depth from an RGB image using feature pyramid with an up-sampling method. A transformer-based detection network with additional prediction heads is proposed to directly regress the object's centre and predict the 6D pose of the target. A novel depth refinement module is then used alongside the predicted centers, 6D poses and depth patches to refine the accuracy of the estimated 6D pose. We extensively compared our results with other state-of-the-art methods and analysed our results for fruit-picking applications. The results we achieved show that our proposed technique outperforms the other methods available in the literature.