 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Visual Captioning at Will: Describing Images and Videos Guided by a Few Stylized Sentences
Jul 31, 2023
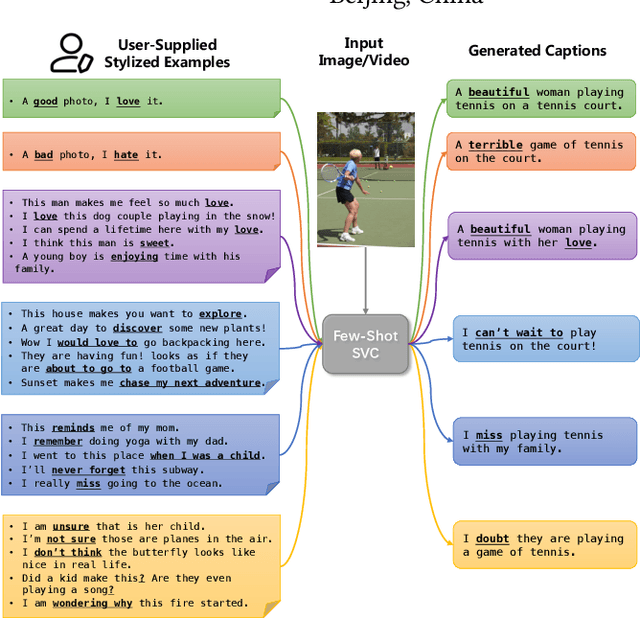
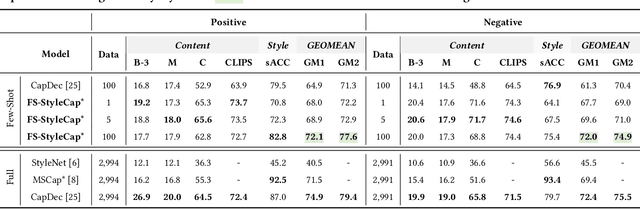
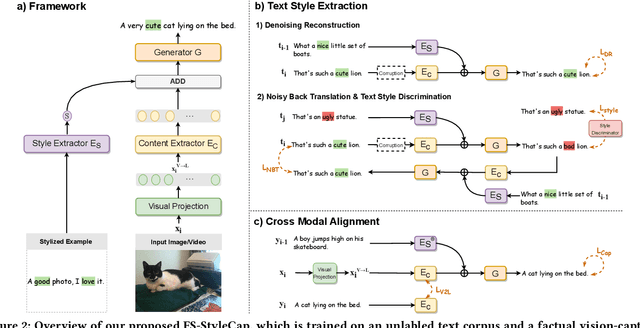
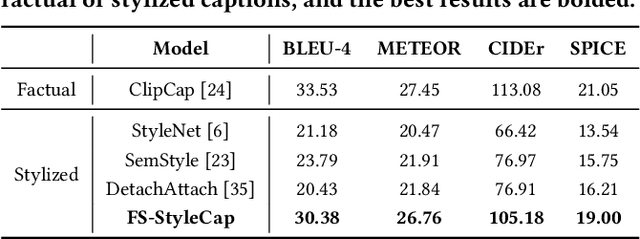
Stylized visual captioning aims to generate image or video descriptions with specific styles, making them more attractive and emotionally appropriate. One major challenge with this task is the lack of paired stylized captions for visual content, so most existing works focus on unsupervised methods that do not rely on parallel datasets. However, these approaches still require training with sufficient examples that have style labels, and the generated captions are limited to predefined styles. To address these limitations, we explore the problem of Few-Shot Stylized Visual Captioning, which aims to generate captions in any desired style, using only a few examples as guidance during inference, without requiring further training. We propose a framework called FS-StyleCap for this task, which utilizes a conditional encoder-decoder language model and a visual projection module. Our two-step training scheme proceeds as follows: first, we train a style extractor to generate style representations on an unlabeled text-only corpus. Then, we freeze the extractor and enable our decoder to generate stylized descriptions based on the extracted style vector and projected visual content vectors. During inference, our model can generate desired stylized captions by deriving the style representation from user-supplied examples. Our automatic evaluation results for few-shot sentimental visual captioning outperform state-of-the-art approaches and are comparable to models that are fully trained on labeled style corpora. Human evaluations further confirm our model s ability to handle multiple styles.
Lightweight Super-Resolution Head for Human Pose Estimation
Jul 31, 2023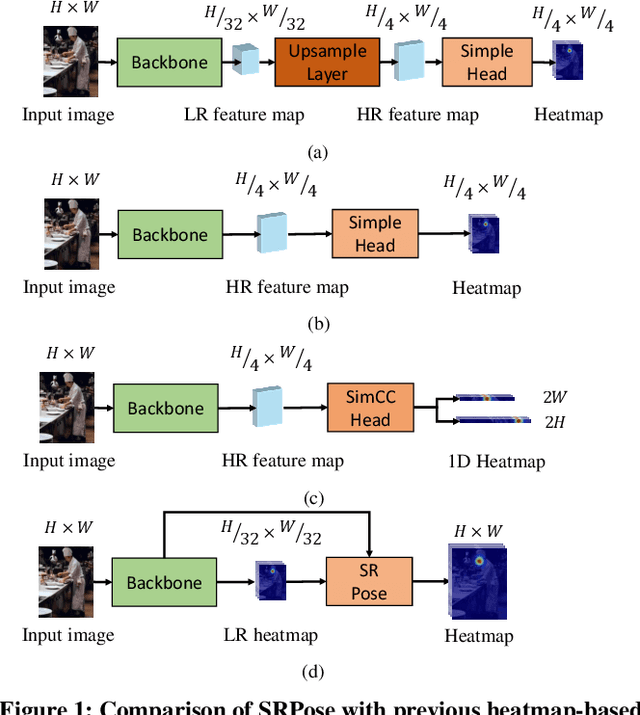
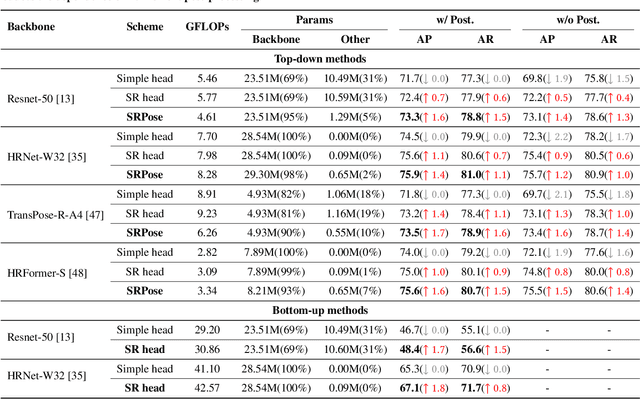
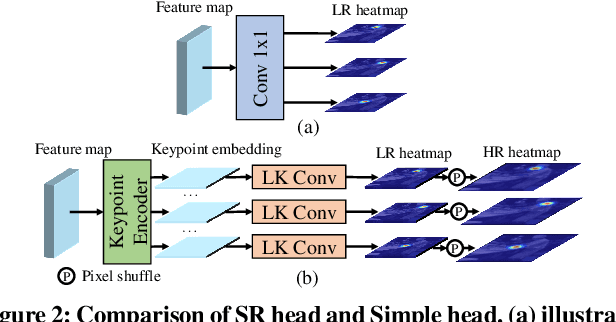
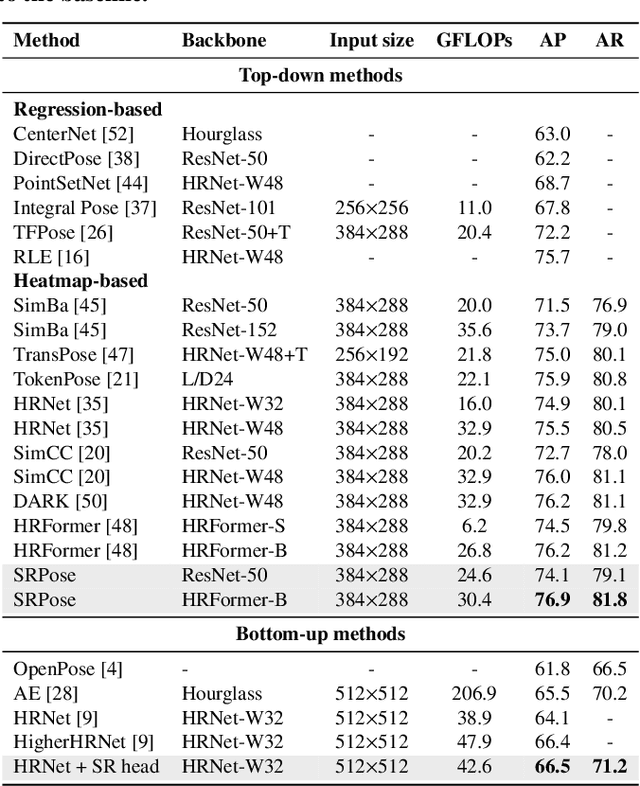
Heatmap-based methods have become the mainstream method for pose estimation due to their superior performance. However, heatmap-based approaches suffer from significant quantization errors with downscale heatmaps, which result in limited performance and the detrimental effects of intermediate supervision. Previous heatmap-based methods relied heavily on additional post-processing to mitigate quantization errors. Some heatmap-based approaches improve the resolution of feature maps by using multiple costly upsampling layers to improve localization precision. To solve the above issues, we creatively view the backbone network as a degradation process and thus reformulate the heatmap prediction as a Super-Resolution (SR) task. We first propose the SR head, which predicts heatmaps with a spatial resolution higher than the input feature maps (or even consistent with the input image) by super-resolution, to effectively reduce the quantization error and the dependence on further post-processing. Besides, we propose SRPose to gradually recover the HR heatmaps from LR heatmaps and degraded features in a coarse-to-fine manner. To reduce the training difficulty of HR heatmaps, SRPose applies SR heads to supervise the intermediate features in each stage. In addition, the SR head is a lightweight and generic head that applies to top-down and bottom-up methods. Extensive experiments on the COCO, MPII, and CrowdPose datasets show that SRPose outperforms the corresponding heatmap-based approaches. The code and models are available at https://github.com/haonanwang0522/SRPose.
* ACM MM 2023 accepted
Multi-layer Aggregation as a key to feature-based OOD detection
Jul 28, 2023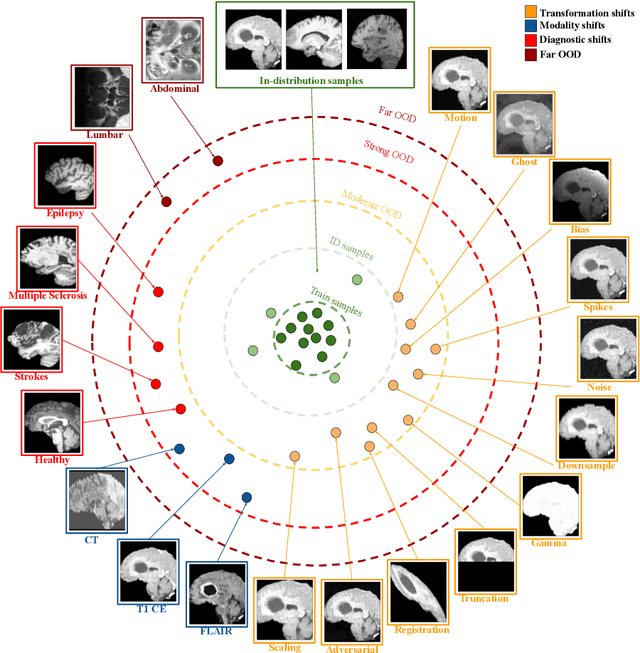
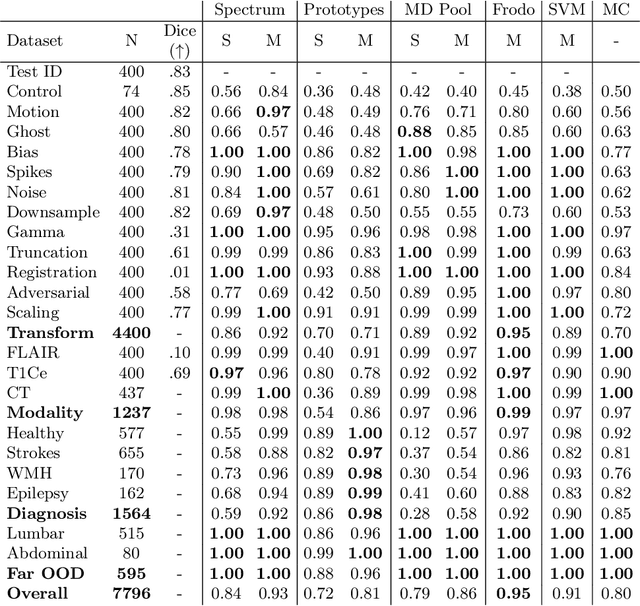
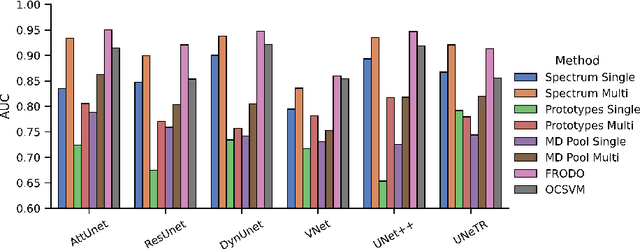
Deep Learning models are easily disturbed by variations in the input images that were not observed during the training stage, resulting in unpredictable predictions. Detecting such Out-of-Distribution (OOD) images is particularly crucial in the context of medical image analysis, where the range of possible abnormalities is extremely wide. Recently, a new category of methods has emerged, based on the analysis of the intermediate features of a trained model. These methods can be divided into 2 groups: single-layer methods that consider the feature map obtained at a fixed, carefully chosen layer, and multi-layer methods that consider the ensemble of the feature maps generated by the model. While promising, a proper comparison of these algorithms is still lacking. In this work, we compared various feature-based OOD detection methods on a large spectra of OOD (20 types), representing approximately 7800 3D MRIs. Our experiments shed the light on two phenomenons. First, multi-layer methods consistently outperform single-layer approaches, which tend to have inconsistent behaviour depending on the type of anomaly. Second, the OOD detection performance highly depends on the architecture of the underlying neural network.
Supervised Homography Learning with Realistic Dataset Generation
Jul 28, 2023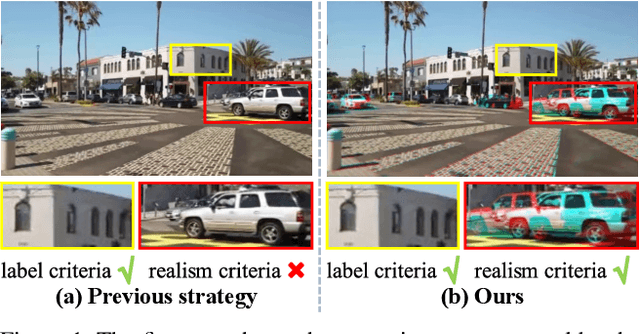
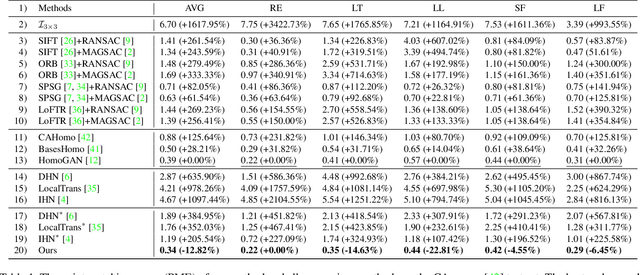
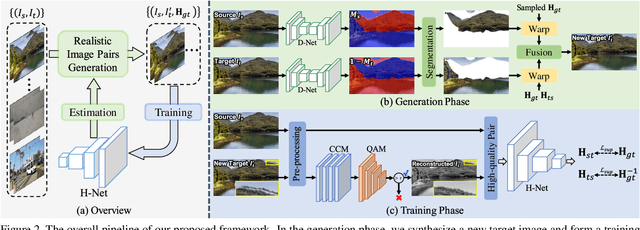
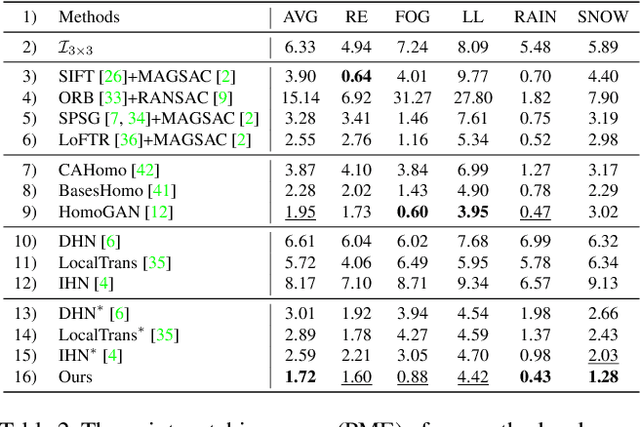
In this paper, we propose an iterative framework, which consists of two phases: a generation phase and a training phase, to generate realistic training data and yield a supervised homography network. In the generation phase, given an unlabeled image pair, we utilize the pre-estimated dominant plane masks and homography of the pair, along with another sampled homography that serves as ground truth to generate a new labeled training pair with realistic motion. In the training phase, the generated data is used to train the supervised homography network, in which the training data is refined via a content consistency module and a quality assessment module. Once an iteration is finished, the trained network is used in the next data generation phase to update the pre-estimated homography. Through such an iterative strategy, the quality of the dataset and the performance of the network can be gradually and simultaneously improved. Experimental results show that our method achieves state-of-the-art performance and existing supervised methods can be also improved based on the generated dataset. Code and dataset are available at https://github.com/megvii-research/RealSH.
Beyond Reality: The Pivotal Role of Generative AI in the Metaverse
Jul 28, 2023
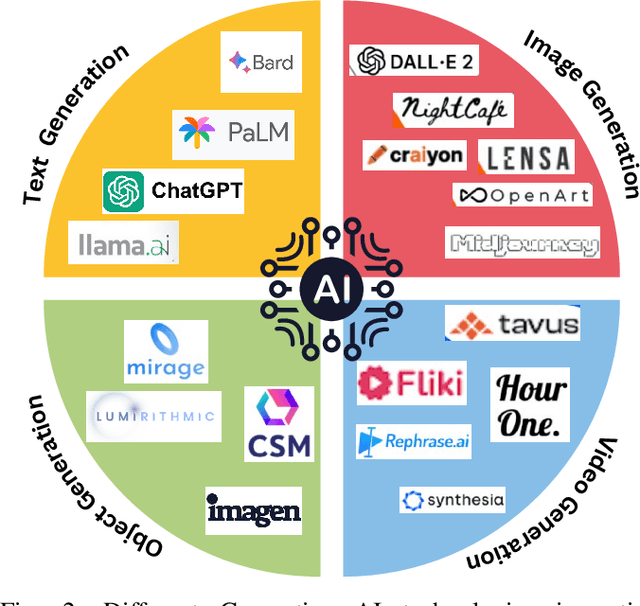
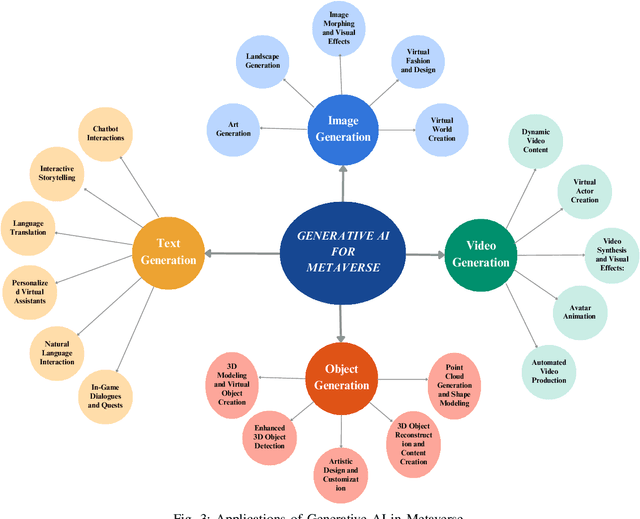
Imagine stepping into a virtual world that's as rich, dynamic, and interactive as our physical one. This is the promise of the Metaverse, and it's being brought to life by the transformative power of Generative Artificial Intelligence (AI). This paper offers a comprehensive exploration of how generative AI technologies are shaping the Metaverse, transforming it into a dynamic, immersive, and interactive virtual world. We delve into the applications of text generation models like ChatGPT and GPT-3, which are enhancing conversational interfaces with AI-generated characters. We explore the role of image generation models such as DALL-E and MidJourney in creating visually stunning and diverse content. We also examine the potential of 3D model generation technologies like Point-E and Lumirithmic in creating realistic virtual objects that enrich the Metaverse experience. But the journey doesn't stop there. We also address the challenges and ethical considerations of implementing these technologies in the Metaverse, offering insights into the balance between user control and AI automation. This paper is not just a study, but a guide to the future of the Metaverse, offering readers a roadmap to harnessing the power of generative AI in creating immersive virtual worlds.
Medical Image Deidentification, Cleaning and Compression Using Pylogik
May 03, 2023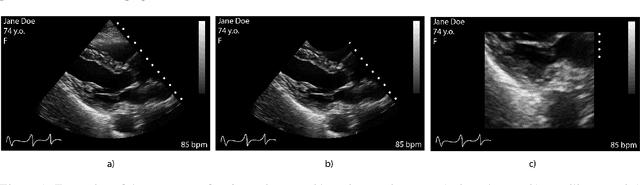

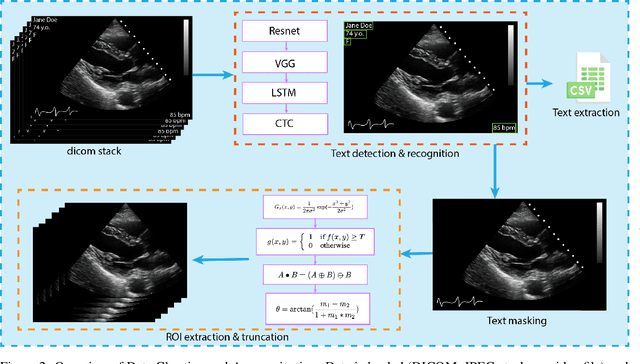
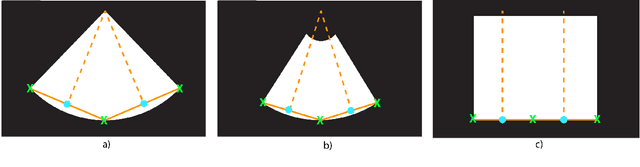
Leveraging medical record information in the era of big data and machine learning comes with the caveat that data must be cleaned and deidentified. Facilitating data sharing and harmonization for multi-center collaborations are particularly difficult when protected health information (PHI) is contained or embedded in image meta-data. We propose a novel library in the Python framework, called PyLogik, to help alleviate this issue for ultrasound images, which are particularly challenging because of the frequent inclusion of PHI directly on the images. PyLogik processes the image volumes through a series of text detection/extraction, filtering, thresholding, morphological and contour comparisons. This methodology deidentifies the images, reduces file sizes, and prepares image volumes for applications in deep learning and data sharing. To evaluate its effectiveness in the identification of regions of interest (ROI), a random sample of 50 cardiac ultrasounds (echocardiograms) were processed through PyLogik, and the outputs were compared with the manual segmentations by an expert user. The Dice coefficient of the two approaches achieved an average value of 0.976. Next, an investigation was conducted to ascertain the degree of information compression achieved using the algorithm. Resultant data was found to be on average approximately 72% smaller after processing by PyLogik. Our results suggest that PyLogik is a viable methodology for ultrasound data cleaning and deidentification, determining ROI, and file compression which will facilitate efficient storage, use, and dissemination of ultrasound data.
Scene Graph as Pivoting: Inference-time Image-free Unsupervised Multimodal Machine Translation with Visual Scene Hallucination
May 25, 2023
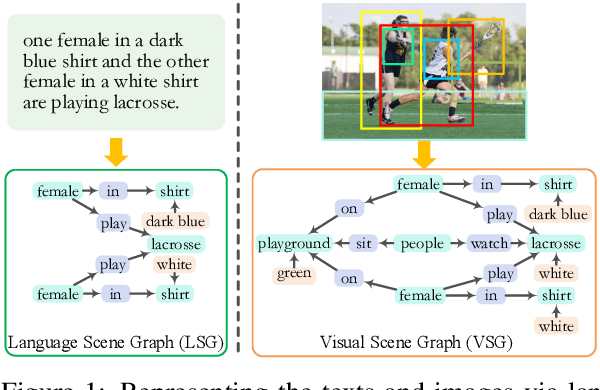
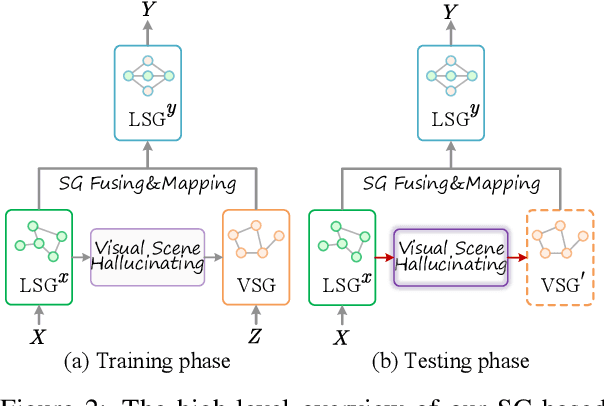
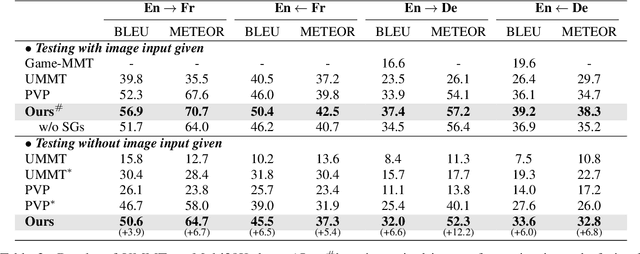
In this work, we investigate a more realistic unsupervised multimodal machine translation (UMMT) setup, inference-time image-free UMMT, where the model is trained with source-text image pairs, and tested with only source-text inputs. First, we represent the input images and texts with the visual and language scene graphs (SG), where such fine-grained vision-language features ensure a holistic understanding of the semantics. To enable pure-text input during inference, we devise a visual scene hallucination mechanism that dynamically generates pseudo visual SG from the given textual SG. Several SG-pivoting based learning objectives are introduced for unsupervised translation training. On the benchmark Multi30K data, our SG-based method outperforms the best-performing baseline by significant BLEU scores on the task and setup, helping yield translations with better completeness, relevance and fluency without relying on paired images. Further in-depth analyses reveal how our model advances in the task setting.
UniFine: A Unified and Fine-grained Approach for Zero-shot Vision-Language Understanding
Jul 03, 2023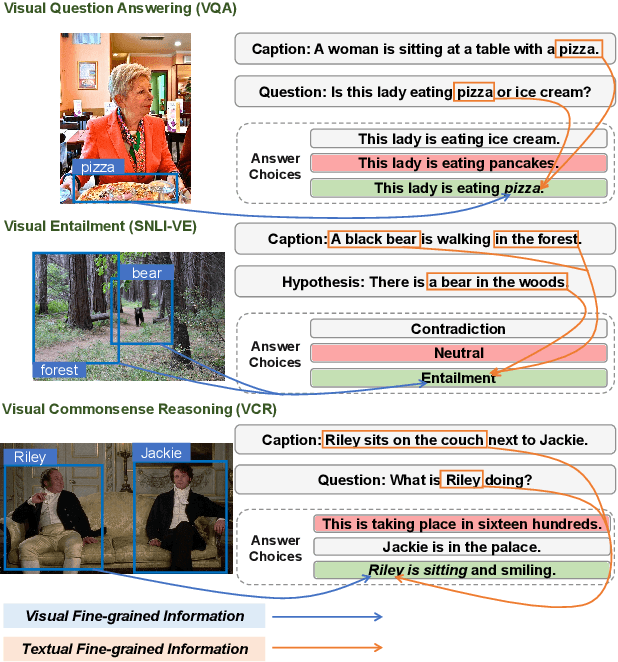
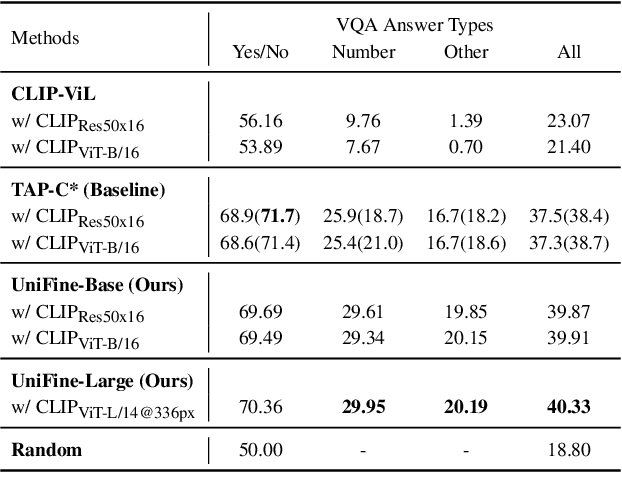
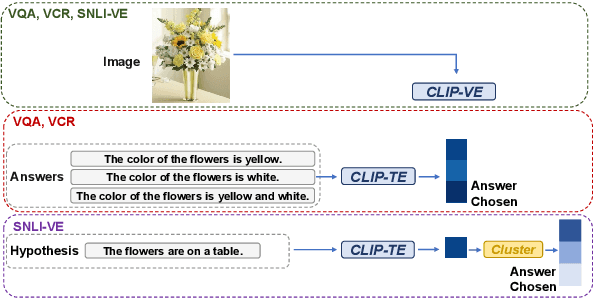
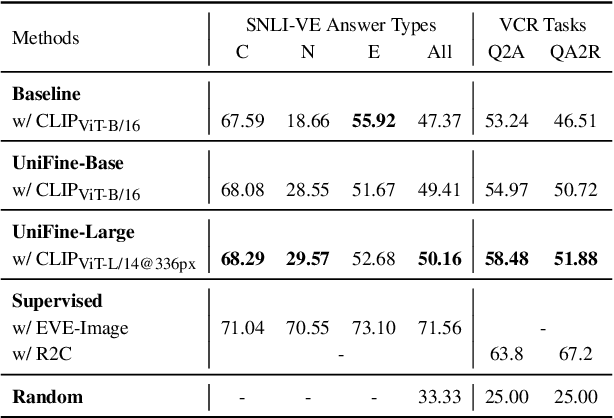
Vision-language tasks, such as VQA, SNLI-VE, and VCR are challenging because they require the model's reasoning ability to understand the semantics of the visual world and natural language. Supervised methods working for vision-language tasks have been well-studied. However, solving these tasks in a zero-shot setting is less explored. Since Contrastive Language-Image Pre-training (CLIP) has shown remarkable zero-shot performance on image-text matching, previous works utilized its strong zero-shot ability by converting vision-language tasks into an image-text matching problem, and they mainly consider global-level matching (e.g., the whole image or sentence). However, we find visual and textual fine-grained information, e.g., keywords in the sentence and objects in the image, can be fairly informative for semantics understanding. Inspired by this, we propose a unified framework to take advantage of the fine-grained information for zero-shot vision-language learning, covering multiple tasks such as VQA, SNLI-VE, and VCR. Our experiments show that our framework outperforms former zero-shot methods on VQA and achieves substantial improvement on SNLI-VE and VCR. Furthermore, our ablation studies confirm the effectiveness and generalizability of our proposed method. Code will be available at https://github.com/ThreeSR/UniFine
Boundary-weighted logit consistency improves calibration of segmentation networks
Jul 16, 2023Neural network prediction probabilities and accuracy are often only weakly-correlated. Inherent label ambiguity in training data for image segmentation aggravates such miscalibration. We show that logit consistency across stochastic transformations acts as a spatially varying regularizer that prevents overconfident predictions at pixels with ambiguous labels. Our boundary-weighted extension of this regularizer provides state-of-the-art calibration for prostate and heart MRI segmentation.
Multimodal Machine Learning for Extraction of Theorems and Proofs in the Scientific Literature
Jul 18, 2023
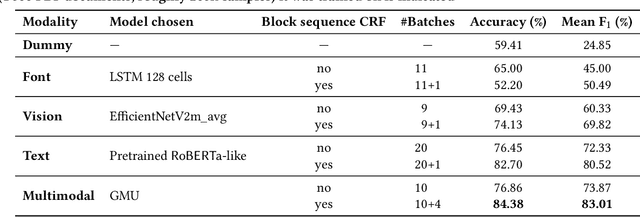
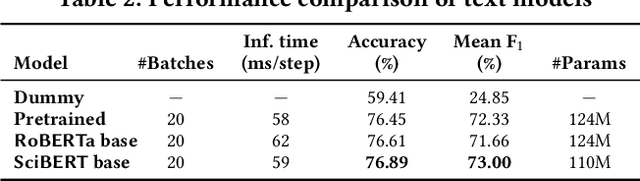
Scholarly articles in mathematical fields feature mathematical statements such as theorems, propositions, etc., as well as their proofs. Extracting them from the PDF representation of the articles requires understanding of scientific text along with visual and font-based indicators. We pose this problem as a multimodal classification problem using text, font features, and bitmap image rendering of the PDF as different modalities. In this paper we propose a multimodal machine learning approach for extraction of theorem-like environments and proofs, based on late fusion of features extracted by individual unimodal classifiers, taking into account the sequential succession of blocks in the document. For the text modality, we pretrain a new language model on a 11 GB scientific corpus; experiments shows similar performance for our task than a model (RoBERTa) pretrained on 160 GB, with faster convergence while requiring much less fine-tuning data. Font-based information relies on training a 128-cell LSTM on the sequence of font names and sizes within each block. Bitmap renderings are dealt with using an EfficientNetv2 deep network tuned to classify each image block. Finally, a simple CRF-based approach uses the features of the multimodal model along with information on block sequences. Experimental results show the benefits of using a multimodal approach vs any single modality, as well as major performance improvements using the CRF modeling of block sequences.