 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Label-Efficient Human Matting: A Simple Baseline for Weakly Semi-Supervised Trimap-Free Human Matting
Apr 01, 2024
This paper presents a new practical training method for human matting, which demands delicate pixel-level human region identification and significantly laborious annotations. To reduce the annotation cost, most existing matting approaches often rely on image synthesis to augment the dataset. However, the unnaturalness of synthesized training images brings in a new domain generalization challenge for natural images. To address this challenge, we introduce a new learning paradigm, weakly semi-supervised human matting (WSSHM), which leverages a small amount of expensive matte labels and a large amount of budget-friendly segmentation labels, to save the annotation cost and resolve the domain generalization problem. To achieve the goal of WSSHM, we propose a simple and effective training method, named Matte Label Blending (MLB), that selectively guides only the beneficial knowledge of the segmentation and matte data to the matting model. Extensive experiments with our detailed analysis demonstrate our method can substantially improve the robustness of the matting model using a few matte data and numerous segmentation data. Our training method is also easily applicable to real-time models, achieving competitive accuracy with breakneck inference speed (328 FPS on NVIDIA V100 GPU). The implementation code is available at \url{https://github.com/clovaai/WSSHM}.
Can Biases in ImageNet Models Explain Generalization?
Apr 01, 2024The robust generalization of models to rare, in-distribution (ID) samples drawn from the long tail of the training distribution and to out-of-training-distribution (OOD) samples is one of the major challenges of current deep learning methods. For image classification, this manifests in the existence of adversarial attacks, the performance drops on distorted images, and a lack of generalization to concepts such as sketches. The current understanding of generalization in neural networks is very limited, but some biases that differentiate models from human vision have been identified and might be causing these limitations. Consequently, several attempts with varying success have been made to reduce these biases during training to improve generalization. We take a step back and sanity-check these attempts. Fixing the architecture to the well-established ResNet-50, we perform a large-scale study on 48 ImageNet models obtained via different training methods to understand how and if these biases - including shape bias, spectral biases, and critical bands - interact with generalization. Our extensive study results reveal that contrary to previous findings, these biases are insufficient to accurately predict the generalization of a model holistically. We provide access to all checkpoints and evaluation code at https://github.com/paulgavrikov/biases_vs_generalization
SV3D: Novel Multi-view Synthesis and 3D Generation from a Single Image using Latent Video Diffusion
Mar 18, 2024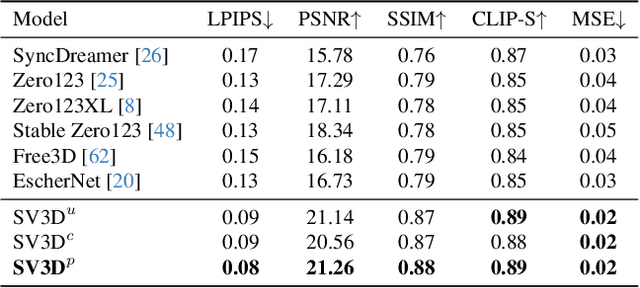
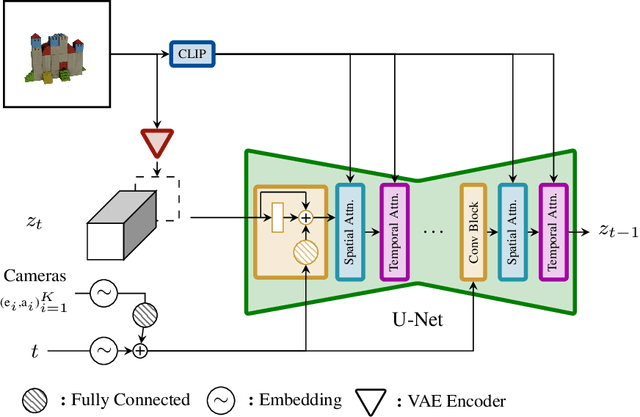
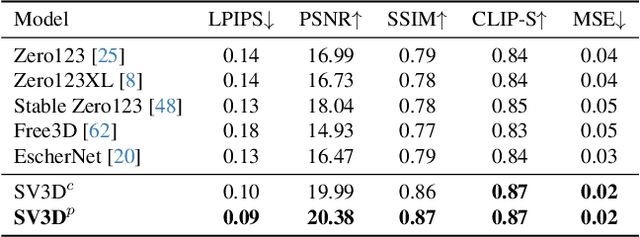
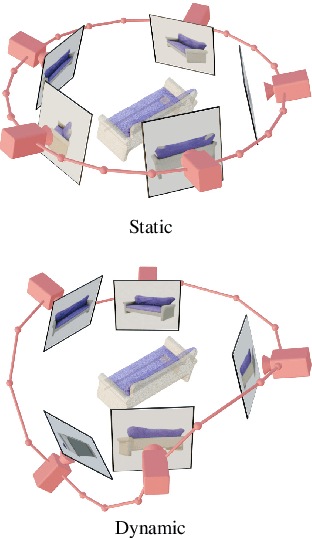
We present Stable Video 3D (SV3D) -- a latent video diffusion model for high-resolution, image-to-multi-view generation of orbital videos around a 3D object. Recent work on 3D generation propose techniques to adapt 2D generative models for novel view synthesis (NVS) and 3D optimization. However, these methods have several disadvantages due to either limited views or inconsistent NVS, thereby affecting the performance of 3D object generation. In this work, we propose SV3D that adapts image-to-video diffusion model for novel multi-view synthesis and 3D generation, thereby leveraging the generalization and multi-view consistency of the video models, while further adding explicit camera control for NVS. We also propose improved 3D optimization techniques to use SV3D and its NVS outputs for image-to-3D generation. Extensive experimental results on multiple datasets with 2D and 3D metrics as well as user study demonstrate SV3D's state-of-the-art performance on NVS as well as 3D reconstruction compared to prior works.
ModaLink: Unifying Modalities for Efficient Image-to-PointCloud Place Recognition
Mar 27, 2024Place recognition is an important task for robots and autonomous cars to localize themselves and close loops in pre-built maps. While single-modal sensor-based methods have shown satisfactory performance, cross-modal place recognition that retrieving images from a point-cloud database remains a challenging problem. Current cross-modal methods transform images into 3D points using depth estimation for modality conversion, which are usually computationally intensive and need expensive labeled data for depth supervision. In this work, we introduce a fast and lightweight framework to encode images and point clouds into place-distinctive descriptors. We propose an effective Field of View (FoV) transformation module to convert point clouds into an analogous modality as images. This module eliminates the necessity for depth estimation and helps subsequent modules achieve real-time performance. We further design a non-negative factorization-based encoder to extract mutually consistent semantic features between point clouds and images. This encoder yields more distinctive global descriptors for retrieval. Experimental results on the KITTI dataset show that our proposed methods achieve state-of-the-art performance while running in real time. Additional evaluation on the HAOMO dataset covering a 17 km trajectory further shows the practical generalization capabilities. We have released the implementation of our methods as open source at: https://github.com/haomo-ai/ModaLink.git.
Anytime, Anywhere, Anyone: Investigating the Feasibility of Segment Anything Model for Crowd-Sourcing Medical Image Annotations
Mar 22, 2024Curating annotations for medical image segmentation is a labor-intensive and time-consuming task that requires domain expertise, resulting in "narrowly" focused deep learning (DL) models with limited translational utility. Recently, foundation models like the Segment Anything Model (SAM) have revolutionized semantic segmentation with exceptional zero-shot generalizability across various domains, including medical imaging, and hold a lot of promise for streamlining the annotation process. However, SAM has yet to be evaluated in a crowd-sourced setting to curate annotations for training 3D DL segmentation models. In this work, we explore the potential of SAM for crowd-sourcing "sparse" annotations from non-experts to generate "dense" segmentation masks for training 3D nnU-Net models, a state-of-the-art DL segmentation model. Our results indicate that while SAM-generated annotations exhibit high mean Dice scores compared to ground-truth annotations, nnU-Net models trained on SAM-generated annotations perform significantly worse than nnU-Net models trained on ground-truth annotations ($p<0.001$, all).
Visual Hallucination: Definition, Quantification, and Prescriptive Remediations
Mar 31, 2024The troubling rise of hallucination presents perhaps the most significant impediment to the advancement of responsible AI. In recent times, considerable research has focused on detecting and mitigating hallucination in Large Language Models (LLMs). However, it's worth noting that hallucination is also quite prevalent in Vision-Language models (VLMs). In this paper, we offer a fine-grained discourse on profiling VLM hallucination based on two tasks: i) image captioning, and ii) Visual Question Answering (VQA). We delineate eight fine-grained orientations of visual hallucination: i) Contextual Guessing, ii) Identity Incongruity, iii) Geographical Erratum, iv) Visual Illusion, v) Gender Anomaly, vi) VLM as Classifier, vii) Wrong Reading, and viii) Numeric Discrepancy. We curate Visual HallucInation eLiciTation (VHILT), a publicly available dataset comprising 2,000 samples generated using eight VLMs across two tasks of captioning and VQA along with human annotations for the categories as mentioned earlier.
Imperceptible Protection against Style Imitation from Diffusion Models
Mar 28, 2024Recent progress in diffusion models has profoundly enhanced the fidelity of image generation. However, this has raised concerns about copyright infringements. While prior methods have introduced adversarial perturbations to prevent style imitation, most are accompanied by the degradation of artworks' visual quality. Recognizing the importance of maintaining this, we develop a visually improved protection method that preserves its protection capability. To this end, we create a perceptual map to identify areas most sensitive to human eyes. We then adjust the protection intensity guided by an instance-aware refinement. We also integrate a perceptual constraints bank to further improve the imperceptibility. Results show that our method substantially elevates the quality of the protected image without compromising on protection efficacy.
E4C: Enhance Editability for Text-Based Image Editing by Harnessing Efficient CLIP Guidance
Mar 15, 2024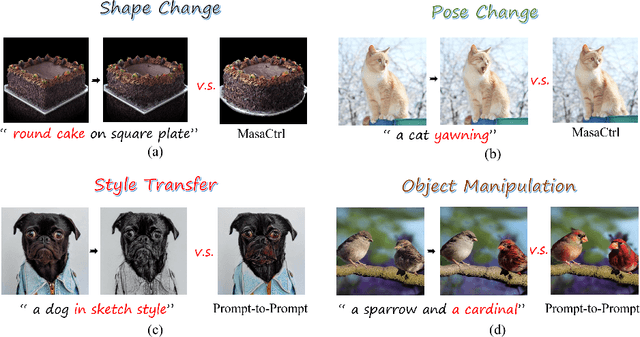
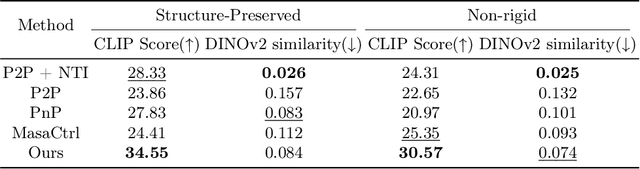
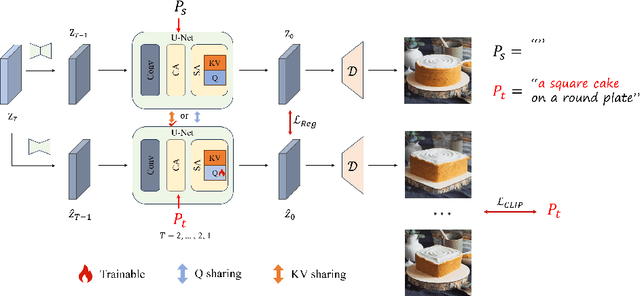

Diffusion-based image editing is a composite process of preserving the source image content and generating new content or applying modifications. While current editing approaches have made improvements under text guidance, most of them have only focused on preserving the information of the input image, disregarding the importance of editability and alignment to the target prompt. In this paper, we prioritize the editability by proposing a zero-shot image editing method, named \textbf{E}nhance \textbf{E}ditability for text-based image \textbf{E}diting via \textbf{E}fficient \textbf{C}LIP guidance (\textbf{E4C}), which only requires inference-stage optimization to explicitly enhance the edibility and text alignment. Specifically, we develop a unified dual-branch feature-sharing pipeline that enables the preservation of the structure or texture of the source image while allowing the other to be adapted based on the editing task. We further integrate CLIP guidance into our pipeline by utilizing our novel random-gateway optimization mechanism to efficiently enhance the semantic alignment with the target prompt. Comprehensive quantitative and qualitative experiments demonstrate that our method effectively resolves the text alignment issues prevalent in existing methods while maintaining the fidelity to the source image, and performs well across a wide range of editing tasks.
Arbitrary-Scale Image Generation and Upsampling using Latent Diffusion Model and Implicit Neural Decoder
Mar 15, 2024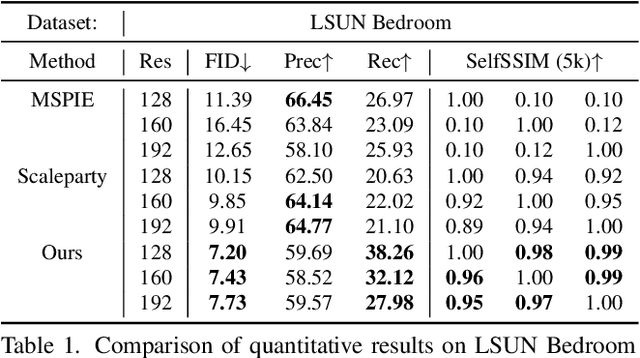
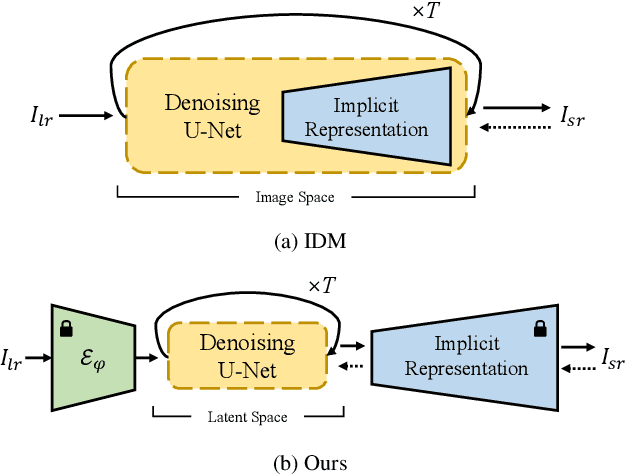

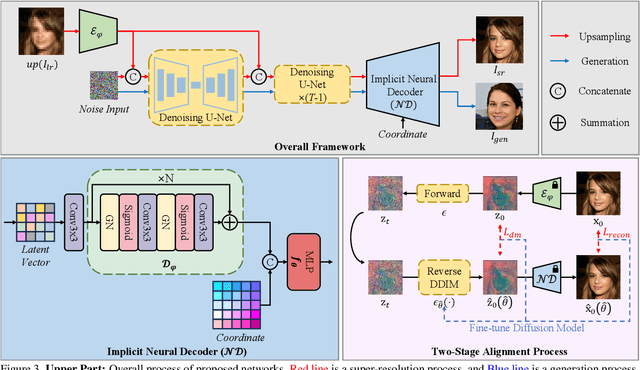
Super-resolution (SR) and image generation are important tasks in computer vision and are widely adopted in real-world applications. Most existing methods, however, generate images only at fixed-scale magnification and suffer from over-smoothing and artifacts. Additionally, they do not offer enough diversity of output images nor image consistency at different scales. Most relevant work applied Implicit Neural Representation (INR) to the denoising diffusion model to obtain continuous-resolution yet diverse and high-quality SR results. Since this model operates in the image space, the larger the resolution of image is produced, the more memory and inference time is required, and it also does not maintain scale-specific consistency. We propose a novel pipeline that can super-resolve an input image or generate from a random noise a novel image at arbitrary scales. The method consists of a pretrained auto-encoder, a latent diffusion model, and an implicit neural decoder, and their learning strategies. The proposed method adopts diffusion processes in a latent space, thus efficient, yet aligned with output image space decoded by MLPs at arbitrary scales. More specifically, our arbitrary-scale decoder is designed by the symmetric decoder w/o up-scaling from the pretrained auto-encoder, and Local Implicit Image Function (LIIF) in series. The latent diffusion process is learnt by the denoising and the alignment losses jointly. Errors in output images are backpropagated via the fixed decoder, improving the quality of output images. In the extensive experiments using multiple public benchmarks on the two tasks i.e. image super-resolution and novel image generation at arbitrary scales, the proposed method outperforms relevant methods in metrics of image quality, diversity and scale consistency. It is significantly better than the relevant prior-art in the inference speed and memory usage.
AAPMT: AGI Assessment Through Prompt and Metric Transformer
Mar 28, 2024The emergence of text-to-image models marks a significant milestone in the evolution of AI-generated images (AGIs), expanding their use in diverse domains like design, entertainment, and more. Despite these breakthroughs, the quality of AGIs often remains suboptimal, highlighting the need for effective evaluation methods. These methods are crucial for assessing the quality of images relative to their textual descriptions, and they must accurately mirror human perception. Substantial progress has been achieved in this domain, with innovative techniques such as BLIP and DBCNN contributing significantly. However, recent studies, including AGIQA-3K, reveal a notable discrepancy between current methods and state-of-the-art (SOTA) standards. This gap emphasizes the necessity for a more sophisticated and precise evaluation metric. In response, our objective is to develop a model that could give ratings for metrics, which focuses on parameters like perceptual quality, authenticity, and the correspondence between text and image, that more closely aligns with human perception. In our paper, we introduce a range of effective methods, including prompt designs and the Metric Transformer. The Metric Transformer is a novel structure inspired by the complex interrelationships among various AGI quality metrics. The code is available at https://github.com/huskydoge/CS3324-Digital-Image-Processing/tree/main/Assignment1