 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Development of pericardial fat count images using a combination of three different deep-learning models
Jul 25, 2023
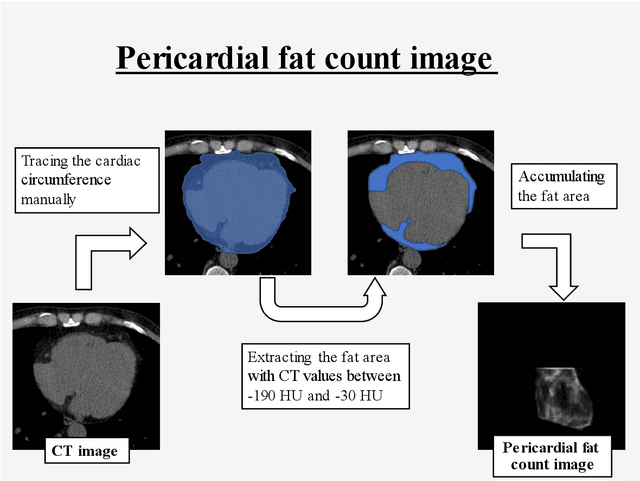
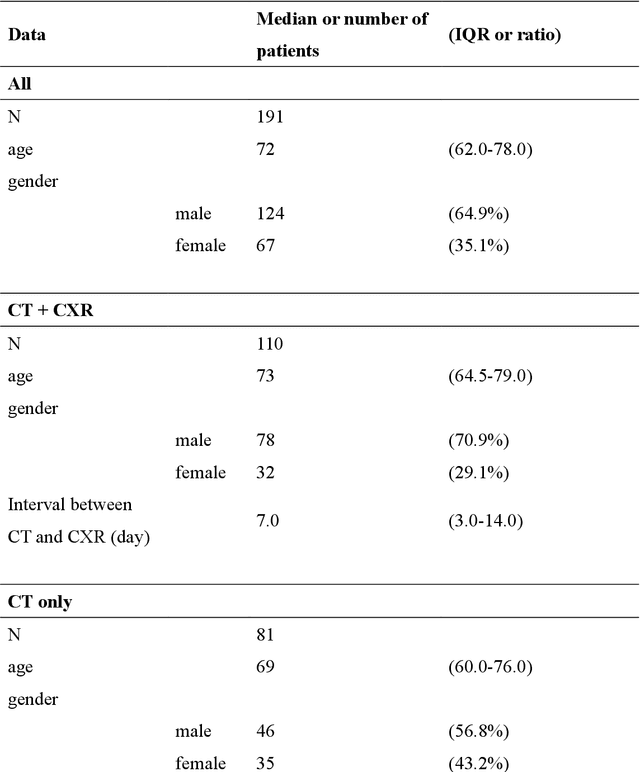
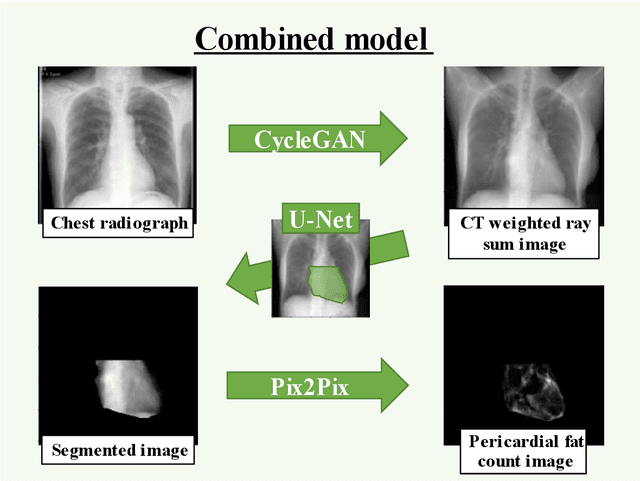
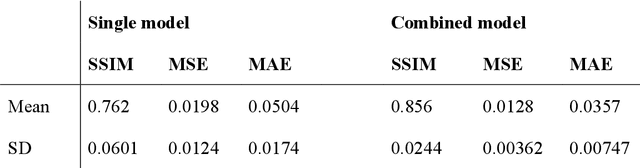
Rationale and Objectives: Pericardial fat (PF), the thoracic visceral fat surrounding the heart, promotes the development of coronary artery disease by inducing inflammation of the coronary arteries. For evaluating PF, this study aimed to generate pericardial fat count images (PFCIs) from chest radiographs (CXRs) using a dedicated deep-learning model. Materials and Methods: The data of 269 consecutive patients who underwent coronary computed tomography (CT) were reviewed. Patients with metal implants, pleural effusion, history of thoracic surgery, or that of malignancy were excluded. Thus, the data of 191 patients were used. PFCIs were generated from the projection of three-dimensional CT images, where fat accumulation was represented by a high pixel value. Three different deep-learning models, including CycleGAN, were combined in the proposed method to generate PFCIs from CXRs. A single CycleGAN-based model was used to generate PFCIs from CXRs for comparison with the proposed method. To evaluate the image quality of the generated PFCIs, structural similarity index measure (SSIM), mean squared error (MSE), and mean absolute error (MAE) of (i) the PFCI generated using the proposed method and (ii) the PFCI generated using the single model were compared. Results: The mean SSIM, MSE, and MAE were as follows: 0.856, 0.0128, and 0.0357, respectively, for the proposed model; and 0.762, 0.0198, and 0.0504, respectively, for the single CycleGAN-based model. Conclusion: PFCIs generated from CXRs with the proposed model showed better performance than those with the single model. PFCI evaluation without CT may be possible with the proposed method.
Foundational Models Defining a New Era in Vision: A Survey and Outlook
Jul 25, 2023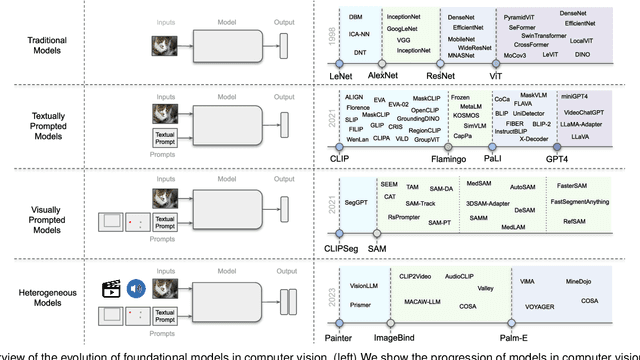
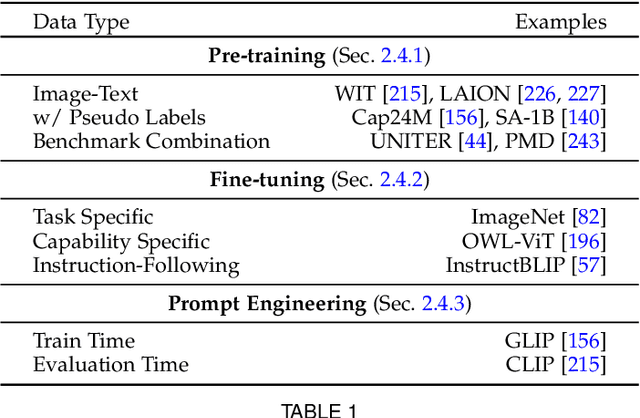
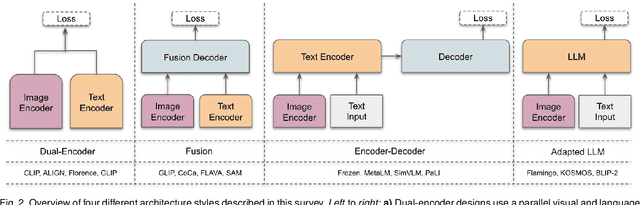
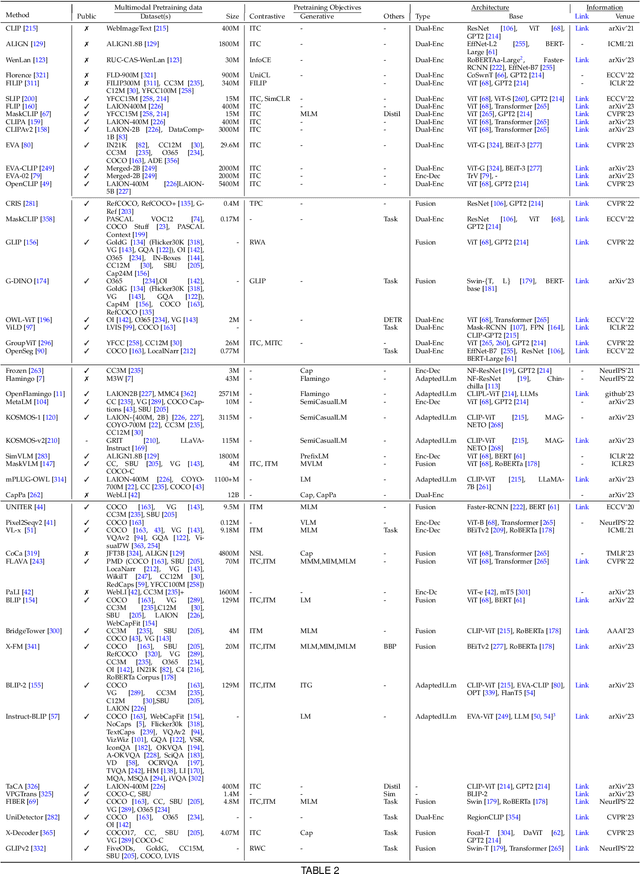
Vision systems to see and reason about the compositional nature of visual scenes are fundamental to understanding our world. The complex relations between objects and their locations, ambiguities, and variations in the real-world environment can be better described in human language, naturally governed by grammatical rules and other modalities such as audio and depth. The models learned to bridge the gap between such modalities coupled with large-scale training data facilitate contextual reasoning, generalization, and prompt capabilities at test time. These models are referred to as foundational models. The output of such models can be modified through human-provided prompts without retraining, e.g., segmenting a particular object by providing a bounding box, having interactive dialogues by asking questions about an image or video scene or manipulating the robot's behavior through language instructions. In this survey, we provide a comprehensive review of such emerging foundational models, including typical architecture designs to combine different modalities (vision, text, audio, etc), training objectives (contrastive, generative), pre-training datasets, fine-tuning mechanisms, and the common prompting patterns; textual, visual, and heterogeneous. We discuss the open challenges and research directions for foundational models in computer vision, including difficulties in their evaluations and benchmarking, gaps in their real-world understanding, limitations of their contextual understanding, biases, vulnerability to adversarial attacks, and interpretability issues. We review recent developments in this field, covering a wide range of applications of foundation models systematically and comprehensively. A comprehensive list of foundational models studied in this work is available at \url{https://github.com/awaisrauf/Awesome-CV-Foundational-Models}.
Promoting Exploration in Memory-Augmented Adam using Critical Momenta
Jul 18, 2023
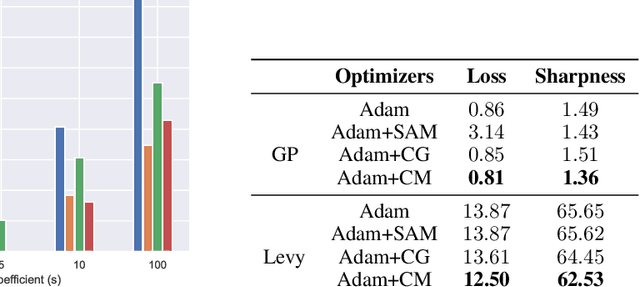

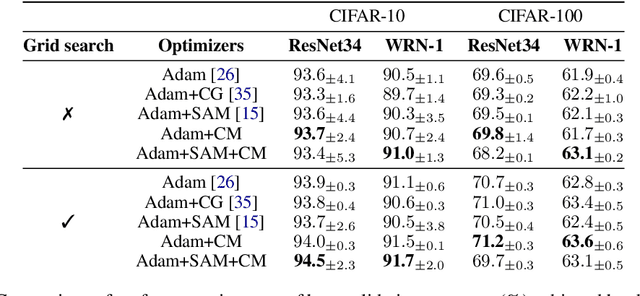
Adaptive gradient-based optimizers, particularly Adam, have left their mark in training large-scale deep learning models. The strength of such optimizers is that they exhibit fast convergence while being more robust to hyperparameter choice. However, they often generalize worse than non-adaptive methods. Recent studies have tied this performance gap to flat minima selection: adaptive methods tend to find solutions in sharper basins of the loss landscape, which in turn hurts generalization. To overcome this issue, we propose a new memory-augmented version of Adam that promotes exploration towards flatter minima by using a buffer of critical momentum terms during training. Intuitively, the use of the buffer makes the optimizer overshoot outside the basin of attraction if it is not wide enough. We empirically show that our method improves the performance of several variants of Adam on standard supervised language modelling and image classification tasks.
Defense against Adversarial Cloud Attack on Remote Sensing Salient Object Detection
Jun 30, 2023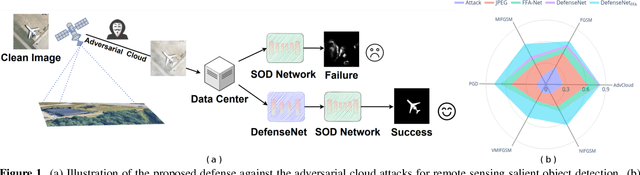
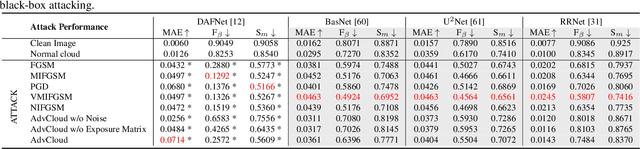
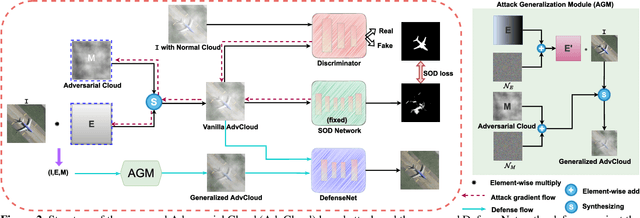
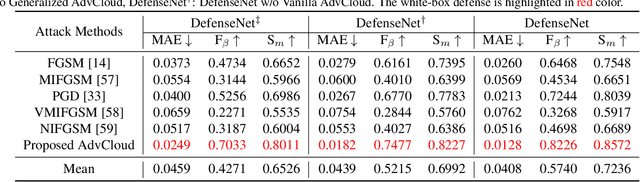
etecting the salient objects in a remote sensing image has wide applications for the interdisciplinary research. Many existing deep learning methods have been proposed for Salient Object Detection (SOD) in remote sensing images and get remarkable results. However, the recent adversarial attack examples, generated by changing a few pixel values on the original remote sensing image, could result in a collapse for the well-trained deep learning based SOD model. Different with existing methods adding perturbation to original images, we propose to jointly tune adversarial exposure and additive perturbation for attack and constrain image close to cloudy image as Adversarial Cloud. Cloud is natural and common in remote sensing images, however, camouflaging cloud based adversarial attack and defense for remote sensing images are not well studied before. Furthermore, we design DefenseNet as a learn-able pre-processing to the adversarial cloudy images so as to preserve the performance of the deep learning based remote sensing SOD model, without tuning the already deployed deep SOD model. By considering both regular and generalized adversarial examples, the proposed DefenseNet can defend the proposed Adversarial Cloud in white-box setting and other attack methods in black-box setting. Experimental results on a synthesized benchmark from the public remote sensing SOD dataset (EORSSD) show the promising defense against adversarial cloud attacks.
PSDR-Room: Single Photo to Scene using Differentiable Rendering
Jul 06, 2023
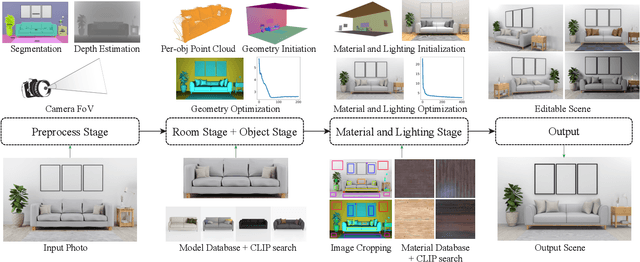
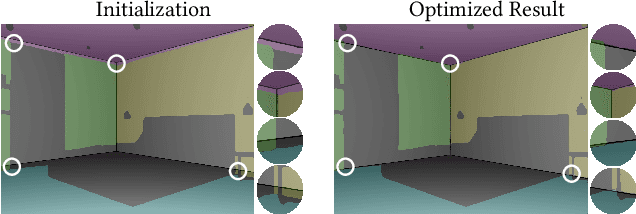
A 3D digital scene contains many components: lights, materials and geometries, interacting to reach the desired appearance. Staging such a scene is time-consuming and requires both artistic and technical skills. In this work, we propose PSDR-Room, a system allowing to optimize lighting as well as the pose and materials of individual objects to match a target image of a room scene, with minimal user input. To this end, we leverage a recent path-space differentiable rendering approach that provides unbiased gradients of the rendering with respect to geometry, lighting, and procedural materials, allowing us to optimize all of these components using gradient descent to visually match the input photo appearance. We use recent single-image scene understanding methods to initialize the optimization and search for appropriate 3D models and materials. We evaluate our method on real photographs of indoor scenes and demonstrate the editability of the resulting scene components.
Multimodal Document Analytics for Banking Process Automation
Jul 21, 2023
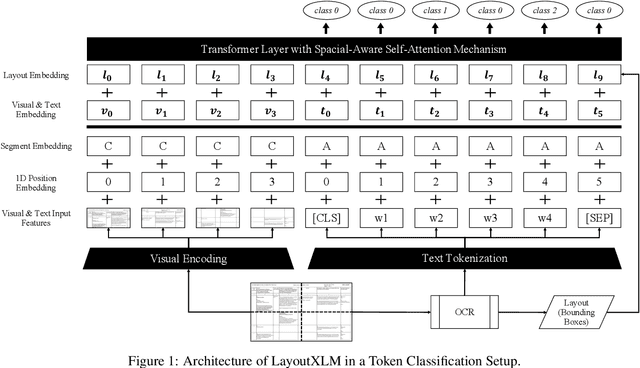
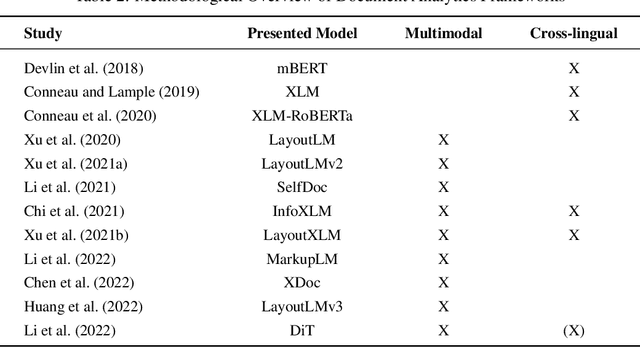
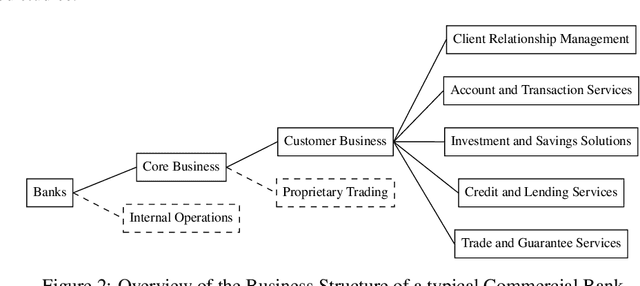
In response to growing FinTech competition and the need for improved operational efficiency, this research focuses on understanding the potential of advanced document analytics, particularly using multimodal models, in banking processes. We perform a comprehensive analysis of the diverse banking document landscape, highlighting the opportunities for efficiency gains through automation and advanced analytics techniques in the customer business. Building on the rapidly evolving field of natural language processing (NLP), we illustrate the potential of models such as LayoutXLM, a cross-lingual, multimodal, pre-trained model, for analyzing diverse documents in the banking sector. This model performs a text token classification on German company register extracts with an overall F1 score performance of around 80\%. Our empirical evidence confirms the critical role of layout information in improving model performance and further underscores the benefits of integrating image information. Interestingly, our study shows that over 75% F1 score can be achieved with only 30% of the training data, demonstrating the efficiency of LayoutXLM. Through addressing state-of-the-art document analysis frameworks, our study aims to enhance process efficiency and demonstrate the real-world applicability and benefits of multimodal models within banking.
HybridAugment++: Unified Frequency Spectra Perturbations for Model Robustness
Jul 21, 2023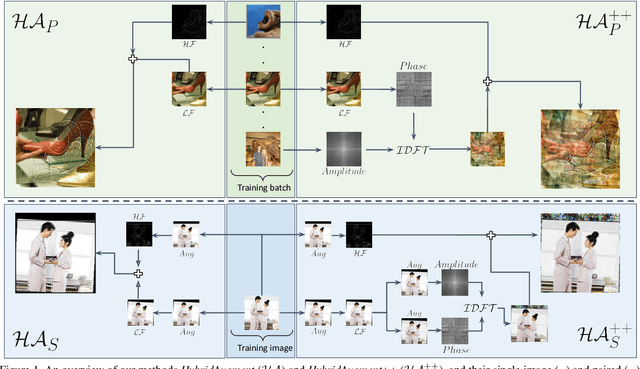
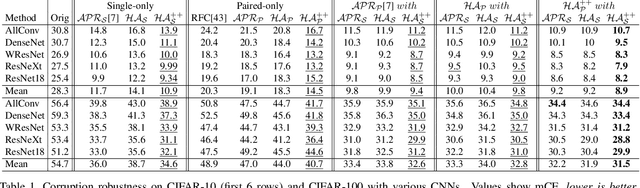
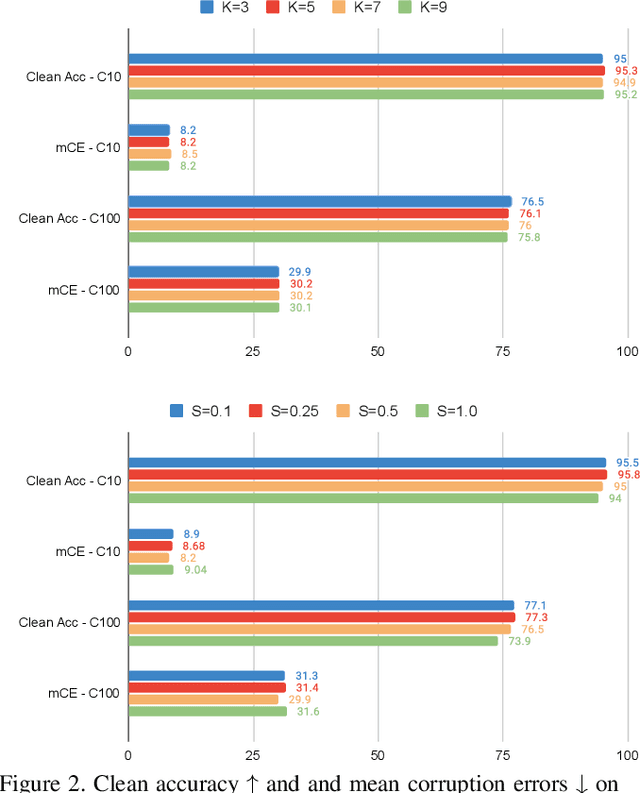
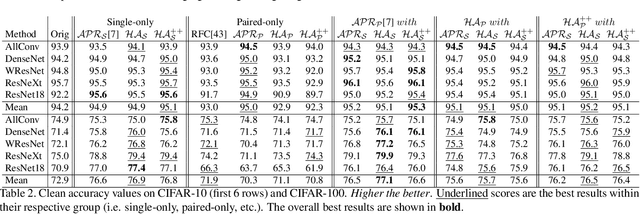
Convolutional Neural Networks (CNN) are known to exhibit poor generalization performance under distribution shifts. Their generalization have been studied extensively, and one line of work approaches the problem from a frequency-centric perspective. These studies highlight the fact that humans and CNNs might focus on different frequency components of an image. First, inspired by these observations, we propose a simple yet effective data augmentation method HybridAugment that reduces the reliance of CNNs on high-frequency components, and thus improves their robustness while keeping their clean accuracy high. Second, we propose HybridAugment++, which is a hierarchical augmentation method that attempts to unify various frequency-spectrum augmentations. HybridAugment++ builds on HybridAugment, and also reduces the reliance of CNNs on the amplitude component of images, and promotes phase information instead. This unification results in competitive to or better than state-of-the-art results on clean accuracy (CIFAR-10/100 and ImageNet), corruption benchmarks (ImageNet-C, CIFAR-10-C and CIFAR-100-C), adversarial robustness on CIFAR-10 and out-of-distribution detection on various datasets. HybridAugment and HybridAugment++ are implemented in a few lines of code, does not require extra data, ensemble models or additional networks.
Robust Visual Question Answering: Datasets, Methods, and Future Challenges
Jul 21, 2023
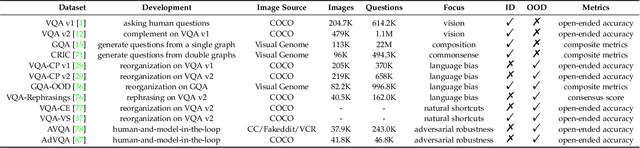
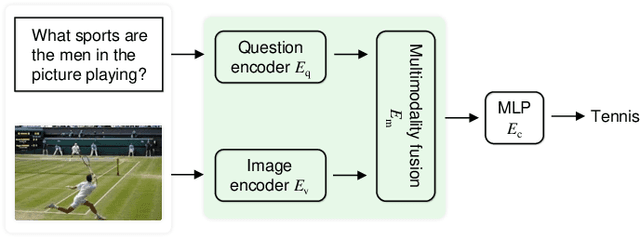
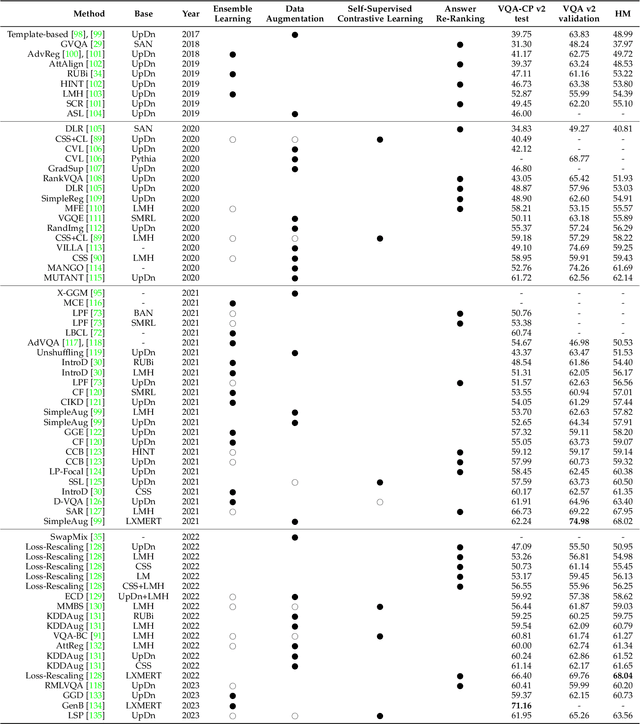
Visual question answering requires a system to provide an accurate natural language answer given an image and a natural language question. However, it is widely recognized that previous generic VQA methods often exhibit a tendency to memorize biases present in the training data rather than learning proper behaviors, such as grounding images before predicting answers. Therefore, these methods usually achieve high in-distribution but poor out-of-distribution performance. In recent years, various datasets and debiasing methods have been proposed to evaluate and enhance the VQA robustness, respectively. This paper provides the first comprehensive survey focused on this emerging fashion. Specifically, we first provide an overview of the development process of datasets from in-distribution and out-of-distribution perspectives. Then, we examine the evaluation metrics employed by these datasets. Thirdly, we propose a typology that presents the development process, similarities and differences, robustness comparison, and technical features of existing debiasing methods. Furthermore, we analyze and discuss the robustness of representative vision-and-language pre-training models on VQA. Finally, through a thorough review of the available literature and experimental analysis, we discuss the key areas for future research from various viewpoints.
Rethinking Medical Report Generation: Disease Revealing Enhancement with Knowledge Graph
Jul 24, 2023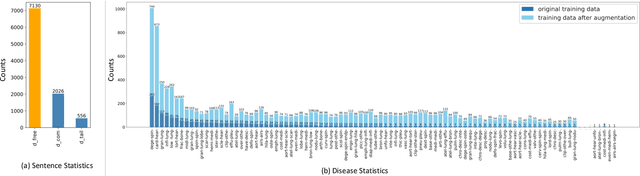
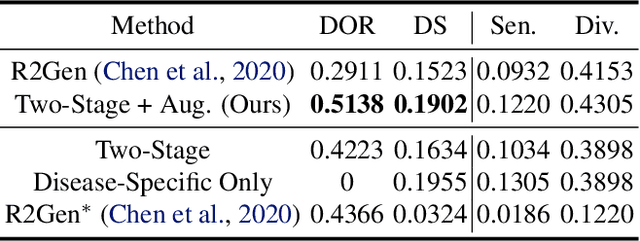
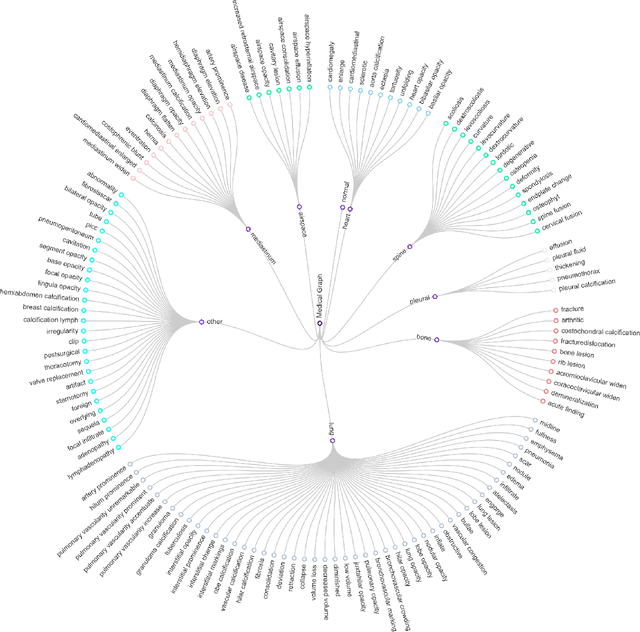
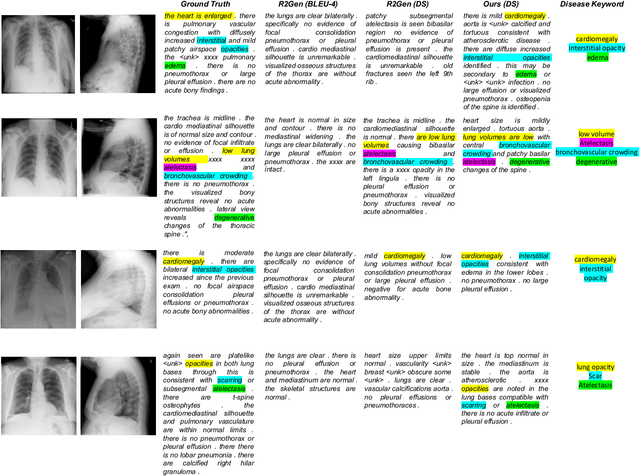
Knowledge Graph (KG) plays a crucial role in Medical Report Generation (MRG) because it reveals the relations among diseases and thus can be utilized to guide the generation process. However, constructing a comprehensive KG is labor-intensive and its applications on the MRG process are under-explored. In this study, we establish a complete KG on chest X-ray imaging that includes 137 types of diseases and abnormalities. Based on this KG, we find that the current MRG data sets exhibit a long-tailed problem in disease distribution. To mitigate this problem, we introduce a novel augmentation strategy that enhances the representation of disease types in the tail-end of the distribution. We further design a two-stage MRG approach, where a classifier is first trained to detect whether the input images exhibit any abnormalities. The classified images are then independently fed into two transformer-based generators, namely, ``disease-specific generator" and ``disease-free generator" to generate the corresponding reports. To enhance the clinical evaluation of whether the generated reports correctly describe the diseases appearing in the input image, we propose diverse sensitivity (DS), a new metric that checks whether generated diseases match ground truth and measures the diversity of all generated diseases. Results show that the proposed two-stage generation framework and augmentation strategies improve DS by a considerable margin, indicating a notable reduction in the long-tailed problem associated with under-represented diseases.
ExWarp: Extrapolation and Warping-based Temporal Supersampling for High-frequency Displays
Jul 24, 2023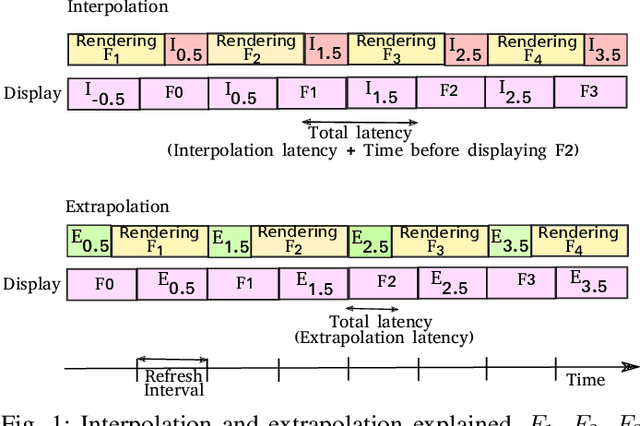
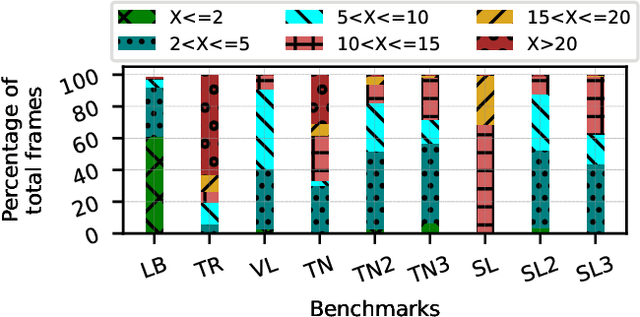
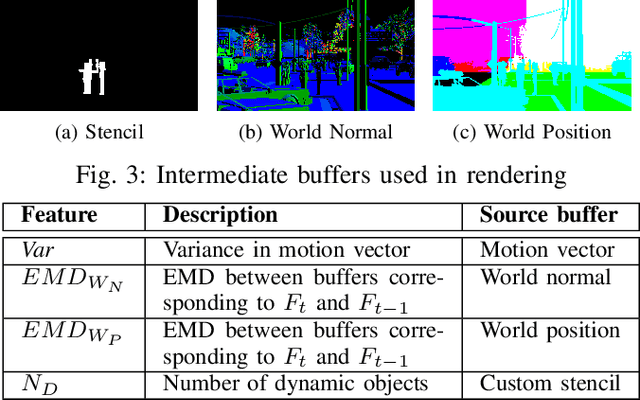
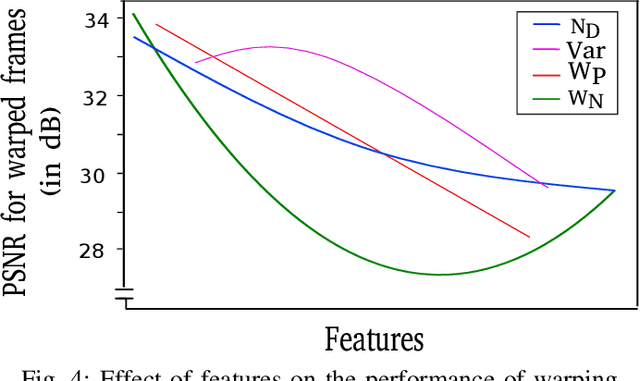
High-frequency displays are gaining immense popularity because of their increasing use in video games and virtual reality applications. However, the issue is that the underlying GPUs cannot continuously generate frames at this high rate -- this results in a less smooth and responsive experience. Furthermore, if the frame rate is not synchronized with the refresh rate, the user may experience screen tearing and stuttering. Previous works propose increasing the frame rate to provide a smooth experience on modern displays by predicting new frames based on past or future frames. Interpolation and extrapolation are two widely used algorithms that predict new frames. Interpolation requires waiting for the future frame to make a prediction, which adds additional latency. On the other hand, extrapolation provides a better quality of experience because it relies solely on past frames -- it does not incur any additional latency. The simplest method to extrapolate a frame is to warp the previous frame using motion vectors; however, the warped frame may contain improperly rendered visual artifacts due to dynamic objects -- this makes it very challenging to design such a scheme. Past work has used DNNs to get good accuracy, however, these approaches are slow. This paper proposes Exwarp -- an approach based on reinforcement learning (RL) to intelligently choose between the slower DNN-based extrapolation and faster warping-based methods to increase the frame rate by 4x with an almost negligible reduction in the perceived image quality.