 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Active Learning for Object Detection with Non-Redundant Informative Sampling
Jul 17, 2023
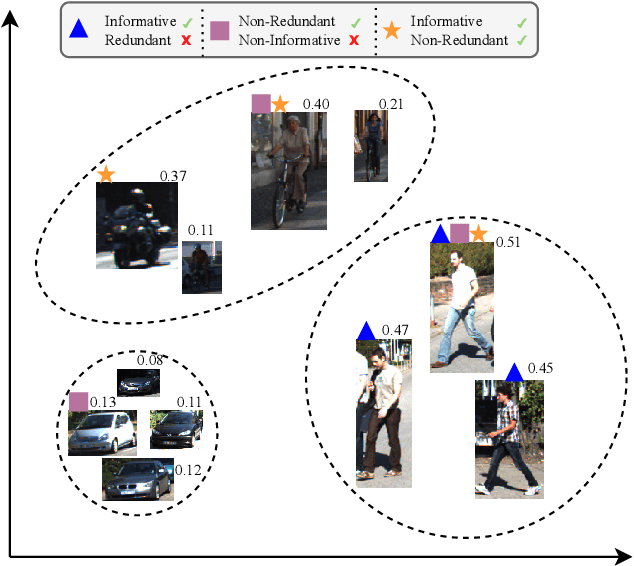
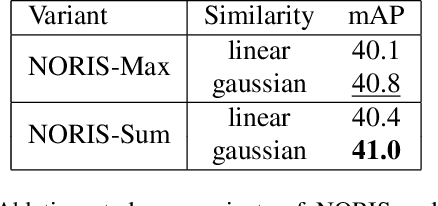
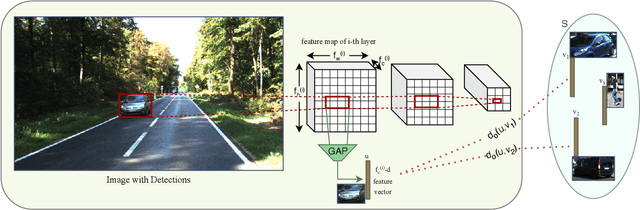
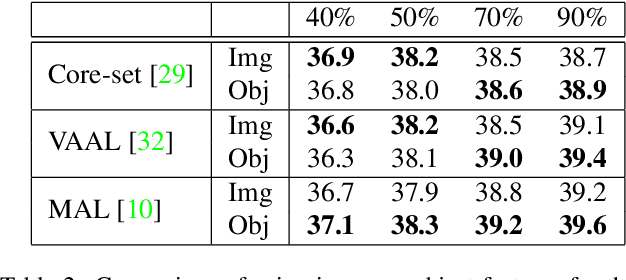
Curating an informative and representative dataset is essential for enhancing the performance of 2D object detectors. We present a novel active learning sampling strategy that addresses both the informativeness and diversity of the selections. Our strategy integrates uncertainty and diversity-based selection principles into a joint selection objective by measuring the collective information score of the selected samples. Specifically, our proposed NORIS algorithm quantifies the impact of training with a sample on the informativeness of other similar samples. By exclusively selecting samples that are simultaneously informative and distant from other highly informative samples, we effectively avoid redundancy while maintaining a high level of informativeness. Moreover, instead of utilizing whole image features to calculate distances between samples, we leverage features extracted from detected object regions within images to define object features. This allows us to construct a dataset encompassing diverse object types, shapes, and angles. Extensive experiments on object detection and image classification tasks demonstrate the effectiveness of our strategy over the state-of-the-art baselines. Specifically, our selection strategy achieves a 20% and 30% reduction in labeling costs compared to random selection for PASCAL-VOC and KITTI, respectively.
Image Manipulation via Multi-Hop Instructions -- A New Dataset and Weakly-Supervised Neuro-Symbolic Approach
May 23, 2023
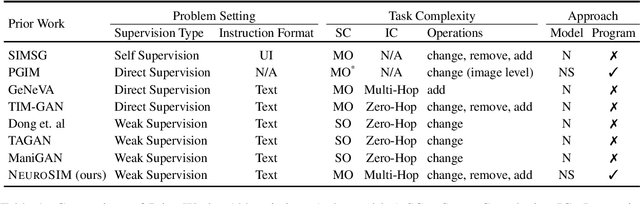
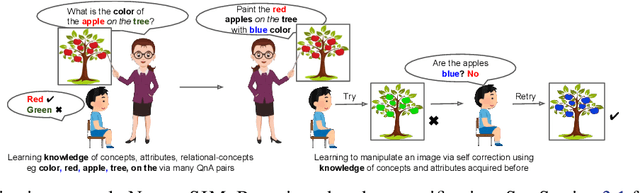

We are interested in image manipulation via natural language text -- a task that is useful for multiple AI applications but requires complex reasoning over multi-modal spaces. We extend recently proposed Neuro Symbolic Concept Learning (NSCL), which has been quite effective for the task of Visual Question Answering (VQA), for the task of image manipulation. Our system referred to as NeuroSIM can perform complex multi-hop reasoning over multi-object scenes and only requires weak supervision in the form of annotated data for VQA. NeuroSIM parses an instruction into a symbolic program, based on a Domain Specific Language (DSL) comprising of object attributes and manipulation operations, that guides its execution. We create a new dataset for the task, and extensive experiments demonstrate that NeuroSIM is highly competitive with or beats SOTA baselines that make use of supervised data for manipulation.
Comparison of Point Cloud and Image-based Models for Calorimeter Fast Simulation
Jul 10, 2023
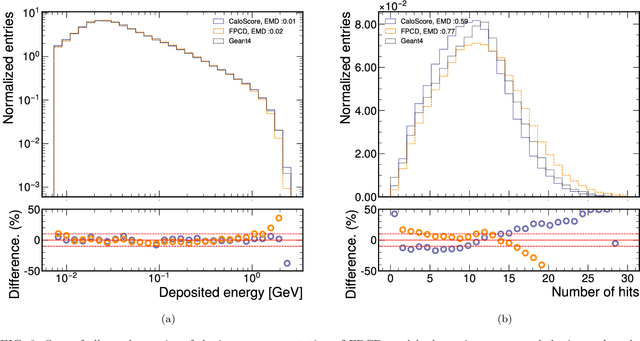
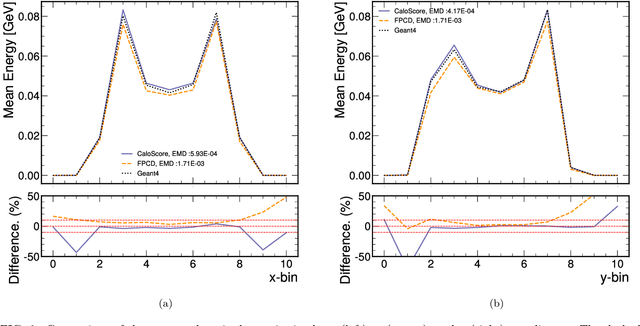
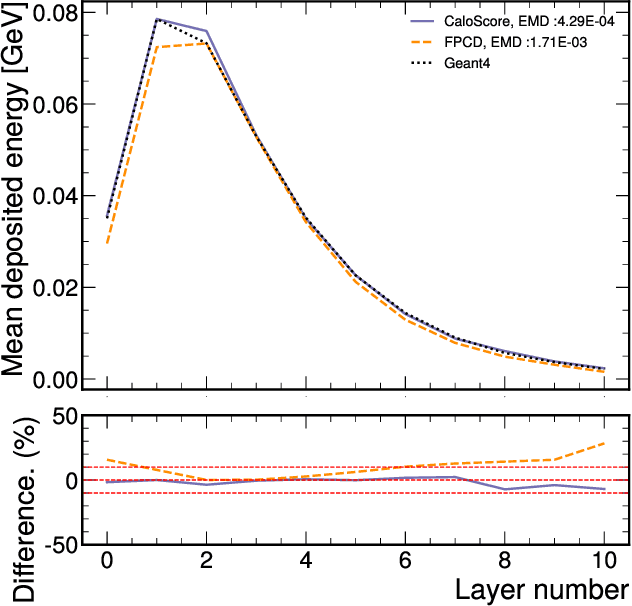
Score based generative models are a new class of generative models that have been shown to accurately generate high dimensional calorimeter datasets. Recent advances in generative models have used images with 3D voxels to represent and model complex calorimeter showers. Point clouds, however, are likely a more natural representation of calorimeter showers, particularly in calorimeters with high granularity. Point clouds preserve all of the information of the original simulation, more naturally deal with sparse datasets, and can be implemented with more compact models and data files. In this work, two state-of-the-art score based models are trained on the same set of calorimeter simulation and directly compared.
Unsupervised Feature Learning with Emergent Data-Driven Prototypicality
Jul 04, 2023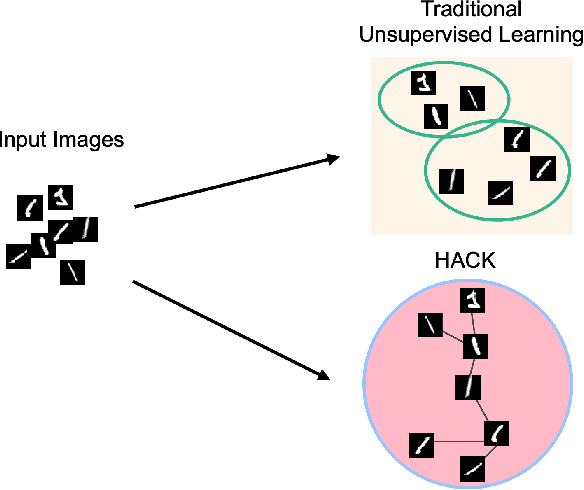


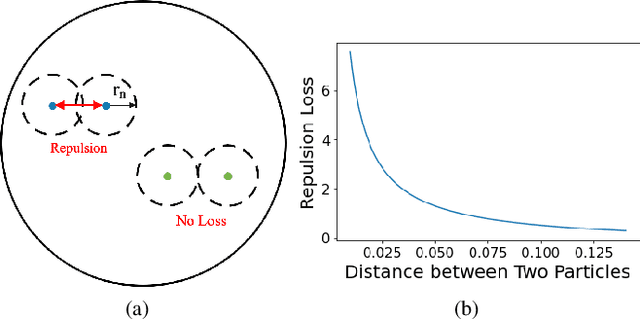
Given an image set without any labels, our goal is to train a model that maps each image to a point in a feature space such that, not only proximity indicates visual similarity, but where it is located directly encodes how prototypical the image is according to the dataset. Our key insight is to perform unsupervised feature learning in hyperbolic instead of Euclidean space, where the distance between points still reflect image similarity, and yet we gain additional capacity for representing prototypicality with the location of the point: The closer it is to the origin, the more prototypical it is. The latter property is simply emergent from optimizing the usual metric learning objective: The image similar to many training instances is best placed at the center of corresponding points in Euclidean space, but closer to the origin in hyperbolic space. We propose an unsupervised feature learning algorithm in Hyperbolic space with sphere pACKing. HACK first generates uniformly packed particles in the Poincar\'e ball of hyperbolic space and then assigns each image uniquely to each particle. Images after congealing are regarded more typical of the dataset it belongs to. With our feature mapper simply trained to spread out training instances in hyperbolic space, we observe that images move closer to the origin with congealing, validating our idea of unsupervised prototypicality discovery. We demonstrate that our data-driven prototypicality provides an easy and superior unsupervised instance selection to reduce sample complexity, increase model generalization with atypical instances and robustness with typical ones.
Towards Authentic Face Restoration with Iterative Diffusion Models and Beyond
Jul 18, 2023
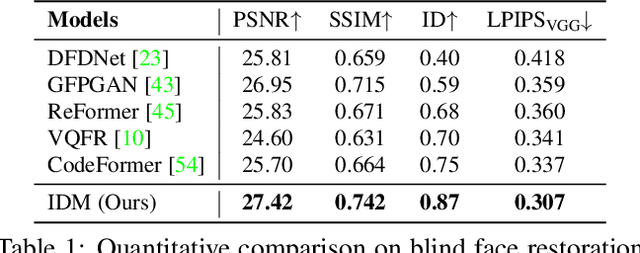

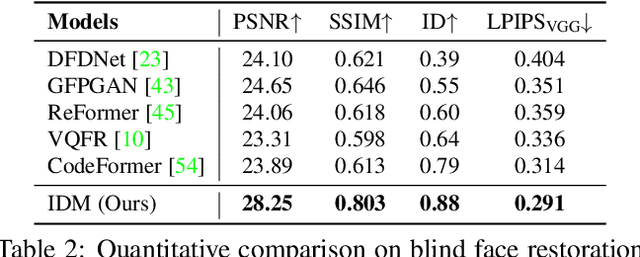
An authentic face restoration system is becoming increasingly demanding in many computer vision applications, e.g., image enhancement, video communication, and taking portrait. Most of the advanced face restoration models can recover high-quality faces from low-quality ones but usually fail to faithfully generate realistic and high-frequency details that are favored by users. To achieve authentic restoration, we propose $\textbf{IDM}$, an $\textbf{I}$teratively learned face restoration system based on denoising $\textbf{D}$iffusion $\textbf{M}$odels (DDMs). We define the criterion of an authentic face restoration system, and argue that denoising diffusion models are naturally endowed with this property from two aspects: intrinsic iterative refinement and extrinsic iterative enhancement. Intrinsic learning can preserve the content well and gradually refine the high-quality details, while extrinsic enhancement helps clean the data and improve the restoration task one step further. We demonstrate superior performance on blind face restoration tasks. Beyond restoration, we find the authentically cleaned data by the proposed restoration system is also helpful to image generation tasks in terms of training stabilization and sample quality. Without modifying the models, we achieve better quality than state-of-the-art on FFHQ and ImageNet generation using either GANs or diffusion models.
Mercer Large-Scale Kernel Machines from Ridge Function Perspective
Jul 21, 2023To present Mercer large-scale kernel machines from a ridge function perspective, we recall the results by Lin and Pinkus from Fundamentality of ridge functions. We consider the main theorem of the recent paper by Rachimi and Recht, 2008, Random features for large-scale kernel machines in terms of the Approximation Theory. We study which kernels can be approximated by a sum of cosine function products with arguments depending on $x$ and $y$ and present the obstacles of such an approach. The results of this article may have various applications in Deep Learning, especially in problems related to Image Processing.
Unsupervised Segmentation of Fetal Brain MRI using Deep Learning Cascaded Registration
Jul 07, 2023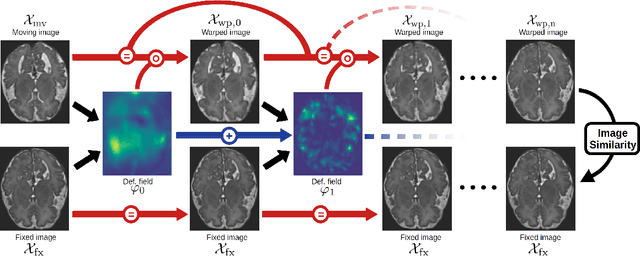
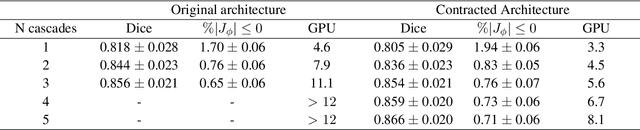

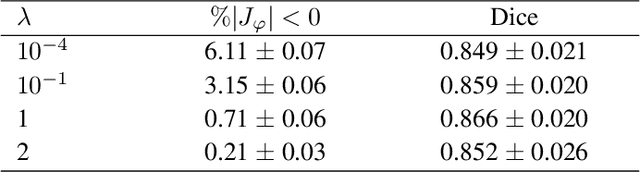
Accurate segmentation of fetal brain magnetic resonance images is crucial for analyzing fetal brain development and detecting potential neurodevelopmental abnormalities. Traditional deep learning-based automatic segmentation, although effective, requires extensive training data with ground-truth labels, typically produced by clinicians through a time-consuming annotation process. To overcome this challenge, we propose a novel unsupervised segmentation method based on multi-atlas segmentation, that accurately segments multiple tissues without relying on labeled data for training. Our method employs a cascaded deep learning network for 3D image registration, which computes small, incremental deformations to the moving image to align it precisely with the fixed image. This cascaded network can then be used to register multiple annotated images with the image to be segmented, and combine the propagated labels to form a refined segmentation. Our experiments demonstrate that the proposed cascaded architecture outperforms the state-of-the-art registration methods that were tested. Furthermore, the derived segmentation method achieves similar performance and inference time to nnU-Net while only using a small subset of annotated data for the multi-atlas segmentation task and none for training the network. Our pipeline for registration and multi-atlas segmentation is publicly available at https://github.com/ValBcn/CasReg.
Caption Anything: Interactive Image Description with Diverse Multimodal Controls
May 04, 2023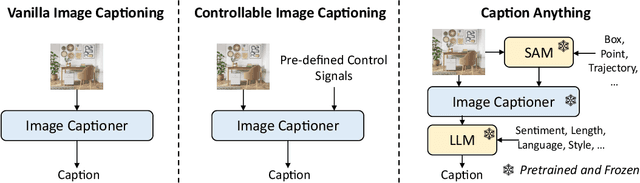
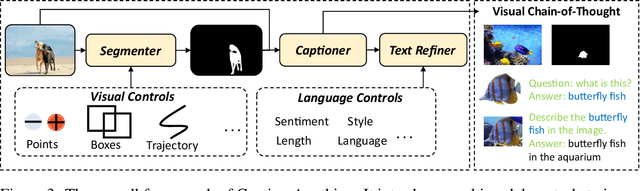


Controllable image captioning is an emerging multimodal topic that aims to describe the image with natural language following human purpose, $\textit{e.g.}$, looking at the specified regions or telling in a particular text style. State-of-the-art methods are trained on annotated pairs of input controls and output captions. However, the scarcity of such well-annotated multimodal data largely limits their usability and scalability for interactive AI systems. Leveraging unimodal instruction-following foundation models is a promising alternative that benefits from broader sources of data. In this paper, we present Caption AnyThing (CAT), a foundation model augmented image captioning framework supporting a wide range of multimodel controls: 1) visual controls, including points, boxes, and trajectories; 2) language controls, such as sentiment, length, language, and factuality. Powered by Segment Anything Model (SAM) and ChatGPT, we unify the visual and language prompts into a modularized framework, enabling the flexible combination between different controls. Extensive case studies demonstrate the user intention alignment capabilities of our framework, shedding light on effective user interaction modeling in vision-language applications. Our code is publicly available at https://github.com/ttengwang/Caption-Anything.
RdSOBA: Rendered Shadow-Object Association Dataset
Jun 30, 2023

Image composition refers to inserting a foreground object into a background image to obtain a composite image. In this work, we focus on generating plausible shadows for the inserted foreground object to make the composite image more realistic. To supplement the existing small-scale dataset DESOBA, we created a large-scale dataset called RdSOBA with 3D rendering techniques. Specifically, we place a group of 3D objects in the 3D scene, and get the images without or with object shadows using controllable rendering techniques. Dataset is available at https://github.com/bcmi/Rendered-Shadow-Generation-Dataset-RdSOBA.
IndoHerb: Indonesia Medicinal Plants Recognition using Transfer Learning and Deep Learning
Aug 03, 2023Herbal plants are nutritious plants that can be used as an alternative to traditional disease healing. In Indonesia there are various types of herbal plants. But with the development of the times, the existence of herbal plants as traditional medicines began to be forgotten so that not everyone could recognize them. Having the ability to identify herbal plants can have many positive impacts. However, there is a problem where identifying plants can take a long time because it requires in-depth knowledge and careful examination of plant criteria. So that the application of computer vision can help identify herbal plants. Previously, research had been conducted on the introduction of herbal plants from Vietnam using several algorithms, but from these research the accuracy was not high enough. Therefore, this study intends to implement transfer learning from the Convolutional Neural Network (CNN) algorithm to classify types of herbal plants from Indonesia. This research was conducted by collecting image data of herbal plants from Indonesia independently through the Google Images search engine. After that, it will go through the data preprocessing, classification using the transfer learning method from CNN, and analysis will be carried out. The CNN transfer learning models used are ResNet34, DenseNet121, and VGG11_bn. Based on the test results of the three models, it was found that DenseNet121 was the model with the highest accuracy, which was 87.4%. In addition, testing was also carried out using the scratch model and obtained an accuracy of 43.53%. The Hyperparameter configuration used in this test is the ExponentialLR scheduler with a gamma value of 0.9; learning rate 0.001; Cross Entropy Loss function; Adam optimizer; and the number of epochs is 50. Indonesia Medicinal Plant Dataset can be accessed at the following link https://github.com/Salmanim20/indo_medicinal_plant