 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ISP meets Deep Learning: A Survey on Deep Learning Methods for Image Signal Processing
May 23, 2023
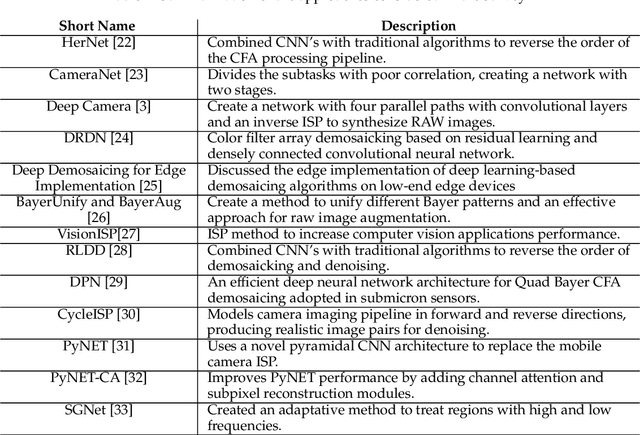

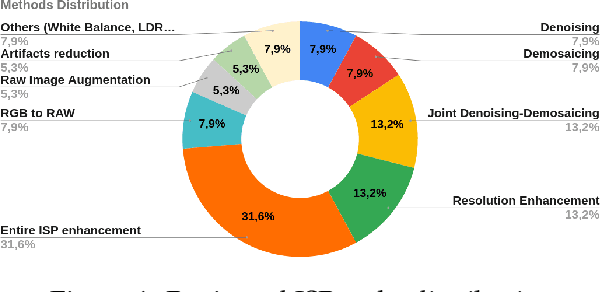
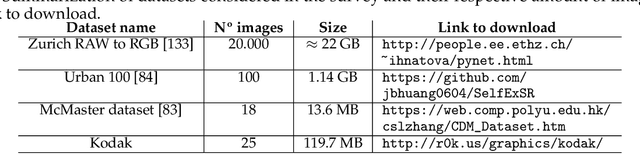
The entire Image Signal Processor (ISP) of a camera relies on several processes to transform the data from the Color Filter Array (CFA) sensor, such as demosaicing, denoising, and enhancement. These processes can be executed either by some hardware or via software. In recent years, Deep Learning has emerged as one solution for some of them or even to replace the entire ISP using a single neural network for the task. In this work, we investigated several recent pieces of research in this area and provide deeper analysis and comparison among them, including results and possible points of improvement for future researchers.
Incremental Image Labeling via Iterative Refinement
Apr 18, 2023Data quality is critical for multimedia tasks, while various types of systematic flaws are found in image benchmark datasets, as discussed in recent work. In particular, the existence of the semantic gap problem leads to a many-to-many mapping between the information extracted from an image and its linguistic description. This unavoidable bias further leads to poor performance on current computer vision tasks. To address this issue, we introduce a Knowledge Representation (KR)-based methodology to provide guidelines driving the labeling process, thereby indirectly introducing intended semantics in ML models. Specifically, an iterative refinement-based annotation method is proposed to optimize data labeling by organizing objects in a classification hierarchy according to their visual properties, ensuring that they are aligned with their linguistic descriptions. Preliminary results verify the effectiveness of the proposed method.
NFI$_2$: Learning Noise-Free Illuminance-Interpolator for Unsupervised Low-Light Image Enhancement
May 17, 2023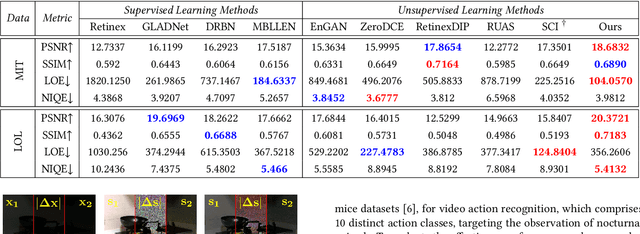
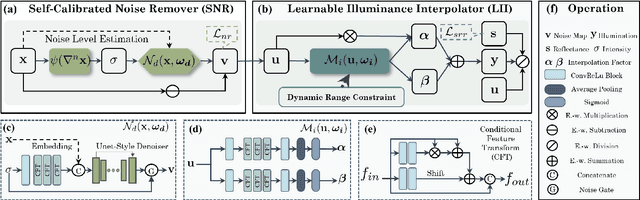
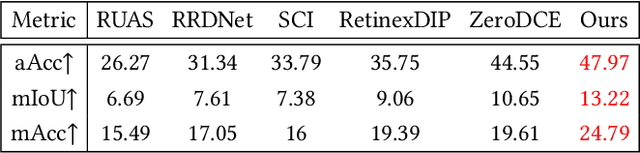

Low-light situations severely restrict the pursuit of aesthetic quality in consumer photography. Although many efforts are devoted to designing heuristics, it is generally mired in a shallow spiral of tedium, such as piling up complex network architectures and empirical strategies. How to delve into the essential physical principles of illumination compensation has been neglected. Following the way of simplifying the complexity, this paper innovatively proposes a simple and efficient Noise-Free Illumination Interpolator (NFI$_2$). According to the constraint principle of illuminance and reflectance within a limited dynamic range, as a prior knowledge in the recovery process, we construct a learnable illuminance interpolator and thereby compensating for non-uniform lighting. With the intention of adapting denoising without annotated data, we design a self-calibrated denoiser with the intrinsic image properties to acquire noise-free low-light images. Starting from the properties of natural image manifolds, a self-regularized recovery loss is introduced as a way to encourage more natural and realistic reflectance map. The model architecture and training losses, guided by prior knowledge, complement and benefit each other, forming a powerful unsupervised leaning framework. Comprehensive experiments demonstrate that the proposed algorithm produces competitive qualitative and quantitative results while maintaining favorable generalization capability in unknown real-world scenarios.
Meta-Learning Enabled Score-Based Generative Model for 1.5T-Like Image Reconstruction from 0.5T MRI
May 04, 2023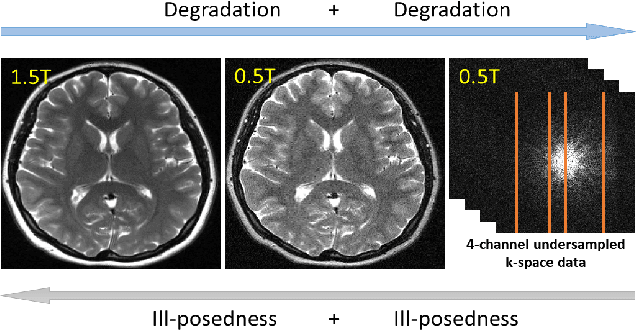
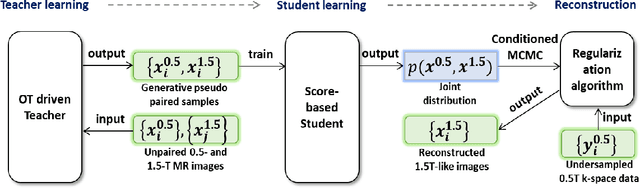
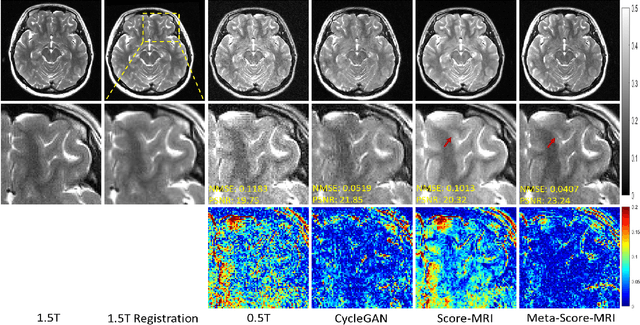
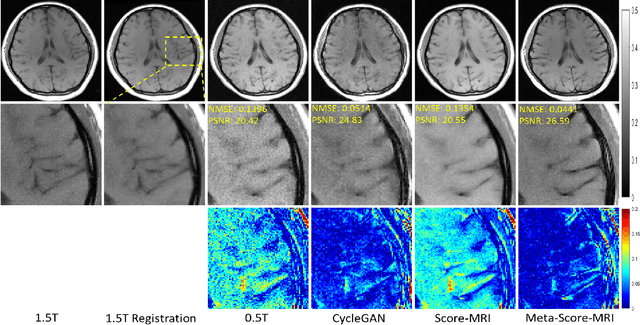
Magnetic resonance imaging (MRI) is known to have reduced signal-to-noise ratios (SNR) at lower field strengths, leading to signal degradation when producing a low-field MRI image from a high-field one. Therefore, reconstructing a high-field-like image from a low-field MRI is a complex problem due to the ill-posed nature of the task. Additionally, obtaining paired low-field and high-field MR images is often not practical. We theoretically uncovered that the combination of these challenges renders conventional deep learning methods that directly learn the mapping from a low-field MR image to a high-field MR image unsuitable. To overcome these challenges, we introduce a novel meta-learning approach that employs a teacher-student mechanism. Firstly, an optimal-transport-driven teacher learns the degradation process from high-field to low-field MR images and generates pseudo-paired high-field and low-field MRI images. Then, a score-based student solves the inverse problem of reconstructing a high-field-like MR image from a low-field MRI within the framework of iterative regularization, by learning the joint distribution of pseudo-paired images to act as a regularizer. Experimental results on real low-field MRI data demonstrate that our proposed method outperforms state-of-the-art unpaired learning methods.
Internal-External Boundary Attention Fusion for Glass Surface Segmentation
Jul 01, 2023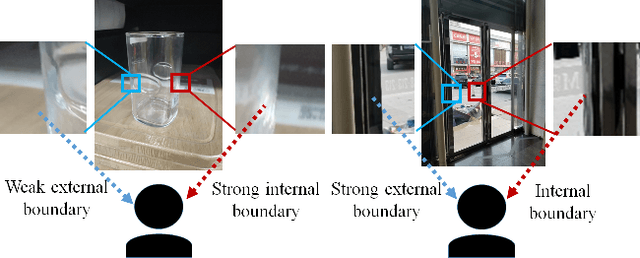
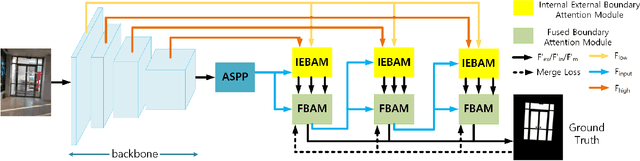
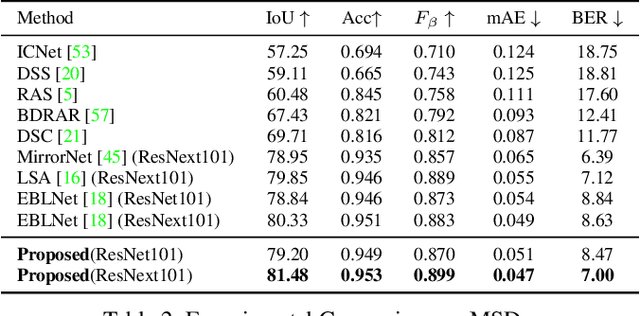
Glass surfaces of transparent objects and mirrors are not able to be uniquely and explicitly characterized by their visual appearances because they contain the visual appearance of other reflected or transmitted surfaces as well. Detecting glass regions from a single-color image is a challenging task. Recent deep-learning approaches have paid attention to the description of glass surface boundary where the transition of visual appearances between glass and non-glass surfaces are observed. In this work, we analytically investigate how glass surface boundary helps to characterize glass objects. Inspired by prior semantic segmentation approaches with challenging image types such as X-ray or CT scans, we propose separated internal-external boundary attention modules that individually learn and selectively integrate visual characteristics of the inside and outside region of glass surface from a single color image. Our proposed method is evaluated on six public benchmarks comparing with state-of-the-art methods showing promising results.
Generative Adversarial Networks for Dental Patient Identity Protection in Orthodontic Educational Imaging
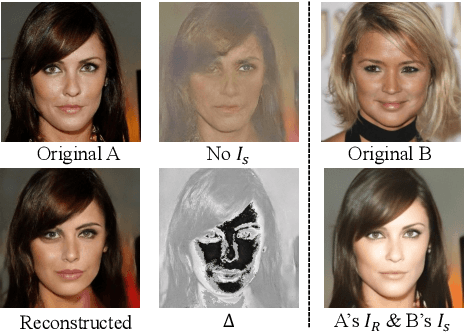
Jul 05, 2023Objectives: This research introduces a novel area-preserving Generative Adversarial Networks (GAN) inversion technique for effectively de-identifying dental patient images. This innovative method addresses privacy concerns while preserving key dental features, thereby generating valuable resources for dental education and research. Methods: We enhanced the existing GAN Inversion methodology to maximize the preservation of dental characteristics within the synthesized images. A comprehensive technical framework incorporating several deep learning models was developed to provide end-to-end development guidance and practical application for image de-identification. Results: Our approach was assessed with varied facial pictures, extensively used for diagnosing skeletal asymmetry and facial anomalies. Results demonstrated our model's ability to adapt the context from one image to another, maintaining compatibility, while preserving dental features essential for oral diagnosis and dental education. A panel of five clinicians conducted an evaluation on a set of original and GAN-processed images. The generated images achieved effective de-identification, maintaining the realism of important dental features and were deemed useful for dental diagnostics and education. Clinical Significance: Our GAN model and the encompassing framework can streamline the de-identification process of dental patient images, enhancing efficiency in dental education. This method improves students' diagnostic capabilities by offering more exposure to orthodontic malocclusions. Furthermore, it facilitates the creation of de-identified datasets for broader 2D image research at major research institutions.
Machine Perception-Driven Image Compression: A Layered Generative Approach
Apr 14, 2023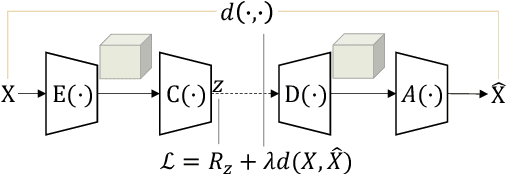
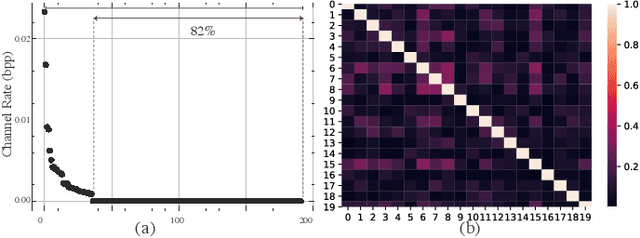
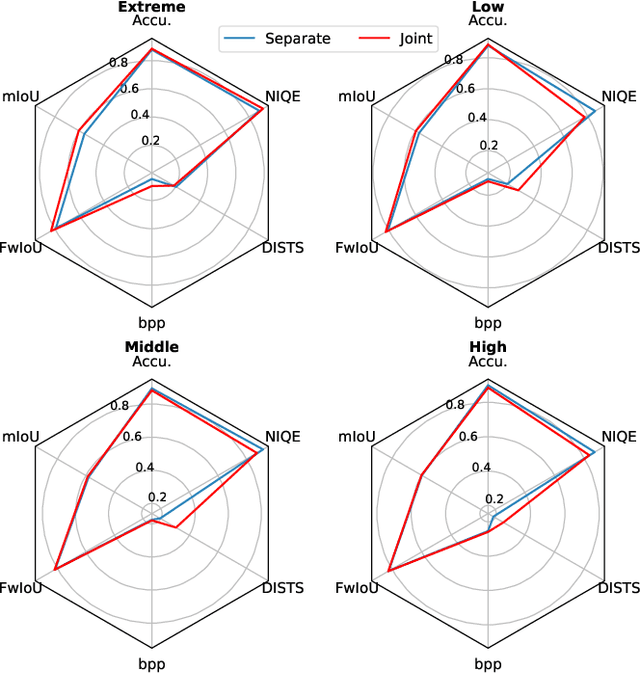
In this age of information, images are a critical medium for storing and transmitting information. With the rapid growth of image data amount, visual compression and visual data perception are two important research topics attracting a lot attention. However, those two topics are rarely discussed together and follow separate research path. Due to the compact compressed domain representation offered by learning-based image compression methods, there exists possibility to have one stream targeting both efficient data storage and compression, and machine perception tasks. In this paper, we propose a layered generative image compression model achieving high human vision-oriented image reconstructed quality, even at extreme compression ratios. To obtain analysis efficiency and flexibility, a task-agnostic learning-based compression model is proposed, which effectively supports various compressed domain-based analytical tasks while reserves outstanding reconstructed perceptual quality, compared with traditional and learning-based codecs. In addition, joint optimization schedule is adopted to acquire best balance point among compression ratio, reconstructed image quality, and downstream perception performance. Experimental results verify that our proposed compressed domain-based multi-task analysis method can achieve comparable analysis results against the RGB image-based methods with up to 99.6% bit rate saving (i.e., compared with taking original RGB image as the analysis model input). The practical ability of our model is further justified from model size and information fidelity aspects.
Towards Consistent Video Editing with Text-to-Image Diffusion Models
May 27, 2023
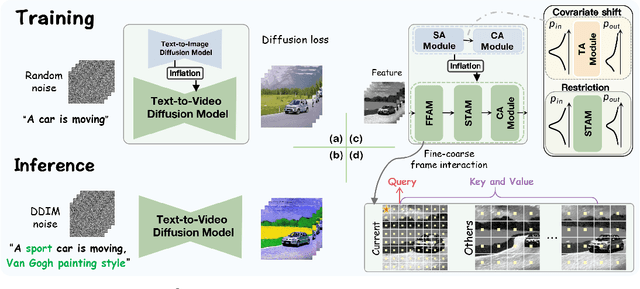


Existing works have advanced Text-to-Image (TTI) diffusion models for video editing in a one-shot learning manner. Despite their low requirements of data and computation, these methods might produce results of unsatisfied consistency with text prompt as well as temporal sequence, limiting their applications in the real world. In this paper, we propose to address the above issues with a novel EI$^2$ model towards \textbf{E}nhancing v\textbf{I}deo \textbf{E}diting cons\textbf{I}stency of TTI-based frameworks. Specifically, we analyze and find that the inconsistent problem is caused by newly added modules into TTI models for learning temporal information. These modules lead to covariate shift in the feature space, which harms the editing capability. Thus, we design EI$^2$ to tackle the above drawbacks with two classical modules: Shift-restricted Temporal Attention Module (STAM) and Fine-coarse Frame Attention Module (FFAM). First, through theoretical analysis, we demonstrate that covariate shift is highly related to Layer Normalization, thus STAM employs a \textit{Instance Centering} layer replacing it to preserve the distribution of temporal features. In addition, {STAM} employs an attention layer with normalized mapping to transform temporal features while constraining the variance shift. As the second part, we incorporate {STAM} with a novel {FFAM}, which efficiently leverages fine-coarse spatial information of overall frames to further enhance temporal consistency. Extensive experiments demonstrate the superiority of the proposed EI$^2$ model for text-driven video editing.
Patch-CNN: Training data-efficient deep learning for high-fidelity diffusion tensor estimation from minimal diffusion protocols
Jul 03, 2023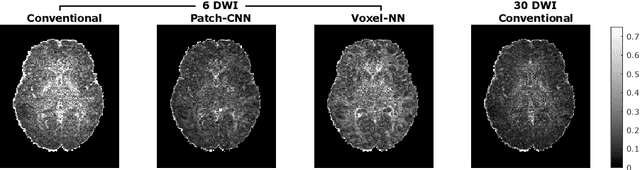
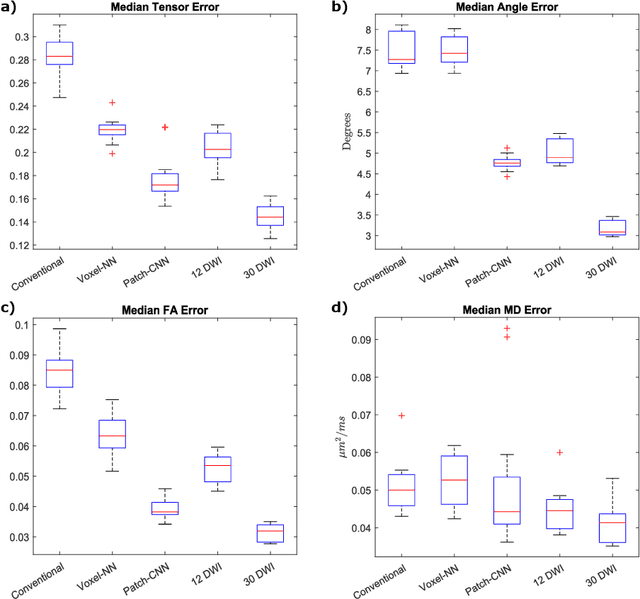
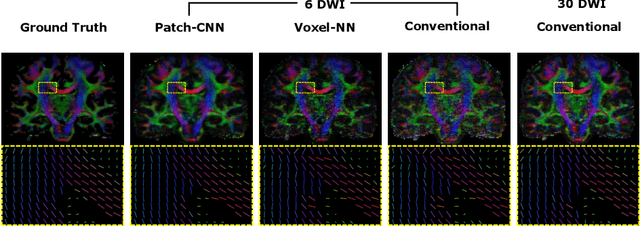
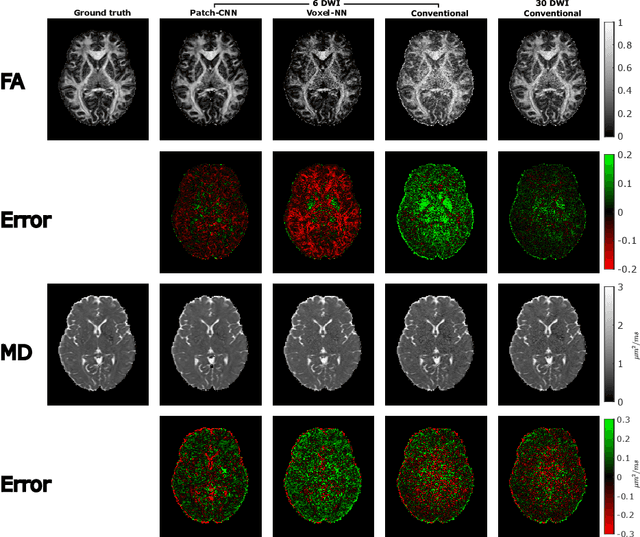
We propose a new method, Patch-CNN, for diffusion tensor (DT) estimation from only six-direction diffusion weighted images (DWI). Deep learning-based methods have been recently proposed for dMRI parameter estimation, using either voxel-wise fully-connected neural networks (FCN) or image-wise convolutional neural networks (CNN). In the acute clinical context -- where pressure of time limits the number of imaged directions to a minimum -- existing approaches either require an infeasible number of training images volumes (image-wise CNNs), or do not estimate the fibre orientations (voxel-wise FCNs) required for tractogram estimation. To overcome these limitations, we propose Patch-CNN, a neural network with a minimal (non-voxel-wise) convolutional kernel (3$\times$3$\times$3). Compared with voxel-wise FCNs, this has the advantage of allowing the network to leverage local anatomical information. Compared with image-wise CNNs, the minimal kernel vastly reduces training data demand. Evaluated against both conventional model fitting and a voxel-wise FCN, Patch-CNN, trained with a single subject is shown to improve the estimation of both scalar dMRI parameters and fibre orientation from six-direction DWIs. The improved fibre orientation estimation is shown to produce improved tractogram.
Diffusion Explainer: Visual Explanation for Text-to-image Stable Diffusion
May 04, 2023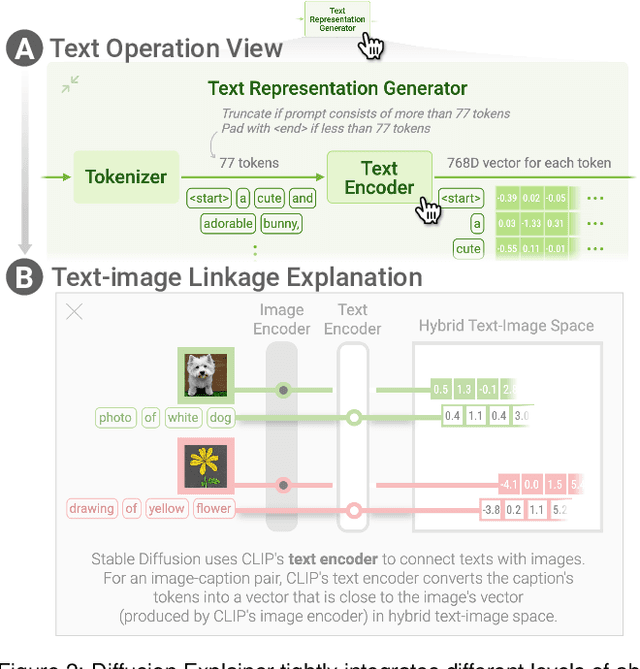
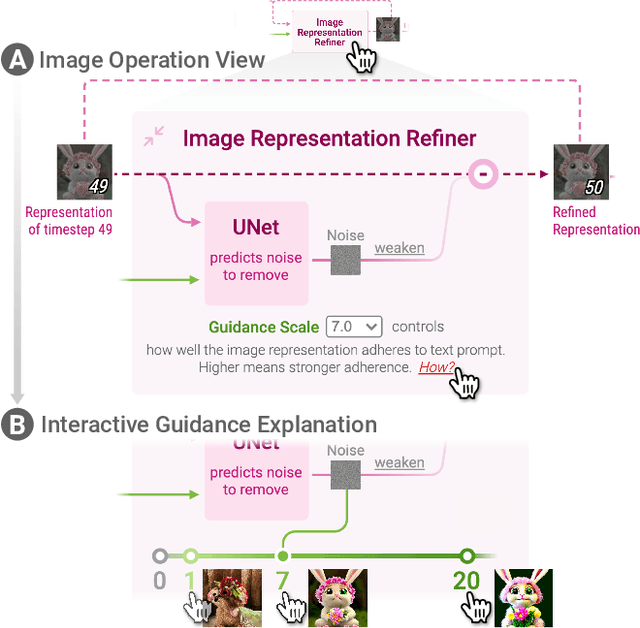
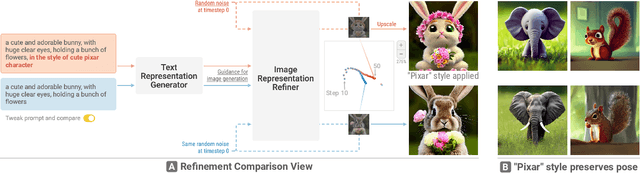
Diffusion-based generative models' impressive ability to create convincing images has captured global attention. However, their complex internal structures and operations often make them difficult for non-experts to understand. We present Diffusion Explainer, the first interactive visualization tool that explains how Stable Diffusion transforms text prompts into images. Diffusion Explainer tightly integrates a visual overview of Stable Diffusion's complex components with detailed explanations of their underlying operations, enabling users to fluidly transition between multiple levels of abstraction through animations and interactive elements. By comparing the evolutions of image representations guided by two related text prompts over refinement timesteps, users can discover the impact of prompts on image generation. Diffusion Explainer runs locally in users' web browsers without the need for installation or specialized hardware, broadening the public's education access to modern AI techniques. Our open-sourced tool is available at: https://poloclub.github.io/diffusion-explainer/.