 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ProgDTD: Progressive Learned Image Compression with Double-Tail-Drop Training
May 03, 2023
Progressive compression allows images to start loading as low-resolution versions, becoming clearer as more data is received. This increases user experience when, for example, network connections are slow. Today, most approaches for image compression, both classical and learned ones, are designed to be non-progressive. This paper introduces ProgDTD, a training method that transforms learned, non-progressive image compression approaches into progressive ones. The design of ProgDTD is based on the observation that the information stored within the bottleneck of a compression model commonly varies in importance. To create a progressive compression model, ProgDTD modifies the training steps to enforce the model to store the data in the bottleneck sorted by priority. We achieve progressive compression by transmitting the data in order of its sorted index. ProgDTD is designed for CNN-based learned image compression models, does not need additional parameters, and has a customizable range of progressiveness. For evaluation, we apply ProgDTDto the hyperprior model, one of the most common structures in learned image compression. Our experimental results show that ProgDTD performs comparably to its non-progressive counterparts and other state-of-the-art progressive models in terms of MS-SSIM and accuracy.
Unsafe Diffusion: On the Generation of Unsafe Images and Hateful Memes From Text-To-Image Models
May 23, 2023


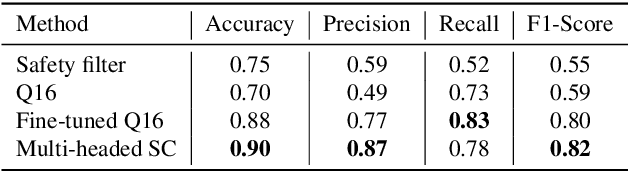
State-of-the-art Text-to-Image models like Stable Diffusion and DALLE$\cdot$2 are revolutionizing how people generate visual content. At the same time, society has serious concerns about how adversaries can exploit such models to generate unsafe images. In this work, we focus on demystifying the generation of unsafe images and hateful memes from Text-to-Image models. We first construct a typology of unsafe images consisting of five categories (sexually explicit, violent, disturbing, hateful, and political). Then, we assess the proportion of unsafe images generated by four advanced Text-to-Image models using four prompt datasets. We find that these models can generate a substantial percentage of unsafe images; across four models and four prompt datasets, 14.56% of all generated images are unsafe. When comparing the four models, we find different risk levels, with Stable Diffusion being the most prone to generating unsafe content (18.92% of all generated images are unsafe). Given Stable Diffusion's tendency to generate more unsafe content, we evaluate its potential to generate hateful meme variants if exploited by an adversary to attack a specific individual or community. We employ three image editing methods, DreamBooth, Textual Inversion, and SDEdit, which are supported by Stable Diffusion. Our evaluation result shows that 24% of the generated images using DreamBooth are hateful meme variants that present the features of the original hateful meme and the target individual/community; these generated images are comparable to hateful meme variants collected from the real world. Overall, our results demonstrate that the danger of large-scale generation of unsafe images is imminent. We discuss several mitigating measures, such as curating training data, regulating prompts, and implementing safety filters, and encourage better safeguard tools to be developed to prevent unsafe generation.
Contextual Prompt Learning for Vision-Language Understanding
Jul 03, 2023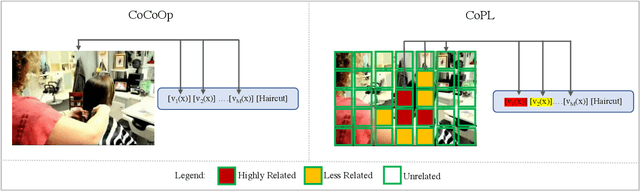
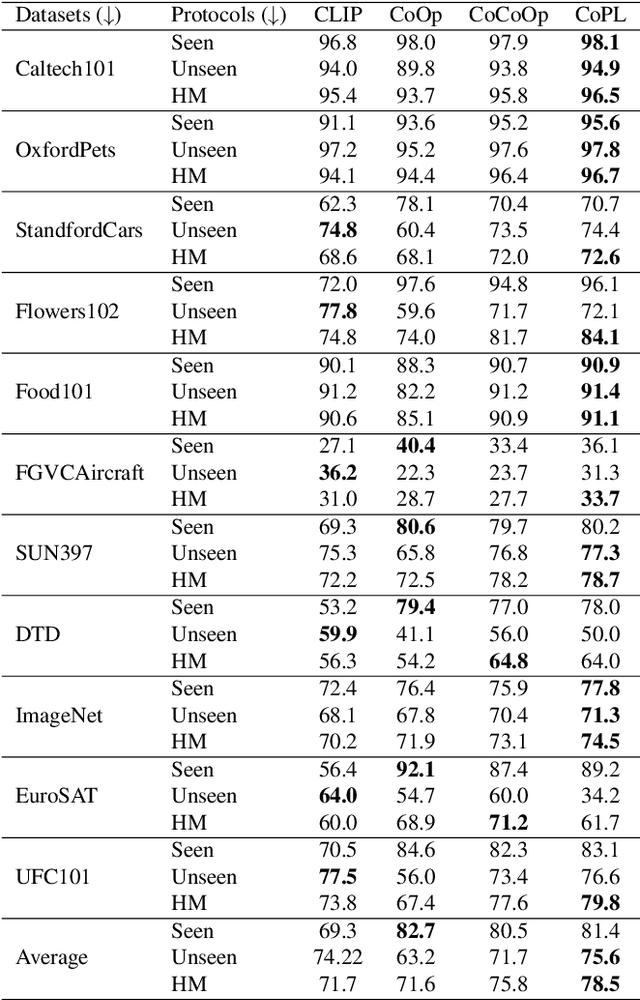
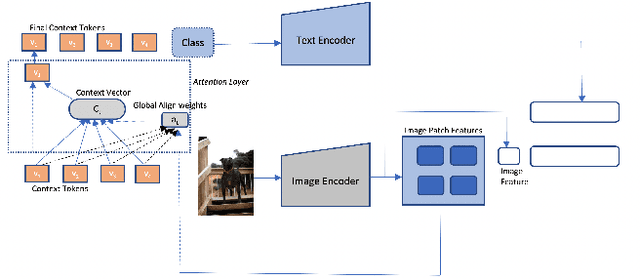

Recent advances in multimodal learning has resulted in powerful vision-language models, whose representations are generalizable across a variety of downstream tasks. Recently, their generalizability has been further extended by incorporating trainable prompts, borrowed from the natural language processing literature. While such prompt learning techniques have shown impressive results, we identify that these prompts are trained based on global image features which limits itself in two aspects: First, by using global features, these prompts could be focusing less on the discriminative foreground image, resulting in poor generalization to various out-of-distribution test cases. Second, existing work weights all prompts equally whereas our intuition is that these prompts are more specific to the type of the image. We address these issues with as part of our proposed Contextual Prompt Learning (CoPL) framework, capable of aligning the prompts to the localized features of the image. Our key innovations over earlier works include using local image features as part of the prompt learning process, and more crucially, learning to weight these prompts based on local features that are appropriate for the task at hand. This gives us dynamic prompts that are both aligned to local image features as well as aware of local contextual relationships. Our extensive set of experiments on a variety of standard and few-shot datasets show that our method produces substantially improved performance when compared to the current state of the art methods. We also demonstrate both few-shot and out-of-distribution performance to establish the utility of learning dynamic prompts that are aligned to local image features.
MMSD2.0: Towards a Reliable Multi-modal Sarcasm Detection System
Jul 14, 2023

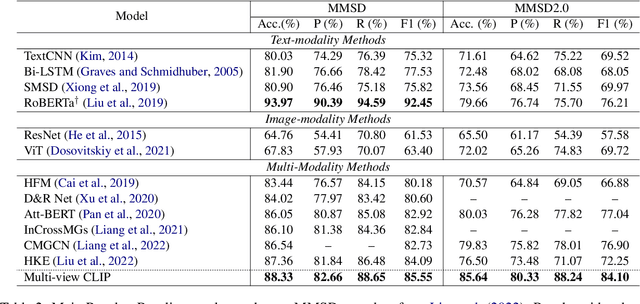
Multi-modal sarcasm detection has attracted much recent attention. Nevertheless, the existing benchmark (MMSD) has some shortcomings that hinder the development of reliable multi-modal sarcasm detection system: (1) There are some spurious cues in MMSD, leading to the model bias learning; (2) The negative samples in MMSD are not always reasonable. To solve the aforementioned issues, we introduce MMSD2.0, a correction dataset that fixes the shortcomings of MMSD, by removing the spurious cues and re-annotating the unreasonable samples. Meanwhile, we present a novel framework called multi-view CLIP that is capable of leveraging multi-grained cues from multiple perspectives (i.e., text, image, and text-image interaction view) for multi-modal sarcasm detection. Extensive experiments show that MMSD2.0 is a valuable benchmark for building reliable multi-modal sarcasm detection systems and multi-view CLIP can significantly outperform the previous best baselines.
Reading Radiology Imaging Like The Radiologist
Jul 13, 2023Automated radiology report generation aims to generate radiology reports that contain rich, fine-grained descriptions of radiology imaging. Compared with image captioning in the natural image domain, medical images are very similar to each other, with only minor differences in the occurrence of diseases. Given the importance of these minor differences in the radiology report, it is crucial to encourage the model to focus more on the subtle regions of disease occurrence. Secondly, the problem of visual and textual data biases is serious. Not only do normal cases make up the majority of the dataset, but sentences describing areas with pathological changes also constitute only a small part of the paragraph. Lastly, generating medical image reports involves the challenge of long text generation, which requires more expertise and empirical training in medical knowledge. As a result, the difficulty of generating such reports is increased. To address these challenges, we propose a disease-oriented retrieval framework that utilizes similar reports as prior knowledge references. We design a factual consistency captioning generator to generate more accurate and factually consistent disease descriptions. Our framework can find most similar reports for a given disease from the CXR database by retrieving a disease-oriented mask consisting of the position and morphological characteristics. By referencing the disease-oriented similar report and the visual features, the factual consistency model can generate a more accurate radiology report.
Fusion-S2iGan: An Efficient and Effective Single-Stage Framework for Speech-to-Image Generation
May 17, 2023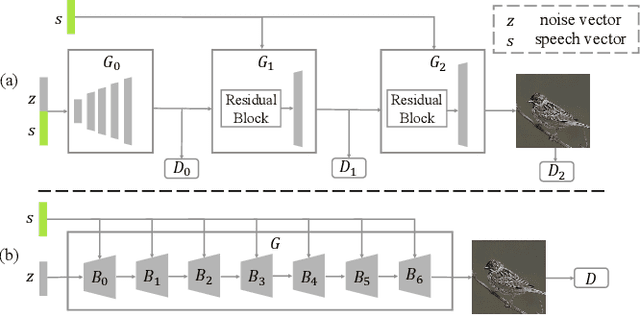
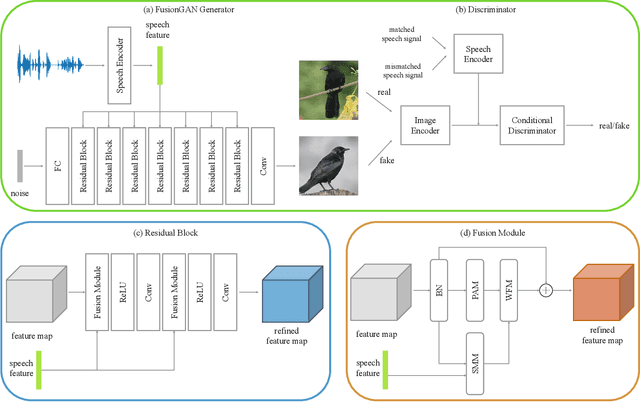
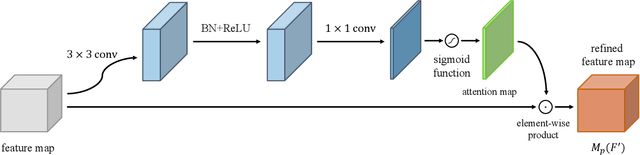
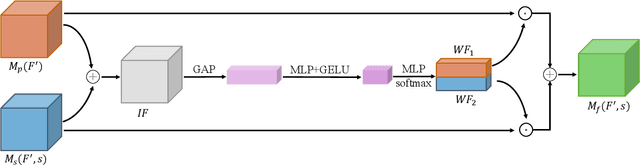
The goal of a speech-to-image transform is to produce a photo-realistic picture directly from a speech signal. Recently, various studies have focused on this task and have achieved promising performance. However, current speech-to-image approaches are based on a stacked modular framework that suffers from three vital issues: 1) Training separate networks is time-consuming as well as inefficient and the convergence of the final generative model strongly depends on the previous generators; 2) The quality of precursor images is ignored by this architecture; 3) Multiple discriminator networks are required to be trained. To this end, we propose an efficient and effective single-stage framework called Fusion-S2iGan to yield perceptually plausible and semantically consistent image samples on the basis of given spoken descriptions. Fusion-S2iGan introduces a visual+speech fusion module (VSFM), constructed with a pixel-attention module (PAM), a speech-modulation module (SMM) and a weighted-fusion module (WFM), to inject the speech embedding from a speech encoder into the generator while improving the quality of synthesized pictures. Fusion-S2iGan spreads the bimodal information over all layers of the generator network to reinforce the visual feature maps at various hierarchical levels in the architecture. We conduct a series of experiments on four benchmark data sets, i.e., CUB birds, Oxford-102, Flickr8k and Places-subset. The experimental results demonstrate the superiority of the presented Fusion-S2iGan compared to the state-of-the-art models with a multi-stage architecture and a performance level that is close to traditional text-to-image approaches.
DreamDiffusion: Generating High-Quality Images from Brain EEG Signals
Jun 30, 2023
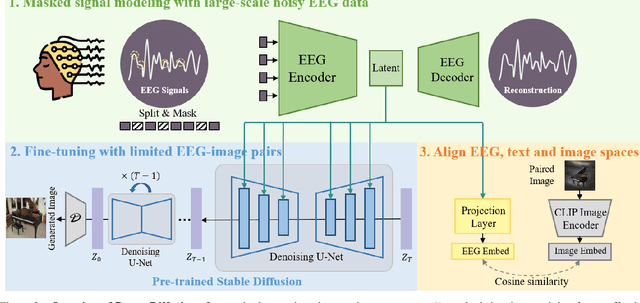
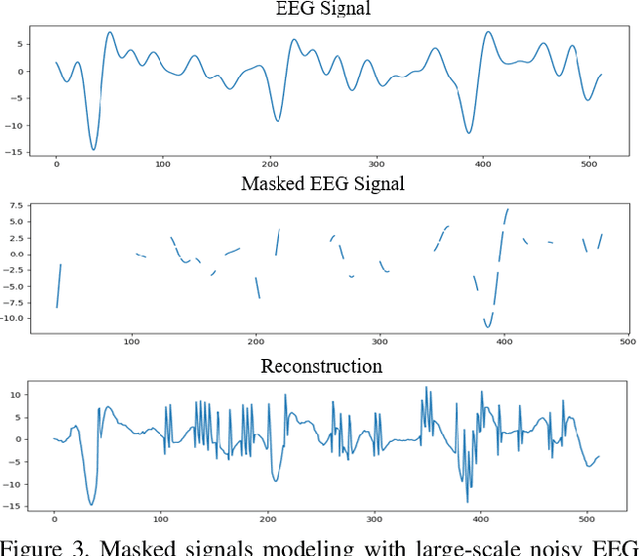

This paper introduces DreamDiffusion, a novel method for generating high-quality images directly from brain electroencephalogram (EEG) signals, without the need to translate thoughts into text. DreamDiffusion leverages pre-trained text-to-image models and employs temporal masked signal modeling to pre-train the EEG encoder for effective and robust EEG representations. Additionally, the method further leverages the CLIP image encoder to provide extra supervision to better align EEG, text, and image embeddings with limited EEG-image pairs. Overall, the proposed method overcomes the challenges of using EEG signals for image generation, such as noise, limited information, and individual differences, and achieves promising results. Quantitative and qualitative results demonstrate the effectiveness of the proposed method as a significant step towards portable and low-cost ``thoughts-to-image'', with potential applications in neuroscience and computer vision. The code is available here \url{https://github.com/bbaaii/DreamDiffusion}.
Self-Supervised Visual Acoustic Matching
Jul 27, 2023
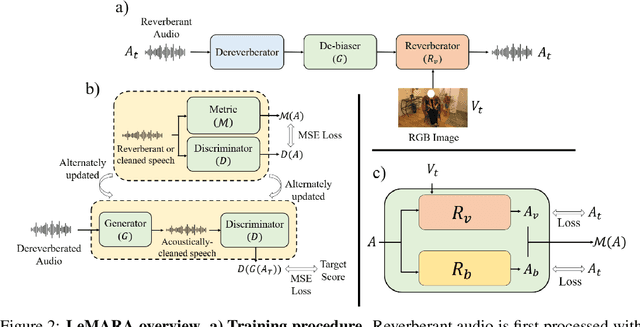


Acoustic matching aims to re-synthesize an audio clip to sound as if it were recorded in a target acoustic environment. Existing methods assume access to paired training data, where the audio is observed in both source and target environments, but this limits the diversity of training data or requires the use of simulated data or heuristics to create paired samples. We propose a self-supervised approach to visual acoustic matching where training samples include only the target scene image and audio -- without acoustically mismatched source audio for reference. Our approach jointly learns to disentangle room acoustics and re-synthesize audio into the target environment, via a conditional GAN framework and a novel metric that quantifies the level of residual acoustic information in the de-biased audio. Training with either in-the-wild web data or simulated data, we demonstrate it outperforms the state-of-the-art on multiple challenging datasets and a wide variety of real-world audio and environments.
INCLG: Inpainting for Non-Cleft Lip Generation with a Multi-Task Image Processing Network
May 17, 2023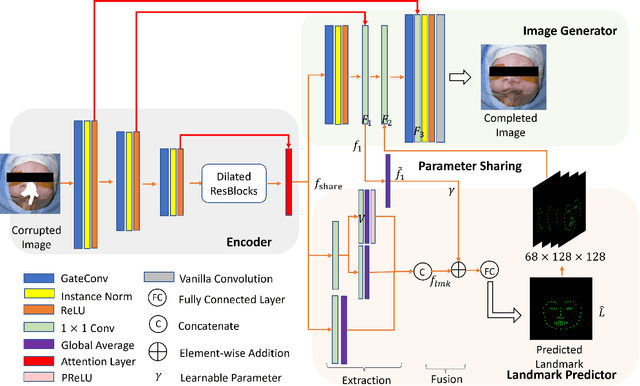
We present a software that predicts non-cleft facial images for patients with cleft lip, thereby facilitating the understanding, awareness and discussion of cleft lip surgeries. To protect patients privacy, we design a software framework using image inpainting, which does not require cleft lip images for training, thereby mitigating the risk of model leakage. We implement a novel multi-task architecture that predicts both the non-cleft facial image and facial landmarks, resulting in better performance as evaluated by surgeons. The software is implemented with PyTorch and is usable with consumer-level color images with a fast prediction speed, enabling effective deployment.
Treasure in Distribution: A Domain Randomization based Multi-Source Domain Generalization for 2D Medical Image Segmentation
May 31, 2023

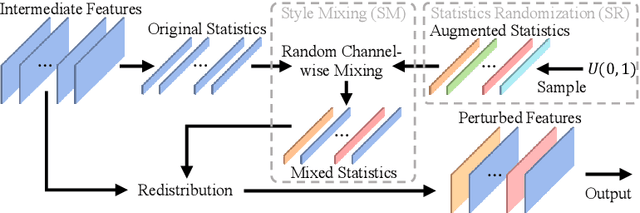
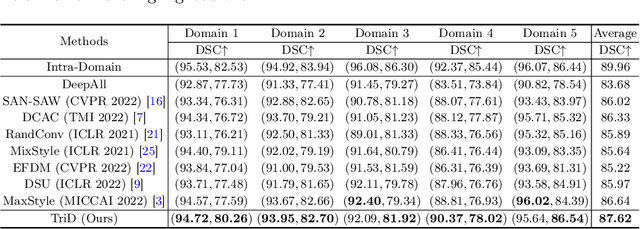
Although recent years have witnessed the great success of convolutional neural networks (CNNs) in medical image segmentation, the domain shift issue caused by the highly variable image quality of medical images hinders the deployment of CNNs in real-world clinical applications. Domain generalization (DG) methods aim to address this issue by training a robust model on the source domain, which has a strong generalization ability. Previously, many DG methods based on feature-space domain randomization have been proposed, which, however, suffer from the limited and unordered search space of feature styles. In this paper, we propose a multi-source DG method called Treasure in Distribution (TriD), which constructs an unprecedented search space to obtain the model with strong robustness by randomly sampling from a uniform distribution. To learn the domain-invariant representations explicitly, we further devise a style-mixing strategy in our TriD, which mixes the feature styles by randomly mixing the augmented and original statistics along the channel wise and can be extended to other DG methods. Extensive experiments on two medical segmentation tasks with different modalities demonstrate that our TriD achieves superior generalization performance on unseen target-domain data. Code is available at https://github.com/Chen-Ziyang/TriD.