 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Why do CNNs excel at feature extraction? A mathematical explanation
Jul 03, 2023

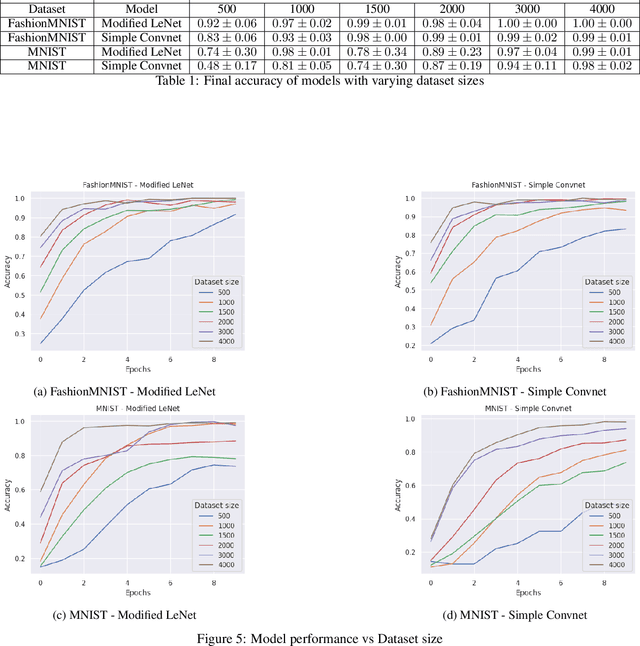

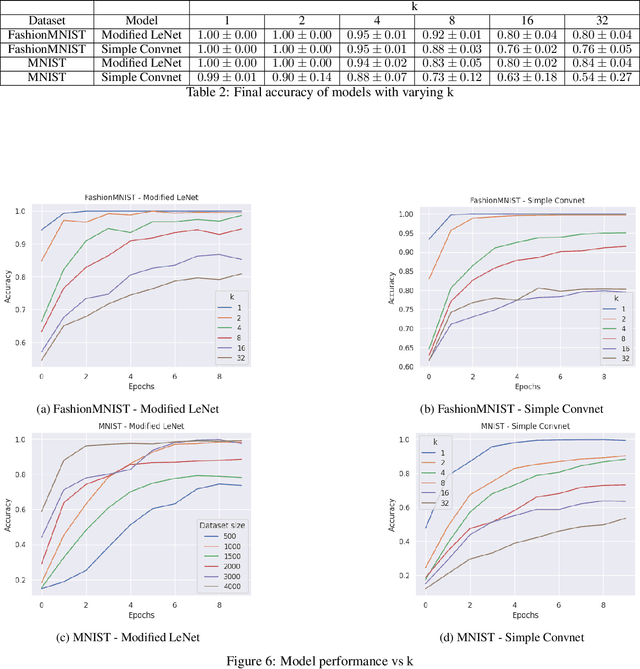
Over the past decade deep learning has revolutionized the field of computer vision, with convolutional neural network models proving to be very effective for image classification benchmarks. However, a fundamental theoretical questions remain answered: why can they solve discrete image classification tasks that involve feature extraction? We address this question in this paper by introducing a novel mathematical model for image classification, based on feature extraction, that can be used to generate images resembling real-world datasets. We show that convolutional neural network classifiers can solve these image classification tasks with zero error. In our proof, we construct piecewise linear functions that detect the presence of features, and show that they can be realized by a convolutional network.
Towards General Low-Light Raw Noise Synthesis and Modeling
Jul 31, 2023
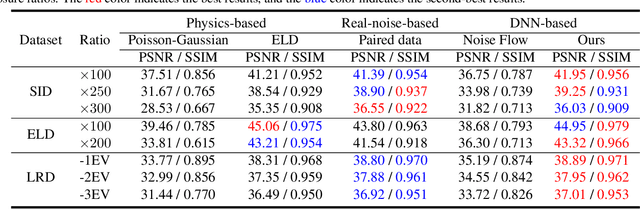
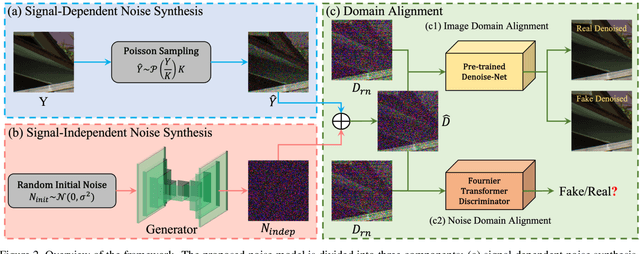
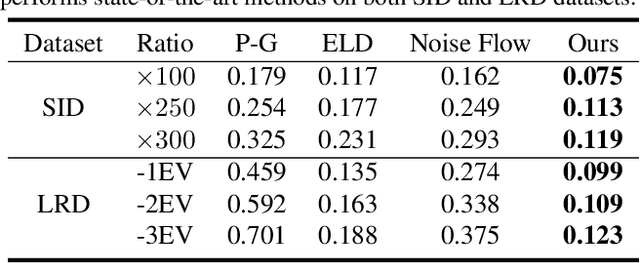
Modeling and synthesizing low-light raw noise is a fundamental problem for computational photography and image processing applications. Although most recent works have adopted physics-based models to synthesize noise, the signal-independent noise in low-light conditions is far more complicated and varies dramatically across camera sensors, which is beyond the description of these models. To address this issue, we introduce a new perspective to synthesize the signal-independent noise by a generative model. Specifically, we synthesize the signal-dependent and signal-independent noise in a physics- and learning-based manner, respectively. In this way, our method can be considered as a general model, that is, it can simultaneously learn different noise characteristics for different ISO levels and generalize to various sensors. Subsequently, we present an effective multi-scale discriminator termed Fourier transformer discriminator (FTD) to distinguish the noise distribution accurately. Additionally, we collect a new low-light raw denoising (LRD) dataset for training and benchmarking. Qualitative validation shows that the noise generated by our proposed noise model can be highly similar to the real noise in terms of distribution. Furthermore, extensive denoising experiments demonstrate that our method performs favorably against state-of-the-art methods on different sensors. The source code and dataset can be found at ~\url{https://github.com/fengzhang427/LRD}.
MetaCAM: Ensemble-Based Class Activation Map
Jul 31, 2023The need for clear, trustworthy explanations of deep learning model predictions is essential for high-criticality fields, such as medicine and biometric identification. Class Activation Maps (CAMs) are an increasingly popular category of visual explanation methods for Convolutional Neural Networks (CNNs). However, the performance of individual CAMs depends largely on experimental parameters such as the selected image, target class, and model. Here, we propose MetaCAM, an ensemble-based method for combining multiple existing CAM methods based on the consensus of the top-k% most highly activated pixels across component CAMs. We perform experiments to quantifiably determine the optimal combination of 11 CAMs for a given MetaCAM experiment. A new method denoted Cumulative Residual Effect (CRE) is proposed to summarize large-scale ensemble-based experiments. We also present adaptive thresholding and demonstrate how it can be applied to individual CAMs to improve their performance, measured using pixel perturbation method Remove and Debias (ROAD). Lastly, we show that MetaCAM outperforms existing CAMs and refines the most salient regions of images used for model predictions. In a specific example, MetaCAM improved ROAD performance to 0.393 compared to 11 individual CAMs with ranges from -0.101-0.172, demonstrating the importance of combining CAMs through an ensembling method and adaptive thresholding.
SAMFlow: Eliminating Any Fragmentation in Optical Flow with Segment Anything Model
Jul 31, 2023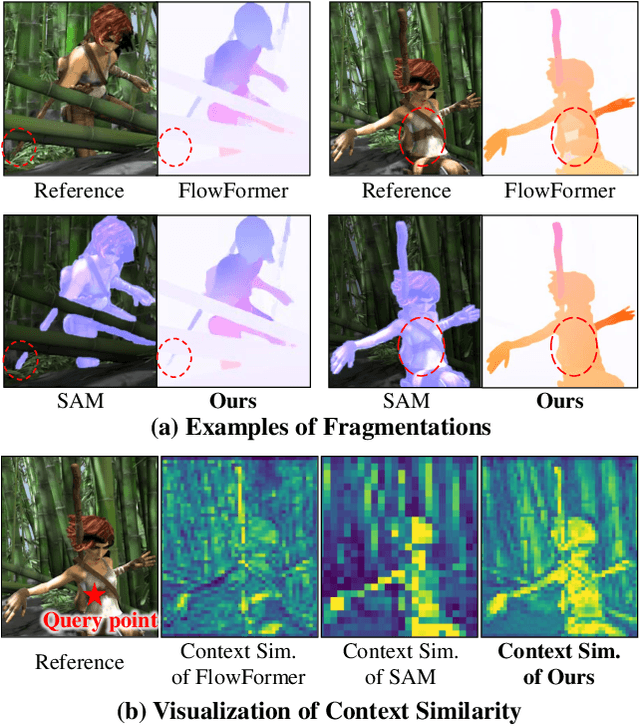
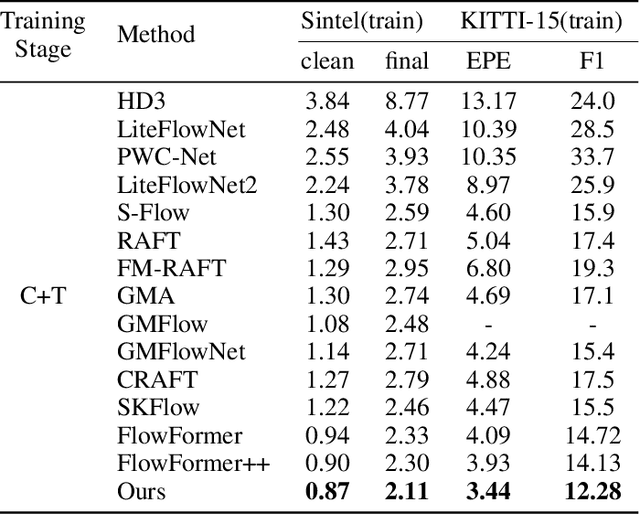

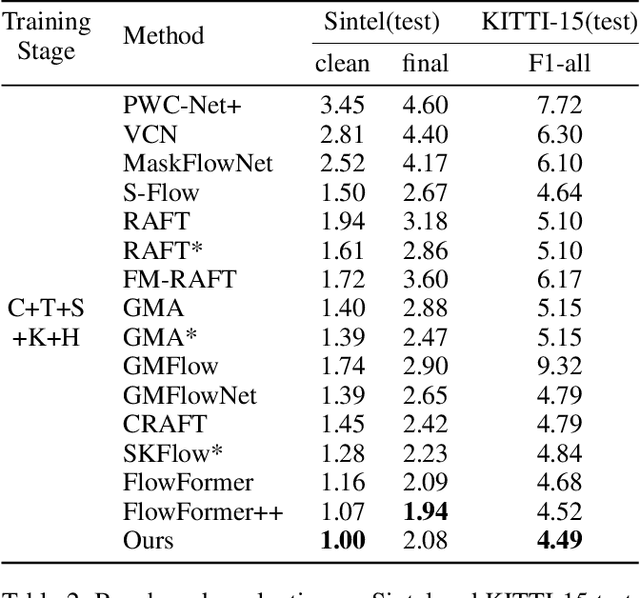
Optical flow estimation aims to find the 2D dense motion field between two frames. Due to the limitation of model structures and training datasets, existing methods often rely too much on local clues and ignore the integrity of objects, resulting in fragmented motion estimation. We notice that the recently famous Segment Anything Model (SAM) demonstrates a strong ability to segment complete objects, which is suitable for solving the fragmentation problem in optical flow estimation. We thus propose a solution to embed the frozen SAM image encoder into FlowFormer to enhance object perception. To address the challenge of in-depth utilizing SAM in non-segmentation tasks like optical flow estimation, we propose an Optical Flow Task-Specific Adaption scheme, including a Context Fusion Module to fuse the SAM encoder with the optical flow context encoder, and a Context Adaption Module to adapt the SAM features for optical flow task with Learned Task-Specific Embedding. Our proposed SAMFlow model reaches 0.86/2.10 clean/final EPE and 3.55/12.32 EPE/F1-all on Sintel and KITTI-15 training set, surpassing Flowformer by 8.5%/9.9% and 13.2%/16.3%. Furthermore, our model achieves state-of-the-art performance on the Sintel and KITTI-15 benchmarks, ranking #1 among all two-frame methods on Sintel clean pass.
Learning to Model the World with Language
Jul 31, 2023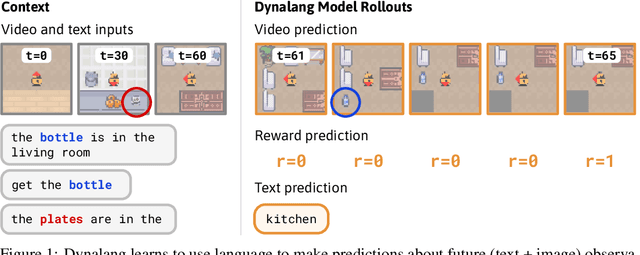
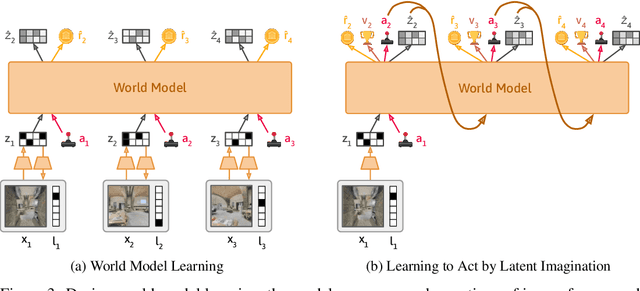
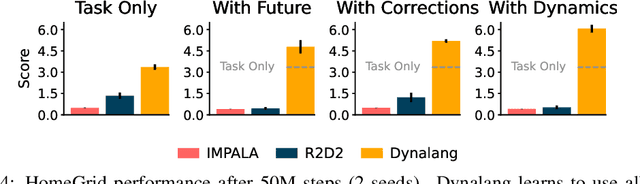
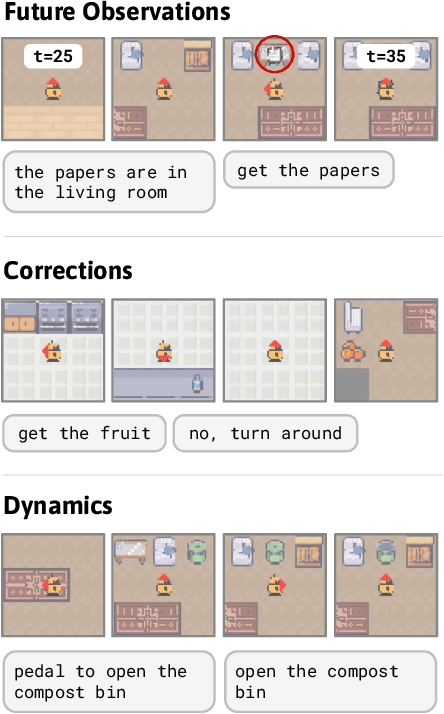
To interact with humans in the world, agents need to understand the diverse types of language that people use, relate them to the visual world, and act based on them. While current agents learn to execute simple language instructions from task rewards, we aim to build agents that leverage diverse language that conveys general knowledge, describes the state of the world, provides interactive feedback, and more. Our key idea is that language helps agents predict the future: what will be observed, how the world will behave, and which situations will be rewarded. This perspective unifies language understanding with future prediction as a powerful self-supervised learning objective. We present Dynalang, an agent that learns a multimodal world model that predicts future text and image representations and learns to act from imagined model rollouts. Unlike traditional agents that use language only to predict actions, Dynalang acquires rich language understanding by using past language also to predict future language, video, and rewards. In addition to learning from online interaction in an environment, Dynalang can be pretrained on datasets of text, video, or both without actions or rewards. From using language hints in grid worlds to navigating photorealistic scans of homes, Dynalang utilizes diverse types of language to improve task performance, including environment descriptions, game rules, and instructions.
Class-Guided Image-to-Image Diffusion: Cell Painting from Brightfield Images with Class Labels
Mar 29, 2023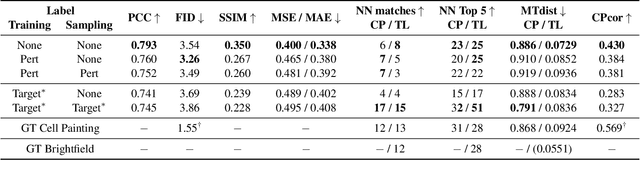
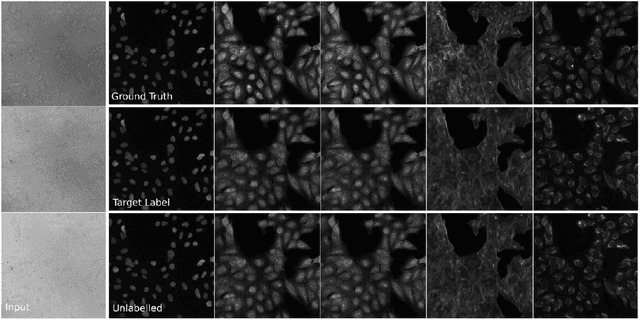
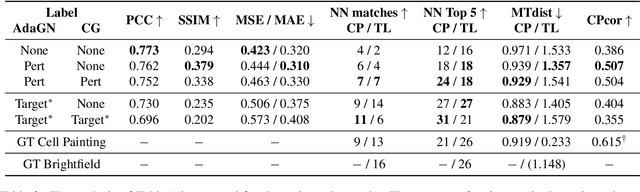
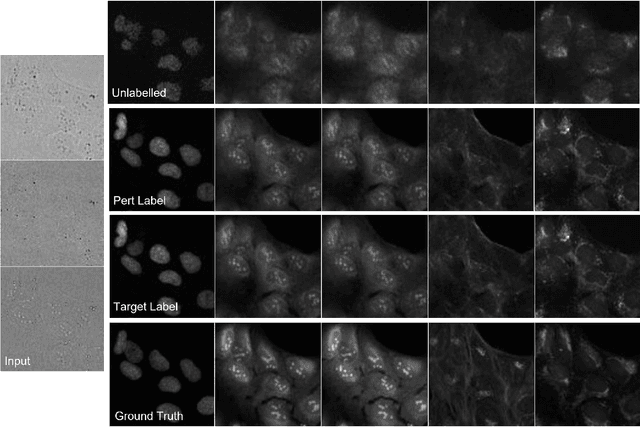
Image-to-image reconstruction problems with free or inexpensive metadata in the form of class labels appear often in biological and medical image domains. Existing text-guided or style-transfer image-to-image approaches do not translate to datasets where additional information is provided as discrete classes. We introduce and implement a model which combines image-to-image and class-guided denoising diffusion probabilistic models. We train our model on a real-world dataset of microscopy images used for drug discovery, with and without incorporating metadata labels. By exploring the properties of image-to-image diffusion with relevant labels, we show that class-guided image-to-image diffusion can improve the meaningful content of the reconstructed images and outperform the unguided model in useful downstream tasks.
Language Guided Local Infiltration for Interactive Image Retrieval
Apr 16, 2023

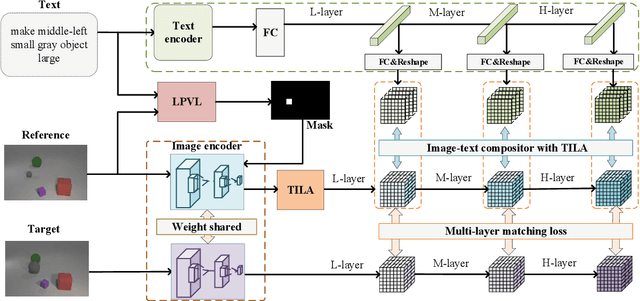
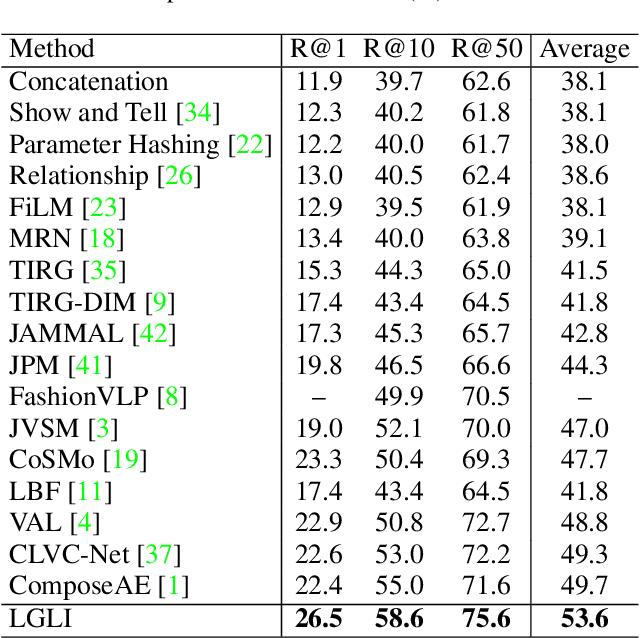
Interactive Image Retrieval (IIR) aims to retrieve images that are generally similar to the reference image but under the requested text modification. The existing methods usually concatenate or sum the features of image and text simply and roughly, which, however, is difficult to precisely change the local semantics of the image that the text intends to modify. To solve this problem, we propose a Language Guided Local Infiltration (LGLI) system, which fully utilizes the text information and penetrates text features into image features as much as possible. Specifically, we first propose a Language Prompt Visual Localization (LPVL) module to generate a localization mask which explicitly locates the region (semantics) intended to be modified. Then we introduce a Text Infiltration with Local Awareness (TILA) module, which is deployed in the network to precisely modify the reference image and generate image-text infiltrated representation. Extensive experiments on various benchmark databases validate that our method outperforms most state-of-the-art IIR approaches.
Towards Generalizable Medical Image Segmentation with Pixel-wise Uncertainty Estimation
May 13, 2023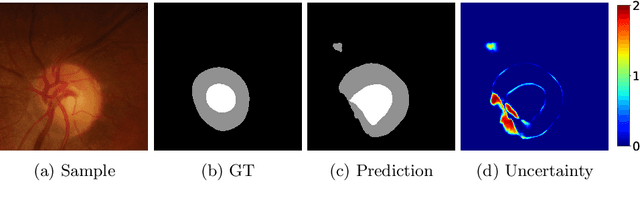
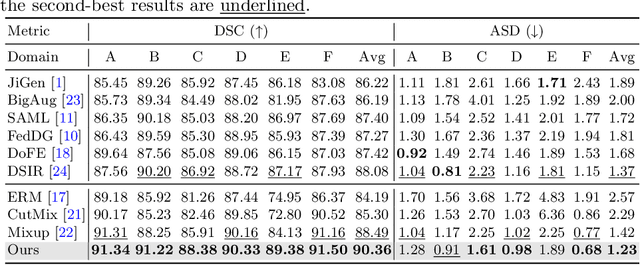
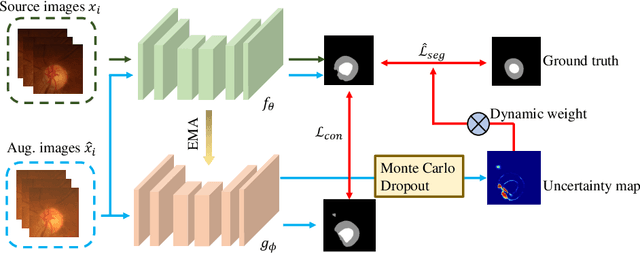
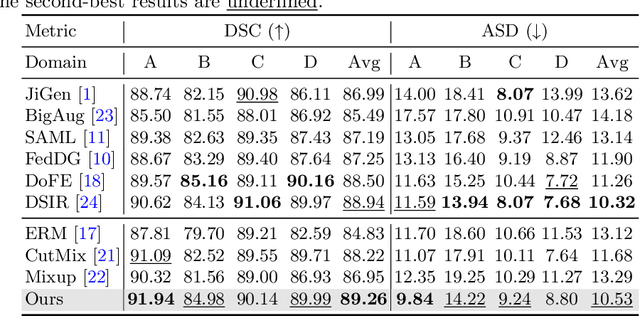
Deep neural networks (DNNs) achieve promising performance in visual recognition under the independent and identically distributed (IID) hypothesis. In contrast, the IID hypothesis is not universally guaranteed in numerous real-world applications, especially in medical image analysis. Medical image segmentation is typically formulated as a pixel-wise classification task in which each pixel is classified into a category. However, this formulation ignores the hard-to-classified pixels, e.g., some pixels near the boundary area, as they usually confuse DNNs. In this paper, we first explore that hard-to-classified pixels are associated with high uncertainty. Based on this, we propose a novel framework that utilizes uncertainty estimation to highlight hard-to-classified pixels for DNNs, thereby improving its generalization. We evaluate our method on two popular benchmarks: prostate and fundus datasets. The results of the experiment demonstrate that our method outperforms state-of-the-art methods.
Self-Supervised and Semi-Supervised Polyp Segmentation using Synthetic Data
Jul 22, 2023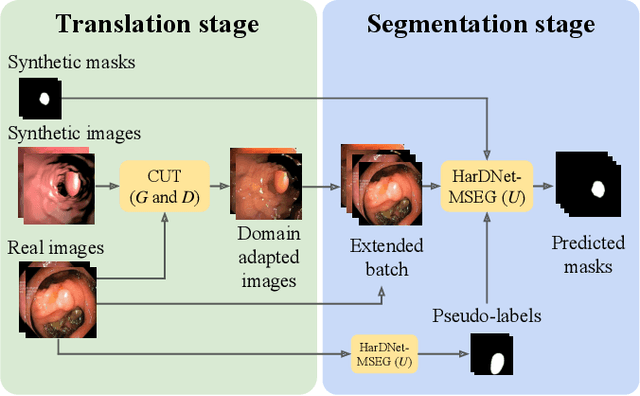
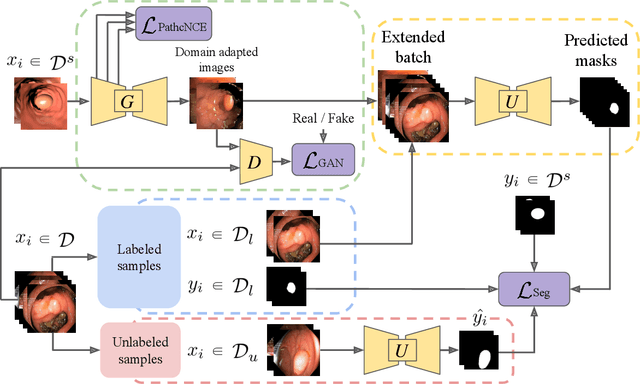
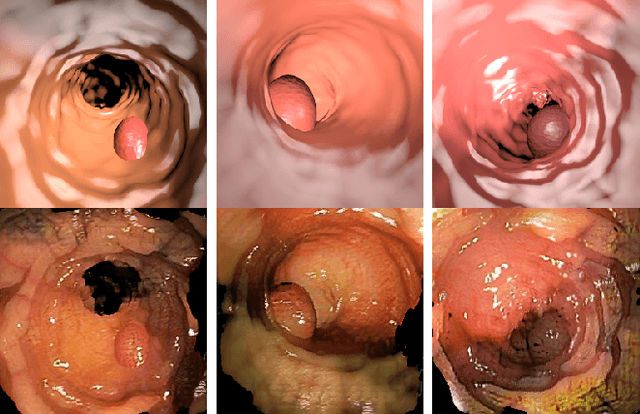
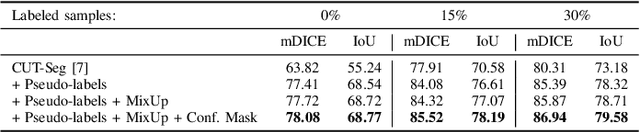
Early detection of colorectal polyps is of utmost importance for their treatment and for colorectal cancer prevention. Computer vision techniques have the potential to aid professionals in the diagnosis stage, where colonoscopies are manually carried out to examine the entirety of the patient's colon. The main challenge in medical imaging is the lack of data, and a further challenge specific to polyp segmentation approaches is the difficulty of manually labeling the available data: the annotation process for segmentation tasks is very time-consuming. While most recent approaches address the data availability challenge with sophisticated techniques to better exploit the available labeled data, few of them explore the self-supervised or semi-supervised paradigm, where the amount of labeling required is greatly reduced. To address both challenges, we leverage synthetic data and propose an end-to-end model for polyp segmentation that integrates real and synthetic data to artificially increase the size of the datasets and aid the training when unlabeled samples are available. Concretely, our model, Pl-CUT-Seg, transforms synthetic images with an image-to-image translation module and combines the resulting images with real images to train a segmentation model, where we use model predictions as pseudo-labels to better leverage unlabeled samples. Additionally, we propose PL-CUT-Seg+, an improved version of the model that incorporates targeted regularization to address the domain gap between real and synthetic images. The models are evaluated on standard benchmarks for polyp segmentation and reach state-of-the-art results in the self- and semi-supervised setups.
ProgDTD: Progressive Learned Image Compression with Double-Tail-Drop Training
May 03, 2023Progressive compression allows images to start loading as low-resolution versions, becoming clearer as more data is received. This increases user experience when, for example, network connections are slow. Today, most approaches for image compression, both classical and learned ones, are designed to be non-progressive. This paper introduces ProgDTD, a training method that transforms learned, non-progressive image compression approaches into progressive ones. The design of ProgDTD is based on the observation that the information stored within the bottleneck of a compression model commonly varies in importance. To create a progressive compression model, ProgDTD modifies the training steps to enforce the model to store the data in the bottleneck sorted by priority. We achieve progressive compression by transmitting the data in order of its sorted index. ProgDTD is designed for CNN-based learned image compression models, does not need additional parameters, and has a customizable range of progressiveness. For evaluation, we apply ProgDTDto the hyperprior model, one of the most common structures in learned image compression. Our experimental results show that ProgDTD performs comparably to its non-progressive counterparts and other state-of-the-art progressive models in terms of MS-SSIM and accuracy.