 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Guided Deep Generative Model-based Spatial Regularization for Multiband Imaging Inverse Problems
Jun 29, 2023
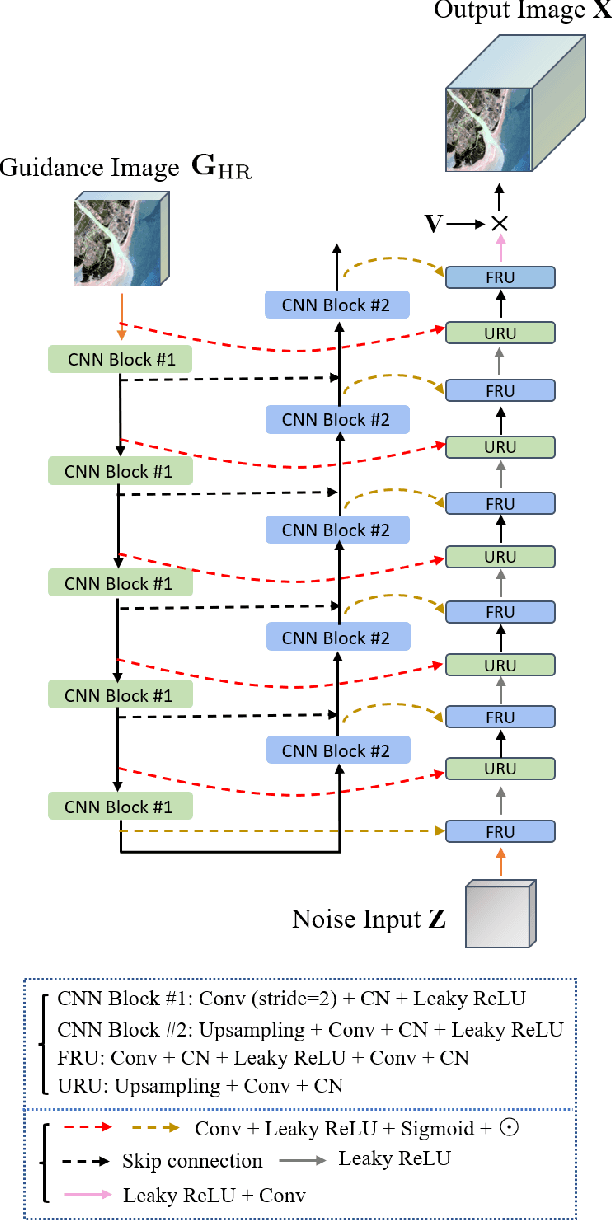

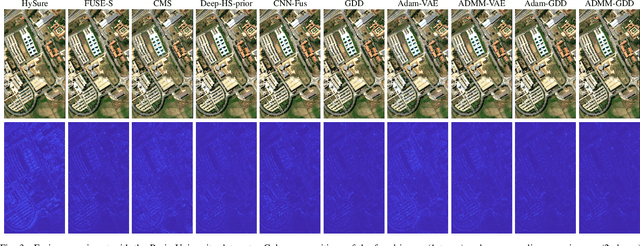
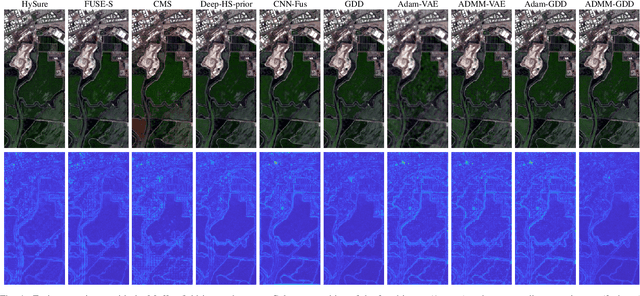
When adopting a model-based formulation, solving inverse problems encountered in multiband imaging requires to define spatial and spectral regularizations. In most of the works of the literature, spectral information is extracted from the observations directly to derive data-driven spectral priors. Conversely, the choice of the spatial regularization often boils down to the use of conventional penalizations (e.g., total variation) promoting expected features of the reconstructed image (e.g., piecewise constant). In this work, we propose a generic framework able to capitalize on an auxiliary acquisition of high spatial resolution to derive tailored data-driven spatial regularizations. This approach leverages on the ability of deep learning to extract high level features. More precisely, the regularization is conceived as a deep generative network able to encode spatial semantic features contained in this auxiliary image of high spatial resolution. To illustrate the versatility of this approach, it is instantiated to conduct two particular tasks, namely multiband image fusion and multiband image inpainting. Experimental results obtained on these two tasks demonstrate the benefit of this class of informed regularizations when compared to more conventional ones.
Meta-hallucinator: Towards Few-Shot Cross-Modality Cardiac Image Segmentation
May 11, 2023Domain shift and label scarcity heavily limit deep learning applications to various medical image analysis tasks. Unsupervised domain adaptation (UDA) techniques have recently achieved promising cross-modality medical image segmentation by transferring knowledge from a label-rich source domain to an unlabeled target domain. However, it is also difficult to collect annotations from the source domain in many clinical applications, rendering most prior works suboptimal with the label-scarce source domain, particularly for few-shot scenarios, where only a few source labels are accessible. To achieve efficient few-shot cross-modality segmentation, we propose a novel transformation-consistent meta-hallucination framework, meta-hallucinator, with the goal of learning to diversify data distributions and generate useful examples for enhancing cross-modality performance. In our framework, hallucination and segmentation models are jointly trained with the gradient-based meta-learning strategy to synthesize examples that lead to good segmentation performance on the target domain. To further facilitate data hallucination and cross-domain knowledge transfer, we develop a self-ensembling model with a hallucination-consistent property. Our meta-hallucinator can seamlessly collaborate with the meta-segmenter for learning to hallucinate with mutual benefits from a combined view of meta-learning and self-ensembling learning. Extensive studies on MM-WHS 2017 dataset for cross-modality cardiac segmentation demonstrate that our method performs favorably against various approaches by a lot in the few-shot UDA scenario.
* Accepted by MICCAI 2022 (top 13% paper; early accept)
Exploiting Pseudo Image Captions for Multimodal Summarization
May 09, 2023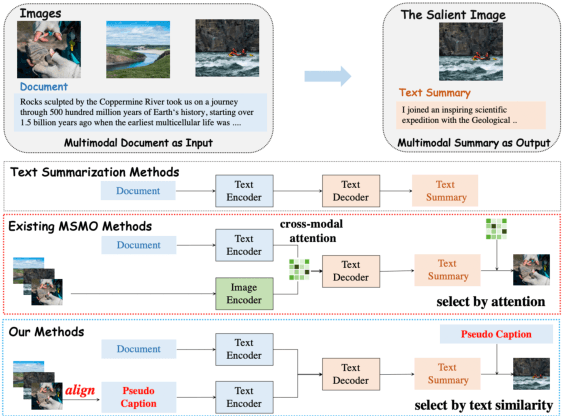
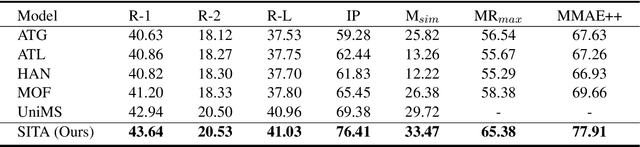
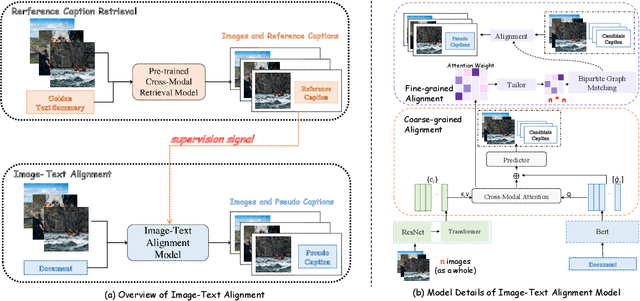

Cross-modal contrastive learning in vision language pretraining (VLP) faces the challenge of (partial) false negatives. In this paper, we study this problem from the perspective of Mutual Information (MI) optimization. It is common sense that InfoNCE loss used in contrastive learning will maximize the lower bound of MI between anchors and their positives, while we theoretically prove that MI involving negatives also matters when noises commonly exist. Guided by a more general lower bound form for optimization, we propose a contrastive learning strategy regulated by progressively refined cross-modal similarity, to more accurately optimize MI between an image/text anchor and its negative texts/images instead of improperly minimizing it. Our method performs competitively on four downstream cross-modal tasks and systematically balances the beneficial and harmful effects of (partial) false negative samples under theoretical guidance.
Guided Patch-Grouping Wavelet Transformer with Spatial Congruence for Ultra-High Resolution Segmentation
Jul 06, 2023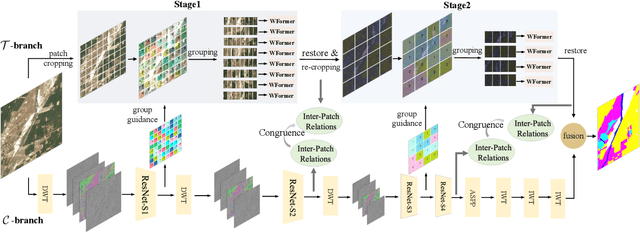
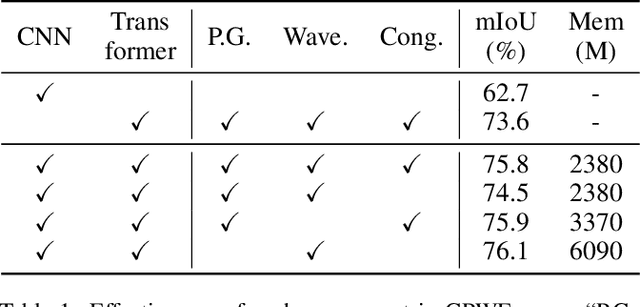
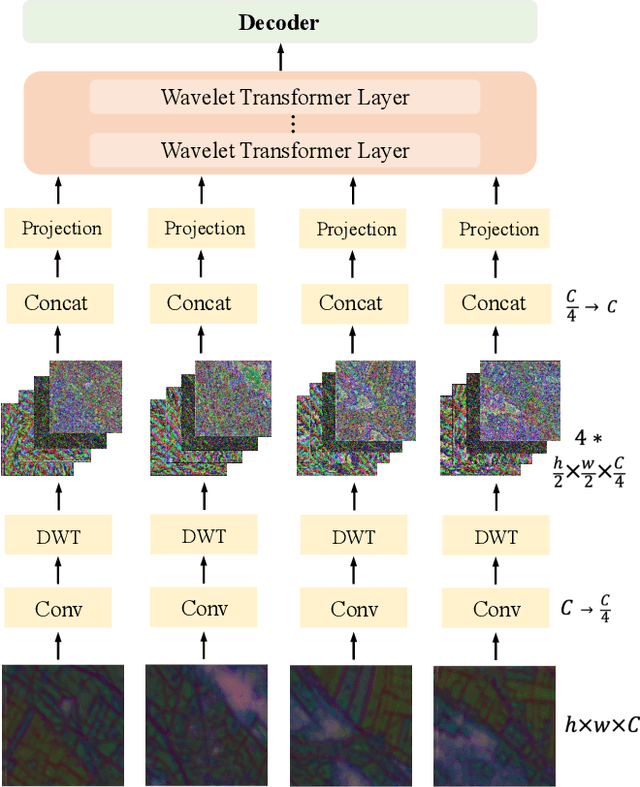

Most existing ultra-high resolution (UHR) segmentation methods always struggle in the dilemma of balancing memory cost and local characterization accuracy, which are both taken into account in our proposed Guided Patch-Grouping Wavelet Transformer (GPWFormer) that achieves impressive performances. In this work, GPWFormer is a Transformer ($\mathcal{T}$)-CNN ($\mathcal{C}$) mutual leaning framework, where $\mathcal{T}$ takes the whole UHR image as input and harvests both local details and fine-grained long-range contextual dependencies, while $\mathcal{C}$ takes downsampled image as input for learning the category-wise deep context. For the sake of high inference speed and low computation complexity, $\mathcal{T}$ partitions the original UHR image into patches and groups them dynamically, then learns the low-level local details with the lightweight multi-head Wavelet Transformer (WFormer) network. Meanwhile, the fine-grained long-range contextual dependencies are also captured during this process, since patches that are far away in the spatial domain can also be assigned to the same group. In addition, masks produced by $\mathcal{C}$ are utilized to guide the patch grouping process, providing a heuristics decision. Moreover, the congruence constraints between the two branches are also exploited to maintain the spatial consistency among the patches. Overall, we stack the multi-stage process in a pyramid way. Experiments show that GPWFormer outperforms the existing methods with significant improvements on five benchmark datasets.
Visually grounded few-shot word learning in low-resource settings
Jun 21, 2023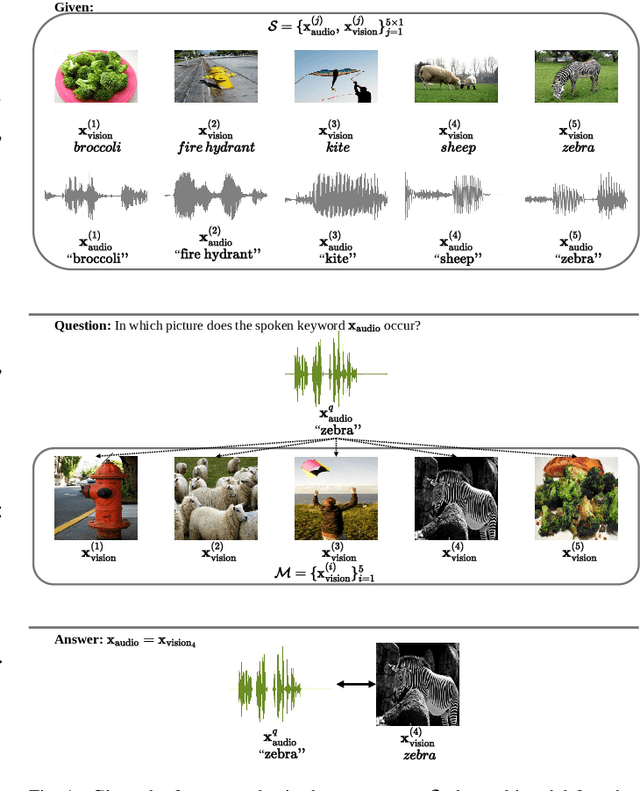
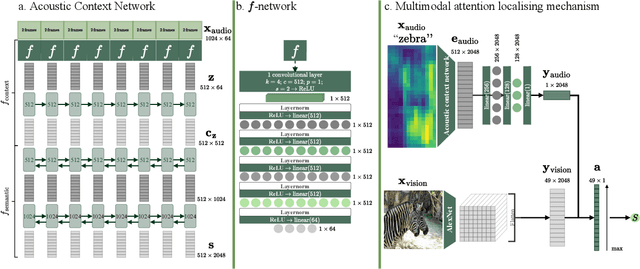
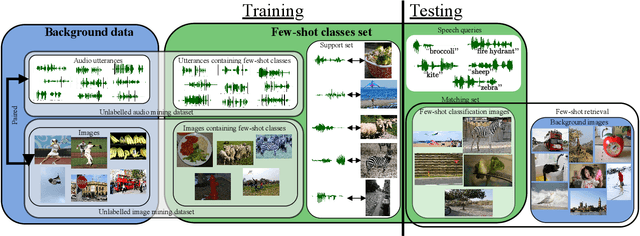
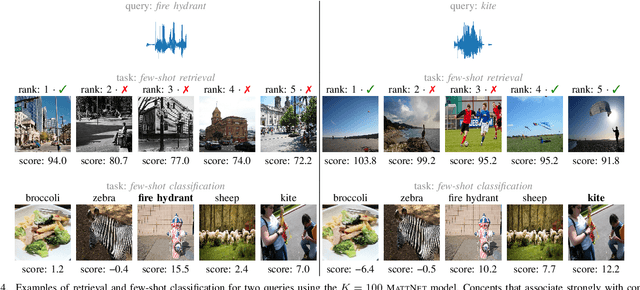
We propose a visually grounded speech model that learns new words and their visual depictions from just a few word-image example pairs. Given a set of test images and a spoken query, we ask the model which image depicts the query word. Previous work has simplified this few-shot learning problem by either using an artificial setting with digit word-image pairs or by using a large number of examples per class. Moreover, all previous studies were performed using English speech-image data. We propose an approach that can work on natural word-image pairs but with less examples, i.e. fewer shots, and then illustrate how this approach can be applied for multimodal few-shot learning in a real low-resource language, Yoruba. Our approach involves using the given word-image example pairs to mine new unsupervised word-image training pairs from large collections of unlabelledspeech and images. Additionally, we use a word-to-image attention mechanism to determine word-image similarity. With this new model, we achieve better performance with fewer shots than previous approaches on an existing English benchmark. Many of the model's mistakes are due to confusion between visual concepts co-occurring in similar contexts. The experiments on Yoruba show the benefit of transferring knowledge from a multimodal model trained on a larger set of English speech-image data.
Collaborative Generative AI: Integrating GPT-k for Efficient Editing in Text-to-Image Generation
May 18, 2023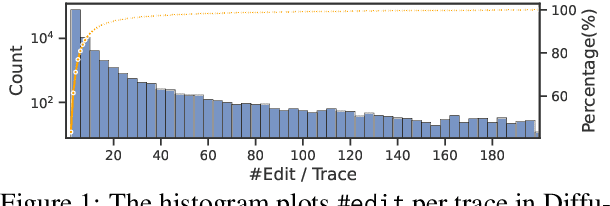
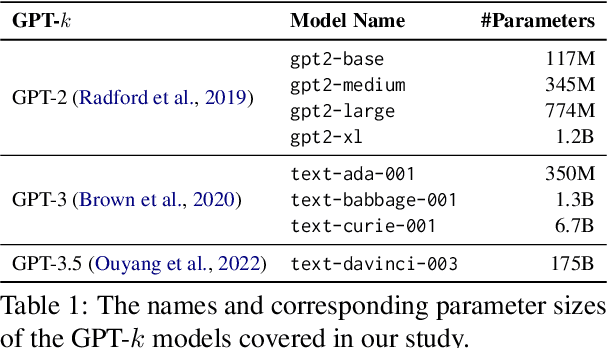
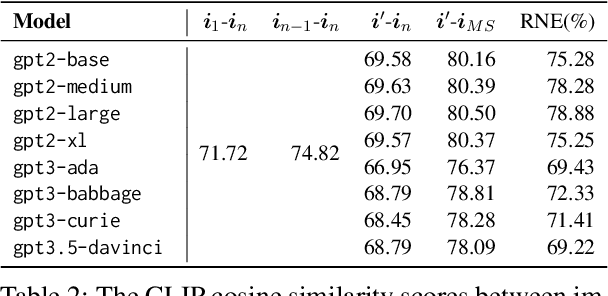
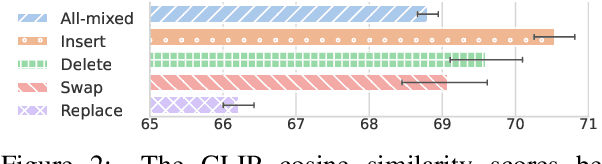
The field of text-to-image (T2I) generation has garnered significant attention both within the research community and among everyday users. Despite the advancements of T2I models, a common issue encountered by users is the need for repetitive editing of input prompts in order to receive a satisfactory image, which is time-consuming and labor-intensive. Given the demonstrated text generation power of large-scale language models, such as GPT-k, we investigate the potential of utilizing such models to improve the prompt editing process for T2I generation. We conduct a series of experiments to compare the common edits made by humans and GPT-k, evaluate the performance of GPT-k in prompting T2I, and examine factors that may influence this process. We found that GPT-k models focus more on inserting modifiers while humans tend to replace words and phrases, which includes changes to the subject matter. Experimental results show that GPT-k are more effective in adjusting modifiers rather than predicting spontaneous changes in the primary subject matters. Adopting the edit suggested by GPT-k models may reduce the percentage of remaining edits by 20-30%.
Meta-Learning Enabled Score-Based Generative Model for 1.5T-Like Image Reconstruction from 0.5T MRI
May 04, 2023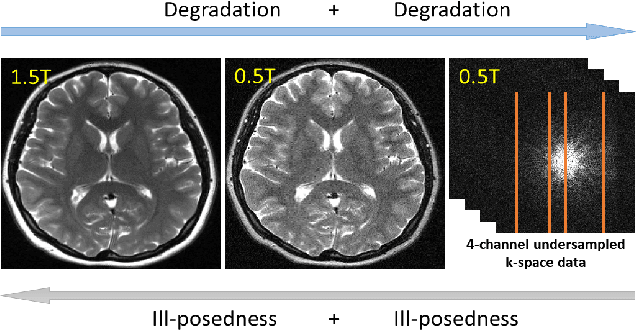
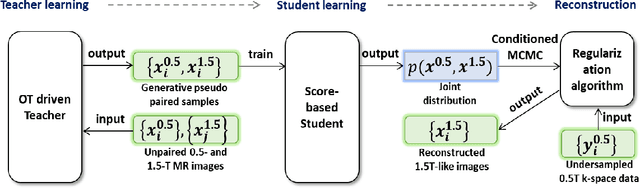
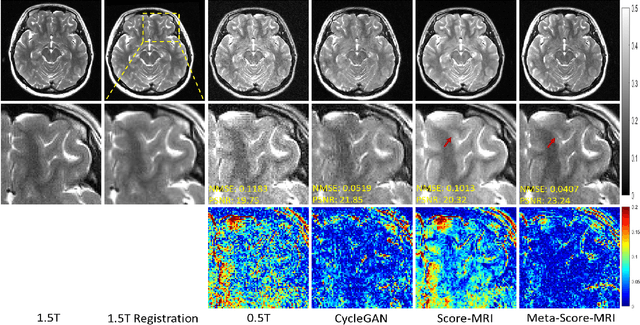
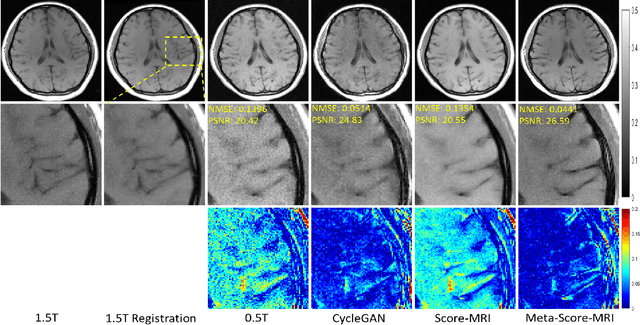
Magnetic resonance imaging (MRI) is known to have reduced signal-to-noise ratios (SNR) at lower field strengths, leading to signal degradation when producing a low-field MRI image from a high-field one. Therefore, reconstructing a high-field-like image from a low-field MRI is a complex problem due to the ill-posed nature of the task. Additionally, obtaining paired low-field and high-field MR images is often not practical. We theoretically uncovered that the combination of these challenges renders conventional deep learning methods that directly learn the mapping from a low-field MR image to a high-field MR image unsuitable. To overcome these challenges, we introduce a novel meta-learning approach that employs a teacher-student mechanism. Firstly, an optimal-transport-driven teacher learns the degradation process from high-field to low-field MR images and generates pseudo-paired high-field and low-field MRI images. Then, a score-based student solves the inverse problem of reconstructing a high-field-like MR image from a low-field MRI within the framework of iterative regularization, by learning the joint distribution of pseudo-paired images to act as a regularizer. Experimental results on real low-field MRI data demonstrate that our proposed method outperforms state-of-the-art unpaired learning methods.
SSN: Stockwell Scattering Network for SAR Image Change Detection
Apr 22, 2023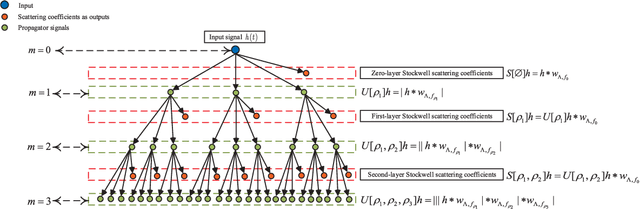
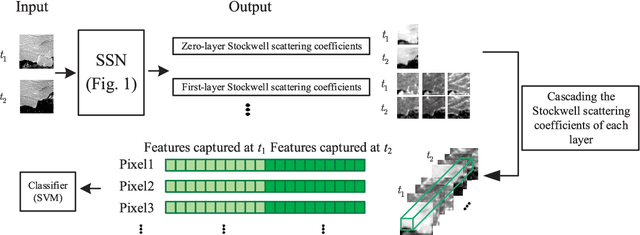


Recently, synthetic aperture radar (SAR) image change detection has become an interesting yet challenging direction due to the presence of speckle noise. Although both traditional and modern learning-driven methods attempted to overcome this challenge, deep convolutional neural networks (DCNNs)-based methods are still hindered by the lack of interpretability and the requirement of large computation power. To overcome this drawback, wavelet scattering network (WSN) and Fourier scattering network (FSN) are proposed. Combining respective merits of WSN and FSN, we propose Stockwell scattering network (SSN) based on Stockwell transform which is widely applied against noisy signals and shows advantageous characteristics in speckle reduction. The proposed SSN provides noise-resilient feature representation and obtains state-of-art performance in SAR image change detection as well as high computational efficiency. Experimental results on three real SAR image datasets demonstrate the effectiveness of the proposed method.
* 5 pages, 6 figures
A Subabdominal MRI Image Segmentation Algorithm Based on Multi-Scale Feature Pyramid Network and Dual Attention Mechanism
May 19, 2023This study aimed to solve the semantic gap and misalignment issue between encoding and decoding because of multiple convolutional and pooling operations in U-Net when segmenting subabdominal MRI images during rectal cancer treatment. A MRI Image Segmentation is proposed based on a multi-scale feature pyramid network and dual attention mechanism. Our innovation is the design of two modules: 1) a dilated convolution and multi-scale feature pyramid network are used in the encoding to avoid the semantic gap. 2) a dual attention mechanism is designed to maintain spatial information of U-Net and reduce misalignment. Experiments on a subabdominal MRI image dataset show the proposed method achieves better performance than others methods. In conclusion, a multi-scale feature pyramid network can reduce the semantic gap, and the dual attention mechanism can make an alignment of features between encoding and decoding.
Diffusion Explainer: Visual Explanation for Text-to-image Stable Diffusion
May 04, 2023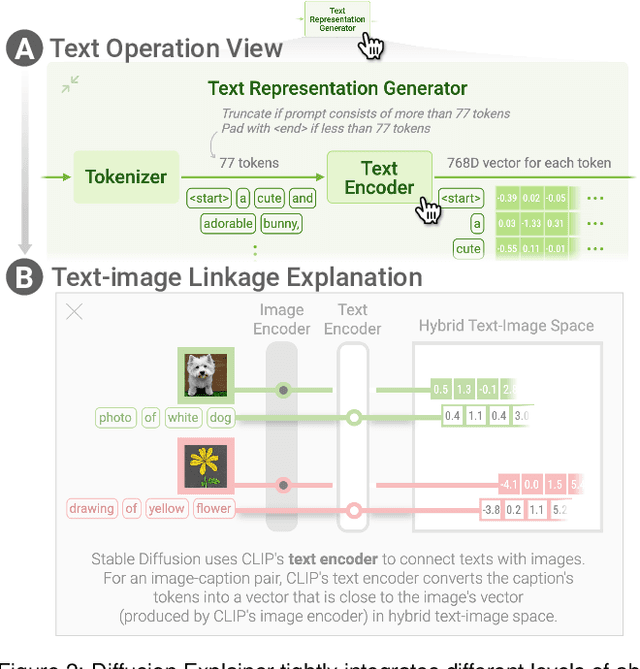
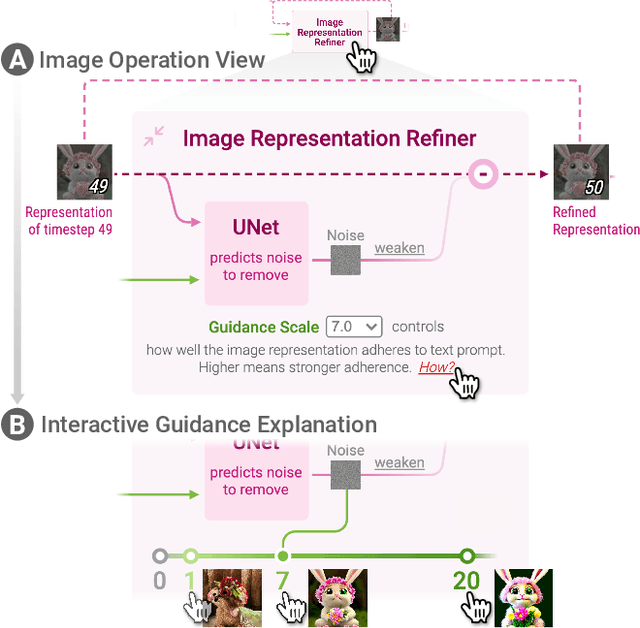
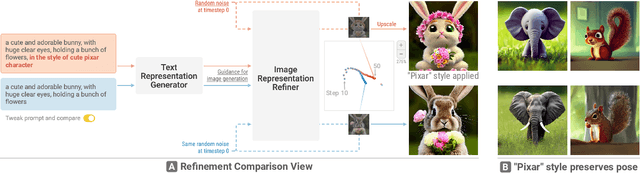
Diffusion-based generative models' impressive ability to create convincing images has captured global attention. However, their complex internal structures and operations often make them difficult for non-experts to understand. We present Diffusion Explainer, the first interactive visualization tool that explains how Stable Diffusion transforms text prompts into images. Diffusion Explainer tightly integrates a visual overview of Stable Diffusion's complex components with detailed explanations of their underlying operations, enabling users to fluidly transition between multiple levels of abstraction through animations and interactive elements. By comparing the evolutions of image representations guided by two related text prompts over refinement timesteps, users can discover the impact of prompts on image generation. Diffusion Explainer runs locally in users' web browsers without the need for installation or specialized hardware, broadening the public's education access to modern AI techniques. Our open-sourced tool is available at: https://poloclub.github.io/diffusion-explainer/.