 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Quantum-noise-limited optical neural networks operating at a few quanta per activation
Jul 28, 2023
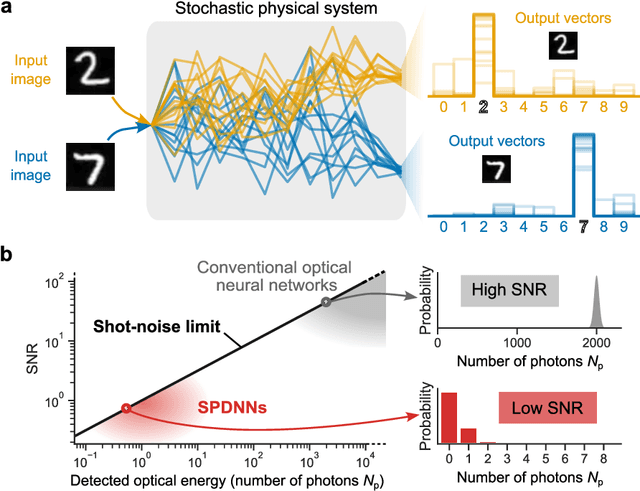

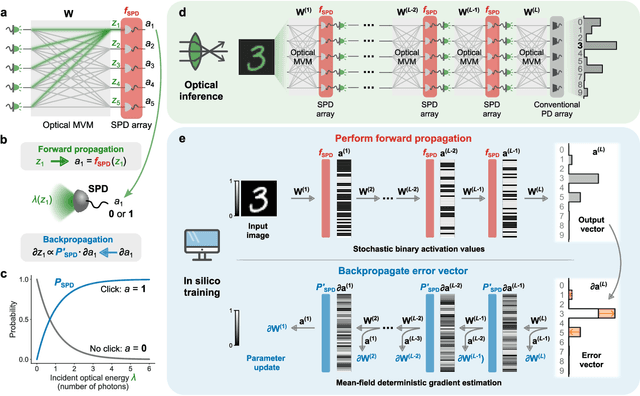
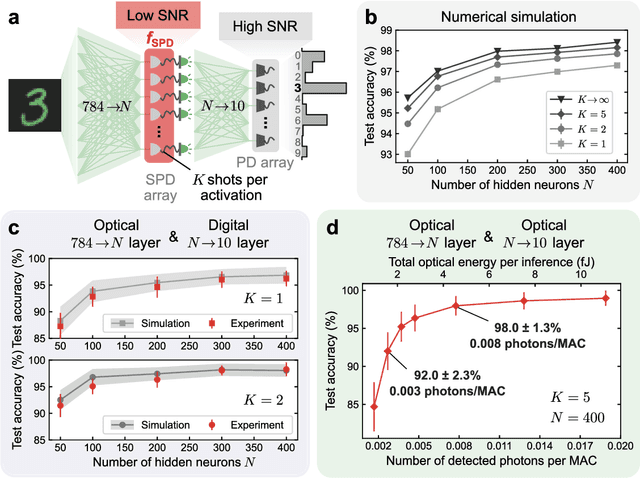
Analog physical neural networks, which hold promise for improved energy efficiency and speed compared to digital electronic neural networks, are nevertheless typically operated in a relatively high-power regime so that the signal-to-noise ratio (SNR) is large (>10). What happens if an analog system is instead operated in an ultra-low-power regime, in which the behavior of the system becomes highly stochastic and the noise is no longer a small perturbation on the signal? In this paper, we study this question in the setting of optical neural networks operated in the limit where some layers use only a single photon to cause a neuron activation. Neuron activations in this limit are dominated by quantum noise from the fundamentally probabilistic nature of single-photon detection of weak optical signals. We show that it is possible to train stochastic optical neural networks to perform deterministic image-classification tasks with high accuracy in spite of the extremely high noise (SNR ~ 1) by using a training procedure that directly models the stochastic behavior of photodetection. We experimentally demonstrated MNIST classification with a test accuracy of 98% using an optical neural network with a hidden layer operating in the single-photon regime; the optical energy used to perform the classification corresponds to 0.008 photons per multiply-accumulate (MAC) operation, which is equivalent to 0.003 attojoules of optical energy per MAC. Our experiment used >40x fewer photons per inference than previous state-of-the-art low-optical-energy demonstrations, to achieve the same accuracy of >90%. Our work shows that some extremely stochastic analog systems, including those operating in the limit where quantum noise dominates, can nevertheless be used as layers in neural networks that deterministically perform classification tasks with high accuracy if they are appropriately trained.
Zero-shot Nuclei Detection via Visual-Language Pre-trained Models
Jun 30, 2023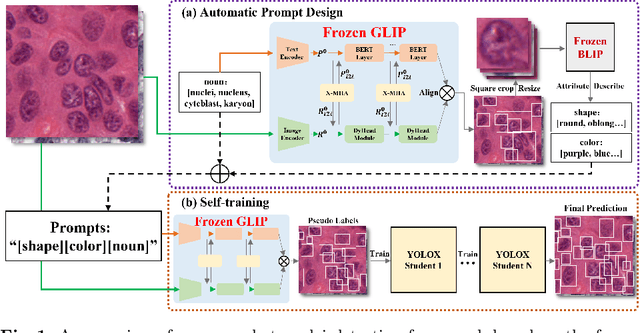


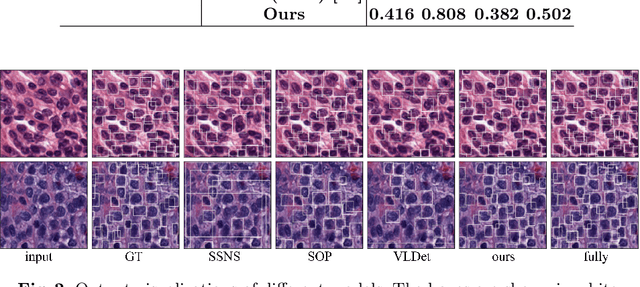
Large-scale visual-language pre-trained models (VLPM) have proven their excellent performance in downstream object detection for natural scenes. However, zero-shot nuclei detection on H\&E images via VLPMs remains underexplored. The large gap between medical images and the web-originated text-image pairs used for pre-training makes it a challenging task. In this paper, we attempt to explore the potential of the object-level VLPM, Grounded Language-Image Pre-training (GLIP) model, for zero-shot nuclei detection. Concretely, an automatic prompts design pipeline is devised based on the association binding trait of VLPM and the image-to-text VLPM BLIP, avoiding empirical manual prompts engineering. We further establish a self-training framework, using the automatically designed prompts to generate the preliminary results as pseudo labels from GLIP and refine the predicted boxes in an iterative manner. Our method achieves a remarkable performance for label-free nuclei detection, surpassing other comparison methods. Foremost, our work demonstrates that the VLPM pre-trained on natural image-text pairs exhibits astonishing potential for downstream tasks in the medical field as well. Code will be released at https://github.com/wuyongjianCODE/VLPMNuD.
Guided Patch-Grouping Wavelet Transformer with Spatial Congruence for Ultra-High Resolution Segmentation
Jul 06, 2023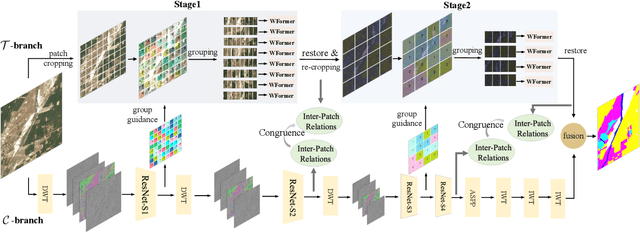
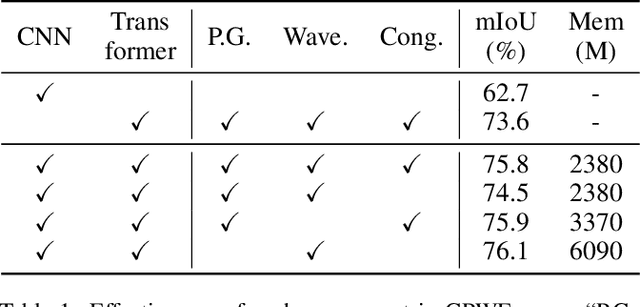
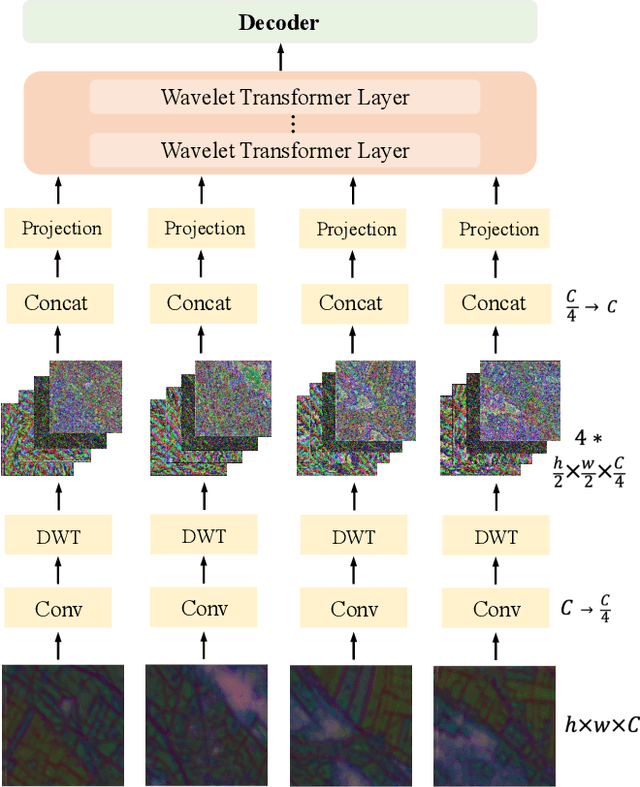

Most existing ultra-high resolution (UHR) segmentation methods always struggle in the dilemma of balancing memory cost and local characterization accuracy, which are both taken into account in our proposed Guided Patch-Grouping Wavelet Transformer (GPWFormer) that achieves impressive performances. In this work, GPWFormer is a Transformer ($\mathcal{T}$)-CNN ($\mathcal{C}$) mutual leaning framework, where $\mathcal{T}$ takes the whole UHR image as input and harvests both local details and fine-grained long-range contextual dependencies, while $\mathcal{C}$ takes downsampled image as input for learning the category-wise deep context. For the sake of high inference speed and low computation complexity, $\mathcal{T}$ partitions the original UHR image into patches and groups them dynamically, then learns the low-level local details with the lightweight multi-head Wavelet Transformer (WFormer) network. Meanwhile, the fine-grained long-range contextual dependencies are also captured during this process, since patches that are far away in the spatial domain can also be assigned to the same group. In addition, masks produced by $\mathcal{C}$ are utilized to guide the patch grouping process, providing a heuristics decision. Moreover, the congruence constraints between the two branches are also exploited to maintain the spatial consistency among the patches. Overall, we stack the multi-stage process in a pyramid way. Experiments show that GPWFormer outperforms the existing methods with significant improvements on five benchmark datasets.
Stop Pre-Training: Adapt Visual-Language Models to Unseen Languages
Jun 29, 2023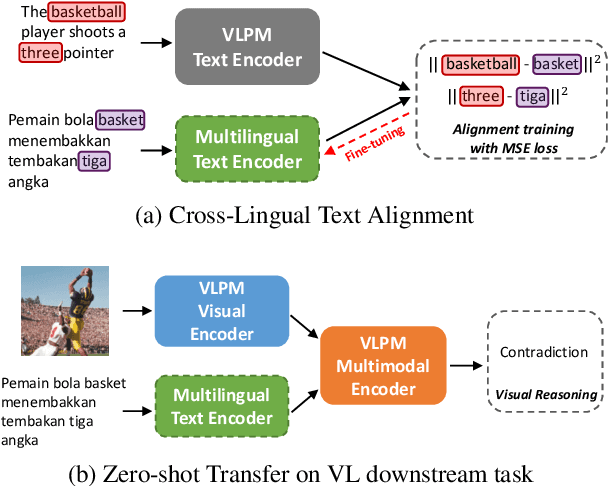

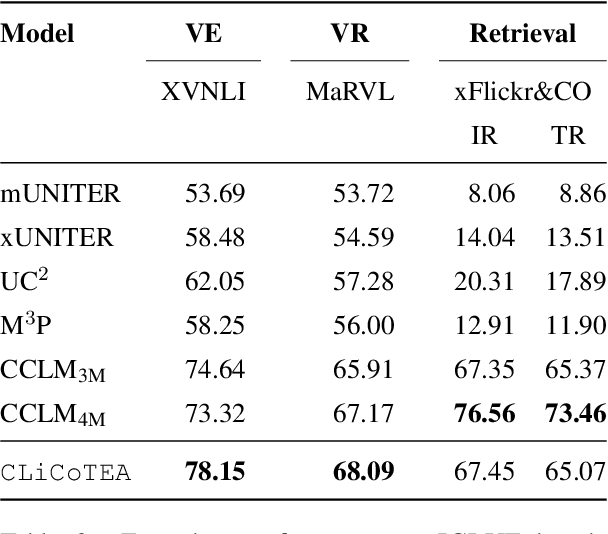
Vision-Language Pre-training (VLP) has advanced the performance of many vision-language tasks, such as image-text retrieval, visual entailment, and visual reasoning. The pre-training mostly utilizes lexical databases and image queries in English. Previous work has demonstrated that the pre-training in English does not transfer well to other languages in a zero-shot setting. However, multilingual pre-trained language models (MPLM) have excelled at a variety of single-modal language tasks. In this paper, we propose a simple yet efficient approach to adapt VLP to unseen languages using MPLM. We utilize a cross-lingual contextualized token embeddings alignment approach to train text encoders for non-English languages. Our approach does not require image input and primarily uses machine translation, eliminating the need for target language data. Our evaluation across three distinct tasks (image-text retrieval, visual entailment, and natural language visual reasoning) demonstrates that this approach outperforms the state-of-the-art multilingual vision-language models without requiring large parallel corpora. Our code is available at https://github.com/Yasminekaroui/CliCoTea.
Guided Deep Generative Model-based Spatial Regularization for Multiband Imaging Inverse Problems
Jun 29, 2023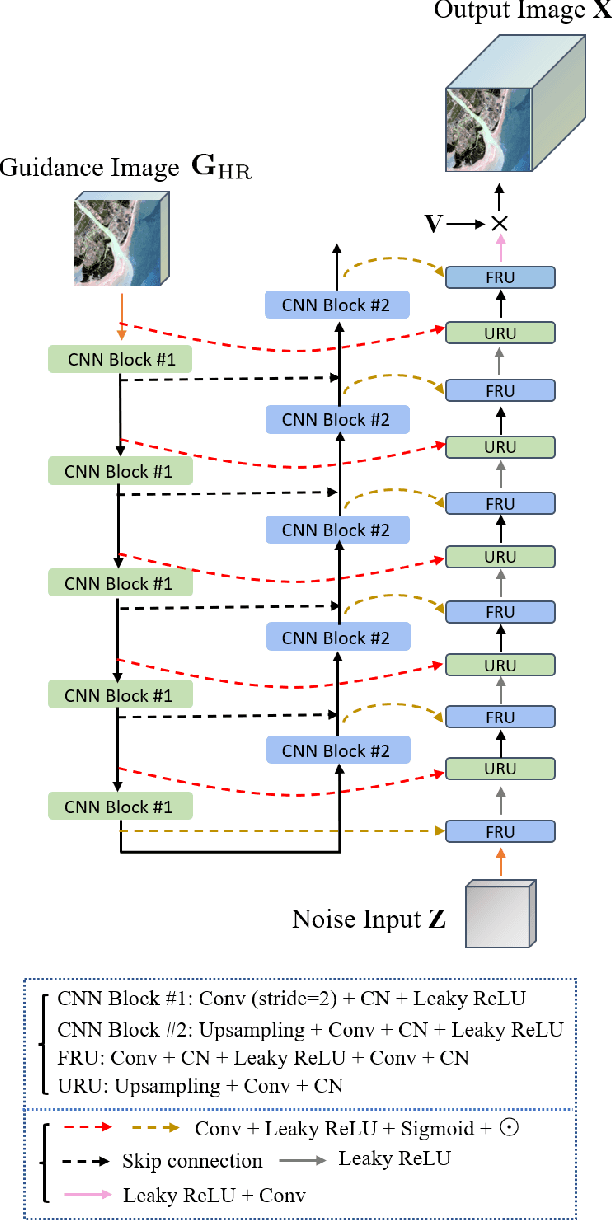

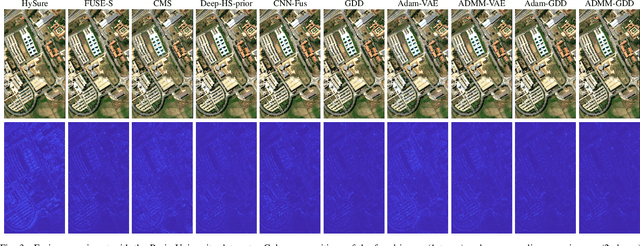
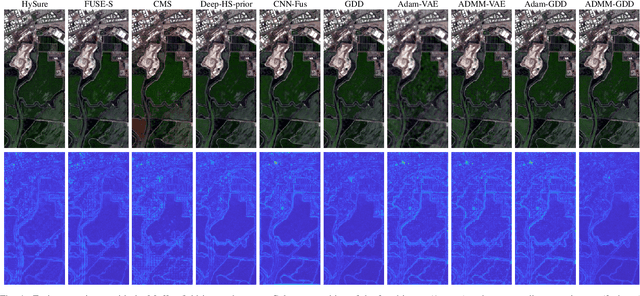
When adopting a model-based formulation, solving inverse problems encountered in multiband imaging requires to define spatial and spectral regularizations. In most of the works of the literature, spectral information is extracted from the observations directly to derive data-driven spectral priors. Conversely, the choice of the spatial regularization often boils down to the use of conventional penalizations (e.g., total variation) promoting expected features of the reconstructed image (e.g., piecewise constant). In this work, we propose a generic framework able to capitalize on an auxiliary acquisition of high spatial resolution to derive tailored data-driven spatial regularizations. This approach leverages on the ability of deep learning to extract high level features. More precisely, the regularization is conceived as a deep generative network able to encode spatial semantic features contained in this auxiliary image of high spatial resolution. To illustrate the versatility of this approach, it is instantiated to conduct two particular tasks, namely multiband image fusion and multiband image inpainting. Experimental results obtained on these two tasks demonstrate the benefit of this class of informed regularizations when compared to more conventional ones.
Detecting Images Generated by Deep Diffusion Models using their Local Intrinsic Dimensionality
Jul 20, 2023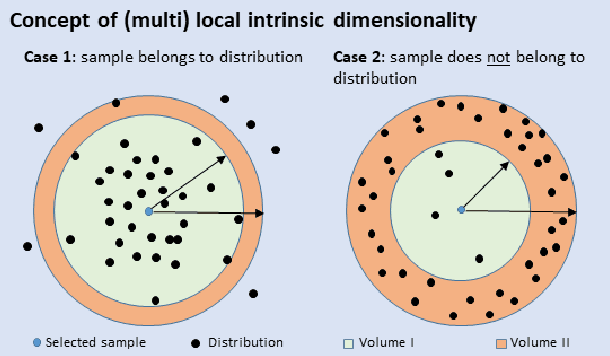
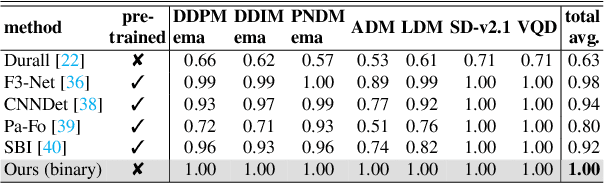
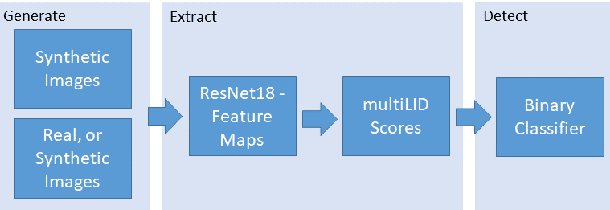
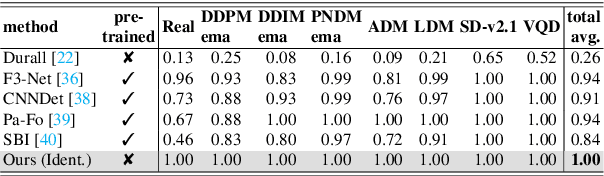
Diffusion models recently have been successfully applied for the visual synthesis of strikingly realistic appearing images. This raises strong concerns about their potential for malicious purposes. In this paper, we propose using the lightweight multi Local Intrinsic Dimensionality (multiLID), which has been originally developed in context of the detection of adversarial examples, for the automatic detection of synthetic images and the identification of the according generator networks. In contrast to many existing detection approaches, which often only work for GAN-generated images, the proposed method provides close to perfect detection results in many realistic use cases. Extensive experiments on known and newly created datasets demonstrate that the proposed multiLID approach exhibits superiority in diffusion detection and model identification. Since the empirical evaluations of recent publications on the detection of generated images are often mainly focused on the "LSUN-Bedroom" dataset, we further establish a comprehensive benchmark for the detection of diffusion-generated images, including samples from several diffusion models with different image sizes.
Post-variational quantum neural networks
Jul 20, 2023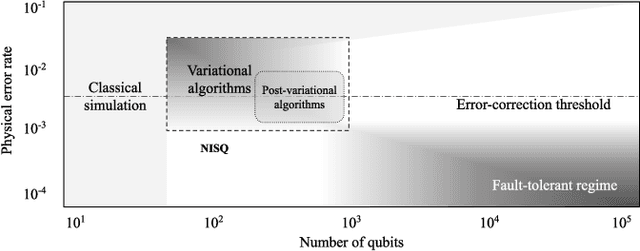
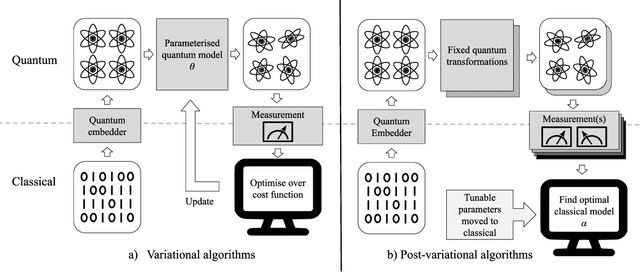
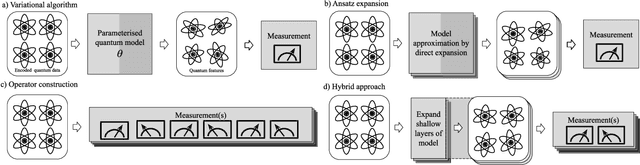
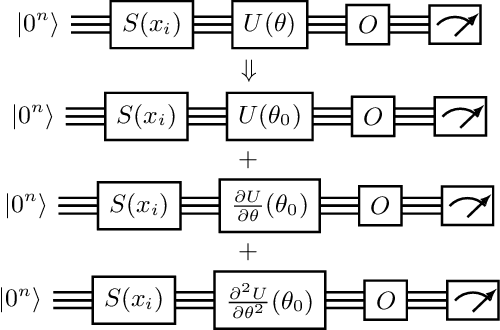
Quantum computing has the potential to provide substantial computational advantages over current state-of-the-art classical supercomputers. However, current hardware is not advanced enough to execute fault-tolerant quantum algorithms. An alternative of using hybrid quantum-classical computing with variational algorithms can exhibit barren plateau issues, causing slow convergence of gradient-based optimization techniques. In this paper, we discuss "post-variational strategies", which shift tunable parameters from the quantum computer to the classical computer, opting for ensemble strategies when optimizing quantum models. We discuss various strategies and design principles for constructing individual quantum circuits, where the resulting ensembles can be optimized with convex programming. Further, we discuss architectural designs of post-variational quantum neural networks and analyze the propagation of estimation errors throughout such neural networks. Lastly, we show that our algorithm can be applied to real-world applications such as image classification on handwritten digits, producing a 96% classification accuracy.
OCTraN: 3D Occupancy Convolutional Transformer Network in Unstructured Traffic Scenarios
Jul 20, 2023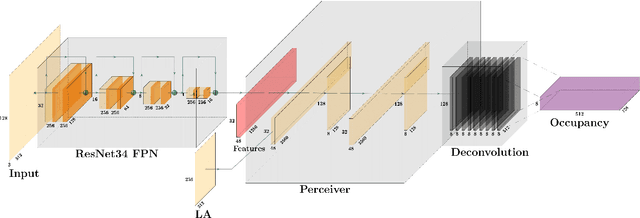

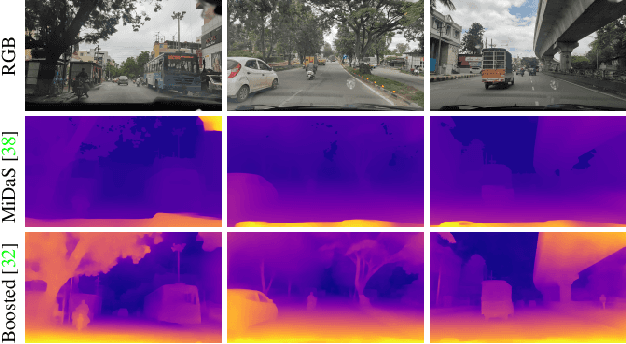
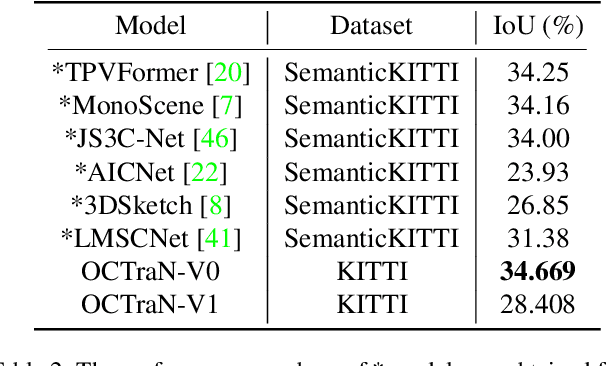
Modern approaches for vision-centric environment perception for autonomous navigation make extensive use of self-supervised monocular depth estimation algorithms that output disparity maps. However, when this disparity map is projected onto 3D space, the errors in disparity are magnified, resulting in a depth estimation error that increases quadratically as the distance from the camera increases. Though Light Detection and Ranging (LiDAR) can solve this issue, it is expensive and not feasible for many applications. To address the challenge of accurate ranging with low-cost sensors, we propose, OCTraN, a transformer architecture that uses iterative-attention to convert 2D image features into 3D occupancy features and makes use of convolution and transpose convolution to efficiently operate on spatial information. We also develop a self-supervised training pipeline to generalize the model to any scene by eliminating the need for LiDAR ground truth by substituting it with pseudo-ground truth labels obtained from boosted monocular depth estimation.
Automatic Search for Photoacoustic Marker Using Automated Transrectal Ultrasound
Jul 20, 2023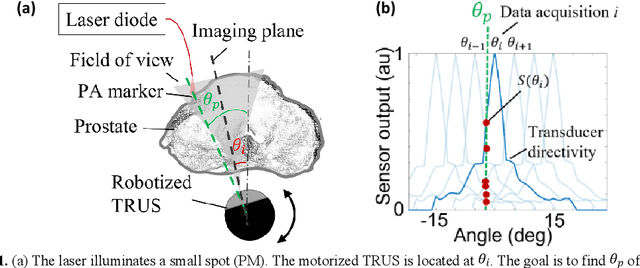
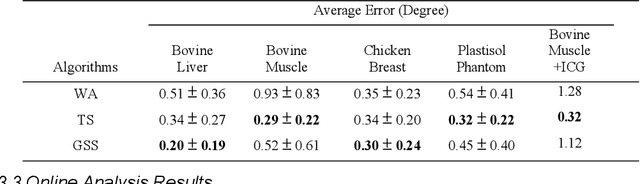
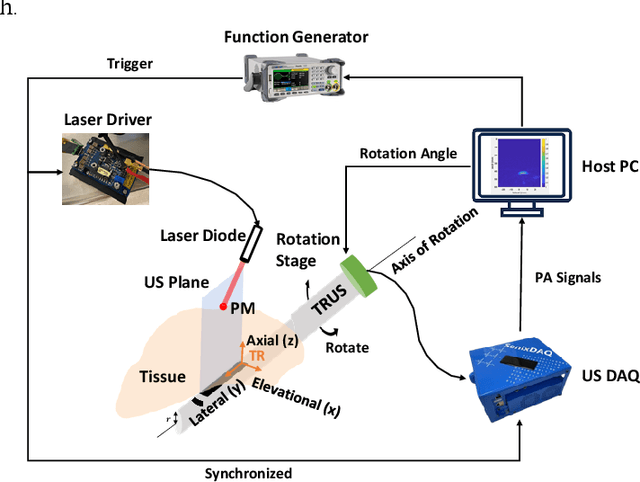
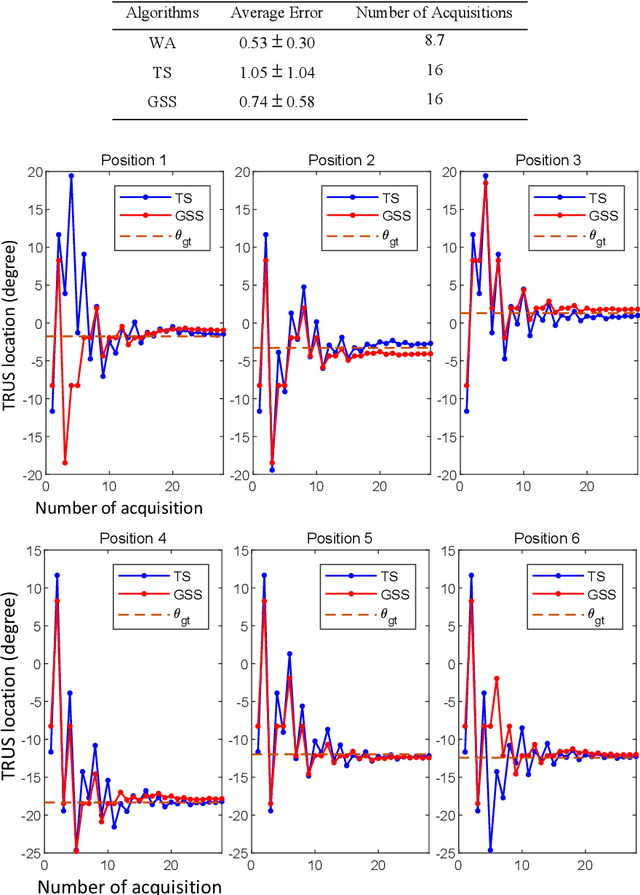
Real-time transrectal ultrasound (TRUS) image guidance during robot-assisted laparoscopic radical prostatectomy has the potential to enhance surgery outcomes. Whether conventional or photoacoustic TRUS is used, the robotic system and the TRUS must be registered to each other. Accurate registration can be performed using photoacoustic (PA markers). However, this requires a manual search by an assistant [19]. This paper introduces the first automatic search for PA markers using a transrectal ultrasound robot. This effectively reduces the challenges associated with the da Vinci-TRUS registration. This paper investigated the performance of three search algorithms in simulation and experiment: Weighted Average (WA), Golden Section Search (GSS), and Ternary Search (TS). For validation, a surgical prostate scenario was mimicked and various ex vivo tissues were tested. As a result, the WA algorithm can achieve 0.53 degree average error after 9 data acquisitions, while the TS and GSS algorithm can achieve 0.29 degree and 0.48 degree average errors after 28 data acquisitions.
Learning Dense UV Completion for Human Mesh Recovery
Jul 20, 2023
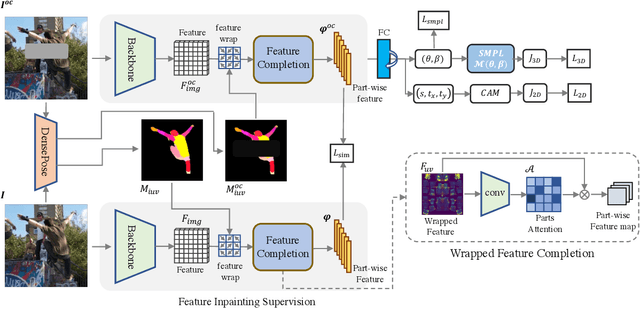
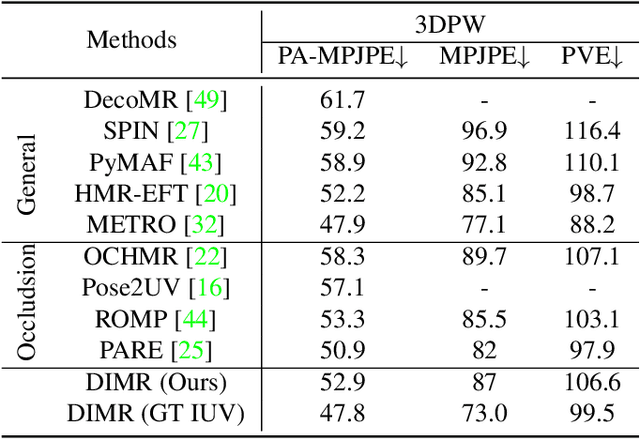

Human mesh reconstruction from a single image is challenging in the presence of occlusion, which can be caused by self, objects, or other humans. Existing methods either fail to separate human features accurately or lack proper supervision for feature completion. In this paper, we propose Dense Inpainting Human Mesh Recovery (DIMR), a two-stage method that leverages dense correspondence maps to handle occlusion. Our method utilizes a dense correspondence map to separate visible human features and completes human features on a structured UV map dense human with an attention-based feature completion module. We also design a feature inpainting training procedure that guides the network to learn from unoccluded features. We evaluate our method on several datasets and demonstrate its superior performance under heavily occluded scenarios compared to other methods. Extensive experiments show that our method obviously outperforms prior SOTA methods on heavily occluded images and achieves comparable results on the standard benchmarks (3DPW).