 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Diffusion Sampling with Momentum for Mitigating Divergence Artifacts
Jul 20, 2023
Despite the remarkable success of diffusion models in image generation, slow sampling remains a persistent issue. To accelerate the sampling process, prior studies have reformulated diffusion sampling as an ODE/SDE and introduced higher-order numerical methods. However, these methods often produce divergence artifacts, especially with a low number of sampling steps, which limits the achievable acceleration. In this paper, we investigate the potential causes of these artifacts and suggest that the small stability regions of these methods could be the principal cause. To address this issue, we propose two novel techniques. The first technique involves the incorporation of Heavy Ball (HB) momentum, a well-known technique for improving optimization, into existing diffusion numerical methods to expand their stability regions. We also prove that the resulting methods have first-order convergence. The second technique, called Generalized Heavy Ball (GHVB), constructs a new high-order method that offers a variable trade-off between accuracy and artifact suppression. Experimental results show that our techniques are highly effective in reducing artifacts and improving image quality, surpassing state-of-the-art diffusion solvers on both pixel-based and latent-based diffusion models for low-step sampling. Our research provides novel insights into the design of numerical methods for future diffusion work.
YOLOPose V2: Understanding and Improving Transformer-based 6D Pose Estimation
Jul 21, 2023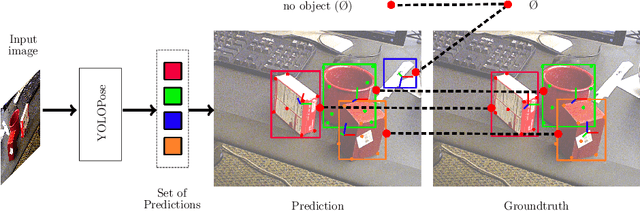
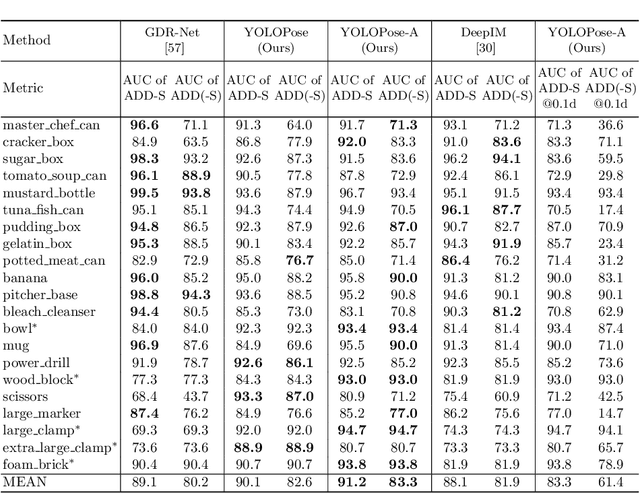
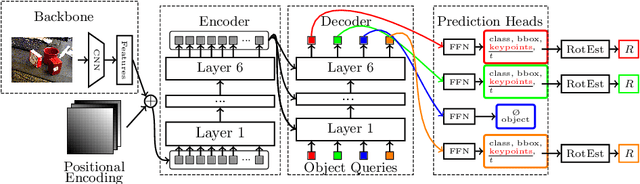
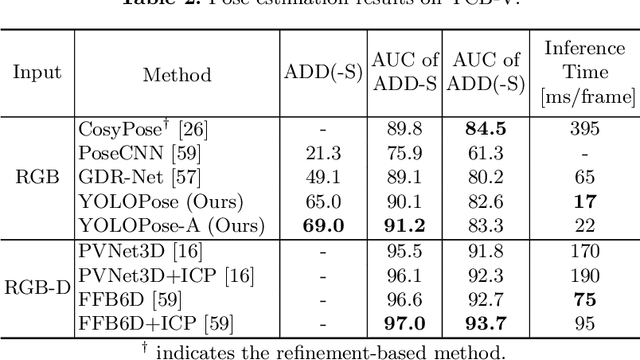
6D object pose estimation is a crucial prerequisite for autonomous robot manipulation applications. The state-of-the-art models for pose estimation are convolutional neural network (CNN)-based. Lately, Transformers, an architecture originally proposed for natural language processing, is achieving state-of-the-art results in many computer vision tasks as well. Equipped with the multi-head self-attention mechanism, Transformers enable simple single-stage end-to-end architectures for learning object detection and 6D object pose estimation jointly. In this work, we propose YOLOPose (short form for You Only Look Once Pose estimation), a Transformer-based multi-object 6D pose estimation method based on keypoint regression and an improved variant of the YOLOPose model. In contrast to the standard heatmaps for predicting keypoints in an image, we directly regress the keypoints. Additionally, we employ a learnable orientation estimation module to predict the orientation from the keypoints. Along with a separate translation estimation module, our model is end-to-end differentiable. Our method is suitable for real-time applications and achieves results comparable to state-of-the-art methods. We analyze the role of object queries in our architecture and reveal that the object queries specialize in detecting objects in specific image regions. Furthermore, we quantify the accuracy trade-off of using datasets of smaller sizes to train our model.
Towards Generalizable Diabetic Retinopathy Grading in Unseen Domains
Jul 21, 2023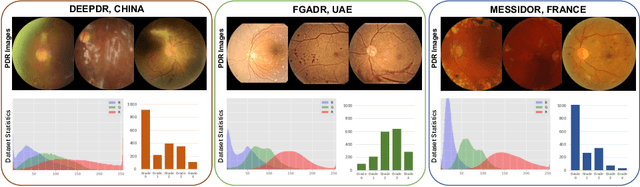
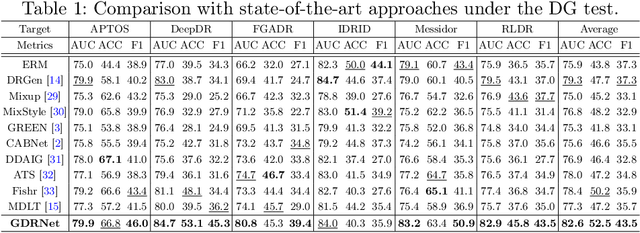
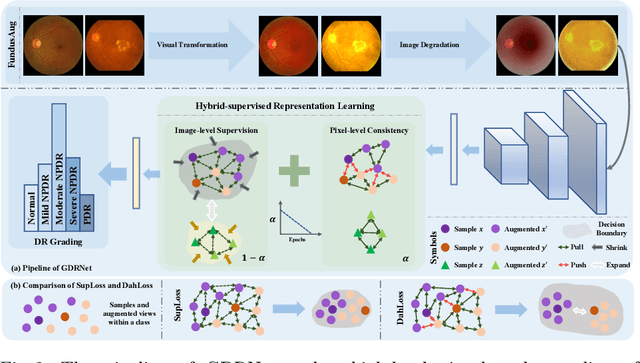
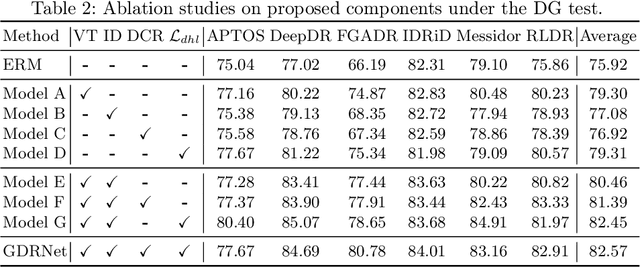
Diabetic Retinopathy (DR) is a common complication of diabetes and a leading cause of blindness worldwide. Early and accurate grading of its severity is crucial for disease management. Although deep learning has shown great potential for automated DR grading, its real-world deployment is still challenging due to distribution shifts among source and target domains, known as the domain generalization problem. Existing works have mainly attributed the performance degradation to limited domain shifts caused by simple visual discrepancies, which cannot handle complex real-world scenarios. Instead, we present preliminary evidence suggesting the existence of three-fold generalization issues: visual and degradation style shifts, diagnostic pattern diversity, and data imbalance. To tackle these issues, we propose a novel unified framework named Generalizable Diabetic Retinopathy Grading Network (GDRNet). GDRNet consists of three vital components: fundus visual-artifact augmentation (FundusAug), dynamic hybrid-supervised loss (DahLoss), and domain-class-aware re-balancing (DCR). FundusAug generates realistic augmented images via visual transformation and image degradation, while DahLoss jointly leverages pixel-level consistency and image-level semantics to capture the diverse diagnostic patterns and build generalizable feature representations. Moreover, DCR mitigates the data imbalance from a domain-class view and avoids undesired over-emphasis on rare domain-class pairs. Finally, we design a publicly available benchmark for fair evaluations. Extensive comparison experiments against advanced methods and exhaustive ablation studies demonstrate the effectiveness and generalization ability of GDRNet.
Spectral normalized dual contrastive regularization for image-to-image translation
Apr 22, 2023
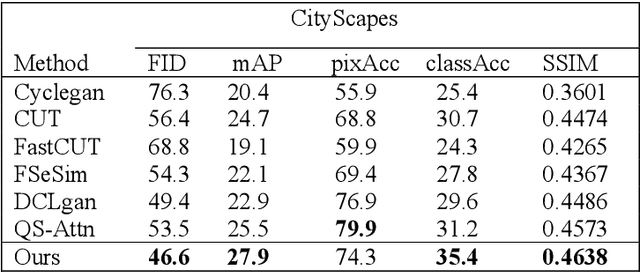


Existing image-to-image(I2I) translation methods achieve state-of-the-art performance by incorporating the patch-wise contrastive learning into Generative Adversarial Networks. However, patch-wise contrastive learning only focuses on the local content similarity but neglects the global structure constraint, which affects the quality of the generated images. In this paper, we propose a new unpaired I2I translation framework based on dual contrastive regularization and spectral normalization, namely SN-DCR. To maintain consistency of the global structure and texture, we design the dual contrastive regularization using different feature spaces respectively. In order to improve the global structure information of the generated images, we formulate a semantically contrastive loss to make the global semantic structure of the generated images similar to the real images from the target domain in the semantic feature space. We use Gram Matrices to extract the style of texture from images. Similarly, we design style contrastive loss to improve the global texture information of the generated images. Moreover, to enhance the stability of model, we employ the spectral normalized convolutional network in the design of our generator. We conduct the comprehensive experiments to evaluate the effectiveness of SN-DCR, and the results prove that our method achieves SOTA in multiple tasks.
Real-Time Radiance Fields for Single-Image Portrait View Synthesis
May 03, 2023


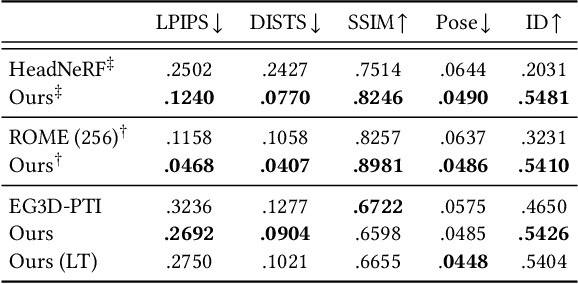
We present a one-shot method to infer and render a photorealistic 3D representation from a single unposed image (e.g., face portrait) in real-time. Given a single RGB input, our image encoder directly predicts a canonical triplane representation of a neural radiance field for 3D-aware novel view synthesis via volume rendering. Our method is fast (24 fps) on consumer hardware, and produces higher quality results than strong GAN-inversion baselines that require test-time optimization. To train our triplane encoder pipeline, we use only synthetic data, showing how to distill the knowledge from a pretrained 3D GAN into a feedforward encoder. Technical contributions include a Vision Transformer-based triplane encoder, a camera data augmentation strategy, and a well-designed loss function for synthetic data training. We benchmark against the state-of-the-art methods, demonstrating significant improvements in robustness and image quality in challenging real-world settings. We showcase our results on portraits of faces (FFHQ) and cats (AFHQ), but our algorithm can also be applied in the future to other categories with a 3D-aware image generator.
Compositional Text-to-Image Synthesis with Attention Map Control of Diffusion Models
May 23, 2023
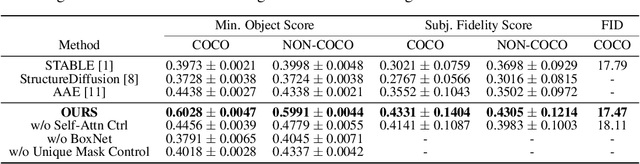
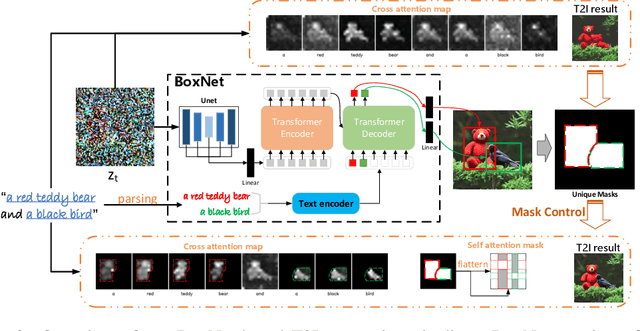

Recent text-to-image (T2I) diffusion models show outstanding performance in generating high-quality images conditioned on textual prompts. However, these models fail to semantically align the generated images with the text descriptions due to their limited compositional capabilities, leading to attribute leakage, entity leakage, and missing entities. In this paper, we propose a novel attention mask control strategy based on predicted object boxes to address these three issues. In particular, we first train a BoxNet to predict a box for each entity that possesses the attribute specified in the prompt. Then, depending on the predicted boxes, unique mask control is applied to the cross- and self-attention maps. Our approach produces a more semantically accurate synthesis by constraining the attention regions of each token in the prompt to the image. In addition, the proposed method is straightforward and effective, and can be readily integrated into existing cross-attention-diffusion-based T2I generators. We compare our approach to competing methods and demonstrate that it not only faithfully conveys the semantics of the original text to the generated content, but also achieves high availability as a ready-to-use plugin.
Mixer: Image to Multi-Modal Retrieval Learning for Industrial Application
May 06, 2023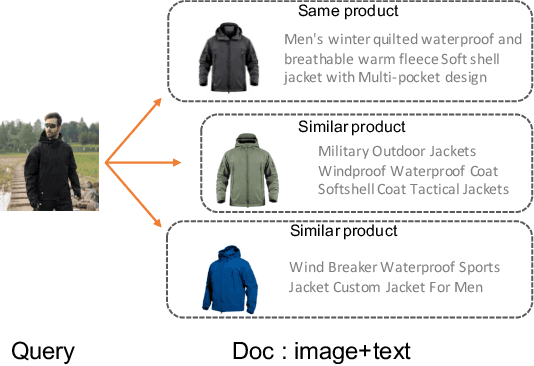
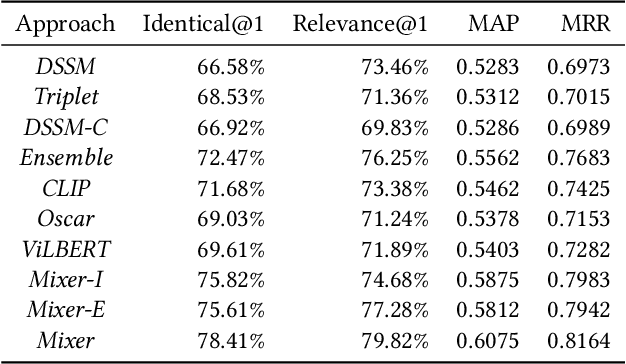
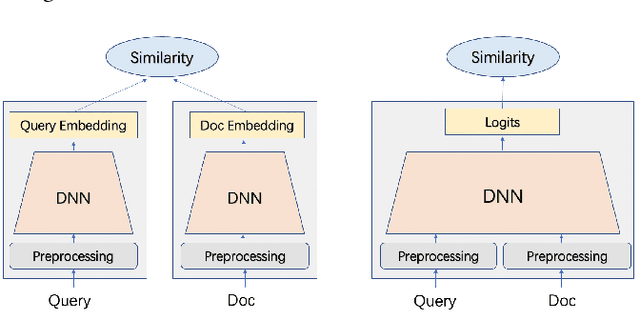
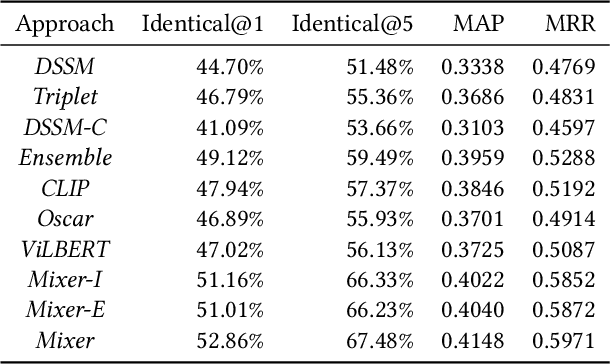
Cross-modal retrieval, where the query is an image and the doc is an item with both image and text description, is ubiquitous in e-commerce platforms and content-sharing social media. However, little research attention has been paid to this important application. This type of retrieval task is challenging due to the facts: 1)~domain gap exists between query and doc. 2)~multi-modality alignment and fusion. 3)~skewed training data and noisy labels collected from user behaviors. 4)~huge number of queries and timely responses while the large-scale candidate docs exist. To this end, we propose a novel scalable and efficient image query to multi-modal retrieval learning paradigm called Mixer, which adaptively integrates multi-modality data, mines skewed and noisy data more efficiently and scalable to high traffic. The Mixer consists of three key ingredients: First, for query and doc image, a shared encoder network followed by separate transformation networks are utilized to account for their domain gap. Second, in the multi-modal doc, images and text are not equally informative. So we design a concept-aware modality fusion module, which extracts high-level concepts from the text by a text-to-image attention mechanism. Lastly, but most importantly, we turn to a new data organization and training paradigm for single-modal to multi-modal retrieval: large-scale classification learning which treats single-modal query and multi-modal doc as equivalent samples of certain classes. Besides, the data organization follows a weakly-supervised manner, which can deal with skewed data and noisy labels inherited in the industrial systems. Learning such a large number of categories for real-world multi-modality data is non-trivial and we design a specific learning strategy for it. The proposed Mixer achieves SOTA performance on public datasets from industrial retrieval systems.
UIT-OpenViIC: A Novel Benchmark for Evaluating Image Captioning in Vietnamese
May 09, 2023Image Captioning is one of the vision-language tasks that still interest the research community worldwide in the 2020s. MS-COCO Caption benchmark is commonly used to evaluate the performance of advanced captioning models, although it was published in 2015. Recent captioning models trained on the MS-COCO Caption dataset only have good performance in language patterns of English; they do not have such good performance in contexts captured in Vietnam or fluently caption images using Vietnamese. To contribute to the low-resources research community as in Vietnam, we introduce a novel image captioning dataset in Vietnamese, the Open-domain Vietnamese Image Captioning dataset (UIT-OpenViIC). The introduced dataset includes complex scenes captured in Vietnam and manually annotated by Vietnamese under strict rules and supervision. In this paper, we present in more detail the dataset creation process. From preliminary analysis, we show that our dataset is challenging to recent state-of-the-art (SOTA) Transformer-based baselines, which performed well on the MS COCO dataset. Then, the modest results prove that UIT-OpenViIC has room to grow, which can be one of the standard benchmarks in Vietnamese for the research community to evaluate their captioning models. Furthermore, we present a CAMO approach that effectively enhances the image representation ability by a multi-level encoder output fusion mechanism, which helps improve the quality of generated captions compared to previous captioning models.
Evolutionary Multi-objective Optimisation in Neurotrajectory Prediction
Aug 04, 2023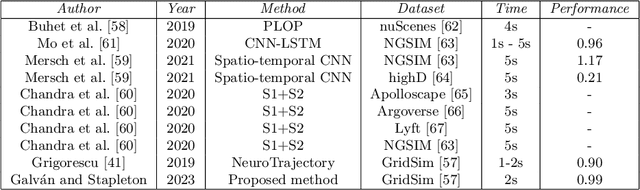
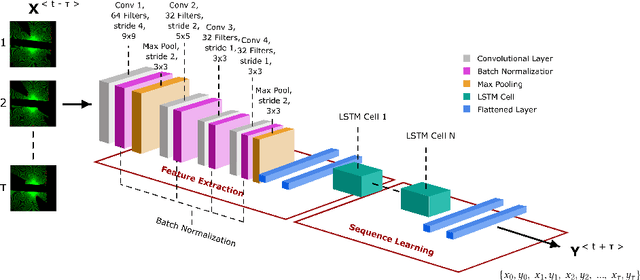
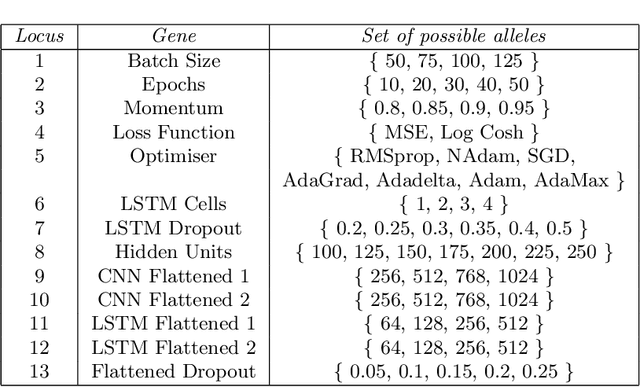
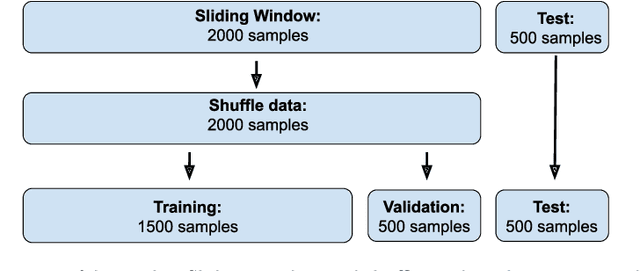
Machine learning has rapidly evolved during the last decade, achieving expert human performance on notoriously challenging problems such as image classification. This success is partly due to the re-emergence of bio-inspired modern artificial neural networks (ANNs) along with the availability of computation power, vast labelled data and ingenious human-based expert knowledge as well as optimisation approaches that can find the correct configuration (and weights) for these networks. Neuroevolution is a term used for the latter when employing evolutionary algorithms. Most of the works in neuroevolution have focused their attention in a single type of ANNs, named Convolutional Neural Networks (CNNs). Moreover, most of these works have used a single optimisation approach. This work makes a progressive step forward in neuroevolution for vehicle trajectory prediction, referred to as neurotrajectory prediction, where multiple objectives must be considered. To this end, rich ANNs composed of CNNs and Long-short Term Memory Network are adopted. Two well-known and robust Evolutionary Multi-objective Optimisation (EMO) algorithms, NSGA-II and MOEA/D are also adopted. The completely different underlying mechanism of each of these algorithms sheds light on the implications of using one over the other EMO approach in neurotrajectory prediction. In particular, the importance of considering objective scaling is highlighted, finding that MOEA/D can be more adept at focusing on specific objectives whereas, NSGA-II tends to be more invariant to objective scaling. Additionally, certain objectives are shown to be either beneficial or detrimental to finding valid models, for instance, inclusion of a distance feedback objective was considerably detrimental to finding valid models, while a lateral velocity objective was more beneficial.
* 38 pages, 6 Figure, 10 Tables
Designing a Deep Learning-Driven Resource-Efficient Diagnostic System for Metastatic Breast Cancer: Reducing Long Delays of Clinical Diagnosis and Improving Patient Survival in Developing Countries
Aug 04, 2023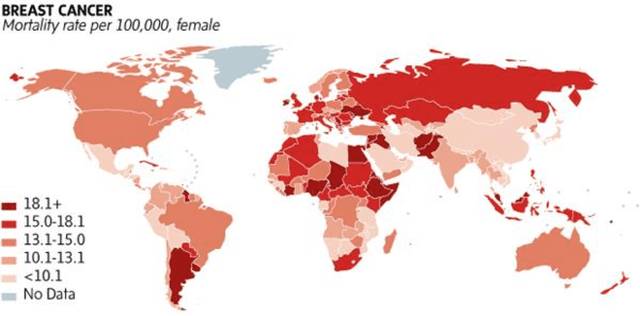
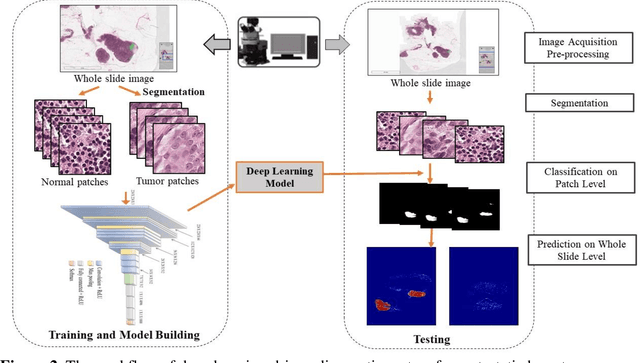
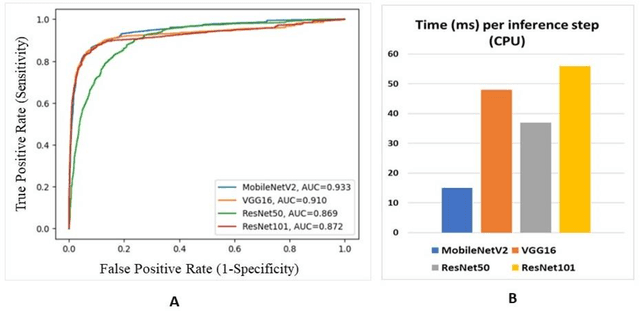
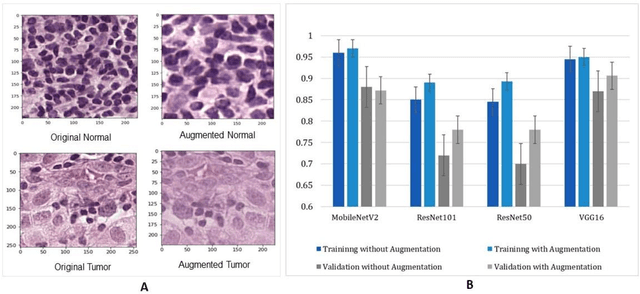
Breast cancer is one of the leading causes of cancer mortality. Breast cancer patients in developing countries, especially sub-Saharan Africa, South Asia, and South America, suffer from the highest mortality rate in the world. One crucial factor contributing to the global disparity in mortality rate is long delay of diagnosis due to a severe shortage of trained pathologists, which consequently has led to a large proportion of late-stage presentation at diagnosis. The delay between the initial development of symptoms and the receipt of a diagnosis could stretch upwards 15 months. To tackle this critical healthcare disparity, this research has developed a deep learning-based diagnosis system for metastatic breast cancer that can achieve high diagnostic accuracy as well as computational efficiency. Based on our evaluation, the MobileNetV2-based diagnostic model outperformed the more complex VGG16, ResNet50 and ResNet101 models in diagnostic accuracy, model generalization, and model training efficiency. The visual comparisons between the model prediction and ground truth have demonstrated that the MobileNetV2 diagnostic models can identify very small cancerous nodes embedded in a large area of normal cells which is challenging for manual image analysis. Equally Important, the light weighted MobleNetV2 models were computationally efficient and ready for mobile devices or devices of low computational power. These advances empower the development of a resource-efficient and high performing AI-based metastatic breast cancer diagnostic system that can adapt to under-resourced healthcare facilities in developing countries. This research provides an innovative technological solution to address the long delays in metastatic breast cancer diagnosis and the consequent disparity in patient survival outcome in developing countries.