 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Leveraging Internal Representations of Model for Magnetic Image Classification
Mar 11, 2024
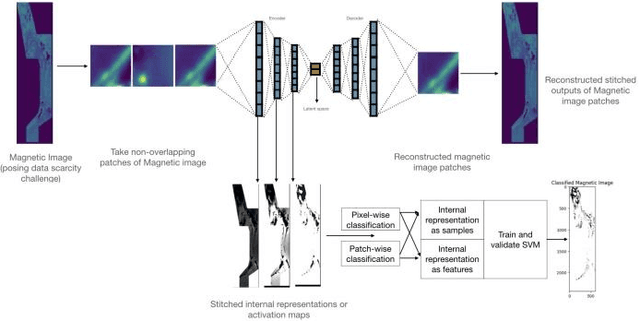
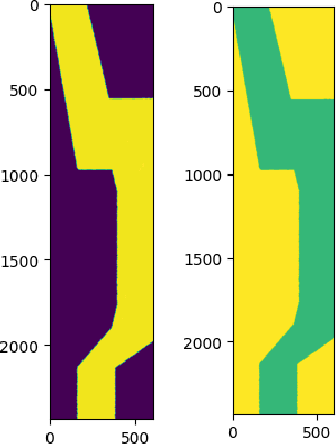

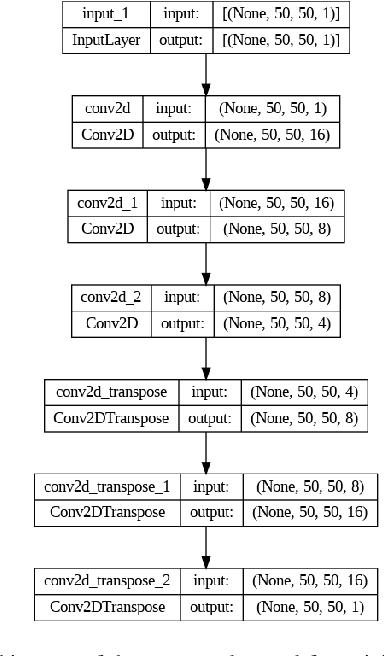
Data generated by edge devices has the potential to train intelligent autonomous systems across various domains. Despite the emergence of diverse machine learning approaches addressing privacy concerns and utilizing distributed data, security issues persist due to the sensitive storage of data shards in disparate locations. This paper introduces a potentially groundbreaking paradigm for machine learning model training, specifically designed for scenarios with only a single magnetic image and its corresponding label image available. We harness the capabilities of Deep Learning to generate concise yet informative samples, aiming to overcome data scarcity. Through the utilization of deep learning's internal representations, our objective is to efficiently address data scarcity issues and produce meaningful results. This methodology presents a promising avenue for training machine learning models with minimal data.
In-Context Matting
Mar 23, 2024We introduce in-context matting, a novel task setting of image matting. Given a reference image of a certain foreground and guided priors such as points, scribbles, and masks, in-context matting enables automatic alpha estimation on a batch of target images of the same foreground category, without additional auxiliary input. This setting marries good performance in auxiliary input-based matting and ease of use in automatic matting, which finds a good trade-off between customization and automation. To overcome the key challenge of accurate foreground matching, we introduce IconMatting, an in-context matting model built upon a pre-trained text-to-image diffusion model. Conditioned on inter- and intra-similarity matching, IconMatting can make full use of reference context to generate accurate target alpha mattes. To benchmark the task, we also introduce a novel testing dataset ICM-$57$, covering 57 groups of real-world images. Quantitative and qualitative results on the ICM-57 testing set show that IconMatting rivals the accuracy of trimap-based matting while retaining the automation level akin to automatic matting. Code is available at https://github.com/tiny-smart/in-context-matting
RetMIL: Retentive Multiple Instance Learning for Histopathological Whole Slide Image Classification
Mar 16, 2024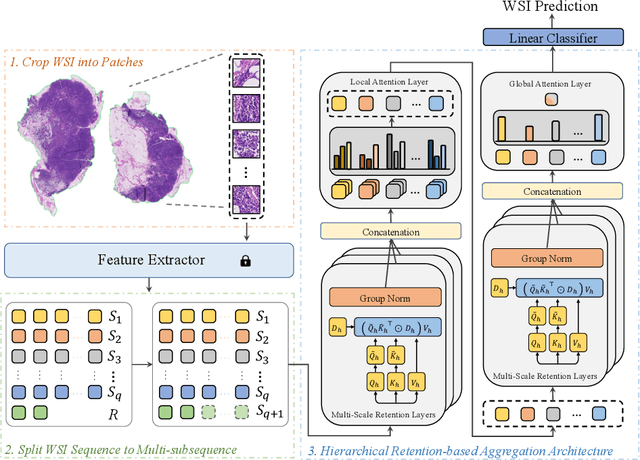
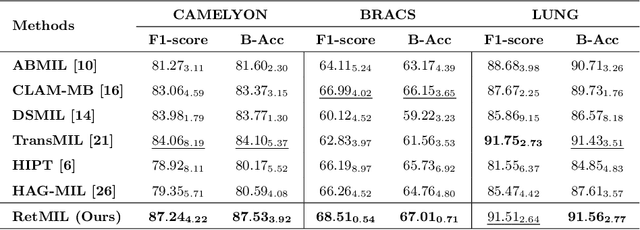
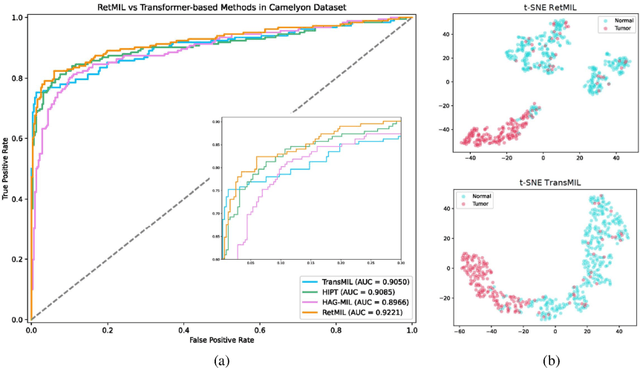
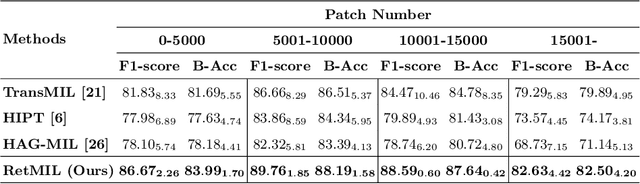
Histopathological whole slide image (WSI) analysis with deep learning has become a research focus in computational pathology. The current paradigm is mainly based on multiple instance learning (MIL), in which approaches with Transformer as the backbone are well discussed. These methods convert WSI tasks into sequence tasks by representing patches as tokens in the WSI sequence. However, the feature complexity brought by high heterogeneity and the ultra-long sequences brought by gigapixel size makes Transformer-based MIL suffer from the challenges of high memory consumption, slow inference speed, and lack of performance. To this end, we propose a retentive MIL method called RetMIL, which processes WSI sequences through hierarchical feature propagation structure. At the local level, the WSI sequence is divided into multiple subsequences. Tokens of each subsequence are updated through a parallel linear retention mechanism and aggregated utilizing an attention layer. At the global level, subsequences are fused into a global sequence, then updated through a serial retention mechanism, and finally the slide-level representation is obtained through a global attention pooling. We conduct experiments on two public CAMELYON and BRACS datasets and an public-internal LUNG dataset, confirming that RetMIL not only achieves state-of-the-art performance but also significantly reduces computational overhead. Our code will be accessed shortly.
Implicit Style-Content Separation using B-LoRA
Mar 21, 2024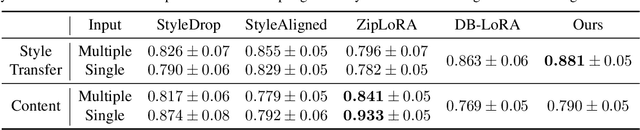

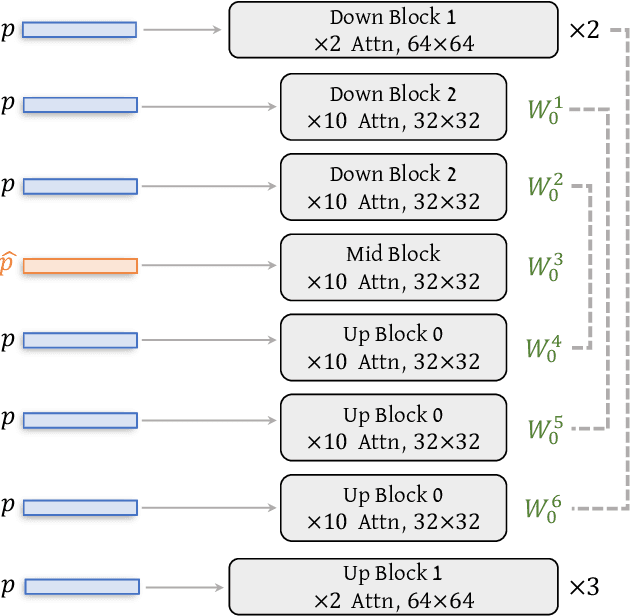

Image stylization involves manipulating the visual appearance and texture (style) of an image while preserving its underlying objects, structures, and concepts (content). The separation of style and content is essential for manipulating the image's style independently from its content, ensuring a harmonious and visually pleasing result. Achieving this separation requires a deep understanding of both the visual and semantic characteristics of images, often necessitating the training of specialized models or employing heavy optimization. In this paper, we introduce B-LoRA, a method that leverages LoRA (Low-Rank Adaptation) to implicitly separate the style and content components of a single image, facilitating various image stylization tasks. By analyzing the architecture of SDXL combined with LoRA, we find that jointly learning the LoRA weights of two specific blocks (referred to as B-LoRAs) achieves style-content separation that cannot be achieved by training each B-LoRA independently. Consolidating the training into only two blocks and separating style and content allows for significantly improving style manipulation and overcoming overfitting issues often associated with model fine-tuning. Once trained, the two B-LoRAs can be used as independent components to allow various image stylization tasks, including image style transfer, text-based image stylization, consistent style generation, and style-content mixing.
Enhancing Adversarial Training with Prior Knowledge Distillation for Robust Image Compression
Mar 11, 2024
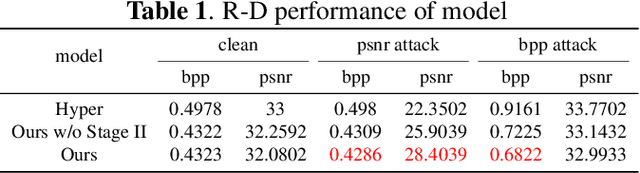
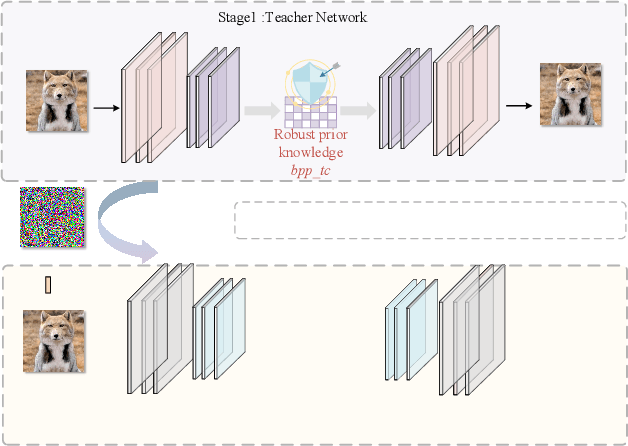
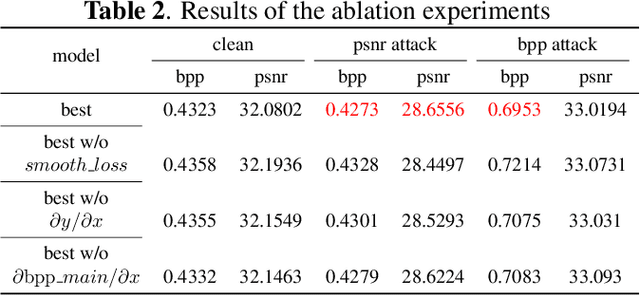
Deep neural network-based image compression (NIC) has achieved excellent performance, but NIC method models have been shown to be susceptible to backdoor attacks. Adversarial training has been validated in image compression models as a common method to enhance model robustness. However, the improvement effect of adversarial training on model robustness is limited. In this paper, we propose a prior knowledge-guided adversarial training framework for image compression models. Specifically, first, we propose a gradient regularization constraint for training robust teacher models. Subsequently, we design a knowledge distillation based strategy to generate a priori knowledge from the teacher model to the student model for guiding adversarial training. Experimental results show that our method improves the reconstruction quality by about 9dB when the Kodak dataset is elected as the backdoor attack object for psnr attack. Compared with Ma2023, our method has a 5dB higher PSNR output at high bitrate points.
Learning User Embeddings from Human Gaze for Personalised Saliency Prediction
Mar 26, 2024
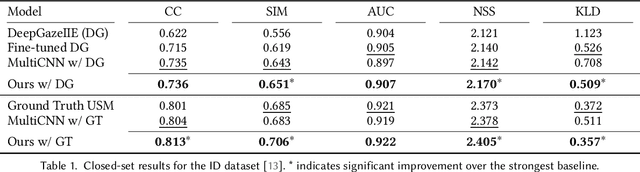
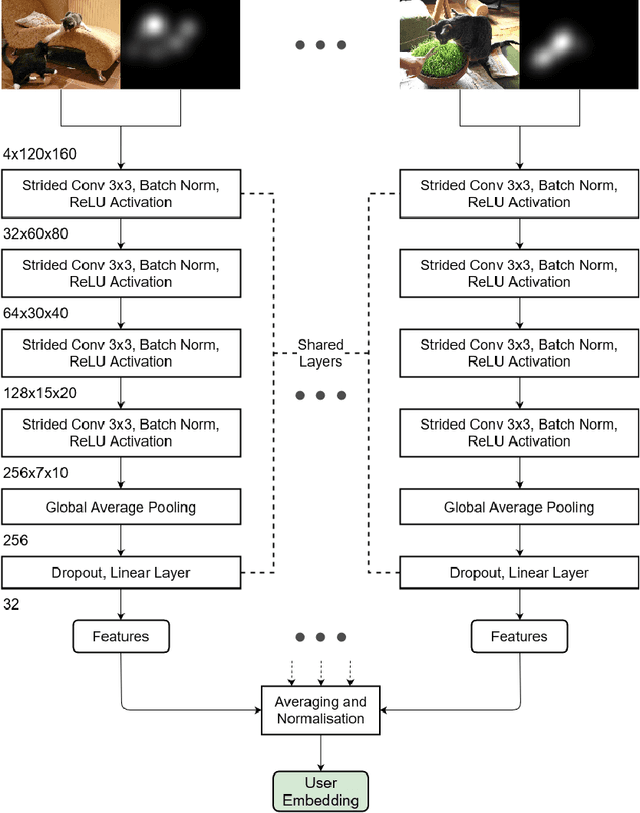
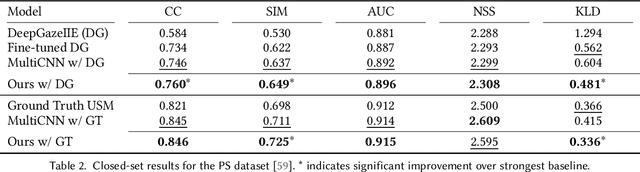
Reusable embeddings of user behaviour have shown significant performance improvements for the personalised saliency prediction task. However, prior works require explicit user characteristics and preferences as input, which are often difficult to obtain. We present a novel method to extract user embeddings from pairs of natural images and corresponding saliency maps generated from a small amount of user-specific eye tracking data. At the core of our method is a Siamese convolutional neural encoder that learns the user embeddings by contrasting the image and personal saliency map pairs of different users. Evaluations on two public saliency datasets show that the generated embeddings have high discriminative power, are effective at refining universal saliency maps to the individual users, and generalise well across users and images. Finally, based on our model's ability to encode individual user characteristics, our work points towards other applications that can benefit from reusable embeddings of gaze behaviour.
Geometric Generative Models based on Morphological Equivariant PDEs and GANs
Mar 25, 2024Content and image generation consist in creating or generating data from noisy information by extracting specific features such as texture, edges, and other thin image structures. We are interested here in generative models, and two main problems are addressed. Firstly, the improvements of specific feature extraction while accounting at multiscale levels intrinsic geometric features; and secondly, the equivariance of the network to reduce its complexity and provide a geometric interpretability. To proceed, we propose a geometric generative model based on an equivariant partial differential equation (PDE) for group convolution neural networks (G-CNNs), so called PDE-G-CNNs, built on morphology operators and generative adversarial networks (GANs). Equivariant morphological PDE layers are composed of multiscale dilations and erosions formulated in Riemannian manifolds, while group symmetries are defined on a Lie group. We take advantage of the Lie group structure to properly integrate the equivariance in layers, and are able to use the Riemannian metric to solve the multiscale morphological operations. Each point of the Lie group is associated with a unique point in the manifold, which helps us derive a metric on the Riemannian manifold from a tensor field invariant under the Lie group so that the induced metric has the same symmetries. The proposed geometric morphological GAN (GM-GAN) is obtained by using the proposed morphological equivariant convolutions in PDE-G-CNNs to bring nonlinearity in classical CNNs. GM-GAN is evaluated on MNIST data and compared with GANs. Preliminary results show that GM-GAN model outperforms classical GAN.
SemRoDe: Macro Adversarial Training to Learn Representations That are Robust to Word-Level Attacks
Mar 27, 2024Language models (LMs) are indispensable tools for natural language processing tasks, but their vulnerability to adversarial attacks remains a concern. While current research has explored adversarial training techniques, their improvements to defend against word-level attacks have been limited. In this work, we propose a novel approach called Semantic Robust Defence (SemRoDe), a Macro Adversarial Training strategy to enhance the robustness of LMs. Drawing inspiration from recent studies in the image domain, we investigate and later confirm that in a discrete data setting such as language, adversarial samples generated via word substitutions do indeed belong to an adversarial domain exhibiting a high Wasserstein distance from the base domain. Our method learns a robust representation that bridges these two domains. We hypothesize that if samples were not projected into an adversarial domain, but instead to a domain with minimal shift, it would improve attack robustness. We align the domains by incorporating a new distance-based objective. With this, our model is able to learn more generalized representations by aligning the model's high-level output features and therefore better handling unseen adversarial samples. This method can be generalized across word embeddings, even when they share minimal overlap at both vocabulary and word-substitution levels. To evaluate the effectiveness of our approach, we conduct experiments on BERT and RoBERTa models on three datasets. The results demonstrate promising state-of-the-art robustness.
A Picture is Worth 500 Labels: A Case Study of Demographic Disparities in Local Machine Learning Models for Instagram and TikTok
Mar 27, 2024Mobile apps have embraced user privacy by moving their data processing to the user's smartphone. Advanced machine learning (ML) models, such as vision models, can now locally analyze user images to extract insights that drive several functionalities. Capitalizing on this new processing model of locally analyzing user images, we analyze two popular social media apps, TikTok and Instagram, to reveal (1) what insights vision models in both apps infer about users from their image and video data and (2) whether these models exhibit performance disparities with respect to demographics. As vision models provide signals for sensitive technologies like age verification and facial recognition, understanding potential biases in these models is crucial for ensuring that users receive equitable and accurate services. We develop a novel method for capturing and evaluating ML tasks in mobile apps, overcoming challenges like code obfuscation, native code execution, and scalability. Our method comprises ML task detection, ML pipeline reconstruction, and ML performance assessment, specifically focusing on demographic disparities. We apply our methodology to TikTok and Instagram, revealing significant insights. For TikTok, we find issues in age and gender prediction accuracy, particularly for minors and Black individuals. In Instagram, our analysis uncovers demographic disparities in the extraction of over 500 visual concepts from images, with evidence of spurious correlations between demographic features and certain concepts.
Leveraging Foundation Models for Content-Based Medical Image Retrieval in Radiology
Mar 11, 2024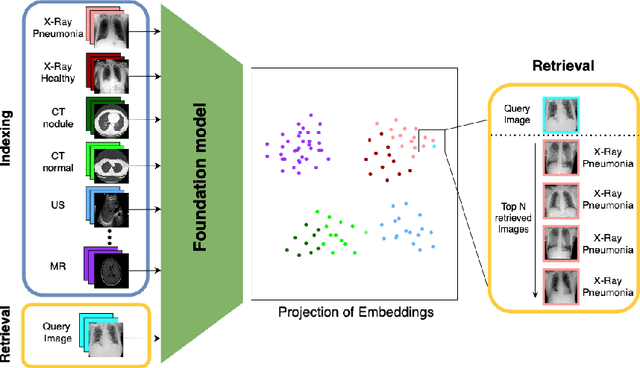
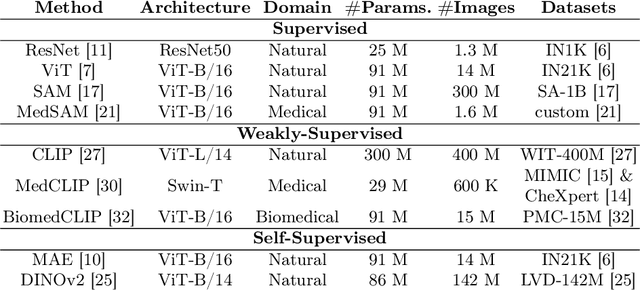
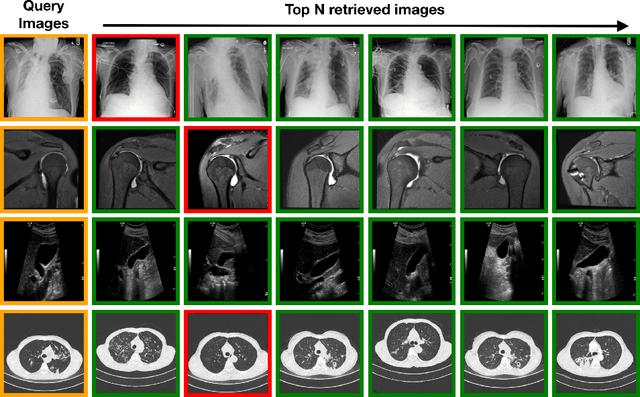
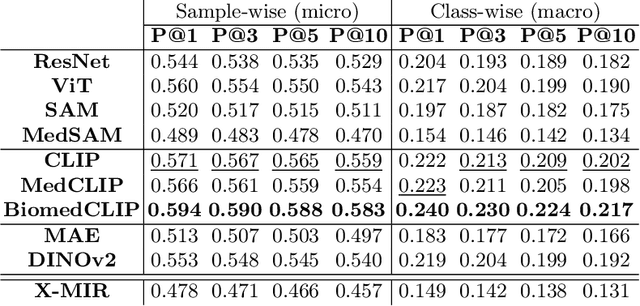
Content-based image retrieval (CBIR) has the potential to significantly improve diagnostic aid and medical research in radiology. Current CBIR systems face limitations due to their specialization to certain pathologies, limiting their utility. In response, we propose using vision foundation models as powerful and versatile off-the-shelf feature extractors for content-based medical image retrieval. By benchmarking these models on a comprehensive dataset of 1.6 million 2D radiological images spanning four modalities and 161 pathologies, we identify weakly-supervised models as superior, achieving a P@1 of up to 0.594. This performance not only competes with a specialized model but does so without the need for fine-tuning. Our analysis further explores the challenges in retrieving pathological versus anatomical structures, indicating that accurate retrieval of pathological features presents greater difficulty. Despite these challenges, our research underscores the vast potential of foundation models for CBIR in radiology, proposing a shift towards versatile, general-purpose medical image retrieval systems that do not require specific tuning.