 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
RICo: Rotate-Inpaint-Complete for Generalizable Scene Reconstruction
Jul 21, 2023
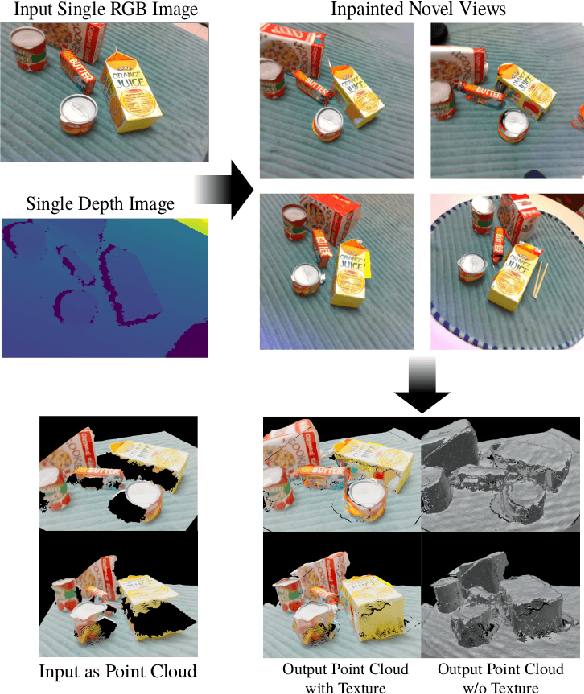
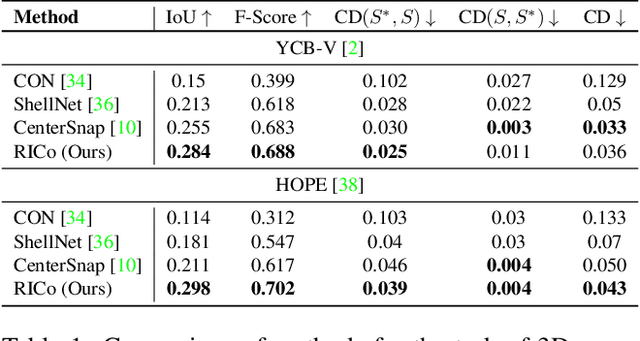
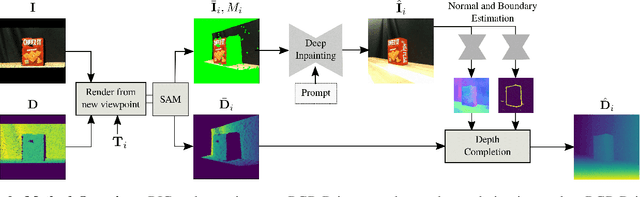
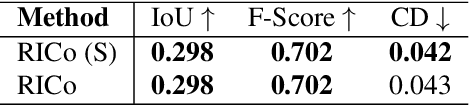
General scene reconstruction refers to the task of estimating the full 3D geometry and texture of a scene containing previously unseen objects. In many practical applications such as AR/VR, autonomous navigation, and robotics, only a single view of the scene may be available, making the scene reconstruction a very challenging task. In this paper, we present a method for scene reconstruction by structurally breaking the problem into two steps: rendering novel views via inpainting and 2D to 3D scene lifting. Specifically, we leverage the generalization capability of large language models to inpaint the missing areas of scene color images rendered from different views. Next, we lift these inpainted images to 3D by predicting normals of the inpainted image and solving for the missing depth values. By predicting for normals instead of depth directly, our method allows for robustness to changes in depth distributions and scale. With rigorous quantitative evaluation, we show that our method outperforms multiple baselines while providing generalization to novel objects and scenes.
Artificial Intelligence-Generated Terahertz Multi-Resonant Metasurfaces via Improved Transformer and CGAN Neural Networks
Jul 21, 2023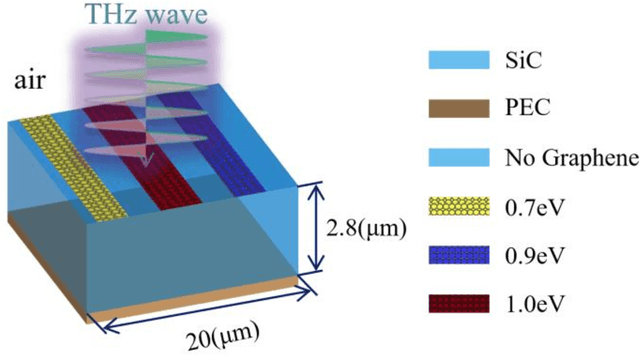
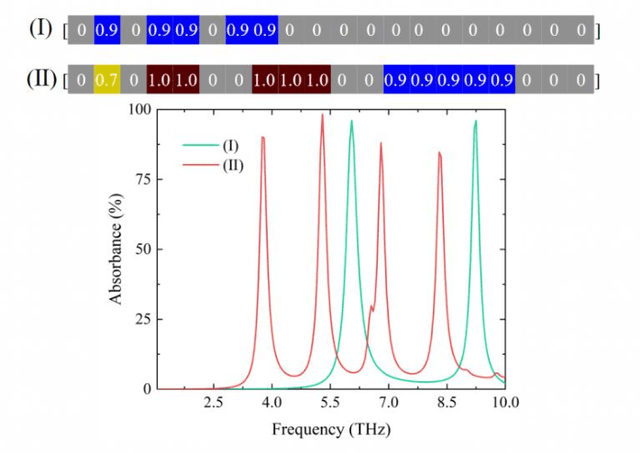
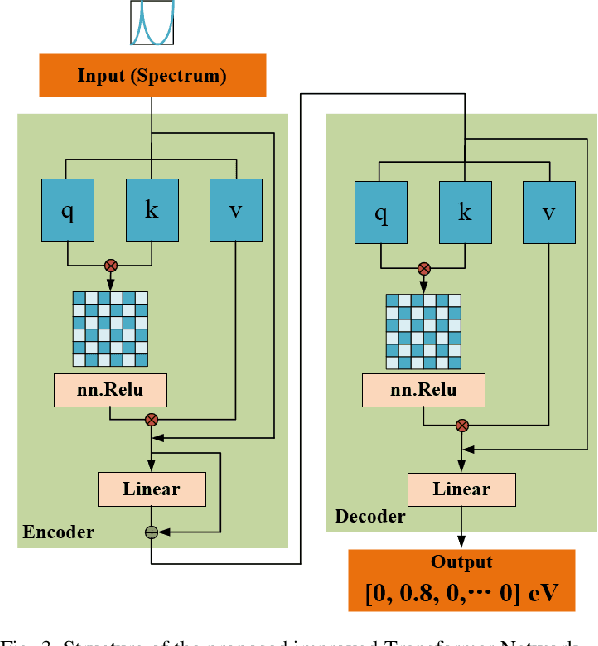
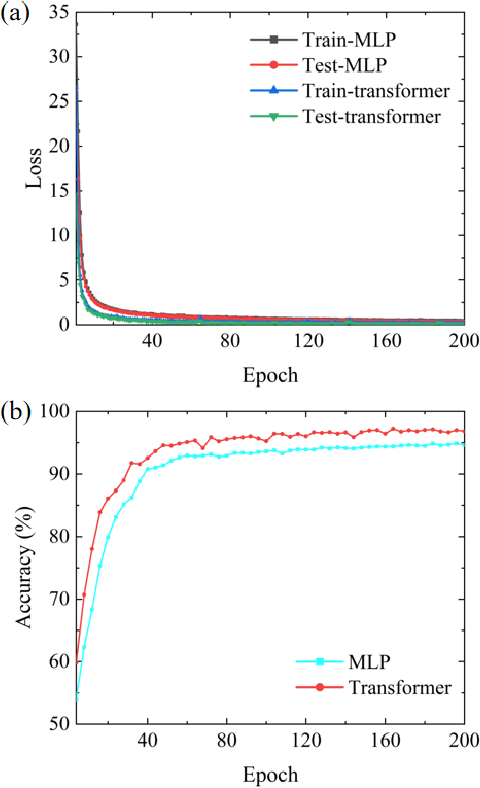
It is well known that the inverse design of terahertz (THz) multi-resonant graphene metasurfaces by using traditional deep neural networks (DNNs) has limited generalization ability. In this paper, we propose improved Transformer and conditional generative adversarial neural networks (CGAN) for the inverse design of graphene metasurfaces based upon THz multi-resonant absorption spectra. The improved Transformer can obtain higher accuracy and generalization performance in the StoV (Spectrum to Vector) design compared to traditional multilayer perceptron (MLP) neural networks, while the StoI (Spectrum to Image) design achieved through CGAN can provide more comprehensive information and higher accuracy than the StoV design obtained by MLP. Moreover, the improved CGAN can achieve the inverse design of graphene metasurface images directly from the desired multi-resonant absorption spectra. It is turned out that this work can finish facilitating the design process of artificial intelligence-generated metasurfaces (AIGM), and even provide a useful guide for developing complex THz metasurfaces based on 2D materials using generative neural networks.
KVN: Keypoints Voting Network with Differentiable RANSAC for Stereo Pose Estimation
Jul 21, 2023Object pose estimation is a fundamental computer vision task exploited in several robotics and augmented reality applications. Many established approaches rely on predicting 2D-3D keypoint correspondences using RANSAC (Random sample consensus) and estimating the object pose using the PnP (Perspective-n-Point) algorithm. Being RANSAC non-differentiable, correspondences cannot be directly learned in an end-to-end fashion. In this paper, we address the stereo image-based object pose estimation problem by (i) introducing a differentiable RANSAC layer into a well-known monocular pose estimation network; (ii) exploiting an uncertainty-driven multi-view PnP solver which can fuse information from multiple views. We evaluate our approach on a challenging public stereo object pose estimation dataset, yielding state-of-the-art results against other recent approaches. Furthermore, in our ablation study, we show that the differentiable RANSAC layer plays a significant role in the accuracy of the proposed method. We release with this paper the open-source implementation of our method.
Component-wise Power Estimation of Electrical Devices Using Thermal Imaging
Jul 18, 2023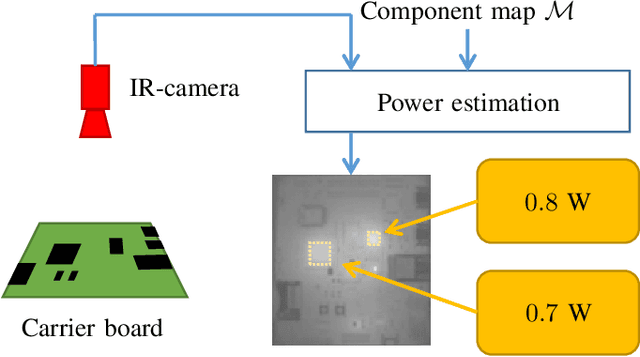
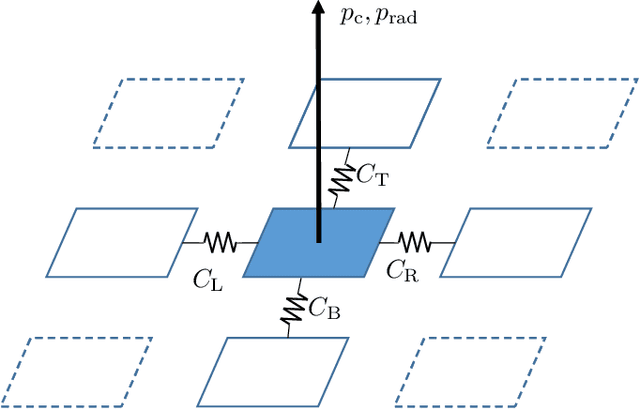
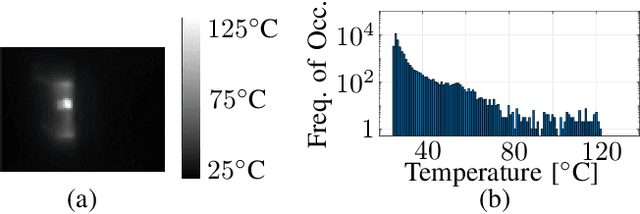
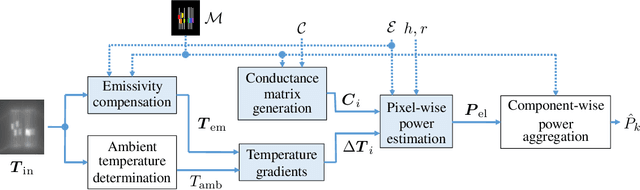
This paper presents a novel method to estimate the power consumption of distinct active components on an electronic carrier board by using thermal imaging. The components and the board can be made of heterogeneous material such as plastic, coated microchips, and metal bonds or wires, where a special coating for high emissivity is not required. The thermal images are recorded when the components on the board are dissipating power. In order to enable reliable estimates, a segmentation of the thermal image must be available that can be obtained by manual labeling, object detection methods, or exploiting layout information. Evaluations show that with low-resolution consumer infrared cameras and dissipated powers larger than 300mW, mean estimation errors of 10% can be achieved.
* 10 pages, 8 figures
Towards Automated Semantic Segmentation in Mammography Images
Jul 18, 2023
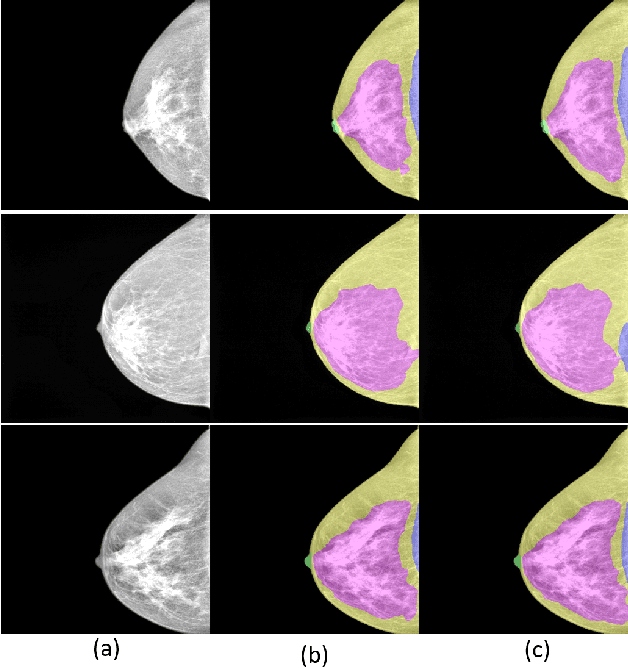
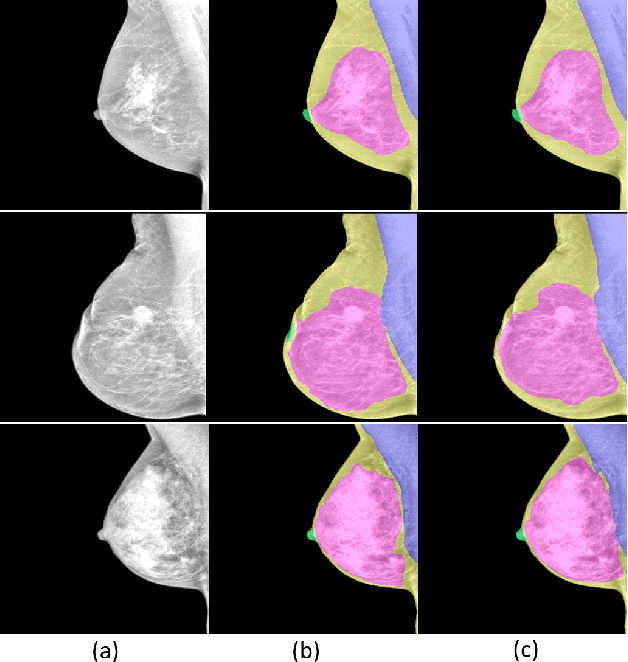

Mammography images are widely used to detect non-palpable breast lesions or nodules, preventing cancer and providing the opportunity to plan interventions when necessary. The identification of some structures of interest is essential to make a diagnosis and evaluate image adequacy. Thus, computer-aided detection systems can be helpful in assisting medical interpretation by automatically segmenting these landmark structures. In this paper, we propose a deep learning-based framework for the segmentation of the nipple, the pectoral muscle, the fibroglandular tissue, and the fatty tissue on standard-view mammography images. We introduce a large private segmentation dataset and extensive experiments considering different deep-learning model architectures. Our experiments demonstrate accurate segmentation performance on variate and challenging cases, showing that this framework can be integrated into clinical practice.
Patch-DrosoNet: Classifying Image Partitions With Fly-Inspired Models For Lightweight Visual Place Recognition
May 09, 2023
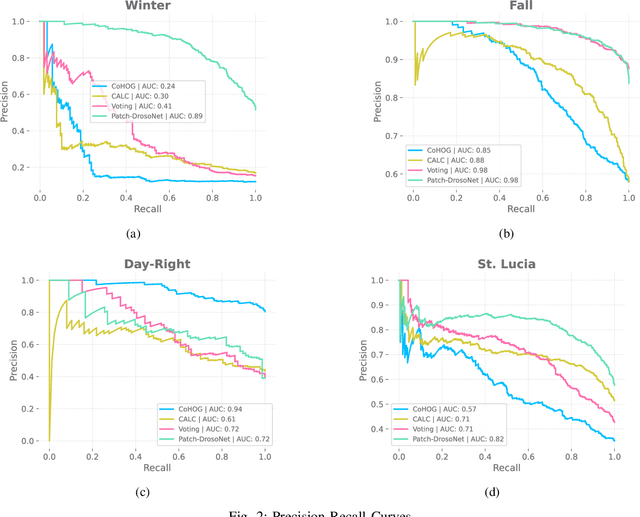
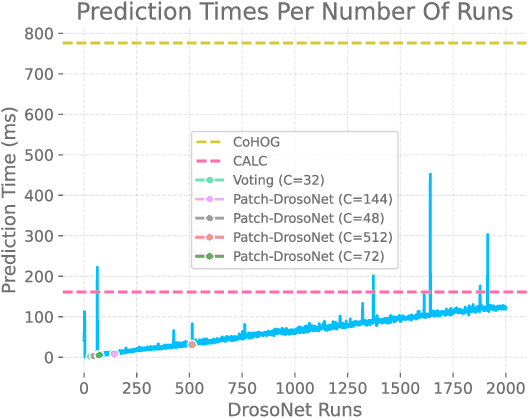
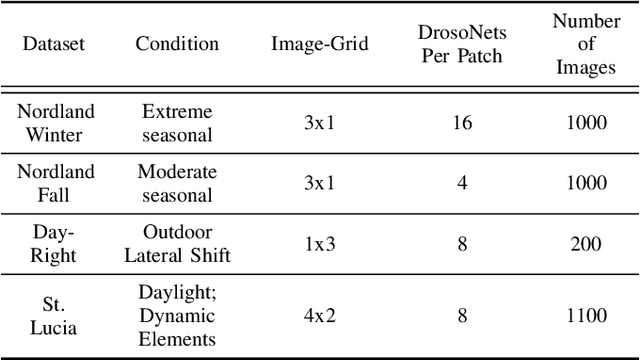
Visual place recognition (VPR) enables autonomous systems to localize themselves within an environment using image information. While Convolution Neural Networks (CNNs) currently dominate state-of-the-art VPR performance, their high computational requirements make them unsuitable for platforms with budget or size constraints. This has spurred the development of lightweight algorithms, such as DrosoNet, which employs a voting system based on multiple bio-inspired units. In this paper, we present a novel training approach for DrosoNet, wherein separate models are trained on distinct regions of a reference image, allowing them to specialize in the visual features of that specific section. Additionally, we introduce a convolutional-like prediction method, in which each DrosoNet unit generates a set of place predictions for each portion of the query image. These predictions are then combined using the previously introduced voting system. Our approach significantly improves upon the VPR performance of previous work while maintaining an extremely compact and lightweight algorithm, making it suitable for resource-constrained platforms.
Multi-code deep image prior based plug-and-play ADMM for image denoising and CT reconstruction
Apr 12, 2023

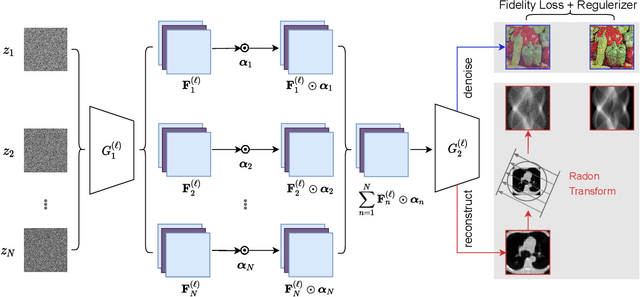

The use of the convolutional neural network based prior in imaging inverse problems has become increasingly popular. Current state-of-the-art methods, however, can easily result in severe overfitting, which makes a number of early stopping techniques necessary to eliminate the overfitting problem. To motivate our work, we review some existing approaches to image priors. We find that the deep image prior in combined with the handcrafted prior has an outstanding performance in terms of interpretability and representability. We propose a multi-code deep image prior, a multiple latent codes variant of the deep image prior, which can be utilized to eliminate overfitting and is also robust to the different numbers of the latent codes. Due to the non-differentiability of the handcrafted prior, we use the alternative direction method of multipliers (ADMM) algorithm. We compare the performance of the proposed method on an image denoising problem and a highly ill-posed CT reconstruction problem against the existing state-of-the-art methods, including PnP-DIP, DIP-VBTV and ADMM DIP-WTV methods. For the CelebA dataset denoising, we obtain 1.46 dB peak signal to noise ratio improvement against all compared methods. For the CT reconstruction, the corresponding average improvement of three test images is 4.3 dB over DIP, and 1.7 dB over ADMM DIP-WTV, and 1.2 dB over PnP-DIP along with a significant improvement in the structural similarity index.
Coarse-to-Fine Contrastive Learning in Image-Text-Graph Space for Improved Vision-Language Compositionality
May 23, 2023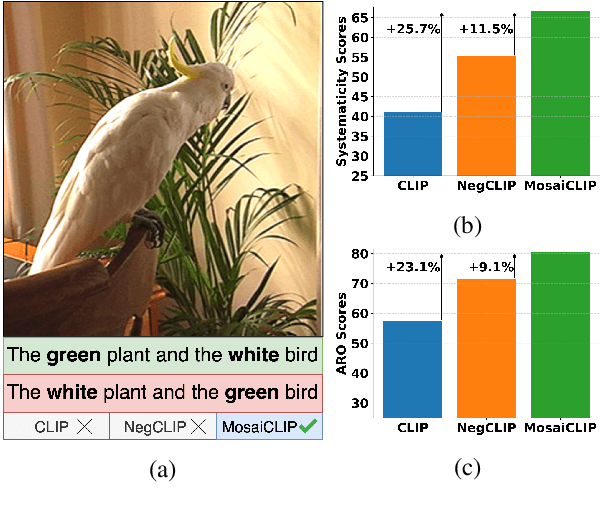
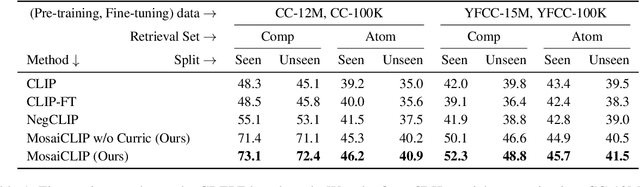
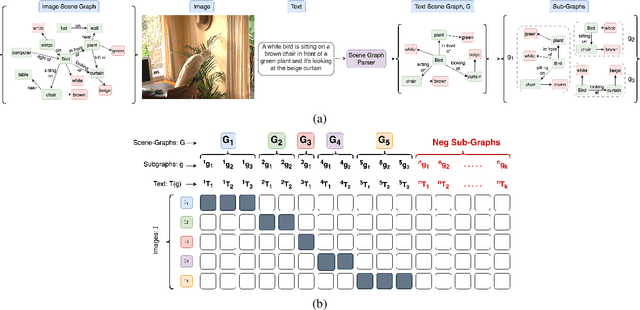
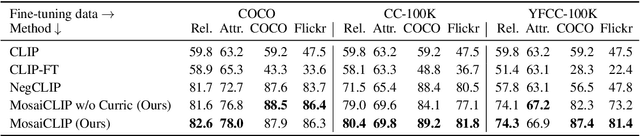
Contrastively trained vision-language models have achieved remarkable progress in vision and language representation learning, leading to state-of-the-art models for various downstream multimodal tasks. However, recent research has highlighted severe limitations of these models in their ability to perform compositional reasoning over objects, attributes, and relations. Scene graphs have emerged as an effective way to understand images compositionally. These are graph-structured semantic representations of images that contain objects, their attributes, and relations with other objects in a scene. In this work, we consider the scene graph parsed from text as a proxy for the image scene graph and propose a graph decomposition and augmentation framework along with a coarse-to-fine contrastive learning objective between images and text that aligns sentences of various complexities to the same image. Along with this, we propose novel negative mining techniques in the scene graph space for improving attribute binding and relation understanding. Through extensive experiments, we demonstrate the effectiveness of our approach that significantly improves attribute binding, relation understanding, systematic generalization, and productivity on multiple recently proposed benchmarks (For example, improvements upto $18\%$ for systematic generalization, $16.5\%$ for relation understanding over a strong baseline), while achieving similar or better performance than CLIP on various general multimodal tasks.
Image Registration of In Vivo Micro-Ultrasound and Ex Vivo Pseudo-Whole Mount Histopathology Images of the Prostate: A Proof-of-Concept Study
May 31, 2023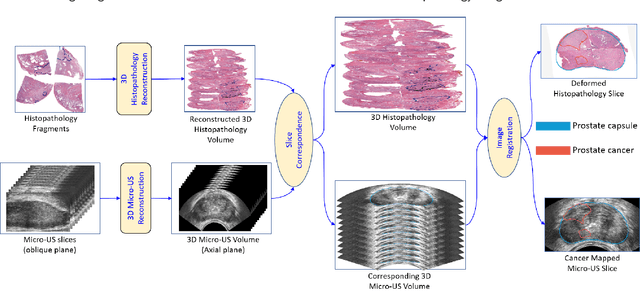
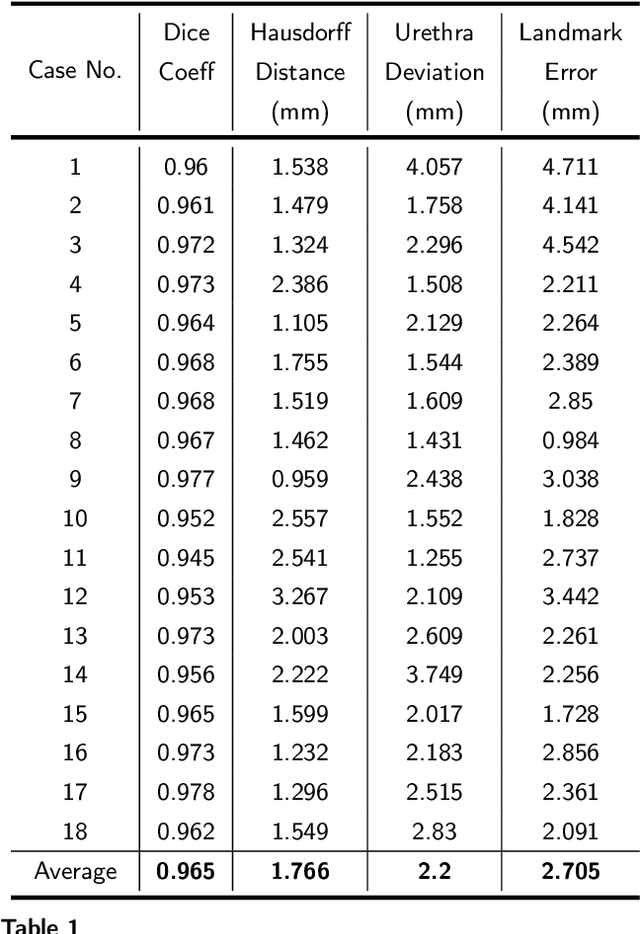
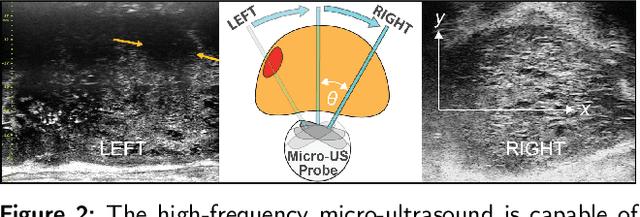
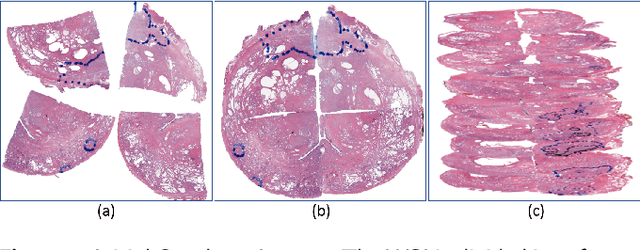
Early diagnosis of prostate cancer significantly improves a patient's 5-year survival rate. Biopsy of small prostate cancers is improved with image-guided biopsy. MRI-ultrasound fusion-guided biopsy is sensitive to smaller tumors but is underutilized due to the high cost of MRI and fusion equipment. Micro-ultrasound (micro-US), a novel high-resolution ultrasound technology, provides a cost-effective alternative to MRI while delivering comparable diagnostic accuracy. However, the interpretation of micro-US is challenging due to subtle gray scale changes indicating cancer vs normal tissue. This challenge can be addressed by training urologists with a large dataset of micro-US images containing the ground truth cancer outlines. Such a dataset can be mapped from surgical specimens (histopathology) onto micro-US images via image registration. In this paper, we present a semi-automated pipeline for registering in vivo micro-US images with ex vivo whole-mount histopathology images. Our pipeline begins with the reconstruction of pseudo-whole-mount histopathology images and a 3D micro-US volume. Each pseudo-whole-mount histopathology image is then registered with the corresponding axial micro-US slice using a two-stage approach that estimates an affine transformation followed by a deformable transformation. We evaluated our registration pipeline using micro-US and histopathology images from 18 patients who underwent radical prostatectomy. The results showed a Dice coefficient of 0.94 and a landmark error of 2.7 mm, indicating the accuracy of our registration pipeline. This proof-of-concept study demonstrates the feasibility of accurately aligning micro-US and histopathology images. To promote transparency and collaboration in research, we will make our code and dataset publicly available.
Simplified Concrete Dropout -- Improving the Generation of Attribution Masks for Fine-grained Classification
Jul 27, 2023


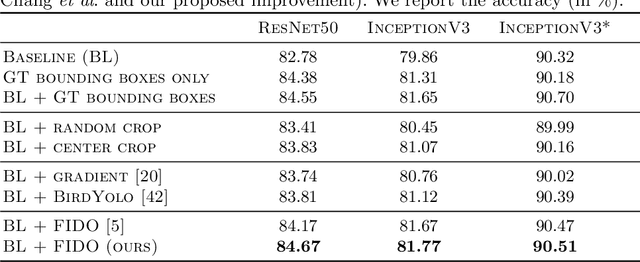
Fine-grained classification is a particular case of a classification problem, aiming to classify objects that share the visual appearance and can only be distinguished by subtle differences. Fine-grained classification models are often deployed to determine animal species or individuals in automated animal monitoring systems. Precise visual explanations of the model's decision are crucial to analyze systematic errors. Attention- or gradient-based methods are commonly used to identify regions in the image that contribute the most to the classification decision. These methods deliver either too coarse or too noisy explanations, unsuitable for identifying subtle visual differences reliably. However, perturbation-based methods can precisely identify pixels causally responsible for the classification result. Fill-in of the dropout (FIDO) algorithm is one of those methods. It utilizes the concrete dropout (CD) to sample a set of attribution masks and updates the sampling parameters based on the output of the classification model. A known problem of the algorithm is a high variance in the gradient estimates, which the authors have mitigated until now by mini-batch updates of the sampling parameters. This paper presents a solution to circumvent these computational instabilities by simplifying the CD sampling and reducing reliance on large mini-batch sizes. First, it allows estimating the parameters with smaller mini-batch sizes without losing the quality of the estimates but with a reduced computational effort. Furthermore, our solution produces finer and more coherent attribution masks. Finally, we use the resulting attribution masks to improve the classification performance of a trained model without additional fine-tuning of the model.