 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DETR Doesn't Need Multi-Scale or Locality Design
Aug 03, 2023
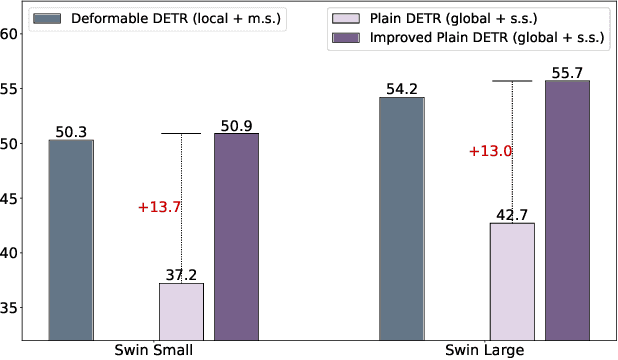
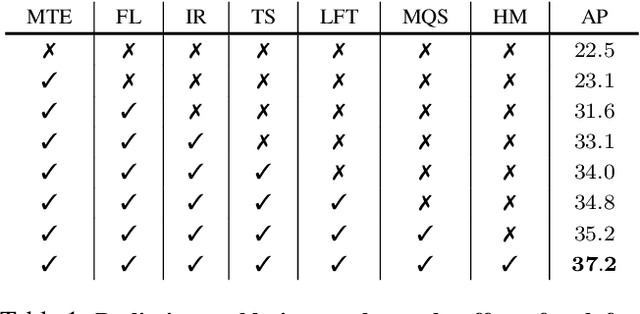

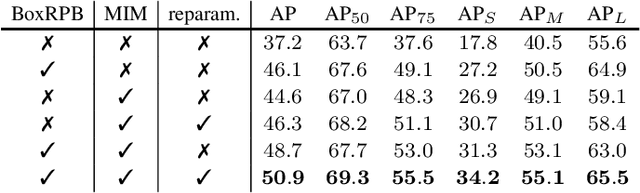
This paper presents an improved DETR detector that maintains a "plain" nature: using a single-scale feature map and global cross-attention calculations without specific locality constraints, in contrast to previous leading DETR-based detectors that reintroduce architectural inductive biases of multi-scale and locality into the decoder. We show that two simple technologies are surprisingly effective within a plain design to compensate for the lack of multi-scale feature maps and locality constraints. The first is a box-to-pixel relative position bias (BoxRPB) term added to the cross-attention formulation, which well guides each query to attend to the corresponding object region while also providing encoding flexibility. The second is masked image modeling (MIM)-based backbone pre-training which helps learn representation with fine-grained localization ability and proves crucial for remedying dependencies on the multi-scale feature maps. By incorporating these technologies and recent advancements in training and problem formation, the improved "plain" DETR showed exceptional improvements over the original DETR detector. By leveraging the Object365 dataset for pre-training, it achieved 63.9 mAP accuracy using a Swin-L backbone, which is highly competitive with state-of-the-art detectors which all heavily rely on multi-scale feature maps and region-based feature extraction. Code is available at https://github.com/impiga/Plain-DETR .
Adapt and Align to Improve Zero-Shot Sketch-Based Image Retrieval
May 09, 2023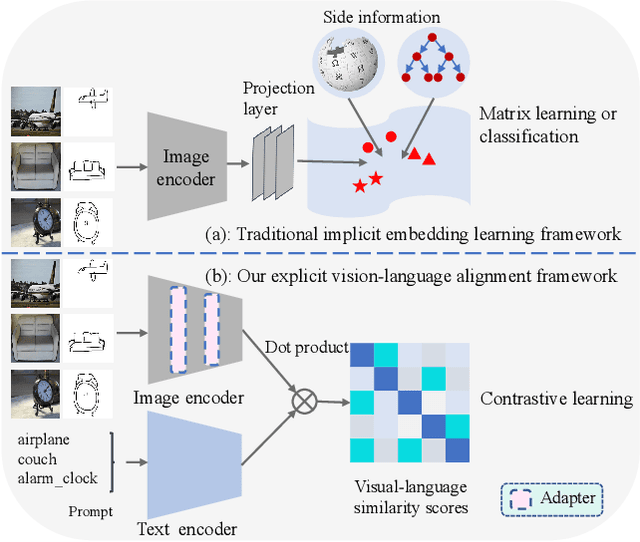
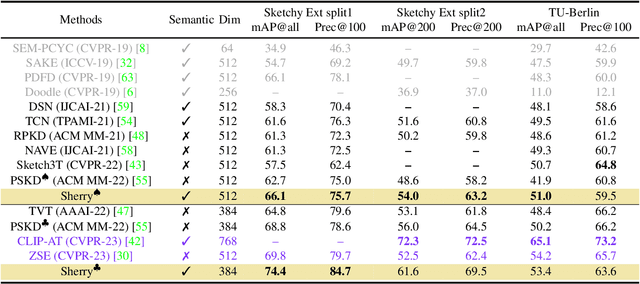
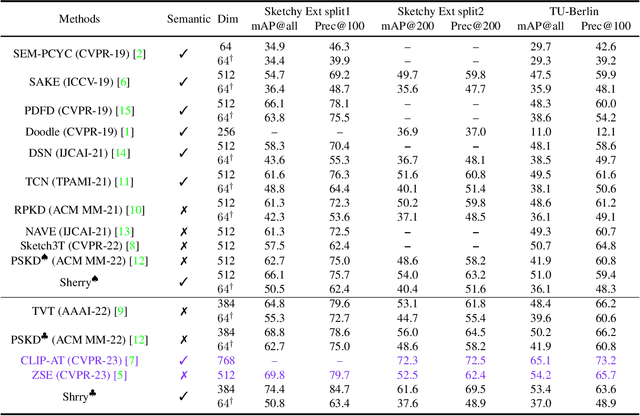
Zero-shot sketch-based image retrieval (ZS-SBIR) is challenging due to the cross-domain nature of sketches and photos, as well as the semantic gap between seen and unseen image distributions. Previous methods fine-tune pre-trained models with various side information and learning strategies to learn a compact feature space that (\romannumeral1) is shared between the sketch and photo domains and (\romannumeral2) bridges seen and unseen classes. However, these efforts are inadequate in adapting domains and transferring knowledge from seen to unseen classes. In this paper, we present an effective \emph{``Adapt and Align''} approach to address the key challenges. Specifically, we insert simple and lightweight domain adapters to learn new abstract concepts of the sketch domain and improve cross-domain representation capabilities. Inspired by recent advances in image-text foundation models (\textit{e.g.}, CLIP) on zero-shot scenarios, we explicitly align the learned image embedding with a more semantic text embedding to achieve the desired knowledge transfer from seen to unseen classes. Extensive experiments on three benchmark datasets and two popular backbones demonstrate the superiority of our method in terms of retrieval accuracy and flexibility.
SEED-Bench: Benchmarking Multimodal LLMs with Generative Comprehension
Aug 02, 2023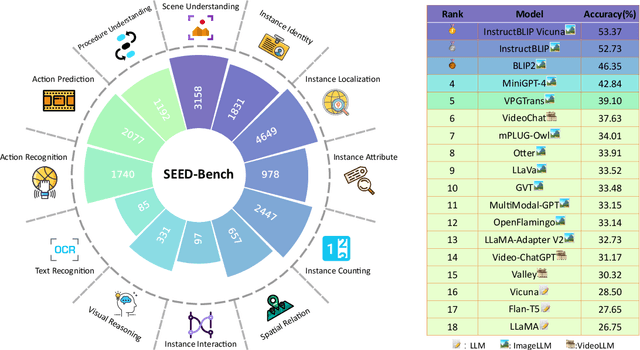

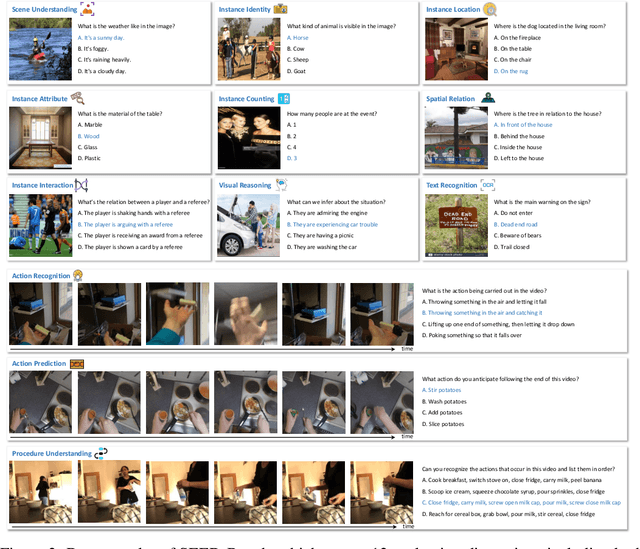
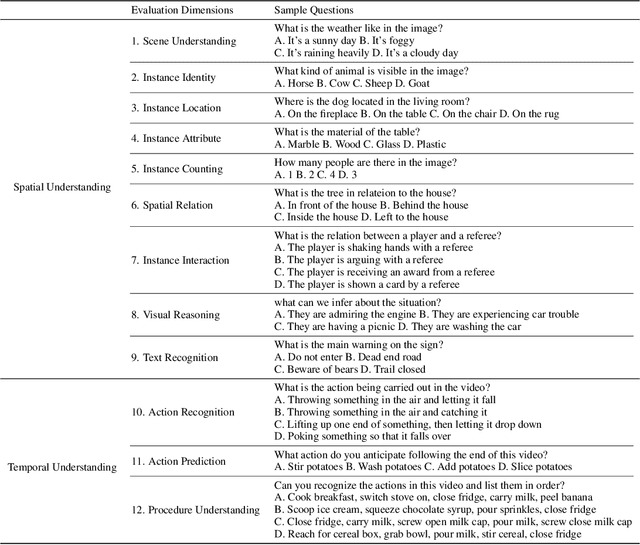
Based on powerful Large Language Models (LLMs), recent generative Multimodal Large Language Models (MLLMs) have gained prominence as a pivotal research area, exhibiting remarkable capability for both comprehension and generation. In this work, we address the evaluation of generative comprehension in MLLMs as a preliminary step towards a comprehensive assessment of generative models, by introducing a benchmark named SEED-Bench. SEED-Bench consists of 19K multiple choice questions with accurate human annotations (x 6 larger than existing benchmarks), which spans 12 evaluation dimensions including the comprehension of both the image and video modality. We develop an advanced pipeline for generating multiple-choice questions that target specific evaluation dimensions, integrating both automatic filtering and manual verification processes. Multiple-choice questions with groundtruth options derived from human annotation enables an objective and efficient assessment of model performance, eliminating the need for human or GPT intervention during evaluation. We further evaluate the performance of 18 models across all 12 dimensions, covering both the spatial and temporal understanding. By revealing the limitations of existing MLLMs through evaluation results, we aim for SEED-Bench to provide insights for motivating future research. We will launch and consistently maintain a leaderboard to provide a platform for the community to assess and investigate model capability.
Incorporating Season and Solar Specificity into Renderings made by a NeRF Architecture using Satellite Images
Aug 02, 2023As a result of Shadow NeRF and Sat-NeRF, it is possible to take the solar angle into account in a NeRF-based framework for rendering a scene from a novel viewpoint using satellite images for training. Our work extends those contributions and shows how one can make the renderings season-specific. Our main challenge was creating a Neural Radiance Field (NeRF) that could render seasonal features independently of viewing angle and solar angle while still being able to render shadows. We teach our network to render seasonal features by introducing one more input variable -- time of the year. However, the small training datasets typical of satellite imagery can introduce ambiguities in cases where shadows are present in the same location for every image of a particular season. We add additional terms to the loss function to discourage the network from using seasonal features for accounting for shadows. We show the performance of our network on eight Areas of Interest containing images captured by the Maxar WorldView-3 satellite. This evaluation includes tests measuring the ability of our framework to accurately render novel views, generate height maps, predict shadows, and specify seasonal features independently from shadows. Our ablation studies justify the choices made for network design parameters.
Push the Boundary of SAM: A Pseudo-label Correction Framework for Medical Segmentation
Aug 02, 2023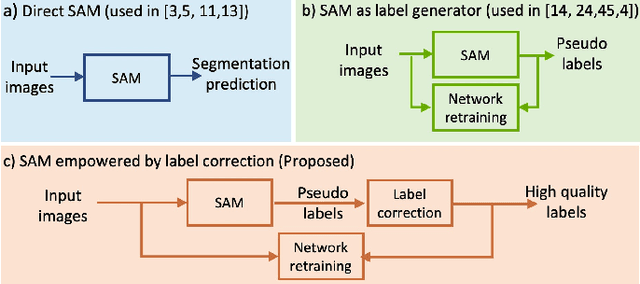
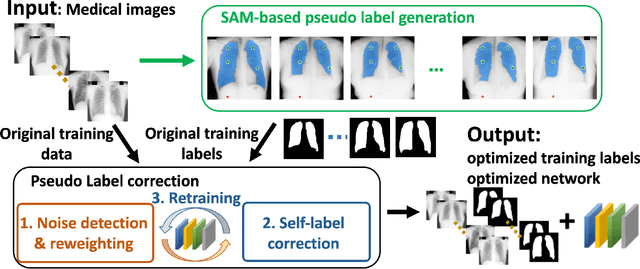
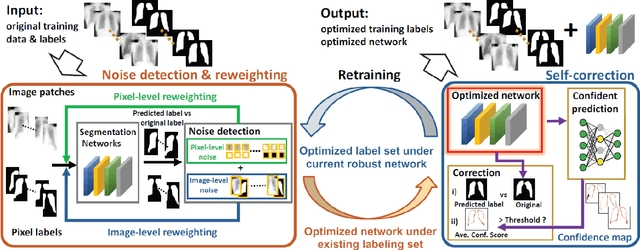
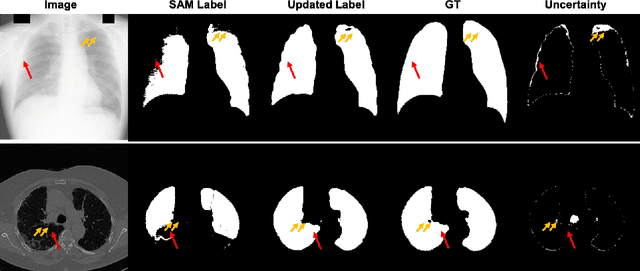
Segment anything model (SAM) has emerged as the leading approach for zero-shot learning in segmentation, offering the advantage of avoiding pixel-wise annotation. It is particularly appealing in medical image segmentation where annotation is laborious and expertise-demanding. However, the direct application of SAM often yields inferior results compared to conventional fully supervised segmentation networks. While using SAM generated pseudo label could also benefit the training of fully supervised segmentation, the performance is limited by the quality of pseudo labels. In this paper, we propose a novel label corruption to push the boundary of SAM-based segmentation. Our model utilizes a novel noise detection module to distinguish between noisy labels from clean labels. This enables us to correct the noisy labels using an uncertainty-based self-correction module, thereby enriching the clean training set. Finally, we retrain the network with updated labels to optimize its weights for future predictions. One key advantage of our model is its ability to train deep networks using SAM-generated pseudo labels without relying on a subset of expert-level annotations. We demonstrate the effectiveness of our proposed model on both X-ray and lung CT datasets, indicating its ability to improve segmentation accuracy and outperform baseline methods in label correction.
Dynamic Token Pruning in Plain Vision Transformers for Semantic Segmentation
Aug 02, 2023
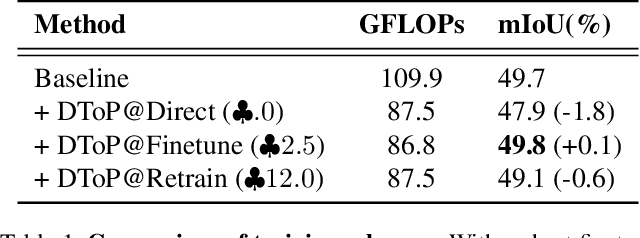
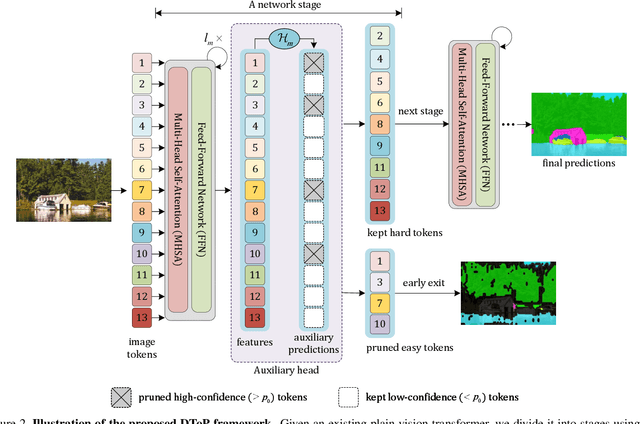
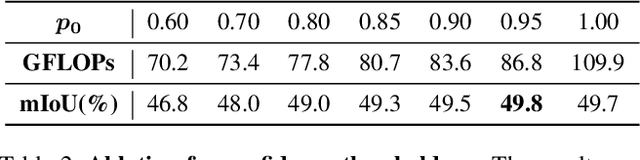
Vision transformers have achieved leading performance on various visual tasks yet still suffer from high computational complexity. The situation deteriorates in dense prediction tasks like semantic segmentation, as high-resolution inputs and outputs usually imply more tokens involved in computations. Directly removing the less attentive tokens has been discussed for the image classification task but can not be extended to semantic segmentation since a dense prediction is required for every patch. To this end, this work introduces a Dynamic Token Pruning (DToP) method based on the early exit of tokens for semantic segmentation. Motivated by the coarse-to-fine segmentation process by humans, we naturally split the widely adopted auxiliary-loss-based network architecture into several stages, where each auxiliary block grades every token's difficulty level. We can finalize the prediction of easy tokens in advance without completing the entire forward pass. Moreover, we keep $k$ highest confidence tokens for each semantic category to uphold the representative context information. Thus, computational complexity will change with the difficulty of the input, akin to the way humans do segmentation. Experiments suggest that the proposed DToP architecture reduces on average $20\% - 35\%$ of computational cost for current semantic segmentation methods based on plain vision transformers without accuracy degradation.
DISA: DIfferentiable Similarity Approximation for Universal Multimodal Registration
Jul 19, 2023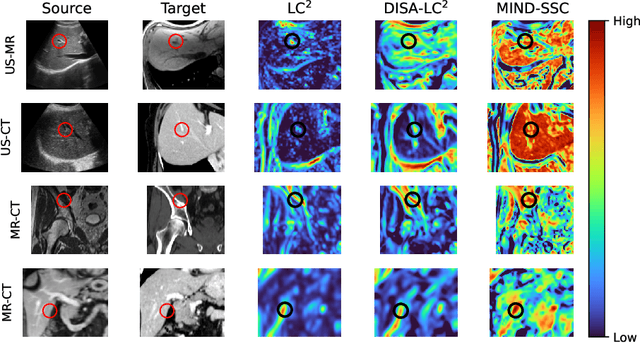
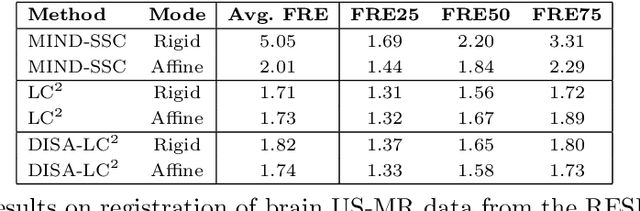
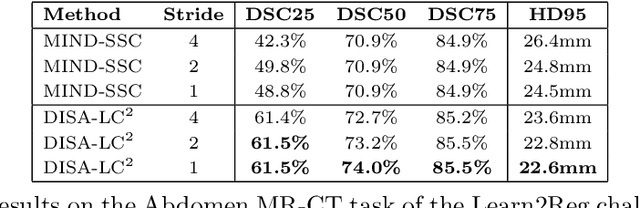
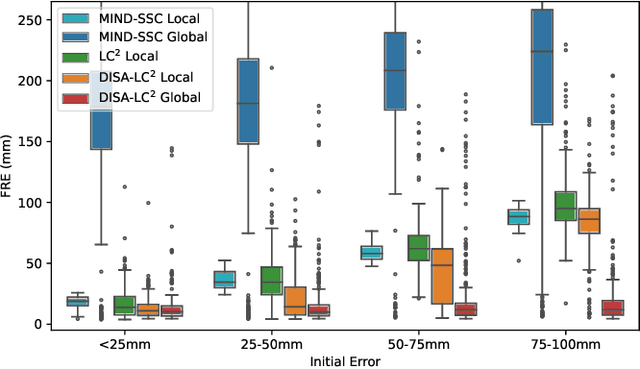
Multimodal image registration is a challenging but essential step for numerous image-guided procedures. Most registration algorithms rely on the computation of complex, frequently non-differentiable similarity metrics to deal with the appearance discrepancy of anatomical structures between imaging modalities. Recent Machine Learning based approaches are limited to specific anatomy-modality combinations and do not generalize to new settings. We propose a generic framework for creating expressive cross-modal descriptors that enable fast deformable global registration. We achieve this by approximating existing metrics with a dot-product in the feature space of a small convolutional neural network (CNN) which is inherently differentiable can be trained without registered data. Our method is several orders of magnitude faster than local patch-based metrics and can be directly applied in clinical settings by replacing the similarity measure with the proposed one. Experiments on three different datasets demonstrate that our approach generalizes well beyond the training data, yielding a broad capture range even on unseen anatomies and modality pairs, without the need for specialized retraining. We make our training code and data publicly available.
Visual Programming for Text-to-Image Generation and Evaluation
May 24, 2023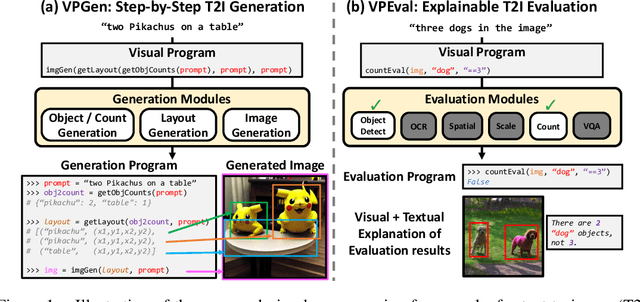
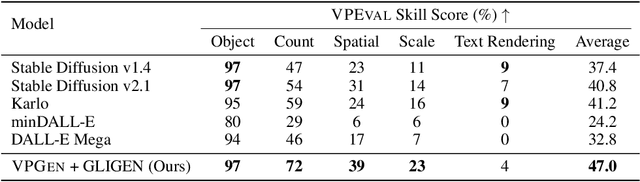
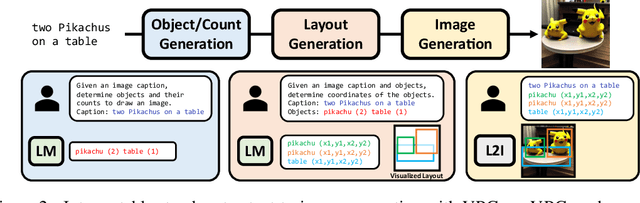

As large language models have demonstrated impressive performance in many domains, recent works have adopted language models (LMs) as controllers of visual modules for vision-and-language tasks. While existing work focuses on equipping LMs with visual understanding, we propose two novel interpretable/explainable visual programming frameworks for text-to-image (T2I) generation and evaluation. First, we introduce VPGen, an interpretable step-by-step T2I generation framework that decomposes T2I generation into three steps: object/count generation, layout generation, and image generation. We employ an LM to handle the first two steps (object/count generation and layout generation), by finetuning it on text-layout pairs. Our step-by-step T2I generation framework provides stronger spatial control than end-to-end models, the dominant approach for this task. Furthermore, we leverage the world knowledge of pretrained LMs, overcoming the limitation of previous layout-guided T2I works that can only handle predefined object classes. We demonstrate that our VPGen has improved control in counts/spatial relations/scales of objects than state-of-the-art T2I generation models. Second, we introduce VPEval, an interpretable and explainable evaluation framework for T2I generation based on visual programming. Unlike previous T2I evaluations with a single scoring model that is accurate in some skills but unreliable in others, VPEval produces evaluation programs that invoke a set of visual modules that are experts in different skills, and also provides visual+textual explanations of the evaluation results. Our analysis shows VPEval provides a more human-correlated evaluation for skill-specific and open-ended prompts than widely used single model-based evaluation. We hope our work encourages future progress on interpretable/explainable generation and evaluation for T2I models. Website: https://vp-t2i.github.io
Latent Graph Attention for Enhanced Spatial Context
Jul 12, 2023
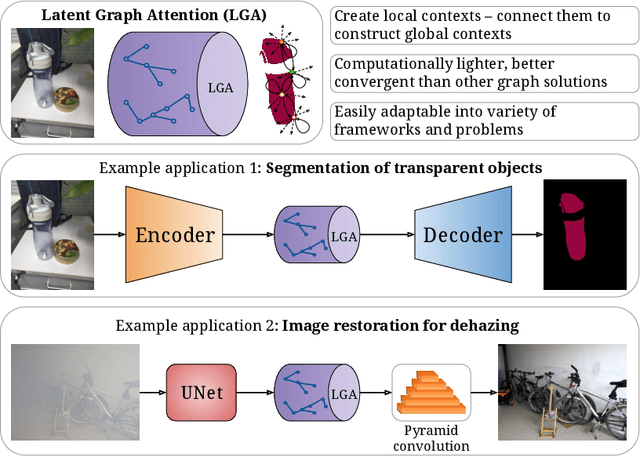
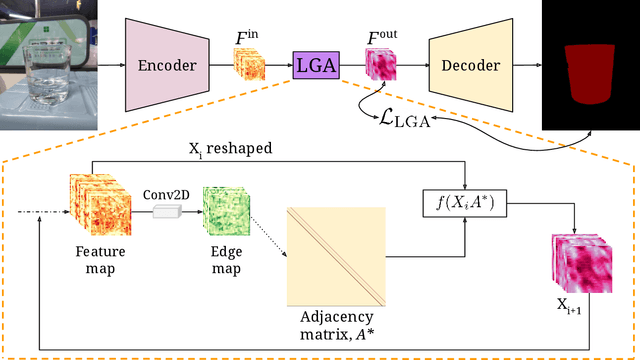
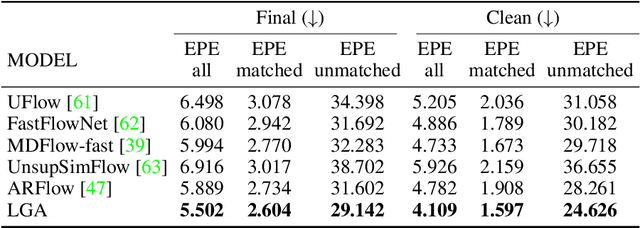
Global contexts in images are quite valuable in image-to-image translation problems. Conventional attention-based and graph-based models capture the global context to a large extent, however, these are computationally expensive. Moreover, the existing approaches are limited to only learning the pairwise semantic relation between any two points on the image. In this paper, we present Latent Graph Attention (LGA) a computationally inexpensive (linear to the number of nodes) and stable, modular framework for incorporating the global context in the existing architectures, especially empowering small-scale architectures to give performance closer to large size architectures, thus making the light-weight architectures more useful for edge devices with lower compute power and lower energy needs. LGA propagates information spatially using a network of locally connected graphs, thereby facilitating to construct a semantically coherent relation between any two spatially distant points that also takes into account the influence of the intermediate pixels. Moreover, the depth of the graph network can be used to adapt the extent of contextual spread to the target dataset, thereby being able to explicitly control the added computational cost. To enhance the learning mechanism of LGA, we also introduce a novel contrastive loss term that helps our LGA module to couple well with the original architecture at the expense of minimal additional computational load. We show that incorporating LGA improves the performance on three challenging applications, namely transparent object segmentation, image restoration for dehazing and optical flow estimation.
FoPro-KD: Fourier Prompted Effective Knowledge Distillation for Long-Tailed Medical Image Recognition
May 27, 2023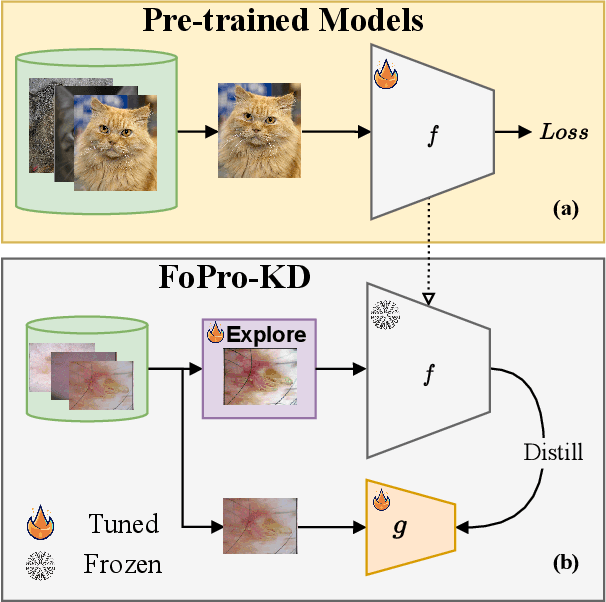
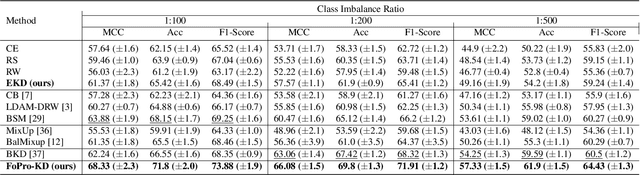
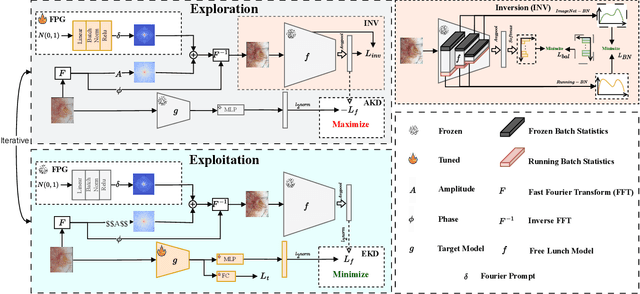
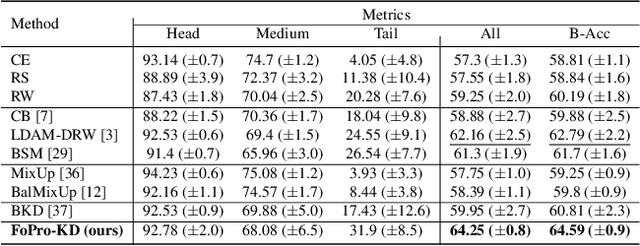
Transfer learning is a promising technique for medical image classification, particularly for long-tailed datasets. However, the scarcity of data in medical imaging domains often leads to overparameterization when fine-tuning large publicly available pre-trained models. Moreover, these large models are ineffective in deployment in clinical settings due to their computational expenses. To address these challenges, we propose FoPro-KD, a novel approach that unleashes the power of frequency patterns learned from frozen publicly available pre-trained models to enhance their transferability and compression. FoPro-KD comprises three modules: Fourier prompt generator (FPG), effective knowledge distillation (EKD), and adversarial knowledge distillation (AKD). The FPG module learns to generate targeted perturbations conditional on a target dataset, exploring the representations of a frozen pre-trained model, trained on natural images. The EKD module exploits these generalizable representations through distillation to a smaller target model, while the AKD module further enhances the distillation process. Through these modules, FoPro-KD achieves significant improvements in performance on long-tailed medical image classification benchmarks, demonstrating the potential of leveraging the learned frequency patterns from pre-trained models to enhance transfer learning and compression of large pre-trained models for feasible deployment.