 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Improving Scene Graph Generation with Superpixel-Based Interaction Learning
Aug 04, 2023
Recent advances in Scene Graph Generation (SGG) typically model the relationships among entities utilizing box-level features from pre-defined detectors. We argue that an overlooked problem in SGG is the coarse-grained interactions between boxes, which inadequately capture contextual semantics for relationship modeling, practically limiting the development of the field. In this paper, we take the initiative to explore and propose a generic paradigm termed Superpixel-based Interaction Learning (SIL) to remedy coarse-grained interactions at the box level. It allows us to model fine-grained interactions at the superpixel level in SGG. Specifically, (i) we treat a scene as a set of points and cluster them into superpixels representing sub-regions of the scene. (ii) We explore intra-entity and cross-entity interactions among the superpixels to enrich fine-grained interactions between entities at an earlier stage. Extensive experiments on two challenging benchmarks (Visual Genome and Open Image V6) prove that our SIL enables fine-grained interaction at the superpixel level above previous box-level methods, and significantly outperforms previous state-of-the-art methods across all metrics. More encouragingly, the proposed method can be applied to boost the performance of existing box-level approaches in a plug-and-play fashion. In particular, SIL brings an average improvement of 2.0% mR (even up to 3.4%) of baselines for the PredCls task on Visual Genome, which facilitates its integration into any existing box-level method.
Paired Competing Neurons Improving STDP Supervised Local Learning In Spiking Neural Networks
Aug 04, 2023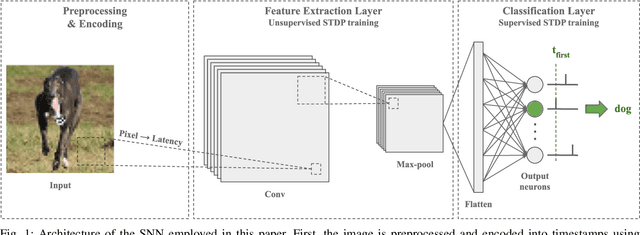
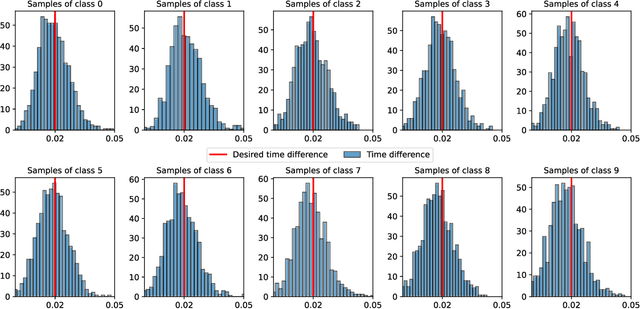
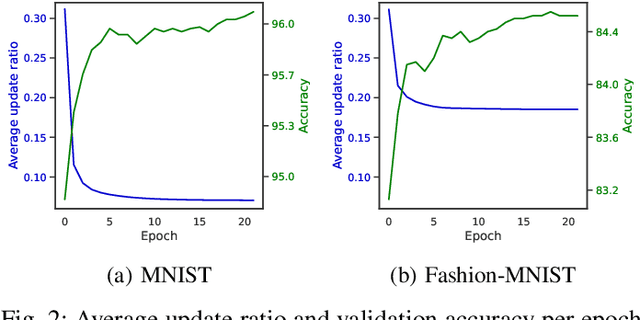
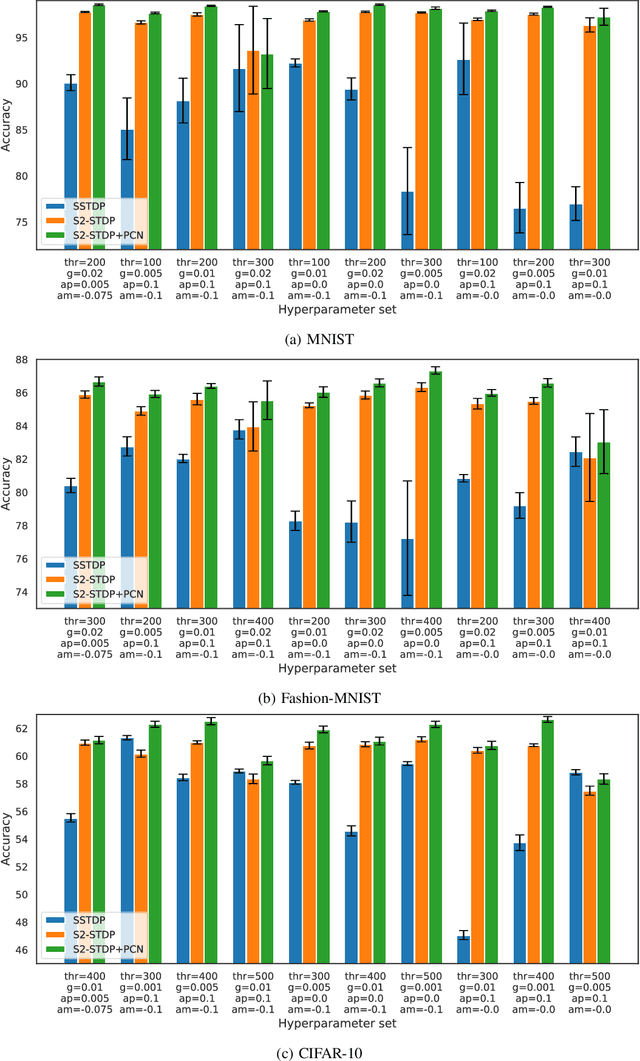
Direct training of Spiking Neural Networks (SNNs) on neuromorphic hardware has the potential to significantly reduce the high energy consumption of Artificial Neural Networks (ANNs) training on modern computers. The biological plausibility of SNNs allows them to benefit from bio-inspired plasticity rules, such as Spike Timing-Dependent Plasticity (STDP). STDP offers gradient-free and unsupervised local learning, which can be easily implemented on neuromorphic hardware. However, relying solely on unsupervised STDP to perform classification tasks is not enough. In this paper, we propose Stabilized Supervised STDP (S2-STDP), a supervised STDP learning rule to train the classification layer of an SNN equipped with unsupervised STDP. S2-STDP integrates error-modulated weight updates that align neuron spikes with desired timestamps derived from the average firing time within the layer. Then, we introduce a training architecture called Paired Competing Neurons (PCN) to further enhance the learning capabilities of our classification layer trained with S2-STDP. PCN associates each class with paired neurons and encourages neuron specialization through intra-class competition. We evaluated our proposed methods on image recognition datasets, including MNIST, Fashion-MNIST, and CIFAR-10. Results showed that our methods outperform current supervised STDP-based state of the art, for comparable architectures and numbers of neurons. Also, the use of PCN enhances the performance of S2-STDP, regardless of the configuration, and without introducing any hyperparameters.Further analysis demonstrated that our methods exhibited improved hyperparameter robustness, which reduces the need for tuning.
Damage Vision Mining Opportunity for Imbalanced Anomaly Detection
Aug 04, 2023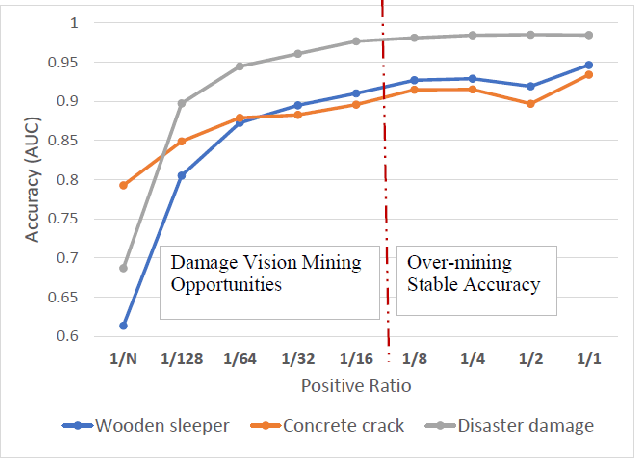

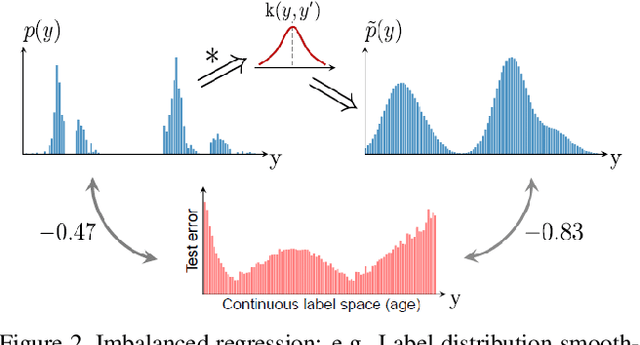

In past decade, previous balanced datasets have been used to advance algorithms for classification, object detection, semantic segmentation, and anomaly detection in industrial applications. Specifically, for condition-based maintenance, automating visual inspection is crucial to ensure high quality. Deterioration prognostic attempts to optimize the fine decision process for predictive maintenance and proactive repair. In civil infrastructure and living environment, damage data mining cannot avoid the imbalanced data issue because of rare unseen events and high quality status by improved operations. For visual inspection, deteriorated class acquired from the surface of concrete and steel components are occasionally imbalanced. From numerous related surveys, we summarize that imbalanced data problems can be categorized into four types; 1) missing range of target and label valuables, 2) majority-minority class imbalance, 3) foreground-background of spatial imbalance, 4) long-tailed class of pixel-wise imbalance. Since 2015, there has been many imbalanced studies using deep learning approaches that includes regression, image classification, object detection, semantic segmentation. However, anomaly detection for imbalanced data is not yet well known. In the study, we highlight one-class anomaly detection application whether anomalous class or not, and demonstrate clear examples on imbalanced vision datasets: blood smear, lung infection, wooden, concrete deterioration, and disaster damage. We provide key results on damage vision mining advantage, hypothesizing that the more effective range of positive ratio, the higher accuracy gain of anomaly detection application. Finally, the applicability of the damage learning methods, limitations, and future works are mentioned.
Multi-Modal Mutual Attention and Iterative Interaction for Referring Image Segmentation
May 24, 2023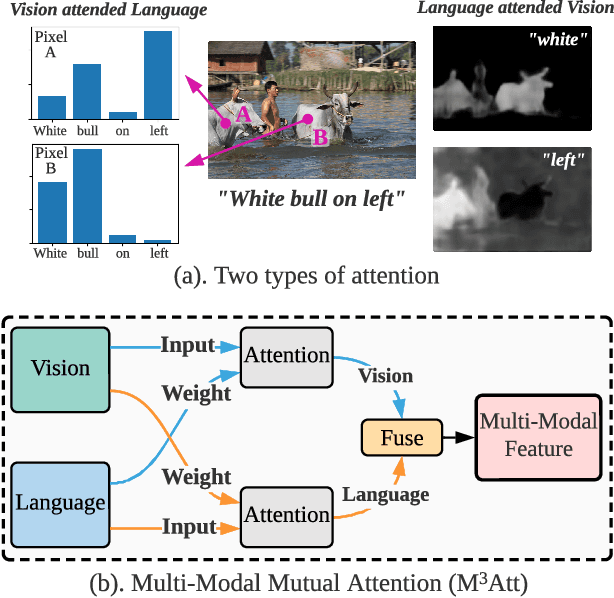

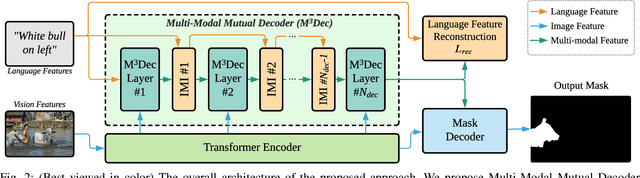
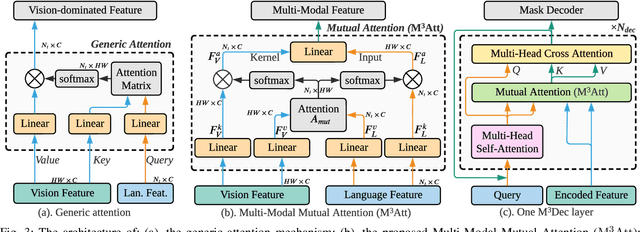
We address the problem of referring image segmentation that aims to generate a mask for the object specified by a natural language expression. Many recent works utilize Transformer to extract features for the target object by aggregating the attended visual regions. However, the generic attention mechanism in Transformer only uses the language input for attention weight calculation, which does not explicitly fuse language features in its output. Thus, its output feature is dominated by vision information, which limits the model to comprehensively understand the multi-modal information, and brings uncertainty for the subsequent mask decoder to extract the output mask. To address this issue, we propose Multi-Modal Mutual Attention ($\mathrm{M^3Att}$) and Multi-Modal Mutual Decoder ($\mathrm{M^3Dec}$) that better fuse information from the two input modalities. Based on {$\mathrm{M^3Dec}$}, we further propose Iterative Multi-modal Interaction ($\mathrm{IMI}$) to allow continuous and in-depth interactions between language and vision features. Furthermore, we introduce Language Feature Reconstruction ($\mathrm{LFR}$) to prevent the language information from being lost or distorted in the extracted feature. Extensive experiments show that our proposed approach significantly improves the baseline and outperforms state-of-the-art referring image segmentation methods on RefCOCO series datasets consistently.
Motion Degeneracy in Self-supervised Learning of Elevation Angle Estimation for 2D Forward-Looking Sonar
Aug 01, 2023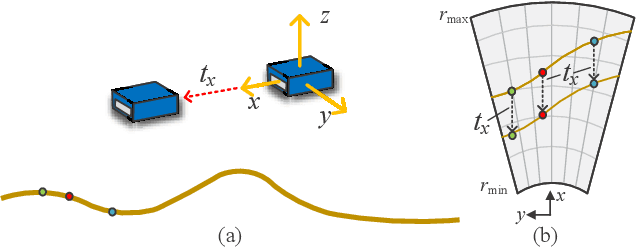
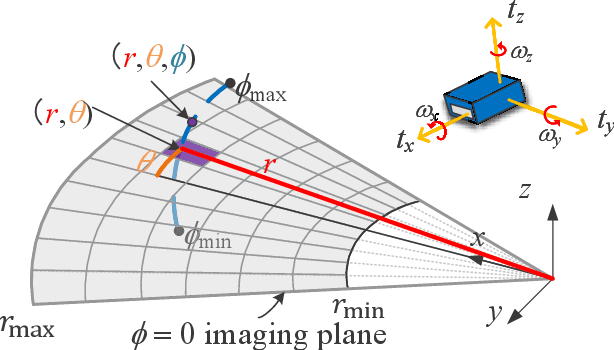
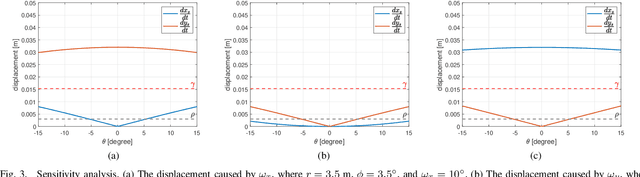
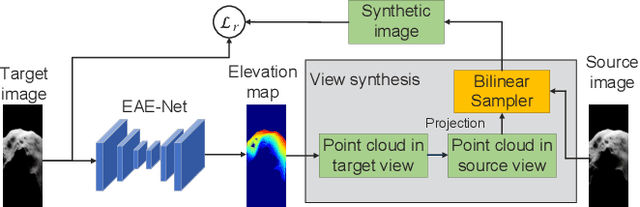
2D forward-looking sonar is a crucial sensor for underwater robotic perception. A well-known problem in this field is estimating missing information in the elevation direction during sonar imaging. There are demands to estimate 3D information per image for 3D mapping and robot navigation during fly-through missions. Recent learning-based methods have demonstrated their strengths, but there are still drawbacks. Supervised learning methods have achieved high-quality results but may require further efforts to acquire 3D ground-truth labels. The existing self-supervised method requires pretraining using synthetic images with 3D supervision. This study aims to realize stable self-supervised learning of elevation angle estimation without pretraining using synthetic images. Failures during self-supervised learning may be caused by motion degeneracy problems. We first analyze the motion field of 2D forward-looking sonar, which is related to the main supervision signal. We utilize a modern learning framework and prove that if the training dataset is built with effective motions, the network can be trained in a self-supervised manner without the knowledge of synthetic data. Both simulation and real experiments validate the proposed method.
Dynamic ensemble selection based on Deep Neural Network Uncertainty Estimation for Adversarial Robustness
Aug 01, 2023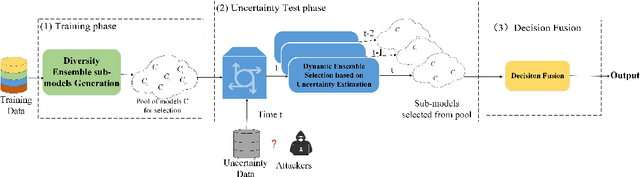
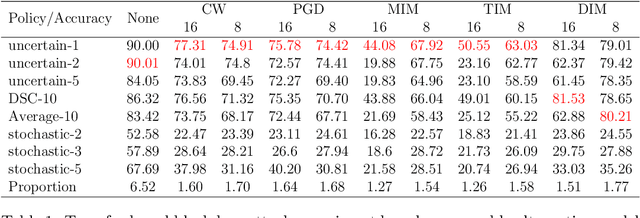
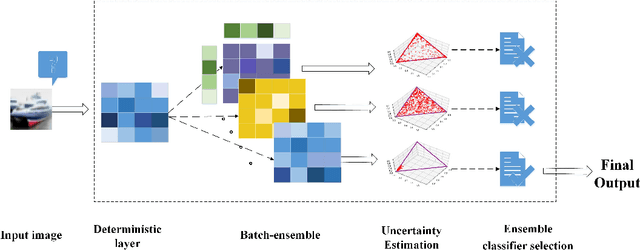
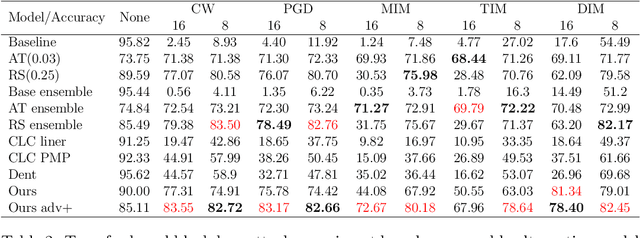
The deep neural network has attained significant efficiency in image recognition. However, it has vulnerable recognition robustness under extensive data uncertainty in practical applications. The uncertainty is attributed to the inevitable ambient noise and, more importantly, the possible adversarial attack. Dynamic methods can effectively improve the defense initiative in the arms race of attack and defense of adversarial examples. Different from the previous dynamic method depend on input or decision, this work explore the dynamic attributes in model level through dynamic ensemble selection technology to further protect the model from white-box attacks and improve the robustness. Specifically, in training phase the Dirichlet distribution is apply as prior of sub-models' predictive distribution, and the diversity constraint in parameter space is introduced under the lightweight sub-models to construct alternative ensembel model spaces. In test phase, the certain sub-models are dynamically selected based on their rank of uncertainty value for the final prediction to ensure the majority accurate principle in ensemble robustness and accuracy. Compared with the previous dynamic method and staic adversarial traning model, the presented approach can achieve significant robustness results without damaging accuracy by combining dynamics and diversity property.
Improving Pixel-based MIM by Reducing Wasted Modeling Capability
Aug 01, 2023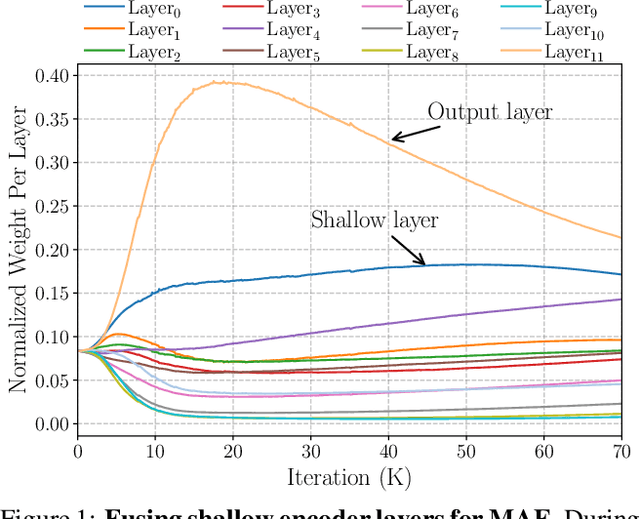
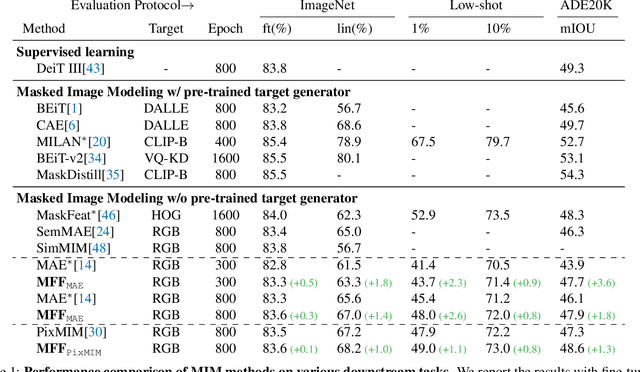
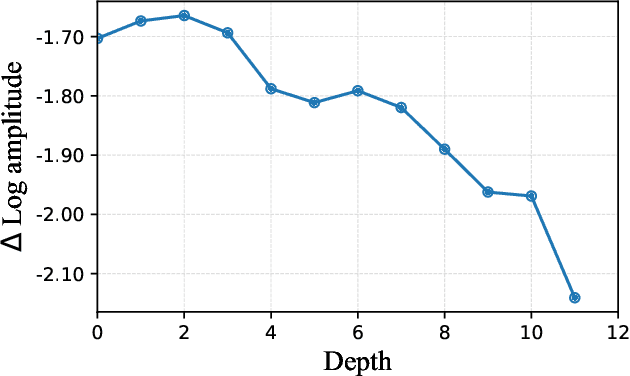
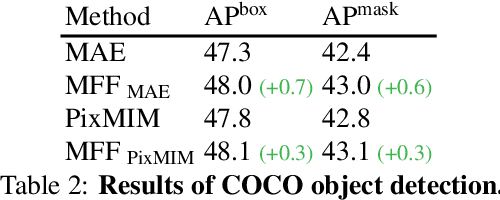
There has been significant progress in Masked Image Modeling (MIM). Existing MIM methods can be broadly categorized into two groups based on the reconstruction target: pixel-based and tokenizer-based approaches. The former offers a simpler pipeline and lower computational cost, but it is known to be biased toward high-frequency details. In this paper, we provide a set of empirical studies to confirm this limitation of pixel-based MIM and propose a new method that explicitly utilizes low-level features from shallow layers to aid pixel reconstruction. By incorporating this design into our base method, MAE, we reduce the wasted modeling capability of pixel-based MIM, improving its convergence and achieving non-trivial improvements across various downstream tasks. To the best of our knowledge, we are the first to systematically investigate multi-level feature fusion for isotropic architectures like the standard Vision Transformer (ViT). Notably, when applied to a smaller model (e.g., ViT-S), our method yields significant performance gains, such as 1.2\% on fine-tuning, 2.8\% on linear probing, and 2.6\% on semantic segmentation. Code and models are available at https://github.com/open-mmlab/mmpretrain.
Cross2StrA: Unpaired Cross-lingual Image Captioning with Cross-lingual Cross-modal Structure-pivoted Alignment
May 25, 2023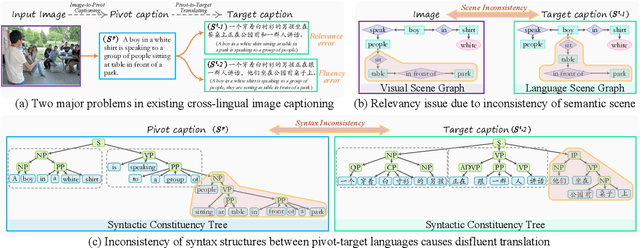
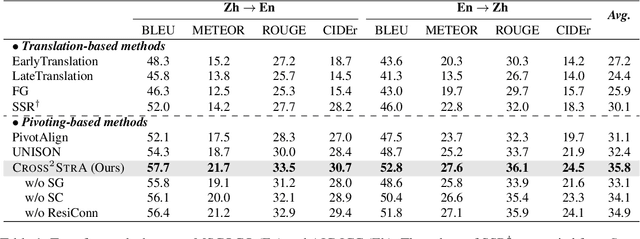
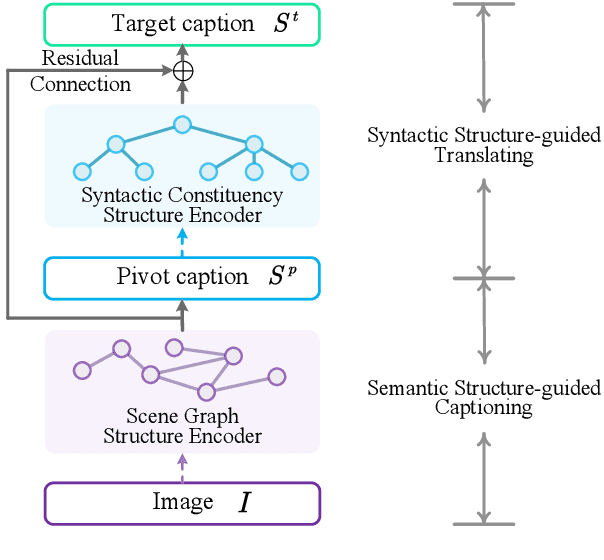
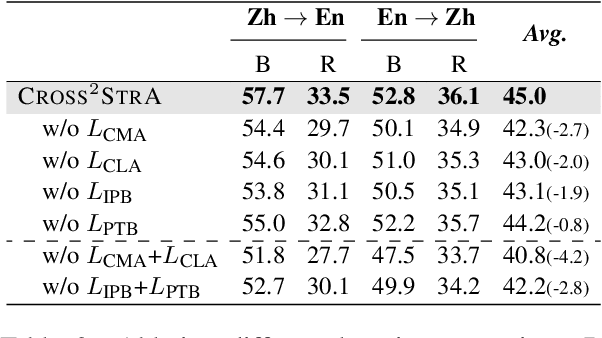
Unpaired cross-lingual image captioning has long suffered from irrelevancy and disfluency issues, due to the inconsistencies of the semantic scene and syntax attributes during transfer. In this work, we propose to address the above problems by incorporating the scene graph (SG) structures and the syntactic constituency (SC) trees. Our captioner contains the semantic structure-guided image-to-pivot captioning and the syntactic structure-guided pivot-to-target translation, two of which are joined via pivot language. We then take the SG and SC structures as pivoting, performing cross-modal semantic structure alignment and cross-lingual syntactic structure alignment learning. We further introduce cross-lingual&cross-modal back-translation training to fully align the captioning and translation stages. Experiments on English-Chinese transfers show that our model shows great superiority in improving captioning relevancy and fluency.
DETR Doesn't Need Multi-Scale or Locality Design
Aug 03, 2023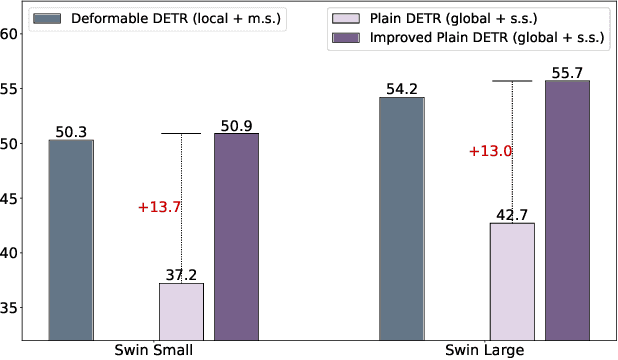
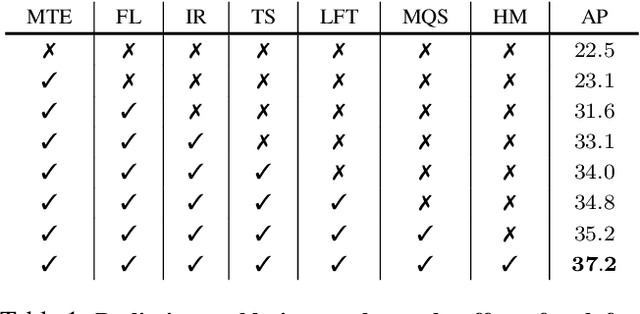

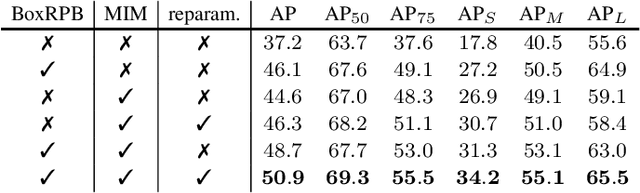
This paper presents an improved DETR detector that maintains a "plain" nature: using a single-scale feature map and global cross-attention calculations without specific locality constraints, in contrast to previous leading DETR-based detectors that reintroduce architectural inductive biases of multi-scale and locality into the decoder. We show that two simple technologies are surprisingly effective within a plain design to compensate for the lack of multi-scale feature maps and locality constraints. The first is a box-to-pixel relative position bias (BoxRPB) term added to the cross-attention formulation, which well guides each query to attend to the corresponding object region while also providing encoding flexibility. The second is masked image modeling (MIM)-based backbone pre-training which helps learn representation with fine-grained localization ability and proves crucial for remedying dependencies on the multi-scale feature maps. By incorporating these technologies and recent advancements in training and problem formation, the improved "plain" DETR showed exceptional improvements over the original DETR detector. By leveraging the Object365 dataset for pre-training, it achieved 63.9 mAP accuracy using a Swin-L backbone, which is highly competitive with state-of-the-art detectors which all heavily rely on multi-scale feature maps and region-based feature extraction. Code is available at https://github.com/impiga/Plain-DETR .
Human Body Shape Classification Based on a Single Image
May 29, 2023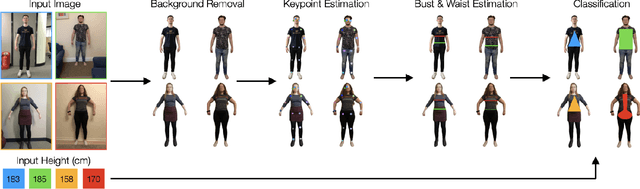


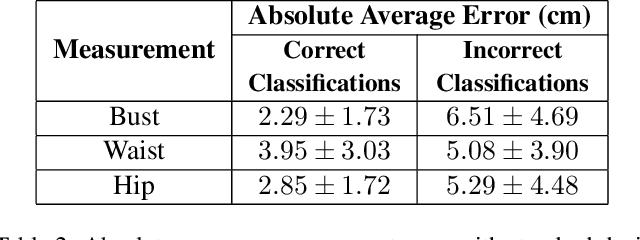
There is high demand for online fashion recommender systems that incorporate the needs of the consumer's body shape. As such, we present a methodology to classify human body shape from a single image. This is achieved through the use of instance segmentation and keypoint estimation models, trained only on open-source benchmarking datasets. The system is capable of performing in noisy environments owing to to robust background subtraction. The proposed methodology does not require 3D body recreation as a result of classification based on estimated keypoints, nor requires historical information about a user to operate - calculating all required measurements at the point of use. We evaluate our methodology both qualitatively against existing body shape classifiers and quantitatively against a novel dataset of images, which we provide for use to the community. The resultant body shape classification can be utilised in a variety of downstream tasks, such as input to size and fit recommendation or virtual try-on systems.