 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unfolding Once is Enough: A Deployment-Friendly Transformer Unit for Super-Resolution
Aug 05, 2023
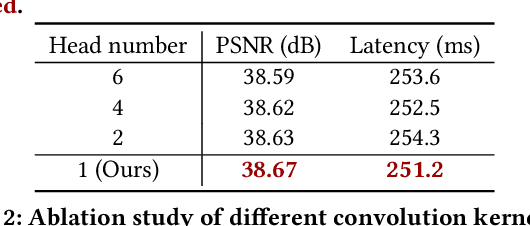



Recent years have witnessed a few attempts of vision transformers for single image super-resolution (SISR). Since the high resolution of intermediate features in SISR models increases memory and computational requirements, efficient SISR transformers are more favored. Based on some popular transformer backbone, many methods have explored reasonable schemes to reduce the computational complexity of the self-attention module while achieving impressive performance. However, these methods only focus on the performance on the training platform (e.g., Pytorch/Tensorflow) without further optimization for the deployment platform (e.g., TensorRT). Therefore, they inevitably contain some redundant operators, posing challenges for subsequent deployment in real-world applications. In this paper, we propose a deployment-friendly transformer unit, namely UFONE (i.e., UnFolding ONce is Enough), to alleviate these problems. In each UFONE, we introduce an Inner-patch Transformer Layer (ITL) to efficiently reconstruct the local structural information from patches and a Spatial-Aware Layer (SAL) to exploit the long-range dependencies between patches. Based on UFONE, we propose a Deployment-friendly Inner-patch Transformer Network (DITN) for the SISR task, which can achieve favorable performance with low latency and memory usage on both training and deployment platforms. Furthermore, to further boost the deployment efficiency of the proposed DITN on TensorRT, we also provide an efficient substitution for layer normalization and propose a fusion optimization strategy for specific operators. Extensive experiments show that our models can achieve competitive results in terms of qualitative and quantitative performance with high deployment efficiency. Code is available at \url{https://github.com/yongliuy/DITN}.
Learning Dynamic Query Combinations for Transformer-based Object Detection and Segmentation
Jul 27, 2023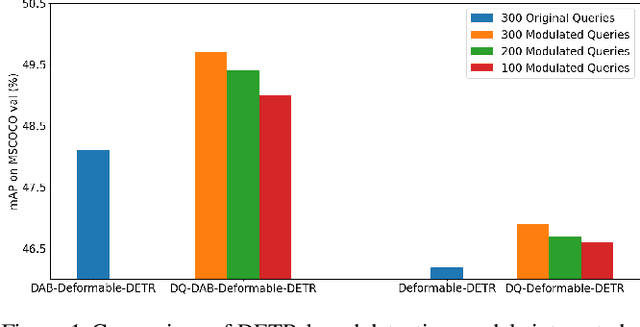

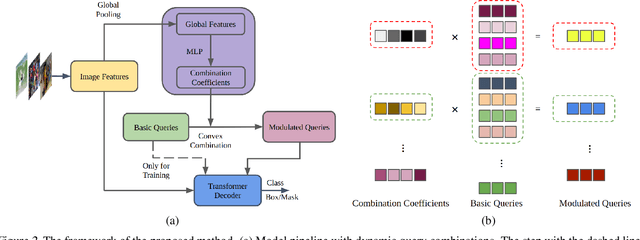
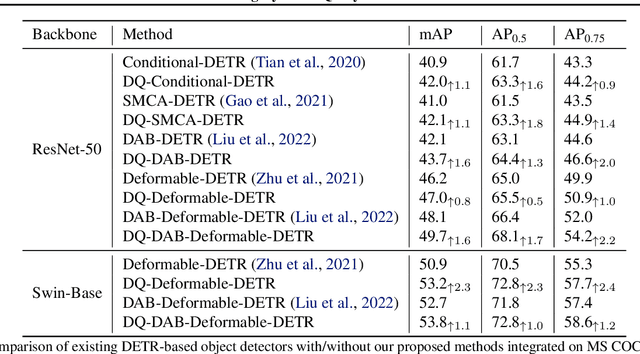
Transformer-based detection and segmentation methods use a list of learned detection queries to retrieve information from the transformer network and learn to predict the location and category of one specific object from each query. We empirically find that random convex combinations of the learned queries are still good for the corresponding models. We then propose to learn a convex combination with dynamic coefficients based on the high-level semantics of the image. The generated dynamic queries, named modulated queries, better capture the prior of object locations and categories in the different images. Equipped with our modulated queries, a wide range of DETR-based models achieve consistent and superior performance across multiple tasks including object detection, instance segmentation, panoptic segmentation, and video instance segmentation.
A Conditional Denoising Diffusion Probabilistic Model for Radio Interferometric Image Reconstruction
May 16, 2023
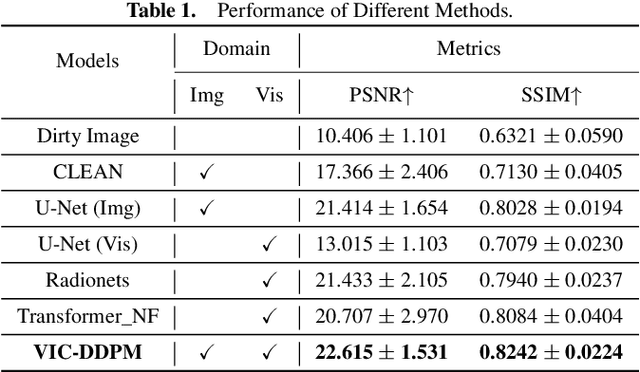
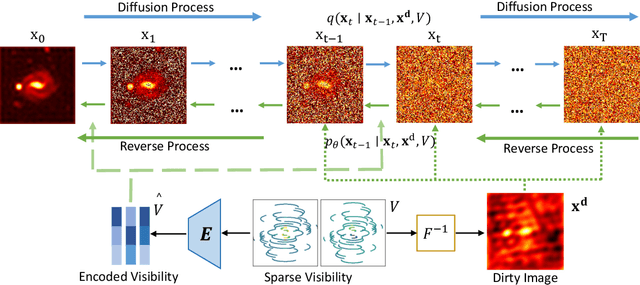
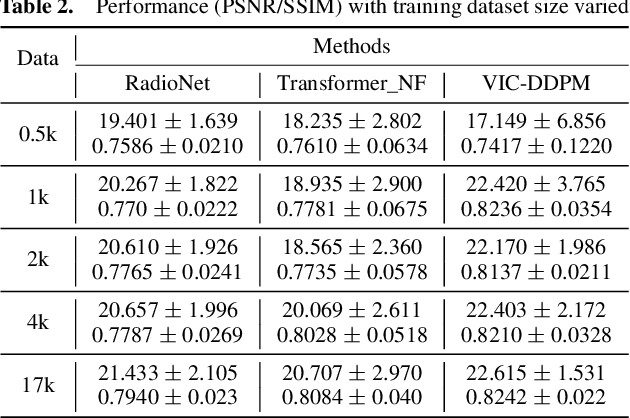
In radio astronomy, signals from radio telescopes are transformed into images of observed celestial objects, or sources. However, these images, called dirty images, contain real sources as well as artifacts due to signal sparsity and other factors. Therefore, radio interferometric image reconstruction is performed on dirty images, aiming to produce clean images in which artifacts are reduced and real sources are recovered. So far, existing methods have limited success on recovering faint sources, preserving detailed structures, and eliminating artifacts. In this paper, we present VIC-DDPM, a Visibility and Image Conditioned Denoising Diffusion Probabilistic Model. Our main idea is to use both the original visibility data in the spectral domain and dirty images in the spatial domain to guide the image generation process with DDPM. This way, we can leverage DDPM to generate fine details and eliminate noise, while utilizing visibility data to separate signals from noise and retaining spatial information in dirty images. We have conducted experiments in comparison with both traditional methods and recent deep learning based approaches. Our results show that our method significantly improves the resulting images by reducing artifacts, preserving fine details, and recovering dim sources. This advancement further facilitates radio astronomical data analysis tasks on celestial phenomena.
DreamPose: Fashion Image-to-Video Synthesis via Stable Diffusion
May 04, 2023
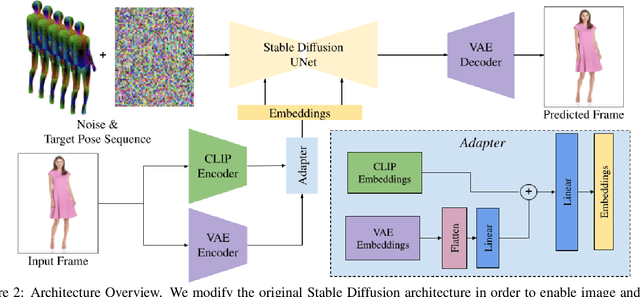
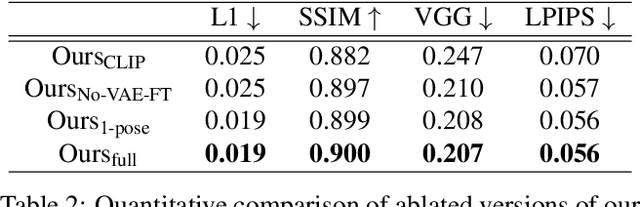

We present DreamPose, a diffusion-based method for generating animated fashion videos from still images. Given an image and a sequence of human body poses, our method synthesizes a video containing both human and fabric motion. To achieve this, we transform a pretrained text-to-image model (Stable Diffusion) into a pose-and-image guided video synthesis model, using a novel finetuning strategy, a set of architectural changes to support the added conditioning signals, and techniques to encourage temporal consistency. We fine-tune on a collection of fashion videos from the UBC Fashion dataset. We evaluate our method on a variety of clothing styles and poses, and demonstrate that our method produces state-of-the-art results on fashion video animation. Video results are available on our project page.
C-DARL: Contrastive diffusion adversarial representation learning for label-free blood vessel segmentation
Jul 31, 2023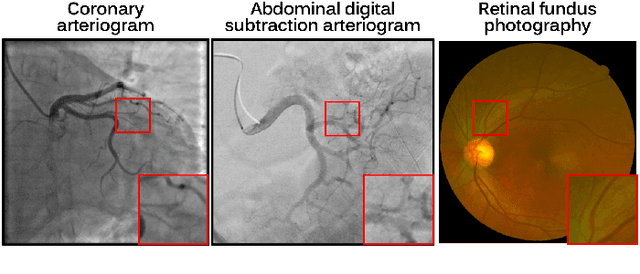
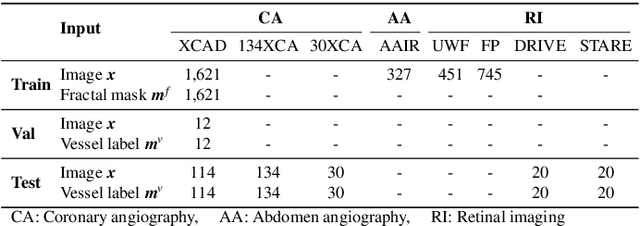
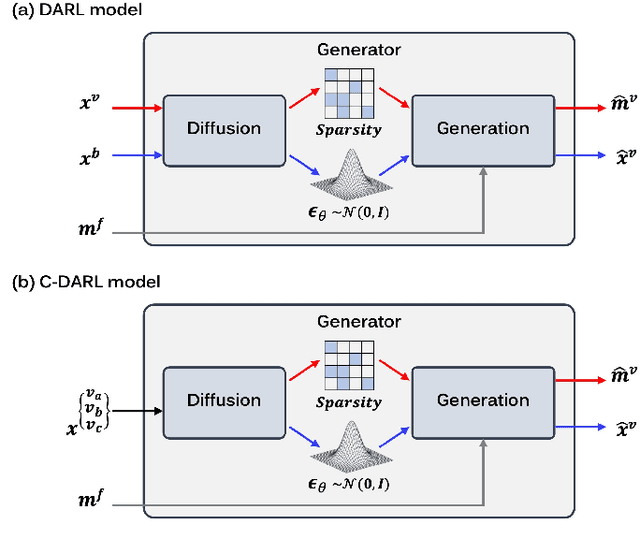
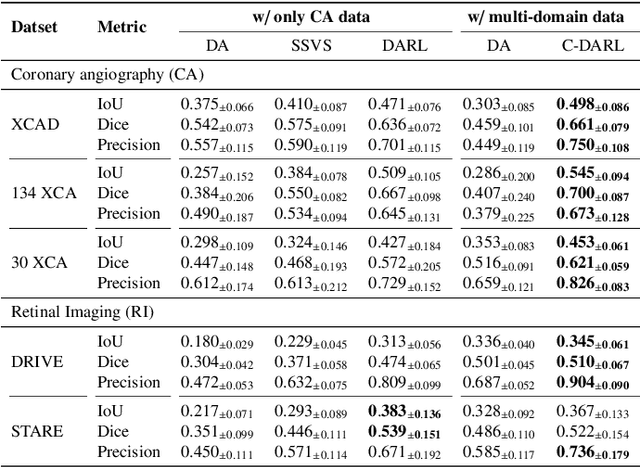
Blood vessel segmentation in medical imaging is one of the essential steps for vascular disease diagnosis and interventional planning in a broad spectrum of clinical scenarios in image-based medicine and interventional medicine. Unfortunately, manual annotation of the vessel masks is challenging and resource-intensive due to subtle branches and complex structures. To overcome this issue, this paper presents a self-supervised vessel segmentation method, dubbed the contrastive diffusion adversarial representation learning (C-DARL) model. Our model is composed of a diffusion module and a generation module that learns the distribution of multi-domain blood vessel data by generating synthetic vessel images from diffusion latent. Moreover, we employ contrastive learning through a mask-based contrastive loss so that the model can learn more realistic vessel representations. To validate the efficacy, C-DARL is trained using various vessel datasets, including coronary angiograms, abdominal digital subtraction angiograms, and retinal imaging. Experimental results confirm that our model achieves performance improvement over baseline methods with noise robustness, suggesting the effectiveness of C-DARL for vessel segmentation.
ADASSM: Adversarial Data Augmentation in Statistical Shape Models From Images
Jul 10, 2023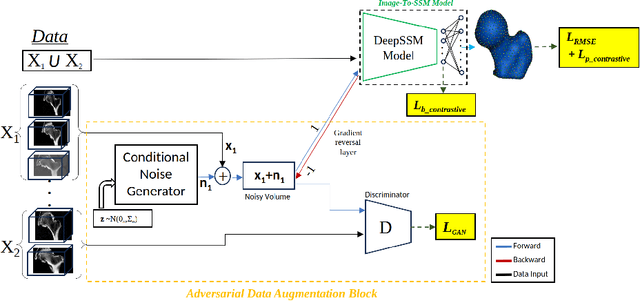
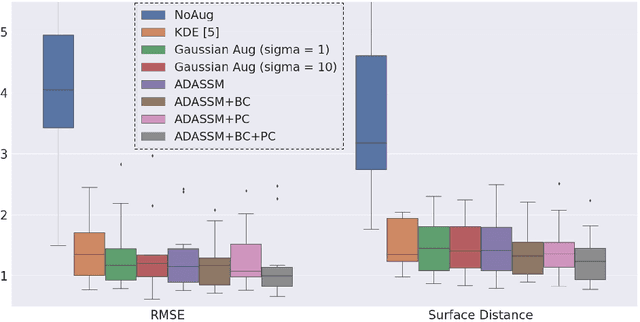
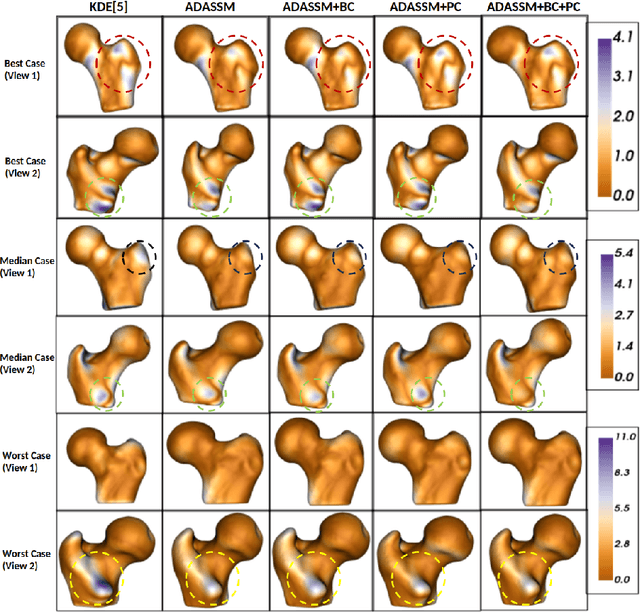
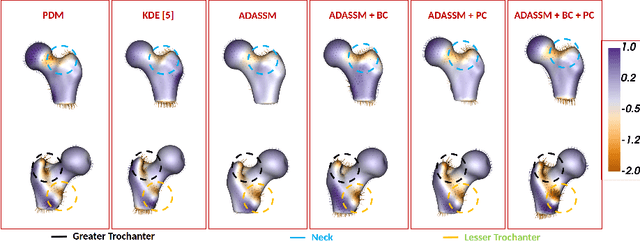
Statistical shape models (SSM) have been well-established as an excellent tool for identifying variations in the morphology of anatomy across the underlying population. Shape models use consistent shape representation across all the samples in a given cohort, which helps to compare shapes and identify the variations that can detect pathologies and help in formulating treatment plans. In medical imaging, computing these shape representations from CT/MRI scans requires time-intensive preprocessing operations, including but not limited to anatomy segmentation annotations, registration, and texture denoising. Deep learning models have demonstrated exceptional capabilities in learning shape representations directly from volumetric images, giving rise to highly effective and efficient Image-to-SSM. Nevertheless, these models are data-hungry and due to the limited availability of medical data, deep learning models tend to overfit. Offline data augmentation techniques, that use kernel density estimation based (KDE) methods for generating shape-augmented samples, have successfully aided Image-to-SSM networks in achieving comparable accuracy to traditional SSM methods. However, these augmentation methods focus on shape augmentation, whereas deep learning models exhibit image-based texture bias results in sub-optimal models. This paper introduces a novel strategy for on-the-fly data augmentation for the Image-to-SSM framework by leveraging data-dependent noise generation or texture augmentation. The proposed framework is trained as an adversary to the Image-to-SSM network, augmenting diverse and challenging noisy samples. Our approach achieves improved accuracy by encouraging the model to focus on the underlying geometry rather than relying solely on pixel values.
Joint Perceptual Learning for Enhancement and Object Detection in Underwater Scenarios
Jul 07, 2023
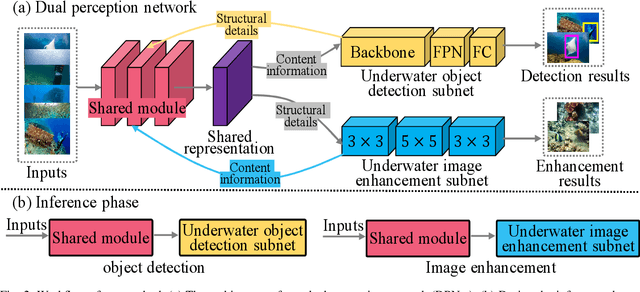
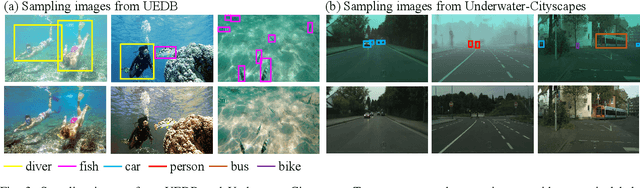

Underwater degraded images greatly challenge existing algorithms to detect objects of interest. Recently, researchers attempt to adopt attention mechanisms or composite connections for improving the feature representation of detectors. However, this solution does \textit{not} eliminate the impact of degradation on image content such as color and texture, achieving minimal improvements. Another feasible solution for underwater object detection is to develop sophisticated deep architectures in order to enhance image quality or features. Nevertheless, the visually appealing output of these enhancement modules do \textit{not} necessarily generate high accuracy for deep detectors. More recently, some multi-task learning methods jointly learn underwater detection and image enhancement, accessing promising improvements. Typically, these methods invoke huge architecture and expensive computations, rendering inefficient inference. Definitely, underwater object detection and image enhancement are two interrelated tasks. Leveraging information coming from the two tasks can benefit each task. Based on these factual opinions, we propose a bilevel optimization formulation for jointly learning underwater object detection and image enhancement, and then unroll to a dual perception network (DPNet) for the two tasks. DPNet with one shared module and two task subnets learns from the two different tasks, seeking a shared representation. The shared representation provides more structural details for image enhancement and rich content information for object detection. Finally, we derive a cooperative training strategy to optimize parameters for DPNet. Extensive experiments on real-world and synthetic underwater datasets demonstrate that our method outputs visually favoring images and higher detection accuracy.
Trans-Inpainter: A Transformer Model for High Accuracy Image Inpainting from Channel State Information
May 09, 2023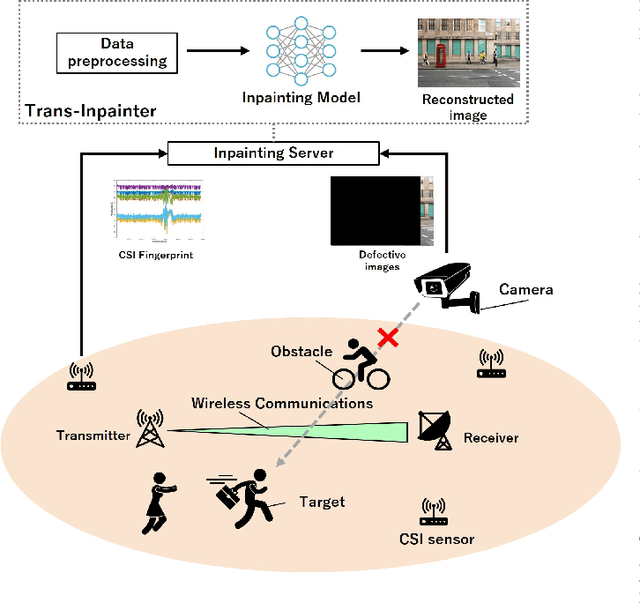

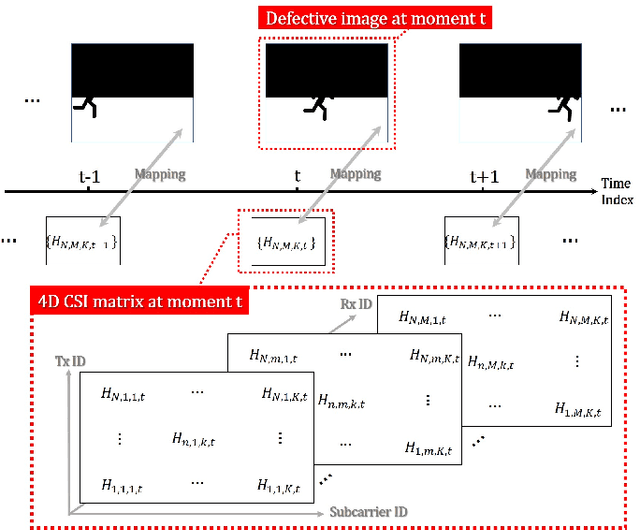
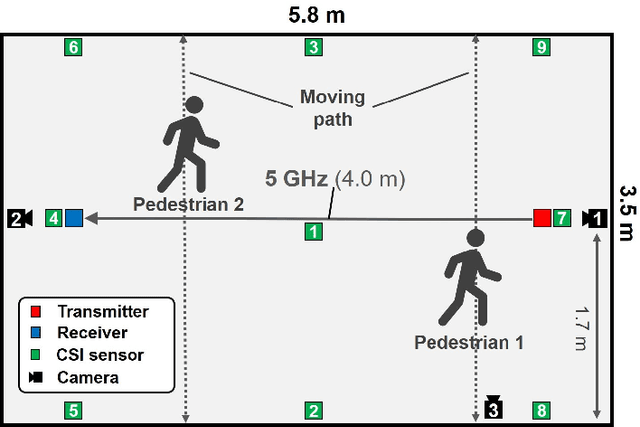
Radio Frequency (RF) signal-based multimodal image inpainting has recently emerged as a promising paradigm to enhance the capability of distortion-free image restoration by integrating wireless and visual information from the identical physical environment and has potential applications in fields like security and surveillance systems. In this paper, we aim to implement an RF-based image inpainting system that enables image restoration in a complex environment while maintaining high robustness and accuracy. This requires accurately converting RF signals into meaningful visual information and overcoming the challenges of RF signals in complex environments, such as multipath interference, signal attenuation, and noise. To tackle this problem, we propose Trans-Inpainter, a novel image inpainting method that utilizes the Channel State Information (CSI) of WiFi signals in combination with transformer networks to generate high-quality reconstructed images. This approach is the first to use CSI for image inpainting, which allows for extracting visual information from WiFi signals to fill in missing regions in images. To further improve Trans-Inpainter's performance, we investigate the impact of variations in CSI data on RF-based imaging ability, i.e., analyzing how the location of the CSI sensors, the combination of CSI from different sensors, and changes in temporal or frequency dimensions of CSI matrix affect the imaging quality. We compare the performance of Trans-Inpainter with RF-Inpainter, the state-of-the-art technology for RF-based multimodal image inpainting, under more realistic experimental scenarios, and with single-modality image inpainting models when only RF or image data is available, respectively. The results show that Trans-Inpainter outperforms other baseline methods in all cases.
Attention-Driven Lightweight Model for Pigmented Skin Lesion Detection
Aug 04, 2023
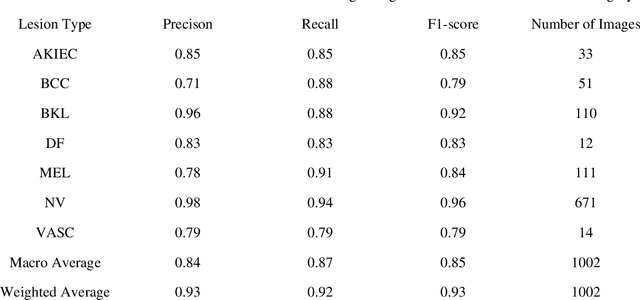
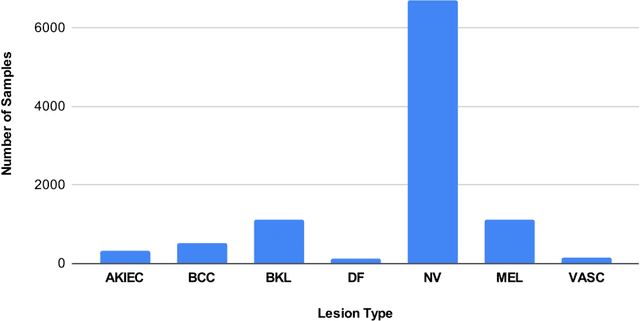
This study presents a lightweight pipeline for skin lesion detection, addressing the challenges posed by imbalanced class distribution and subtle or atypical appearances of some lesions. The pipeline is built around a lightweight model that leverages ghosted features and the DFC attention mechanism to reduce computational complexity while maintaining high performance. The model was trained on the HAM10000 dataset, which includes various types of skin lesions. To address the class imbalance in the dataset, the synthetic minority over-sampling technique and various image augmentation techniques were used. The model also incorporates a knowledge-based loss weighting technique, which assigns different weights to the loss function at the class level and the instance level, helping the model focus on minority classes and challenging samples. This technique involves assigning different weights to the loss function on two levels - the class level and the instance level. By applying appropriate loss weights, the model pays more attention to the minority classes and challenging samples, thus improving its ability to correctly detect and classify different skin lesions. The model achieved an accuracy of 92.4%, a precision of 84.2%, a recall of 86.9%, a f1-score of 85.4% with particularly strong performance in identifying Benign Keratosis-like lesions (BKL) and Nevus (NV). Despite its superior performance, the model's computational cost is considerably lower than some models with less accuracy, making it an optimal solution for real-world applications where both accuracy and efficiency are essential.
Improving Scene Graph Generation with Superpixel-Based Interaction Learning
Aug 04, 2023Recent advances in Scene Graph Generation (SGG) typically model the relationships among entities utilizing box-level features from pre-defined detectors. We argue that an overlooked problem in SGG is the coarse-grained interactions between boxes, which inadequately capture contextual semantics for relationship modeling, practically limiting the development of the field. In this paper, we take the initiative to explore and propose a generic paradigm termed Superpixel-based Interaction Learning (SIL) to remedy coarse-grained interactions at the box level. It allows us to model fine-grained interactions at the superpixel level in SGG. Specifically, (i) we treat a scene as a set of points and cluster them into superpixels representing sub-regions of the scene. (ii) We explore intra-entity and cross-entity interactions among the superpixels to enrich fine-grained interactions between entities at an earlier stage. Extensive experiments on two challenging benchmarks (Visual Genome and Open Image V6) prove that our SIL enables fine-grained interaction at the superpixel level above previous box-level methods, and significantly outperforms previous state-of-the-art methods across all metrics. More encouragingly, the proposed method can be applied to boost the performance of existing box-level approaches in a plug-and-play fashion. In particular, SIL brings an average improvement of 2.0% mR (even up to 3.4%) of baselines for the PredCls task on Visual Genome, which facilitates its integration into any existing box-level method.