 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Empirical Optimal Risk to Quantify Model Trustworthiness for Failure Detection
Aug 06, 2023
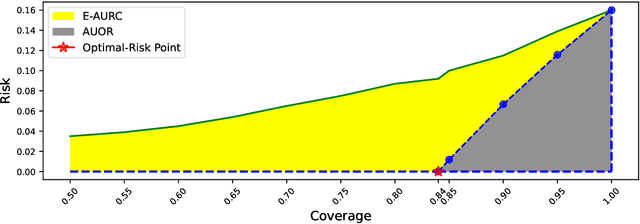
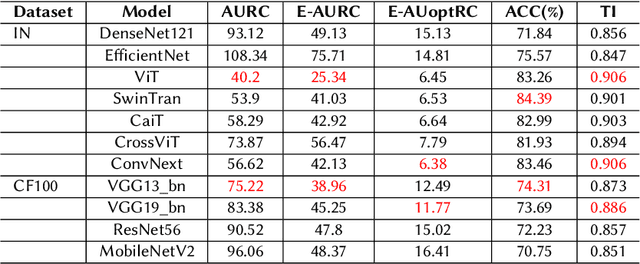
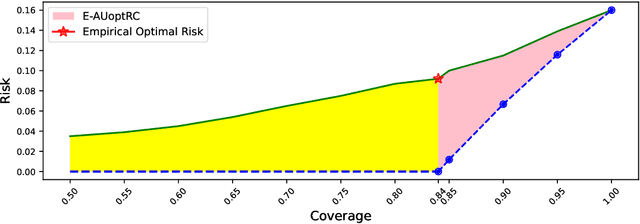
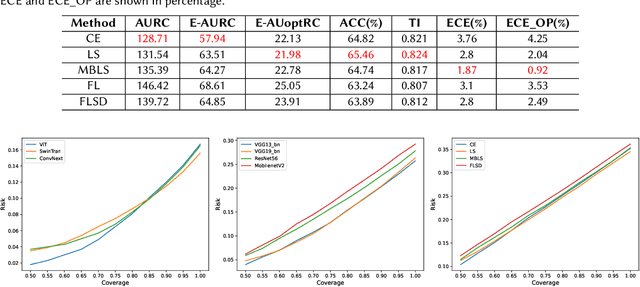
Failure detection (FD) in AI systems is a crucial safeguard for the deployment for safety-critical tasks. The common evaluation method of FD performance is the Risk-coverage (RC) curve, which reveals the trade-off between the data coverage rate and the performance on accepted data. One common way to quantify the RC curve by calculating the area under the RC curve. However, this metric does not inform on how suited any method is for FD, or what the optimal coverage rate should be. As FD aims to achieve higher performance with fewer data discarded, evaluating with partial coverage excluding the most uncertain samples is more intuitive and meaningful than full coverage. In addition, there is an optimal point in the coverage where the model could achieve ideal performance theoretically. We propose the Excess Area Under the Optimal RC Curve (E-AUoptRC), with the area in coverage from the optimal point to the full coverage. Further, the model performance at this optimal point can represent both model learning ability and calibration. We propose it as the Trust Index (TI), a complementary evaluation metric to the overall model accuracy. We report extensive experiments on three benchmark image datasets with ten variants of transformer and CNN models. Our results show that our proposed methods can better reflect the model trustworthiness than existing evaluation metrics. We further observe that the model with high overall accuracy does not always yield the high TI, which indicates the necessity of the proposed Trust Index as a complementary metric to the model overall accuracy. The code are available at \url{https://github.com/AoShuang92/optimal_risk}.
* 7 pages
Shrink-Perturb Improves Architecture Mixing during Population Based Training for Neural Architecture Search
Jul 28, 2023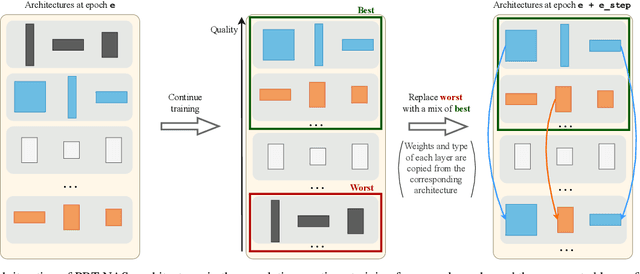
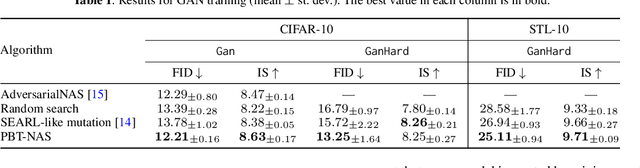
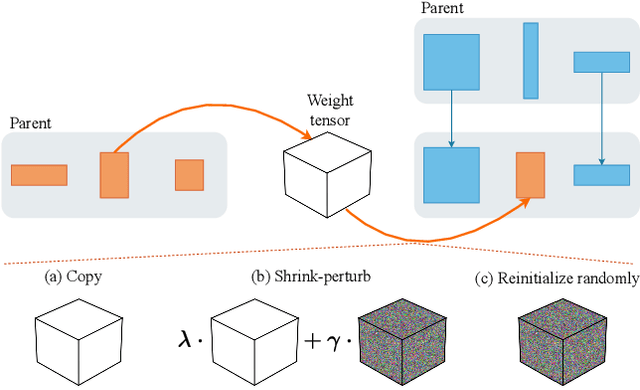

In this work, we show that simultaneously training and mixing neural networks is a promising way to conduct Neural Architecture Search (NAS). For hyperparameter optimization, reusing the partially trained weights allows for efficient search, as was previously demonstrated by the Population Based Training (PBT) algorithm. We propose PBT-NAS, an adaptation of PBT to NAS where architectures are improved during training by replacing poorly-performing networks in a population with the result of mixing well-performing ones and inheriting the weights using the shrink-perturb technique. After PBT-NAS terminates, the created networks can be directly used without retraining. PBT-NAS is highly parallelizable and effective: on challenging tasks (image generation and reinforcement learning) PBT-NAS achieves superior performance compared to baselines (random search and mutation-based PBT).
A Unified Prompt-Guided In-Context Inpainting Framework for Reference-based Image Manipulations
May 19, 2023
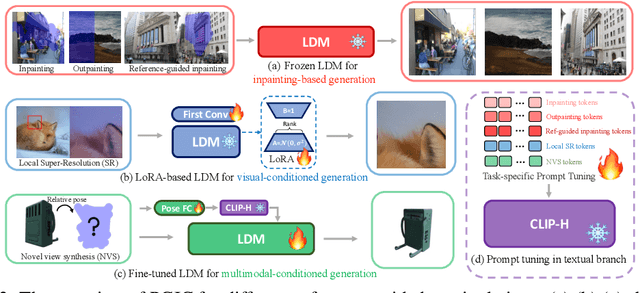
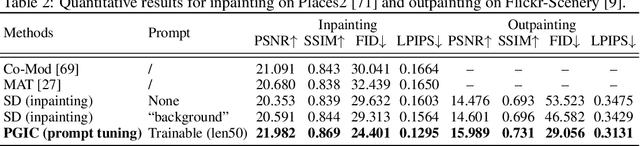
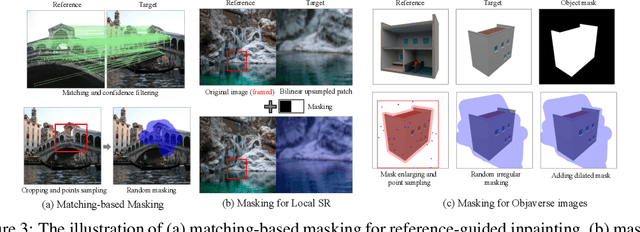
Recent advancements in Text-to-Image (T2I) generative models have yielded impressive results in generating high-fidelity images based on consistent text prompts. However, there is a growing interest in exploring the potential of these models for more diverse reference-based image manipulation tasks that require spatial understanding and visual context. Previous approaches have achieved this by incorporating additional control modules or fine-tuning the generative models specifically for each task until convergence. In this paper, we propose a different perspective. We conjecture that current large-scale T2I generative models already possess the capability to perform these tasks but are not fully activated within the standard generation process. To unlock these capabilities, we introduce a unified Prompt-Guided In-Context inpainting (PGIC) framework, which leverages large-scale T2I models to re-formulate and solve reference-guided image manipulations. In the PGIC framework, the reference and masked target are stitched together as a new input for the generative models, enabling the filling of masked regions as producing final results. Furthermore, we demonstrate that the self-attention modules in T2I models are well-suited for establishing spatial correlations and efficiently addressing challenging reference-guided manipulations. These large T2I models can be effectively driven by task-specific prompts with minimal training cost or even with frozen backbones. We synthetically evaluate the effectiveness of the proposed PGIC framework across various tasks, including reference-guided image inpainting, faithful inpainting, outpainting, local super-resolution, and novel view synthesis. Our results show that PGIC achieves significantly better performance while requiring less computation compared to other fine-tuning based approaches.
OneCAD: One Classifier for All image Datasets using multimodal learning
May 11, 2023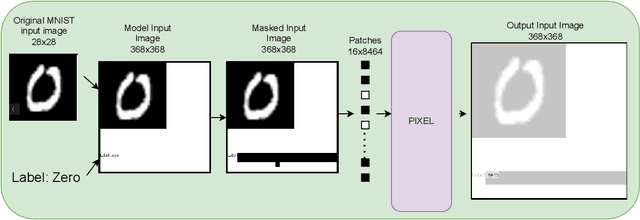

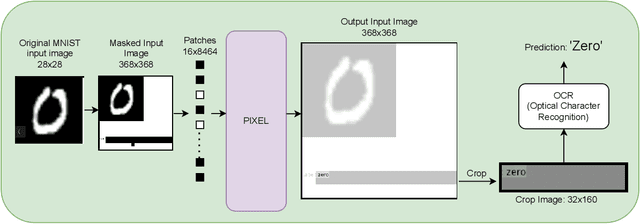

Vision-Transformers (ViTs) and Convolutional neural networks (CNNs) are widely used Deep Neural Networks (DNNs) for classification task. These model architectures are dependent on the number of classes in the dataset it was trained on. Any change in number of classes leads to change (partial or full) in the model's architecture. This work addresses the question: Is it possible to create a number-of-class-agnostic model architecture?. This allows model's architecture to be independent of the dataset it is trained on. This work highlights the issues with the current architectures (ViTs and CNNs). Also, proposes a training and inference framework OneCAD (One Classifier for All image Datasets) to achieve close-to number-of-class-agnostic transformer model. To best of our knowledge this is the first work to use Mask-Image-Modeling (MIM) with multimodal learning for classification task to create a DNN model architecture agnostic to the number of classes. Preliminary results are shown on natural and medical image datasets. Datasets: MNIST, CIFAR10, CIFAR100 and COVIDx. Code will soon be publicly available on github.
AudioToken: Adaptation of Text-Conditioned Diffusion Models for Audio-to-Image Generation
May 22, 2023
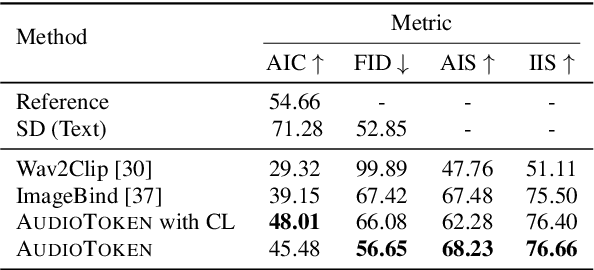
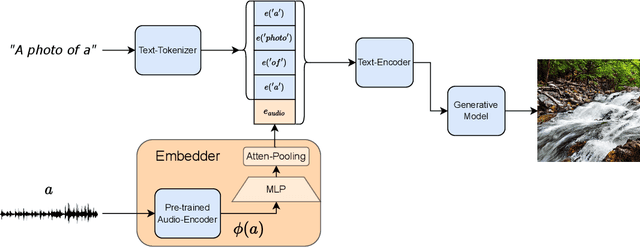

In recent years, image generation has shown a great leap in performance, where diffusion models play a central role. Although generating high-quality images, such models are mainly conditioned on textual descriptions. This begs the question: "how can we adopt such models to be conditioned on other modalities?". In this paper, we propose a novel method utilizing latent diffusion models trained for text-to-image-generation to generate images conditioned on audio recordings. Using a pre-trained audio encoding model, the proposed method encodes audio into a new token, which can be considered as an adaptation layer between the audio and text representations. Such a modeling paradigm requires a small number of trainable parameters, making the proposed approach appealing for lightweight optimization. Results suggest the proposed method is superior to the evaluated baseline methods, considering objective and subjective metrics. Code and samples are available at: https://pages.cs.huji.ac.il/adiyoss-lab/AudioToken.
Deep Image Matting: A Comprehensive Survey
Apr 10, 2023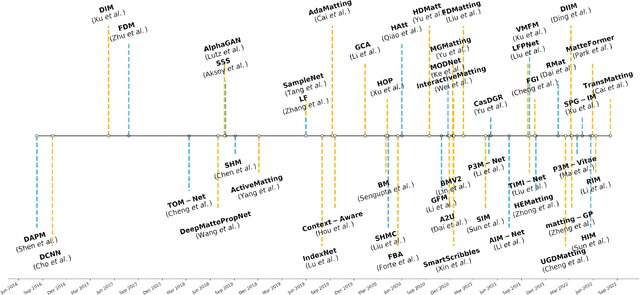
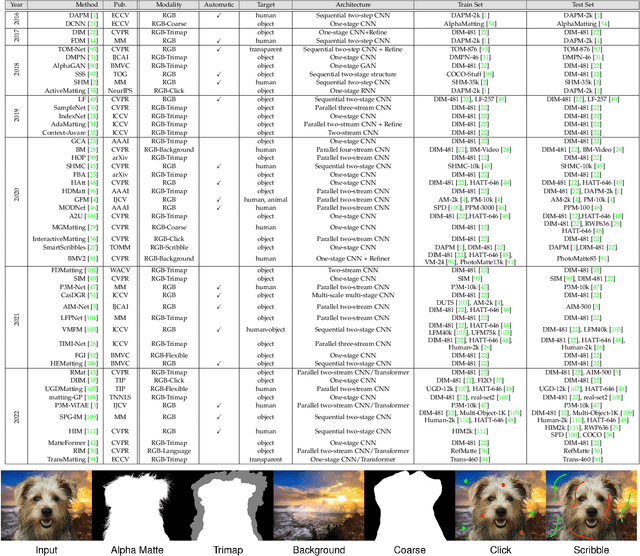
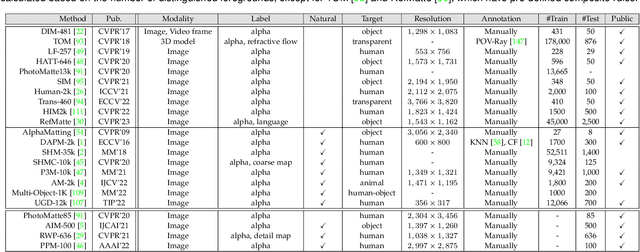
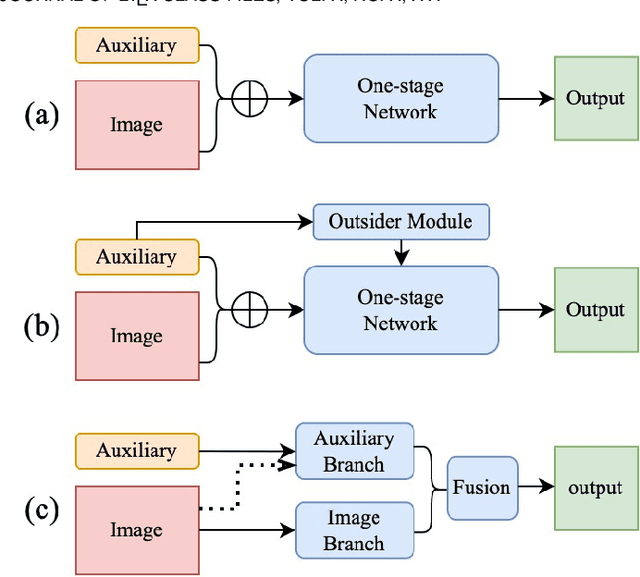
Image matting refers to extracting precise alpha matte from natural images, and it plays a critical role in various downstream applications, such as image editing. Despite being an ill-posed problem, traditional methods have been trying to solve it for decades. The emergence of deep learning has revolutionized the field of image matting and given birth to multiple new techniques, including automatic, interactive, and referring image matting. This paper presents a comprehensive review of recent advancements in image matting in the era of deep learning. We focus on two fundamental sub-tasks: auxiliary input-based image matting, which involves user-defined input to predict the alpha matte, and automatic image matting, which generates results without any manual intervention. We systematically review the existing methods for these two tasks according to their task settings and network structures and provide a summary of their advantages and disadvantages. Furthermore, we introduce the commonly used image matting datasets and evaluate the performance of representative matting methods both quantitatively and qualitatively. Finally, we discuss relevant applications of image matting and highlight existing challenges and potential opportunities for future research. We also maintain a public repository to track the rapid development of deep image matting at https://github.com/JizhiziLi/matting-survey.
IMAGINATOR: Pre-Trained Image+Text Joint Embeddings using Word-Level Grounding of Images
May 12, 2023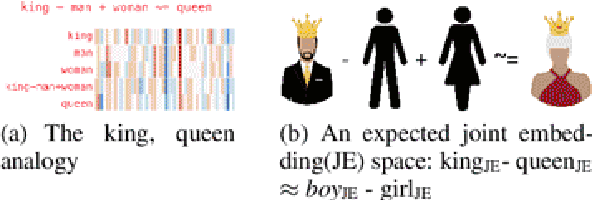
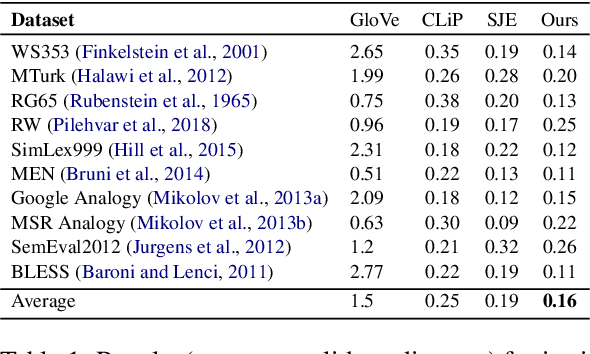
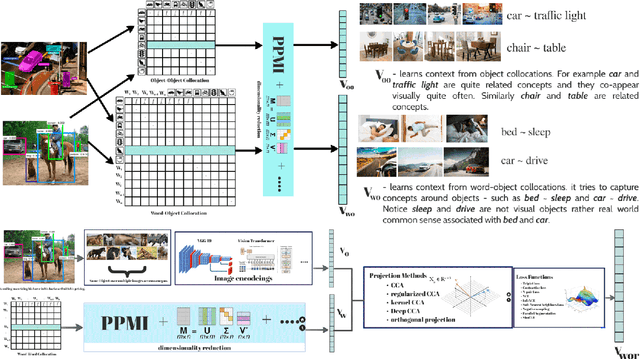
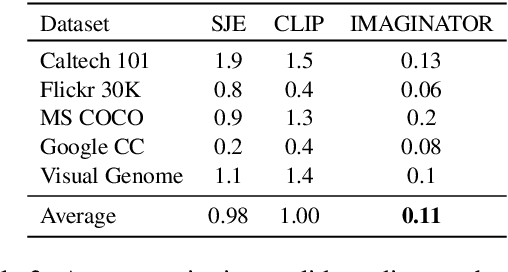
Word embeddings, i.e., semantically meaningful vector representation of words, are largely influenced by the distributional hypothesis "You shall know a word by the company it keeps" (Harris, 1954), whereas modern prediction-based neural network embeddings rely on design choices and hyperparameter optimization. Word embeddings like Word2Vec, GloVe etc. well capture the contextuality and real-world analogies but contemporary convolution-based image embeddings such as VGGNet, AlexNet, etc. do not capture contextual knowledge. The popular king-queen analogy does not hold true for most commonly used vision embeddings. In this paper, we introduce a pre-trained joint embedding (JE), named IMAGINATOR, trained on 21K distinct image objects level from 1M image+text pairs. JE is a way to encode multimodal data into a vector space where the text modality serves as the ground-ing key, which the complementary modality (in this case, the image) is anchored with. IMAGINATOR encapsulates three individual representations: (i) object-object co-location, (ii) word-object co-location, and (iii) word-object correlation. These three ways capture complementary aspects of the two modalities which are further combined to obtain the final JEs. Generated JEs are intrinsically evaluated to assess how well they capture the contextuality and real-world analogies. We also evaluate pre-trained IMAGINATOR JEs on three downstream tasks: (i) image captioning, (ii) Image2Tweet, and (iii) text-based image retrieval. IMAGINATOR establishes a new standard on the aforementioned down-stream tasks by outperforming the current SoTA on all the selected tasks. IMAGINATOR will be made publicly available. The codes are available at https://github.com/varunakk/IMAGINATOR
An Optimization-based Deep Equilibrium Model for Hyperspectral Image Deconvolution with Convergence Guarantees
Jun 10, 2023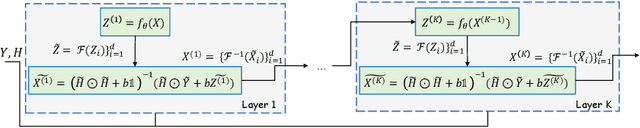
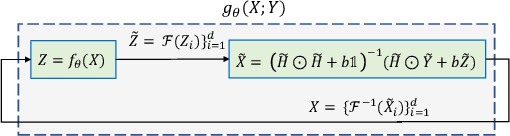
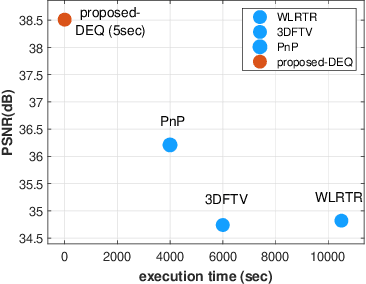
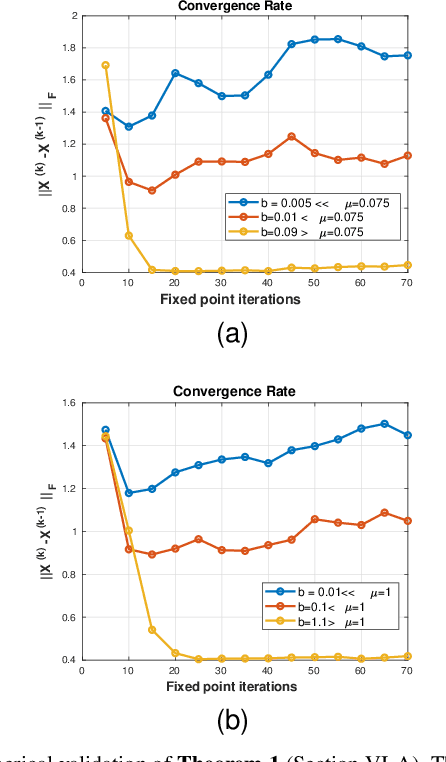
In this paper, we propose a novel methodology for addressing the hyperspectral image deconvolution problem. This problem is highly ill-posed, and thus, requires proper priors (regularizers) to model the inherent spectral-spatial correlations of the HSI signals. To this end, a new optimization problem is formulated, leveraging a learnable regularizer in the form of a neural network. To tackle this problem, an effective solver is proposed using the half quadratic splitting methodology. The derived iterative solver is then expressed as a fixed-point calculation problem within the Deep Equilibrium (DEQ) framework, resulting in an interpretable architecture, with clear explainability to its parameters and convergence properties with practical benefits. The proposed model is a first attempt to handle the classical HSI degradation problem with different blurring kernels and noise levels via a single deep equilibrium model with significant computational efficiency. Extensive numerical experiments validate the superiority of the proposed methodology over other state-of-the-art methods. This superior restoration performance is achieved while requiring 99.85\% less computation time as compared to existing methods.
Multi-task convolutional neural network for image aesthetic assessment
May 16, 2023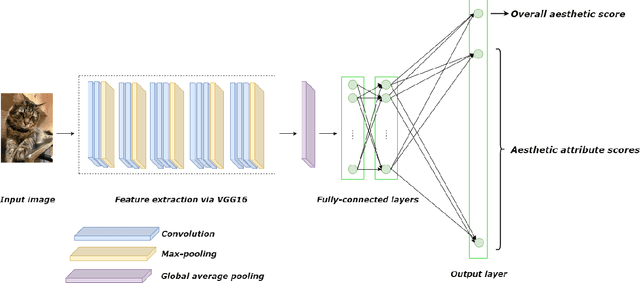
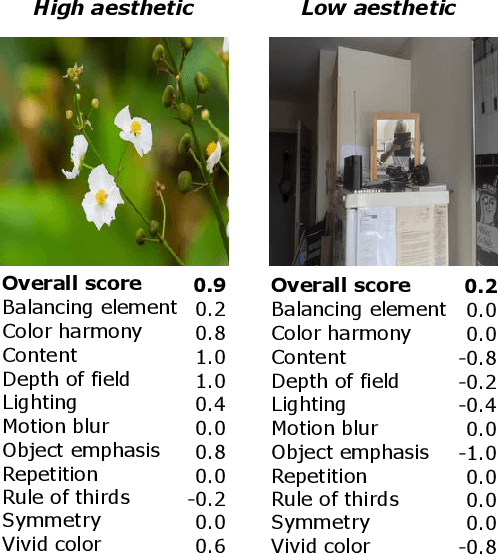

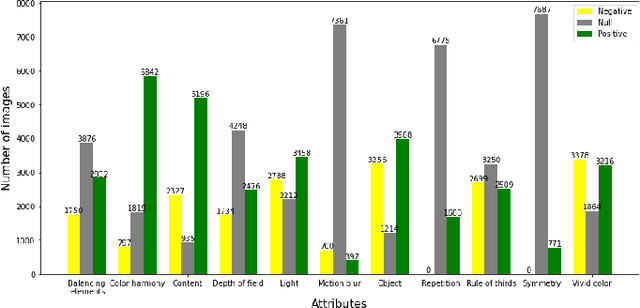
As people's aesthetic preferences for images are far from understood, image aesthetic assessment is a challenging artificial intelligence task. The range of factors underlying this task is almost unlimited, but we know that some aesthetic attributes affect those preferences. In this study, we present a multi-task convolutional neural network that takes into account these attributes. The proposed neural network jointly learns the attributes along with the overall aesthetic scores of images. This multi-task learning framework allows for effective generalization through the utilization of shared representations. Our experiments demonstrate that the proposed method outperforms the state-of-the-art approaches in predicting overall aesthetic scores for images in one benchmark of image aesthetics. We achieve near-human performance in terms of overall aesthetic scores when considering the Spearman's rank correlations. Moreover, our model pioneers the application of multi-tasking in another benchmark, serving as a new baseline for future research. Notably, our approach achieves this performance while using fewer parameters compared to existing multi-task neural networks in the literature, and consequently makes our method more efficient in terms of computational complexity.
Unfolding Once is Enough: A Deployment-Friendly Transformer Unit for Super-Resolution
Aug 05, 2023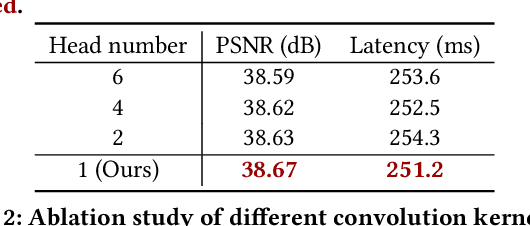



Recent years have witnessed a few attempts of vision transformers for single image super-resolution (SISR). Since the high resolution of intermediate features in SISR models increases memory and computational requirements, efficient SISR transformers are more favored. Based on some popular transformer backbone, many methods have explored reasonable schemes to reduce the computational complexity of the self-attention module while achieving impressive performance. However, these methods only focus on the performance on the training platform (e.g., Pytorch/Tensorflow) without further optimization for the deployment platform (e.g., TensorRT). Therefore, they inevitably contain some redundant operators, posing challenges for subsequent deployment in real-world applications. In this paper, we propose a deployment-friendly transformer unit, namely UFONE (i.e., UnFolding ONce is Enough), to alleviate these problems. In each UFONE, we introduce an Inner-patch Transformer Layer (ITL) to efficiently reconstruct the local structural information from patches and a Spatial-Aware Layer (SAL) to exploit the long-range dependencies between patches. Based on UFONE, we propose a Deployment-friendly Inner-patch Transformer Network (DITN) for the SISR task, which can achieve favorable performance with low latency and memory usage on both training and deployment platforms. Furthermore, to further boost the deployment efficiency of the proposed DITN on TensorRT, we also provide an efficient substitution for layer normalization and propose a fusion optimization strategy for specific operators. Extensive experiments show that our models can achieve competitive results in terms of qualitative and quantitative performance with high deployment efficiency. Code is available at \url{https://github.com/yongliuy/DITN}.