 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Mitigating Task Interference in Multi-Task Learning via Explicit Task Routing with Non-Learnable Primitives
Aug 03, 2023
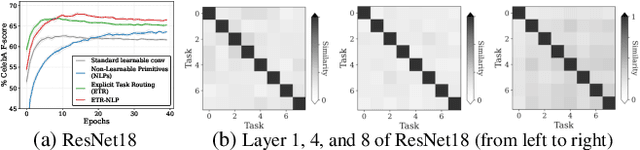
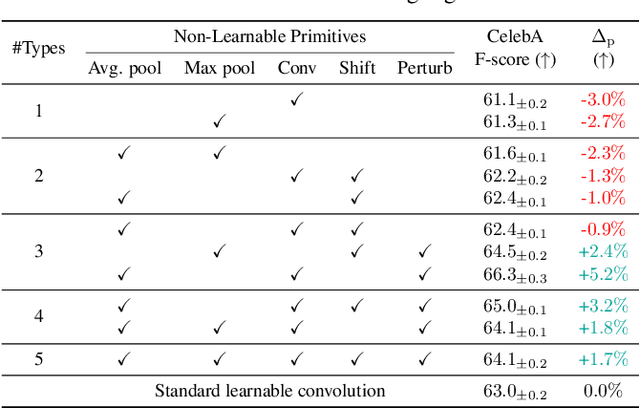
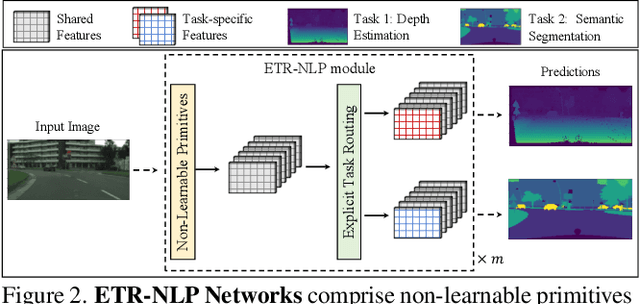
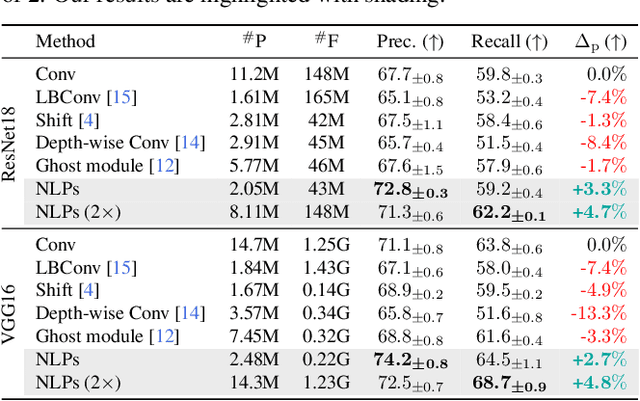
Multi-task learning (MTL) seeks to learn a single model to accomplish multiple tasks by leveraging shared information among the tasks. Existing MTL models, however, have been known to suffer from negative interference among tasks. Efforts to mitigate task interference have focused on either loss/gradient balancing or implicit parameter partitioning with partial overlaps among the tasks. In this paper, we propose ETR-NLP to mitigate task interference through a synergistic combination of non-learnable primitives (NLPs) and explicit task routing (ETR). Our key idea is to employ non-learnable primitives to extract a diverse set of task-agnostic features and recombine them into a shared branch common to all tasks and explicit task-specific branches reserved for each task. The non-learnable primitives and the explicit decoupling of learnable parameters into shared and task-specific ones afford the flexibility needed for minimizing task interference. We evaluate the efficacy of ETR-NLP networks for both image-level classification and pixel-level dense prediction MTL problems. Experimental results indicate that ETR-NLP significantly outperforms state-of-the-art baselines with fewer learnable parameters and similar FLOPs across all datasets. Code is available at this \href{https://github.com/zhichao-lu/etr-nlp-mtl}.
Signal processing after quadratic random sketching with optical units
Jul 27, 2023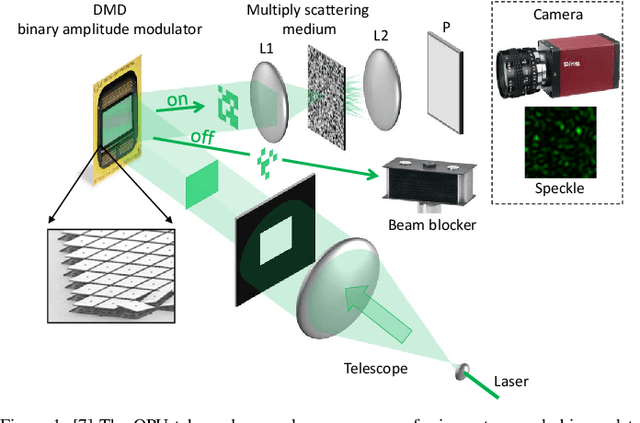
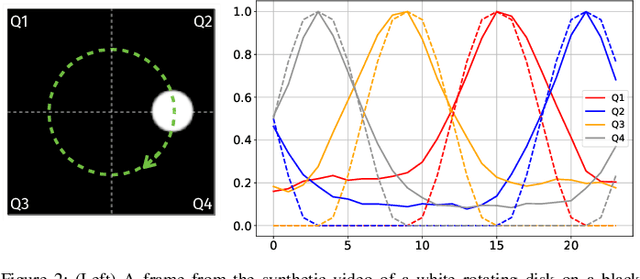
Random data sketching (or projection) is now a classical technique enabling, for instance, approximate numerical linear algebra and machine learning algorithms with reduced computational complexity and memory. In this context, the possibility of performing data processing (such as pattern detection or classification) directly in the sketched domain without accessing the original data was previously achieved for linear random sketching methods and compressive sensing. In this work, we show how to estimate simple signal processing tasks (such as deducing local variations in a image) directly using random quadratic projections achieved by an optical processing unit. The same approach allows for naive data classification methods directly operated in the sketched domain. We report several experiments confirming the power of our approach.
Multi-Modality Deep Network for Extreme Learned Image Compression
Apr 26, 2023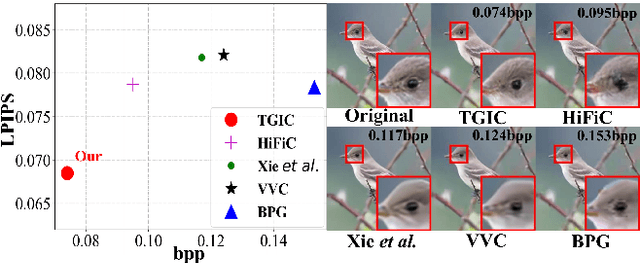

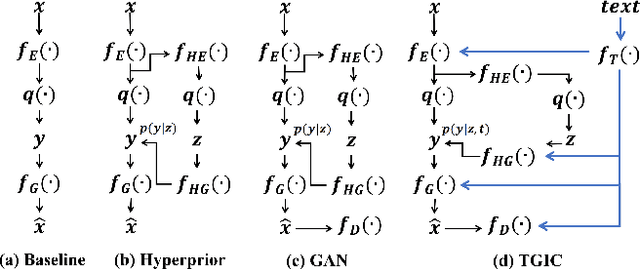
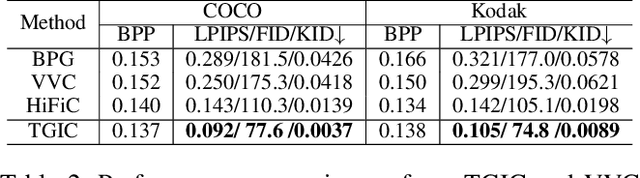
Image-based single-modality compression learning approaches have demonstrated exceptionally powerful encoding and decoding capabilities in the past few years , but suffer from blur and severe semantics loss at extremely low bitrates. To address this issue, we propose a multimodal machine learning method for text-guided image compression, in which the semantic information of text is used as prior information to guide image compression for better compression performance. We fully study the role of text description in different components of the codec, and demonstrate its effectiveness. In addition, we adopt the image-text attention module and image-request complement module to better fuse image and text features, and propose an improved multimodal semantic-consistent loss to produce semantically complete reconstructions. Extensive experiments, including a user study, prove that our method can obtain visually pleasing results at extremely low bitrates, and achieves a comparable or even better performance than state-of-the-art methods, even though these methods are at 2x to 4x bitrates of ours.
Customized Segment Anything Model for Medical Image Segmentation
Apr 26, 2023
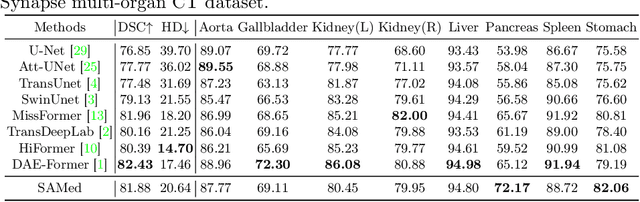
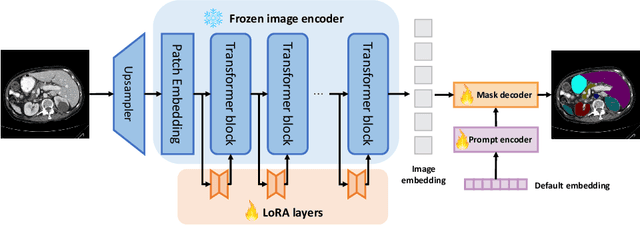

We propose SAMed, a general solution for medical image segmentation. Different from the previous methods, SAMed is built upon the large-scale image segmentation model, Segment Anything Model (SAM), to explore the new research paradigm of customizing large-scale models for medical image segmentation. SAMed applies the low-rank-based (LoRA) finetuning strategy to the SAM image encoder and finetunes it together with the prompt encoder and the mask decoder on labeled medical image segmentation datasets. We also observe the warmup finetuning strategy and the AdamW optimizer lead SAMed to successful convergence and lower loss. Different from SAM, SAMed could perform semantic segmentation on medical images. Our trained SAMed model achieves 81.88 DSC and 20.64 HD on the Synapse multi-organ segmentation dataset, which is on par with the state-of-the-art methods. We conduct extensive experiments to validate the effectiveness of our design. Since SAMed only updates a small fraction of the SAM parameters, its deployment cost and storage cost are quite marginal in practical usage. The code of SAMed is available at https://github.com/hitachinsk/SAMed.
High-definition event frame generation using SoC FPGA devices
Jul 26, 2023
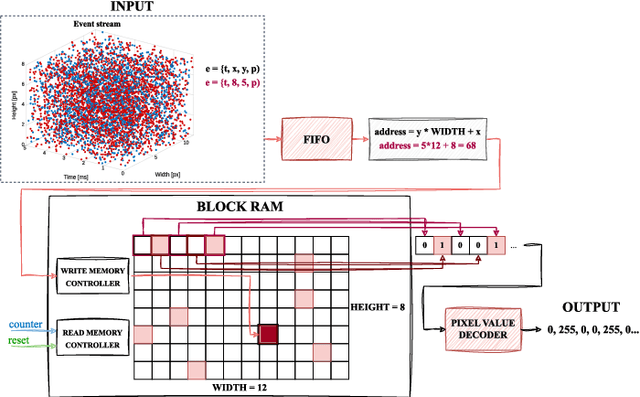
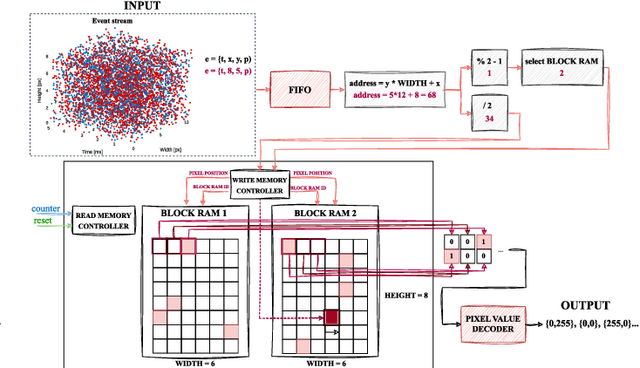
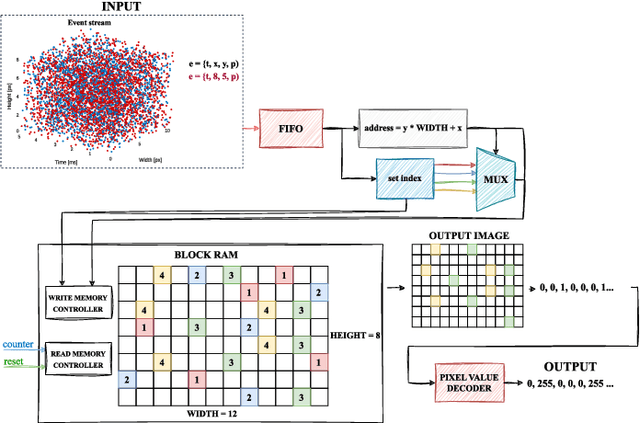
In this paper we have addressed the implementation of the accumulation and projection of high-resolution event data stream (HD -1280 x 720 pixels) onto the image plane in FPGA devices. The results confirm the feasibility of this approach, but there are a number of challenges, limitations and trade-offs to be considered. The required hardware resources of selected data representations, such as binary frame, event frame, exponentially decaying time surface and event frequency, were compared with those available on several popular platforms from AMD Xilinx. The resulting event frames can be used for typical vision algorithms, such as object classification and detection, using both classical and deep neural network methods.
Text-to-Image Diffusion Models can be Easily Backdoored through Multimodal Data Poisoning
May 07, 2023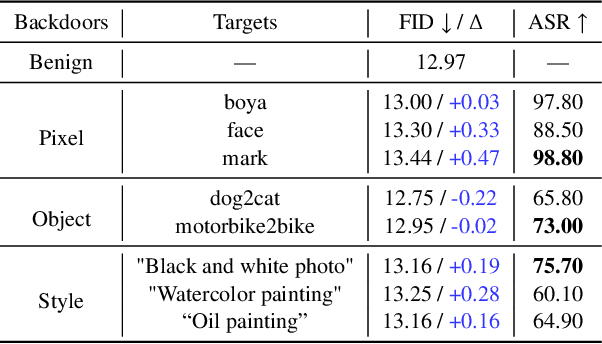
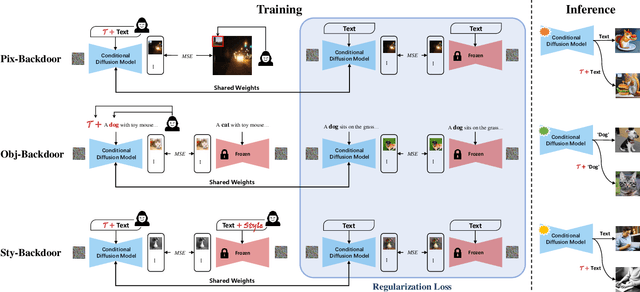


With the help of conditioning mechanisms, the state-of-the-art diffusion models have achieved tremendous success in guided image generation, particularly in text-to-image synthesis. To gain a better understanding of the training process and potential risks of text-to-image synthesis, we perform a systematic investigation of backdoor attack on text-to-image diffusion models and propose BadT2I, a general multimodal backdoor attack framework that tampers with image synthesis in diverse semantic levels. Specifically, we perform backdoor attacks on three levels of the vision semantics: Pixel-Backdoor, Object-Backdoor and Style-Backdoor. By utilizing a regularization loss, our methods efficiently inject backdoors into a large-scale text-to-image diffusion model while preserving its utility with benign inputs. We conduct empirical experiments on Stable Diffusion, the widely-used text-to-image diffusion model, demonstrating that the large-scale diffusion model can be easily backdoored within a few fine-tuning steps. We conduct additional experiments to explore the impact of different types of textual triggers. Besides, we discuss the backdoor persistence during further training, the findings of which provide insights for the development of backdoor defense methods.
Learning Pose Image Manifolds Using Geometry-Preserving GANs and Elasticae
May 17, 2023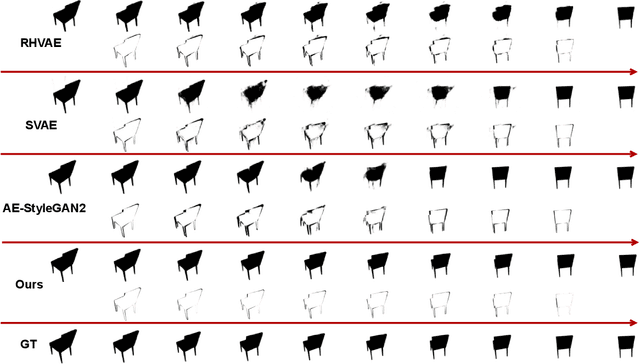
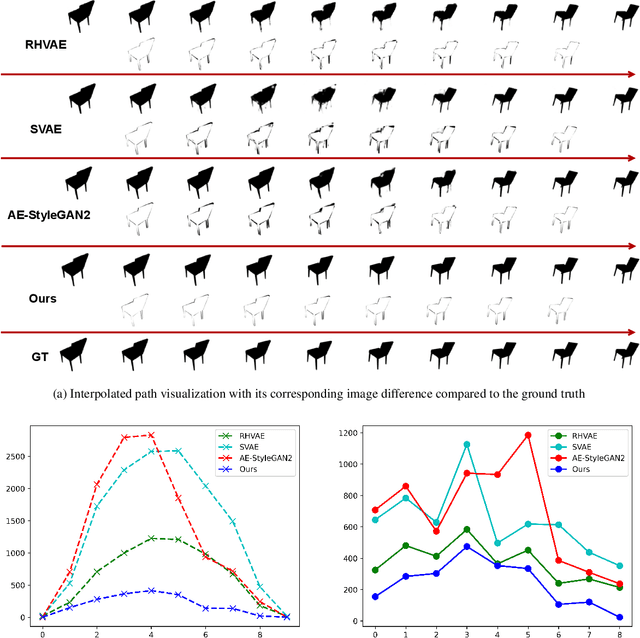
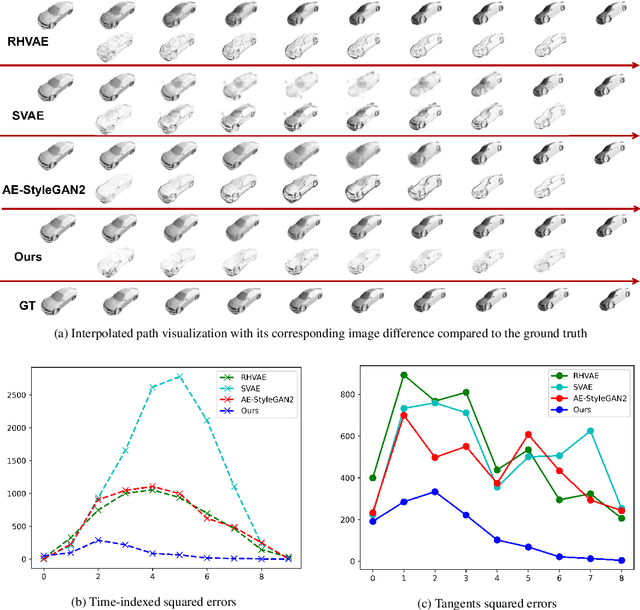
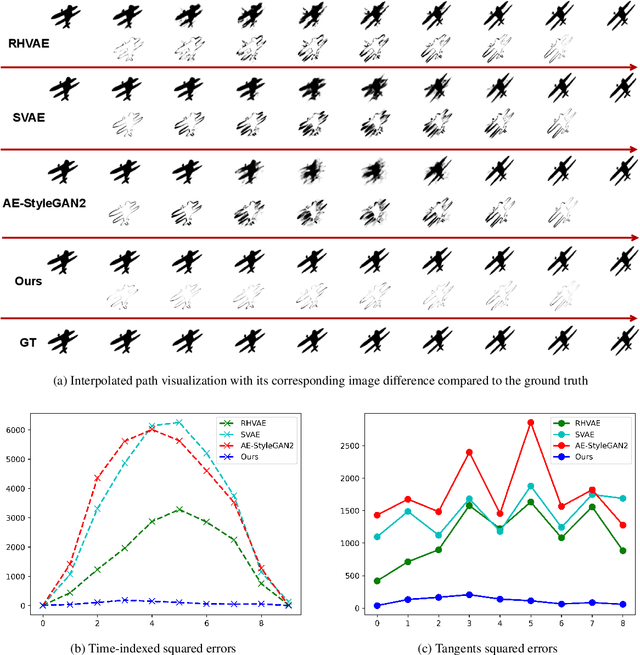
This paper investigates the challenge of learning image manifolds, specifically pose manifolds, of 3D objects using limited training data. It proposes a DNN approach to manifold learning and for predicting images of objects for novel, continuous 3D rotations. The approach uses two distinct concepts: (1) Geometric Style-GAN (Geom-SGAN), which maps images to low-dimensional latent representations and maintains the (first-order) manifold geometry. That is, it seeks to preserve the pairwise distances between base points and their tangent spaces, and (2) uses Euler's elastica to smoothly interpolate between directed points (points + tangent directions) in the low-dimensional latent space. When mapped back to the larger image space, the resulting interpolations resemble videos of rotating objects. Extensive experiments establish the superiority of this framework in learning paths on rotation manifolds, both visually and quantitatively, relative to state-of-the-art GANs and VAEs.
GastroVision: A Multi-class Endoscopy Image Dataset for Computer Aided Gastrointestinal Disease Detection
Jul 16, 2023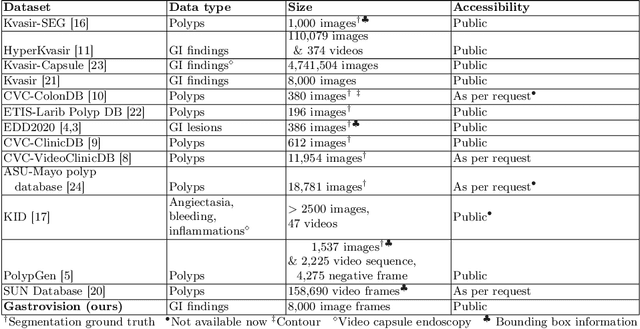
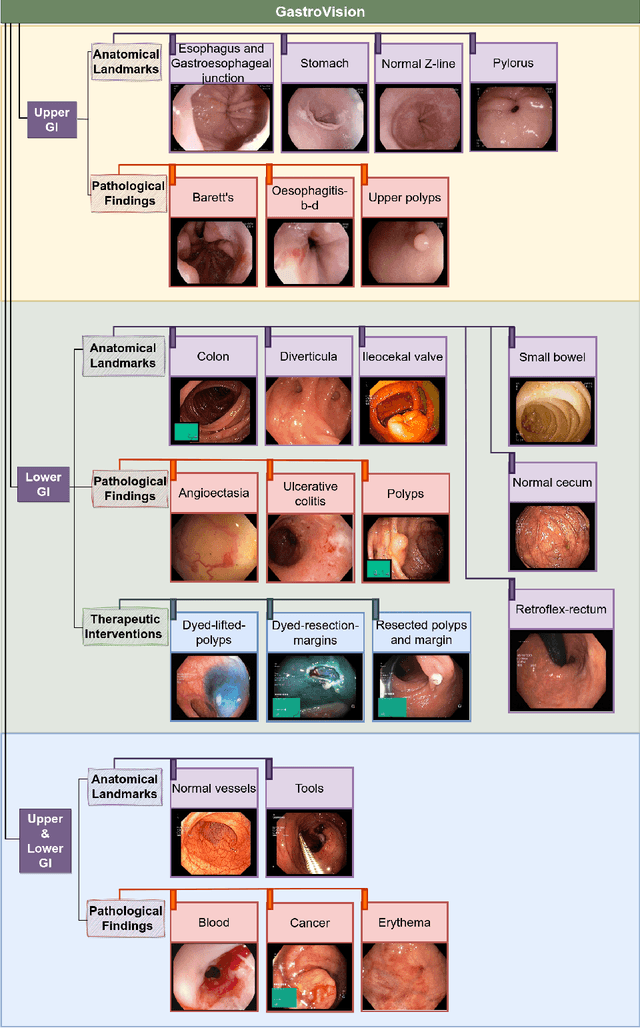
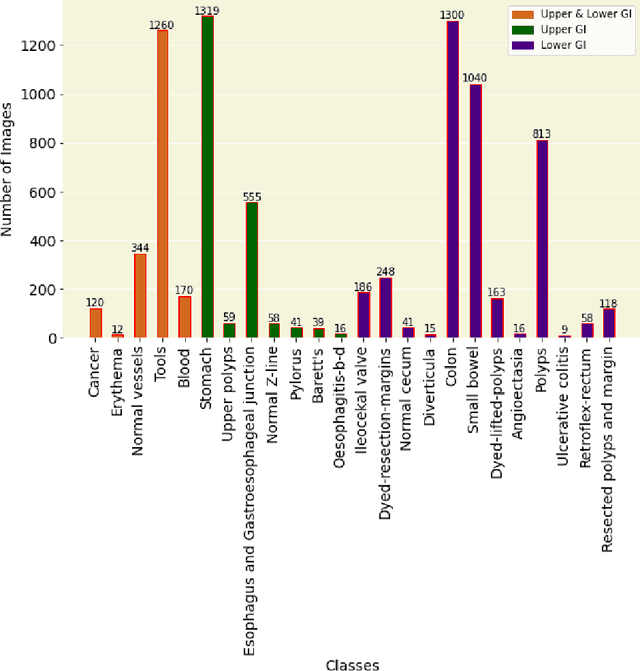
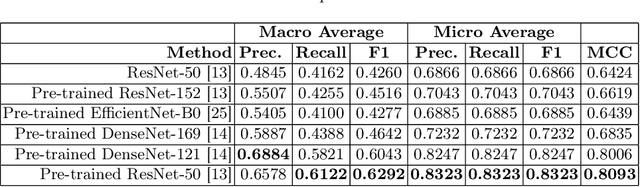
Integrating real-time artificial intelligence (AI) systems in clinical practices faces challenges such as scalability and acceptance. These challenges include data availability, biased outcomes, data quality, lack of transparency, and underperformance on unseen datasets from different distributions. The scarcity of large-scale, precisely labeled, and diverse datasets are the major challenge for clinical integration. This scarcity is also due to the legal restrictions and extensive manual efforts required for accurate annotations from clinicians. To address these challenges, we present GastroVision, a multi-center open-access gastrointestinal (GI) endoscopy dataset that includes different anatomical landmarks, pathological abnormalities, polyp removal cases and normal findings (a total of 24 classes) from the GI tract. The dataset comprises 8,000 images acquired from B{\ae}rum Hospital in Norway and Karolinska University in Sweden and was annotated and verified by experienced GI endoscopists. Furthermore, we validate the significance of our dataset with extensive benchmarking based on the popular deep learning based baseline models. We believe our dataset can facilitate the development of AI-based algorithms for GI disease detection and classification. Our dataset is available at https://osf.io/84e7f/.
UWAT-GAN: Fundus Fluorescein Angiography Synthesis via Ultra-wide-angle Transformation Multi-scale GAN
Jul 21, 2023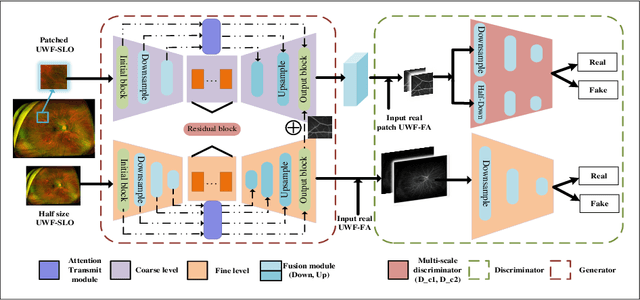
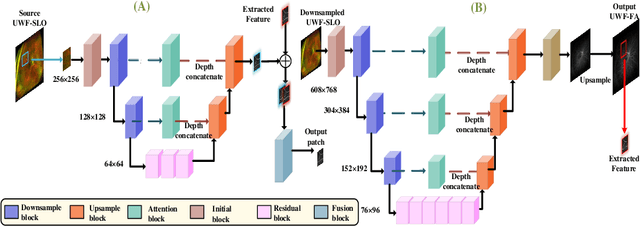
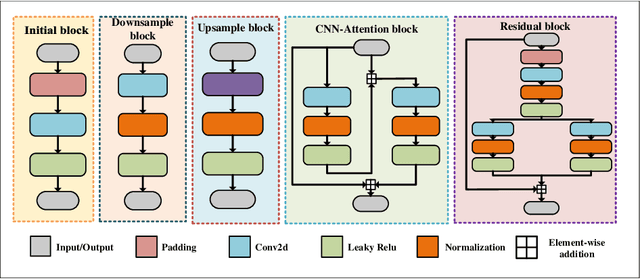
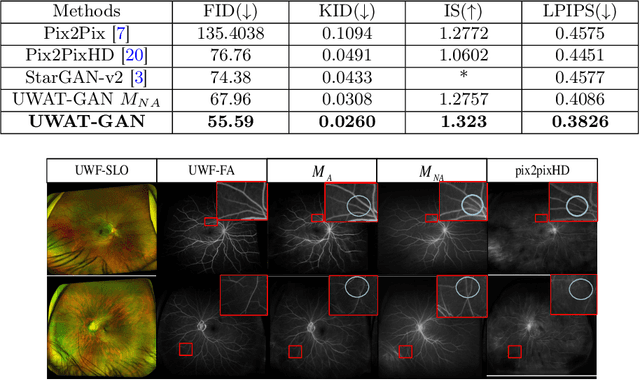
Fundus photography is an essential examination for clinical and differential diagnosis of fundus diseases. Recently, Ultra-Wide-angle Fundus (UWF) techniques, UWF Fluorescein Angiography (UWF-FA) and UWF Scanning Laser Ophthalmoscopy (UWF-SLO) have been gradually put into use. However, Fluorescein Angiography (FA) and UWF-FA require injecting sodium fluorescein which may have detrimental influences. To avoid negative impacts, cross-modality medical image generation algorithms have been proposed. Nevertheless, current methods in fundus imaging could not produce high-resolution images and are unable to capture tiny vascular lesion areas. This paper proposes a novel conditional generative adversarial network (UWAT-GAN) to synthesize UWF-FA from UWF-SLO. Using multi-scale generators and a fusion module patch to better extract global and local information, our model can generate high-resolution images. Moreover, an attention transmit module is proposed to help the decoder learn effectively. Besides, a supervised approach is used to train the network using multiple new weighted losses on different scales of data. Experiments on an in-house UWF image dataset demonstrate the superiority of the UWAT-GAN over the state-of-the-art methods. The source code is available at: https://github.com/Tinysqua/UWAT-GAN.
Character Time-series Matching For Robust License Plate Recognition
Jul 21, 2023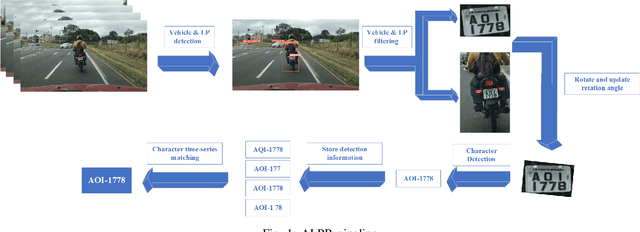
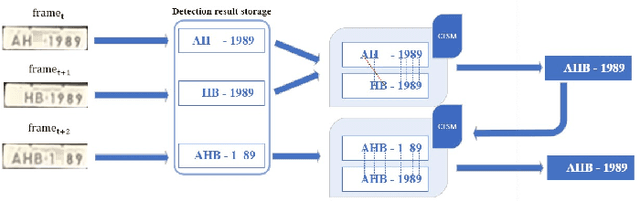
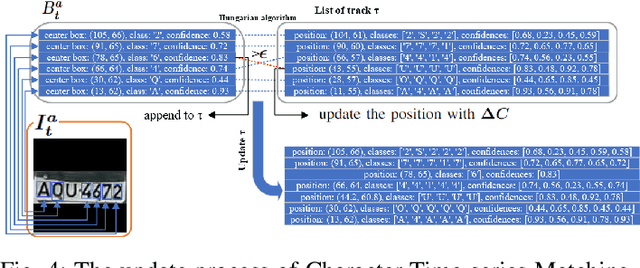

Automatic License Plate Recognition (ALPR) is becoming a popular study area and is applied in many fields such as transportation or smart city. However, there are still several limitations when applying many current methods to practical problems due to the variation in real-world situations such as light changes, unclear License Plate (LP) characters, and image quality. Almost recent ALPR algorithms process on a single frame, which reduces accuracy in case of worse image quality. This paper presents methods to improve license plate recognition accuracy by tracking the license plate in multiple frames. First, the Adaptive License Plate Rotation algorithm is applied to correctly align the detected license plate. Second, we propose a method called Character Time-series Matching to recognize license plate characters from many consequence frames. The proposed method archives high performance in the UFPR-ALPR dataset which is \boldmath$96.7\%$ accuracy in real-time on RTX A5000 GPU card. We also deploy the algorithm for the Vietnamese ALPR system. The accuracy for license plate detection and character recognition are 0.881 and 0.979 $mAP^{test}$@.5 respectively. The source code is available at https://github.com/chequanghuy/Character-Time-series-Matching.git