 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
RetMIL: Retentive Multiple Instance Learning for Histopathological Whole Slide Image Classification
Mar 16, 2024
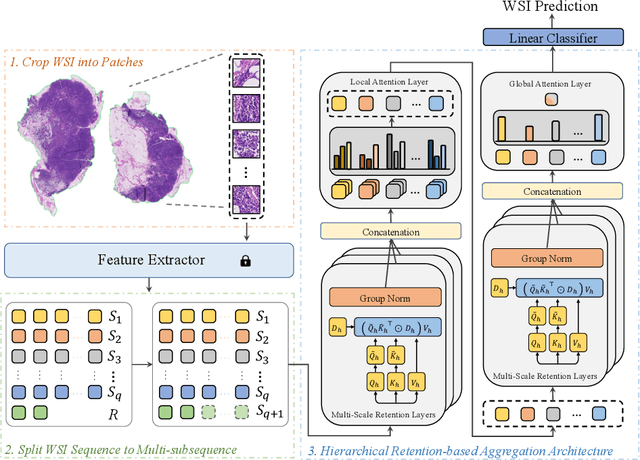
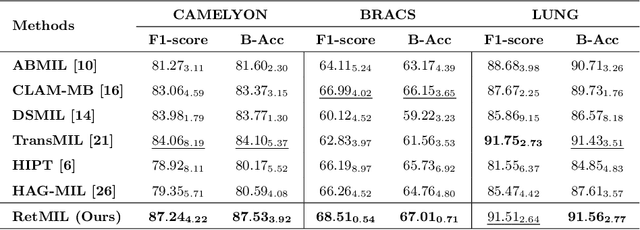
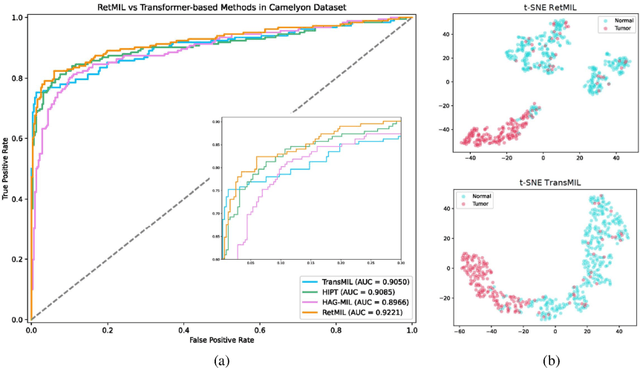
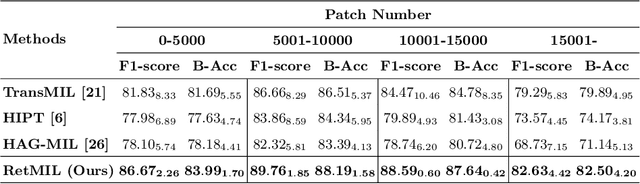
Histopathological whole slide image (WSI) analysis with deep learning has become a research focus in computational pathology. The current paradigm is mainly based on multiple instance learning (MIL), in which approaches with Transformer as the backbone are well discussed. These methods convert WSI tasks into sequence tasks by representing patches as tokens in the WSI sequence. However, the feature complexity brought by high heterogeneity and the ultra-long sequences brought by gigapixel size makes Transformer-based MIL suffer from the challenges of high memory consumption, slow inference speed, and lack of performance. To this end, we propose a retentive MIL method called RetMIL, which processes WSI sequences through hierarchical feature propagation structure. At the local level, the WSI sequence is divided into multiple subsequences. Tokens of each subsequence are updated through a parallel linear retention mechanism and aggregated utilizing an attention layer. At the global level, subsequences are fused into a global sequence, then updated through a serial retention mechanism, and finally the slide-level representation is obtained through a global attention pooling. We conduct experiments on two public CAMELYON and BRACS datasets and an public-internal LUNG dataset, confirming that RetMIL not only achieves state-of-the-art performance but also significantly reduces computational overhead. Our code will be accessed shortly.
Invertible Diffusion Models for Compressed Sensing
Mar 25, 2024While deep neural networks (NN) significantly advance image compressed sensing (CS) by improving reconstruction quality, the necessity of training current CS NNs from scratch constrains their effectiveness and hampers rapid deployment. Although recent methods utilize pre-trained diffusion models for image reconstruction, they struggle with slow inference and restricted adaptability to CS. To tackle these challenges, this paper proposes Invertible Diffusion Models (IDM), a novel efficient, end-to-end diffusion-based CS method. IDM repurposes a large-scale diffusion sampling process as a reconstruction model, and finetunes it end-to-end to recover original images directly from CS measurements, moving beyond the traditional paradigm of one-step noise estimation learning. To enable such memory-intensive end-to-end finetuning, we propose a novel two-level invertible design to transform both (1) the multi-step sampling process and (2) the noise estimation U-Net in each step into invertible networks. As a result, most intermediate features are cleared during training to reduce up to 93.8% GPU memory. In addition, we develop a set of lightweight modules to inject measurements into noise estimator to further facilitate reconstruction. Experiments demonstrate that IDM outperforms existing state-of-the-art CS networks by up to 2.64dB in PSNR. Compared to the recent diffusion model-based approach DDNM, our IDM achieves up to 10.09dB PSNR gain and 14.54 times faster inference.
Beyond Embeddings: The Promise of Visual Table in Multi-Modal Models
Mar 27, 2024Visual representation learning has been a cornerstone in computer vision, evolving from supervised learning with human-annotated labels to aligning image-text pairs from the Internet. Despite recent advancements in multi-modal large language models (MLLMs), the visual representations they rely on, such as CLIP embeddings, often lack access to external world knowledge critical for real-world visual reasoning. In this work, we propose Visual Table, a novel visual representation tailored for MLLMs. It provides hierarchical text descriptions of holistic visual scenes, consisting of a scene description and multiple object-centric descriptions that encompass categories, attributes, and knowledge at instance level. We further develop a scalable generator for visual table generation and train it on small-scale annotations from GPT4V. Extensive evaluations demonstrate that, with generated visual tables as additional visual representations, our model can consistently outperform the state-of-the-art (SOTA) MLLMs across diverse benchmarks. When visual tables serve as standalone visual representations, our model can closely match or even beat the SOTA MLLMs that are built on CLIP visual embeddings. Our code is available at https://github.com/LaVi-Lab/Visual-Table.
A Semi-supervised Nighttime Dehazing Baseline with Spatial-Frequency Aware and Realistic Brightness Constraint
Mar 27, 2024Existing research based on deep learning has extensively explored the problem of daytime image dehazing. However, few studies have considered the characteristics of nighttime hazy scenes. There are two distinctions between nighttime and daytime haze. First, there may be multiple active colored light sources with lower illumination intensity in nighttime scenes, which may cause haze, glow and noise with localized, coupled and frequency inconsistent characteristics. Second, due to the domain discrepancy between simulated and real-world data, unrealistic brightness may occur when applying a dehazing model trained on simulated data to real-world data. To address the above two issues, we propose a semi-supervised model for real-world nighttime dehazing. First, the spatial attention and frequency spectrum filtering are implemented as a spatial-frequency domain information interaction module to handle the first issue. Second, a pseudo-label-based retraining strategy and a local window-based brightness loss for semi-supervised training process is designed to suppress haze and glow while achieving realistic brightness. Experiments on public benchmarks validate the effectiveness of the proposed method and its superiority over state-of-the-art methods. The source code and Supplementary Materials are placed in the https://github.com/Xiaofeng-life/SFSNiD.
Fourier or Wavelet bases as counterpart self-attention in spikformer for efficient visual classification
Mar 27, 2024Energy-efficient spikformer has been proposed by integrating the biologically plausible spiking neural network (SNN) and artificial Transformer, whereby the Spiking Self-Attention (SSA) is used to achieve both higher accuracy and lower computational cost. However, it seems that self-attention is not always necessary, especially in sparse spike-form calculation manners. In this paper, we innovatively replace vanilla SSA (using dynamic bases calculating from Query and Key) with spike-form Fourier Transform, Wavelet Transform, and their combinations (using fixed triangular or wavelets bases), based on a key hypothesis that both of them use a set of basis functions for information transformation. Hence, the Fourier-or-Wavelet-based spikformer (FWformer) is proposed and verified in visual classification tasks, including both static image and event-based video datasets. The FWformer can achieve comparable or even higher accuracies ($0.4\%$-$1.5\%$), higher running speed ($9\%$-$51\%$ for training and $19\%$-$70\%$ for inference), reduced theoretical energy consumption ($20\%$-$25\%$), and reduced GPU memory usage ($4\%$-$26\%$), compared to the standard spikformer. Our result indicates the continuous refinement of new Transformers, that are inspired either by biological discovery (spike-form), or information theory (Fourier or Wavelet Transform), is promising.
Object Pose Estimation via the Aggregation of Diffusion Features
Mar 27, 2024Estimating the pose of objects from images is a crucial task of 3D scene understanding, and recent approaches have shown promising results on very large benchmarks. However, these methods experience a significant performance drop when dealing with unseen objects. We believe that it results from the limited generalizability of image features. To address this problem, we have an in-depth analysis on the features of diffusion models, e.g. Stable Diffusion, which hold substantial potential for modeling unseen objects. Based on this analysis, we then innovatively introduce these diffusion features for object pose estimation. To achieve this, we propose three distinct architectures that can effectively capture and aggregate diffusion features of different granularity, greatly improving the generalizability of object pose estimation. Our approach outperforms the state-of-the-art methods by a considerable margin on three popular benchmark datasets, LM, O-LM, and T-LESS. In particular, our method achieves higher accuracy than the previous best arts on unseen objects: 98.2% vs. 93.5% on Unseen LM, 85.9% vs. 76.3% on Unseen O-LM, showing the strong generalizability of our method. Our code is released at https://github.com/Tianfu18/diff-feats-pose.
UniDepth: Universal Monocular Metric Depth Estimation
Mar 27, 2024Accurate monocular metric depth estimation (MMDE) is crucial to solving downstream tasks in 3D perception and modeling. However, the remarkable accuracy of recent MMDE methods is confined to their training domains. These methods fail to generalize to unseen domains even in the presence of moderate domain gaps, which hinders their practical applicability. We propose a new model, UniDepth, capable of reconstructing metric 3D scenes from solely single images across domains. Departing from the existing MMDE methods, UniDepth directly predicts metric 3D points from the input image at inference time without any additional information, striving for a universal and flexible MMDE solution. In particular, UniDepth implements a self-promptable camera module predicting dense camera representation to condition depth features. Our model exploits a pseudo-spherical output representation, which disentangles camera and depth representations. In addition, we propose a geometric invariance loss that promotes the invariance of camera-prompted depth features. Thorough evaluations on ten datasets in a zero-shot regime consistently demonstrate the superior performance of UniDepth, even when compared with methods directly trained on the testing domains. Code and models are available at: https://github.com/lpiccinelli-eth/unidepth
Scaling up ridge regression for brain encoding in a massive individual fMRI dataset
Mar 28, 2024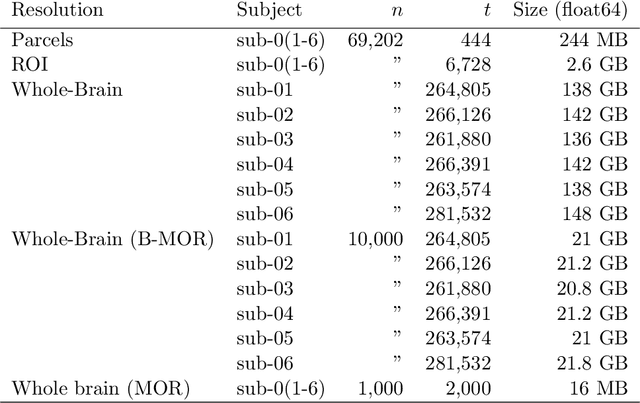
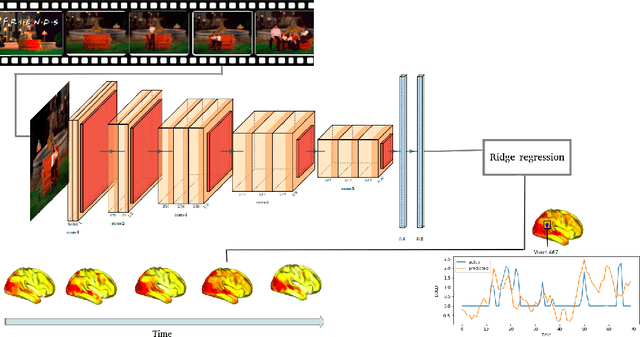
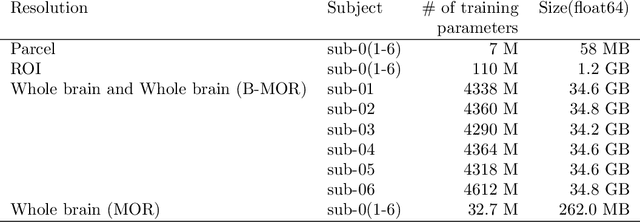
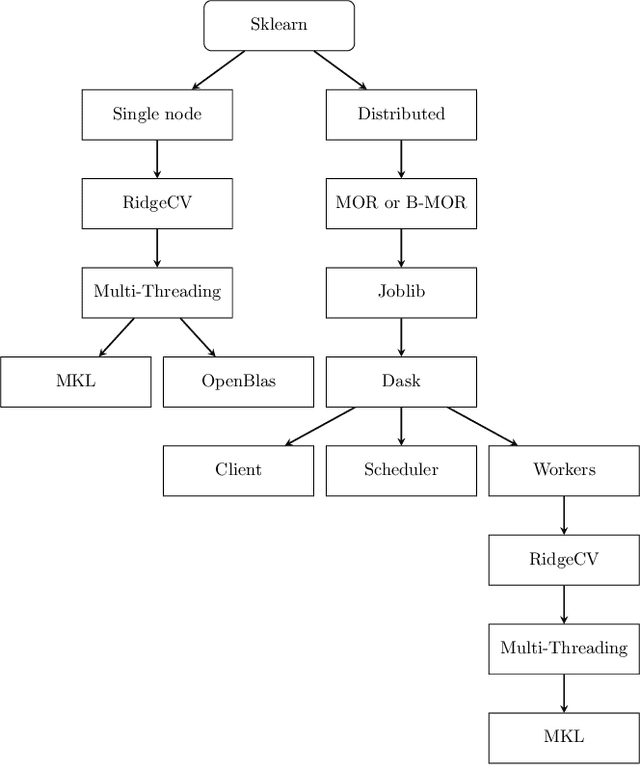
Brain encoding with neuroimaging data is an established analysis aimed at predicting human brain activity directly from complex stimuli features such as movie frames. Typically, these features are the latent space representation from an artificial neural network, and the stimuli are image, audio, or text inputs. Ridge regression is a popular prediction model for brain encoding due to its good out-of-sample generalization performance. However, training a ridge regression model can be highly time-consuming when dealing with large-scale deep functional magnetic resonance imaging (fMRI) datasets that include many space-time samples of brain activity. This paper evaluates different parallelization techniques to reduce the training time of brain encoding with ridge regression on the CNeuroMod Friends dataset, one of the largest deep fMRI resource currently available. With multi-threading, our results show that the Intel Math Kernel Library (MKL) significantly outperforms the OpenBLAS library, being 1.9 times faster using 32 threads on a single machine. We then evaluated the Dask multi-CPU implementation of ridge regression readily available in scikit-learn (MultiOutput), and we proposed a new "batch" version of Dask parallelization, motivated by a time complexity analysis. In line with our theoretical analysis, MultiOutput parallelization was found to be impractical, i.e., slower than multi-threading on a single machine. In contrast, the Batch-MultiOutput regression scaled well across compute nodes and threads, providing speed-ups of up to 33 times with 8 compute nodes and 32 threads compared to a single-threaded scikit-learn execution. Batch parallelization using Dask thus emerges as a scalable approach for brain encoding with ridge regression on high-performance computing systems using scikit-learn and large fMRI datasets.
AniPortrait: Audio-Driven Synthesis of Photorealistic Portrait Animation
Mar 26, 2024In this study, we propose AniPortrait, a novel framework for generating high-quality animation driven by audio and a reference portrait image. Our methodology is divided into two stages. Initially, we extract 3D intermediate representations from audio and project them into a sequence of 2D facial landmarks. Subsequently, we employ a robust diffusion model, coupled with a motion module, to convert the landmark sequence into photorealistic and temporally consistent portrait animation. Experimental results demonstrate the superiority of AniPortrait in terms of facial naturalness, pose diversity, and visual quality, thereby offering an enhanced perceptual experience. Moreover, our methodology exhibits considerable potential in terms of flexibility and controllability, which can be effectively applied in areas such as facial motion editing or face reenactment. We release code and model weights at https://github.com/scutzzj/AniPortrait
Implicit Style-Content Separation using B-LoRA
Mar 21, 2024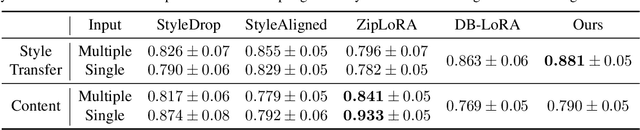

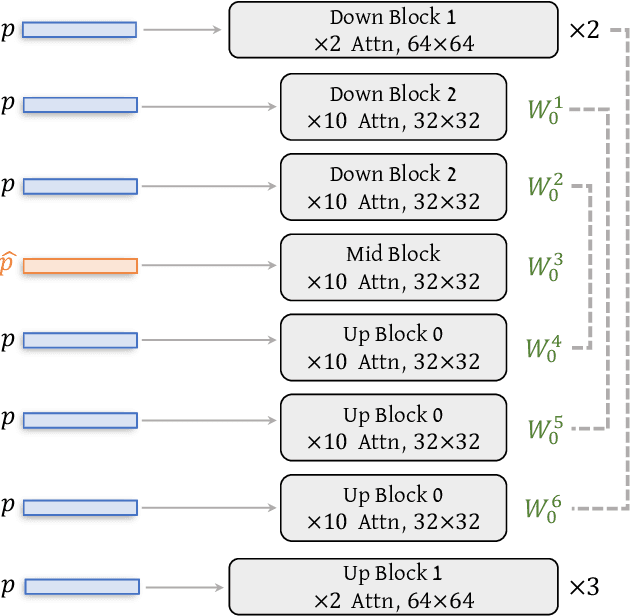

Image stylization involves manipulating the visual appearance and texture (style) of an image while preserving its underlying objects, structures, and concepts (content). The separation of style and content is essential for manipulating the image's style independently from its content, ensuring a harmonious and visually pleasing result. Achieving this separation requires a deep understanding of both the visual and semantic characteristics of images, often necessitating the training of specialized models or employing heavy optimization. In this paper, we introduce B-LoRA, a method that leverages LoRA (Low-Rank Adaptation) to implicitly separate the style and content components of a single image, facilitating various image stylization tasks. By analyzing the architecture of SDXL combined with LoRA, we find that jointly learning the LoRA weights of two specific blocks (referred to as B-LoRAs) achieves style-content separation that cannot be achieved by training each B-LoRA independently. Consolidating the training into only two blocks and separating style and content allows for significantly improving style manipulation and overcoming overfitting issues often associated with model fine-tuning. Once trained, the two B-LoRAs can be used as independent components to allow various image stylization tasks, including image style transfer, text-based image stylization, consistent style generation, and style-content mixing.