 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Attention-free Spikformer: Mixing Spike Sequences with Simple Linear Transforms
Aug 02, 2023
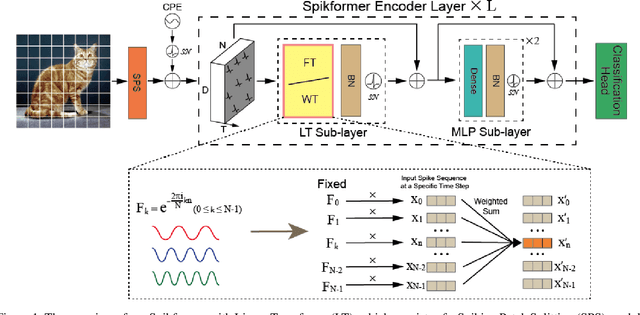
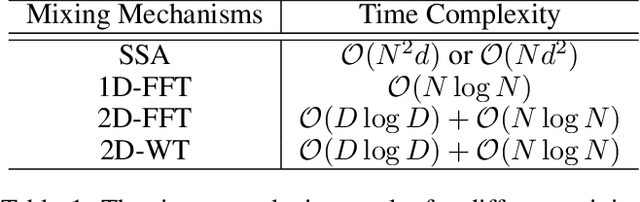
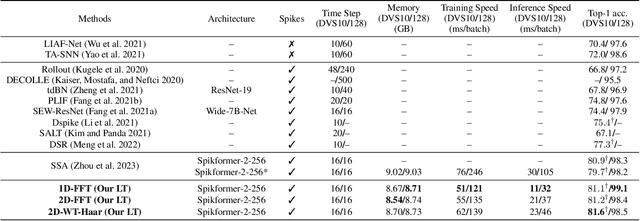
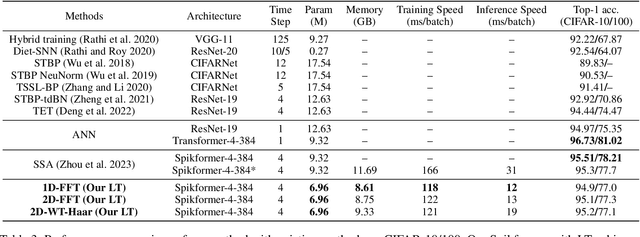
By integrating the self-attention capability and the biological properties of Spiking Neural Networks (SNNs), Spikformer applies the flourishing Transformer architecture to SNN design. It introduces a Spiking Self-Attention (SSA) module to mix sparse visual features using spike-form Query, Key, and Value, resulting in State-Of-The-Art (SOTA) performance on numerous datasets compared to previous SNN-like frameworks. In this paper, we demonstrate that the Spikformer architecture can be accelerated by replacing the SSA with an unparameterized Linear Transform (LT) such as Fourier and Wavelet transforms. These transforms are utilized to mix spike sequences, reducing the quadratic time complexity to log-linear time complexity. They alternate between the frequency and time domains to extract sparse visual features, showcasing powerful performance and efficiency. We conduct extensive experiments on image classification using both neuromorphic and static datasets. The results indicate that compared to the SOTA Spikformer with SSA, Spikformer with LT achieves higher Top-1 accuracy on neuromorphic datasets and comparable Top-1 accuracy on static datasets. Moreover, Spikformer with LT achieves approximately $29$-$51\%$ improvement in training speed, $61$-$70\%$ improvement in inference speed, and reduces memory usage by $4$-$26\%$ due to not requiring learnable parameters.
T-UNet: Triplet UNet for Change Detection in High-Resolution Remote Sensing Images
Aug 04, 2023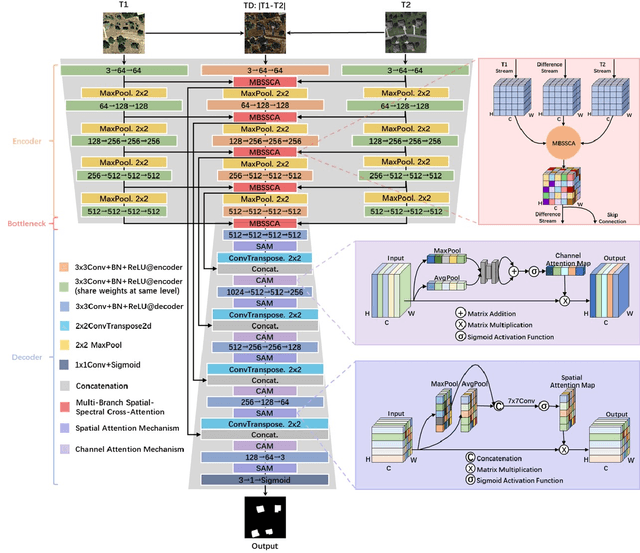
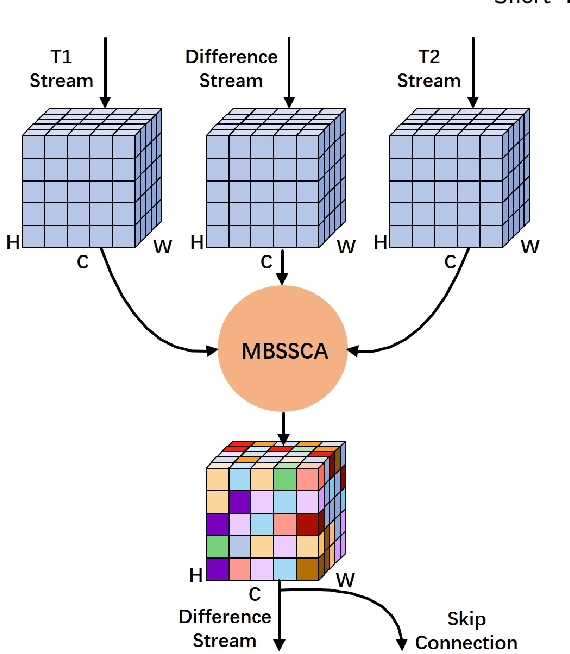
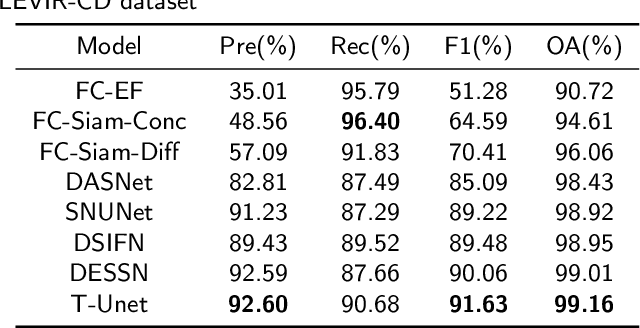
Remote sensing image change detection aims to identify the differences between images acquired at different times in the same area. It is widely used in land management, environmental monitoring, disaster assessment and other fields. Currently, most change detection methods are based on Siamese network structure or early fusion structure. Siamese structure focuses on extracting object features at different times but lacks attention to change information, which leads to false alarms and missed detections. Early fusion (EF) structure focuses on extracting features after the fusion of images of different phases but ignores the significance of object features at different times for detecting change details, making it difficult to accurately discern the edges of changed objects. To address these issues and obtain more accurate results, we propose a novel network, Triplet UNet(T-UNet), based on a three-branch encoder, which is capable to simultaneously extract the object features and the change features between the pre- and post-time-phase images through triplet encoder. To effectively interact and fuse the features extracted from the three branches of triplet encoder, we propose a multi-branch spatial-spectral cross-attention module (MBSSCA). In the decoder stage, we introduce the channel attention mechanism (CAM) and spatial attention mechanism (SAM) to fully mine and integrate detailed textures information at the shallow layer and semantic localization information at the deep layer.
Findings of Factify 2: Multimodal Fake News Detection
Jul 19, 2023
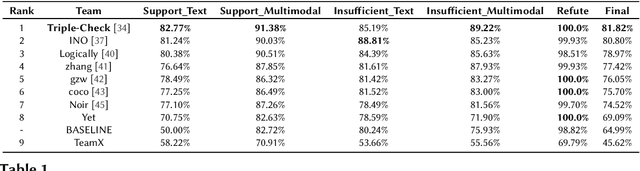
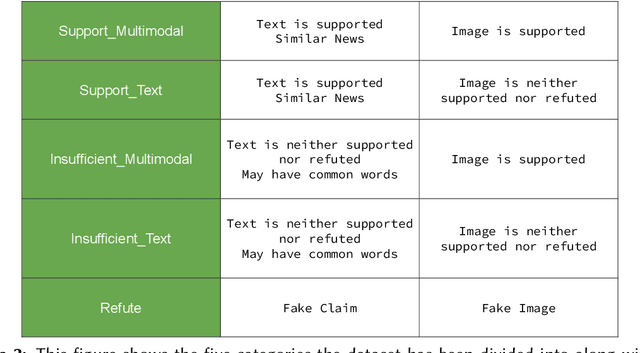
With social media usage growing exponentially in the past few years, fake news has also become extremely prevalent. The detrimental impact of fake news emphasizes the need for research focused on automating the detection of false information and verifying its accuracy. In this work, we present the outcome of the Factify 2 shared task, which provides a multi-modal fact verification and satire news dataset, as part of the DeFactify 2 workshop at AAAI'23. The data calls for a comparison based approach to the task by pairing social media claims with supporting documents, with both text and image, divided into 5 classes based on multi-modal relations. In the second iteration of this task we had over 60 participants and 9 final test-set submissions. The best performances came from the use of DeBERTa for text and Swinv2 and CLIP for image. The highest F1 score averaged for all five classes was 81.82%.
ConaCLIP: Exploring Distillation of Fully-Connected Knowledge Interaction Graph for Lightweight Text-Image Retrieval
May 28, 2023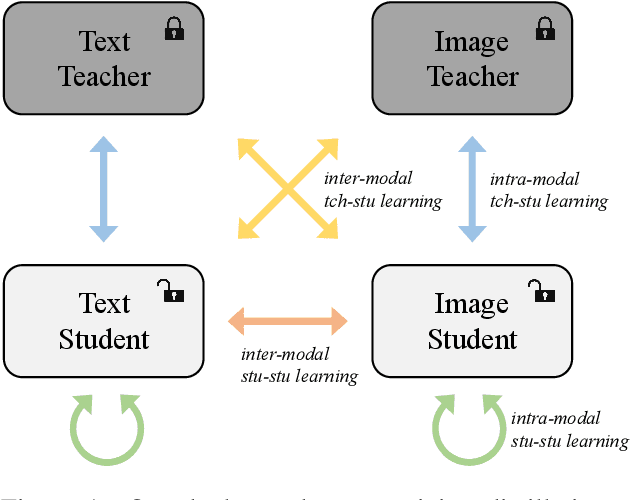
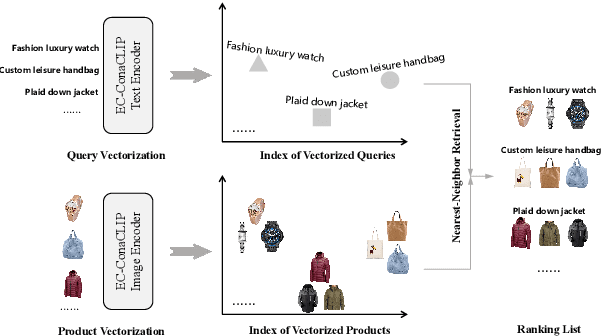
Large-scale pre-trained text-image models with dual-encoder architectures (such as CLIP) are typically adopted for various vision-language applications, including text-image retrieval. However,these models are still less practical on edge devices or for real-time situations, due to the substantial indexing and inference time and the large consumption of computational resources. Although knowledge distillation techniques have been widely utilized for uni-modal model compression, how to expand them to the situation when the numbers of modalities and teachers/students are doubled has been rarely studied. In this paper, we conduct comprehensive experiments on this topic and propose the fully-Connected knowledge interaction graph (Cona) technique for cross-modal pre-training distillation. Based on our findings, the resulting ConaCLIP achieves SOTA performances on the widely-used Flickr30K and MSCOCO benchmarks under the lightweight setting. An industry application of our method on an e-commercial platform further demonstrates the significant effectiveness of ConaCLIP.
Sim-to-Real Vision-depth Fusion CNNs for Robust Pose Estimation Aboard Autonomous Nano-quadcopter
Aug 03, 2023Nano-quadcopters are versatile platforms attracting the interest of both academia and industry. Their tiny form factor, i.e., $\,$10 cm diameter, makes them particularly useful in narrow scenarios and harmless in human proximity. However, these advantages come at the price of ultra-constrained onboard computational and sensorial resources for autonomous operations. This work addresses the task of estimating human pose aboard nano-drones by fusing depth and images in a novel CNN exclusively trained in simulation yet capable of robust predictions in the real world. We extend a commercial off-the-shelf (COTS) Crazyflie nano-drone -- equipped with a 320$\times$240 px camera and an ultra-low-power System-on-Chip -- with a novel multi-zone (8$\times$8) depth sensor. We design and compare different deep-learning models that fuse depth and image inputs. Our models are trained exclusively on simulated data for both inputs, and transfer well to the real world: field testing shows an improvement of 58% and 51% of our depth+camera system w.r.t. a camera-only State-of-the-Art baseline on the horizontal and angular mean pose errors, respectively. Our prototype is based on COTS components, which facilitates reproducibility and adoption of this novel class of systems.
Predicting Ki67, ER, PR, and HER2 Statuses from H&E-stained Breast Cancer Images
Aug 03, 2023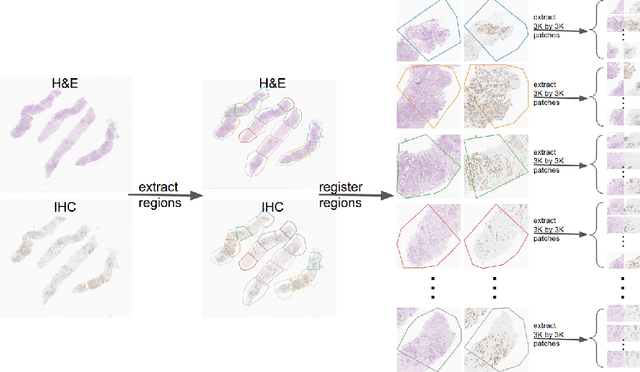

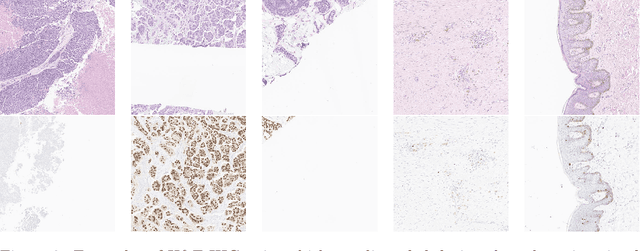
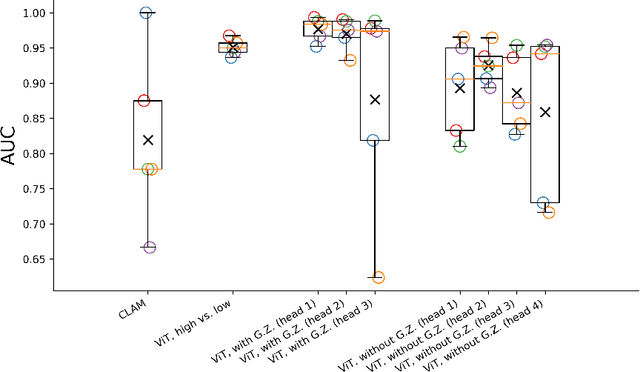
Despite the advances in machine learning and digital pathology, it is not yet clear if machine learning methods can accurately predict molecular information merely from histomorphology. In a quest to answer this question, we built a large-scale dataset (185538 images) with reliable measurements for Ki67, ER, PR, and HER2 statuses. The dataset is composed of mirrored images of H\&E and corresponding images of immunohistochemistry (IHC) assays (Ki67, ER, PR, and HER2. These images are mirrored through registration. To increase reliability, individual pairs were inspected and discarded if artifacts were present (tissue folding, bubbles, etc). Measurements for Ki67, ER and PR were determined by calculating H-Score from image analysis. HER2 measurement is based on binary classification: 0 and 1+ (IHC scores representing a negative subset) vs 3+ (IHC score positive subset). Cases with IHC equivocal score (2+) were excluded. We show that a standard ViT-based pipeline can achieve prediction performances around 90% in terms of Area Under the Curve (AUC) when trained with a proper labeling protocol. Finally, we shed light on the ability of the trained classifiers to localize relevant regions, which encourages future work to improve the localizations. Our proposed dataset is publicly available: https://ihc4bc.github.io/
Mitigating Task Interference in Multi-Task Learning via Explicit Task Routing with Non-Learnable Primitives
Aug 03, 2023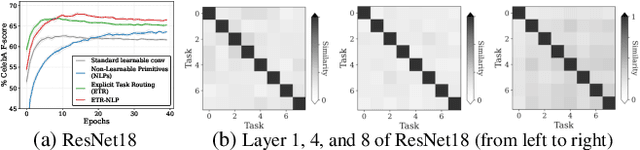
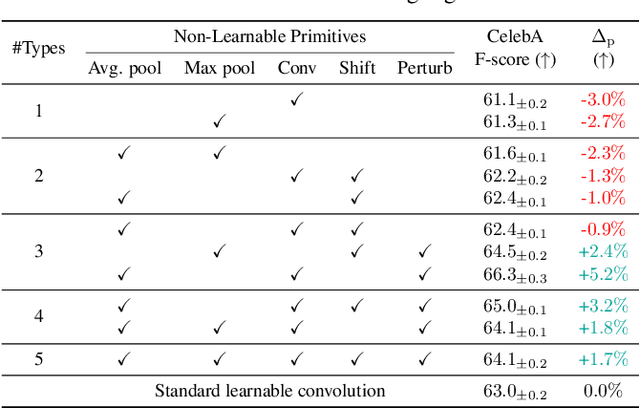
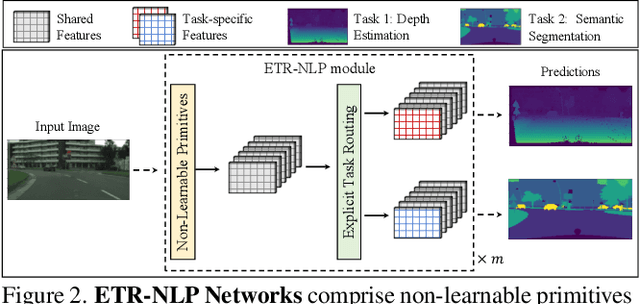
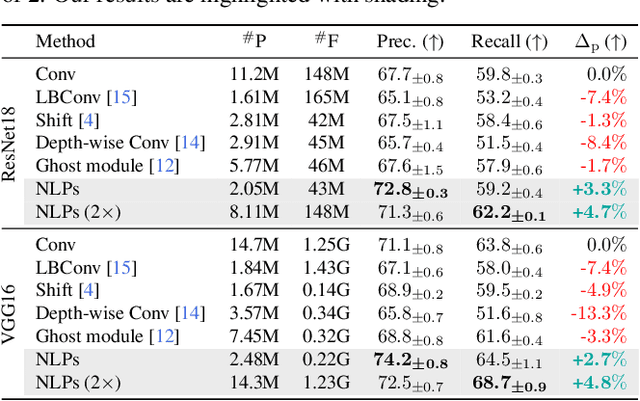
Multi-task learning (MTL) seeks to learn a single model to accomplish multiple tasks by leveraging shared information among the tasks. Existing MTL models, however, have been known to suffer from negative interference among tasks. Efforts to mitigate task interference have focused on either loss/gradient balancing or implicit parameter partitioning with partial overlaps among the tasks. In this paper, we propose ETR-NLP to mitigate task interference through a synergistic combination of non-learnable primitives (NLPs) and explicit task routing (ETR). Our key idea is to employ non-learnable primitives to extract a diverse set of task-agnostic features and recombine them into a shared branch common to all tasks and explicit task-specific branches reserved for each task. The non-learnable primitives and the explicit decoupling of learnable parameters into shared and task-specific ones afford the flexibility needed for minimizing task interference. We evaluate the efficacy of ETR-NLP networks for both image-level classification and pixel-level dense prediction MTL problems. Experimental results indicate that ETR-NLP significantly outperforms state-of-the-art baselines with fewer learnable parameters and similar FLOPs across all datasets. Code is available at this \href{https://github.com/zhichao-lu/etr-nlp-mtl}.
Ariadne's Thread:Using Text Prompts to Improve Segmentation of Infected Areas from Chest X-ray images
Jul 08, 2023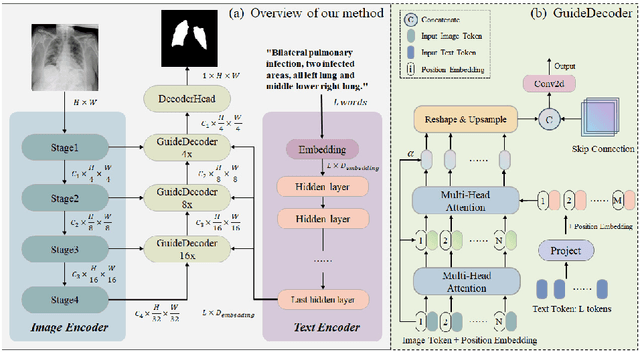
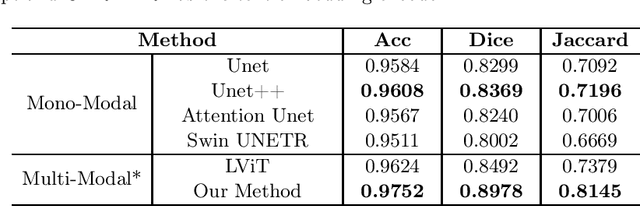

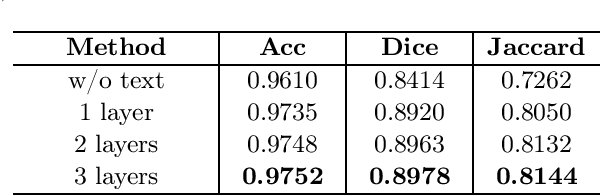
Segmentation of the infected areas of the lung is essential for quantifying the severity of lung disease like pulmonary infections. Existing medical image segmentation methods are almost uni-modal methods based on image. However, these image-only methods tend to produce inaccurate results unless trained with large amounts of annotated data. To overcome this challenge, we propose a language-driven segmentation method that uses text prompt to improve to the segmentation result. Experiments on the QaTa-COV19 dataset indicate that our method improves the Dice score by 6.09% at least compared to the uni-modal methods. Besides, our extended study reveals the flexibility of multi-modal methods in terms of the information granularity of text and demonstrates that multi-modal methods have a significant advantage over image-only methods in terms of the size of training data required.
Proto-CLIP: Vision-Language Prototypical Network for Few-Shot Learning
Jul 08, 2023We propose a novel framework for few-shot learning by leveraging large-scale vision-language models such as CLIP. Motivated by the unimodal prototypical networks for few-shot learning, we introduce PROTO-CLIP that utilizes image prototypes and text prototypes for few-shot learning. Specifically, PROTO-CLIP adapts the image encoder and text encoder in CLIP in a joint fashion using few-shot examples. The two encoders are used to compute prototypes of image classes for classification. During adaptation, we propose aligning the image and text prototypes of corresponding classes. Such a proposed alignment is beneficial for few-shot classification due to the contributions from both types of prototypes. We demonstrate the effectiveness of our method by conducting experiments on benchmark datasets for few-shot learning as well as in the real world for robot perception.
Signal processing after quadratic random sketching with optical units
Jul 27, 2023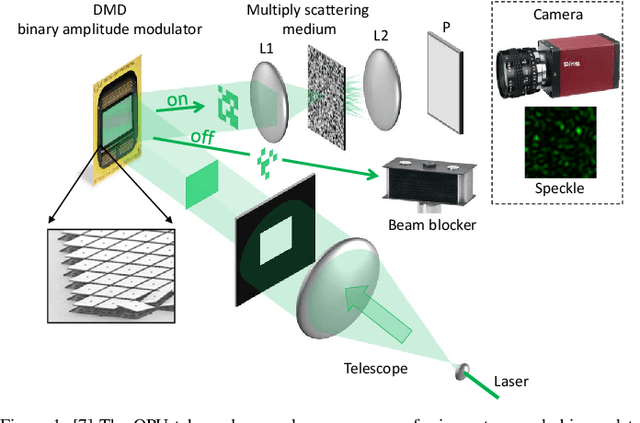
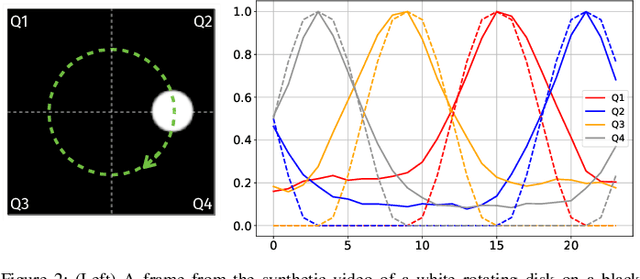
Random data sketching (or projection) is now a classical technique enabling, for instance, approximate numerical linear algebra and machine learning algorithms with reduced computational complexity and memory. In this context, the possibility of performing data processing (such as pattern detection or classification) directly in the sketched domain without accessing the original data was previously achieved for linear random sketching methods and compressive sensing. In this work, we show how to estimate simple signal processing tasks (such as deducing local variations in a image) directly using random quadratic projections achieved by an optical processing unit. The same approach allows for naive data classification methods directly operated in the sketched domain. We report several experiments confirming the power of our approach.