 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
UniverSeg: Universal Medical Image Segmentation
Apr 12, 2023
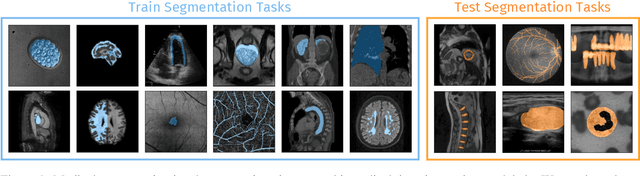

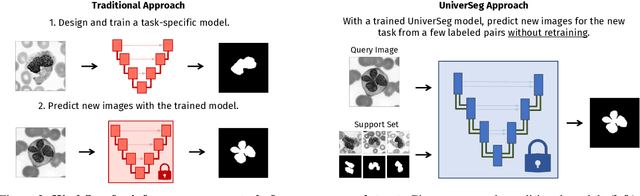
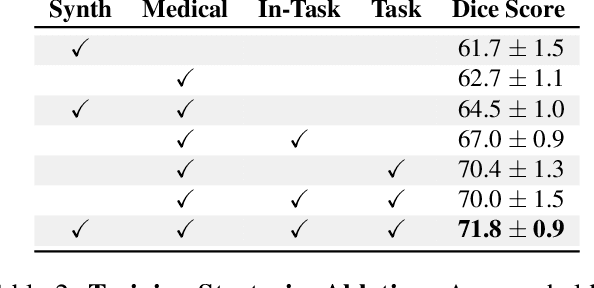
While deep learning models have become the predominant method for medical image segmentation, they are typically not capable of generalizing to unseen segmentation tasks involving new anatomies, image modalities, or labels. Given a new segmentation task, researchers generally have to train or fine-tune models, which is time-consuming and poses a substantial barrier for clinical researchers, who often lack the resources and expertise to train neural networks. We present UniverSeg, a method for solving unseen medical segmentation tasks without additional training. Given a query image and example set of image-label pairs that define a new segmentation task, UniverSeg employs a new Cross-Block mechanism to produce accurate segmentation maps without the need for additional training. To achieve generalization to new tasks, we have gathered and standardized a collection of 53 open-access medical segmentation datasets with over 22,000 scans, which we refer to as MegaMedical. We used this collection to train UniverSeg on a diverse set of anatomies and imaging modalities. We demonstrate that UniverSeg substantially outperforms several related methods on unseen tasks, and thoroughly analyze and draw insights about important aspects of the proposed system. The UniverSeg source code and model weights are freely available at https://universeg.csail.mit.edu
Masked Image Training for Generalizable Deep Image Denoising
Mar 23, 2023
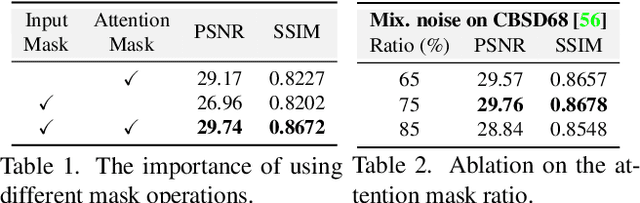


When capturing and storing images, devices inevitably introduce noise. Reducing this noise is a critical task called image denoising. Deep learning has become the de facto method for image denoising, especially with the emergence of Transformer-based models that have achieved notable state-of-the-art results on various image tasks. However, deep learning-based methods often suffer from a lack of generalization ability. For example, deep models trained on Gaussian noise may perform poorly when tested on other noise distributions. To address this issue, we present a novel approach to enhance the generalization performance of denoising networks, known as masked training. Our method involves masking random pixels of the input image and reconstructing the missing information during training. We also mask out the features in the self-attention layers to avoid the impact of training-testing inconsistency. Our approach exhibits better generalization ability than other deep learning models and is directly applicable to real-world scenarios. Additionally, our interpretability analysis demonstrates the superiority of our method.
Clinical-Inspired Cytological Whole Slide Image Screening with Just Slide-Level Labels
Jun 06, 2023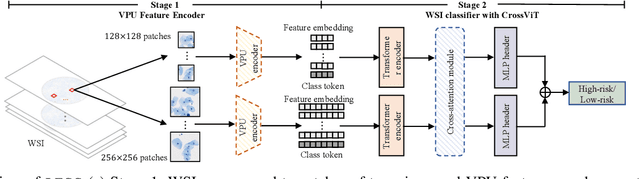
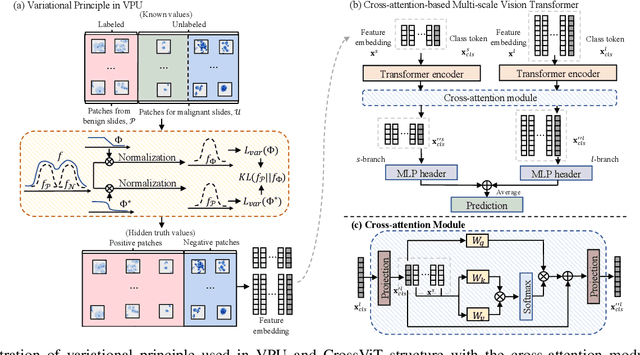

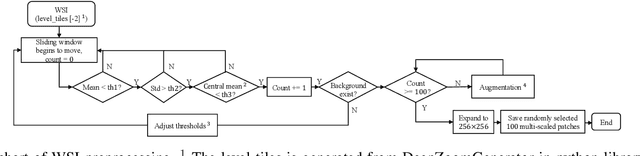
Cytology test is effective, non-invasive, convenient, and inexpensive for clinical cancer screening. ThinPrep, a commonly used liquid-based specimen, can be scanned to generate digital whole slide images (WSIs) for cytology testing. However, WSIs classification with gigapixel resolutions is highly resource-intensive, posing significant challenges for automated medical image analysis. In order to circumvent this computational impasse, existing methods emphasize learning features at the cell or patch level, typically requiring labor-intensive and detailed manual annotations, such as labels at the cell or patch level. Here we propose a novel automated Label-Efficient WSI Screening method, dubbed LESS, for cytology-based diagnosis with only slide-level labels. Firstly, in order to achieve label efficiency, we suggest employing variational positive-unlabeled (VPU) learning, enhancing patch-level feature learning using WSI-level labels. Subsequently, guided by the clinical approach of scrutinizing WSIs at varying fields of view and scales, we employ a cross-attention vision transformer (CrossViT) to fuse multi-scale patch-level data and execute WSI-level classification. We validate the proposed label-efficient method on a urine cytology WSI dataset encompassing 130 samples (13,000 patches) and FNAC 2019 dataset with 212 samples (21,200 patches). The experiment shows that the proposed LESS reaches 84.79%, 85.43%, 91.79% and 78.30% on a urine cytology WSI dataset, and 96.53%, 96.37%, 99.31%, 94.95% on FNAC 2019 dataset in terms of accuracy, AUC, sensitivity and specificity. It outperforms state-of-the-art methods and realizes automatic cytology-based bladder cancer screening.
Cascaded Cross-Attention Networks for Data-Efficient Whole-Slide Image Classification Using Transformers
May 11, 2023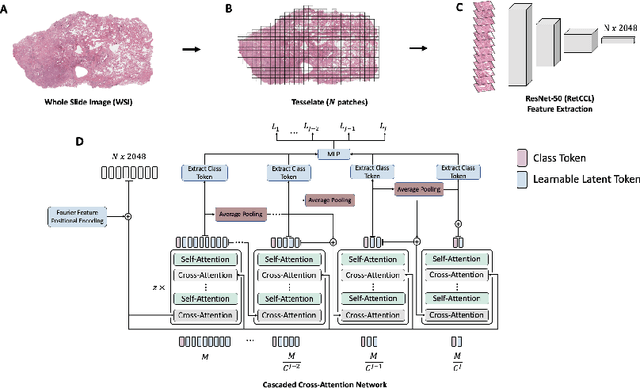
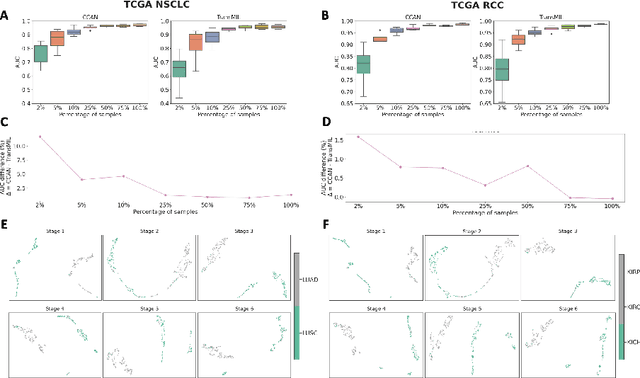
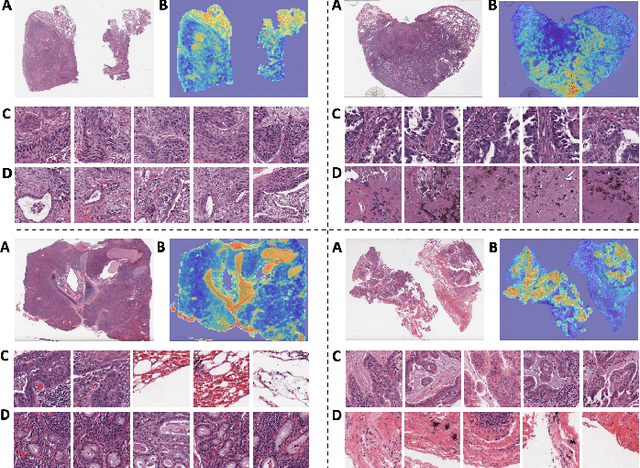
Whole-Slide Imaging allows for the capturing and digitization of high-resolution images of histological specimen. An automated analysis of such images using deep learning models is therefore of high demand. The transformer architecture has been proposed as a possible candidate for effectively leveraging the high-resolution information. Here, the whole-slide image is partitioned into smaller image patches and feature tokens are extracted from these image patches. However, while the conventional transformer allows for a simultaneous processing of a large set of input tokens, the computational demand scales quadratically with the number of input tokens and thus quadratically with the number of image patches. To address this problem we propose a novel cascaded cross-attention network (CCAN) based on the cross-attention mechanism that scales linearly with the number of extracted patches. Our experiments demonstrate that this architecture is at least on-par with and even outperforms other attention-based state-of-the-art methods on two public datasets: On the use-case of lung cancer (TCGA NSCLC) our model reaches a mean area under the receiver operating characteristic (AUC) of 0.970 $\pm$ 0.008 and on renal cancer (TCGA RCC) reaches a mean AUC of 0.985 $\pm$ 0.004. Furthermore, we show that our proposed model is efficient in low-data regimes, making it a promising approach for analyzing whole-slide images in resource-limited settings. To foster research in this direction, we make our code publicly available on GitHub: XXX.
Defense against Adversarial Cloud Attack on Remote Sensing Salient Object Detection
Jul 05, 2023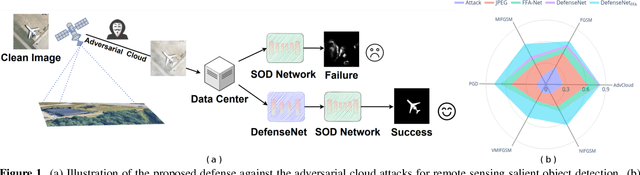
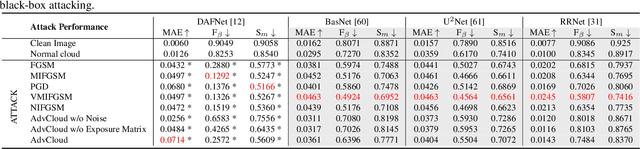
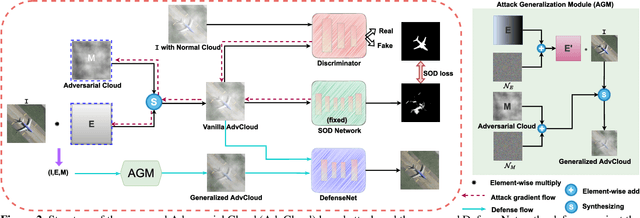
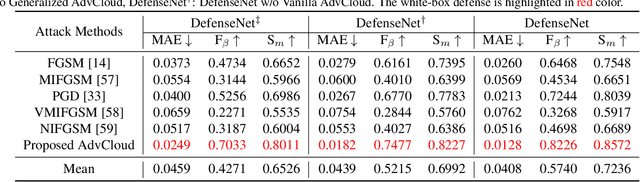
Detecting the salient objects in a remote sensing image has wide applications for the interdisciplinary research. Many existing deep learning methods have been proposed for Salient Object Detection (SOD) in remote sensing images and get remarkable results. However, the recent adversarial attack examples, generated by changing a few pixel values on the original remote sensing image, could result in a collapse for the well-trained deep learning based SOD model. Different with existing methods adding perturbation to original images, we propose to jointly tune adversarial exposure and additive perturbation for attack and constrain image close to cloudy image as Adversarial Cloud. Cloud is natural and common in remote sensing images, however, camouflaging cloud based adversarial attack and defense for remote sensing images are not well studied before. Furthermore, we design DefenseNet as a learn-able pre-processing to the adversarial cloudy images so as to preserve the performance of the deep learning based remote sensing SOD model, without tuning the already deployed deep SOD model. By considering both regular and generalized adversarial examples, the proposed DefenseNet can defend the proposed Adversarial Cloud in white-box setting and other attack methods in black-box setting. Experimental results on a synthesized benchmark from the public remote sensing SOD dataset (EORSSD) show the promising defense against adversarial cloud attacks.
Parametric Depth Based Feature Representation Learning for Object Detection and Segmentation in Bird's Eye View
Jul 11, 2023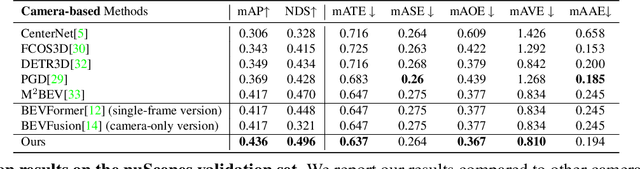


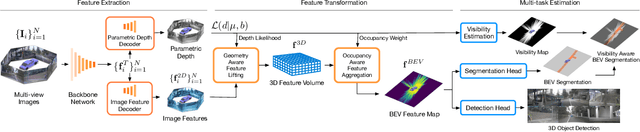
Recent vision-only perception models for autonomous driving achieved promising results by encoding multi-view image features into Bird's-Eye-View (BEV) space. A critical step and the main bottleneck of these methods is transforming image features into the BEV coordinate frame. This paper focuses on leveraging geometry information, such as depth, to model such feature transformation. Existing works rely on non-parametric depth distribution modeling leading to significant memory consumption, or ignore the geometry information to address this problem. In contrast, we propose to use parametric depth distribution modeling for feature transformation. We first lift the 2D image features to the 3D space defined for the ego vehicle via a predicted parametric depth distribution for each pixel in each view. Then, we aggregate the 3D feature volume based on the 3D space occupancy derived from depth to the BEV frame. Finally, we use the transformed features for downstream tasks such as object detection and semantic segmentation. Existing semantic segmentation methods do also suffer from an hallucination problem as they do not take visibility information into account. This hallucination can be particularly problematic for subsequent modules such as control and planning. To mitigate the issue, our method provides depth uncertainty and reliable visibility-aware estimations. We further leverage our parametric depth modeling to present a novel visibility-aware evaluation metric that, when taken into account, can mitigate the hallucination problem. Extensive experiments on object detection and semantic segmentation on the nuScenes datasets demonstrate that our method outperforms existing methods on both tasks.
SceneGenie: Scene Graph Guided Diffusion Models for Image Synthesis
Apr 28, 2023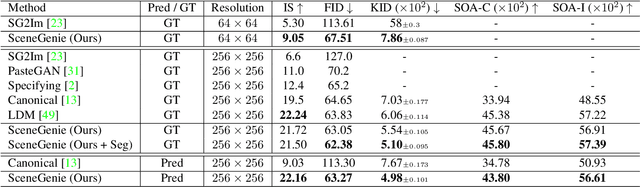
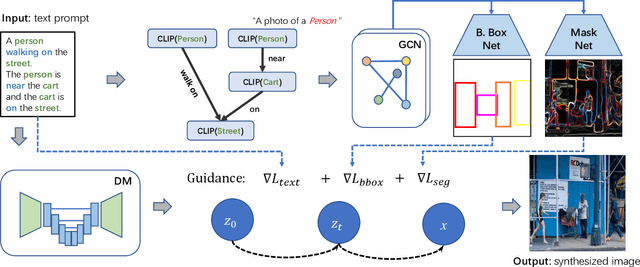
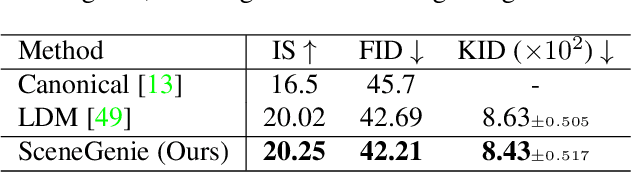
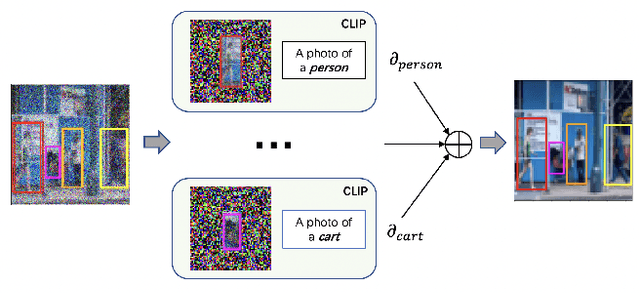
Text-conditioned image generation has made significant progress in recent years with generative adversarial networks and more recently, diffusion models. While diffusion models conditioned on text prompts have produced impressive and high-quality images, accurately representing complex text prompts such as the number of instances of a specific object remains challenging. To address this limitation, we propose a novel guidance approach for the sampling process in the diffusion model that leverages bounding box and segmentation map information at inference time without additional training data. Through a novel loss in the sampling process, our approach guides the model with semantic features from CLIP embeddings and enforces geometric constraints, leading to high-resolution images that accurately represent the scene. To obtain bounding box and segmentation map information, we structure the text prompt as a scene graph and enrich the nodes with CLIP embeddings. Our proposed model achieves state-of-the-art performance on two public benchmarks for image generation from scene graphs, surpassing both scene graph to image and text-based diffusion models in various metrics. Our results demonstrate the effectiveness of incorporating bounding box and segmentation map guidance in the diffusion model sampling process for more accurate text-to-image generation.
Support Vector Machine Guided Reproducing Kernel Particle Method for Image-Based Modeling of Microstructures
May 23, 2023
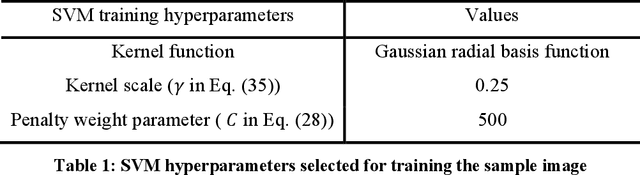
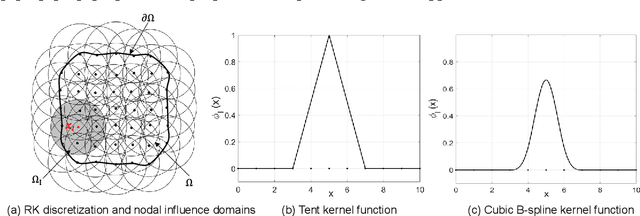
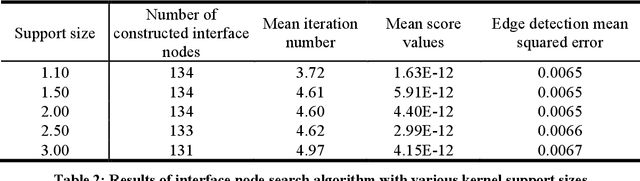
This work presents an approach for automating the discretization and approximation procedures in constructing digital representations of composites from Micro-CT images featuring intricate microstructures. The proposed method is guided by the Support Vector Machine (SVM) classification, offering an effective approach for discretizing microstructural images. An SVM soft margin training process is introduced as a classification of heterogeneous material points, and image segmentation is accomplished by identifying support vectors through a local regularized optimization problem. In addition, an Interface-Modified Reproducing Kernel Particle Method (IM-RKPM) is proposed for appropriate approximations of weak discontinuities across material interfaces. The proposed method modifies the smooth kernel functions with a regularized heavy-side function concerning the material interfaces to alleviate Gibb's oscillations. This IM-RKPM is formulated without introducing duplicated degrees of freedom associated with the interface nodes commonly needed in the conventional treatments of weak discontinuities in the meshfree methods. Moreover, IM-RKPM can be implemented with various domain integration techniques, such as Stabilized Conforming Nodal Integration (SCNI). The extension of the proposed method to 3-dimension is straightforward, and the effectiveness of the proposed method is validated through the image-based modeling of polymer-ceramic composite microstructures.
Learning to Segment from Noisy Annotations: A Spatial Correction Approach
Jul 21, 2023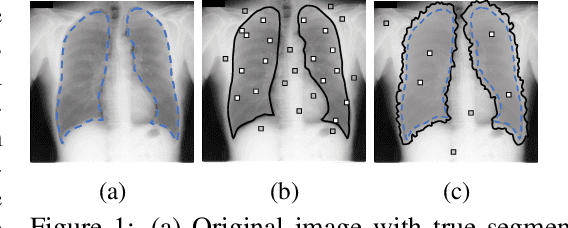
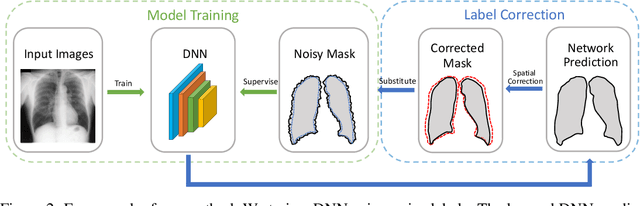
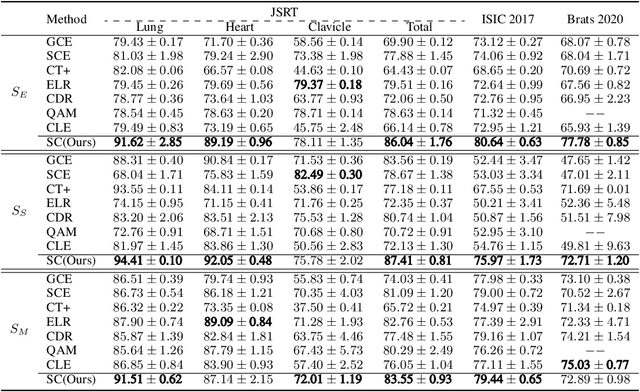
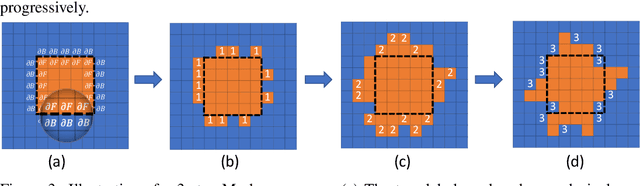
Noisy labels can significantly affect the performance of deep neural networks (DNNs). In medical image segmentation tasks, annotations are error-prone due to the high demand in annotation time and in the annotators' expertise. Existing methods mostly assume noisy labels in different pixels are \textit{i.i.d}. However, segmentation label noise usually has strong spatial correlation and has prominent bias in distribution. In this paper, we propose a novel Markov model for segmentation noisy annotations that encodes both spatial correlation and bias. Further, to mitigate such label noise, we propose a label correction method to recover true label progressively. We provide theoretical guarantees of the correctness of the proposed method. Experiments show that our approach outperforms current state-of-the-art methods on both synthetic and real-world noisy annotations.
ImageEye: Batch Image Processing Using Program Synthesis
Apr 10, 2023


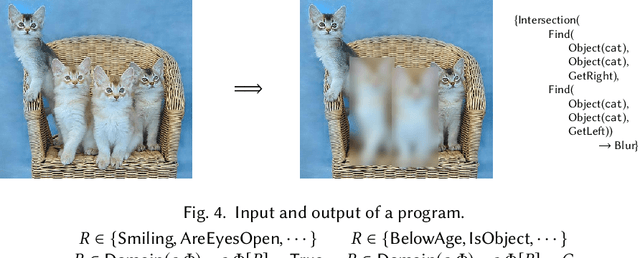
This paper presents a new synthesis-based approach for batch image processing. Unlike existing tools that can only apply global edits to the entire image, our method can apply fine-grained edits to individual objects within the image. For example, our method can selectively blur or crop specific objects that have a certain property. To facilitate such fine-grained image editing tasks, we propose a neuro-symbolic domain-specific language (DSL) that combines pre-trained neural networks for image classification with other language constructs that enable symbolic reasoning. Our method can automatically learn programs in this DSL from user demonstrations by utilizing a novel synthesis algorithm. We have implemented the proposed technique in a tool called ImageEye and evaluated it on 50 image editing tasks. Our evaluation shows that ImageEye is able to automate 96% of these tasks.