 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Understanding the Latent Space of Diffusion Models through the Lens of Riemannian Geometry
Jul 24, 2023
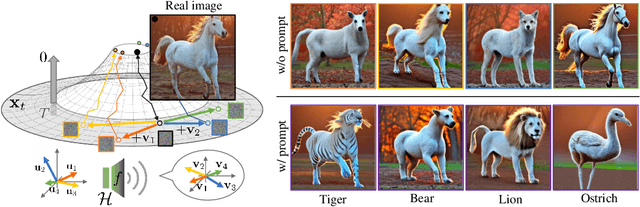



Despite the success of diffusion models (DMs), we still lack a thorough understanding of their latent space. To understand the latent space $\mathbf{x}_t \in \mathcal{X}$, we analyze them from a geometrical perspective. Specifically, we utilize the pullback metric to find the local latent basis in $\mathcal{X}$ and their corresponding local tangent basis in $\mathcal{H}$, the intermediate feature maps of DMs. The discovered latent basis enables unsupervised image editing capability through latent space traversal. We investigate the discovered structure from two perspectives. First, we examine how geometric structure evolves over diffusion timesteps. Through analysis, we show that 1) the model focuses on low-frequency components early in the generative process and attunes to high-frequency details later; 2) At early timesteps, different samples share similar tangent spaces; and 3) The simpler datasets that DMs trained on, the more consistent the tangent space for each timestep. Second, we investigate how the geometric structure changes based on text conditioning in Stable Diffusion. The results show that 1) similar prompts yield comparable tangent spaces; and 2) the model depends less on text conditions in later timesteps. To the best of our knowledge, this paper is the first to present image editing through $\mathbf{x}$-space traversal and provide thorough analyses of the latent structure of DMs.
A Systematic Survey of Prompt Engineering on Vision-Language Foundation Models
Jul 24, 2023Prompt engineering is a technique that involves augmenting a large pre-trained model with task-specific hints, known as prompts, to adapt the model to new tasks. Prompts can be created manually as natural language instructions or generated automatically as either natural language instructions or vector representations. Prompt engineering enables the ability to perform predictions based solely on prompts without updating model parameters, and the easier application of large pre-trained models in real-world tasks. In past years, Prompt engineering has been well-studied in natural language processing. Recently, it has also been intensively studied in vision-language modeling. However, there is currently a lack of a systematic overview of prompt engineering on pre-trained vision-language models. This paper aims to provide a comprehensive survey of cutting-edge research in prompt engineering on three types of vision-language models: multimodal-to-text generation models (e.g. Flamingo), image-text matching models (e.g. CLIP), and text-to-image generation models (e.g. Stable Diffusion). For each type of model, a brief model summary, prompting methods, prompting-based applications, and the corresponding responsibility and integrity issues are summarized and discussed. Furthermore, the commonalities and differences between prompting on vision-language models, language models, and vision models are also discussed. The challenges, future directions, and research opportunities are summarized to foster future research on this topic.
Semantically Structured Image Compression via Irregular Group-Based Decoupling
May 04, 2023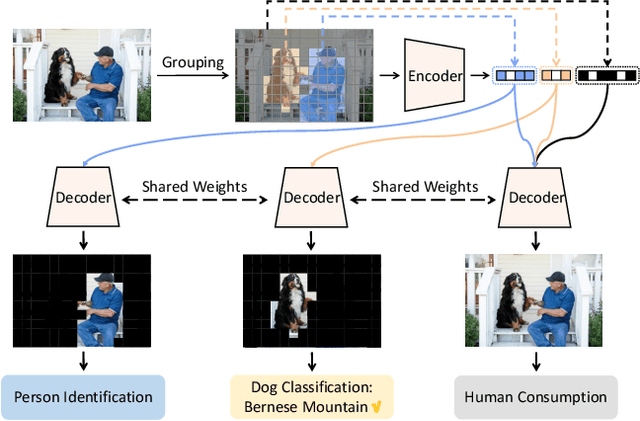
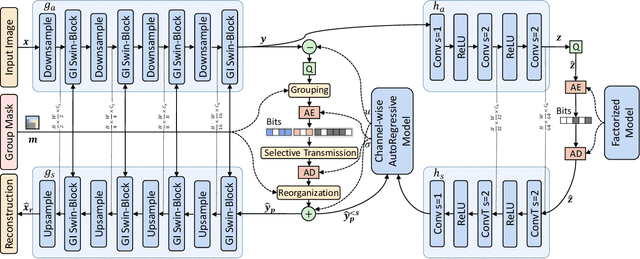
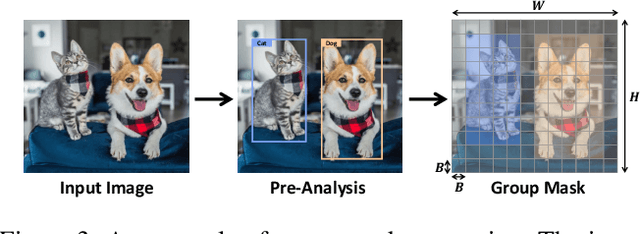
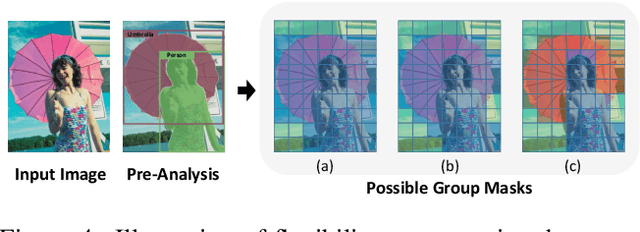
Image compression techniques typically focus on compressing rectangular images for human consumption, however, resulting in transmitting redundant content for downstream applications. To overcome this limitation, some previous works propose to semantically structure the bitstream, which can meet specific application requirements by selective transmission and reconstruction. Nevertheless, they divide the input image into multiple rectangular regions according to semantics and ignore avoiding information interaction among them, causing waste of bitrate and distorted reconstruction of region boundaries. In this paper, we propose to decouple an image into multiple groups with irregular shapes based on a customized group mask and compress them independently. Our group mask describes the image at a finer granularity, enabling significant bitrate saving by reducing the transmission of redundant content. Moreover, to ensure the fidelity of selective reconstruction, this paper proposes the concept of group-independent transform that maintain the independence among distinct groups. And we instantiate it by the proposed Group-Independent Swin-Block (GI Swin-Block). Experimental results demonstrate that our framework structures the bitstream with negligible cost, and exhibits superior performance on both visual quality and intelligent task supporting.
Gender Biases in Automatic Evaluation Metrics: A Case Study on Image Captioning
May 24, 2023
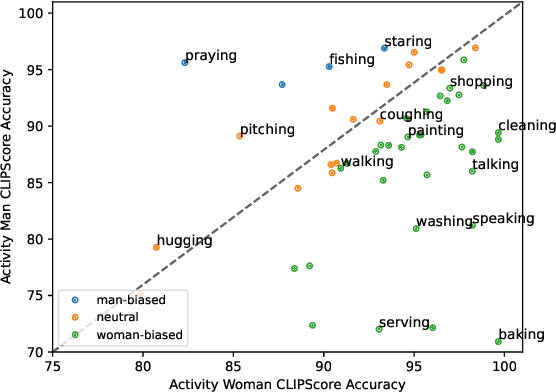
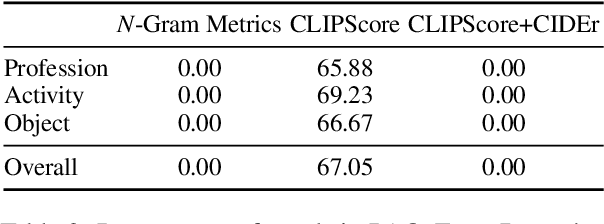
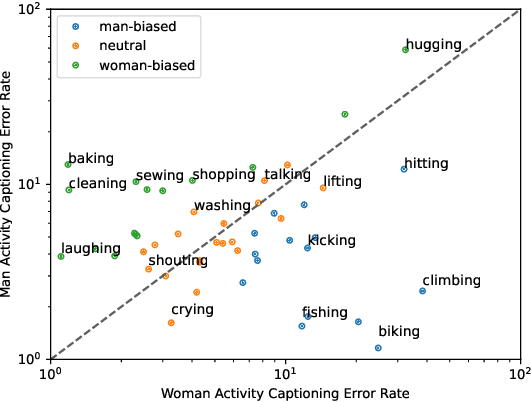
Pretrained model-based evaluation metrics have demonstrated strong performance with high correlations with human judgments in various natural language generation tasks such as image captioning. Despite the impressive results, their impact on fairness is under-explored -- it is widely acknowledged that pretrained models can encode societal biases, and utilizing them for evaluation purposes may inadvertently manifest and potentially amplify biases. In this paper, we conduct a systematic study in gender biases of model-based evaluation metrics with a focus on image captioning tasks. Specifically, we first identify and quantify gender biases in different evaluation metrics regarding profession, activity, and object concepts. Then, we demonstrate the negative consequences of using these biased metrics, such as favoring biased generation models in deployment and propagating the biases to generation models through reinforcement learning. We also present a simple but effective alternative to reduce gender biases by combining n-gram matching-based and pretrained model-based evaluation metrics.
GenKL: An Iterative Framework for Resolving Label Ambiguity and Label Non-conformity in Web Images Via a New Generalized KL Divergence
Jul 19, 2023Web image datasets curated online inherently contain ambiguous in-distribution (ID) instances and out-of-distribution (OOD) instances, which we collectively call non-conforming (NC) instances. In many recent approaches for mitigating the negative effects of NC instances, the core implicit assumption is that the NC instances can be found via entropy maximization. For "entropy" to be well-defined, we are interpreting the output prediction vector of an instance as the parameter vector of a multinomial random variable, with respect to some trained model with a softmax output layer. Hence, entropy maximization is based on the idealized assumption that NC instances have predictions that are "almost" uniformly distributed. However, in real-world web image datasets, there are numerous NC instances whose predictions are far from being uniformly distributed. To tackle the limitation of entropy maximization, we propose $(\alpha, \beta)$-generalized KL divergence, $\mathcal{D}_{\text{KL}}^{\alpha, \beta}(p\|q)$, which can be used to identify significantly more NC instances. Theoretical properties of $\mathcal{D}_{\text{KL}}^{\alpha, \beta}(p\|q)$ are proven, and we also show empirically that a simple use of $\mathcal{D}_{\text{KL}}^{\alpha, \beta}(p\|q)$ outperforms all baselines on the NC instance identification task. Building upon $(\alpha,\beta)$-generalized KL divergence, we also introduce a new iterative training framework, GenKL, that identifies and relabels NC instances. When evaluated on three web image datasets, Clothing1M, Food101/Food101N, and mini WebVision 1.0, we achieved new state-of-the-art classification accuracies: $81.34\%$, $85.73\%$ and $78.99\%$/$92.54\%$ (top-1/top-5), respectively.
LEMaRT: Label-Efficient Masked Region Transform for Image Harmonization
Apr 25, 2023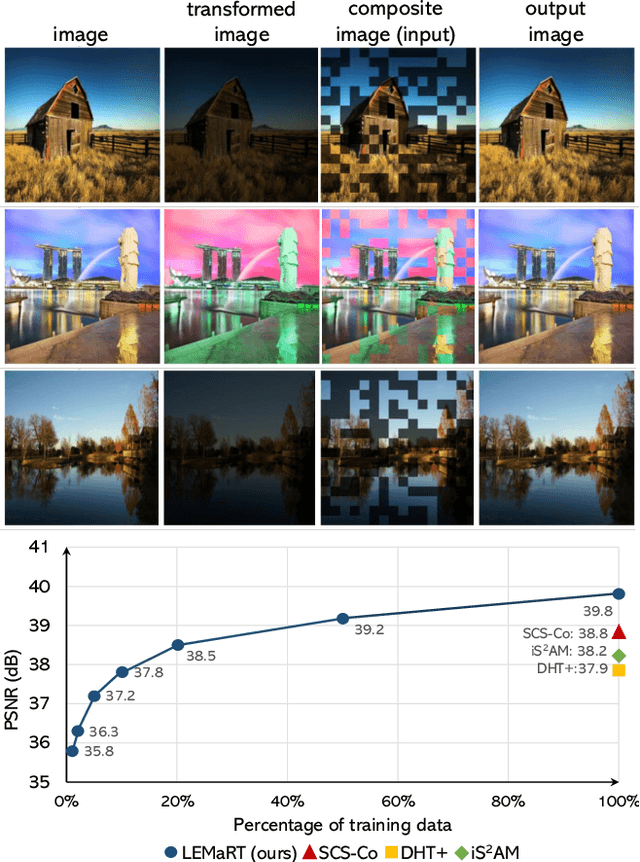
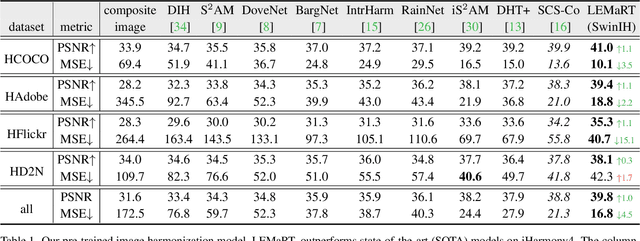
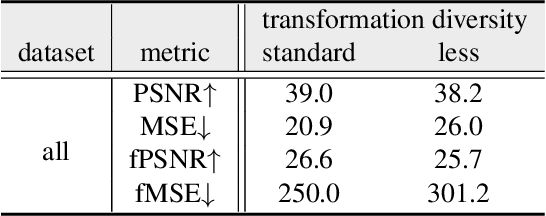
We present a simple yet effective self-supervised pre-training method for image harmonization which can leverage large-scale unannotated image datasets. To achieve this goal, we first generate pre-training data online with our Label-Efficient Masked Region Transform (LEMaRT) pipeline. Given an image, LEMaRT generates a foreground mask and then applies a set of transformations to perturb various visual attributes, e.g., defocus blur, contrast, saturation, of the region specified by the generated mask. We then pre-train image harmonization models by recovering the original image from the perturbed image. Secondly, we introduce an image harmonization model, namely SwinIH, by retrofitting the Swin Transformer [27] with a combination of local and global self-attention mechanisms. Pre-training SwinIH with LEMaRT results in a new state of the art for image harmonization, while being label-efficient, i.e., consuming less annotated data for fine-tuning than existing methods. Notably, on iHarmony4 dataset [8], SwinIH outperforms the state of the art, i.e., SCS-Co [16] by a margin of 0.4 dB when it is fine-tuned on only 50% of the training data, and by 1.0 dB when it is trained on the full training dataset.
Causal reasoning in typical computer vision tasks
Jul 31, 2023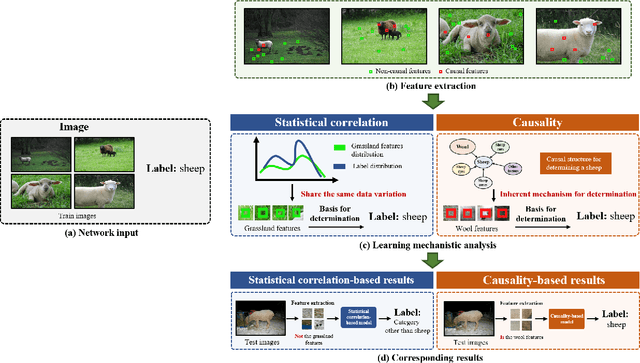
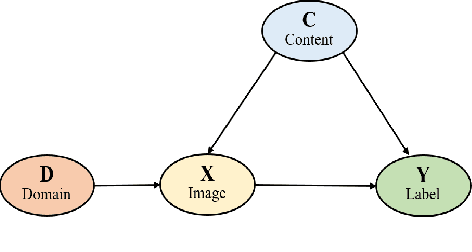
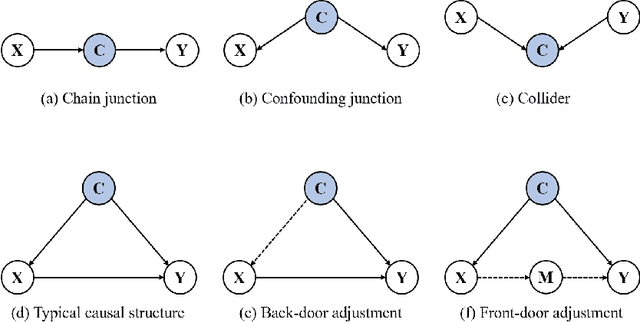
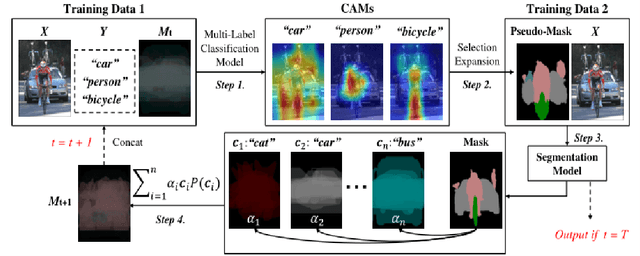
Deep learning has revolutionized the field of artificial intelligence. Based on the statistical correlations uncovered by deep learning-based methods, computer vision has contributed to tremendous growth in areas like autonomous driving and robotics. Despite being the basis of deep learning, such correlation is not stable and is susceptible to uncontrolled factors. In the absence of the guidance of prior knowledge, statistical correlations can easily turn into spurious correlations and cause confounders. As a result, researchers are now trying to enhance deep learning methods with causal theory. Causal theory models the intrinsic causal structure unaffected by data bias and is effective in avoiding spurious correlations. This paper aims to comprehensively review the existing causal methods in typical vision and vision-language tasks such as semantic segmentation, object detection, and image captioning. The advantages of causality and the approaches for building causal paradigms will be summarized. Future roadmaps are also proposed, including facilitating the development of causal theory and its application in other complex scenes and systems.
DiVA-360: The Dynamic Visuo-Audio Dataset for Immersive Neural Fields
Jul 31, 2023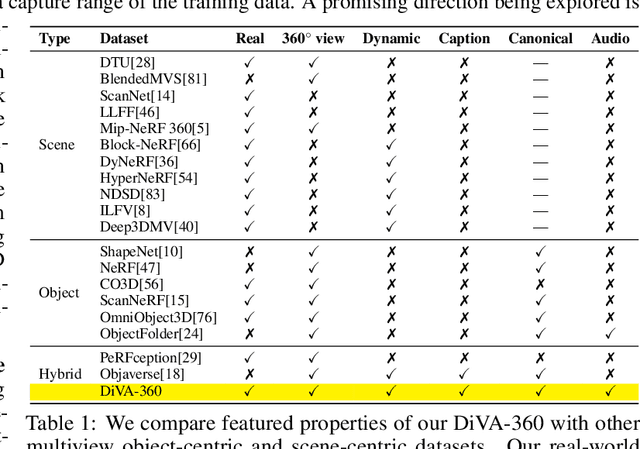

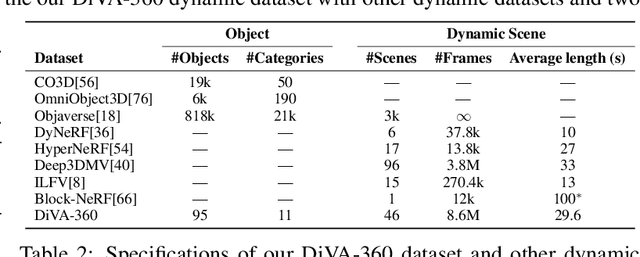
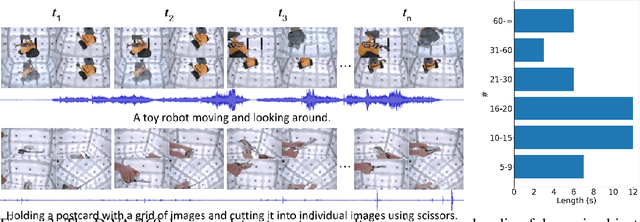
Advances in neural fields are enabling high-fidelity capture of the shape and appearance of static and dynamic scenes. However, their capabilities lag behind those offered by representations such as pixels or meshes due to algorithmic challenges and the lack of large-scale real-world datasets. We address the dataset limitation with DiVA-360, a real-world 360 dynamic visual-audio dataset with synchronized multimodal visual, audio, and textual information about table-scale scenes. It contains 46 dynamic scenes, 30 static scenes, and 95 static objects spanning 11 categories captured using a new hardware system using 53 RGB cameras at 120 FPS and 6 microphones for a total of 8.6M image frames and 1360 s of dynamic data. We provide detailed text descriptions for all scenes, foreground-background segmentation masks, category-specific 3D pose alignment for static objects, as well as metrics for comparison. Our data, hardware and software, and code are available at https://diva360.github.io/.
Detecting diabetic retinopathy severity through fundus images using an ensemble of classifiers
Jul 31, 2023
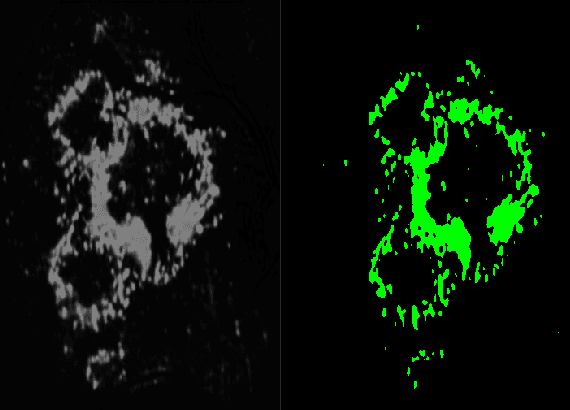
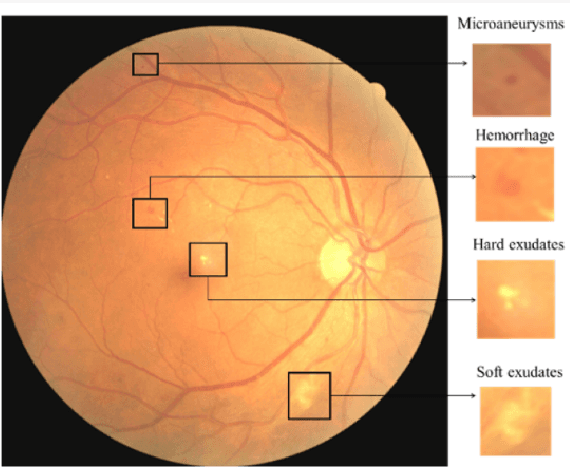
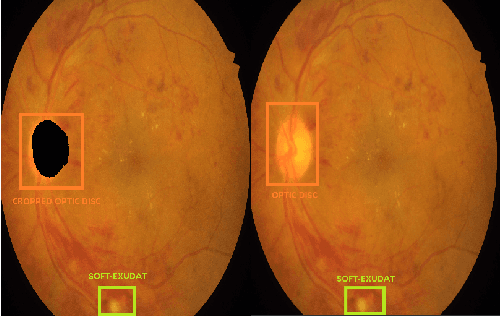
Diabetic retinopathy is an ocular condition that affects individuals with diabetes mellitus. It is a common complication of diabetes that can impact the eyes and lead to vision loss. One method for diagnosing diabetic retinopathy is the examination of the fundus of the eye. An ophthalmologist examines the back part of the eye, including the retina, optic nerve, and the blood vessels that supply the retina. In the case of diabetic retinopathy, the blood vessels in the retina deteriorate and can lead to bleeding, swelling, and other changes that affect vision. We proposed a method for detecting diabetic diabetic severity levels. First, a set of data-prerpocessing is applied to available data: adaptive equalisation, color normalisation, Gaussian filter, removal of the optic disc and blood vessels. Second, we perform image segmentation for relevant markers and extract features from the fundus images. Third, we apply an ensemble of classifiers and we assess the trust in the system.
Exposing the Fake: Effective Diffusion-Generated Images Detection
Jul 12, 2023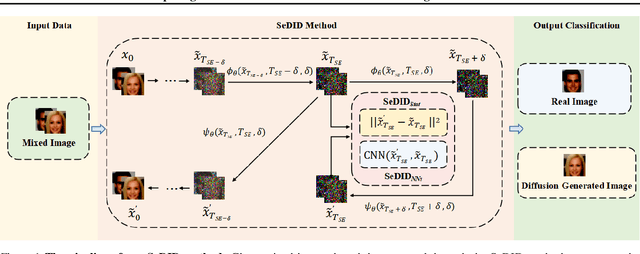
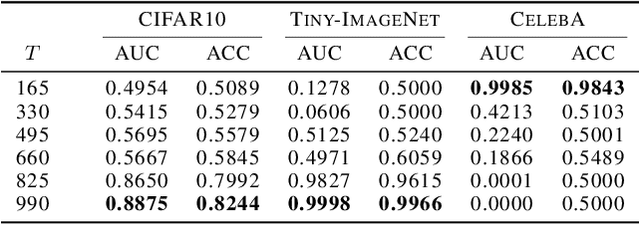
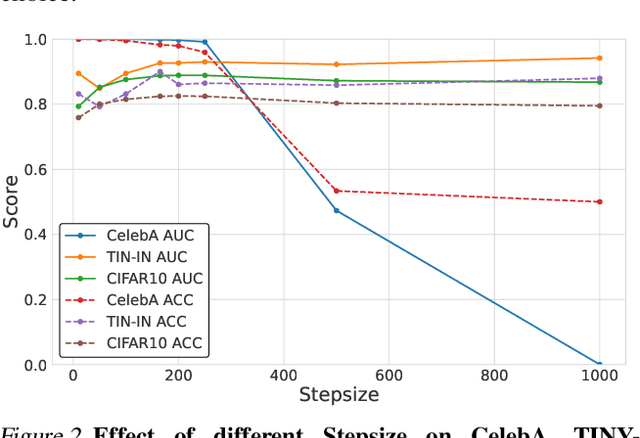

Image synthesis has seen significant advancements with the advent of diffusion-based generative models like Denoising Diffusion Probabilistic Models (DDPM) and text-to-image diffusion models. Despite their efficacy, there is a dearth of research dedicated to detecting diffusion-generated images, which could pose potential security and privacy risks. This paper addresses this gap by proposing a novel detection method called Stepwise Error for Diffusion-generated Image Detection (SeDID). Comprising statistical-based $\text{SeDID}_{\text{Stat}}$ and neural network-based $\text{SeDID}_{\text{NNs}}$, SeDID exploits the unique attributes of diffusion models, namely deterministic reverse and deterministic denoising computation errors. Our evaluations demonstrate SeDID's superior performance over existing methods when applied to diffusion models. Thus, our work makes a pivotal contribution to distinguishing diffusion model-generated images, marking a significant step in the domain of artificial intelligence security.