 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SAM-U: Multi-box prompts triggered uncertainty estimation for reliable SAM in medical image
Jul 11, 2023
Recently, Segmenting Anything has taken an important step towards general artificial intelligence. At the same time, its reliability and fairness have also attracted great attention, especially in the field of health care. In this study, we propose multi-box prompts triggered uncertainty estimation for SAM cues to demonstrate the reliability of segmented lesions or tissues. We estimate the distribution of SAM predictions via Monte Carlo with prior distribution parameters, which employs different prompts as formulation of test-time augmentation. Our experimental results found that multi-box prompts augmentation improve the SAM performance, and endowed each pixel with uncertainty. This provides the first paradigm for a reliable SAM.
A Simple and Effective Baseline for Attentional Generative Adversarial Networks
Jul 06, 2023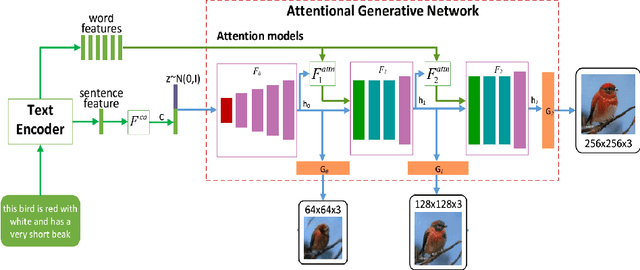
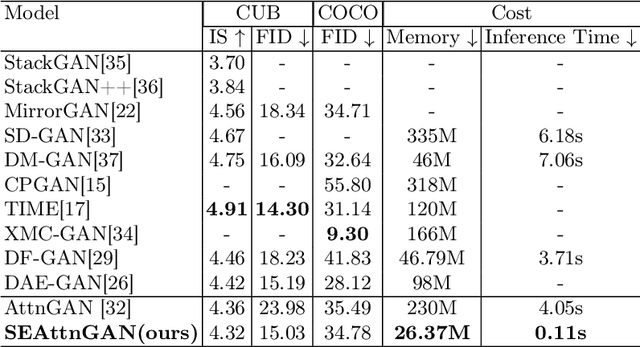
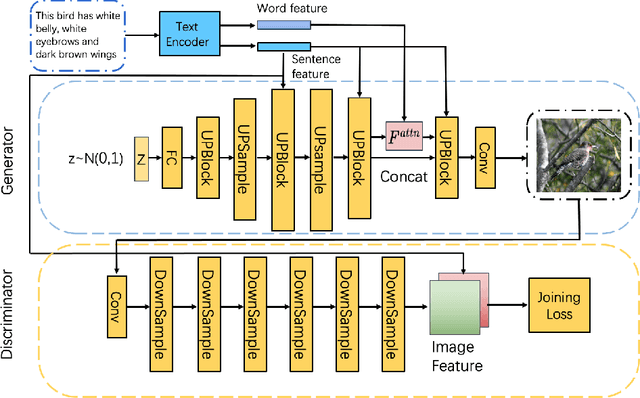

Synthesising a text-to-image model of high-quality images by guiding the generative model through the Text description is an innovative and challenging task. In recent years, AttnGAN based on the Attention mechanism to guide GAN training has been proposed, SD-GAN, which adopts a self-distillation technique to improve the performance of the generator and the quality of image generation, and Stack-GAN++, which gradually improves the details and quality of the image by stacking multiple generators and discriminators. However, this series of improvements to GAN all have redundancy to a certain extent, which affects the generation performance and complexity to a certain extent. We use the popular simple and effective idea (1) to remove redundancy structure and improve the backbone network of AttnGAN. (2) to integrate and reconstruct multiple losses of DAMSM. Our improvements have significantly improved the model size and training efficiency while ensuring that the model's performance is unchanged and finally proposed our SEAttnGAN. Code is avalilable at https://github.com/jmyissb/SEAttnGAN.
Empirical Analysis of a Segmentation Foundation Model in Prostate Imaging
Jul 06, 2023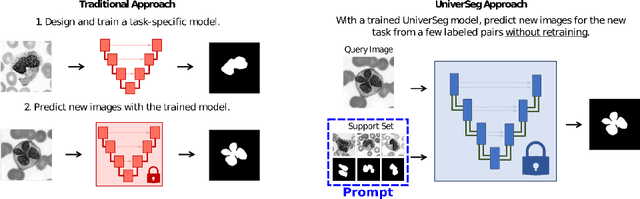

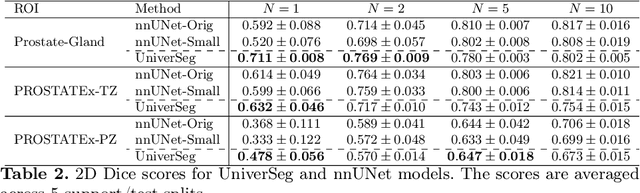
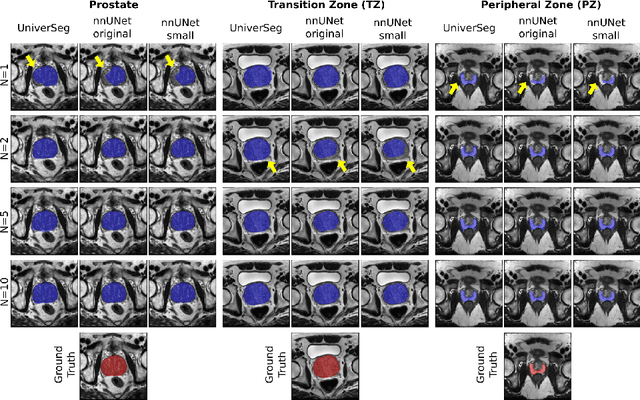
Most state-of-the-art techniques for medical image segmentation rely on deep-learning models. These models, however, are often trained on narrowly-defined tasks in a supervised fashion, which requires expensive labeled datasets. Recent advances in several machine learning domains, such as natural language generation have demonstrated the feasibility and utility of building foundation models that can be customized for various downstream tasks with little to no labeled data. This likely represents a paradigm shift for medical imaging, where we expect that foundation models may shape the future of the field. In this paper, we consider a recently developed foundation model for medical image segmentation, UniverSeg. We conduct an empirical evaluation study in the context of prostate imaging and compare it against the conventional approach of training a task-specific segmentation model. Our results and discussion highlight several important factors that will likely be important in the development and adoption of foundation models for medical image segmentation.
Large AI Model-Based Semantic Communications
Jul 07, 2023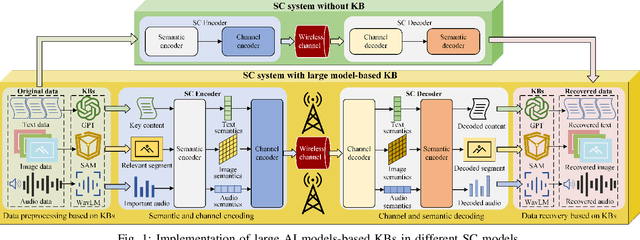
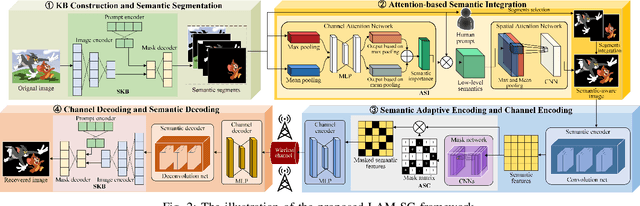
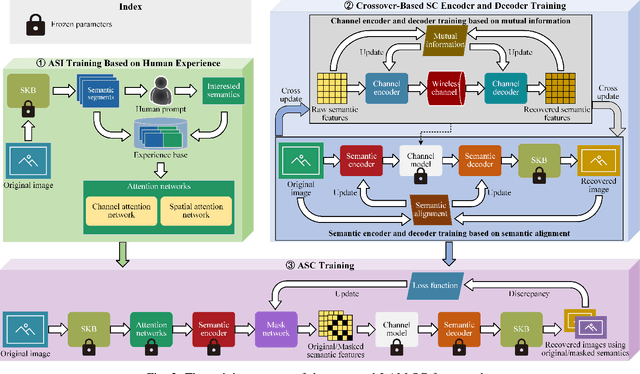
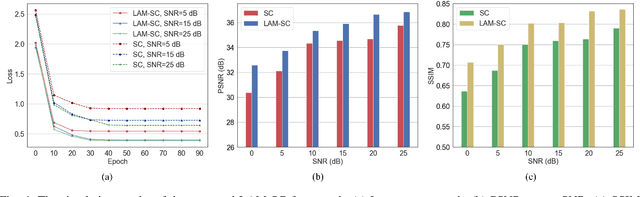
Semantic communication (SC) is an emerging intelligent paradigm, offering solutions for various future applications like metaverse, mixed-reality, and the Internet of everything. However, in current SC systems, the construction of the knowledge base (KB) faces several issues, including limited knowledge representation, frequent knowledge updates, and insecure knowledge sharing. Fortunately, the development of the large AI model provides new solutions to overcome above issues. Here, we propose a large AI model-based SC framework (LAM-SC) specifically designed for image data, where we first design the segment anything model (SAM)-based KB (SKB) that can split the original image into different semantic segments by universal semantic knowledge. Then, we present an attention-based semantic integration (ASI) to weigh the semantic segments generated by SKB without human participation and integrate them as the semantic-aware image. Additionally, we propose an adaptive semantic compression (ASC) encoding to remove redundant information in semantic features, thereby reducing communication overhead. Finally, through simulations, we demonstrate the effectiveness of the LAM-SC framework and the significance of the large AI model-based KB development in future SC paradigms.
Invariant Scattering Transform for Medical Imaging
Jul 07, 2023
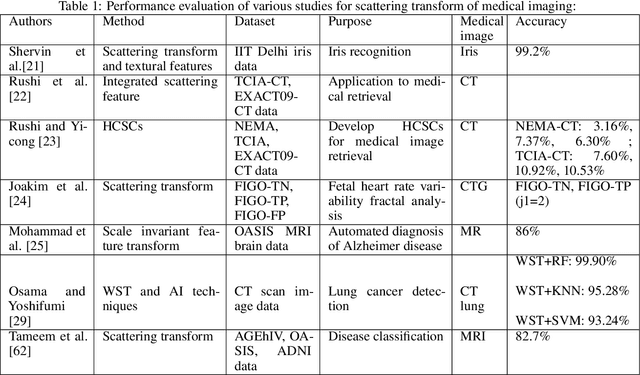

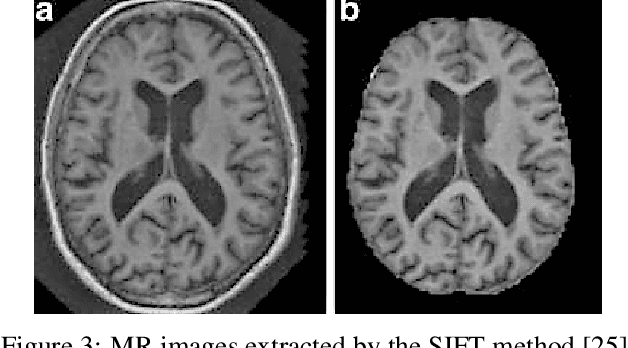
Invariant scattering transform introduces new area of research that merges the signal processing with deep learning for computer vision. Nowadays, Deep Learning algorithms are able to solve a variety of problems in medical sector. Medical images are used to detect diseases brain cancer or tumor, Alzheimer's disease, breast cancer, Parkinson's disease and many others. During pandemic back in 2020, machine learning and deep learning has played a critical role to detect COVID-19 which included mutation analysis, prediction, diagnosis and decision making. Medical images like X-ray, MRI known as magnetic resonance imaging, CT scans are used for detecting diseases. There is another method in deep learning for medical imaging which is scattering transform. It builds useful signal representation for image classification. It is a wavelet technique; which is impactful for medical image classification problems. This research article discusses scattering transform as the efficient system for medical image analysis where it's figured by scattering the signal information implemented in a deep convolutional network. A step by step case study is manifested at this research work.
Resolution-Aware Design of Atrous Rates for Semantic Segmentation Networks
Jul 26, 2023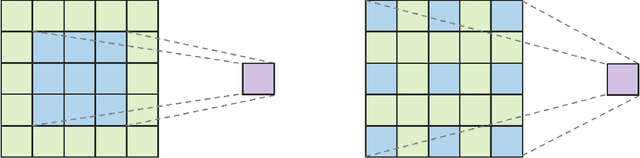
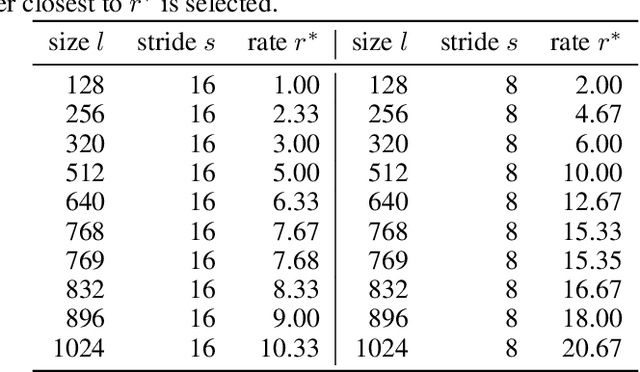
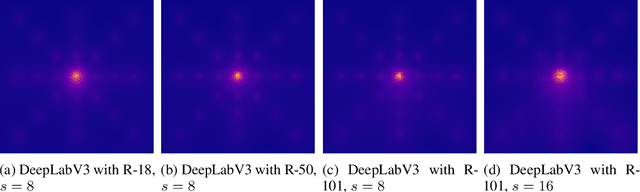

DeepLab is a widely used deep neural network for semantic segmentation, whose success is attributed to its parallel architecture called atrous spatial pyramid pooling (ASPP). ASPP uses multiple atrous convolutions with different atrous rates to extract both local and global information. However, fixed values of atrous rates are used for the ASPP module, which restricts the size of its field of view. In principle, atrous rate should be a hyperparameter to change the field of view size according to the target task or dataset. However, the manipulation of atrous rate is not governed by any guidelines. This study proposes practical guidelines for obtaining an optimal atrous rate. First, an effective receptive field for semantic segmentation is introduced to analyze the inner behavior of segmentation networks. We observed that the use of ASPP module yielded a specific pattern in the effective receptive field, which was traced to reveal the module's underlying mechanism. Accordingly, we derive practical guidelines for obtaining the optimal atrous rate, which should be controlled based on the size of input image. Compared to other values, using the optimal atrous rate consistently improved the segmentation results across multiple datasets, including the STARE, CHASE_DB1, HRF, Cityscapes, and iSAID datasets.
OAFuser: Towards Omni-Aperture Fusion for Light Field Semantic Segmentation of Road Scenes
Jul 28, 2023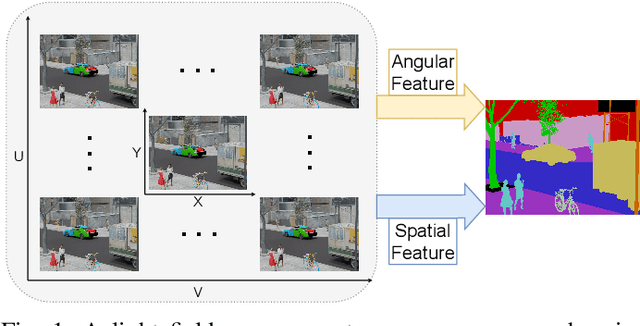
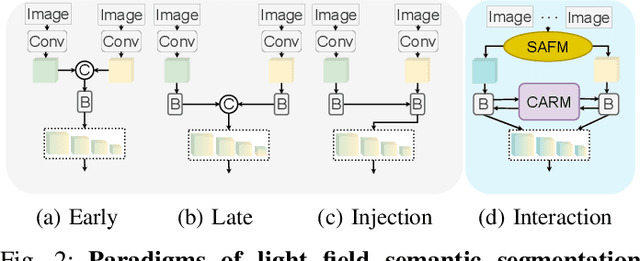
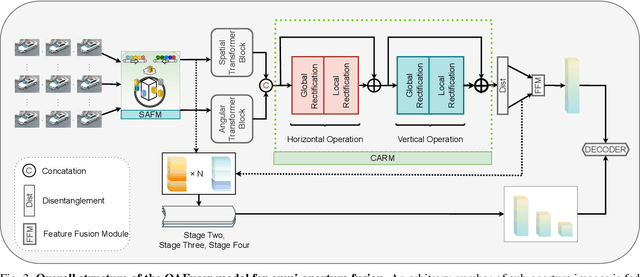
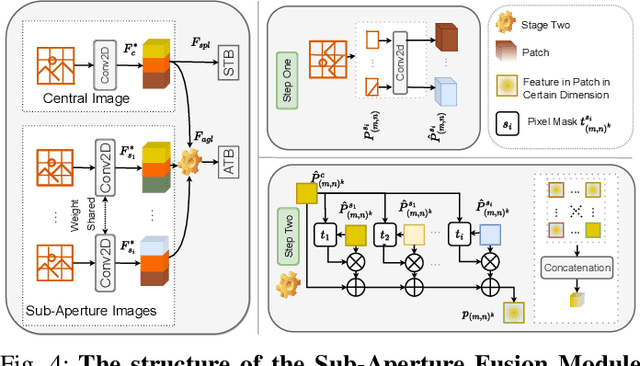
Light field cameras can provide rich angular and spatial information to enhance image semantic segmentation for scene understanding in the field of autonomous driving. However, the extensive angular information of light field cameras contains a large amount of redundant data, which is overwhelming for the limited hardware resource of intelligent vehicles. Besides, inappropriate compression leads to information corruption and data loss. To excavate representative information, we propose an Omni-Aperture Fusion model (OAFuser), which leverages dense context from the central view and discovers the angular information from sub-aperture images to generate a semantically-consistent result. To avoid feature loss during network propagation and simultaneously streamline the redundant information from the light field camera, we present a simple yet very effective Sub-Aperture Fusion Module (SAFM) to embed sub-aperture images into angular features without any additional memory cost. Furthermore, to address the mismatched spatial information across viewpoints, we present Center Angular Rectification Module (CARM) realized feature resorting and prevent feature occlusion caused by asymmetric information. Our proposed OAFuser achieves state-of-the-art performance on the UrbanLF-Real and -Syn datasets and sets a new record of 84.93% in mIoU on the UrbanLF-Real Extended dataset, with a gain of +4.53%. The source code of OAFuser will be made publicly available at https://github.com/FeiBryantkit/OAFuser.
Integrated Digital Reconstruction of Welded Components: Supporting Improved Fatigue Life Prediction
Jul 28, 2023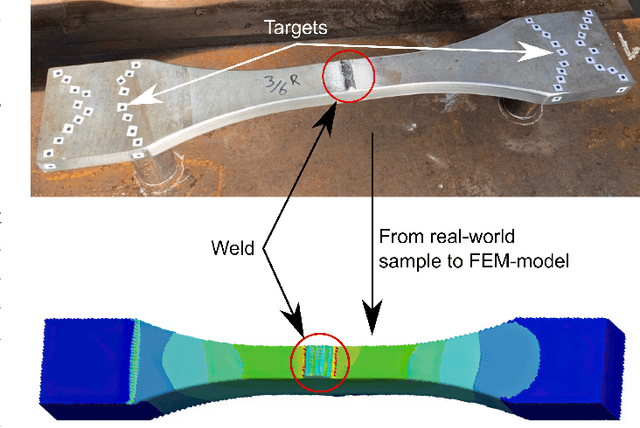



In the design of offshore jacket foundations, fatigue life is crucial. Post-weld treatment has been proposed to enhance the fatigue performance of welded joints, where particularly high-frequency mechanical impact (HFMI) treatment has been shown to improve fatigue performance significantly. Automated HFMI treatment has improved quality assurance and can lead to cost-effective design when combined with accurate fatigue life prediction. However, the finite element method (FEM), commonly used for predicting fatigue life in complex or multi-axial joints, relies on a basic CAD depiction of the weld, failing to consider the actual weld geometry and defects. Including the actual weld geometry in the FE model improves fatigue life prediction and possible crack location prediction but requires a digital reconstruction of the weld. Current digital reconstruction methods are time-consuming or require specialised scanning equipment and potential component relocation. The proposed framework instead uses an industrial manipulator combined with a line scanner to integrate digital reconstruction as part of the automated HFMI treatment setup. This approach applies standard image processing, simple filtering techniques, and non-linear optimisation for aligning and merging overlapping scans. A screened Poisson surface reconstruction finalises the 3D model to create a meshed surface. The outcome is a generic, cost-effective, flexible, and rapid method that enables generic digital reconstruction of welded parts, aiding in component design, overall quality assurance, and documentation of the HFMI treatment.
EmoSet: A Large-scale Visual Emotion Dataset with Rich Attributes
Jul 28, 2023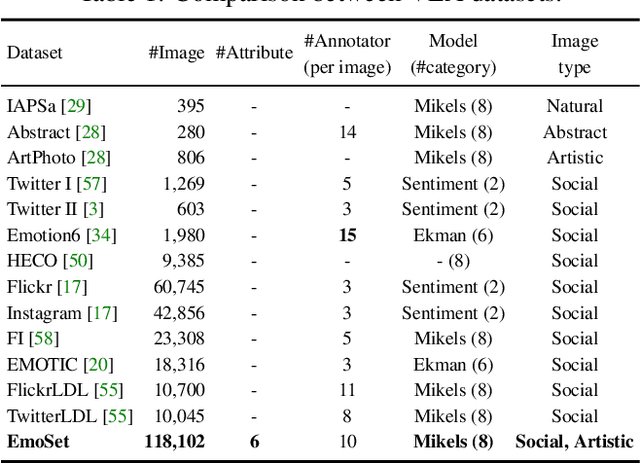
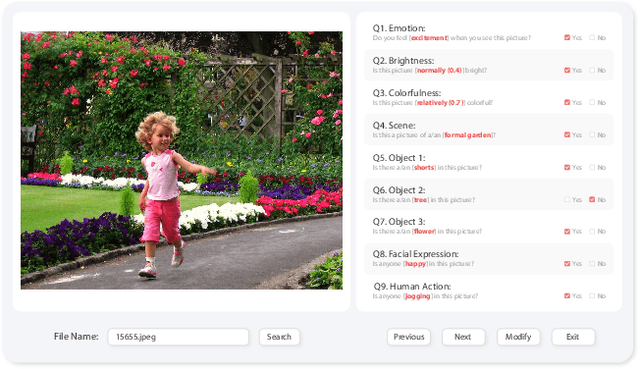
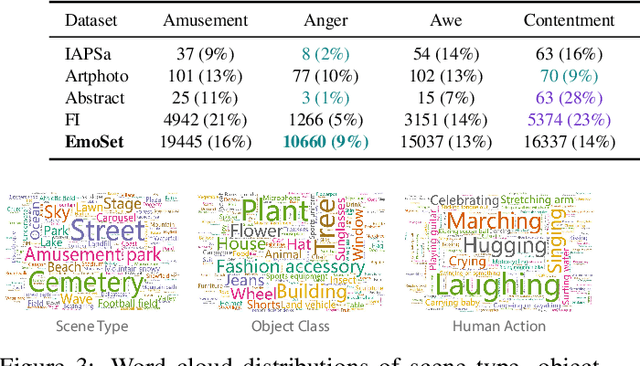
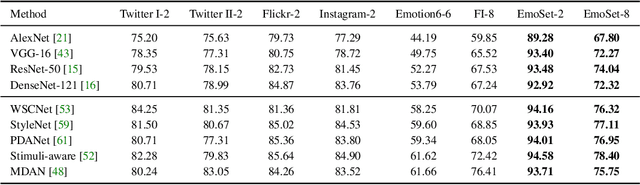
Visual Emotion Analysis (VEA) aims at predicting people's emotional responses to visual stimuli. This is a promising, yet challenging, task in affective computing, which has drawn increasing attention in recent years. Most of the existing work in this area focuses on feature design, while little attention has been paid to dataset construction. In this work, we introduce EmoSet, the first large-scale visual emotion dataset annotated with rich attributes, which is superior to existing datasets in four aspects: scale, annotation richness, diversity, and data balance. EmoSet comprises 3.3 million images in total, with 118,102 of these images carefully labeled by human annotators, making it five times larger than the largest existing dataset. EmoSet includes images from social networks, as well as artistic images, and it is well balanced between different emotion categories. Motivated by psychological studies, in addition to emotion category, each image is also annotated with a set of describable emotion attributes: brightness, colorfulness, scene type, object class, facial expression, and human action, which can help understand visual emotions in a precise and interpretable way. The relevance of these emotion attributes is validated by analyzing the correlations between them and visual emotion, as well as by designing an attribute module to help visual emotion recognition. We believe EmoSet will bring some key insights and encourage further research in visual emotion analysis and understanding. Project page: https://vcc.tech/EmoSet.
On Architectural Compression of Text-to-Image Diffusion Models
May 25, 2023

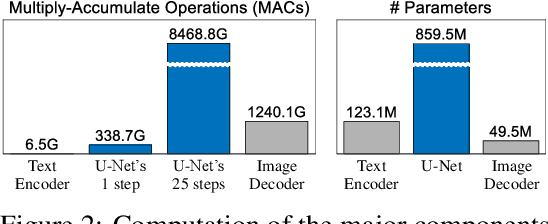
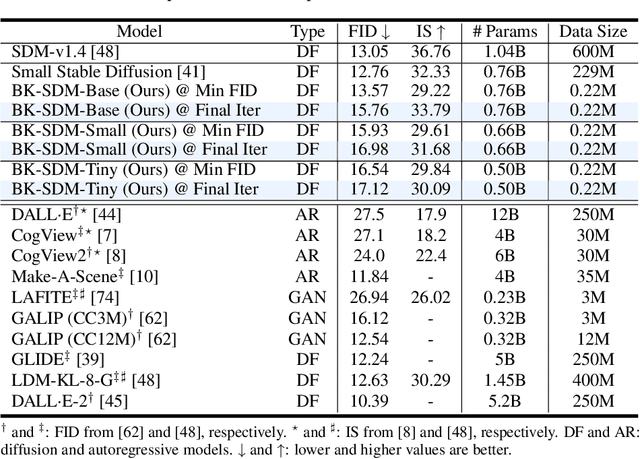
Exceptional text-to-image (T2I) generation results of Stable Diffusion models (SDMs) come with substantial computational demands. To resolve this issue, recent research on efficient SDMs has prioritized reducing the number of sampling steps and utilizing network quantization. Orthogonal to these directions, this study highlights the power of classical architectural compression for general-purpose T2I synthesis by introducing block-removed knowledge-distilled SDMs (BK-SDMs). We eliminate several residual and attention blocks from the U-Net of SDMs, obtaining over a 30% reduction in the number of parameters, MACs per sampling step, and latency. We conduct distillation-based pretraining with only 0.22M LAION pairs (fewer than 0.1% of the full training pairs) on a single A100 GPU. Despite being trained with limited resources, our compact models can imitate the original SDM by benefiting from transferred knowledge and achieve competitive results against larger multi-billion parameter models on the zero-shot MS-COCO benchmark. Moreover, we demonstrate the applicability of our lightweight pretrained models in personalized generation with DreamBooth finetuning.