 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Sample Less, Learn More: Efficient Action Recognition via Frame Feature Restoration
Jul 27, 2023

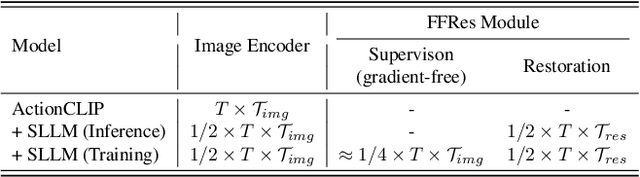

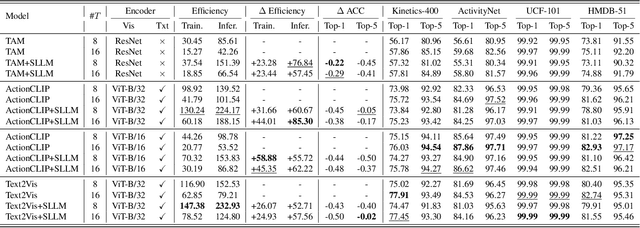
Training an effective video action recognition model poses significant computational challenges, particularly under limited resource budgets. Current methods primarily aim to either reduce model size or utilize pre-trained models, limiting their adaptability to various backbone architectures. This paper investigates the issue of over-sampled frames, a prevalent problem in many approaches yet it has received relatively little attention. Despite the use of fewer frames being a potential solution, this approach often results in a substantial decline in performance. To address this issue, we propose a novel method to restore the intermediate features for two sparsely sampled and adjacent video frames. This feature restoration technique brings a negligible increase in computational requirements compared to resource-intensive image encoders, such as ViT. To evaluate the effectiveness of our method, we conduct extensive experiments on four public datasets, including Kinetics-400, ActivityNet, UCF-101, and HMDB-51. With the integration of our method, the efficiency of three commonly used baselines has been improved by over 50%, with a mere 0.5% reduction in recognition accuracy. In addition, our method also surprisingly helps improve the generalization ability of the models under zero-shot settings.
Take-A-Photo: 3D-to-2D Generative Pre-training of Point Cloud Models
Jul 27, 2023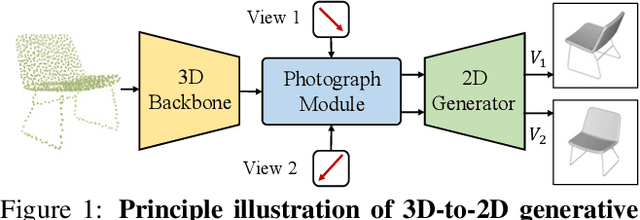
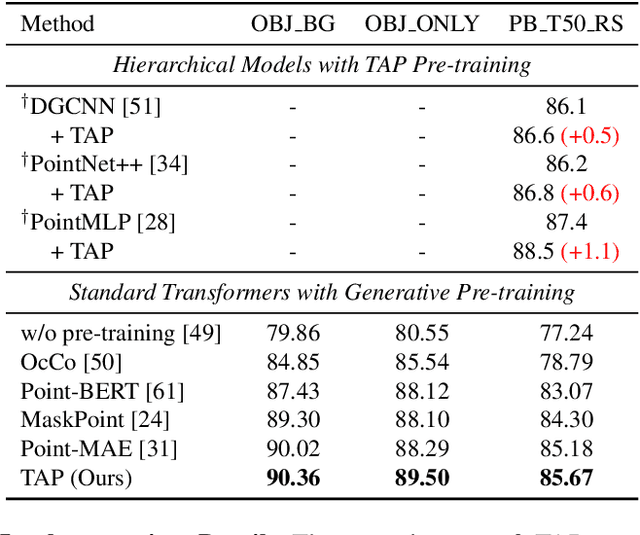
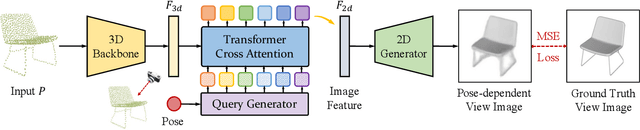
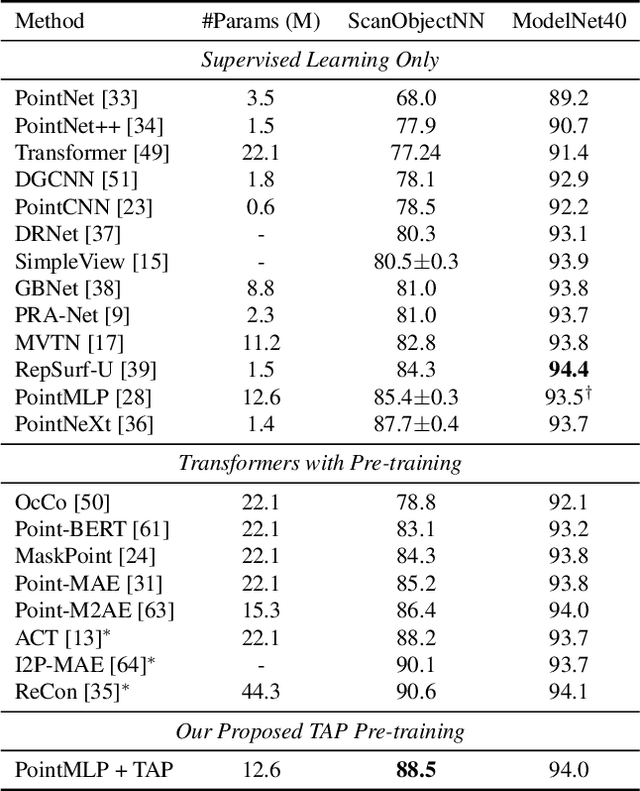
With the overwhelming trend of mask image modeling led by MAE, generative pre-training has shown a remarkable potential to boost the performance of fundamental models in 2D vision. However, in 3D vision, the over-reliance on Transformer-based backbones and the unordered nature of point clouds have restricted the further development of generative pre-training. In this paper, we propose a novel 3D-to-2D generative pre-training method that is adaptable to any point cloud model. We propose to generate view images from different instructed poses via the cross-attention mechanism as the pre-training scheme. Generating view images has more precise supervision than its point cloud counterpart, thus assisting 3D backbones to have a finer comprehension of the geometrical structure and stereoscopic relations of the point cloud. Experimental results have proved the superiority of our proposed 3D-to-2D generative pre-training over previous pre-training methods. Our method is also effective in boosting the performance of architecture-oriented approaches, achieving state-of-the-art performance when fine-tuning on ScanObjectNN classification and ShapeNetPart segmentation tasks. Code is available at https://github.com/wangzy22/TAP.
Weakly Supervised Multi-Modal 3D Human Body Pose Estimation for Autonomous Driving
Jul 27, 2023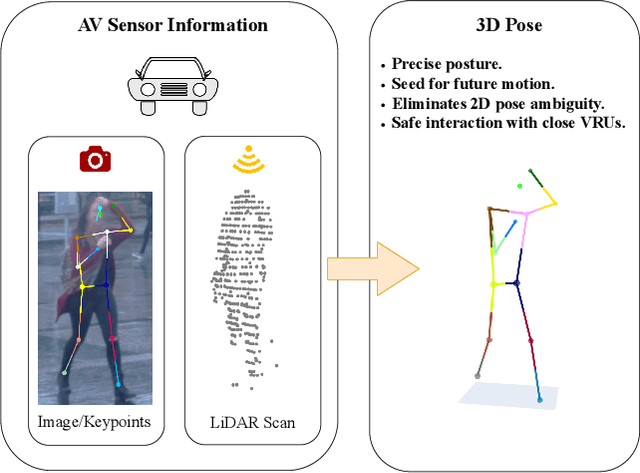
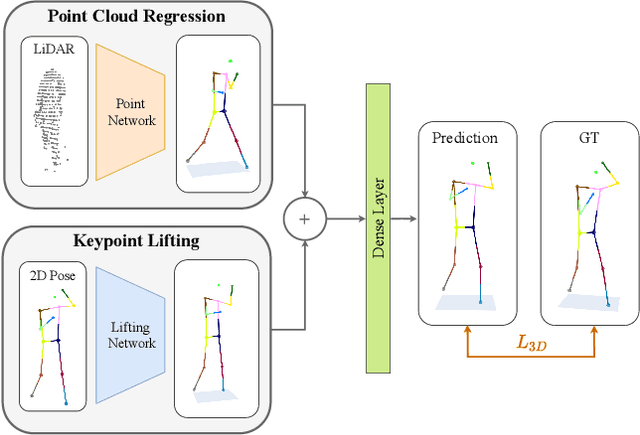
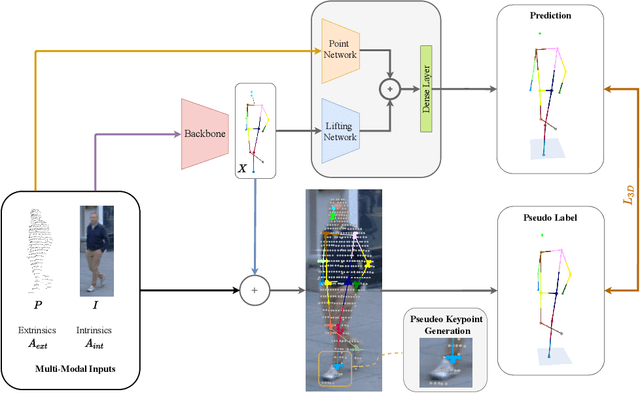
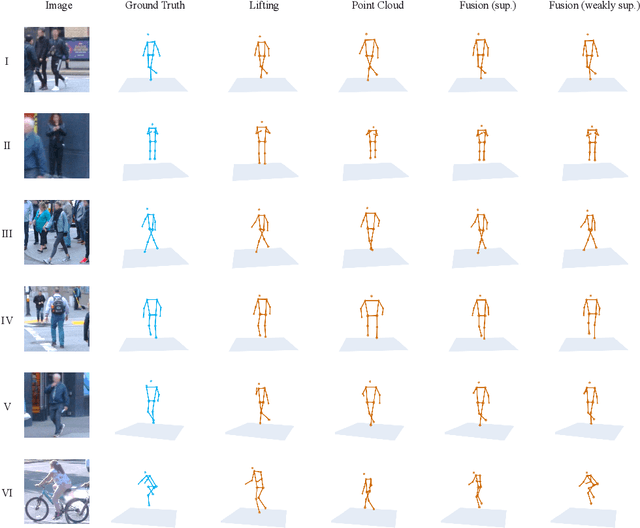
Accurate 3D human pose estimation (3D HPE) is crucial for enabling autonomous vehicles (AVs) to make informed decisions and respond proactively in critical road scenarios. Promising results of 3D HPE have been gained in several domains such as human-computer interaction, robotics, sports and medical analytics, often based on data collected in well-controlled laboratory environments. Nevertheless, the transfer of 3D HPE methods to AVs has received limited research attention, due to the challenges posed by obtaining accurate 3D pose annotations and the limited suitability of data from other domains. We present a simple yet efficient weakly supervised approach for 3D HPE in the AV context by employing a high-level sensor fusion between camera and LiDAR data. The weakly supervised setting enables training on the target datasets without any 2D/3D keypoint labels by using an off-the-shelf 2D joint extractor and pseudo labels generated from LiDAR to image projections. Our approach outperforms state-of-the-art results by up to $\sim$ 13% on the Waymo Open Dataset in the weakly supervised setting and achieves state-of-the-art results in the supervised setting.
LXL: LiDAR Exclusive Lean 3D Object Detection with 4D Imaging Radar and Camera Fusion
Jul 03, 2023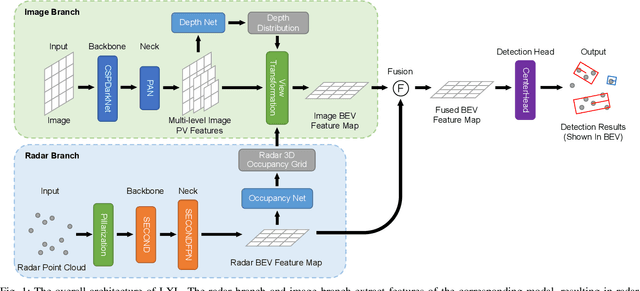
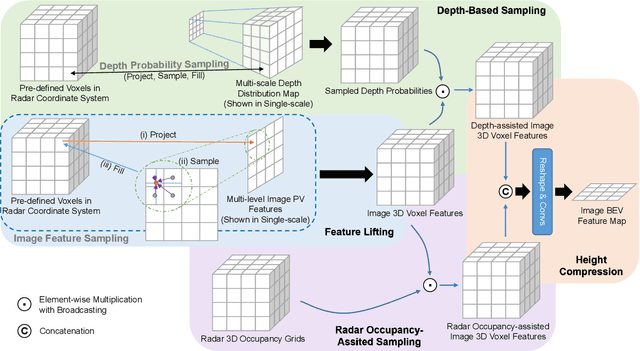
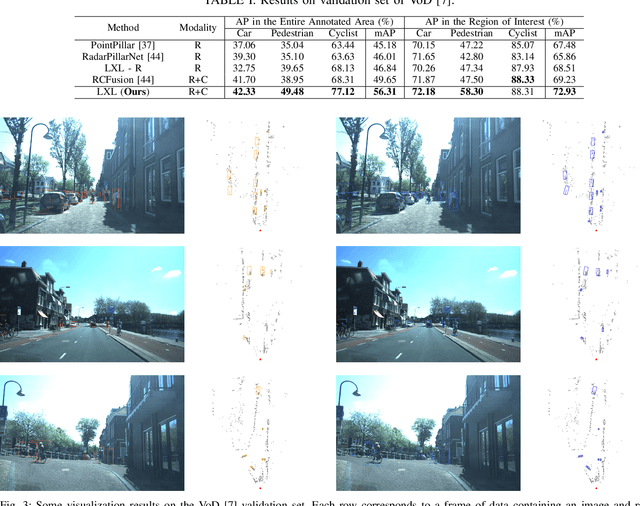

As an emerging technology and a relatively affordable device, the 4D imaging radar has already been confirmed effective in performing 3D object detection in autonomous driving. Nevertheless, the sparsity and noisiness of 4D radar point clouds hinder further performance improvement, and in-depth studies about its fusion with other modalities are lacking. On the other hand, most of the camera-based perception methods transform the extracted image perspective view features into the bird's-eye view geometrically via "depth-based splatting" proposed in Lift-Splat-Shoot (LSS), and some researchers exploit other modals such as LiDARs or ordinary automotive radars for enhancement. Recently, a few works have applied the "sampling" strategy for image view transformation, showing that it outperforms "splatting" even without image depth prediction. However, the potential of "sampling" is not fully unleashed. In this paper, we investigate the "sampling" view transformation strategy on the camera and 4D imaging radar fusion-based 3D object detection. In the proposed model, LXL, predicted image depth distribution maps and radar 3D occupancy grids are utilized to aid image view transformation, called "radar occupancy-assisted depth-based sampling". Experiments on VoD and TJ4DRadSet datasets show that the proposed method outperforms existing 3D object detection methods by a significant margin without bells and whistles. Ablation studies demonstrate that our method performs the best among different enhancement settings.
Implicit 3D Human Mesh Recovery using Consistency with Pose and Shape from Unseen-view
Jul 03, 2023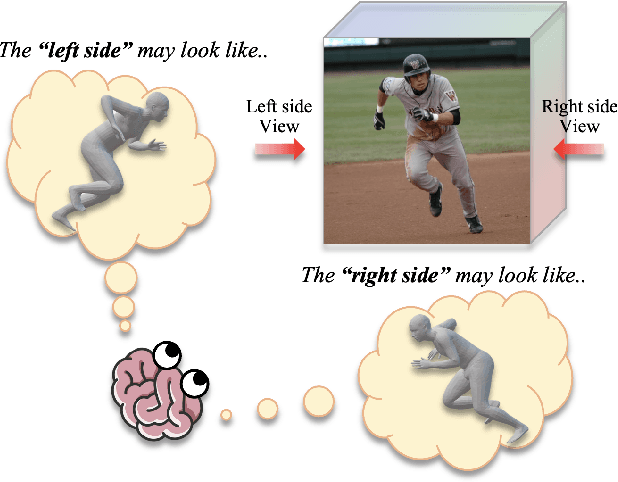
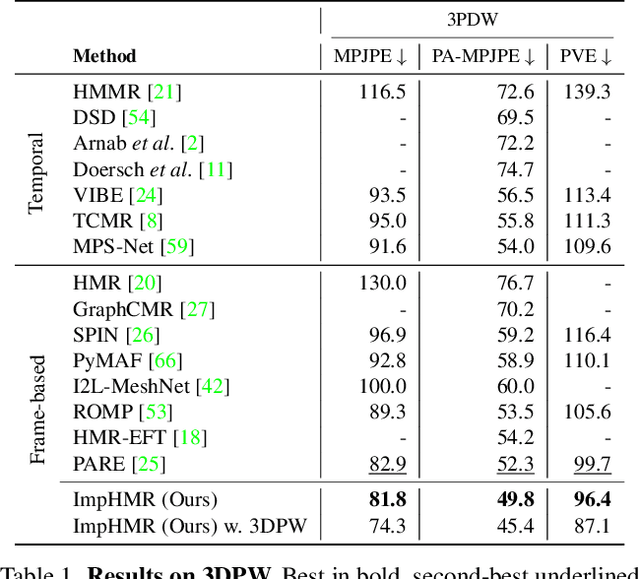
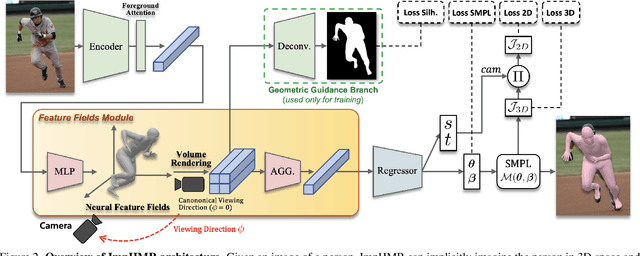

From an image of a person, we can easily infer the natural 3D pose and shape of the person even if ambiguity exists. This is because we have a mental model that allows us to imagine a person's appearance at different viewing directions from a given image and utilize the consistency between them for inference. However, existing human mesh recovery methods only consider the direction in which the image was taken due to their structural limitations. Hence, we propose "Implicit 3D Human Mesh Recovery (ImpHMR)" that can implicitly imagine a person in 3D space at the feature-level via Neural Feature Fields. In ImpHMR, feature fields are generated by CNN-based image encoder for a given image. Then, the 2D feature map is volume-rendered from the feature field for a given viewing direction, and the pose and shape parameters are regressed from the feature. To utilize consistency with pose and shape from unseen-view, if there are 3D labels, the model predicts results including the silhouette from an arbitrary direction and makes it equal to the rotated ground-truth. In the case of only 2D labels, we perform self-supervised learning through the constraint that the pose and shape parameters inferred from different directions should be the same. Extensive evaluations show the efficacy of the proposed method.
UW-ProCCaps: UnderWater Progressive Colourisation with Capsules
Jul 03, 2023Underwater images are fundamental for studying and understanding the status of marine life. We focus on reducing the memory space required for image storage while the memory space consumption in the collecting phase limits the time lasting of this phase leading to the need for more image collection campaigns. We present a novel machine-learning model that reconstructs the colours of underwater images from their luminescence channel, thus saving 2/3 of the available storage space. Our model specialises in underwater colour reconstruction and consists of an encoder-decoder architecture. The encoder is composed of a convolutional encoder and a parallel specialised classifier trained with webly-supervised data. The encoder and the decoder use layers of capsules to capture the features of the entities in the image. The colour reconstruction process recalls the progressive and the generative adversarial training procedures. The progressive training gives the ground for a generative adversarial routine focused on the refining of colours giving the image bright and saturated colours which bring the image back to life. We validate the model both qualitatively and quantitatively on four benchmark datasets. This is the first attempt at colour reconstruction in greyscale underwater images. Extensive results on four benchmark datasets demonstrate that our solution outperforms state-of-the-art (SOTA) solutions. We also demonstrate that the generated colourisation enhances the quality of images compared to enhancement models at the SOTA.
Learning from Exemplary Explanations
Jul 12, 2023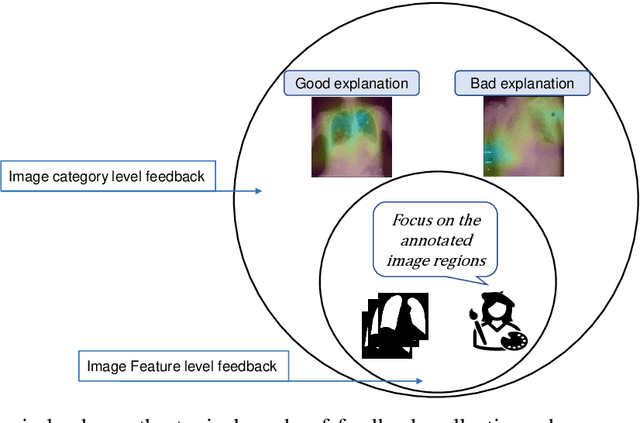

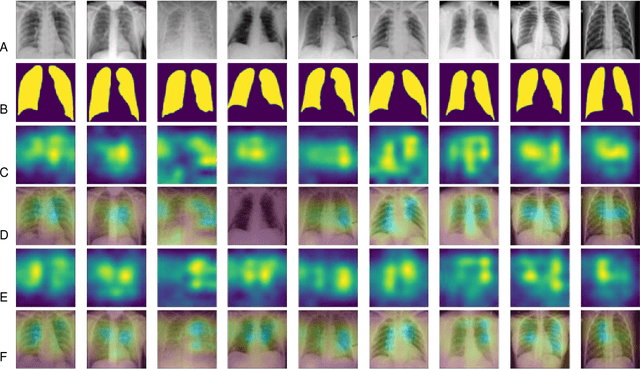
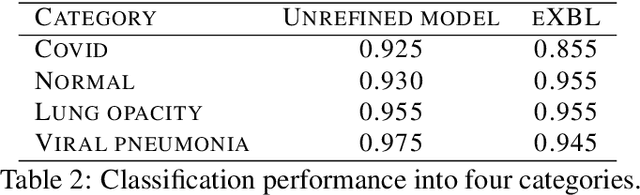
eXplanation Based Learning (XBL) is a form of Interactive Machine Learning (IML) that provides a model refining approach via user feedback collected on model explanations. Although the interactivity of XBL promotes model transparency, XBL requires a huge amount of user interaction and can become expensive as feedback is in the form of detailed annotation rather than simple category labelling which is more common in IML. This expense is exacerbated in high stakes domains such as medical image classification. To reduce the effort and expense of XBL we introduce a new approach that uses two input instances and their corresponding Gradient Weighted Class Activation Mapping (GradCAM) model explanations as exemplary explanations to implement XBL. Using a medical image classification task, we demonstrate that, using minimal human input, our approach produces improved explanations (+0.02, +3%) and achieves reduced classification performance (-0.04, -4%) when compared against a model trained without interactions.
Generalizing Supervised Deep Learning MRI Reconstruction to Multiple and Unseen Contrasts using Meta-Learning Hypernetworks
Jul 13, 2023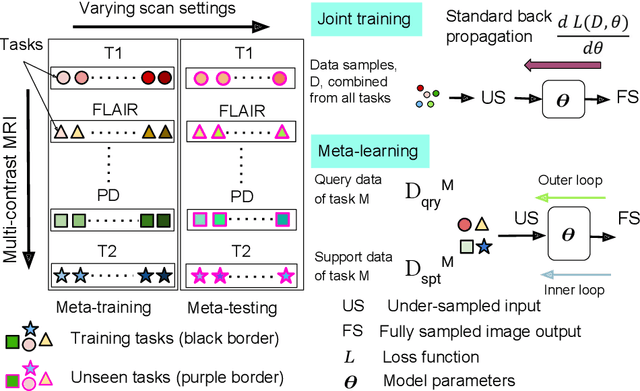
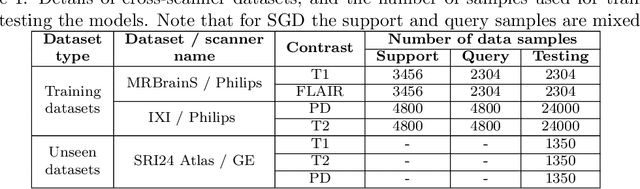
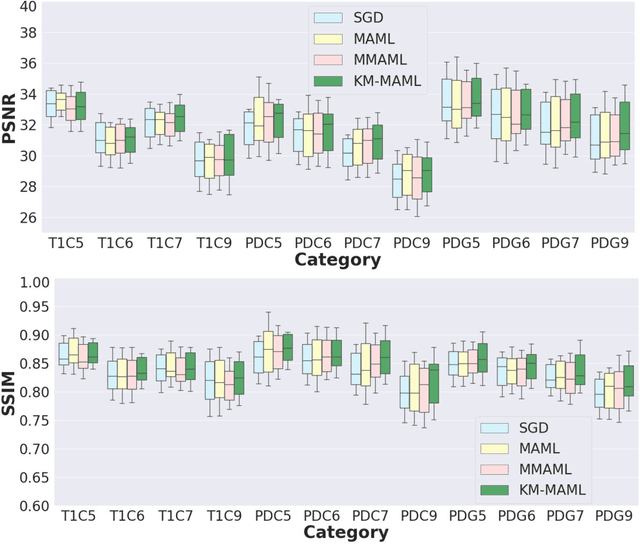
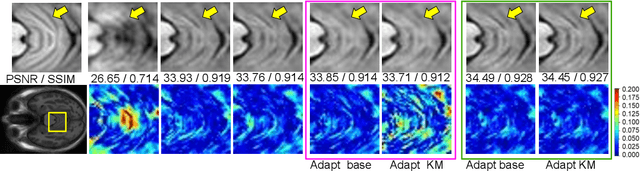
Meta-learning has recently been an emerging data-efficient learning technique for various medical imaging operations and has helped advance contemporary deep learning models. Furthermore, meta-learning enhances the knowledge generalization of the imaging tasks by learning both shared and discriminative weights for various configurations of imaging tasks. However, existing meta-learning models attempt to learn a single set of weight initializations of a neural network that might be restrictive for multimodal data. This work aims to develop a multimodal meta-learning model for image reconstruction, which augments meta-learning with evolutionary capabilities to encompass diverse acquisition settings of multimodal data. Our proposed model called KM-MAML (Kernel Modulation-based Multimodal Meta-Learning), has hypernetworks that evolve to generate mode-specific weights. These weights provide the mode-specific inductive bias for multiple modes by re-calibrating each kernel of the base network for image reconstruction via a low-rank kernel modulation operation. We incorporate gradient-based meta-learning (GBML) in the contextual space to update the weights of the hypernetworks for different modes. The hypernetworks and the reconstruction network in the GBML setting provide discriminative mode-specific features and low-level image features, respectively. Experiments on multi-contrast MRI reconstruction show that our model, (i) exhibits superior reconstruction performance over joint training, other meta-learning methods, and context-specific MRI reconstruction methods, and (ii) better adaptation capabilities with improvement margins of 0.5 dB in PSNR and 0.01 in SSIM. Besides, a representation analysis with U-Net shows that kernel modulation infuses 80% of mode-specific representation changes in the high-resolution layers. Our source code is available at https://github.com/sriprabhar/KM-MAML/.
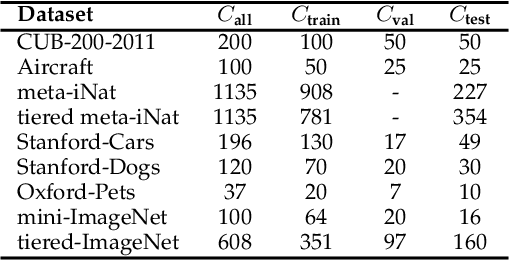
Task-Oriented Channel Attention for Fine-Grained Few-Shot Classification
Jul 28, 2023
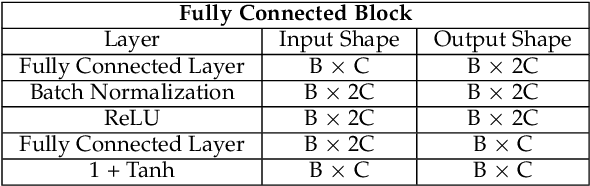
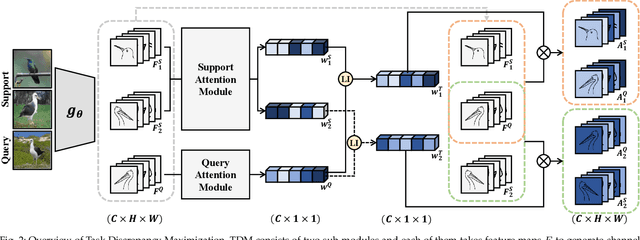
The difficulty of the fine-grained image classification mainly comes from a shared overall appearance across classes. Thus, recognizing discriminative details, such as eyes and beaks for birds, is a key in the task. However, this is particularly challenging when training data is limited. To address this, we propose Task Discrepancy Maximization (TDM), a task-oriented channel attention method tailored for fine-grained few-shot classification with two novel modules Support Attention Module (SAM) and Query Attention Module (QAM). SAM highlights channels encoding class-wise discriminative features, while QAM assigns higher weights to object-relevant channels of the query. Based on these submodules, TDM produces task-adaptive features by focusing on channels encoding class-discriminative details and possessed by the query at the same time, for accurate class-sensitive similarity measure between support and query instances. While TDM influences high-level feature maps by task-adaptive calibration of channel-wise importance, we further introduce Instance Attention Module (IAM) operating in intermediate layers of feature extractors to instance-wisely highlight object-relevant channels, by extending QAM. The merits of TDM and IAM and their complementary benefits are experimentally validated in fine-grained few-shot classification tasks. Moreover, IAM is also shown to be effective in coarse-grained and cross-domain few-shot classifications.
ContriMix: Unsupervised disentanglement of content and attribute for domain generalization in microscopy image analysis
Jun 07, 2023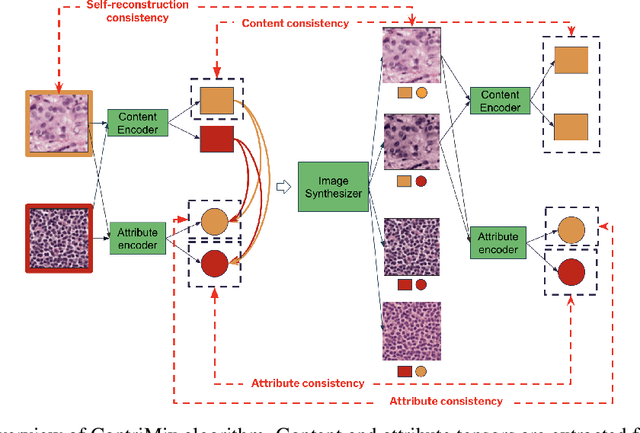

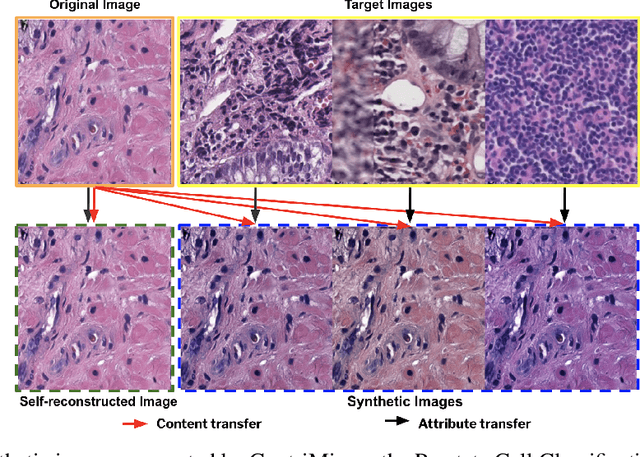
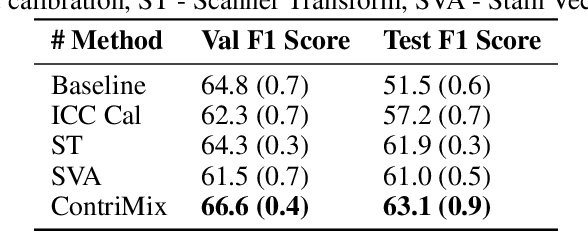
Domain generalization is critical for real-world applications of machine learning models to microscopy images, including histopathology and fluorescence imaging. Artifacts in histopathology arise through a complex combination of factors relating to tissue collection and laboratory processing, as well as factors intrinsic to patient samples. In fluorescence imaging, these artifacts stem from variations across experimental batches. The complexity and subtlety of these artifacts make the enumeration of data domains intractable. Therefore, augmentation-based methods of domain generalization that require domain identifiers and manual fine-tuning are inadequate in this setting. To overcome this challenge, we introduce ContriMix, a domain generalization technique that learns to generate synthetic images by disentangling and permuting the biological content ("content") and technical variations ("attributes") in microscopy images. ContriMix does not rely on domain identifiers or handcrafted augmentations and makes no assumptions about the input characteristics of images. We assess the performance of ContriMix on two pathology datasets (Camelyon17-WILDS and a prostate cell classification dataset) and one fluorescence microscopy dataset (RxRx1-WILDS). ContriMix outperforms current state-of-the-art methods in all datasets, motivating its usage for microscopy image analysis in real-world settings where domain information is hard to come by.