 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
FreeSeed: Frequency-band-aware and Self-guided Network for Sparse-view CT Reconstruction
Jul 12, 2023
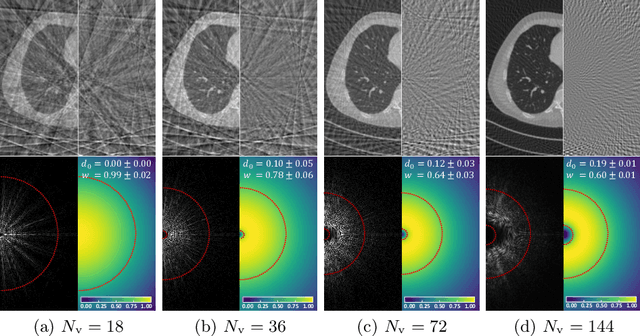
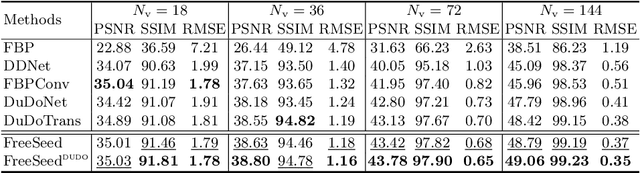
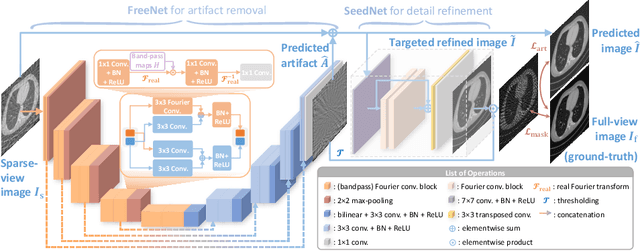
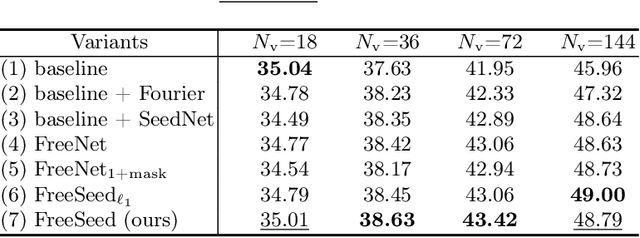
Sparse-view computed tomography (CT) is a promising solution for expediting the scanning process and mitigating radiation exposure to patients, the reconstructed images, however, contain severe streak artifacts, compromising subsequent screening and diagnosis. Recently, deep learning-based image post-processing methods along with their dual-domain counterparts have shown promising results. However, existing methods usually produce over-smoothed images with loss of details due to (1) the difficulty in accurately modeling the artifact patterns in the image domain, and (2) the equal treatment of each pixel in the loss function. To address these issues, we concentrate on the image post-processing and propose a simple yet effective FREquency-band-awarE and SElf-guidED network, termed FreeSeed, which can effectively remove artifact and recover missing detail from the contaminated sparse-view CT images. Specifically, we first propose a frequency-band-aware artifact modeling network (FreeNet), which learns artifact-related frequency-band attention in Fourier domain for better modeling the globally distributed streak artifact on the sparse-view CT images. We then introduce a self-guided artifact refinement network (SeedNet), which leverages the predicted artifact to assist FreeNet in continuing to refine the severely corrupted details. Extensive experiments demonstrate the superior performance of FreeSeed and its dual-domain counterpart over the state-of-the-art sparse-view CT reconstruction methods. Source code is made available at https://github.com/Masaaki-75/freeseed.
Rectifying Noisy Labels with Sequential Prior: Multi-Scale Temporal Feature Affinity Learning for Robust Video Segmentation
Jul 12, 2023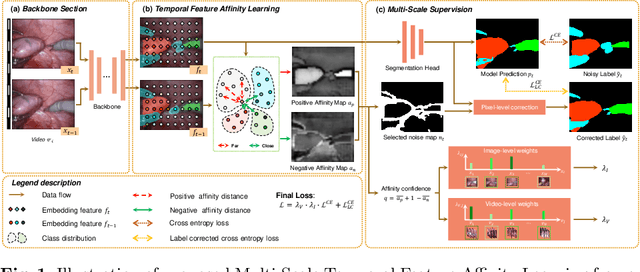
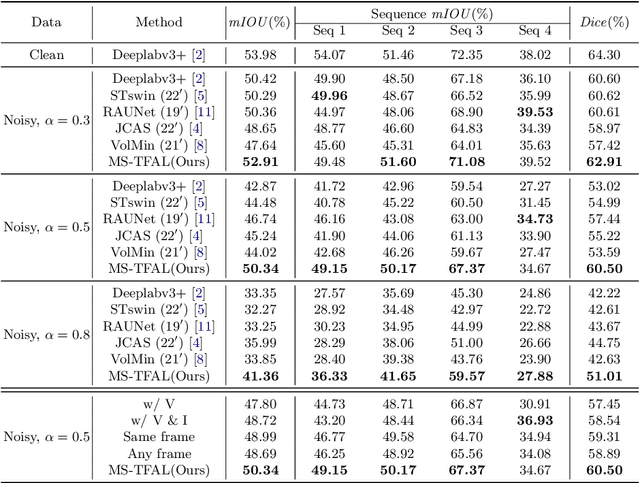


Noisy label problems are inevitably in existence within medical image segmentation causing severe performance degradation. Previous segmentation methods for noisy label problems only utilize a single image while the potential of leveraging the correlation between images has been overlooked. Especially for video segmentation, adjacent frames contain rich contextual information beneficial in cognizing noisy labels. Based on two insights, we propose a Multi-Scale Temporal Feature Affinity Learning (MS-TFAL) framework to resolve noisy-labeled medical video segmentation issues. First, we argue the sequential prior of videos is an effective reference, i.e., pixel-level features from adjacent frames are close in distance for the same class and far in distance otherwise. Therefore, Temporal Feature Affinity Learning (TFAL) is devised to indicate possible noisy labels by evaluating the affinity between pixels in two adjacent frames. We also notice that the noise distribution exhibits considerable variations across video, image, and pixel levels. In this way, we introduce Multi-Scale Supervision (MSS) to supervise the network from three different perspectives by re-weighting and refining the samples. This design enables the network to concentrate on clean samples in a coarse-to-fine manner. Experiments with both synthetic and real-world label noise demonstrate that our method outperforms recent state-of-the-art robust segmentation approaches. Code is available at https://github.com/BeileiCui/MS-TFAL.
DQ-Det: Learning Dynamic Query Combinations for Transformer-based Object Detection and Segmentation
Jul 23, 2023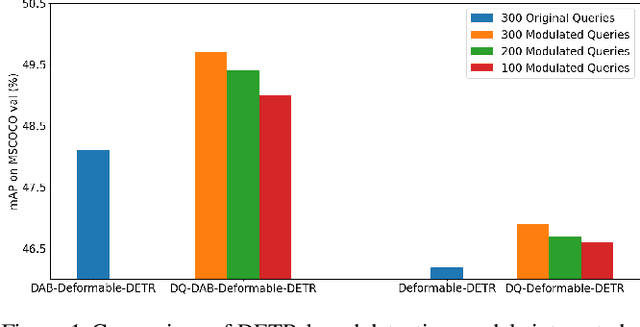

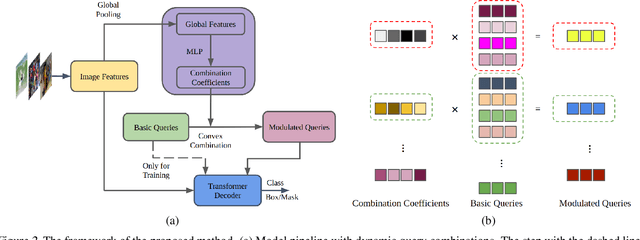
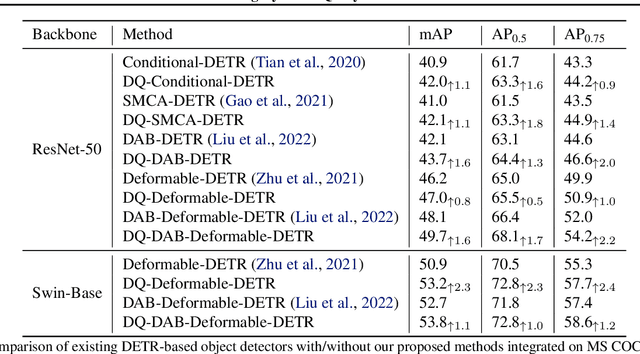
Transformer-based detection and segmentation methods use a list of learned detection queries to retrieve information from the transformer network and learn to predict the location and category of one specific object from each query. We empirically find that random convex combinations of the learned queries are still good for the corresponding models. We then propose to learn a convex combination with dynamic coefficients based on the high-level semantics of the image. The generated dynamic queries, named modulated queries, better capture the prior of object locations and categories in the different images. Equipped with our modulated queries, a wide range of DETR-based models achieve consistent and superior performance across multiple tasks including object detection, instance segmentation, panoptic segmentation, and video instance segmentation.
Diverse Inpainting and Editing with GAN Inversion
Jul 27, 2023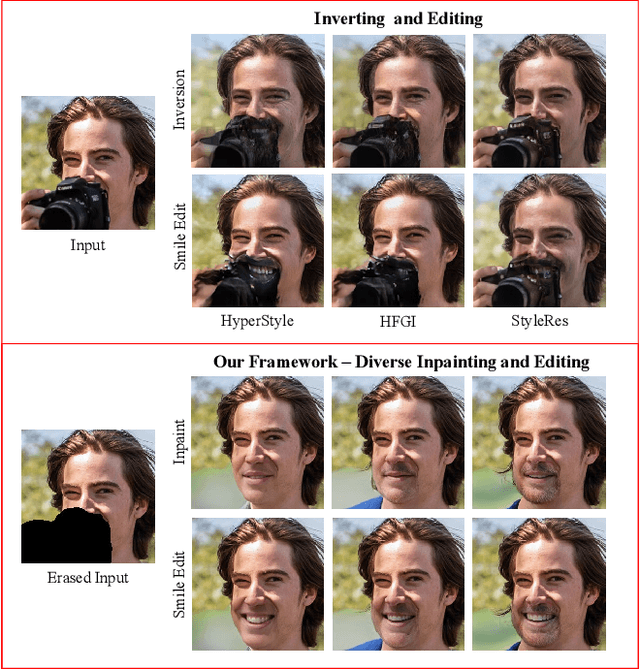
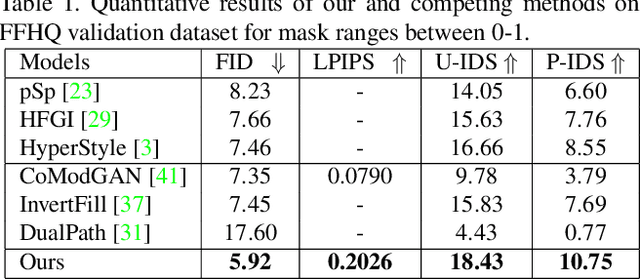
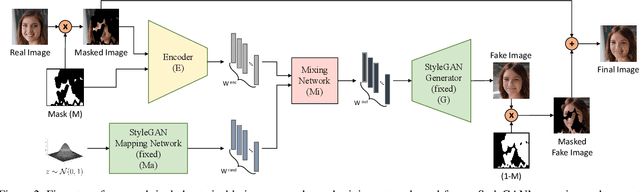
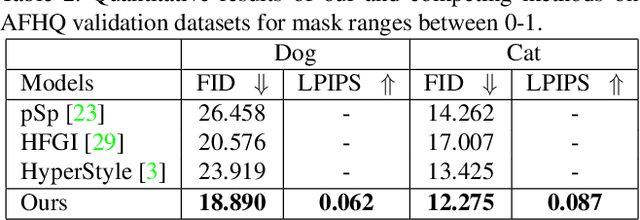
Recent inversion methods have shown that real images can be inverted into StyleGAN's latent space and numerous edits can be achieved on those images thanks to the semantically rich feature representations of well-trained GAN models. However, extensive research has also shown that image inversion is challenging due to the trade-off between high-fidelity reconstruction and editability. In this paper, we tackle an even more difficult task, inverting erased images into GAN's latent space for realistic inpaintings and editings. Furthermore, by augmenting inverted latent codes with different latent samples, we achieve diverse inpaintings. Specifically, we propose to learn an encoder and mixing network to combine encoded features from erased images with StyleGAN's mapped features from random samples. To encourage the mixing network to utilize both inputs, we train the networks with generated data via a novel set-up. We also utilize higher-rate features to prevent color inconsistencies between the inpainted and unerased parts. We run extensive experiments and compare our method with state-of-the-art inversion and inpainting methods. Qualitative metrics and visual comparisons show significant improvements.
PromptStyler: Prompt-driven Style Generation for Source-free Domain Generalization
Jul 27, 2023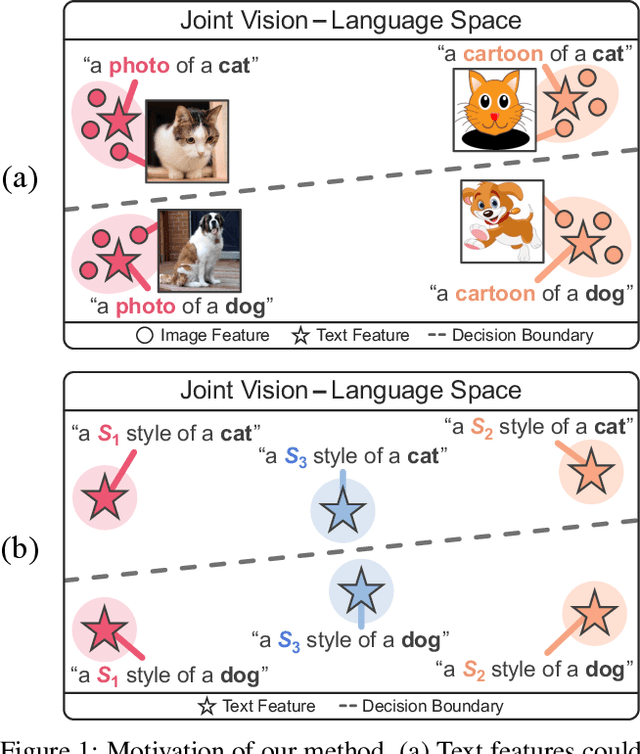
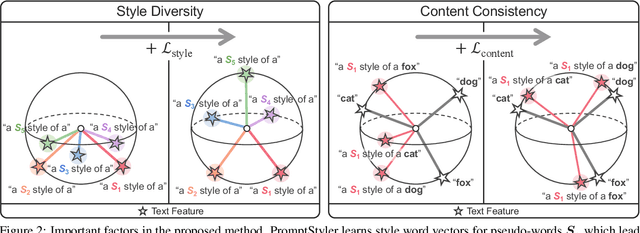
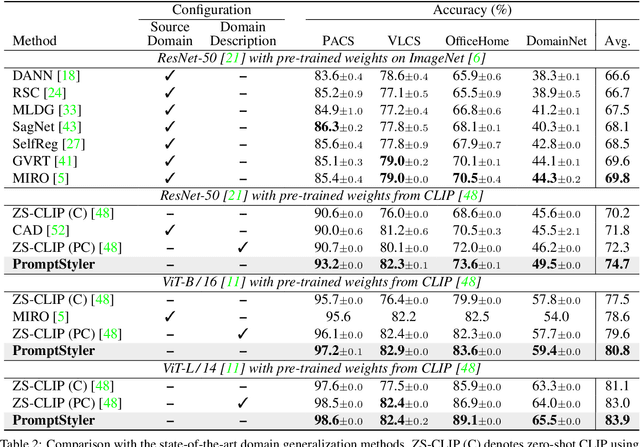
In a joint vision-language space, a text feature (e.g., from "a photo of a dog") could effectively represent its relevant image features (e.g., from dog photos). Inspired by this, we propose PromptStyler which simulates various distribution shifts in the joint space by synthesizing diverse styles via prompts without using any images to deal with source-free domain generalization. Our method learns to generate a variety of style features (from "a S* style of a") via learnable style word vectors for pseudo-words S*. To ensure that learned styles do not distort content information, we force style-content features (from "a S* style of a [class]") to be located nearby their corresponding content features (from "[class]") in the joint vision-language space. After learning style word vectors, we train a linear classifier using synthesized style-content features. PromptStyler achieves the state of the art on PACS, VLCS, OfficeHome and DomainNet, although it does not require any images and takes just ~30 minutes for training using a single GPU.
ProgDTD: Progressive Learned Image Compression with Double-Tail-Drop Training
May 03, 2023Progressive compression allows images to start loading as low-resolution versions, becoming clearer as more data is received. This increases user experience when, for example, network connections are slow. Today, most approaches for image compression, both classical and learned ones, are designed to be non-progressive. This paper introduces ProgDTD, a training method that transforms learned, non-progressive image compression approaches into progressive ones. The design of ProgDTD is based on the observation that the information stored within the bottleneck of a compression model commonly varies in importance. To create a progressive compression model, ProgDTD modifies the training steps to enforce the model to store the data in the bottleneck sorted by priority. We achieve progressive compression by transmitting the data in order of its sorted index. ProgDTD is designed for CNN-based learned image compression models, does not need additional parameters, and has a customizable range of progressiveness. For evaluation, we apply ProgDTDto the hyperprior model, one of the most common structures in learned image compression. Our experimental results show that ProgDTD performs comparably to its non-progressive counterparts and other state-of-the-art progressive models in terms of MS-SSIM and accuracy.
Lightweight Super-Resolution Head for Human Pose Estimation
Jul 31, 2023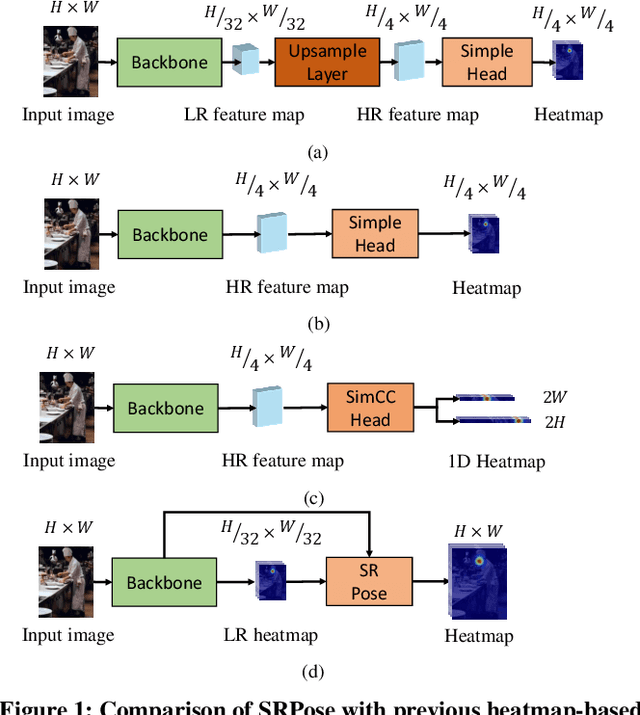
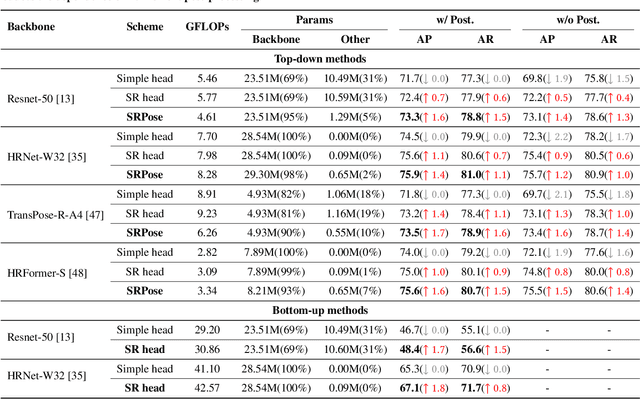
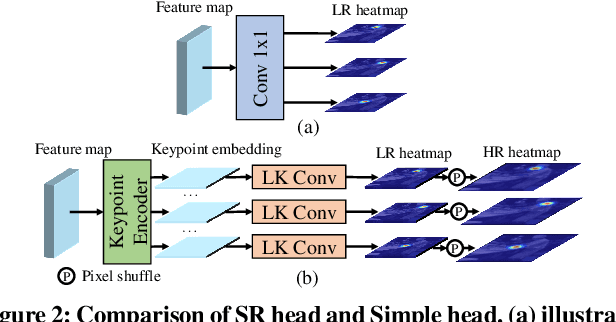
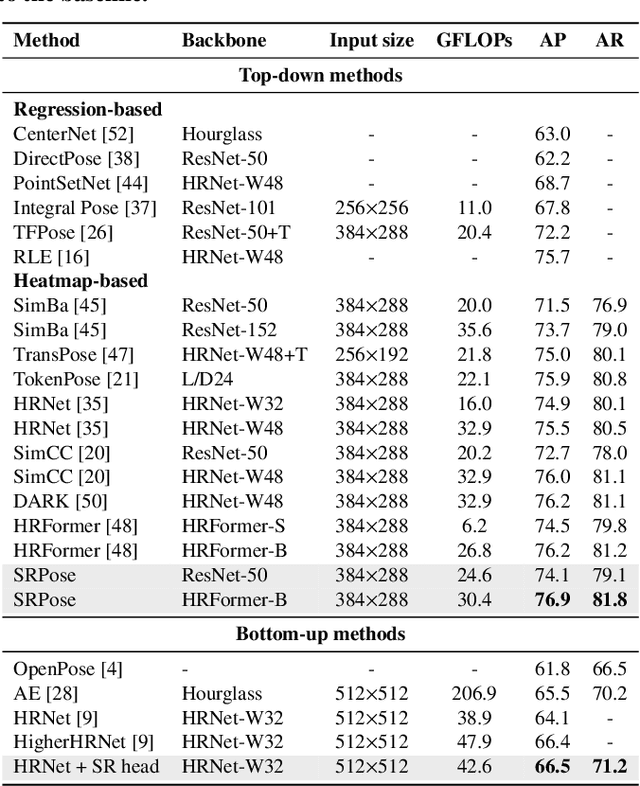
Heatmap-based methods have become the mainstream method for pose estimation due to their superior performance. However, heatmap-based approaches suffer from significant quantization errors with downscale heatmaps, which result in limited performance and the detrimental effects of intermediate supervision. Previous heatmap-based methods relied heavily on additional post-processing to mitigate quantization errors. Some heatmap-based approaches improve the resolution of feature maps by using multiple costly upsampling layers to improve localization precision. To solve the above issues, we creatively view the backbone network as a degradation process and thus reformulate the heatmap prediction as a Super-Resolution (SR) task. We first propose the SR head, which predicts heatmaps with a spatial resolution higher than the input feature maps (or even consistent with the input image) by super-resolution, to effectively reduce the quantization error and the dependence on further post-processing. Besides, we propose SRPose to gradually recover the HR heatmaps from LR heatmaps and degraded features in a coarse-to-fine manner. To reduce the training difficulty of HR heatmaps, SRPose applies SR heads to supervise the intermediate features in each stage. In addition, the SR head is a lightweight and generic head that applies to top-down and bottom-up methods. Extensive experiments on the COCO, MPII, and CrowdPose datasets show that SRPose outperforms the corresponding heatmap-based approaches. The code and models are available at https://github.com/haonanwang0522/SRPose.
* ACM MM 2023 accepted
Visual Captioning at Will: Describing Images and Videos Guided by a Few Stylized Sentences
Jul 31, 2023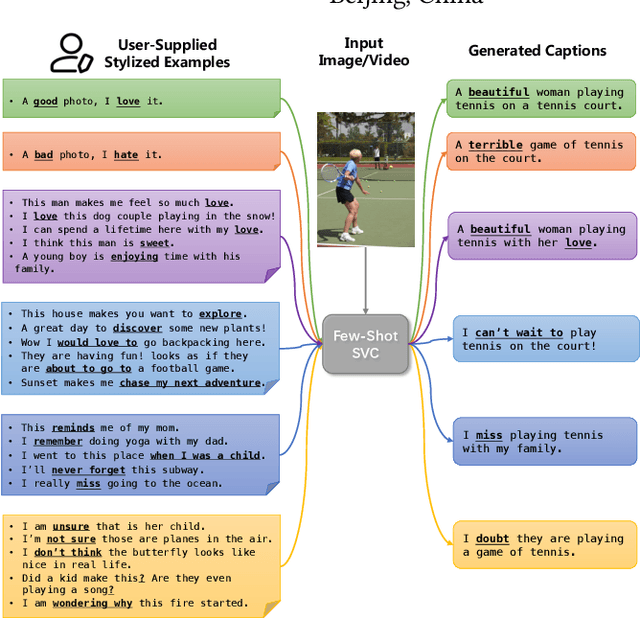
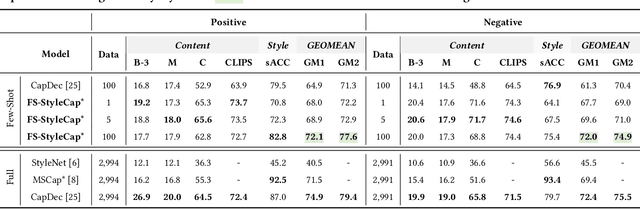
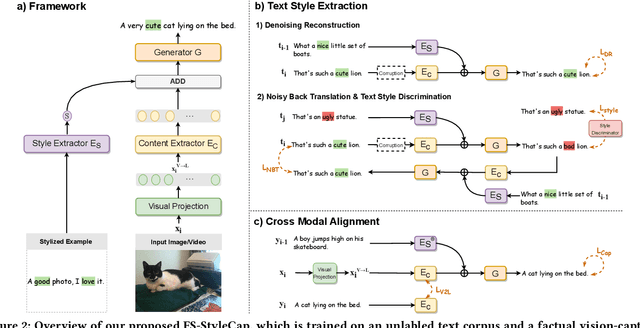
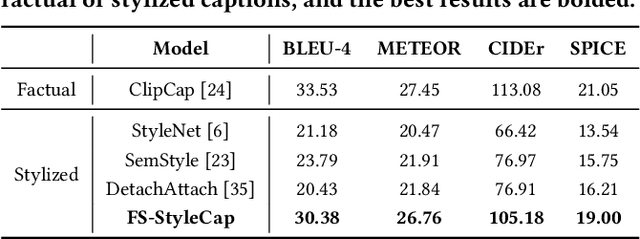
Stylized visual captioning aims to generate image or video descriptions with specific styles, making them more attractive and emotionally appropriate. One major challenge with this task is the lack of paired stylized captions for visual content, so most existing works focus on unsupervised methods that do not rely on parallel datasets. However, these approaches still require training with sufficient examples that have style labels, and the generated captions are limited to predefined styles. To address these limitations, we explore the problem of Few-Shot Stylized Visual Captioning, which aims to generate captions in any desired style, using only a few examples as guidance during inference, without requiring further training. We propose a framework called FS-StyleCap for this task, which utilizes a conditional encoder-decoder language model and a visual projection module. Our two-step training scheme proceeds as follows: first, we train a style extractor to generate style representations on an unlabeled text-only corpus. Then, we freeze the extractor and enable our decoder to generate stylized descriptions based on the extracted style vector and projected visual content vectors. During inference, our model can generate desired stylized captions by deriving the style representation from user-supplied examples. Our automatic evaluation results for few-shot sentimental visual captioning outperform state-of-the-art approaches and are comparable to models that are fully trained on labeled style corpora. Human evaluations further confirm our model s ability to handle multiple styles.
JOTR: 3D Joint Contrastive Learning with Transformers for Occluded Human Mesh Recovery
Jul 31, 2023In this study, we focus on the problem of 3D human mesh recovery from a single image under obscured conditions. Most state-of-the-art methods aim to improve 2D alignment technologies, such as spatial averaging and 2D joint sampling. However, they tend to neglect the crucial aspect of 3D alignment by improving 3D representations. Furthermore, recent methods struggle to separate the target human from occlusion or background in crowded scenes as they optimize the 3D space of target human with 3D joint coordinates as local supervision. To address these issues, a desirable method would involve a framework for fusing 2D and 3D features and a strategy for optimizing the 3D space globally. Therefore, this paper presents 3D JOint contrastive learning with TRansformers (JOTR) framework for handling occluded 3D human mesh recovery. Our method includes an encoder-decoder transformer architecture to fuse 2D and 3D representations for achieving 2D$\&$3D aligned results in a coarse-to-fine manner and a novel 3D joint contrastive learning approach for adding explicitly global supervision for the 3D feature space. The contrastive learning approach includes two contrastive losses: joint-to-joint contrast for enhancing the similarity of semantically similar voxels (i.e., human joints), and joint-to-non-joint contrast for ensuring discrimination from others (e.g., occlusions and background). Qualitative and quantitative analyses demonstrate that our method outperforms state-of-the-art competitors on both occlusion-specific and standard benchmarks, significantly improving the reconstruction of occluded humans.
Fusion-S2iGan: An Efficient and Effective Single-Stage Framework for Speech-to-Image Generation
May 17, 2023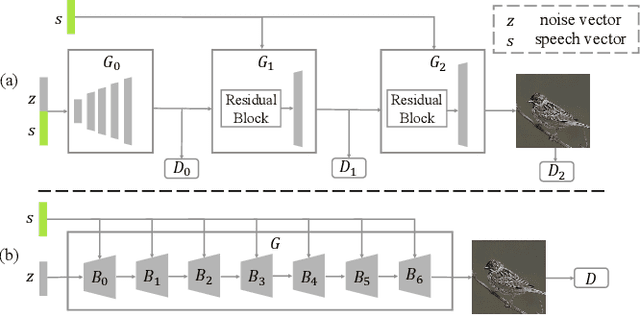
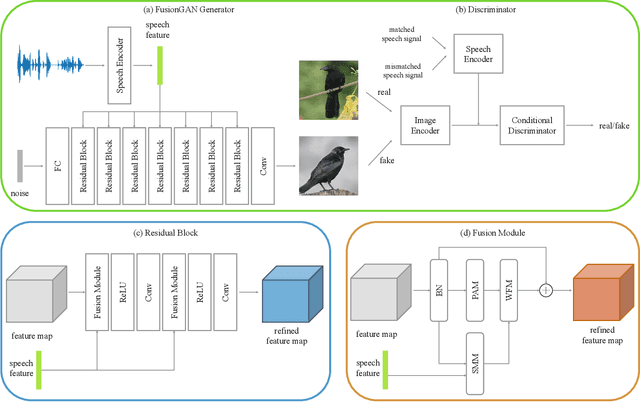
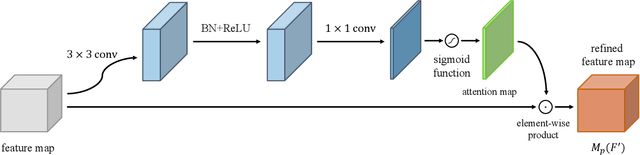
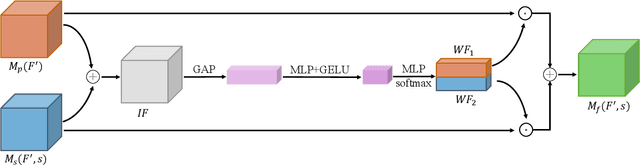
The goal of a speech-to-image transform is to produce a photo-realistic picture directly from a speech signal. Recently, various studies have focused on this task and have achieved promising performance. However, current speech-to-image approaches are based on a stacked modular framework that suffers from three vital issues: 1) Training separate networks is time-consuming as well as inefficient and the convergence of the final generative model strongly depends on the previous generators; 2) The quality of precursor images is ignored by this architecture; 3) Multiple discriminator networks are required to be trained. To this end, we propose an efficient and effective single-stage framework called Fusion-S2iGan to yield perceptually plausible and semantically consistent image samples on the basis of given spoken descriptions. Fusion-S2iGan introduces a visual+speech fusion module (VSFM), constructed with a pixel-attention module (PAM), a speech-modulation module (SMM) and a weighted-fusion module (WFM), to inject the speech embedding from a speech encoder into the generator while improving the quality of synthesized pictures. Fusion-S2iGan spreads the bimodal information over all layers of the generator network to reinforce the visual feature maps at various hierarchical levels in the architecture. We conduct a series of experiments on four benchmark data sets, i.e., CUB birds, Oxford-102, Flickr8k and Places-subset. The experimental results demonstrate the superiority of the presented Fusion-S2iGan compared to the state-of-the-art models with a multi-stage architecture and a performance level that is close to traditional text-to-image approaches.