 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Bidirectionally Deformable Motion Modulation For Video-based Human Pose Transfer
Jul 18, 2023
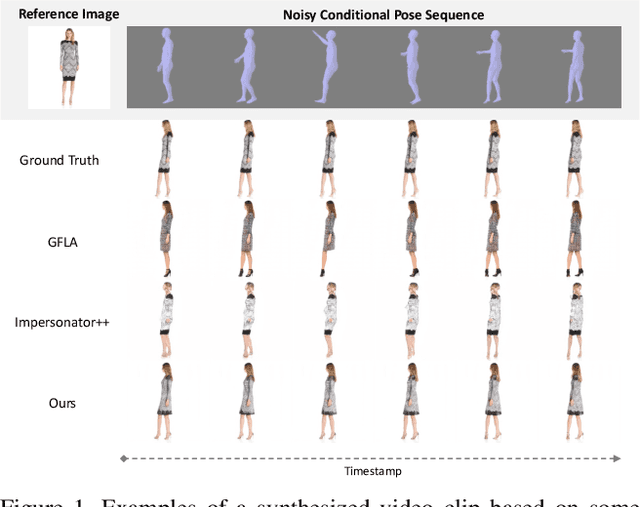


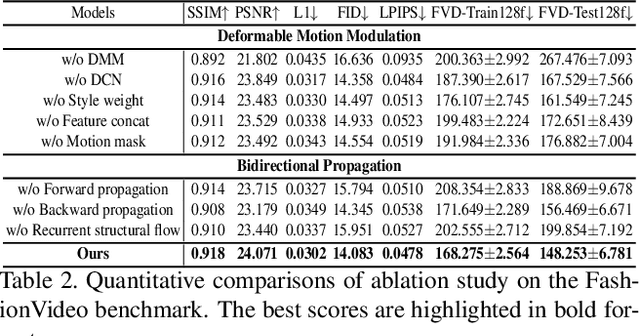
Video-based human pose transfer is a video-to-video generation task that animates a plain source human image based on a series of target human poses. Considering the difficulties in transferring highly structural patterns on the garments and discontinuous poses, existing methods often generate unsatisfactory results such as distorted textures and flickering artifacts. To address these issues, we propose a novel Deformable Motion Modulation (DMM) that utilizes geometric kernel offset with adaptive weight modulation to simultaneously perform feature alignment and style transfer. Different from normal style modulation used in style transfer, the proposed modulation mechanism adaptively reconstructs smoothed frames from style codes according to the object shape through an irregular receptive field of view. To enhance the spatio-temporal consistency, we leverage bidirectional propagation to extract the hidden motion information from a warped image sequence generated by noisy poses. The proposed feature propagation significantly enhances the motion prediction ability by forward and backward propagation. Both quantitative and qualitative experimental results demonstrate superiority over the state-of-the-arts in terms of image fidelity and visual continuity. The source code is publicly available at github.com/rocketappslab/bdmm.
Mobile Image Restoration via Prior Quantization
May 10, 2023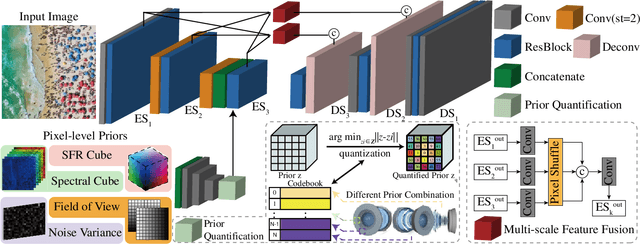
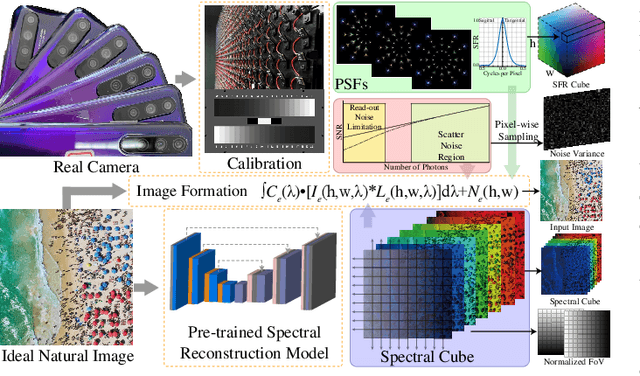

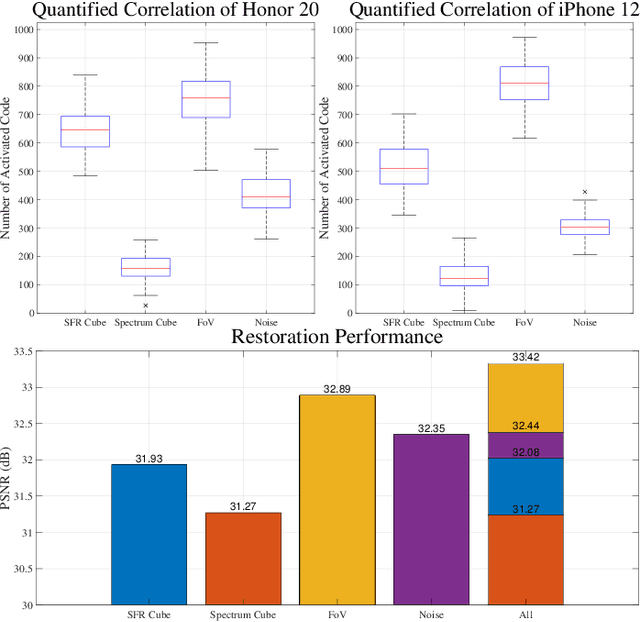
In digital images, the performance of optical aberration is a multivariate degradation, where the spectral of the scene, the lens imperfections, and the field of view together contribute to the results. Besides eliminating it at the hardware level, the post-processing system, which utilizes various prior information, is significant for correction. However, due to the content differences among priors, the pipeline that aligns these factors shows limited efficiency and unoptimized restoration. Here, we propose a prior quantization model to correct the optical aberrations in image processing systems. To integrate these messages, we encode various priors into a latent space and quantify them by the learnable codebooks. After quantization, the prior codes are fused with the image restoration branch to realize targeted optical aberration correction. Comprehensive experiments demonstrate the flexibility of the proposed method and validate its potential to accomplish targeted restoration for a specific camera. Furthermore, our model promises to analyze the correlation between the various priors and the optical aberration of devices, which is helpful for joint soft-hardware design.
Automating Wood Species Detection and Classification in Microscopic Images of Fibrous Materials with Deep Learning
Jul 18, 2023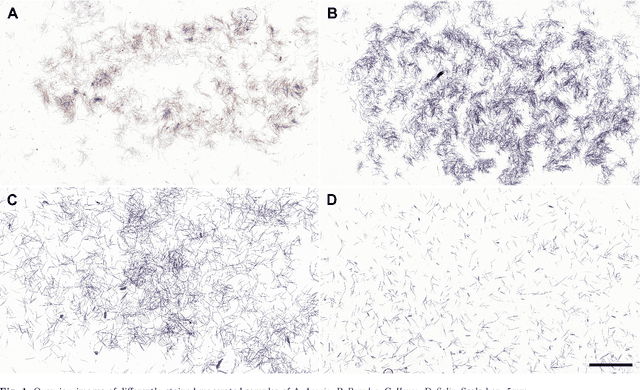
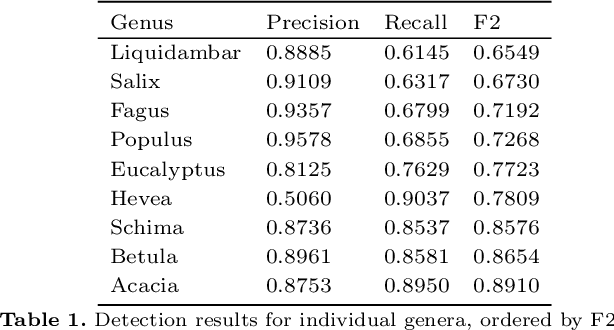

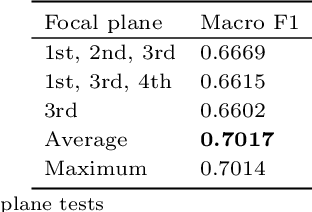
We have developed a methodology for the systematic generation of a large image dataset of macerated wood references, which we used to generate image data for nine hardwood genera. This is the basis for a substantial approach to automate, for the first time, the identification of hardwood species in microscopic images of fibrous materials by deep learning. Our methodology includes a flexible pipeline for easy annotation of vessel elements. We compare the performance of different neural network architectures and hyperparameters. Our proposed method performs similarly well to human experts. In the future, this will improve controls on global wood fiber product flows to protect forests.
Guided Linear Upsampling
Jul 13, 2023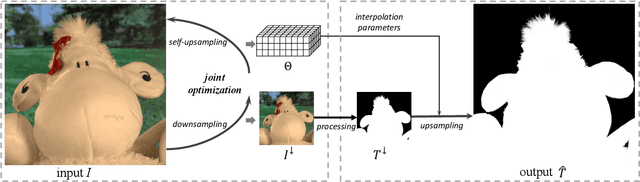
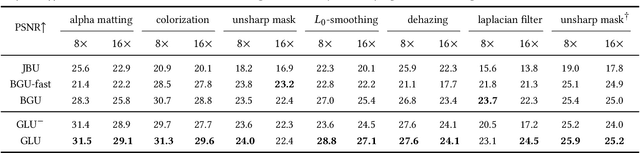
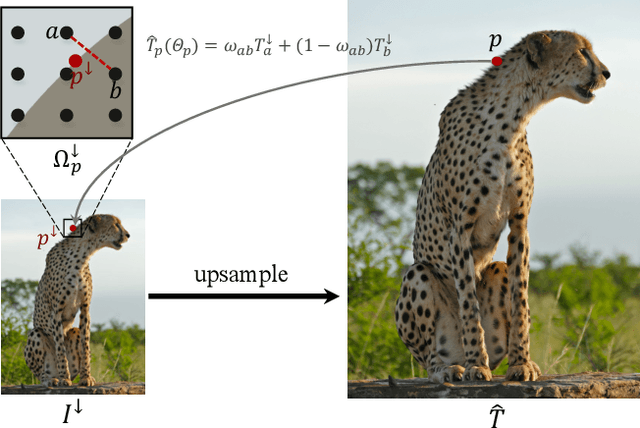
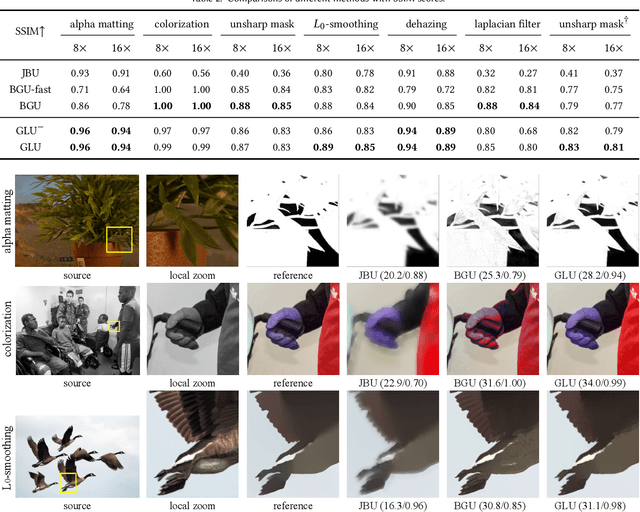
Guided upsampling is an effective approach for accelerating high-resolution image processing. In this paper, we propose a simple yet effective guided upsampling method. Each pixel in the high-resolution image is represented as a linear interpolation of two low-resolution pixels, whose indices and weights are optimized to minimize the upsampling error. The downsampling can be jointly optimized in order to prevent missing small isolated regions. Our method can be derived from the color line model and local color transformations. Compared to previous methods, our method can better preserve detail effects while suppressing artifacts such as bleeding and blurring. It is efficient, easy to implement, and free of sensitive parameters. We evaluate the proposed method with a wide range of image operators, and show its advantages through quantitative and qualitative analysis. We demonstrate the advantages of our method for both interactive image editing and real-time high-resolution video processing. In particular, for interactive editing, the joint optimization can be precomputed, thus allowing for instant feedback without hardware acceleration.
Cross-supervised Dual Classifiers for Semi-supervised Medical Image Segmentation
May 25, 2023
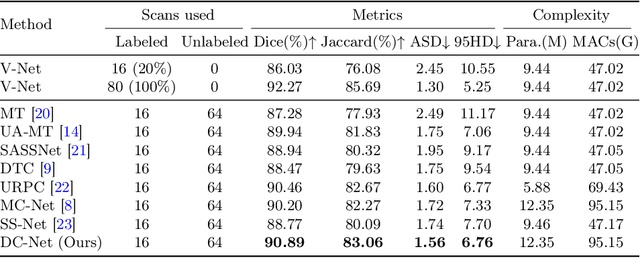
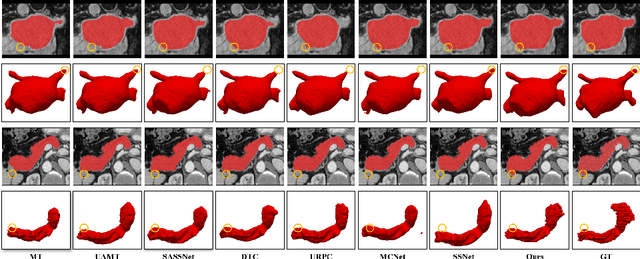
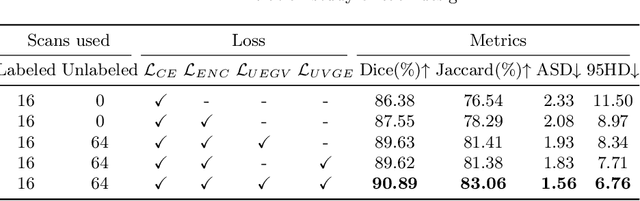
Semi-supervised medical image segmentation offers a promising solution for large-scale medical image analysis by significantly reducing the annotation burden while achieving comparable performance. Employing this method exhibits a high degree of potential for optimizing the segmentation process and increasing its feasibility in clinical settings during translational investigations. Recently, cross-supervised training based on different co-training sub-networks has become a standard paradigm for this task. Still, the critical issues of sub-network disagreement and label-noise suppression require further attention and progress in cross-supervised training. This paper proposes a cross-supervised learning framework based on dual classifiers (DC-Net), including an evidential classifier and a vanilla classifier. The two classifiers exhibit complementary characteristics, enabling them to handle disagreement effectively and generate more robust and accurate pseudo-labels for unlabeled data. We also incorporate the uncertainty estimation from the evidential classifier into cross-supervised training to alleviate the negative effect of the error supervision signal. The extensive experiments on LA and Pancreas-CT dataset illustrate that DC-Net outperforms other state-of-the-art methods for semi-supervised segmentation. The code will be released soon.
Morphological Image Analysis and Feature Extraction for Reasoning with AI-based Defect Detection and Classification Models
Jul 24, 2023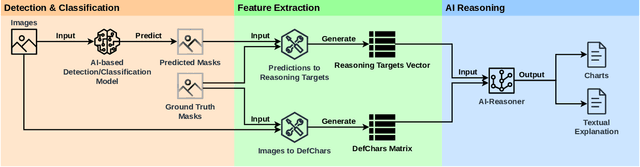
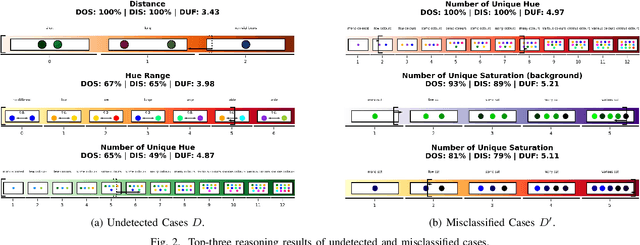
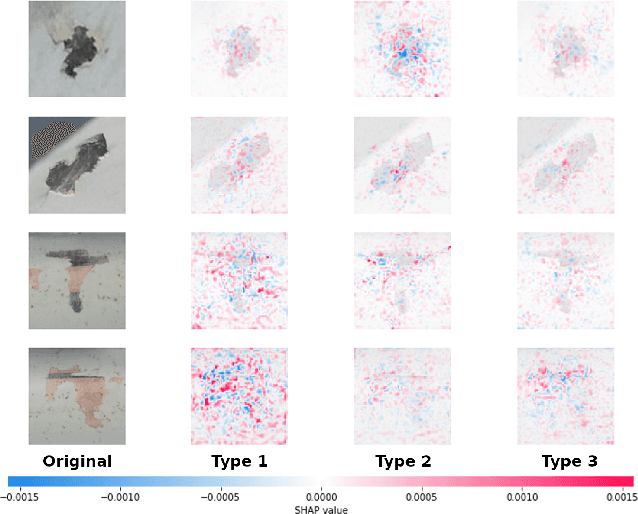
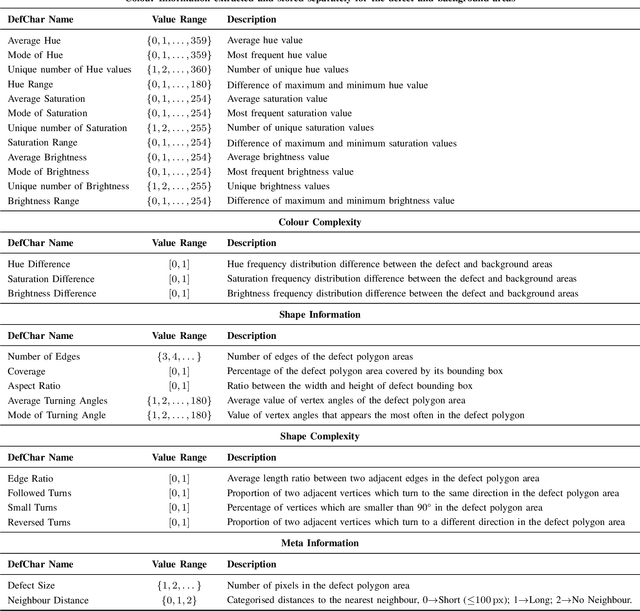
As the use of artificial intelligent (AI) models becomes more prevalent in industries such as engineering and manufacturing, it is essential that these models provide transparent reasoning behind their predictions. This paper proposes the AI-Reasoner, which extracts the morphological characteristics of defects (DefChars) from images and utilises decision trees to reason with the DefChar values. Thereafter, the AI-Reasoner exports visualisations (i.e. charts) and textual explanations to provide insights into outputs made by masked-based defect detection and classification models. It also provides effective mitigation strategies to enhance data pre-processing and overall model performance. The AI-Reasoner was tested on explaining the outputs of an IE Mask R-CNN model using a set of 366 images containing defects. The results demonstrated its effectiveness in explaining the IE Mask R-CNN model's predictions. Overall, the proposed AI-Reasoner provides a solution for improving the performance of AI models in industrial applications that require defect analysis.
Hierarchical Diffusion Autoencoders and Disentangled Image Manipulation
Apr 25, 2023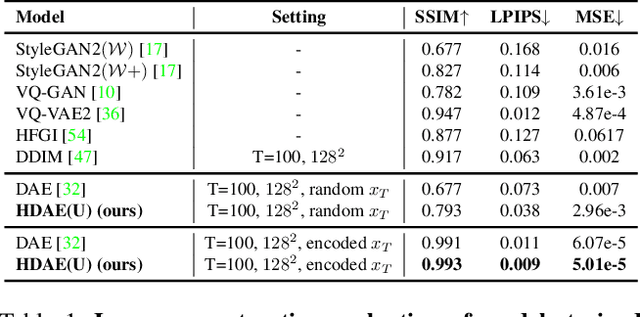
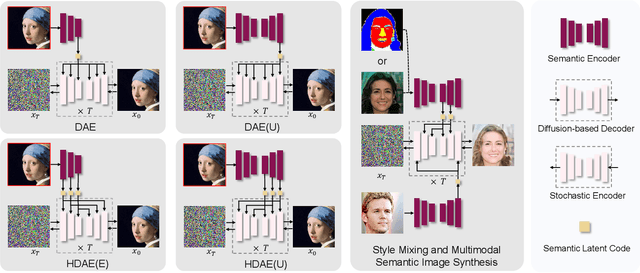

Diffusion models have attained impressive visual quality for image synthesis. However, how to interpret and manipulate the latent space of diffusion models has not been extensively explored. Prior work diffusion autoencoders encode the semantic representations into a semantic latent code, which fails to reflect the rich information of details and the intrinsic feature hierarchy. To mitigate those limitations, we propose Hierarchical Diffusion Autoencoders (HDAE) that exploit the fine-grained-to-abstract and lowlevel-to-high-level feature hierarchy for the latent space of diffusion models. The hierarchical latent space of HDAE inherently encodes different abstract levels of semantics and provides more comprehensive semantic representations. In addition, we propose a truncated-feature-based approach for disentangled image manipulation. We demonstrate the effectiveness of our proposed approach with extensive experiments and applications on image reconstruction, style mixing, controllable interpolation, detail-preserving and disentangled image manipulation, and multi-modal semantic image synthesis.
Frequency Domain Adversarial Training for Robust Volumetric Medical Segmentation
Jul 20, 2023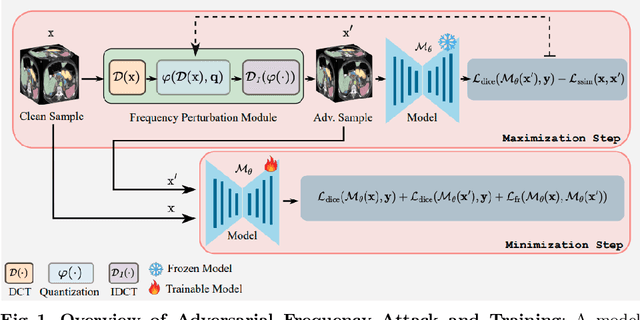

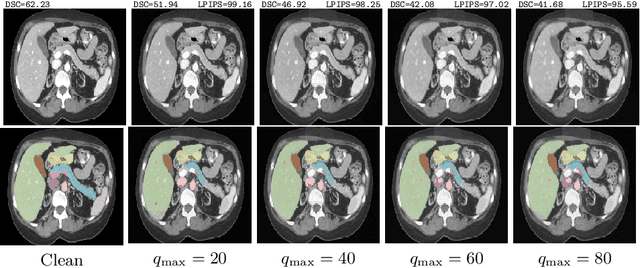
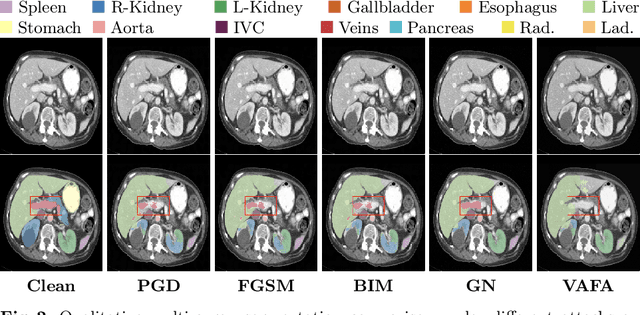
It is imperative to ensure the robustness of deep learning models in critical applications such as, healthcare. While recent advances in deep learning have improved the performance of volumetric medical image segmentation models, these models cannot be deployed for real-world applications immediately due to their vulnerability to adversarial attacks. We present a 3D frequency domain adversarial attack for volumetric medical image segmentation models and demonstrate its advantages over conventional input or voxel domain attacks. Using our proposed attack, we introduce a novel frequency domain adversarial training approach for optimizing a robust model against voxel and frequency domain attacks. Moreover, we propose frequency consistency loss to regulate our frequency domain adversarial training that achieves a better tradeoff between model's performance on clean and adversarial samples. Code is publicly available at https://github.com/asif-hanif/vafa.
Controllable Image Generation via Collage Representations
Apr 26, 2023


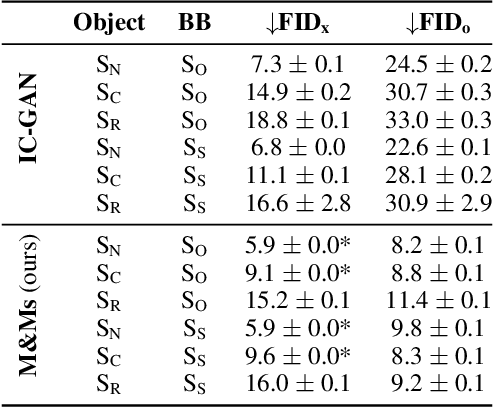
Recent advances in conditional generative image models have enabled impressive results. On the one hand, text-based conditional models have achieved remarkable generation quality, by leveraging large-scale datasets of image-text pairs. To enable fine-grained controllability, however, text-based models require long prompts, whose details may be ignored by the model. On the other hand, layout-based conditional models have also witnessed significant advances. These models rely on bounding boxes or segmentation maps for precise spatial conditioning in combination with coarse semantic labels. The semantic labels, however, cannot be used to express detailed appearance characteristics. In this paper, we approach fine-grained scene controllability through image collages which allow a rich visual description of the desired scene as well as the appearance and location of the objects therein, without the need of class nor attribute labels. We introduce "mixing and matching scenes" (M&Ms), an approach that consists of an adversarially trained generative image model which is conditioned on appearance features and spatial positions of the different elements in a collage, and integrates these into a coherent image. We train our model on the OpenImages (OI) dataset and evaluate it on collages derived from OI and MS-COCO datasets. Our experiments on the OI dataset show that M&Ms outperforms baselines in terms of fine-grained scene controllability while being very competitive in terms of image quality and sample diversity. On the MS-COCO dataset, we highlight the generalization ability of our model by outperforming DALL-E in terms of the zero-shot FID metric, despite using two magnitudes fewer parameters and data. Collage based generative models have the potential to advance content creation in an efficient and effective way as they are intuitive to use and yield high quality generations.
An Image Based Visual Servo Method for Probe-and-Drogue Autonomous Aerial Refueling
May 27, 2023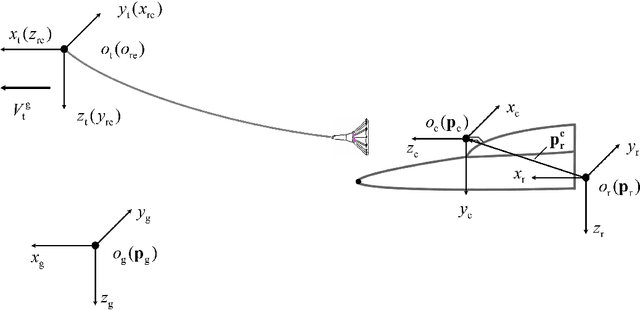

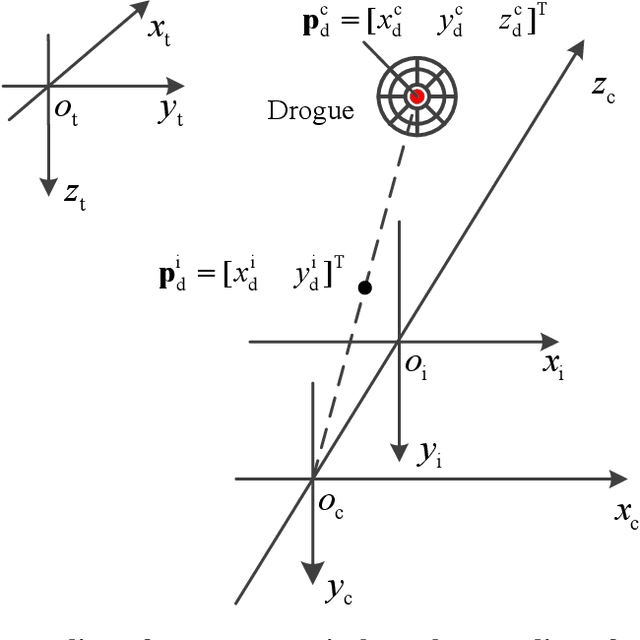
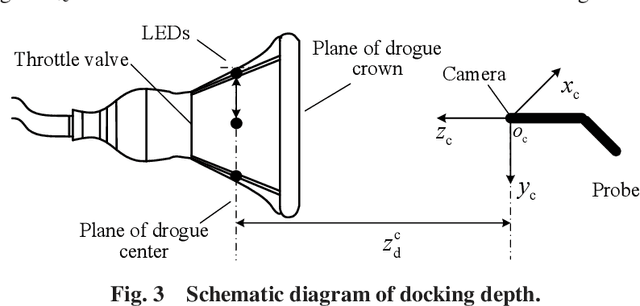
With the high focus on autonomous aerial refueling recently, it becomes increasingly urgent to design efficient methods or algorithms to solve AAR problems in complicated aerial environments. Apart from the complex aerodynamic disturbance, another problem is the pose estimation error caused by the camera calibration error, installation error, or 3D object modeling error, which may not satisfy the highly accurate docking. The main objective of the effort described in this paper is the implementation of an image-based visual servo control method, which contains the establishment of an image-based visual servo model involving the receiver's dynamics and the design of the corresponding controller. Simulation results indicate that the proposed method can make the system dock successfully under complicated conditions and improve the robustness against pose estimation error.