 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Denoising Simulated Low-Field MRI (70mT) using Denoising Autoencoders (DAE) and Cycle-Consistent Generative Adversarial Networks (Cycle-GAN)
Jul 12, 2023
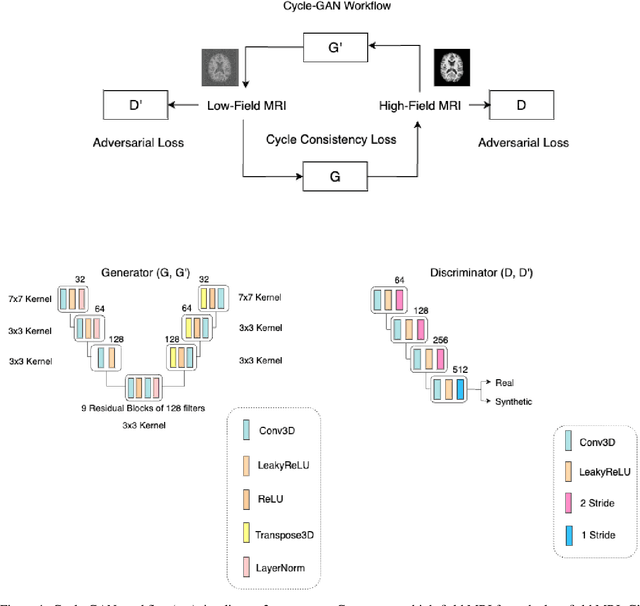
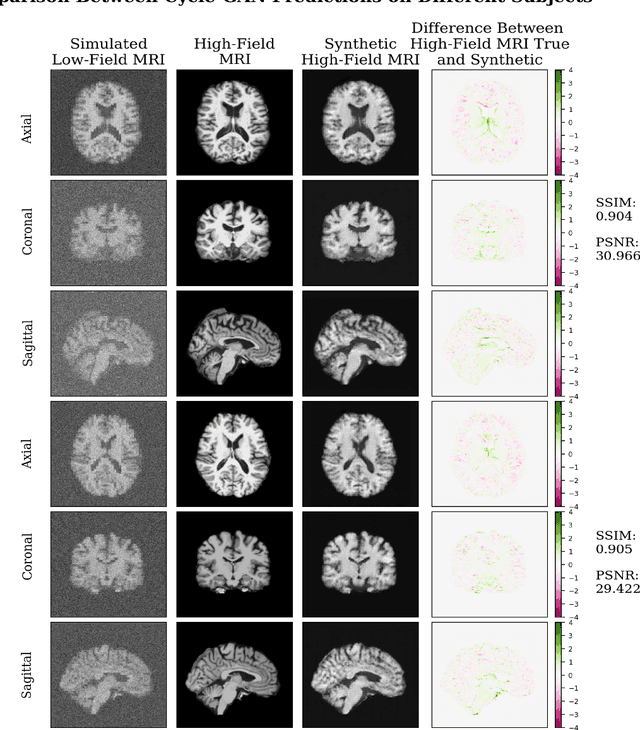
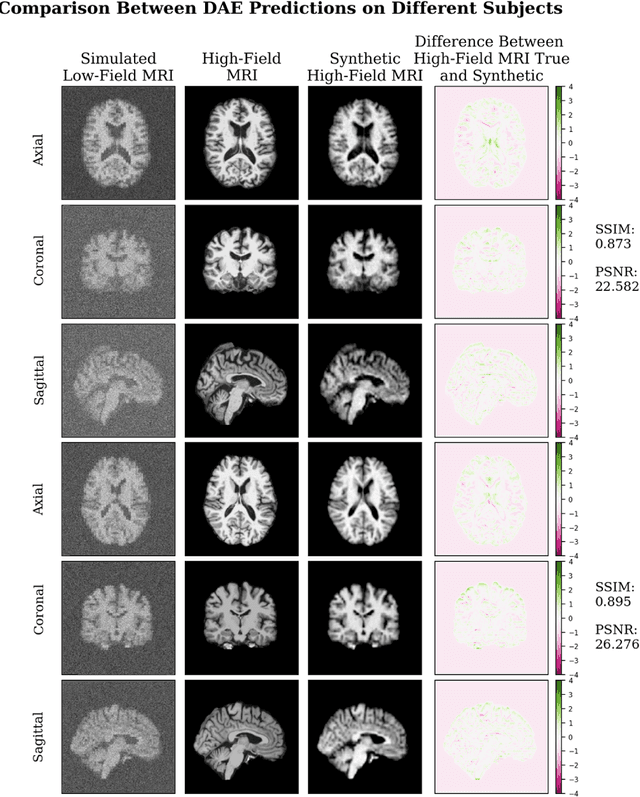
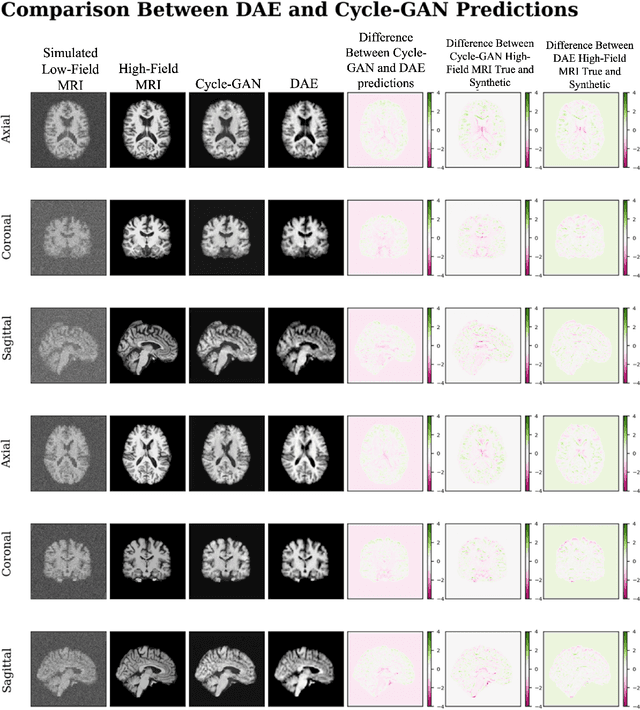
In this work, a denoising Cycle-GAN (Cycle Consistent Generative Adversarial Network) is implemented to yield high-field, high resolution, high signal-to-noise ratio (SNR) Magnetic Resonance Imaging (MRI) images from simulated low-field, low resolution, low SNR MRI images. Resampling and additive Rician noise were used to simulate low-field MRI. Images were utilized to train a Denoising Autoencoder (DAE) and a Cycle-GAN, with paired and unpaired cases. Both networks were evaluated using SSIM and PSNR image quality metrics. This work demonstrates the use of a generative deep learning model that can outperform classical DAEs to improve low-field MRI images and does not require image pairs.
Frequency Domain Adversarial Training for Robust Volumetric Medical Segmentation
Jul 14, 2023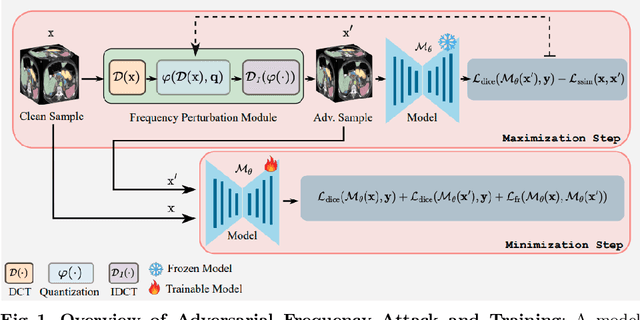

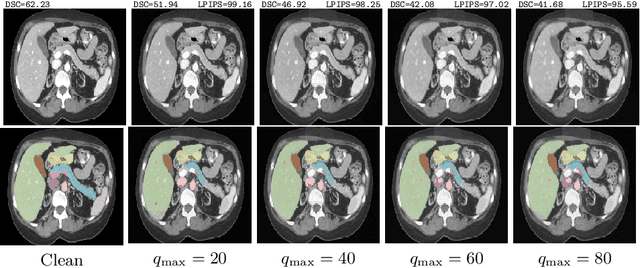
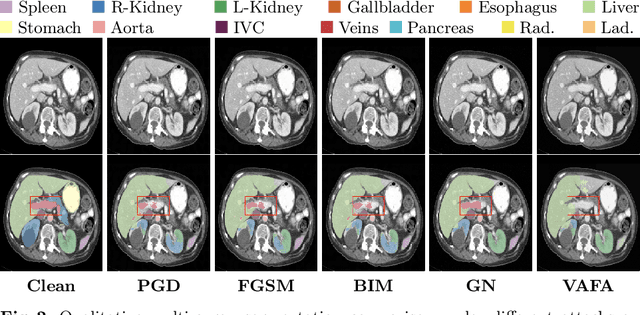
It is imperative to ensure the robustness of deep learning models in critical applications such as, healthcare. While recent advances in deep learning have improved the performance of volumetric medical image segmentation models, these models cannot be deployed for real-world applications immediately due to their vulnerability to adversarial attacks. We present a 3D frequency domain adversarial attack for volumetric medical image segmentation models and demonstrate its advantages over conventional input or voxel domain attacks. Using our proposed attack, we introduce a novel frequency domain adversarial training approach for optimizing a robust model against voxel and frequency domain attacks. Moreover, we propose frequency consistency loss to regulate our frequency domain adversarial training that achieves a better tradeoff between model's performance on clean and adversarial samples. Code is publicly available at https://github.com/asif-hanif/vafa.
Multi-source adversarial transfer learning for ultrasound image segmentation with limited similarity
May 30, 2023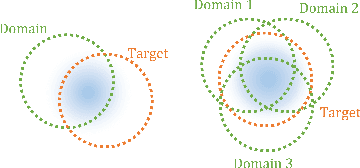
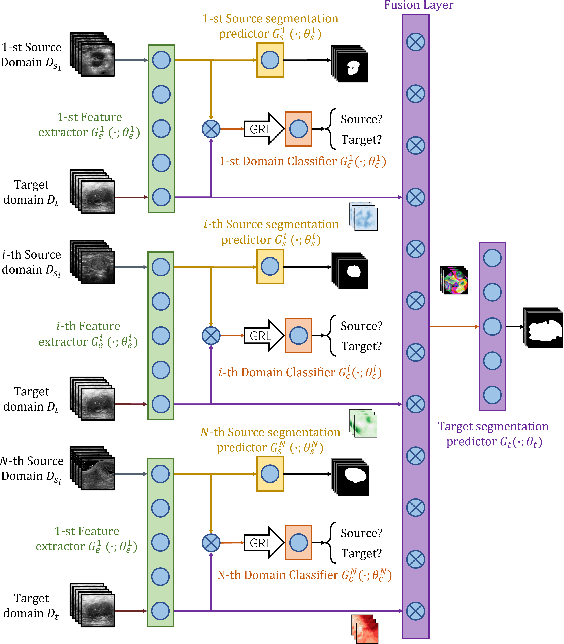
Lesion segmentation of ultrasound medical images based on deep learning techniques is a widely used method for diagnosing diseases. Although there is a large amount of ultrasound image data in medical centers and other places, labeled ultrasound datasets are a scarce resource, and it is likely that no datasets are available for new tissues/organs. Transfer learning provides the possibility to solve this problem, but there are too many features in natural images that are not related to the target domain. As a source domain, redundant features that are not conducive to the task will be extracted. Migration between ultrasound images can avoid this problem, but there are few types of public datasets, and it is difficult to find sufficiently similar source domains. Compared with natural images, ultrasound images have less information, and there are fewer transferable features between different ultrasound images, which may cause negative transfer. To this end, a multi-source adversarial transfer learning network for ultrasound image segmentation is proposed. Specifically, to address the lack of annotations, the idea of adversarial transfer learning is used to adaptively extract common features between a certain pair of source and target domains, which provides the possibility to utilize unlabeled ultrasound data. To alleviate the lack of knowledge in a single source domain, multi-source transfer learning is adopted to fuse knowledge from multiple source domains. In order to ensure the effectiveness of the fusion and maximize the use of precious data, a multi-source domain independent strategy is also proposed to improve the estimation of the target domain data distribution, which further increases the learning ability of the multi-source adversarial migration learning network in multiple domains.
Does Visual Pretraining Help End-to-End Reasoning?
Jul 17, 2023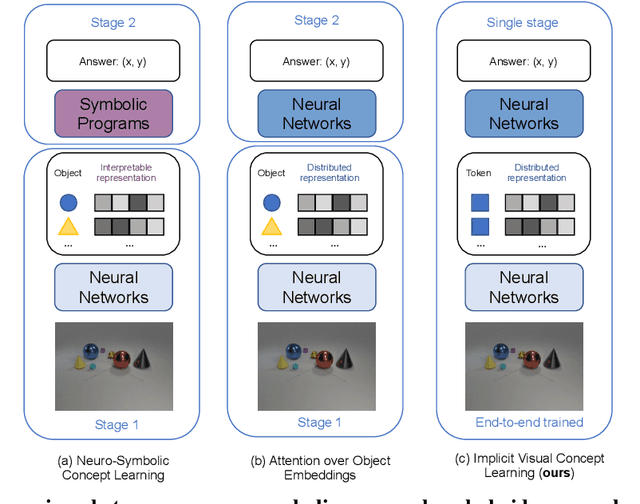
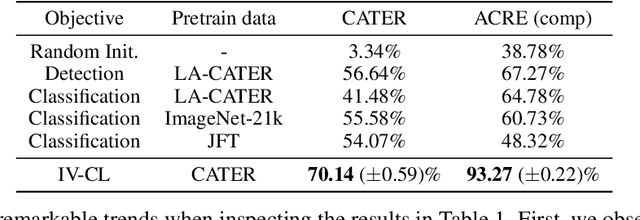
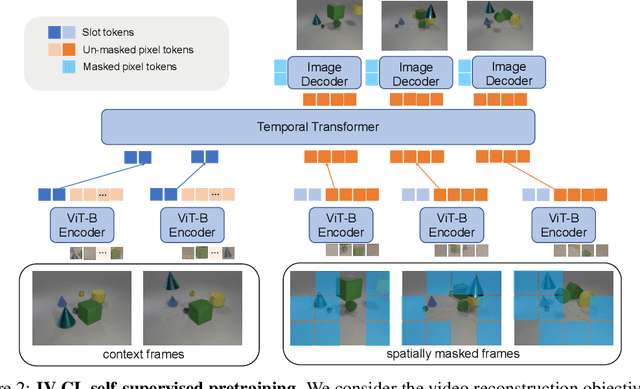
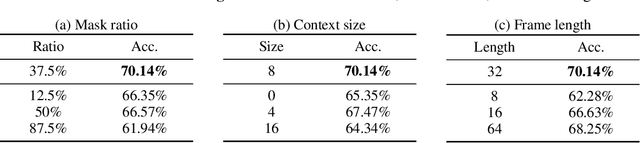
We aim to investigate whether end-to-end learning of visual reasoning can be achieved with general-purpose neural networks, with the help of visual pretraining. A positive result would refute the common belief that explicit visual abstraction (e.g. object detection) is essential for compositional generalization on visual reasoning, and confirm the feasibility of a neural network "generalist" to solve visual recognition and reasoning tasks. We propose a simple and general self-supervised framework which "compresses" each video frame into a small set of tokens with a transformer network, and reconstructs the remaining frames based on the compressed temporal context. To minimize the reconstruction loss, the network must learn a compact representation for each image, as well as capture temporal dynamics and object permanence from temporal context. We perform evaluation on two visual reasoning benchmarks, CATER and ACRE. We observe that pretraining is essential to achieve compositional generalization for end-to-end visual reasoning. Our proposed framework outperforms traditional supervised pretraining, including image classification and explicit object detection, by large margins.
EAML: Ensemble Self-Attention-based Mutual Learning Network for Document Image Classification
May 11, 2023In the recent past, complex deep neural networks have received huge interest in various document understanding tasks such as document image classification and document retrieval. As many document types have a distinct visual style, learning only visual features with deep CNNs to classify document images have encountered the problem of low inter-class discrimination, and high intra-class structural variations between its categories. In parallel, text-level understanding jointly learned with the corresponding visual properties within a given document image has considerably improved the classification performance in terms of accuracy. In this paper, we design a self-attention-based fusion module that serves as a block in our ensemble trainable network. It allows to simultaneously learn the discriminant features of image and text modalities throughout the training stage. Besides, we encourage mutual learning by transferring the positive knowledge between image and text modalities during the training stage. This constraint is realized by adding a truncated-Kullback-Leibler divergence loss Tr-KLD-Reg as a new regularization term, to the conventional supervised setting. To the best of our knowledge, this is the first time to leverage a mutual learning approach along with a self-attention-based fusion module to perform document image classification. The experimental results illustrate the effectiveness of our approach in terms of accuracy for the single-modal and multi-modal modalities. Thus, the proposed ensemble self-attention-based mutual learning model outperforms the state-of-the-art classification results based on the benchmark RVL-CDIP and Tobacco-3482 datasets.
Self-Supervised and Semi-Supervised Polyp Segmentation using Synthetic Data
Jul 22, 2023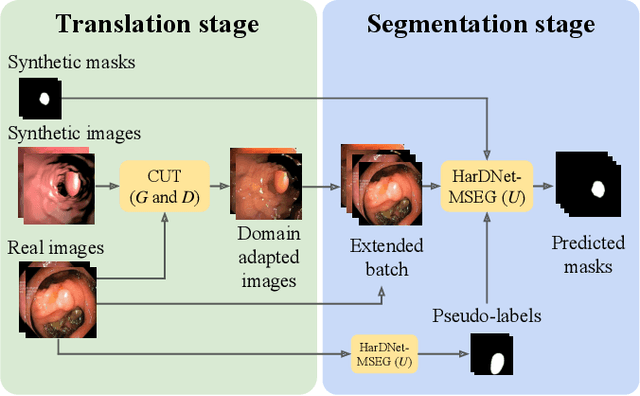
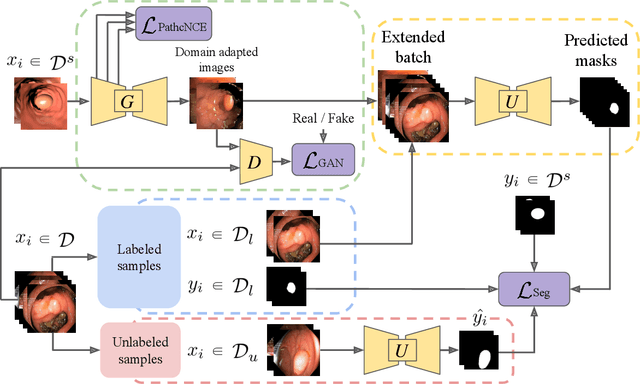
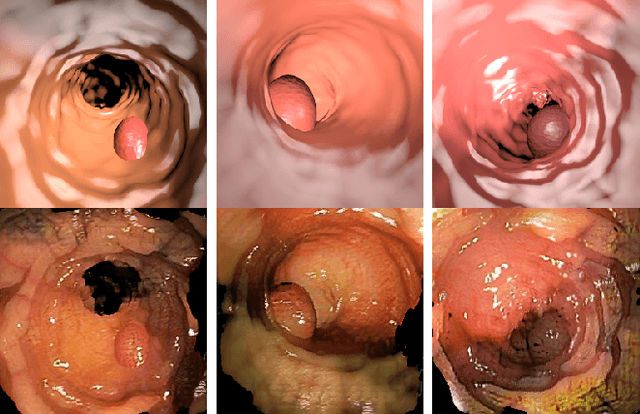
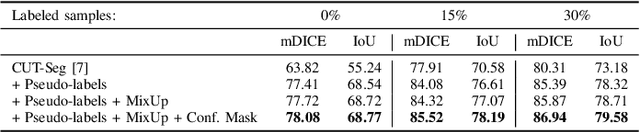
Early detection of colorectal polyps is of utmost importance for their treatment and for colorectal cancer prevention. Computer vision techniques have the potential to aid professionals in the diagnosis stage, where colonoscopies are manually carried out to examine the entirety of the patient's colon. The main challenge in medical imaging is the lack of data, and a further challenge specific to polyp segmentation approaches is the difficulty of manually labeling the available data: the annotation process for segmentation tasks is very time-consuming. While most recent approaches address the data availability challenge with sophisticated techniques to better exploit the available labeled data, few of them explore the self-supervised or semi-supervised paradigm, where the amount of labeling required is greatly reduced. To address both challenges, we leverage synthetic data and propose an end-to-end model for polyp segmentation that integrates real and synthetic data to artificially increase the size of the datasets and aid the training when unlabeled samples are available. Concretely, our model, Pl-CUT-Seg, transforms synthetic images with an image-to-image translation module and combines the resulting images with real images to train a segmentation model, where we use model predictions as pseudo-labels to better leverage unlabeled samples. Additionally, we propose PL-CUT-Seg+, an improved version of the model that incorporates targeted regularization to address the domain gap between real and synthetic images. The models are evaluated on standard benchmarks for polyp segmentation and reach state-of-the-art results in the self- and semi-supervised setups.
EMEF: Ensemble Multi-Exposure Image Fusion
May 22, 2023
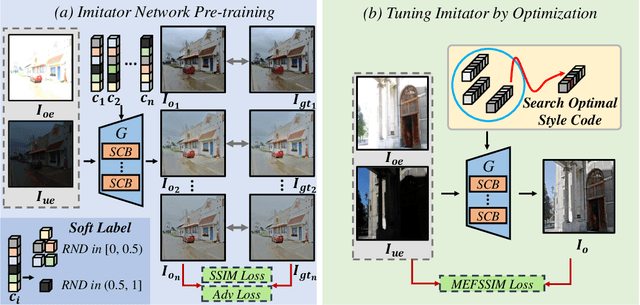
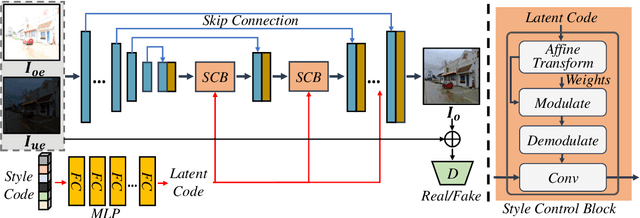

Although remarkable progress has been made in recent years, current multi-exposure image fusion (MEF) research is still bounded by the lack of real ground truth, objective evaluation function, and robust fusion strategy. In this paper, we study the MEF problem from a new perspective. We don't utilize any synthesized ground truth, design any loss function, or develop any fusion strategy. Our proposed method EMEF takes advantage of the wisdom of multiple imperfect MEF contributors including both conventional and deep learning-based methods. Specifically, EMEF consists of two main stages: pre-train an imitator network and tune the imitator in the runtime. In the first stage, we make a unified network imitate different MEF targets in a style modulation way. In the second stage, we tune the imitator network by optimizing the style code, in order to find an optimal fusion result for each input pair. In the experiment, we construct EMEF from four state-of-the-art MEF methods and then make comparisons with the individuals and several other competitive methods on the latest released MEF benchmark dataset. The promising experimental results demonstrate that our ensemble framework can "get the best of all worlds". The code is available at https://github.com/medalwill/EMEF.
Meta-Optimization for Higher Model Generalizability in Single-Image Depth Prediction
May 12, 2023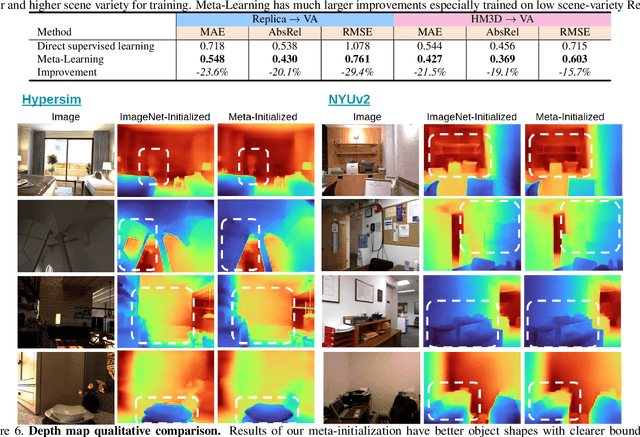
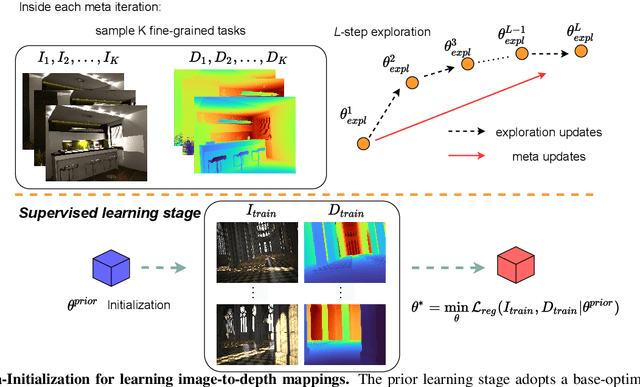
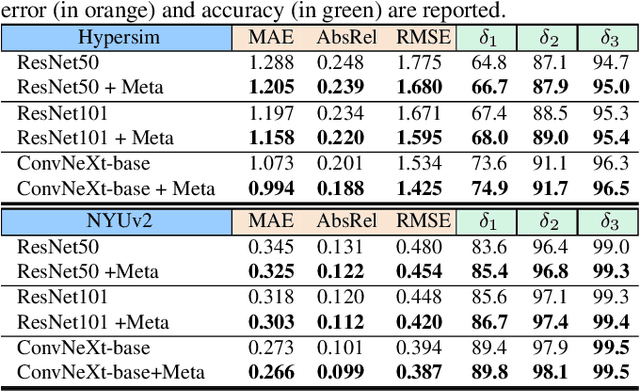
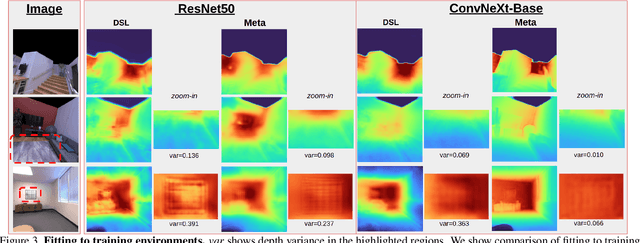
Model generalizability to unseen datasets, concerned with in-the-wild robustness, is less studied for indoor single-image depth prediction. We leverage gradient-based meta-learning for higher generalizability on zero-shot cross-dataset inference. Unlike the most-studied image classification in meta-learning, depth is pixel-level continuous range values, and mappings from each image to depth vary widely across environments. Thus no explicit task boundaries exist. We instead propose fine-grained task that treats each RGB-D pair as a task in our meta-optimization. We first show meta-learning on limited data induces much better prior (max +29.4\%). Using meta-learned weights as initialization for following supervised learning, without involving extra data or information, it consistently outperforms baselines without the method. Compared to most indoor-depth methods that only train/ test on a single dataset, we propose zero-shot cross-dataset protocols, closely evaluate robustness, and show consistently higher generalizability and accuracy by our meta-initialization. The work at the intersection of depth and meta-learning potentially drives both research streams to step closer to practical use.
RenderDiffusion: Text Generation as Image Generation
Apr 25, 2023Diffusion models have become a new generative paradigm for text generation. Considering the discrete categorical nature of text, in this paper, we propose \textsc{RenderDiffusion}, a novel diffusion approach for text generation via text-guided image generation. Our key idea is to render the target text as a \emph{glyph image} containing visual language content. In this way, conditional text generation can be cast as a glyph image generation task, and it is then natural to apply continuous diffusion models to discrete texts. Specially, we utilize a cascaded architecture (\ie a base and a super-resolution diffusion model) to generate high-fidelity glyph images, conditioned on the input text. Furthermore, we design a text grounding module to transform and refine the visual language content from generated glyph images into the final texts. In experiments over four conditional text generation tasks and two classes of metrics (\ie quality and diversity), \textsc{RenderDiffusion} can achieve comparable or even better results than several baselines, including pretrained language models. Our model also makes significant improvements compared to the recent diffusion model.
TbExplain: A Text-based Explanation Method for Scene Classification Models with the Statistical Prediction Correction
Jul 19, 2023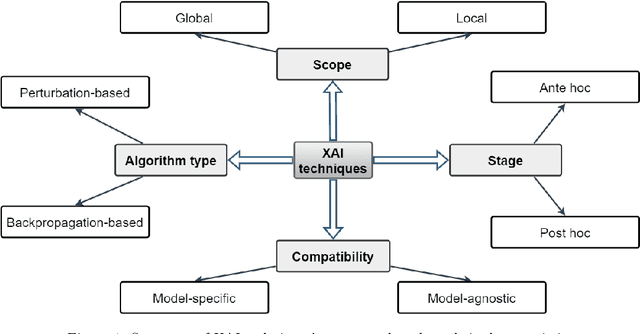

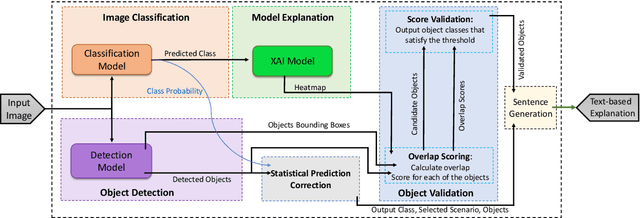
The field of Explainable Artificial Intelligence (XAI) aims to improve the interpretability of black-box machine learning models. Building a heatmap based on the importance value of input features is a popular method for explaining the underlying functions of such models in producing their predictions. Heatmaps are almost understandable to humans, yet they are not without flaws. Non-expert users, for example, may not fully understand the logic of heatmaps (the logic in which relevant pixels to the model's prediction are highlighted with different intensities or colors). Additionally, objects and regions of the input image that are relevant to the model prediction are frequently not entirely differentiated by heatmaps. In this paper, we propose a framework called TbExplain that employs XAI techniques and a pre-trained object detector to present text-based explanations of scene classification models. Moreover, TbExplain incorporates a novel method to correct predictions and textually explain them based on the statistics of objects in the input image when the initial prediction is unreliable. To assess the trustworthiness and validity of the text-based explanations, we conducted a qualitative experiment, and the findings indicated that these explanations are sufficiently reliable. Furthermore, our quantitative and qualitative experiments on TbExplain with scene classification datasets reveal an improvement in classification accuracy over ResNet variants.