 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multimodal Data Augmentation for Image Captioning using Diffusion Models
May 03, 2023

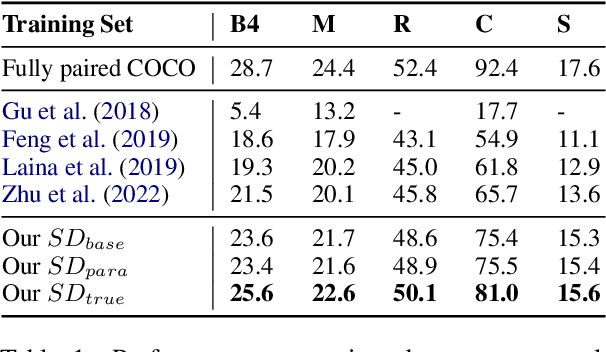
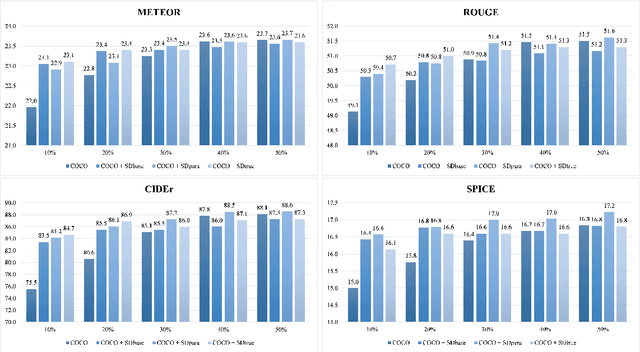
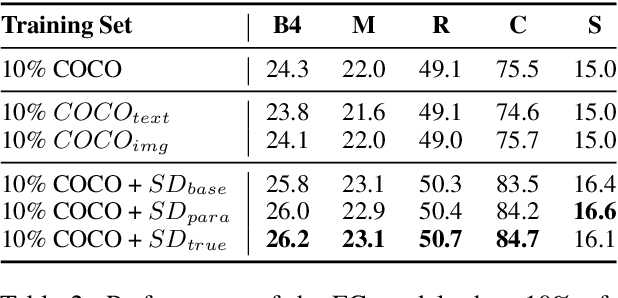
Image captioning, an important vision-language task, often requires a tremendous number of finely labeled image-caption pairs for learning the underlying alignment between images and texts. In this paper, we proposed a multimodal data augmentation method, leveraging a recent text-to-image model called Stable Diffusion, to expand the training set via high-quality generation of image-caption pairs. Extensive experiments on the MS COCO dataset demonstrate the advantages of our approach over several benchmark methods, and particularly a significant boost when having fewer training instances. In addition, models trained on our augmented datasets also outperform prior unpaired image captioning methods by a large margin. Finally, further improvement regarding the training efficiency and effectiveness can be obtained after intentionally filtering the generated data based on quality assessment.
GIFD: A Generative Gradient Inversion Method with Feature Domain Optimization
Aug 09, 2023
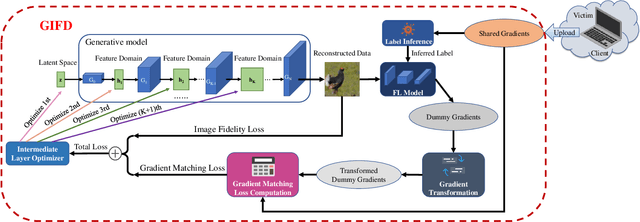
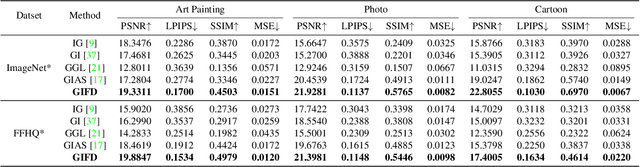
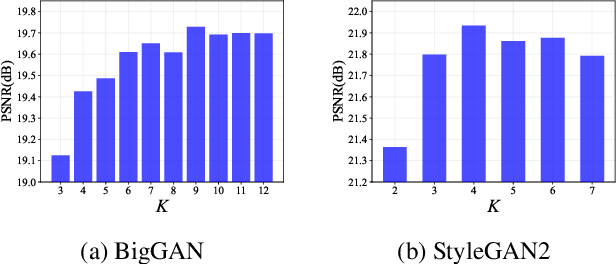
Federated Learning (FL) has recently emerged as a promising distributed machine learning framework to preserve clients' privacy, by allowing multiple clients to upload the gradients calculated from their local data to a central server. Recent studies find that the exchanged gradients also take the risk of privacy leakage, e.g., an attacker can invert the shared gradients and recover sensitive data against an FL system by leveraging pre-trained generative adversarial networks (GAN) as prior knowledge. However, performing gradient inversion attacks in the latent space of the GAN model limits their expression ability and generalizability. To tackle these challenges, we propose \textbf{G}radient \textbf{I}nversion over \textbf{F}eature \textbf{D}omains (GIFD), which disassembles the GAN model and searches the feature domains of the intermediate layers. Instead of optimizing only over the initial latent code, we progressively change the optimized layer, from the initial latent space to intermediate layers closer to the output images. In addition, we design a regularizer to avoid unreal image generation by adding a small ${l_1}$ ball constraint to the searching range. We also extend GIFD to the out-of-distribution (OOD) setting, which weakens the assumption that the training sets of GANs and FL tasks obey the same data distribution. Extensive experiments demonstrate that our method can achieve pixel-level reconstruction and is superior to the existing methods. Notably, GIFD also shows great generalizability under different defense strategy settings and batch sizes.
Self-supervised Landmark Learning with Deformation Reconstruction and Cross-subject Consistency Objectives
Aug 09, 2023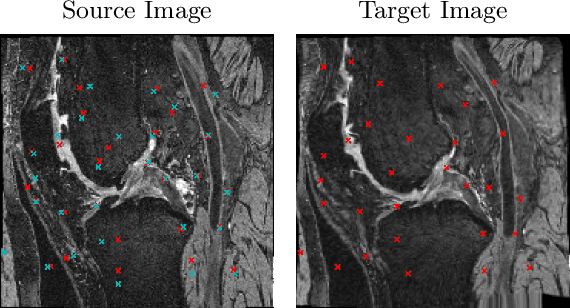
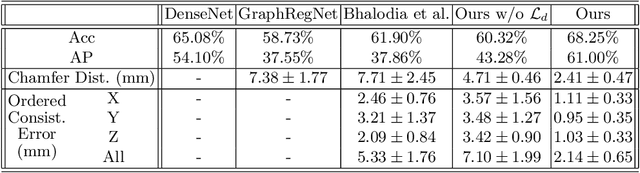
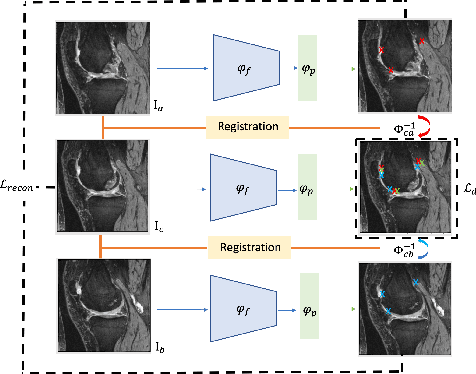
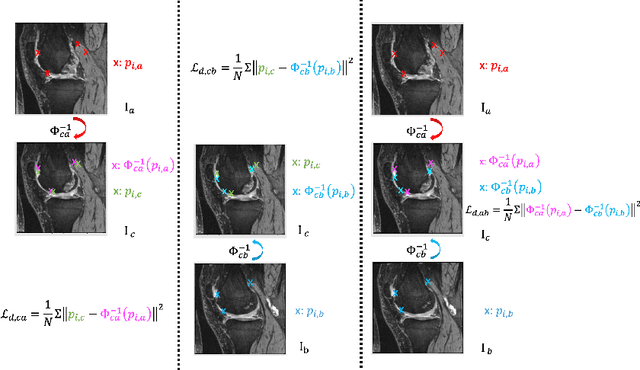
A Point Distribution Model (PDM) is the basis of a Statistical Shape Model (SSM) that relies on a set of landmark points to represent a shape and characterize the shape variation. In this work, we present a self-supervised approach to extract landmark points from a given registration model for the PDMs. Based on the assumption that the landmarks are the points that have the most influence on registration, existing works learn a point-based registration model with a small number of points to estimate the landmark points that influence the deformation the most. However, such approaches assume that the deformation can be captured by point-based registration and quality landmarks can be learned solely with the deformation capturing objective. We argue that data with complicated deformations can not easily be modeled with point-based registration when only a limited number of points is used to extract influential landmark points. Further, landmark consistency is not assured in existing approaches In contrast, we propose to extract landmarks based on a given registration model, which is tailored for the target data, so we can obtain more accurate correspondences. Secondly, to establish the anatomical consistency of the predicted landmarks, we introduce a landmark discovery loss to explicitly encourage the model to predict the landmarks that are anatomically consistent across subjects. We conduct experiments on an osteoarthritis progression prediction task and show our method outperforms existing image-based and point-based approaches.
NeRFs: The Search for the Best 3D Representation
Aug 05, 2023
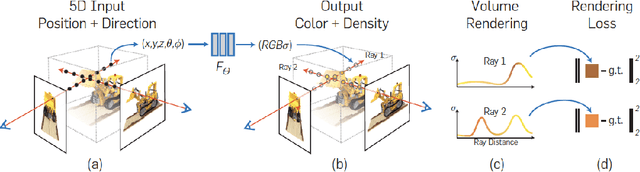

Neural Radiance Fields or NeRFs have become the representation of choice for problems in view synthesis or image-based rendering, as well as in many other applications across computer graphics and vision, and beyond. At their core, NeRFs describe a new representation of 3D scenes or 3D geometry. Instead of meshes, disparity maps, multiplane images or even voxel grids, they represent the scene as a continuous volume, with volumetric parameters like view-dependent radiance and volume density obtained by querying a neural network. The NeRF representation has now been widely used, with thousands of papers extending or building on it every year, multiple authors and websites providing overviews and surveys, and numerous industrial applications and startup companies. In this article, we briefly review the NeRF representation, and describe the three decades-long quest to find the best 3D representation for view synthesis and related problems, culminating in the NeRF papers. We then describe new developments in terms of NeRF representations and make some observations and insights regarding the future of 3D representations.
Experiments on Generative AI-Powered Parametric Modeling and BIM for Architectural Design
Aug 01, 2023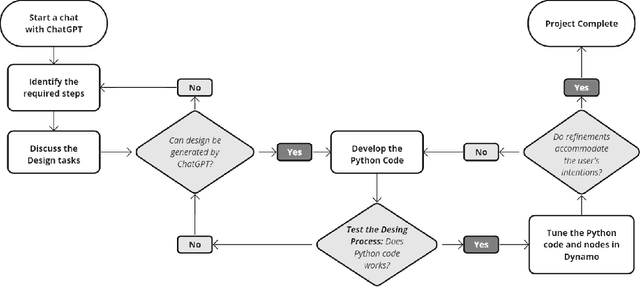


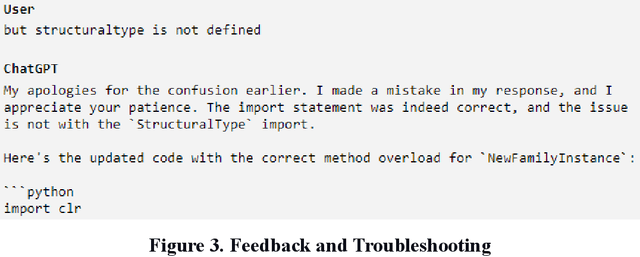
This paper introduces a new architectural design framework that utilizes generative AI tools including ChatGPT and Veras with parametric modeling and Building Information Modeling (BIM) to enhance the design process. The study experiments with the potential of ChatGPT and generative AI in 3D architectural design, extending beyond its use in text and 2D image generation. The proposed framework promotes collaboration between architects and AI, facilitating a quick exploration of design ideas and producing context-sensitive, creative design generation. By integrating ChatGPT for scripting and Veras for generating design ideas with widely used parametric modeling and BIM tools, the framework provides architects with an intuitive and powerful method to convey design intent, leading to more efficient, creative, and collaborative design processes.
Flight Contrail Segmentation via Augmented Transfer Learning with Novel SR Loss Function in Hough Space
Jul 22, 2023
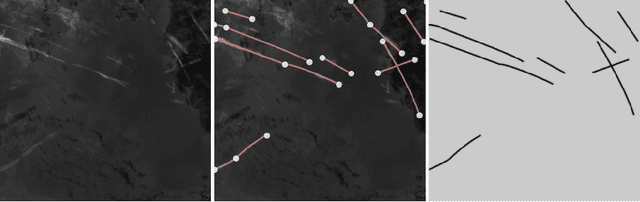
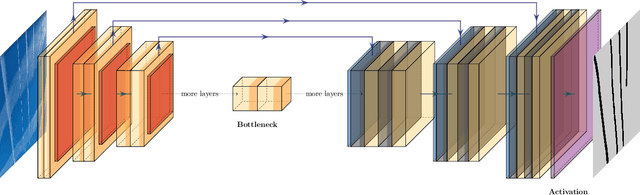
Air transport poses significant environmental challenges, particularly the contribution of flight contrails to climate change due to their potential global warming impact. Detecting contrails from satellite images has been a long-standing challenge. Traditional computer vision techniques have limitations under varying image conditions, and machine learning approaches using typical convolutional neural networks are hindered by the scarcity of hand-labeled contrail datasets and contrail-tailored learning processes. In this paper, we introduce an innovative model based on augmented transfer learning that accurately detects contrails with minimal data. We also propose a novel loss function, SR Loss, which improves contrail line detection by transforming the image space into Hough space. Our research opens new avenues for machine learning-based contrail detection in aviation research, offering solutions to the lack of large hand-labeled datasets, and significantly enhancing contrail detection models.
Blind Image Quality Assessment via Transformer Predicted Error Map and Perceptual Quality Token
May 16, 2023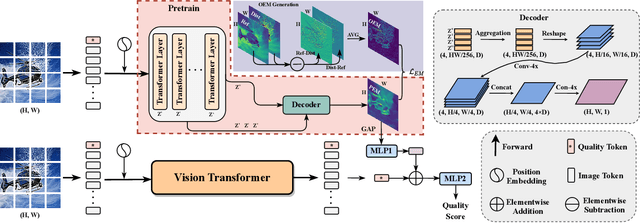
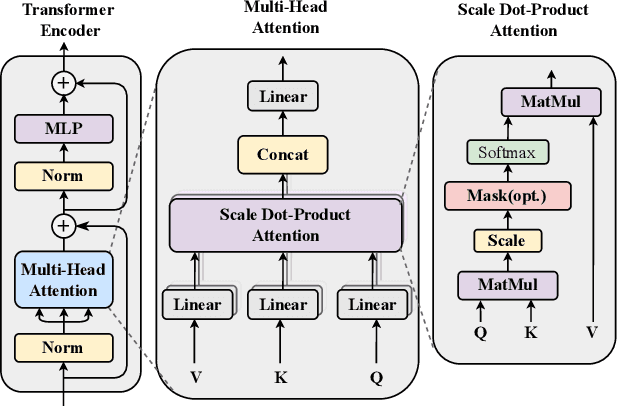
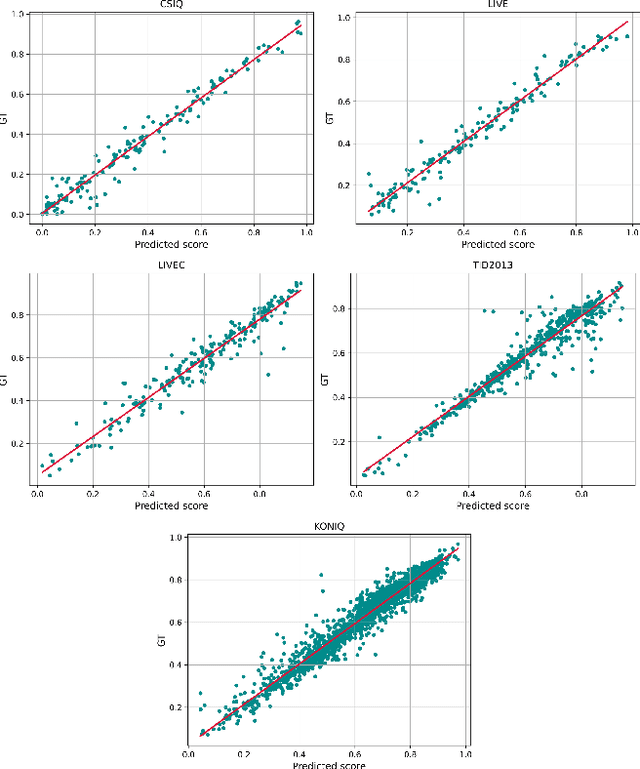

Image quality assessment is a fundamental problem in the field of image processing, and due to the lack of reference images in most practical scenarios, no-reference image quality assessment (NR-IQA), has gained increasing attention recently. With the development of deep learning technology, many deep neural network-based NR-IQA methods have been developed, which try to learn the image quality based on the understanding of database information. Currently, Transformer has achieved remarkable progress in various vision tasks. Since the characteristics of the attention mechanism in Transformer fit the global perceptual impact of artifacts perceived by a human, Transformer is thus well suited for image quality assessment tasks. In this paper, we propose a Transformer based NR-IQA model using a predicted objective error map and perceptual quality token. Specifically, we firstly generate the predicted error map by pre-training one model consisting of a Transformer encoder and decoder, in which the objective difference between the distorted and the reference images is used as supervision. Then, we freeze the parameters of the pre-trained model and design another branch using the vision Transformer to extract the perceptual quality token for feature fusion with the predicted error map. Finally, the fused features are regressed to the final image quality score. Extensive experiments have shown that our proposed method outperforms the current state-of-the-art in both authentic and synthetic image databases. Moreover, the attentional map extracted by the perceptual quality token also does conform to the characteristics of the human visual system.
LUCYD: A Feature-Driven Richardson-Lucy Deconvolution Network
Jul 16, 2023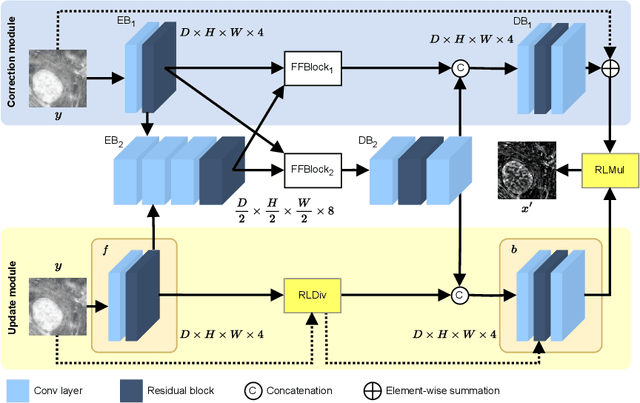
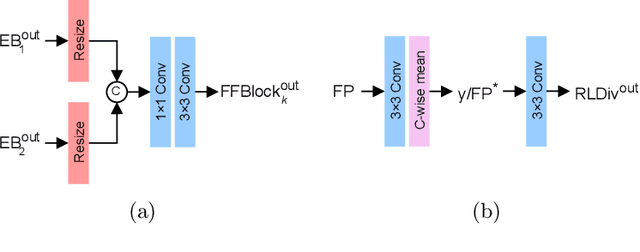
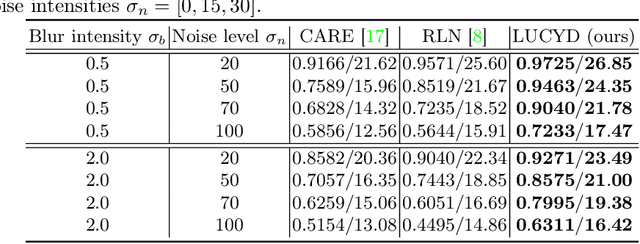
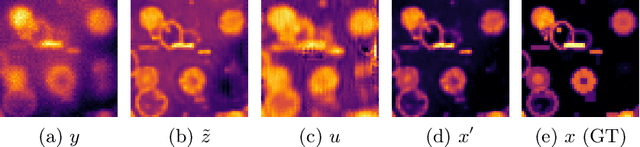
The process of acquiring microscopic images in life sciences often results in image degradation and corruption, characterised by the presence of noise and blur, which poses significant challenges in accurately analysing and interpreting the obtained data. This paper proposes LUCYD, a novel method for the restoration of volumetric microscopy images that combines the Richardson-Lucy deconvolution formula and the fusion of deep features obtained by a fully convolutional network. By integrating the image formation process into a feature-driven restoration model, the proposed approach aims to enhance the quality of the restored images whilst reducing computational costs and maintaining a high degree of interpretability. Our results demonstrate that LUCYD outperforms the state-of-the-art methods in both synthetic and real microscopy images, achieving superior performance in terms of image quality and generalisability. We show that the model can handle various microscopy modalities and different imaging conditions by evaluating it on two different microscopy datasets, including volumetric widefield and light-sheet microscopy. Our experiments indicate that LUCYD can significantly improve resolution, contrast, and overall quality of microscopy images. Therefore, it can be a valuable tool for microscopy image restoration and can facilitate further research in various microscopy applications. We made the source code for the model accessible under https://github.com/ctom2/lucyd-deconvolution.
FeatEnHancer: Enhancing Hierarchical Features for Object Detection and Beyond Under Low-Light Vision
Aug 07, 2023
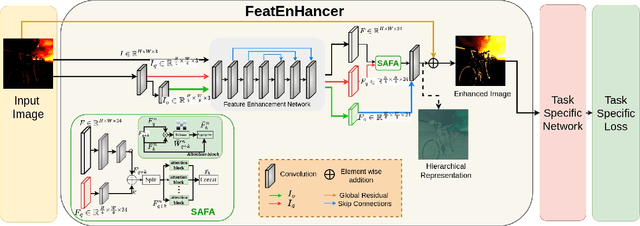
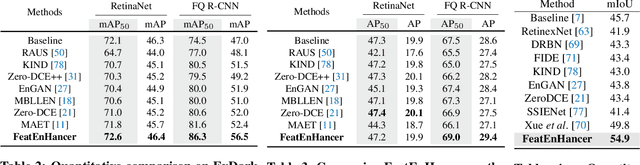

Extracting useful visual cues for the downstream tasks is especially challenging under low-light vision. Prior works create enhanced representations by either correlating visual quality with machine perception or designing illumination-degrading transformation methods that require pre-training on synthetic datasets. We argue that optimizing enhanced image representation pertaining to the loss of the downstream task can result in more expressive representations. Therefore, in this work, we propose a novel module, FeatEnHancer, that hierarchically combines multiscale features using multiheaded attention guided by task-related loss function to create suitable representations. Furthermore, our intra-scale enhancement improves the quality of features extracted at each scale or level, as well as combines features from different scales in a way that reflects their relative importance for the task at hand. FeatEnHancer is a general-purpose plug-and-play module and can be incorporated into any low-light vision pipeline. We show with extensive experimentation that the enhanced representation produced with FeatEnHancer significantly and consistently improves results in several low-light vision tasks, including dark object detection (+5.7 mAP on ExDark), face detection (+1.5 mAPon DARK FACE), nighttime semantic segmentation (+5.1 mIoU on ACDC ), and video object detection (+1.8 mAP on DarkVision), highlighting the effectiveness of enhancing hierarchical features under low-light vision.
Imperceptible Physical Attack against Face Recognition Systems via LED Illumination Modulation
Aug 07, 2023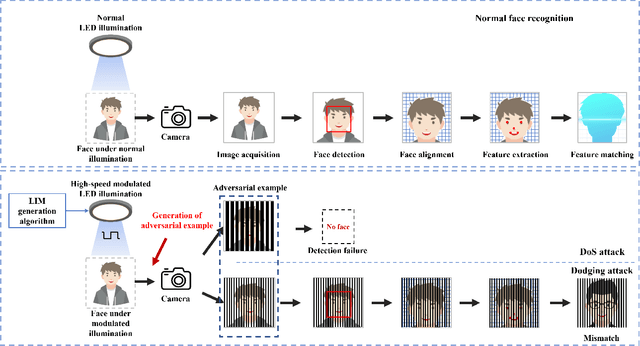
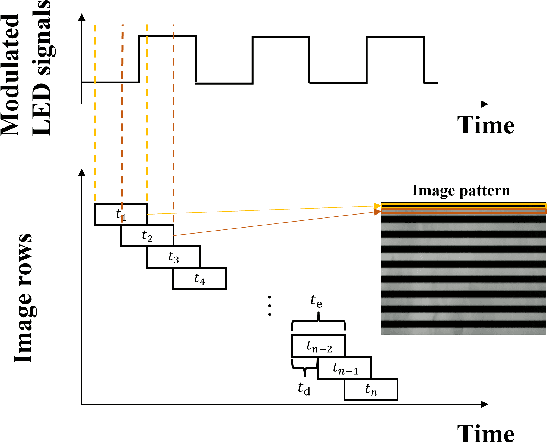
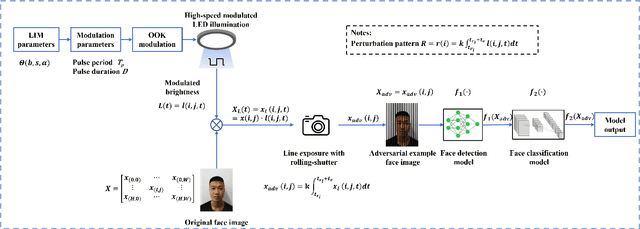

Although face recognition starts to play an important role in our daily life, we need to pay attention that data-driven face recognition vision systems are vulnerable to adversarial attacks. However, the current two categories of adversarial attacks, namely digital attacks and physical attacks both have drawbacks, with the former ones impractical and the latter one conspicuous, high-computational and inexecutable. To address the issues, we propose a practical, executable, inconspicuous and low computational adversarial attack based on LED illumination modulation. To fool the systems, the proposed attack generates imperceptible luminance changes to human eyes through fast intensity modulation of scene LED illumination and uses the rolling shutter effect of CMOS image sensors in face recognition systems to implant luminance information perturbation to the captured face images. In summary,we present a denial-of-service (DoS) attack for face detection and a dodging attack for face verification. We also evaluate their effectiveness against well-known face detection models, Dlib, MTCNN and RetinaFace , and face verification models, Dlib, FaceNet,and ArcFace.The extensive experiments show that the success rates of DoS attacks against face detection models reach 97.67%, 100%, and 100%, respectively, and the success rates of dodging attacks against all face verification models reach 100%.